 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Self-Supervised Disentangled Representation Learning for Robust Target Speech Extraction
Dec 16, 2023
Speech signals are inherently complex as they encompass both global acoustic characteristics and local semantic information. However, in the task of target speech extraction, certain elements of global and local semantic information in the reference speech, which are irrelevant to speaker identity, can lead to speaker confusion within the speech extraction network. To overcome this challenge, we propose a self-supervised disentangled representation learning method. Our approach tackles this issue through a two-phase process, utilizing a reference speech encoding network and a global information disentanglement network to gradually disentangle the speaker identity information from other irrelevant factors. We exclusively employ the disentangled speaker identity information to guide the speech extraction network. Moreover, we introduce the adaptive modulation Transformer to ensure that the acoustic representation of the mixed signal remains undisturbed by the speaker embeddings. This component incorporates speaker embeddings as conditional information, facilitating natural and efficient guidance for the speech extraction network. Experimental results substantiate the effectiveness of our meticulously crafted approach, showcasing a substantial reduction in the likelihood of speaker confusion.
EIGEN: Expert-Informed Joint Learning Aggregation for High-Fidelity Information Extraction from Document Images
Nov 23, 2023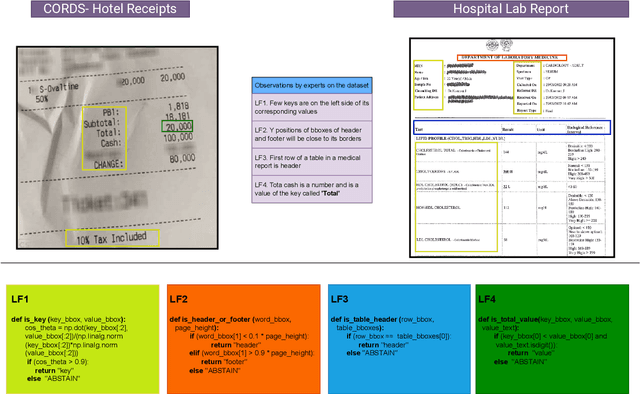
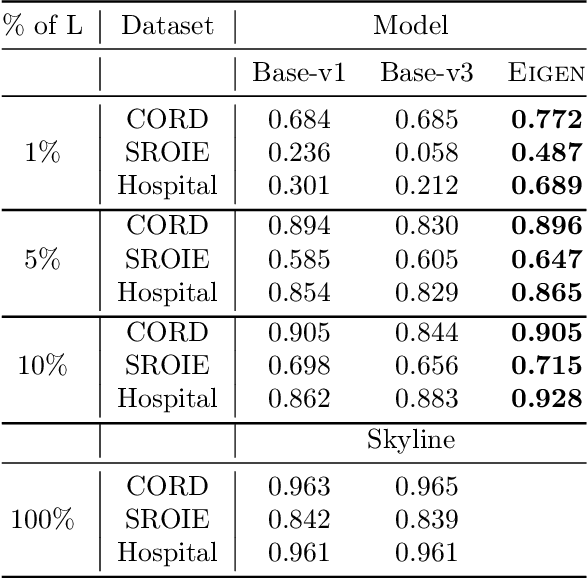
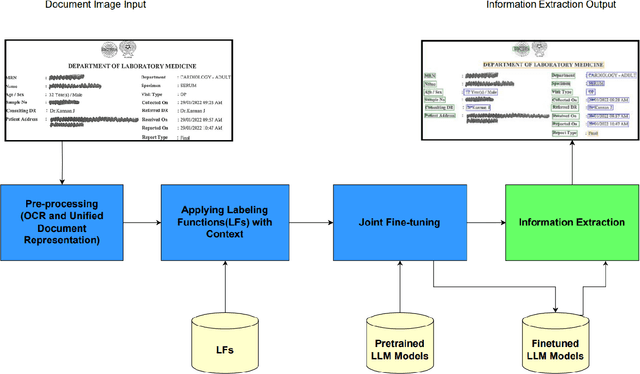
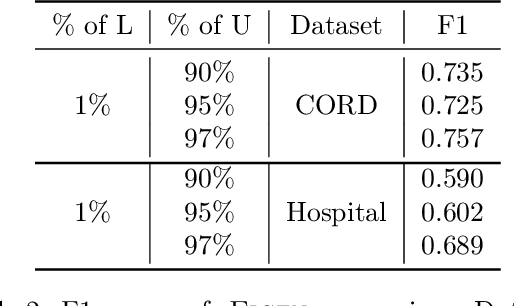
Information Extraction (IE) from document images is challenging due to the high variability of layout formats. Deep models such as LayoutLM and BROS have been proposed to address this problem and have shown promising results. However, they still require a large amount of field-level annotations for training these models. Other approaches using rule-based methods have also been proposed based on the understanding of the layout and semantics of a form such as geometric position, or type of the fields, etc. In this work, we propose a novel approach, EIGEN (Expert-Informed Joint Learning aGgrEatioN), which combines rule-based methods with deep learning models using data programming approaches to circumvent the requirement of annotation of large amounts of training data. Specifically, EIGEN consolidates weak labels induced from multiple heuristics through generative models and use them along with a small number of annotated labels to jointly train a deep model. In our framework, we propose the use of labeling functions that include incorporating contextual information thus capturing the visual and language context of a word for accurate categorization. We empirically show that our EIGEN framework can significantly improve the performance of state-of-the-art deep models with the availability of very few labeled data instances. The source code is available at https://github.com/ayushayush591/EIGEN-High-Fidelity-Extraction-Document-Images.
Channel Estimation for mmWave MIMO using sub-6 GHz Out-of-Band Information
Nov 16, 2023Future wireless multiple-input multiple-output (MIMO) communication systems will employ sub-6 GHz and millimeter wave (mmWave) frequency bands working cooperatively. Establishing a MIMO communication link usually relies on estimating channel state information (CSI) which is difficult to acquire at mmWave frequencies due to a low signal-to-noise ratio (SNR). In this paper, we propose three novel methods to estimate mmWave MIMO channels using out-of-band information obtained from the sub-6GHz band. We compare the proposed channel estimation methods with a conventional one utilizing only in-band information. Simulation results show that the proposed methods outperform the conventional mmWave channel estimation method in terms of achievable spectral efficiency, especially at low SNR and high K-factor.
LLM4VG: Large Language Models Evaluation for Video Grounding
Dec 28, 2023Recently, researchers have attempted to investigate the capability of LLMs in handling videos and proposed several video LLM models. However, the ability of LLMs to handle video grounding (VG), which is an important time-related video task requiring the model to precisely locate the start and end timestamps of temporal moments in videos that match the given textual queries, still remains unclear and unexplored in literature. To fill the gap, in this paper, we propose the LLM4VG benchmark, which systematically evaluates the performance of different LLMs on video grounding tasks. Based on our proposed LLM4VG, we design extensive experiments to examine two groups of video LLM models on video grounding: (i) the video LLMs trained on the text-video pairs (denoted as VidLLM), and (ii) the LLMs combined with pretrained visual description models such as the video/image captioning model. We propose prompt methods to integrate the instruction of VG and description from different kinds of generators, including caption-based generators for direct visual description and VQA-based generators for information enhancement. We also provide comprehensive comparisons of various VidLLMs and explore the influence of different choices of visual models, LLMs, prompt designs, etc, as well. Our experimental evaluations lead to two conclusions: (i) the existing VidLLMs are still far away from achieving satisfactory video grounding performance, and more time-related video tasks should be included to further fine-tune these models, and (ii) the combination of LLMs and visual models shows preliminary abilities for video grounding with considerable potential for improvement by resorting to more reliable models and further guidance of prompt instructions.
A Non-Uniform Low-Light Image Enhancement Method with Multi-Scale Attention Transformer and Luminance Consistency Loss
Dec 27, 2023Low-light image enhancement aims to improve the perception of images collected in dim environments and provide high-quality data support for image recognition tasks. When dealing with photos captured under non-uniform illumination, existing methods cannot adaptively extract the differentiated luminance information, which will easily cause over-exposure and under-exposure. From the perspective of unsupervised learning, we propose a multi-scale attention Transformer named MSATr, which sufficiently extracts local and global features for light balance to improve the visual quality. Specifically, we present a multi-scale window division scheme, which uses exponential sequences to adjust the window size of each layer. Within different-sized windows, the self-attention computation can be refined, ensuring the pixel-level feature processing capability of the model. For feature interaction across windows, a global transformer branch is constructed to provide comprehensive brightness perception and alleviate exposure problems. Furthermore, we propose a loop training strategy, using the diverse images generated by weighted mixing and a luminance consistency loss to improve the model's generalization ability effectively. Extensive experiments on several benchmark datasets quantitatively and qualitatively prove that our MSATr is superior to state-of-the-art low-light image enhancement methods, and the enhanced images have more natural brightness and outstanding details. The code is released at https://github.com/fang001021/MSATr.
Selective-Memory Meta-Learning with Environment Representations for Sound Event Localization and Detection
Dec 27, 2023Environment shifts and conflicts present significant challenges for learning-based sound event localization and detection (SELD) methods. SELD systems, when trained in particular acoustic settings, often show restricted generalization capabilities for diverse acoustic environments. Furthermore, it is notably costly to obtain annotated samples for spatial sound events. Deploying a SELD system in a new environment requires extensive time for re-training and fine-tuning. To overcome these challenges, we propose environment-adaptive Meta-SELD, designed for efficient adaptation to new environments using minimal data. Our method specifically utilizes computationally synthesized spatial data and employs Model-Agnostic Meta-Learning (MAML) on a pre-trained, environment-independent model. The method then utilizes fast adaptation to unseen real-world environments using limited samples from the respective environments. Inspired by the Learning-to-Forget approach, we introduce the concept of selective memory as a strategy for resolving conflicts across environments. This approach involves selectively memorizing target-environment-relevant information and adapting to the new environments through the selective attenuation of model parameters. In addition, we introduce environment representations to characterize different acoustic settings, enhancing the adaptability of our attenuation approach to various environments. We evaluate our proposed method on the development set of the Sony-TAU Realistic Spatial Soundscapes 2023 (STARSS23) dataset and computationally synthesized scenes. Experimental results demonstrate the superior performance of the proposed method compared to conventional supervised learning methods, particularly in localization.
Dynamic Sub-graph Distillation for Robust Semi-supervised Continual Learning
Dec 27, 2023Continual learning (CL) has shown promising results and comparable performance to learning at once in a fully supervised manner. However, CL strategies typically require a large number of labeled samples, making their real-life deployment challenging. In this work, we focus on semi-supervised continual learning (SSCL), where the model progressively learns from partially labeled data with unknown categories. We provide a comprehensive analysis of SSCL and demonstrate that unreliable distributions of unlabeled data lead to unstable training and refinement of the progressing stages. This problem severely impacts the performance of SSCL. To address the limitations, we propose a novel approach called Dynamic Sub-Graph Distillation (DSGD) for semi-supervised continual learning, which leverages both semantic and structural information to achieve more stable knowledge distillation on unlabeled data and exhibit robustness against distribution bias. Firstly, we formalize a general model of structural distillation and design a dynamic graph construction for the continual learning progress. Next, we define a structure distillation vector and design a dynamic sub-graph distillation algorithm, which enables end-to-end training and adaptability to scale up tasks. The entire proposed method is adaptable to various CL methods and supervision settings. Finally, experiments conducted on three datasets CIFAR10, CIFAR100, and ImageNet-100, with varying supervision ratios, demonstrate the effectiveness of our proposed approach in mitigating the catastrophic forgetting problem in semi-supervised continual learning scenarios.
Joint Sensing and Task-Oriented Communications with Image and Wireless Data Modalities for Dynamic Spectrum Access
Dec 21, 2023This paper introduces a deep learning approach to dynamic spectrum access, leveraging the synergy of multi-modal image and spectrum data for the identification of potential transmitters. We consider an edge device equipped with a camera that is taking images of potential objects such as vehicles that may harbor transmitters. Recognizing the computational constraints and trust issues associated with on-device computation, we propose a collaborative system wherein the edge device communicates selectively processed information to a trusted receiver acting as a fusion center, where a decision is made to identify whether a potential transmitter is present, or not. To achieve this, we employ task-oriented communications, utilizing an encoder at the transmitter for joint source coding, channel coding, and modulation. This architecture efficiently transmits essential information of reduced dimension for object classification. Simultaneously, the transmitted signals may reflect off objects and return to the transmitter, allowing for the collection of target sensing data. Then the collected sensing data undergoes a second round of encoding at the transmitter, with the reduced-dimensional information communicated back to the fusion center through task-oriented communications. On the receiver side, a decoder performs the task of identifying a transmitter by fusing data received through joint sensing and task-oriented communications. The two encoders at the transmitter and the decoder at the receiver are jointly trained, enabling a seamless integration of image classification and wireless signal detection. Using AWGN and Rayleigh channel models, we demonstrate the effectiveness of the proposed approach, showcasing high accuracy in transmitter identification across diverse channel conditions while sustaining low latency in decision making.
Deep Structure and Attention Aware Subspace Clustering
Dec 25, 2023Clustering is a fundamental unsupervised representation learning task with wide application in computer vision and pattern recognition. Deep clustering utilizes deep neural networks to learn latent representation, which is suitable for clustering. However, previous deep clustering methods, especially image clustering, focus on the features of the data itself and ignore the relationship between the data, which is crucial for clustering. In this paper, we propose a novel Deep Structure and Attention aware Subspace Clustering (DSASC), which simultaneously considers data content and structure information. We use a vision transformer to extract features, and the extracted features are divided into two parts, structure features, and content features. The two features are used to learn a more efficient subspace structure for spectral clustering. Extensive experimental results demonstrate that our method significantly outperforms state-of-the-art methods. Our code will be available at https://github.com/cs-whh/DSASC
Cross-Modal Reasoning with Event Correlation for Video Question Answering
Dec 20, 2023Video Question Answering (VideoQA) is a very attractive and challenging research direction aiming to understand complex semantics of heterogeneous data from two domains, i.e., the spatio-temporal video content and the word sequence in question. Although various attention mechanisms have been utilized to manage contextualized representations by modeling intra- and inter-modal relationships of the two modalities, one limitation of the predominant VideoQA methods is the lack of reasoning with event correlation, that is, sensing and analyzing relationships among abundant and informative events contained in the video. In this paper, we introduce the dense caption modality as a new auxiliary and distill event-correlated information from it to infer the correct answer. To this end, we propose a novel end-to-end trainable model, Event-Correlated Graph Neural Networks (EC-GNNs), to perform cross-modal reasoning over information from the three modalities (i.e., caption, video, and question). Besides the exploitation of a brand new modality, we employ cross-modal reasoning modules for explicitly modeling inter-modal relationships and aggregating relevant information across different modalities, and we propose a question-guided self-adaptive multi-modal fusion module to collect the question-oriented and event-correlated evidence through multi-step reasoning. We evaluate our model on two widely-used benchmark datasets and conduct an ablation study to justify the effectiveness of each proposed component.