 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
VADIS -- a VAriable Detection, Interlinking and Summarization system
Dec 20, 2023
The VADIS system addresses the demand of providing enhanced information access in the domain of the social sciences. This is achieved by allowing users to search and use survey variables in context of their underlying research data and scholarly publications which have been interlinked with each other.
Disentangled Representation Learning with Transmitted Information Bottleneck
Nov 03, 2023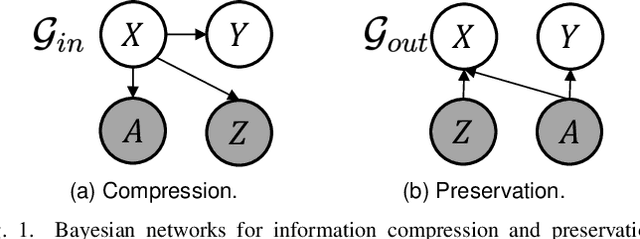
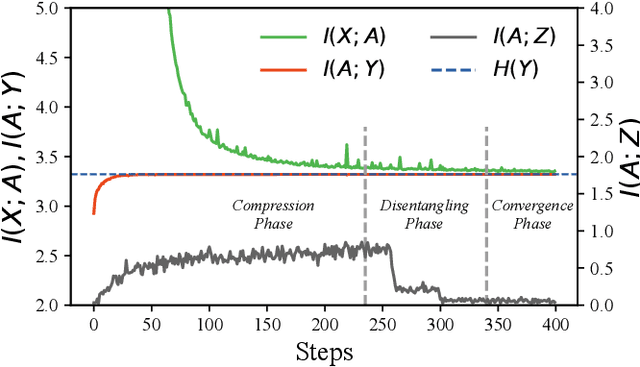

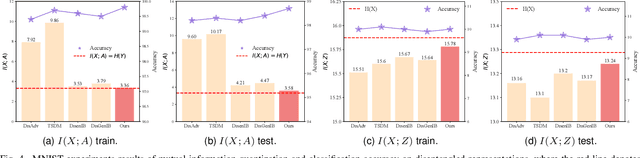
Encoding only the task-related information from the raw data, \ie, disentangled representation learning, can greatly contribute to the robustness and generalizability of models. Although significant advances have been made by regularizing the information in representations with information theory, two major challenges remain: 1) the representation compression inevitably leads to performance drop; 2) the disentanglement constraints on representations are in complicated optimization. To these issues, we introduce Bayesian networks with transmitted information to formulate the interaction among input and representations during disentanglement. Building upon this framework, we propose \textbf{DisTIB} (\textbf{T}ransmitted \textbf{I}nformation \textbf{B}ottleneck for \textbf{Dis}entangled representation learning), a novel objective that navigates the balance between information compression and preservation. We employ variational inference to derive a tractable estimation for DisTIB. This estimation can be simply optimized via standard gradient descent with a reparameterization trick. Moreover, we theoretically prove that DisTIB can achieve optimal disentanglement, underscoring its superior efficacy. To solidify our claims, we conduct extensive experiments on various downstream tasks to demonstrate the appealing efficacy of DisTIB and validate our theoretical analyses.
Agent Attention: On the Integration of Softmax and Linear Attention
Dec 22, 2023The attention module is the key component in Transformers. While the global attention mechanism offers high expressiveness, its excessive computational cost restricts its applicability in various scenarios. In this paper, we propose a novel attention paradigm, Agent Attention, to strike a favorable balance between computational efficiency and representation power. Specifically, the Agent Attention, denoted as a quadruple $(Q, A, K, V)$, introduces an additional set of agent tokens $A$ into the conventional attention module. The agent tokens first act as the agent for the query tokens $Q$ to aggregate information from $K$ and $V$, and then broadcast the information back to $Q$. Given the number of agent tokens can be designed to be much smaller than the number of query tokens, the agent attention is significantly more efficient than the widely adopted Softmax attention, while preserving global context modelling capability. Interestingly, we show that the proposed agent attention is equivalent to a generalized form of linear attention. Therefore, agent attention seamlessly integrates the powerful Softmax attention and the highly efficient linear attention. Extensive experiments demonstrate the effectiveness of agent attention with various vision Transformers and across diverse vision tasks, including image classification, object detection, semantic segmentation and image generation. Notably, agent attention has shown remarkable performance in high-resolution scenarios, owning to its linear attention nature. For instance, when applied to Stable Diffusion, our agent attention accelerates generation and substantially enhances image generation quality without any additional training. Code is available at https://github.com/LeapLabTHU/Agent-Attention.
Adversarial Data Poisoning for Fake News Detection: How to Make a Model Misclassify a Target News without Modifying It
Dec 23, 2023Fake news detection models are critical to countering disinformation but can be manipulated through adversarial attacks. In this position paper, we analyze how an attacker can compromise the performance of an online learning detector on specific news content without being able to manipulate the original target news. In some contexts, such as social networks, where the attacker cannot exert complete control over all the information, this scenario can indeed be quite plausible. Therefore, we show how an attacker could potentially introduce poisoning data into the training data to manipulate the behavior of an online learning method. Our initial findings reveal varying susceptibility of logistic regression models based on complexity and attack type.
RoleEval: A Bilingual Role Evaluation Benchmark for Large Language Models
Dec 26, 2023The rapid evolution of large language models (LLMs) necessitates effective benchmarks for evaluating their role knowledge, which is essential for establishing connections with the real world and providing more immersive interactions. This paper introduces RoleEval, a bilingual benchmark designed to assess the memorization, utilization, and reasoning capabilities of role knowledge. RoleEval comprises RoleEval-Global (including internationally recognized characters) and RoleEval-Chinese (including characters popular in China), with 6,000 Chinese-English parallel multiple-choice questions focusing on 300 influential people and fictional characters drawn from a variety of domains including celebrities, anime, comics, movies, TV series, games, and fiction. These questions cover basic knowledge and multi-hop reasoning abilities, aiming to systematically probe various aspects such as personal information, relationships, abilities, and experiences of the characters. To maintain high standards, we perform a hybrid quality check process combining automatic and human verification, ensuring that the questions are diverse, challenging, and discriminative. Our extensive evaluations of RoleEval across various open-source and proprietary large language models, under both the zero- and few-shot settings, reveal insightful findings. Notably, while GPT-4 outperforms other models on RoleEval-Global, Chinese LLMs excel on RoleEval-Chinese, highlighting significant knowledge distribution differences. We expect that RoleEval will highlight the significance of assessing role knowledge for foundation models across various languages and cultural settings.
Review on Causality Detection Based on Empirical Dynamic Modeling
Dec 26, 2023In contemporary scientific research, understanding the distinction between correlation and causation is crucial. While correlation is a widely used analytical standard, it does not inherently imply causation. This paper addresses the potential for misinterpretation in relying solely on correlation, especially in the context of nonlinear dynamics. Despite the rapid development of various correlation research methodologies, including machine learning, the exploration into mining causal correlations between variables remains ongoing. Empirical Dynamic Modeling (EDM) emerges as a data-driven framework for modeling dynamic systems, distinguishing itself by eschewing traditional formulaic methods in data analysis. Instead, it reconstructs dynamic system behavior directly from time series data. The fundamental premise of EDM is that dynamic systems can be conceptualized as processes where a set of states, governed by specific rules, evolve over time in a high-dimensional space. By reconstructing these evolving states, dynamic systems can be effectively modeled. Using EDM, this paper explores the detection of causal relationships between variables within dynamic systems through their time series data. It posits that if variable X causes variable Y, then the information about X is inherent in Y and can be extracted from Y's data. This study begins by examining the dialectical relationship between correlation and causation, emphasizing that correlation does not equate to causation, and the absence of correlation does not necessarily indicate a lack of causation.
Towards Probing Contact Center Large Language Models
Dec 26, 2023Fine-tuning large language models (LLMs) with domain-specific instructions has emerged as an effective method to enhance their domain-specific understanding. Yet, there is limited work that examines the core characteristics acquired during this process. In this study, we benchmark the fundamental characteristics learned by contact-center (CC) specific instruction fine-tuned LLMs with out-of-the-box (OOB) LLMs via probing tasks encompassing conversational, channel, and automatic speech recognition (ASR) properties. We explore different LLM architectures (Flan-T5 and Llama), sizes (3B, 7B, 11B, 13B), and fine-tuning paradigms (full fine-tuning vs PEFT). Our findings reveal remarkable effectiveness of CC-LLMs on the in-domain downstream tasks, with improvement in response acceptability by over 48% compared to OOB-LLMs. Additionally, we compare the performance of OOB-LLMs and CC-LLMs on the widely used SentEval dataset, and assess their capabilities in terms of surface, syntactic, and semantic information through probing tasks. Intriguingly, we note a relatively consistent performance of probing classifiers on the set of probing tasks. Our observations indicate that CC-LLMs, while outperforming their out-of-the-box counterparts, exhibit a tendency to rely less on encoding surface, syntactic, and semantic properties, highlighting the intricate interplay between domain-specific adaptation and probing task performance opening up opportunities to explore behavior of fine-tuned language models in specialized contexts.
An Incremental Update Framework for Online Recommenders with Data-Driven Prior
Dec 26, 2023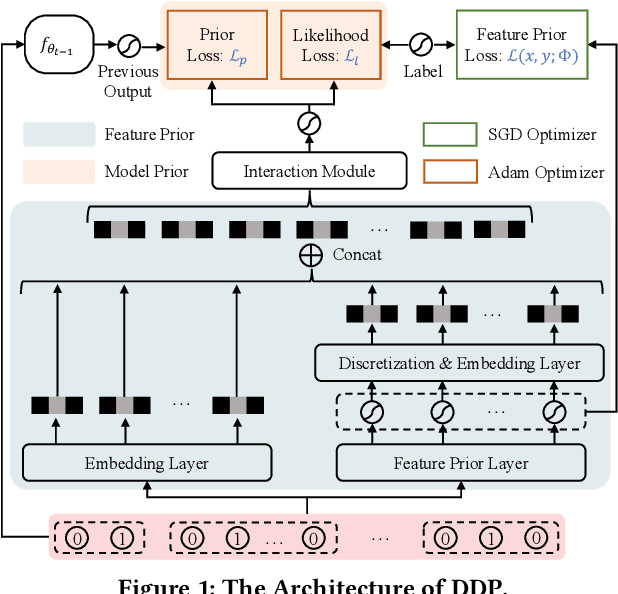
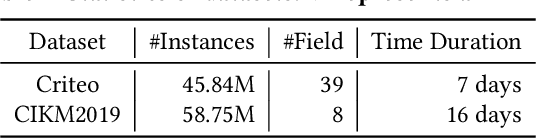
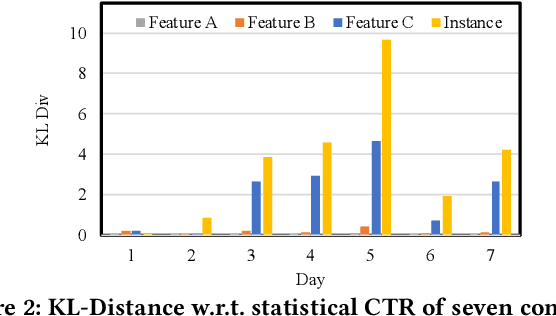
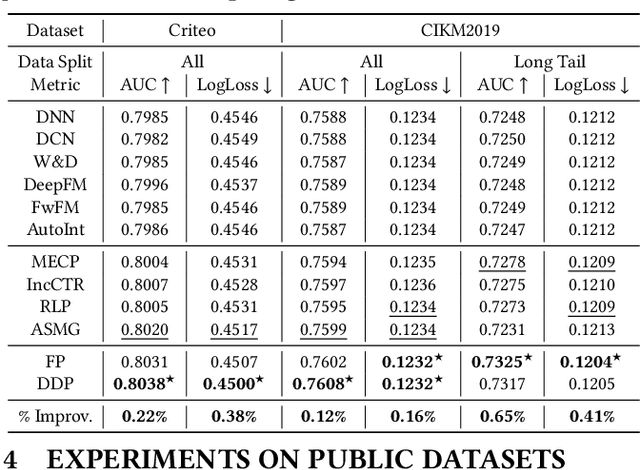
Online recommenders have attained growing interest and created great revenue for businesses. Given numerous users and items, incremental update becomes a mainstream paradigm for learning large-scale models in industrial scenarios, where only newly arrived data within a sliding window is fed into the model, meeting the strict requirements of quick response. However, this strategy would be prone to overfitting to newly arrived data. When there exists a significant drift of data distribution, the long-term information would be discarded, which harms the recommendation performance. Conventional methods address this issue through native model-based continual learning methods, without analyzing the data characteristics for online recommenders. To address the aforementioned issue, we propose an incremental update framework for online recommenders with Data-Driven Prior (DDP), which is composed of Feature Prior (FP) and Model Prior (MP). The FP performs the click estimation for each specific value to enhance the stability of the training process. The MP incorporates previous model output into the current update while strictly following the Bayes rules, resulting in a theoretically provable prior for the robust update. In this way, both the FP and MP are well integrated into the unified framework, which is model-agnostic and can accommodate various advanced interaction models. Extensive experiments on two publicly available datasets as well as an industrial dataset demonstrate the superior performance of the proposed framework.
ANN vs SNN: A case study for Neural Decoding in Implantable Brain-Machine Interfaces
Dec 26, 2023While it is important to make implantable brain-machine interfaces (iBMI) wireless to increase patient comfort and safety, the trend of increased channel count in recent neural probes poses a challenge due to the concomitant increase in the data rate. Extracting information from raw data at the source by using edge computing is a promising solution to this problem, with integrated intention decoders providing the best compression ratio. In this work, we compare different neural networks (NN) for motor decoding in terms of accuracy and implementation cost. We further show that combining traditional signal processing techniques with machine learning ones deliver surprisingly good performance even with simple NNs. Adding a block Bidirectional Bessel filter provided maximum gains of $\approx 0.05$, $0.04$ and $0.03$ in $R^2$ for ANN\_3d, SNN\_3D and ANN models, while the gains were lower ($\approx 0.02$ or less) for LSTM and SNN\_streaming models. Increasing training data helped improve the $R^2$ of all models by $0.03-0.04$ indicating they have more capacity for future improvement. In general, LSTM and SNN\_streaming models occupy the high and low ends of the pareto curves (for accuracy vs. memory/operations) respectively while SNN\_3D and ANN\_3D occupy intermediate positions. Our work presents state of the art results for this dataset and paves the way for decoder-integrated-implants of the future.
Inverse Transfer Multiobjective Optimization
Dec 26, 2023Transfer optimization enables data-efficient optimization of a target task by leveraging experiential priors from related source tasks. This is especially useful in multiobjective optimization settings where a set of trade-off solutions is sought under tight evaluation budgets. In this paper, we introduce a novel concept of inverse transfer in multiobjective optimization. Inverse transfer stands out by employing probabilistic inverse models to map performance vectors in the objective space to population search distributions in task-specific decision space, facilitating knowledge transfer through objective space unification. Building upon this idea, we introduce the first Inverse Transfer Multiobjective Evolutionary Optimizer (invTrEMO). A key highlight of invTrEMO is its ability to harness the common objective functions prevalent in many application areas, even when decision spaces do not precisely align between tasks. This allows invTrEMO to uniquely and effectively utilize information from heterogeneous source tasks as well. Furthermore, invTrEMO yields high-precision inverse models as a significant byproduct, enabling the generation of tailored solutions on-demand based on user preferences. Empirical studies on multi- and many-objective benchmark problems, as well as a practical case study, showcase the faster convergence rate and modelling accuracy of the invTrEMO relative to state-of-the-art evolutionary and Bayesian optimization algorithms. The source code of the invTrEMO is made available at https://github.com/LiuJ-2023/invTrEMO.