 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Exploring Nature: Datasets and Models for Analyzing Nature-Related Disclosures
Dec 28, 2023
Nature is an amorphous concept. Yet, it is essential for the planet's well-being to understand how the economy interacts with it. To address the growing demand for information on corporate nature disclosure, we provide datasets and classifiers to detect nature communication by companies. We ground our approach in the guidelines of the Taskforce on Nature-related Financial Disclosures (TNFD). Particularly, we focus on the specific dimensions of water, forest, and biodiversity. For each dimension, we create an expert-annotated dataset with 2,200 text samples and train classifier models. Furthermore, we show that nature communication is more prevalent in hotspot areas and directly effected industries like agriculture and utilities. Our approach is the first to respond to calls to assess corporate nature communication on a large scale.
Do Androids Know They're Only Dreaming of Electric Sheep?
Dec 28, 2023We design probes trained on the internal representations of a transformer language model that are predictive of its hallucinatory behavior on in-context generation tasks. To facilitate this detection, we create a span-annotated dataset of organic and synthetic hallucinations over several tasks. We find that probes trained on the force-decoded states of synthetic hallucinations are generally ecologically invalid in organic hallucination detection. Furthermore, hidden state information about hallucination appears to be task and distribution-dependent. Intrinsic and extrinsic hallucination saliency varies across layers, hidden state types, and tasks; notably, extrinsic hallucinations tend to be more salient in a transformer's internal representations. Outperforming multiple contemporary baselines, we show that probing is a feasible and efficient alternative to language model hallucination evaluation when model states are available.
Context-aware Communication for Multi-agent Reinforcement Learning
Dec 25, 2023Effective communication protocols in multi-agent reinforcement learning (MARL) are critical to fostering cooperation and enhancing team performance. To leverage communication, many previous works have proposed to compress local information into a single message and broadcast it to all reachable agents. This simplistic messaging mechanism, however, may fail to provide adequate, critical, and relevant information to individual agents, especially in severely bandwidth-limited scenarios. This motivates us to develop context-aware communication schemes for MARL, aiming to deliver personalized messages to different agents. Our communication protocol, named CACOM, consists of two stages. In the first stage, agents exchange coarse representations in a broadcast fashion, providing context for the second stage. Following this, agents utilize attention mechanisms in the second stage to selectively generate messages personalized for the receivers. Furthermore, we employ the learned step size quantization (LSQ) technique for message quantization to reduce the communication overhead. To evaluate the effectiveness of CACOM, we integrate it with both actor-critic and value-based MARL algorithms. Empirical results on cooperative benchmark tasks demonstrate that CACOM provides evident performance gains over baselines under communication-constrained scenarios.
Visual Point Cloud Forecasting enables Scalable Autonomous Driving
Dec 29, 2023In contrast to extensive studies on general vision, pre-training for scalable visual autonomous driving remains seldom explored. Visual autonomous driving applications require features encompassing semantics, 3D geometry, and temporal information simultaneously for joint perception, prediction, and planning, posing dramatic challenges for pre-training. To resolve this, we bring up a new pre-training task termed as visual point cloud forecasting - predicting future point clouds from historical visual input. The key merit of this task captures the synergic learning of semantics, 3D structures, and temporal dynamics. Hence it shows superiority in various downstream tasks. To cope with this new problem, we present ViDAR, a general model to pre-train downstream visual encoders. It first extracts historical embeddings by the encoder. These representations are then transformed to 3D geometric space via a novel Latent Rendering operator for future point cloud prediction. Experiments show significant gain in downstream tasks, e.g., 3.1% NDS on 3D detection, ~10% error reduction on motion forecasting, and ~15% less collision rate on planning.
Robust TOA-based Localization with Inaccurate Anchors for MANET
Dec 29, 2023Accurate node localization is vital for mobile ad hoc networks (MANETs). Current methods like Time of Arrival (TOA) can estimate node positions using imprecise baseplates and achieve the Cram\'er-Rao lower bound (CRLB) accuracy. In multi-hop MANETs, some nodes lack direct links to base anchors, depending on neighbor nodes as dynamic anchors for chain localization. However, the dynamic nature of MANETs challenges TOA's robustness due to the availability and accuracy of base anchors, coupled with ranging errors. To address the issue of cascading positioning error divergence, we first derive the CRLB for any primary node in MANETs as a metric to tackle localization error in cascading scenarios. Second, we propose an advanced two-step TOA method based on CRLB which is able to approximate target node's CRLB with only local neighbor information. Finally, simulation results confirm the robustness of our algorithm, achieving CRLB-level accuracy for small ranging errors and maintaining precision for larger errors compared to existing TOA methods.
K-PERM: Personalized Response Generation Using Dynamic Knowledge Retrieval and Persona-Adaptive Queries
Dec 29, 2023Personalizing conversational agents can enhance the quality of conversations and increase user engagement. However, they often lack external knowledge to appropriately tend to a user's persona. This is particularly crucial for practical applications like mental health support, nutrition planning, culturally sensitive conversations, or reducing toxic behavior in conversational agents. To enhance the relevance and comprehensiveness of personalized responses, we propose using a two-step approach that involves (1) selectively integrating user personas and (2) contextualizing the response with supplementing information from a background knowledge source. We develop K-PERM (Knowledge-guided PErsonalization with Reward Modulation), a dynamic conversational agent that combines these elements. K-PERM achieves state-of-the-art performance on the popular FoCus dataset, containing real-world personalized conversations concerning global landmarks. We show that using responses from K-PERM can improve performance in state-of-the-art LLMs (GPT 3.5) by 10.5%, highlighting the impact of K-PERM for personalizing chatbots.
Accent-VITS:accent transfer for end-to-end TTS
Dec 29, 2023Accent transfer aims to transfer an accent from a source speaker to synthetic speech in the target speaker's voice. The main challenge is how to effectively disentangle speaker timbre and accent which are entangled in speech. This paper presents a VITS-based end-to-end accent transfer model named Accent-VITS.Based on the main structure of VITS, Accent-VITS makes substantial improvements to enable effective and stable accent transfer.We leverage a hierarchical CVAE structure to model accent pronunciation information and acoustic features, respectively, using bottleneck features and mel spectrums as constraints.Moreover, the text-to-wave mapping in VITS is decomposed into text-to-accent and accent-to-wave mappings in Accent-VITS. In this way, the disentanglement of accent and speaker timbre becomes be more stable and effective.Experiments on multi-accent and Mandarin datasets show that Accent-VITS achieves higher speaker similarity, accent similarity and speech naturalness as compared with a strong baseline.
DarkShot: Lighting Dark Images with Low-Compute and High-Quality
Dec 29, 2023Nighttime photography encounters escalating challenges in extremely low-light conditions, primarily attributable to the ultra-low signal-to-noise ratio. For real-world deployment, a practical solution must not only produce visually appealing results but also require minimal computation. However, most existing methods are either focused on improving restoration performance or employ lightweight models at the cost of quality. This paper proposes a lightweight network that outperforms existing state-of-the-art (SOTA) methods in low-light enhancement tasks while minimizing computation. The proposed network incorporates Siamese Self-Attention Block (SSAB) and Skip-Channel Attention (SCA) modules, which enhance the model's capacity to aggregate global information and are well-suited for high-resolution images. Additionally, based on our analysis of the low-light image restoration process, we propose a Two-Stage Framework that achieves superior results. Our model can restore a UHD 4K resolution image with minimal computation while keeping SOTA restoration quality.
Decoupling SQL Query Hardness Parsing for Text-to-SQL
Dec 29, 2023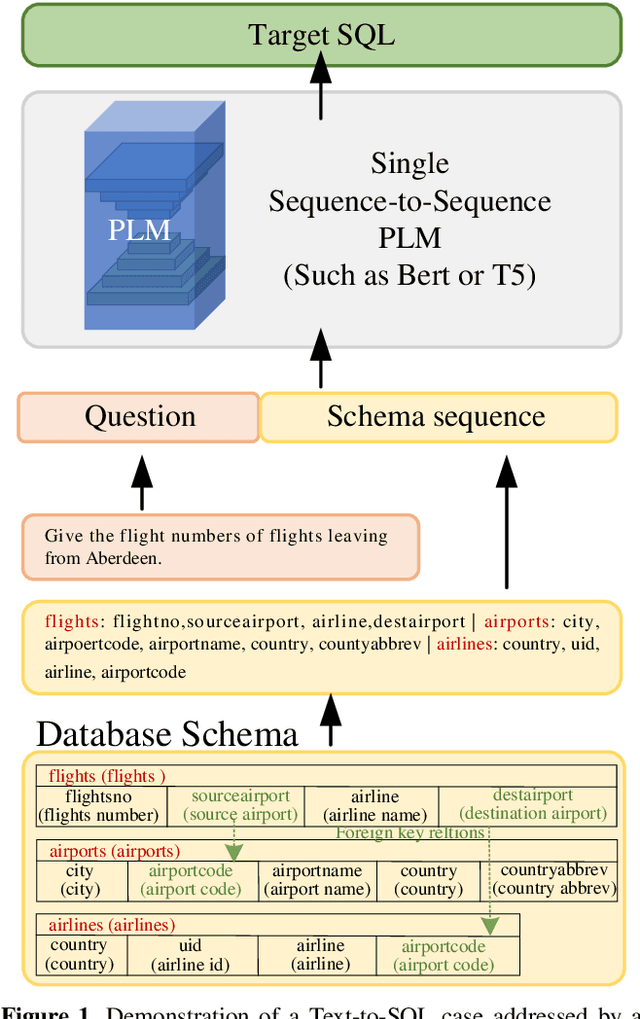


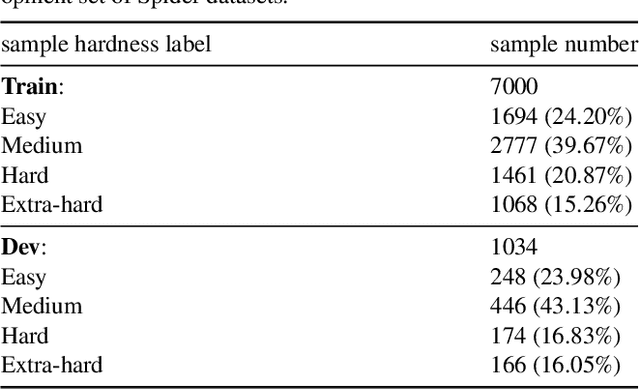
The fundamental goal of the Text-to-SQL task is to translate natural language question into SQL query. Current research primarily emphasizes the information coupling between natural language questions and schemas, and significant progress has been made in this area. The natural language questions as the primary task requirements source determines the hardness of correspond SQL queries, the correlation between the two always be ignored. However, when the correlation between questions and queries was decoupled, it may simplify the task. In this paper, we introduce an innovative framework for Text-to-SQL based on decoupling SQL query hardness parsing. This framework decouples the Text-to-SQL task based on query hardness by analyzing questions and schemas, simplifying the multi-hardness task into a single-hardness challenge. This greatly reduces the parsing pressure on the language model. We evaluate our proposed framework and achieve a new state-of-the-art performance of fine-turning methods on Spider dev.
Client-wise Modality Selection for Balanced Multi-modal Federated Learning
Dec 31, 2023Selecting proper clients to participate in the iterative federated learning (FL) rounds is critical to effectively harness a broad range of distributed datasets. Existing client selection methods simply consider the variability among FL clients with uni-modal data, however, have yet to consider clients with multi-modalities. We reveal that traditional client selection scheme in MFL may suffer from a severe modality-level bias, which impedes the collaborative exploitation of multi-modal data, leading to insufficient local data exploration and global aggregation. To tackle this challenge, we propose a Client-wise Modality Selection scheme for MFL (CMSFed) that can comprehensively utilize information from each modality via avoiding such client selection bias caused by modality imbalance. Specifically, in each MFL round, the local data from different modalities are selectively employed to participate in local training and aggregation to mitigate potential modality imbalance of the global model. To approximate the fully aggregated model update in a balanced way, we introduce a novel local training loss function to enhance the weak modality and align the divergent feature spaces caused by inconsistent modality adoption strategies for different clients simultaneously. Then, a modality-level gradient decoupling method is designed to derive respective submodular functions to maintain the gradient diversity during the selection progress and balance MFL according to local modality imbalance in each iteration. Our extensive experiments showcase the superiority of CMSFed over baselines and its effectiveness in multi-modal data exploitation.