 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
AQuA -- Combining Experts' and Non-Experts' Views To Assess Deliberation Quality in Online Discussions Using LLMs
Apr 04, 2024
Measuring the quality of contributions in political online discussions is crucial in deliberation research and computer science. Research has identified various indicators to assess online discussion quality, and with deep learning advancements, automating these measures has become feasible. While some studies focus on analyzing specific quality indicators, a comprehensive quality score incorporating various deliberative aspects is often preferred. In this work, we introduce AQuA, an additive score that calculates a unified deliberative quality score from multiple indices for each discussion post. Unlike other singular scores, AQuA preserves information on the deliberative aspects present in comments, enhancing model transparency. We develop adapter models for 20 deliberative indices, and calculate correlation coefficients between experts' annotations and the perceived deliberativeness by non-experts to weigh the individual indices into a single deliberative score. We demonstrate that the AQuA score can be computed easily from pre-trained adapters and aligns well with annotations on other datasets that have not be seen during training. The analysis of experts' vs. non-experts' annotations confirms theoretical findings in the social science literature.
Decentralised Moderation for Interoperable Social Networks: A Conversation-based Approach for Pleroma and the Fediverse
Apr 03, 2024The recent development of decentralised and interoperable social networks (such as the "fediverse") creates new challenges for content moderators. This is because millions of posts generated on one server can easily "spread" to another, even if the recipient server has very different moderation policies. An obvious solution would be to leverage moderation tools to automatically tag (and filter) posts that contravene moderation policies, e.g. related to toxic speech. Recent work has exploited the conversational context of a post to improve this automatic tagging, e.g. using the replies to a post to help classify if it contains toxic speech. This has shown particular potential in environments with large training sets that contain complete conversations. This, however, creates challenges in a decentralised context, as a single conversation may be fragmented across multiple servers. Thus, each server only has a partial view of an entire conversation because conversations are often federated across servers in a non-synchronized fashion. To address this, we propose a decentralised conversation-aware content moderation approach suitable for the fediverse. Our approach employs a graph deep learning model (GraphNLI) trained locally on each server. The model exploits local data to train a model that combines post and conversational information captured through random walks to detect toxicity. We evaluate our approach with data from Pleroma, a major decentralised and interoperable micro-blogging network containing 2 million conversations. Our model effectively detects toxicity on larger instances, exclusively trained using their local post information (0.8837 macro-F1). Our approach has considerable scope to improve moderation in decentralised and interoperable social networks such as Pleroma or Mastodon.
SLIMBRAIN: Augmented Reality Real-Time Acquisition and Processing System For Hyperspectral Classification Mapping with Depth Information for In-Vivo Surgical Procedures
Mar 25, 2024Over the last two decades, augmented reality (AR) has led to the rapid development of new interfaces in various fields of social and technological application domains. One such domain is medicine, and to a higher extent surgery, where these visualization techniques help to improve the effectiveness of preoperative and intraoperative procedures. Following this trend, this paper presents SLIMBRAIN, a real-time acquisition and processing AR system suitable to classify and display brain tumor tissue from hyperspectral (HS) information. This system captures and processes HS images at 14 frames per second (FPS) during the course of a tumor resection operation to detect and delimit cancer tissue at the same time the neurosurgeon operates. The result is represented in an AR visualization where the classification results are overlapped with the RGB point cloud captured by a LiDAR camera. This representation allows natural navigation of the scene at the same time it is captured and processed, improving the visualization and hence effectiveness of the HS technology to delimit tumors. The whole system has been verified in real brain tumor resection operations.
Near-Field Channel Estimation in Dual-Band XL-MIMO with Side Information-Assisted Compressed Sensing
Mar 19, 2024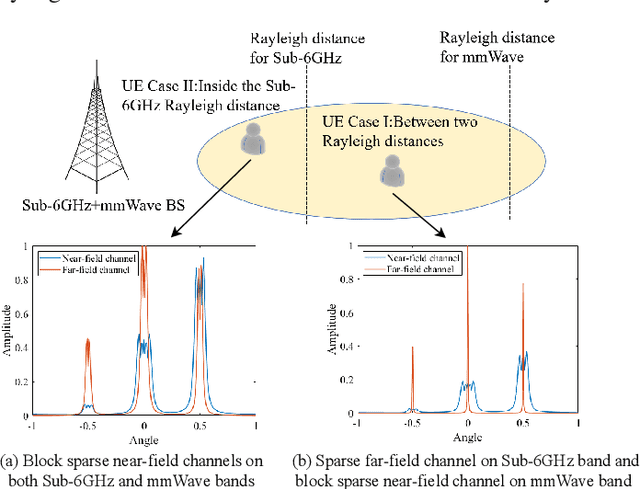
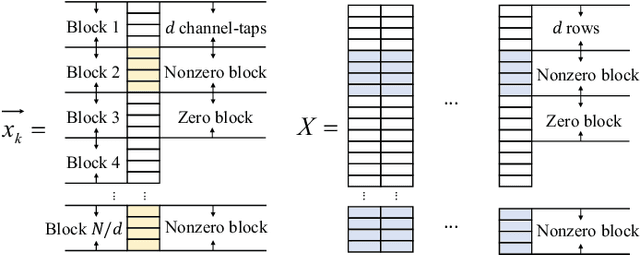
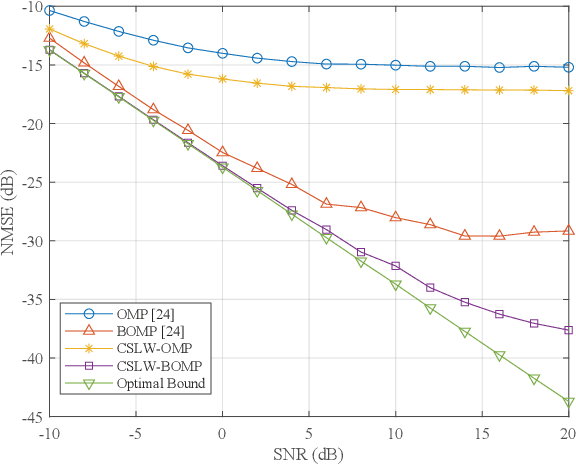
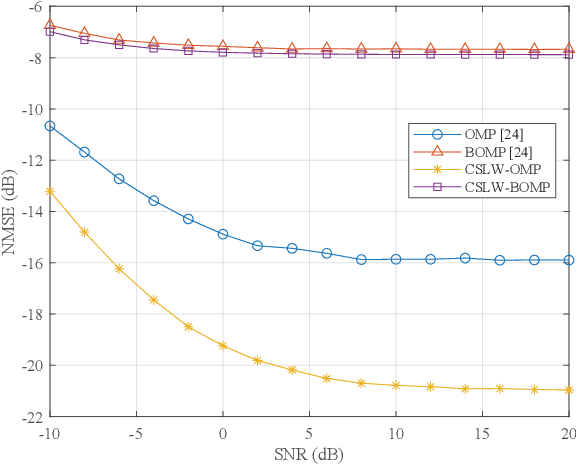
Near-field communication comes to be an indispensable part of the future sixth generation (6G) communications at the arrival of the forth-coming deployment of extremely large-scale multiple-input-multiple-output (XL-MIMO) systems. Due to the substantial number of antennas, the electromagnetic radiation field is modeled by the spherical waves instead of the conventional planar waves, leading to severe weak sparsity to angular-domain near-field channel. Therefore, the channel estimation reminiscent of the conventional compression sensing (CS) approaches in the angular domain, judiciously utilized for low pilot overhead, may result in unprecedented challenges. To this end, this paper proposes a brand-new near-field channel estimation scheme by exploiting the naturally occurring useful side information. Specifically, we formulate the dual-band near-field communication model based on the fact that high-frequency systems are likely to be deployed with lower-frequency systems. Representative side information, i.e., the structural characteristic information derived by the sparsity ambiguity and the out-of-band spatial information stemming from the lower-frequency channel, is explored and tailored to materialize exceptional near-field channel estimation. Furthermore, in-depth theoretical analyses are developed to guarantee the minimum estimation error, based on which a suite of algorithms leveraging the elaborating side information are proposed. Numerical simulations demonstrate that the designed algorithms provide more assured results than the off-the-shelf approaches in the context of the dual-band near-field communications in both on- and off-grid scenarios, where the angle of departures/arrivals are discretely or continuously distributed, respectively.
PRobELM: Plausibility Ranking Evaluation for Language Models
Apr 04, 2024This paper introduces PRobELM (Plausibility Ranking Evaluation for Language Models), a benchmark designed to assess language models' ability to discern more plausible from less plausible scenarios through their parametric knowledge. While benchmarks such as TruthfulQA emphasise factual accuracy or truthfulness, and others such as COPA explore plausible scenarios without explicitly incorporating world knowledge, PRobELM seeks to bridge this gap by evaluating models' capabilities to prioritise plausible scenarios that leverage world knowledge over less plausible alternatives. This design allows us to assess the potential of language models for downstream use cases such as literature-based discovery where the focus is on identifying information that is likely but not yet known. Our benchmark is constructed from a dataset curated from Wikidata edit histories, tailored to align the temporal bounds of the training data for the evaluated models. PRobELM facilitates the evaluation of language models across multiple prompting types, including statement, text completion, and question-answering. Experiments with 10 models of various sizes and architectures on the relationship between model scales, training recency, and plausibility performance, reveal that factual accuracy does not directly correlate with plausibility performance and that up-to-date training data enhances plausibility assessment across different model architectures.
Know Your Neighbors: Improving Single-View Reconstruction via Spatial Vision-Language Reasoning
Apr 04, 2024Recovering the 3D scene geometry from a single view is a fundamental yet ill-posed problem in computer vision. While classical depth estimation methods infer only a 2.5D scene representation limited to the image plane, recent approaches based on radiance fields reconstruct a full 3D representation. However, these methods still struggle with occluded regions since inferring geometry without visual observation requires (i) semantic knowledge of the surroundings, and (ii) reasoning about spatial context. We propose KYN, a novel method for single-view scene reconstruction that reasons about semantic and spatial context to predict each point's density. We introduce a vision-language modulation module to enrich point features with fine-grained semantic information. We aggregate point representations across the scene through a language-guided spatial attention mechanism to yield per-point density predictions aware of the 3D semantic context. We show that KYN improves 3D shape recovery compared to predicting density for each 3D point in isolation. We achieve state-of-the-art results in scene and object reconstruction on KITTI-360, and show improved zero-shot generalization compared to prior work. Project page: https://ruili3.github.io/kyn.
Decoupling Static and Hierarchical Motion Perception for Referring Video Segmentation
Apr 04, 2024Referring video segmentation relies on natural language expressions to identify and segment objects, often emphasizing motion clues. Previous works treat a sentence as a whole and directly perform identification at the video-level, mixing up static image-level cues with temporal motion cues. However, image-level features cannot well comprehend motion cues in sentences, and static cues are not crucial for temporal perception. In fact, static cues can sometimes interfere with temporal perception by overshadowing motion cues. In this work, we propose to decouple video-level referring expression understanding into static and motion perception, with a specific emphasis on enhancing temporal comprehension. Firstly, we introduce an expression-decoupling module to make static cues and motion cues perform their distinct role, alleviating the issue of sentence embeddings overlooking motion cues. Secondly, we propose a hierarchical motion perception module to capture temporal information effectively across varying timescales. Furthermore, we employ contrastive learning to distinguish the motions of visually similar objects. These contributions yield state-of-the-art performance across five datasets, including a remarkable $\textbf{9.2%}$ $\mathcal{J\&F}$ improvement on the challenging $\textbf{MeViS}$ dataset. Code is available at https://github.com/heshuting555/DsHmp.
DiffBody: Human Body Restoration by Imagining with Generative Diffusion Prior
Apr 04, 2024Human body restoration plays a vital role in various applications related to the human body. Despite recent advances in general image restoration using generative models, their performance in human body restoration remains mediocre, often resulting in foreground and background blending, over-smoothing surface textures, missing accessories, and distorted limbs. Addressing these challenges, we propose a novel approach by constructing a human body-aware diffusion model that leverages domain-specific knowledge to enhance performance. Specifically, we employ a pretrained body attention module to guide the diffusion model's focus on the foreground, addressing issues caused by blending between the subject and background. We also demonstrate the value of revisiting the language modality of the diffusion model in restoration tasks by seamlessly incorporating text prompt to improve the quality of surface texture and additional clothing and accessories details. Additionally, we introduce a diffusion sampler tailored for fine-grained human body parts, utilizing local semantic information to rectify limb distortions. Lastly, we collect a comprehensive dataset for benchmarking and advancing the field of human body restoration. Extensive experimental validation showcases the superiority of our approach, both quantitatively and qualitatively, over existing methods.
Design and Optimization of Cooperative Sensing With Limited Backhaul Capacity
Apr 04, 2024This paper introduces a cooperative sensing framework designed for integrated sensing and communication cellular networks. The framework comprises one base station (BS) functioning as the sensing transmitter, while several nearby BSs act as sensing receivers. The primary objective is to facilitate cooperative target localization by enabling each receiver to share specific information with a fusion center (FC) over a limited capacity backhaul link. To achieve this goal, we propose an advanced cooperative sensing design that enhances the communication process between the receivers and the FC. Each receiver independently estimates the time delay and the reflecting coefficient associated with the reflected path from the target. Subsequently, each receiver transmits the estimated values and the received signal samples centered around the estimated time delay to the FC. To efficiently quantize the signal samples, a Karhunen-Lo\`eve Transform coding scheme is employed. Furthermore, an optimization problem is formulated to allocate backhaul resources for quantizing different samples, improving target localization. Numerical results validate the effectiveness of our proposed advanced design and demonstrate its superiority over a baseline design, where only the locally estimated values are transmitted from each receiver to the FC.
M3TCM: Multi-modal Multi-task Context Model for Utterance Classification in Motivational Interviews
Apr 04, 2024Accurate utterance classification in motivational interviews is crucial to automatically understand the quality and dynamics of client-therapist interaction, and it can serve as a key input for systems mediating such interactions. Motivational interviews exhibit three important characteristics. First, there are two distinct roles, namely client and therapist. Second, they are often highly emotionally charged, which can be expressed both in text and in prosody. Finally, context is of central importance to classify any given utterance. Previous works did not adequately incorporate all of these characteristics into utterance classification approaches for mental health dialogues. In contrast, we present M3TCM, a Multi-modal, Multi-task Context Model for utterance classification. Our approach for the first time employs multi-task learning to effectively model both joint and individual components of therapist and client behaviour. Furthermore, M3TCM integrates information from the text and speech modality as well as the conversation context. With our novel approach, we outperform the state of the art for utterance classification on the recently introduced AnnoMI dataset with a relative improvement of 20% for the client- and by 15% for therapist utterance classification. In extensive ablation studies, we quantify the improvement resulting from each contribution.