 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Image Captioning in news report scenario
Apr 02, 2024
Image captioning strives to generate pertinent captions for specified images, situating itself at the crossroads of Computer Vision (CV) and Natural Language Processing (NLP). This endeavor is of paramount importance with far-reaching applications in recommendation systems, news outlets, social media, and beyond. Particularly within the realm of news reporting, captions are expected to encompass detailed information, such as the identities of celebrities captured in the images. However, much of the existing body of work primarily centers around understanding scenes and actions. In this paper, we explore the realm of image captioning specifically tailored for celebrity photographs, illustrating its broad potential for enhancing news industry practices. This exploration aims to augment automated news content generation, thereby facilitating a more nuanced dissemination of information. Our endeavor shows a broader horizon, enriching the narrative in news reporting through a more intuitive image captioning framework.
Near-Field Channel Estimation in Dual-Band XL-MIMO with Side Information-Assisted Compressed Sensing
Mar 19, 2024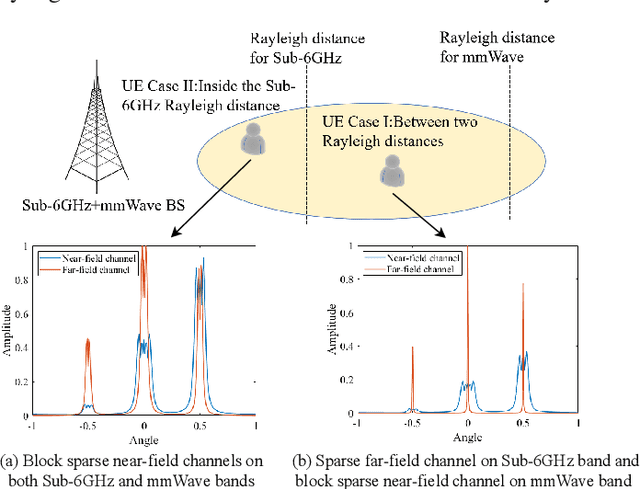
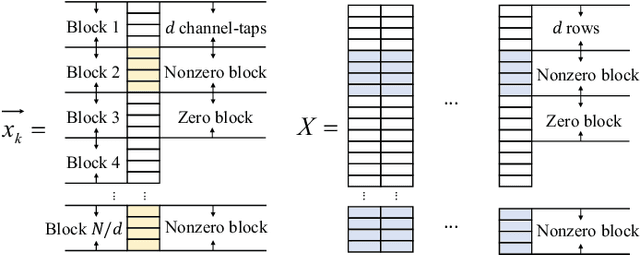
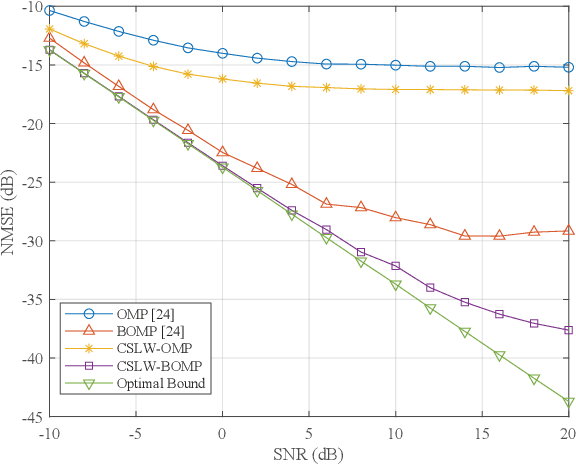
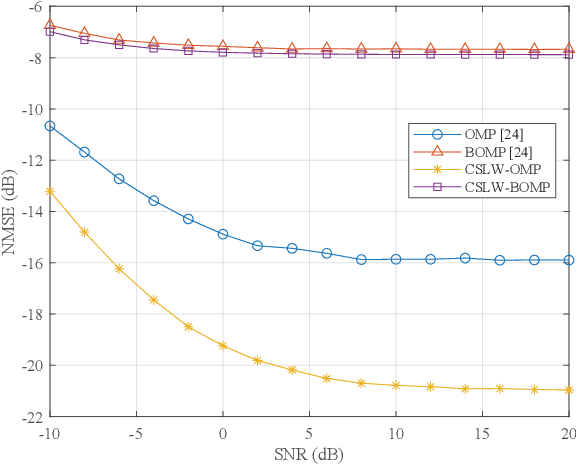
Near-field communication comes to be an indispensable part of the future sixth generation (6G) communications at the arrival of the forth-coming deployment of extremely large-scale multiple-input-multiple-output (XL-MIMO) systems. Due to the substantial number of antennas, the electromagnetic radiation field is modeled by the spherical waves instead of the conventional planar waves, leading to severe weak sparsity to angular-domain near-field channel. Therefore, the channel estimation reminiscent of the conventional compression sensing (CS) approaches in the angular domain, judiciously utilized for low pilot overhead, may result in unprecedented challenges. To this end, this paper proposes a brand-new near-field channel estimation scheme by exploiting the naturally occurring useful side information. Specifically, we formulate the dual-band near-field communication model based on the fact that high-frequency systems are likely to be deployed with lower-frequency systems. Representative side information, i.e., the structural characteristic information derived by the sparsity ambiguity and the out-of-band spatial information stemming from the lower-frequency channel, is explored and tailored to materialize exceptional near-field channel estimation. Furthermore, in-depth theoretical analyses are developed to guarantee the minimum estimation error, based on which a suite of algorithms leveraging the elaborating side information are proposed. Numerical simulations demonstrate that the designed algorithms provide more assured results than the off-the-shelf approaches in the context of the dual-band near-field communications in both on- and off-grid scenarios, where the angle of departures/arrivals are discretely or continuously distributed, respectively.
Universal representations for financial transactional data: embracing local, global, and external contexts
Apr 02, 2024Effective processing of financial transactions is essential for banking data analysis. However, in this domain, most methods focus on specialized solutions to stand-alone problems instead of constructing universal representations suitable for many problems. We present a representation learning framework that addresses diverse business challenges. We also suggest novel generative models that account for data specifics, and a way to integrate external information into a client's representation, leveraging insights from other customers' actions. Finally, we offer a benchmark, describing representation quality globally, concerning the entire transaction history; locally, reflecting the client's current state; and dynamically, capturing representation evolution over time. Our generative approach demonstrates superior performance in local tasks, with an increase in ROC-AUC of up to 14\% for the next MCC prediction task and up to 46\% for downstream tasks from existing contrastive baselines. Incorporating external information improves the scores by an additional 20\%.
Do Large Language Models Rank Fairly? An Empirical Study on the Fairness of LLMs as Rankers
Apr 04, 2024The integration of Large Language Models (LLMs) in information retrieval has raised a critical reevaluation of fairness in the text-ranking models. LLMs, such as GPT models and Llama2, have shown effectiveness in natural language understanding tasks, and prior works (e.g., RankGPT) have also demonstrated that the LLMs exhibit better performance than the traditional ranking models in the ranking task. However, their fairness remains largely unexplored. This paper presents an empirical study evaluating these LLMs using the TREC Fair Ranking dataset, focusing on the representation of binary protected attributes such as gender and geographic location, which are historically underrepresented in search outcomes. Our analysis delves into how these LLMs handle queries and documents related to these attributes, aiming to uncover biases in their ranking algorithms. We assess fairness from both user and content perspectives, contributing an empirical benchmark for evaluating LLMs as the fair ranker.
Rumor Detection with a novel graph neural network approach
Apr 02, 2024The wide spread of rumors on social media has caused a negative impact on people's daily life, leading to potential panic, fear, and mental health problems for the public. How to debunk rumors as early as possible remains a challenging problem. Existing studies mainly leverage information propagation structure to detect rumors, while very few works focus on correlation among users that they may coordinate to spread rumors in order to gain large popularity. In this paper, we propose a new detection model, that jointly learns both the representations of user correlation and information propagation to detect rumors on social media. Specifically, we leverage graph neural networks to learn the representations of user correlation from a bipartite graph that describes the correlations between users and source tweets, and the representations of information propagation with a tree structure. Then we combine the learned representations from these two modules to classify the rumors. Since malicious users intend to subvert our model after deployment, we further develop a greedy attack scheme to analyze the cost of three adversarial attacks: graph attack, comment attack, and joint attack. Evaluation results on two public datasets illustrate that the proposed MODEL outperforms the state-of-the-art rumor detection models. We also demonstrate our method performs well for early rumor detection. Moreover, the proposed detection method is more robust to adversarial attacks compared to the best existing method. Importantly, we show that it requires a high cost for attackers to subvert user correlation pattern, demonstrating the importance of considering user correlation for rumor detection.
Estimating mixed memberships in multi-layer networks
Apr 05, 2024Community detection in multi-layer networks has emerged as a crucial area of modern network analysis. However, conventional approaches often assume that nodes belong exclusively to a single community, which fails to capture the complex structure of real-world networks where nodes may belong to multiple communities simultaneously. To address this limitation, we propose novel spectral methods to estimate the common mixed memberships in the multi-layer mixed membership stochastic block model. The proposed methods leverage the eigen-decomposition of three aggregate matrices: the sum of adjacency matrices, the debiased sum of squared adjacency matrices, and the sum of squared adjacency matrices. We establish rigorous theoretical guarantees for the consistency of our methods. Specifically, we derive per-node error rates under mild conditions on network sparsity, demonstrating their consistency as the number of nodes and/or layers increases under the multi-layer mixed membership stochastic block model. Our theoretical results reveal that the method leveraging the sum of adjacency matrices generally performs poorer than the other two methods for mixed membership estimation in multi-layer networks. We conduct extensive numerical experiments to empirically validate our theoretical findings. For real-world multi-layer networks with unknown community information, we introduce two novel modularity metrics to quantify the quality of mixed membership community detection. Finally, we demonstrate the practical applications of our algorithms and modularity metrics by applying them to real-world multi-layer networks, demonstrating their effectiveness in extracting meaningful community structures.
Verifiable by Design: Aligning Language Models to Quote from Pre-Training Data
Apr 05, 2024For humans to trust the fluent generations of large language models (LLMs), they must be able to verify their correctness against trusted, external sources. Recent efforts aim to increase verifiability through citations of retrieved documents or post-hoc provenance. However, such citations are prone to mistakes that further complicate their verifiability. To address these limitations, we tackle the verifiability goal with a different philosophy: we trivialize the verification process by developing models that quote verbatim statements from trusted sources in pre-training data. We propose Quote-Tuning, which demonstrates the feasibility of aligning LLMs to leverage memorized information and quote from pre-training data. Quote-Tuning quantifies quoting against large corpora with efficient membership inference tools, and uses the amount of quotes as an implicit reward signal to construct a synthetic preference dataset for quoting, without any human annotation. Next, the target model is aligned to quote using preference optimization algorithms. Experimental results show that Quote-Tuning significantly increases the percentage of LLM generation quoted verbatim from high-quality pre-training documents by 55% to 130% relative to untuned models while maintaining response quality. Further experiments demonstrate that Quote-Tuning generalizes quoting to out-of-domain data, is applicable in different tasks, and provides additional benefits to truthfulness. Quote-Tuning not only serves as a hassle-free method to increase quoting but also opens up avenues for improving LLM trustworthiness through better verifiability.
Towards Efficient Information Fusion: Concentric Dual Fusion Attention Based Multiple Instance Learning for Whole Slide Images
Mar 21, 2024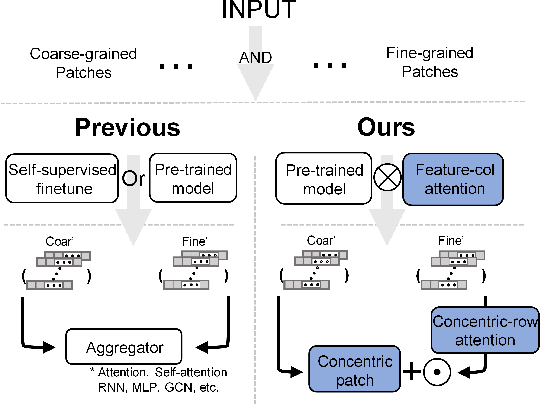
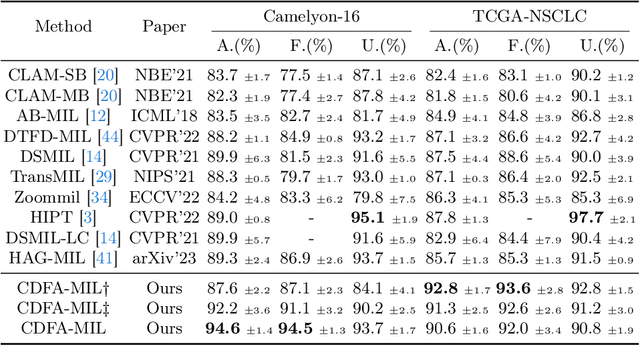
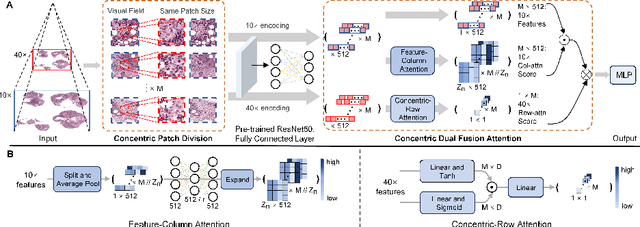
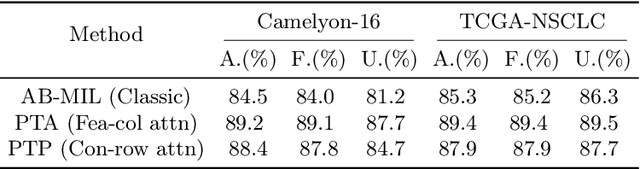
In the realm of digital pathology, multi-magnification Multiple Instance Learning (multi-mag MIL) has proven effective in leveraging the hierarchical structure of Whole Slide Images (WSIs) to reduce information loss and redundant data. However, current methods fall short in bridging the domain gap between pretrained models and medical imaging, and often fail to account for spatial relationships across different magnifications. Addressing these challenges, we introduce the Concentric Dual Fusion Attention-MIL (CDFA-MIL) framework,which innovatively combines point-to-area feature-colum attention and point-to-point concentric-row attention using concentric patch. This approach is designed to effectively fuse correlated information, enhancing feature representation and providing stronger correlation guidance for WSI analysis. CDFA-MIL distinguishes itself by offering a robust fusion strategy that leads to superior WSI recognition. Its application has demonstrated exceptional performance, significantly surpassing existing MIL methods in accuracy and F1 scores on prominent datasets like Camelyon16 and TCGA-NSCLC. Specifically, CDFA-MIL achieved an average accuracy and F1-score of 93.7\% and 94.1\% respectively on these datasets, marking a notable advancement over traditional MIL approaches.
SLIMBRAIN: Augmented Reality Real-Time Acquisition and Processing System For Hyperspectral Classification Mapping with Depth Information for In-Vivo Surgical Procedures
Mar 25, 2024Over the last two decades, augmented reality (AR) has led to the rapid development of new interfaces in various fields of social and technological application domains. One such domain is medicine, and to a higher extent surgery, where these visualization techniques help to improve the effectiveness of preoperative and intraoperative procedures. Following this trend, this paper presents SLIMBRAIN, a real-time acquisition and processing AR system suitable to classify and display brain tumor tissue from hyperspectral (HS) information. This system captures and processes HS images at 14 frames per second (FPS) during the course of a tumor resection operation to detect and delimit cancer tissue at the same time the neurosurgeon operates. The result is represented in an AR visualization where the classification results are overlapped with the RGB point cloud captured by a LiDAR camera. This representation allows natural navigation of the scene at the same time it is captured and processed, improving the visualization and hence effectiveness of the HS technology to delimit tumors. The whole system has been verified in real brain tumor resection operations.
Select and Summarize: Scene Saliency for Movie Script Summarization
Apr 04, 2024Abstractive summarization for long-form narrative texts such as movie scripts is challenging due to the computational and memory constraints of current language models. A movie script typically comprises a large number of scenes; however, only a fraction of these scenes are salient, i.e., important for understanding the overall narrative. The salience of a scene can be operationalized by considering it as salient if it is mentioned in the summary. Automatically identifying salient scenes is difficult due to the lack of suitable datasets. In this work, we introduce a scene saliency dataset that consists of human-annotated salient scenes for 100 movies. We propose a two-stage abstractive summarization approach which first identifies the salient scenes in script and then generates a summary using only those scenes. Using QA-based evaluation, we show that our model outperforms previous state-of-the-art summarization methods and reflects the information content of a movie more accurately than a model that takes the whole movie script as input.