 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Tensor Networks for Explainable Machine Learning in Cybersecurity
Dec 29, 2023
In this paper we show how tensor networks help in developing explainability of machine learning algorithms. Specifically, we develop an unsupervised clustering algorithm based on Matrix Product States (MPS) and apply it in the context of a real use-case of adversary-generated threat intelligence. Our investigation proves that MPS rival traditional deep learning models such as autoencoders and GANs in terms of performance, while providing much richer model interpretability. Our approach naturally facilitates the extraction of feature-wise probabilities, Von Neumann Entropy, and mutual information, offering a compelling narrative for classification of anomalies and fostering an unprecedented level of transparency and interpretability, something fundamental to understand the rationale behind artificial intelligence decisions.
Exploring Hyperspectral Anomaly Detection with Human Vision: A Small Target Aware Detector
Jan 02, 2024Hyperspectral anomaly detection (HAD) aims to localize pixel points whose spectral features differ from the background. HAD is essential in scenarios of unknown or camouflaged target features, such as water quality monitoring, crop growth monitoring and camouflaged target detection, where prior information of targets is difficult to obtain. Existing HAD methods aim to objectively detect and distinguish background and anomalous spectra, which can be achieved almost effortlessly by human perception. However, the underlying processes of human visual perception are thought to be quite complex. In this paper, we analyze hyperspectral image (HSI) features under human visual perception, and transfer the solution process of HAD to the more robust feature space for the first time. Specifically, we propose a small target aware detector (STAD), which introduces saliency maps to capture HSI features closer to human visual perception. STAD not only extracts more anomalous representations, but also reduces the impact of low-confidence regions through a proposed small target filter (STF). Furthermore, considering the possibility of HAD algorithms being applied to edge devices, we propose a full connected network to convolutional network knowledge distillation strategy. It can learn the spectral and spatial features of the HSI while lightening the network. We train the network on the HAD100 training set and validate the proposed method on the HAD100 test set. Our method provides a new solution space for HAD that is closer to human visual perception with high confidence. Sufficient experiments on real HSI with multiple method comparisons demonstrate the excellent performance and unique potential of the proposed method. The code is available at https://github.com/majitao-xd/STAD-HAD.
User authentication system based on human exhaled breath physics
Jan 02, 2024This work, in a pioneering approach, attempts to build a biometric system that works purely based on the fluid mechanics governing exhaled breath. We test the hypothesis that the structure of turbulence in exhaled human breath can be exploited to build biometric algorithms. This work relies on the idea that the extrathoracic airway is unique for every individual, making the exhaled breath a biomarker. Methods including classical multi-dimensional hypothesis testing approach and machine learning models are employed in building user authentication algorithms, namely user confirmation and user identification. A user confirmation algorithm tries to verify whether a user is the person they claim to be. A user identification algorithm tries to identify a user's identity with no prior information available. A dataset of exhaled breath time series samples from 94 human subjects was used to evaluate the performance of these algorithms. The user confirmation algorithms performed exceedingly well for the given dataset with over $97\%$ true confirmation rate. The machine learning based algorithm achieved a good true confirmation rate, reiterating our understanding of why machine learning based algorithms typically outperform classical hypothesis test based algorithms. The user identification algorithm performs reasonably well with the provided dataset with over $50\%$ of the users identified as being within two possible suspects. We show surprisingly unique turbulent signatures in the exhaled breath that have not been discovered before. In addition to discussions on a novel biometric system, we make arguments to utilise this idea as a tool to gain insights into the morphometric variation of extrathoracic airway across individuals. Such tools are expected to have future potential in the area of personalised medicines.
ScatterFormer: Efficient Voxel Transformer with Scattered Linear Attention
Jan 01, 2024Window-based transformers have demonstrated strong ability in large-scale point cloud understanding by capturing context-aware representations with affordable attention computation in a more localized manner. However, because of the sparse nature of point clouds, the number of voxels per window varies significantly. Current methods partition the voxels in each window into multiple subsets of equal size, which cost expensive overhead in sorting and padding the voxels, making them run slower than sparse convolution based methods. In this paper, we present ScatterFormer, which, for the first time to our best knowledge, could directly perform attention on voxel sets with variable length. The key of ScatterFormer lies in the innovative Scatter Linear Attention (SLA) module, which leverages the linear attention mechanism to process in parallel all voxels scattered in different windows. Harnessing the hierarchical computation units of the GPU and matrix blocking algorithm, we reduce the latency of the proposed SLA module to less than 1 ms on moderate GPUs. Besides, we develop a cross-window interaction module to simultaneously enhance the local representation and allow the information flow across windows, eliminating the need for window shifting. Our proposed ScatterFormer demonstrates 73 mAP (L2) on the large-scale Waymo Open Dataset and 70.5 NDS on the NuScenes dataset, running at an outstanding detection rate of 28 FPS. Code is available at https://github.com/skyhehe123/ScatterFormer
Text Representation Distillation via Information Bottleneck Principle
Nov 09, 2023Pre-trained language models (PLMs) have recently shown great success in text representation field. However, the high computational cost and high-dimensional representation of PLMs pose significant challenges for practical applications. To make models more accessible, an effective method is to distill large models into smaller representation models. In order to relieve the issue of performance degradation after distillation, we propose a novel Knowledge Distillation method called IBKD. This approach is motivated by the Information Bottleneck principle and aims to maximize the mutual information between the final representation of the teacher and student model, while simultaneously reducing the mutual information between the student model's representation and the input data. This enables the student model to preserve important learned information while avoiding unnecessary information, thus reducing the risk of over-fitting. Empirical studies on two main downstream applications of text representation (Semantic Textual Similarity and Dense Retrieval tasks) demonstrate the effectiveness of our proposed approach.
DXAI: Explaining Classification by Image Decomposition
Dec 30, 2023We propose a new way to explain and to visualize neural network classification through a decomposition-based explainable AI (DXAI). Instead of providing an explanation heatmap, our method yields a decomposition of the image into class-agnostic and class-distinct parts, with respect to the data and chosen classifier. Following a fundamental signal processing paradigm of analysis and synthesis, the original image is the sum of the decomposed parts. We thus obtain a radically different way of explaining classification. The class-agnostic part ideally is composed of all image features which do not posses class information, where the class-distinct part is its complementary. This new visualization can be more helpful and informative in certain scenarios, especially when the attributes are dense, global and additive in nature, for instance, when colors or textures are essential for class distinction. Code is available at https://github.com/dxai2024/dxai.
Efficient Two-Phase Offline Deep Reinforcement Learning from Preference Feedback
Dec 30, 2023In this work, we consider the offline preference-based reinforcement learning problem. We focus on the two-phase learning approach that is prevalent in previous reinforcement learning from human preference works. We find a challenge in applying two-phase learning in the offline PBRL setting that the learned utility model can be too hard for the learning agent to optimize during the second learning phase. To overcome the challenge, we propose a two-phasing learning approach under behavior regularization through action clipping. The insight is that the state-actions which are poorly covered by the dataset can only provide limited information and increase the complexity of the problem in the second learning phase. Our method ignores such state-actions during the second learning phase to achieve higher learning efficiency. We empirically verify that our method has high learning efficiency on a variety of datasets in robotic control environments.
AerialBooth: Mutual Information Guidance for Text Controlled Aerial View Synthesis from a Single Image
Nov 27, 2023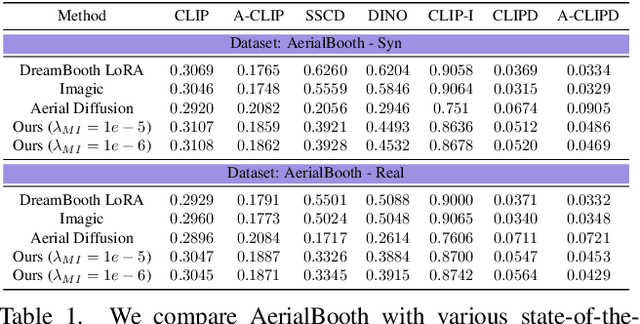
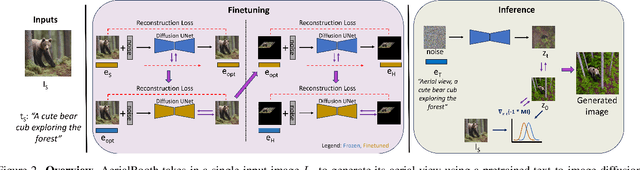
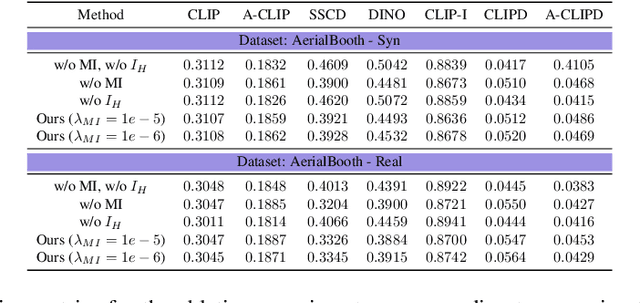

We present a novel method, AerialBooth, for synthesizing the aerial view from a single input image using its text description. We leverage the pretrained text-to-2D image stable diffusion model as prior knowledge of the 3D world. The model is finetuned in two steps to optimize for the text embedding and the UNet that reconstruct the input image and its inverse perspective mapping respectively. The inverse perspective mapping creates variance within the text-image space of the diffusion model, while providing weak guidance for aerial view synthesis. At inference, we steer the contents of the generated image towards the input image using novel mutual information guidance that maximizes the information content between the probability distributions of the two images. We evaluate our approach on a wide spectrum of real and synthetic data, including natural scenes, indoor scenes, human action, etc. Through extensive experiments and ablation studies, we demonstrate the effectiveness of AerialBooth and also its generalizability to other text-controlled views. We also show that AerialBooth achieves the best viewpoint-fidelity trade-off though quantitative evaluation on 7 metrics analyzing viewpoint and fidelity w.r.t. input image. Code and data is available at https://github.com/divyakraman/AerialBooth2023.
DuaLight: Enhancing Traffic Signal Control by Leveraging Scenario-Specific and Scenario-Shared Knowledge
Dec 22, 2023Reinforcement learning has been revolutionizing the traditional traffic signal control task, showing promising power to relieve congestion and improve efficiency. However, the existing methods lack effective learning mechanisms capable of absorbing dynamic information inherent to a specific scenario and universally applicable dynamic information across various scenarios. Moreover, within each specific scenario, they fail to fully capture the essential empirical experiences about how to coordinate between neighboring and target intersections, leading to sub-optimal system-wide outcomes. Viewing these issues, we propose DuaLight, which aims to leverage both the experiential information within a single scenario and the generalizable information across various scenarios for enhanced decision-making. Specifically, DuaLight introduces a scenario-specific experiential weight module with two learnable parts: Intersection-wise and Feature-wise, guiding how to adaptively utilize neighbors and input features for each scenario, thus providing a more fine-grained understanding of different intersections. Furthermore, we implement a scenario-shared Co-Train module to facilitate the learning of generalizable dynamics information across different scenarios. Empirical results on both real-world and synthetic scenarios show DuaLight achieves competitive performance across various metrics, offering a promising solution to alleviate traffic congestion, with 3-7\% improvements. The code is available under: https://github.com/lujiaming-12138/DuaLight.
Modeling Systemic Risk: A Time-Varying Nonparametric Causal Inference Framework
Dec 27, 2023We propose a nonparametric and time-varying directed information graph (TV-DIG) framework to estimate the evolving causal structure in time series networks, thereby addressing the limitations of traditional econometric models in capturing high-dimensional, nonlinear, and time-varying interconnections among series. This framework employs an information-theoretic measure rooted in a generalized version of Granger-causality, which is applicable to both linear and nonlinear dynamics. Our framework offers advancements in measuring systemic risk and establishes meaningful connections with established econometric models, including vector autoregression and switching models. We evaluate the efficacy of our proposed model through simulation experiments and empirical analysis, reporting promising results in recovering simulated time-varying networks with nonlinear and multivariate structures. We apply this framework to identify and monitor the evolution of interconnectedness and systemic risk among major assets and industrial sectors within the financial network. We focus on cryptocurrencies' potential systemic risks to financial stability, including spillover effects on other sectors during crises like the COVID-19 pandemic and the Federal Reserve's 2020 emergency response. Our findings reveals significant, previously underrecognized pre-2020 influences of cryptocurrencies on certain financial sectors, highlighting their potential systemic risks and offering a systematic approach in tracking evolving cross-sector interactions within financial networks.