 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Any-point Trajectory Modeling for Policy Learning
Dec 28, 2023

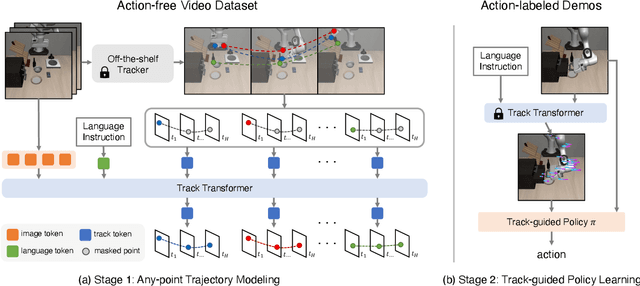
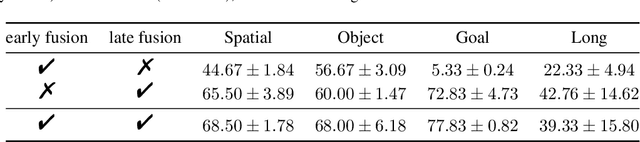
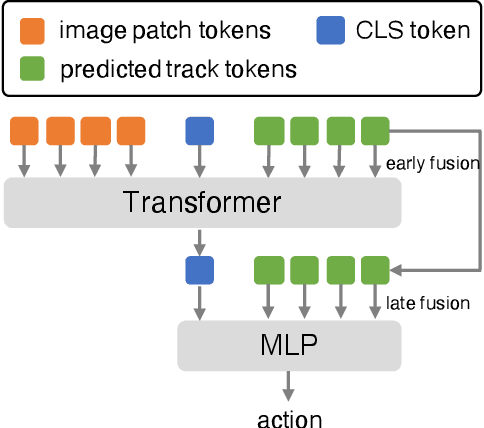
Learning from demonstration is a powerful method for teaching robots new skills, and more demonstration data often improves policy learning. However, the high cost of collecting demonstration data is a significant bottleneck. Videos, as a rich data source, contain knowledge of behaviors, physics, and semantics, but extracting control-specific information from them is challenging due to the lack of action labels. In this work, we introduce a novel framework, Any-point Trajectory Modeling (ATM), that utilizes video demonstrations by pre-training a trajectory model to predict future trajectories of arbitrary points within a video frame. Once trained, these trajectories provide detailed control guidance, enabling the learning of robust visuomotor policies with minimal action-labeled data. Our method's effectiveness is demonstrated across 130 simulation tasks, focusing on language-conditioned manipulation tasks. Visualizations and code are available at: \url{https://xingyu-lin.github.io/atm}.
Improving the Robustness of Quantized Deep Neural Networks to White-Box Attacks using Stochastic Quantization and Information-Theoretic Ensemble Training
Nov 30, 2023Most real-world applications that employ deep neural networks (DNNs) quantize them to low precision to reduce the compute needs. We present a method to improve the robustness of quantized DNNs to white-box adversarial attacks. We first tackle the limitation of deterministic quantization to fixed ``bins'' by introducing a differentiable Stochastic Quantizer (SQ). We explore the hypothesis that different quantizations may collectively be more robust than each quantized DNN. We formulate a training objective to encourage different quantized DNNs to learn different representations of the input image. The training objective captures diversity and accuracy via mutual information between ensemble members. Through experimentation, we demonstrate substantial improvement in robustness against $L_\infty$ attacks even if the attacker is allowed to backpropagate through SQ (e.g., > 50\% accuracy to PGD(5/255) on CIFAR10 without adversarial training), compared to vanilla DNNs as well as existing ensembles of quantized DNNs. We extend the method to detect attacks and generate robustness profiles in the adversarial information plane (AIP), towards a unified analysis of different threat models by correlating the MI and accuracy.
A Two-stream Hybrid CNN-Transformer Network for Skeleton-based Human Interaction Recognition
Dec 31, 2023Human Interaction Recognition is the process of identifying interactive actions between multiple participants in a specific situation. The aim is to recognise the action interactions between multiple entities and their meaning. Many single Convolutional Neural Network has issues, such as the inability to capture global instance interaction features or difficulty in training, leading to ambiguity in action semantics. In addition, the computational complexity of the Transformer cannot be ignored, and its ability to capture local information and motion features in the image is poor. In this work, we propose a Two-stream Hybrid CNN-Transformer Network (THCT-Net), which exploits the local specificity of CNN and models global dependencies through the Transformer. CNN and Transformer simultaneously model the entity, time and space relationships between interactive entities respectively. Specifically, Transformer-based stream integrates 3D convolutions with multi-head self-attention to learn inter-token correlations; We propose a new multi-branch CNN framework for CNN-based streams that automatically learns joint spatio-temporal features from skeleton sequences. The convolutional layer independently learns the local features of each joint neighborhood and aggregates the features of all joints. And the raw skeleton coordinates as well as their temporal difference are integrated with a dual-branch paradigm to fuse the motion features of the skeleton. Besides, a residual structure is added to speed up training convergence. Finally, the recognition results of the two branches are fused using parallel splicing. Experimental results on diverse and challenging datasets, demonstrate that the proposed method can better comprehend and infer the meaning and context of various actions, outperforming state-of-the-art methods.
Benchmarking Hebbian learning rules for associative memory
Dec 30, 2023Associative memory or content addressable memory is an important component function in computer science and information processing and is a key concept in cognitive and computational brain science. Many different neural network architectures and learning rules have been proposed to model associative memory of the brain while investigating key functions like pattern completion and rivalry, noise reduction, and storage capacity. A less investigated but important function is prototype extraction where the training set comprises pattern instances generated by distorting prototype patterns and the task of the trained network is to recall the correct prototype pattern given a new instance. In this paper we characterize these different aspects of associative memory performance and benchmark six different learning rules on storage capacity and prototype extraction. We consider only models with Hebbian plasticity that operate on sparse distributed representations with unit activities in the interval [0,1]. We evaluate both non-modular and modular network architectures and compare performance when trained and tested on different kinds of sparse random binary pattern sets, including correlated ones. We show that covariance learning has a robust but low storage capacity under these conditions and that the Bayesian Confidence Propagation learning rule (BCPNN) is superior with a good margin in all cases except one, reaching a three times higher composite score than the second best learning rule tested.
Advancing TTP Analysis: Harnessing the Power of Encoder-Only and Decoder-Only Language Models with Retrieval Augmented Generation
Dec 30, 2023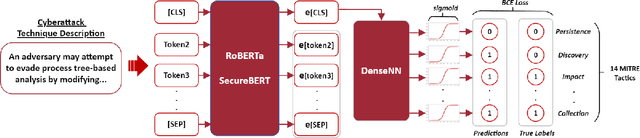

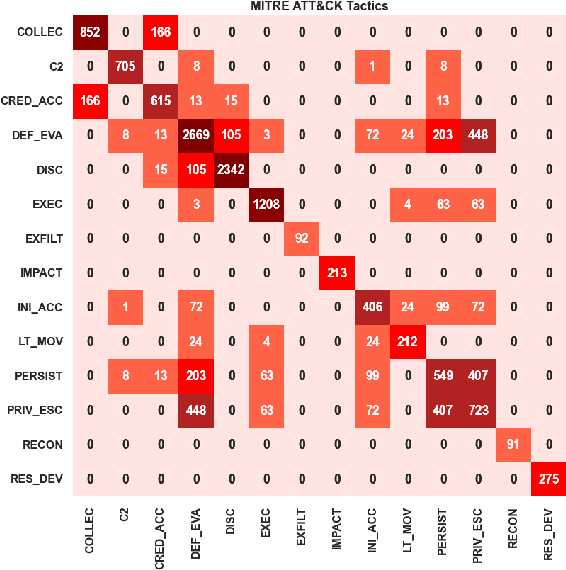
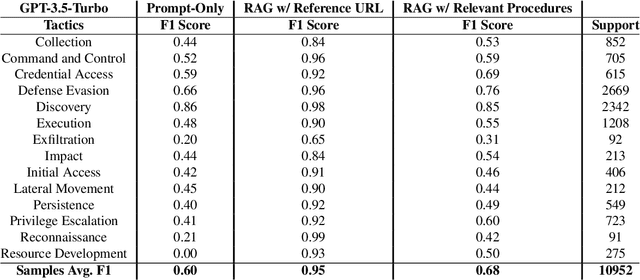
Tactics, Techniques, and Procedures (TTPs) outline the methods attackers use to exploit vulnerabilities. The interpretation of TTPs in the MITRE ATT&CK framework can be challenging for cybersecurity practitioners due to presumed expertise, complex dependencies, and inherent ambiguity. Meanwhile, advancements with Large Language Models (LLMs) have led to recent surge in studies exploring its uses in cybersecurity operations. This leads us to question how well encoder-only (e.g., RoBERTa) and decoder-only (e.g., GPT-3.5) LLMs can comprehend and summarize TTPs to inform analysts of the intended purposes (i.e., tactics) of a cyberattack procedure. The state-of-the-art LLMs have shown to be prone to hallucination by providing inaccurate information, which is problematic in critical domains like cybersecurity. Therefore, we propose the use of Retrieval Augmented Generation (RAG) techniques to extract relevant contexts for each cyberattack procedure for decoder-only LLMs (without fine-tuning). We further contrast such approach against supervised fine-tuning (SFT) of encoder-only LLMs. Our results reveal that both the direct-use of decoder-only LLMs (i.e., its pre-trained knowledge) and the SFT of encoder-only LLMs offer inaccurate interpretation of cyberattack procedures. Significant improvements are shown when RAG is used for decoder-only LLMs, particularly when directly relevant context is found. This study further sheds insights on the limitations and capabilities of using RAG for LLMs in interpreting TTPs.
Discrete Messages Improve Communication Efficiency among Isolated Intelligent Agents
Dec 28, 2023Individuals, despite having varied life experiences and learning processes, can communicate effectively through languages. This study aims to explore the efficiency of language as a communication medium. We put forth two specific hypotheses: First, discrete messages are more effective than continuous ones when agents have diverse personal experiences. Second, communications using multiple discrete tokens are more advantageous than those using a single token. To valdate these hypotheses, we designed multi-agent machine learning experiments to assess communication efficiency using various information transmission methods between speakers and listeners. Our empirical findings indicate that, in scenarios where agents are exposed to different data, communicating through sentences composed of discrete tokens offers the best inter-agent communication efficiency. The limitations of our finding include lack of systematic advantages over other more sophisticated encoder-decoder model such as variational autoencoder and lack of evluation on non-image dataset, which we will leave for future studies.
Disentangling continuous and discrete linguistic signals in transformer-based sentence embeddings
Dec 18, 2023Sentence and word embeddings encode structural and semantic information in a distributed manner. Part of the information encoded -- particularly lexical information -- can be seen as continuous, whereas other -- like structural information -- is most often discrete. We explore whether we can compress transformer-based sentence embeddings into a representation that separates different linguistic signals -- in particular, information relevant to subject-verb agreement and verb alternations. We show that by compressing an input sequence that shares a targeted phenomenon into the latent layer of a variational autoencoder-like system, the targeted linguistic information becomes more explicit. A latent layer with both discrete and continuous components captures better the targeted phenomena than a latent layer with only discrete or only continuous components. These experiments are a step towards separating linguistic signals from distributed text embeddings and linking them to more symbolic representations.
Discrete Distribution Networks
Dec 29, 2023We introduce a novel generative model, the Discrete Distribution Networks (DDN), that approximates data distribution using hierarchical discrete distributions. We posit that since the features within a network inherently contain distributional information, liberating the network from a single output to concurrently generate multiple samples proves to be highly effective. Therefore, DDN fits the target distribution, including continuous ones, by generating multiple discrete sample points. To capture finer details of the target data, DDN selects the output that is closest to the Ground Truth (GT) from the coarse results generated in the first layer. This selected output is then fed back into the network as a condition for the second layer, thereby generating new outputs more similar to the GT. As the number of DDN layers increases, the representational space of the outputs expands exponentially, and the generated samples become increasingly similar to the GT. This hierarchical output pattern of discrete distributions endows DDN with two intriguing properties: highly compressed representation and more general zero-shot conditional generation. We demonstrate the efficacy of DDN and these intriguing properties through experiments on CIFAR-10 and FFHQ.
Research on the Laws of Multimodal Perception and Cognition from a Cross-cultural Perspective -- Taking Overseas Chinese Gardens as an Example
Dec 29, 2023This study aims to explore the complex relationship between perceptual and cognitive interactions in multimodal data analysis,with a specific emphasis on spatial experience design in overseas Chinese gardens. It is found that evaluation content and images on social media can reflect individuals' concerns and sentiment responses, providing a rich data base for cognitive research that contains both sentimental and image-based cognitive information. Leveraging deep learning techniques, we analyze textual and visual data from social media, thereby unveiling the relationship between people's perceptions and sentiment cognition within the context of overseas Chinese gardens. In addition, our study introduces a multi-agent system (MAS)alongside AI agents. Each agent explores the laws of aesthetic cognition through chat scene simulation combined with web search. This study goes beyond the traditional approach of translating perceptions into sentiment scores, allowing for an extension of the research methodology in terms of directly analyzing texts and digging deeper into opinion data. This study provides new perspectives for understanding aesthetic experience and its impact on architecture and landscape design across diverse cultural contexts, which is an essential contribution to the field of cultural communication and aesthetic understanding.
Function-Space Regularization in Neural Networks: A Probabilistic Perspective
Dec 28, 2023Parameter-space regularization in neural network optimization is a fundamental tool for improving generalization. However, standard parameter-space regularization methods make it challenging to encode explicit preferences about desired predictive functions into neural network training. In this work, we approach regularization in neural networks from a probabilistic perspective and show that by viewing parameter-space regularization as specifying an empirical prior distribution over the model parameters, we can derive a probabilistically well-motivated regularization technique that allows explicitly encoding information about desired predictive functions into neural network training. This method -- which we refer to as function-space empirical Bayes (FSEB) -- includes both parameter- and function-space regularization, is mathematically simple, easy to implement, and incurs only minimal computational overhead compared to standard regularization techniques. We evaluate the utility of this regularization technique empirically and demonstrate that the proposed method leads to near-perfect semantic shift detection, highly-calibrated predictive uncertainty estimates, successful task adaption from pre-trained models, and improved generalization under covariate shift.