 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DDistill-SR: Reparameterized Dynamic Distillation Network for Lightweight Image Super-Resolution
Dec 22, 2023
Recent research on deep convolutional neural networks (CNNs) has provided a significant performance boost on efficient super-resolution (SR) tasks by trading off the performance and applicability. However, most existing methods focus on subtracting feature processing consumption to reduce the parameters and calculations without refining the immediate features, which leads to inadequate information in the restoration. In this paper, we propose a lightweight network termed DDistill-SR, which significantly improves the SR quality by capturing and reusing more helpful information in a static-dynamic feature distillation manner. Specifically, we propose a plug-in reparameterized dynamic unit (RDU) to promote the performance and inference cost trade-off. During the training phase, the RDU learns to linearly combine multiple reparameterizable blocks by analyzing varied input statistics to enhance layer-level representation. In the inference phase, the RDU is equally converted to simple dynamic convolutions that explicitly capture robust dynamic and static feature maps. Then, the information distillation block is constructed by several RDUs to enforce hierarchical refinement and selective fusion of spatial context information. Furthermore, we propose a dynamic distillation fusion (DDF) module to enable dynamic signals aggregation and communication between hierarchical modules to further improve performance. Empirical results show that our DDistill-SR outperforms the baselines and achieves state-of-the-art results on most super-resolution domains with much fewer parameters and less computational overhead. We have released the code of DDistill-SR at https://github.com/icandle/DDistill-SR.
* Accepted by IEEE Transactions on Multimedia (TMM)
Sparse-view CT Reconstruction with 3D Gaussian Volumetric Representation
Dec 25, 2023Sparse-view CT is a promising strategy for reducing the radiation dose of traditional CT scans, but reconstructing high-quality images from incomplete and noisy data is challenging. Recently, 3D Gaussian has been applied to model complex natural scenes, demonstrating fast convergence and better rendering of novel views compared to implicit neural representations (INRs). Taking inspiration from the successful application of 3D Gaussians in natural scene modeling and novel view synthesis, we investigate their potential for sparse-view CT reconstruction. We leverage prior information from the filtered-backprojection reconstructed image to initialize the Gaussians; and update their parameters via comparing difference in the projection space. Performance is further enhanced by adaptive density control. Compared to INRs, 3D Gaussians benefit more from prior information to explicitly bypass learning in void spaces and allocate the capacity efficiently, accelerating convergence. 3D Gaussians also efficiently learn high-frequency details. Trained in a self-supervised manner, 3D Gaussians avoid the need for large-scale paired data. Our experiments on the AAPM-Mayo dataset demonstrate that 3D Gaussians can provide superior performance compared to INR-based methods. This work is in progress, and the code will be publicly available.
Structured Probabilistic Coding
Dec 25, 2023This paper presents a new supervised representation learning framework, namely structured probabilistic coding (SPC), to learn compact and informative representations from input related to the target task. SPC is an encoder-only probabilistic coding technology with a structured regularization from the target label space. It can enhance the generalization ability of pre-trained language models for better language understanding. Specifically, our probabilistic coding technology simultaneously performs information encoding and task prediction in one module to more fully utilize the effective information from input data. It uses variational inference in the output space to reduce randomness and uncertainty. Besides, to better control the probability distribution in the latent space, a structured regularization is proposed to promote class-level uniformity in the latent space. With the regularization term, SPC can preserve the Gaussian distribution structure of latent code as well as better cover the hidden space with class uniformly. Experimental results on 12 natural language understanding tasks demonstrate that our SPC effectively improves the performance of pre-trained language models for classification and regression. Extensive experiments show that SPC can enhance the generalization capability, robustness to label noise, and clustering quality of output representations.
HGE: Embedding Temporal Knowledge Graphs in a Product Space of Heterogeneous Geometric Subspaces
Dec 25, 2023Temporal knowledge graphs represent temporal facts $(s,p,o,\tau)$ relating a subject $s$ and an object $o$ via a relation label $p$ at time $\tau$, where $\tau$ could be a time point or time interval. Temporal knowledge graphs may exhibit static temporal patterns at distinct points in time and dynamic temporal patterns between different timestamps. In order to learn a rich set of static and dynamic temporal patterns and apply them for inference, several embedding approaches have been suggested in the literature. However, as most of them resort to single underlying embedding spaces, their capability to model all kinds of temporal patterns was severely limited by having to adhere to the geometric property of their one embedding space. We lift this limitation by an embedding approach that maps temporal facts into a product space of several heterogeneous geometric subspaces with distinct geometric properties, i.e.\ Complex, Dual, and Split-complex spaces. In addition, we propose a temporal-geometric attention mechanism to integrate information from different geometric subspaces conveniently according to the captured relational and temporal information. Experimental results on standard temporal benchmark datasets favorably evaluate our approach against state-of-the-art models.
Towards Faithful Explanations for Text Classification with Robustness Improvement and Explanation Guided Training
Dec 29, 2023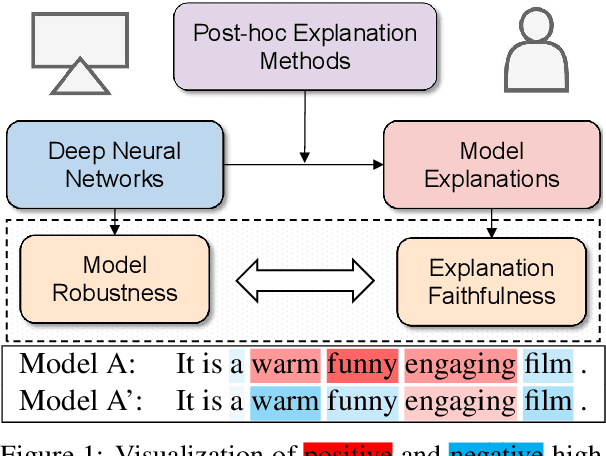
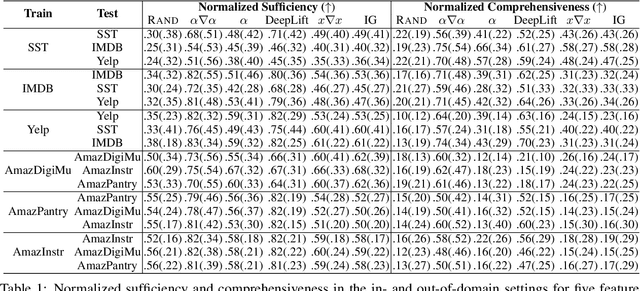
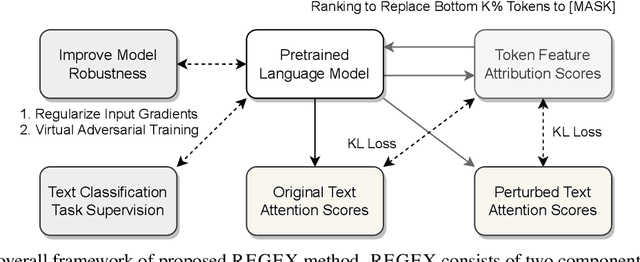

Feature attribution methods highlight the important input tokens as explanations to model predictions, which have been widely applied to deep neural networks towards trustworthy AI. However, recent works show that explanations provided by these methods face challenges of being faithful and robust. In this paper, we propose a method with Robustness improvement and Explanation Guided training towards more faithful EXplanations (REGEX) for text classification. First, we improve model robustness by input gradient regularization technique and virtual adversarial training. Secondly, we use salient ranking to mask noisy tokens and maximize the similarity between model attention and feature attribution, which can be seen as a self-training procedure without importing other external information. We conduct extensive experiments on six datasets with five attribution methods, and also evaluate the faithfulness in the out-of-domain setting. The results show that REGEX improves fidelity metrics of explanations in all settings and further achieves consistent gains based on two randomization tests. Moreover, we show that using highlight explanations produced by REGEX to train select-then-predict models results in comparable task performance to the end-to-end method.
Efficient Multi-scale Network with Learnable Discrete Wavelet Transform for Blind Motion Deblurring
Dec 29, 2023Coarse-to-fine schemes are widely used in traditional single-image motion deblur; however, in the context of deep learning, existing multi-scale algorithms not only require the use of complex modules for feature fusion of low-scale RGB images and deep semantics, but also manually generate low-resolution pairs of images that do not have sufficient confidence. In this work, we propose a multi-scale network based on single-input and multiple-outputs(SIMO) for motion deblurring. This simplifies the complexity of algorithms based on a coarse-to-fine scheme. To alleviate restoration defects impacting detail information brought about by using a multi-scale architecture, we combine the characteristics of real-world blurring trajectories with a learnable wavelet transform module to focus on the directional continuity and frequency features of the step-by-step transitions between blurred images to sharp images. In conclusion, we propose a multi-scale network with a learnable discrete wavelet transform (MLWNet), which exhibits state-of-the-art performance on multiple real-world deblurred datasets, in terms of both subjective and objective quality as well as computational efficiency.
Commonsense for Zero-Shot Natural Language Video Localization
Dec 29, 2023Zero-shot Natural Language-Video Localization (NLVL) methods have exhibited promising results in training NLVL models exclusively with raw video data by dynamically generating video segments and pseudo-query annotations. However, existing pseudo-queries often lack grounding in the source video, resulting in unstructured and disjointed content. In this paper, we investigate the effectiveness of commonsense reasoning in zero-shot NLVL. Specifically, we present CORONET, a zero-shot NLVL framework that leverages commonsense to bridge the gap between videos and generated pseudo-queries via a commonsense enhancement module. CORONET employs Graph Convolution Networks (GCN) to encode commonsense information extracted from a knowledge graph, conditioned on the video, and cross-attention mechanisms to enhance the encoded video and pseudo-query representations prior to localization. Through empirical evaluations on two benchmark datasets, we demonstrate that CORONET surpasses both zero-shot and weakly supervised baselines, achieving improvements up to 32.13% across various recall thresholds and up to 6.33% in mIoU. These results underscore the significance of leveraging commonsense reasoning for zero-shot NLVL.
CARAT: Contrastive Feature Reconstruction and Aggregation for Multi-modal Multi-label Emotion Recognition
Dec 29, 2023Multi-modal multi-label emotion recognition (MMER) aims to identify relevant emotions from multiple modalities. The challenge of MMER is how to effectively capture discriminative features for multiple labels from heterogeneous data. Recent studies are mainly devoted to exploring various fusion strategies to integrate multi-modal information into a unified representation for all labels. However, such a learning scheme not only overlooks the specificity of each modality but also fails to capture individual discriminative features for different labels. Moreover, dependencies of labels and modalities cannot be effectively modeled. To address these issues, this paper presents ContrAstive feature Reconstruction and AggregaTion (CARAT) for the MMER task. Specifically, we devise a reconstruction-based fusion mechanism to better model fine-grained modality-to-label dependencies by contrastively learning modal-separated and label-specific features. To further exploit the modality complementarity, we introduce a shuffle-based aggregation strategy to enrich co-occurrence collaboration among labels. Experiments on two benchmark datasets CMU-MOSEI and M3ED demonstrate the effectiveness of CARAT over state-of-the-art methods. Code is available at https://github.com/chengzju/CARAT.
SANIA: Polyak-type Optimization Framework Leads to Scale Invariant Stochastic Algorithms
Dec 28, 2023Adaptive optimization methods are widely recognized as among the most popular approaches for training Deep Neural Networks (DNNs). Techniques such as Adam, AdaGrad, and AdaHessian utilize a preconditioner that modifies the search direction by incorporating information about the curvature of the objective function. However, despite their adaptive characteristics, these methods still require manual fine-tuning of the step-size. This, in turn, impacts the time required to solve a particular problem. This paper presents an optimization framework named SANIA to tackle these challenges. Beyond eliminating the need for manual step-size hyperparameter settings, SANIA incorporates techniques to address poorly scaled or ill-conditioned problems. We also explore several preconditioning methods, including Hutchinson's method, which approximates the Hessian diagonal of the loss function. We conclude with an extensive empirical examination of the proposed techniques across classification tasks, covering both convex and non-convex contexts.
Graph Learning in 4D: a Quaternion-valued Laplacian to Enhance Spectral GCNs
Dec 28, 2023We introduce QuaterGCN, a spectral Graph Convolutional Network (GCN) with quaternion-valued weights at whose core lies the Quaternionic Laplacian, a quaternion-valued Laplacian matrix by whose proposal we generalize two widely-used Laplacian matrices: the classical Laplacian (defined for undirected graphs) and the complex-valued Sign-Magnetic Laplacian (proposed to handle digraphs with weights of arbitrary sign). In addition to its generality, our Quaternionic Laplacian is the only Laplacian to completely preserve the topology of a digraph, as it can handle graphs and digraphs containing antiparallel pairs of edges (digons) of different weights without reducing them to a single (directed or undirected) edge as done with other Laplacians. Experimental results show the superior performance of QuaterGCN compared to other state-of-the-art GCNs, particularly in scenarios where the information the digons carry is crucial to successfully address the task at hand.