 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Automatic detection of relevant information, predictions and forecasts in financial news through topic modelling with Latent Dirichlet Allocation
Mar 30, 2024
Financial news items are unstructured sources of information that can be mined to extract knowledge for market screening applications. Manual extraction of relevant information from the continuous stream of finance-related news is cumbersome and beyond the skills of many investors, who, at most, can follow a few sources and authors. Accordingly, we focus on the analysis of financial news to identify relevant text and, within that text, forecasts and predictions. We propose a novel Natural Language Processing (NLP) system to assist investors in the detection of relevant financial events in unstructured textual sources by considering both relevance and temporality at the discursive level. Firstly, we segment the text to group together closely related text. Secondly, we apply co-reference resolution to discover internal dependencies within segments. Finally, we perform relevant topic modelling with Latent Dirichlet Allocation (LDA) to separate relevant from less relevant text and then analyse the relevant text using a Machine Learning-oriented temporal approach to identify predictions and speculative statements. We created an experimental data set composed of 2,158 financial news items that were manually labelled by NLP researchers to evaluate our solution. The ROUGE-L values for the identification of relevant text and predictions/forecasts were 0.662 and 0.982, respectively. To our knowledge, this is the first work to jointly consider relevance and temporality at the discursive level. It contributes to the transfer of human associative discourse capabilities to expert systems through the combination of multi-paragraph topic segmentation and co-reference resolution to separate author expression patterns, topic modelling with LDA to detect relevant text, and discursive temporality analysis to identify forecasts and predictions within this text.
DWE+: Dual-Way Matching Enhanced Framework for Multimodal Entity Linking
Apr 07, 2024Multimodal entity linking (MEL) aims to utilize multimodal information (usually textual and visual information) to link ambiguous mentions to unambiguous entities in knowledge base. Current methods facing main issues: (1)treating the entire image as input may contain redundant information. (2)the insufficient utilization of entity-related information, such as attributes in images. (3)semantic inconsistency between the entity in knowledge base and its representation. To this end, we propose DWE+ for multimodal entity linking. DWE+ could capture finer semantics and dynamically maintain semantic consistency with entities. This is achieved by three aspects: (a)we introduce a method for extracting fine-grained image features by partitioning the image into multiple local objects. Then, hierarchical contrastive learning is used to further align semantics between coarse-grained information(text and image) and fine-grained (mention and visual objects). (b)we explore ways to extract visual attributes from images to enhance fusion feature such as facial features and identity. (c)we leverage Wikipedia and ChatGPT to capture the entity representation, achieving semantic enrichment from both static and dynamic perspectives, which better reflects the real-world entity semantics. Experiments on Wikimel, Richpedia, and Wikidiverse datasets demonstrate the effectiveness of DWE+ in improving MEL performance. Specifically, we optimize these datasets and achieve state-of-the-art performance on the enhanced datasets. The code and enhanced datasets are released on https://github.com/season1blue/DWET
Weakly Supervised Deep Hyperspherical Quantization for Image Retrieval
Apr 07, 2024Deep quantization methods have shown high efficiency on large-scale image retrieval. However, current models heavily rely on ground-truth information, hindering the application of quantization in label-hungry scenarios. A more realistic demand is to learn from inexhaustible uploaded images that are associated with informal tags provided by amateur users. Though such sketchy tags do not obviously reveal the labels, they actually contain useful semantic information for supervising deep quantization. To this end, we propose Weakly-Supervised Deep Hyperspherical Quantization (WSDHQ), which is the first work to learn deep quantization from weakly tagged images. Specifically, 1) we use word embeddings to represent the tags and enhance their semantic information based on a tag correlation graph. 2) To better preserve semantic information in quantization codes and reduce quantization error, we jointly learn semantics-preserving embeddings and supervised quantizer on hypersphere by employing a well-designed fusion layer and tailor-made loss functions. Extensive experiments show that WSDHQ can achieve state-of-art performance on weakly-supervised compact coding. Code is available at https://github.com/gimpong/AAAI21-WSDHQ.
Private Wasserstein Distance with Random Noises
Apr 10, 2024Wasserstein distance is a principle measure of data divergence from a distributional standpoint. However, its application becomes challenging in the context of data privacy, where sharing raw data is restricted. Prior attempts have employed techniques like Differential Privacy or Federated optimization to approximate Wasserstein distance. Nevertheless, these approaches often lack accuracy and robustness against potential attack. In this study, we investigate the underlying triangular properties within the Wasserstein space, leading to a straightforward solution named TriangleWad. This approach enables the computation of Wasserstein distance between datasets stored across different entities. Notably, TriangleWad is 20 times faster, making raw data information truly invisible, enhancing resilience against attacks, and without sacrificing estimation accuracy. Through comprehensive experimentation across various tasks involving both image and text data, we demonstrate its superior performance and generalizations.
Language Models Can Reduce Asymmetry in Information Markets
Mar 21, 2024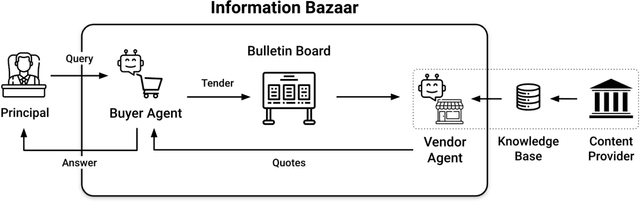

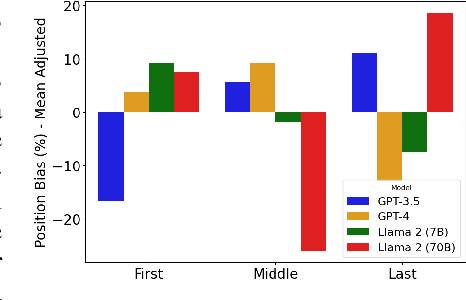
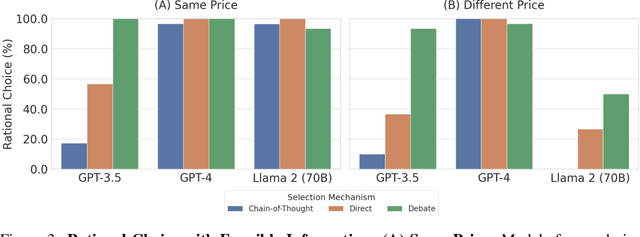
This work addresses the buyer's inspection paradox for information markets. The paradox is that buyers need to access information to determine its value, while sellers need to limit access to prevent theft. To study this, we introduce an open-source simulated digital marketplace where intelligent agents, powered by language models, buy and sell information on behalf of external participants. The central mechanism enabling this marketplace is the agents' dual capabilities: they not only have the capacity to assess the quality of privileged information but also come equipped with the ability to forget. This ability to induce amnesia allows vendors to grant temporary access to proprietary information, significantly reducing the risk of unauthorized retention while enabling agents to accurately gauge the information's relevance to specific queries or tasks. To perform well, agents must make rational decisions, strategically explore the marketplace through generated sub-queries, and synthesize answers from purchased information. Concretely, our experiments (a) uncover biases in language models leading to irrational behavior and evaluate techniques to mitigate these biases, (b) investigate how price affects demand in the context of informational goods, and (c) show that inspection and higher budgets both lead to higher quality outcomes.
Is There a One-Model-Fits-All Approach to Information Extraction? Revisiting Task Definition Biases
Mar 25, 2024Definition bias is a negative phenomenon that can mislead models. Definition bias in information extraction appears not only across datasets from different domains but also within datasets sharing the same domain. We identify two types of definition bias in IE: bias among information extraction datasets and bias between information extraction datasets and instruction tuning datasets. To systematically investigate definition bias, we conduct three probing experiments to quantitatively analyze it and discover the limitations of unified information extraction and large language models in solving definition bias. To mitigate definition bias in information extraction, we propose a multi-stage framework consisting of definition bias measurement, bias-aware fine-tuning, and task-specific bias mitigation. Experimental results demonstrate the effectiveness of our framework in addressing definition bias. Resources of this paper can be found at https://github.com/EZ-hwh/definition-bias
SpikeNVS: Enhancing Novel View Synthesis from Blurry Images via Spike Camera
Apr 11, 2024One of the most critical factors in achieving sharp Novel View Synthesis (NVS) using neural field methods like Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) is the quality of the training images. However, Conventional RGB cameras are susceptible to motion blur. In contrast, neuromorphic cameras like event and spike cameras inherently capture more comprehensive temporal information, which can provide a sharp representation of the scene as additional training data. Recent methods have explored the integration of event cameras to improve the quality of NVS. The event-RGB approaches have some limitations, such as high training costs and the inability to work effectively in the background. Instead, our study introduces a new method that uses the spike camera to overcome these limitations. By considering texture reconstruction from spike streams as ground truth, we design the Texture from Spike (TfS) loss. Since the spike camera relies on temporal integration instead of temporal differentiation used by event cameras, our proposed TfS loss maintains manageable training costs. It handles foreground objects with backgrounds simultaneously. We also provide a real-world dataset captured with our spike-RGB camera system to facilitate future research endeavors. We conduct extensive experiments using synthetic and real-world datasets to demonstrate that our design can enhance novel view synthesis across NeRF and 3DGS. The code and dataset will be made available for public access.
RiskLabs: Predicting Financial Risk Using Large Language Model Based on Multi-Sources Data
Apr 11, 2024The integration of Artificial Intelligence (AI) techniques, particularly large language models (LLMs), in finance has garnered increasing academic attention. Despite progress, existing studies predominantly focus on tasks like financial text summarization, question-answering (Q$\&$A), and stock movement prediction (binary classification), with a notable gap in the application of LLMs for financial risk prediction. Addressing this gap, in this paper, we introduce \textbf{RiskLabs}, a novel framework that leverages LLMs to analyze and predict financial risks. RiskLabs uniquely combines different types of financial data, including textual and vocal information from Earnings Conference Calls (ECCs), market-related time series data, and contextual news data surrounding ECC release dates. Our approach involves a multi-stage process: initially extracting and analyzing ECC data using LLMs, followed by gathering and processing time-series data before the ECC dates to model and understand risk over different timeframes. Using multimodal fusion techniques, RiskLabs amalgamates these varied data features for comprehensive multi-task financial risk prediction. Empirical experiment results demonstrate RiskLab's effectiveness in forecasting both volatility and variance in financial markets. Through comparative experiments, we demonstrate how different data sources contribute to financial risk assessment and discuss the critical role of LLMs in this context. Our findings not only contribute to the AI in finance application but also open new avenues for applying LLMs in financial risk assessment.
Two-Way Aerial Secure Communications via Distributed Collaborative Beamforming under Eavesdropper Collusion
Apr 11, 2024Unmanned aerial vehicles (UAVs)-enabled aerial communication provides a flexible, reliable, and cost-effective solution for a range of wireless applications. However, due to the high line-of-sight (LoS) probability, aerial communications between UAVs are vulnerable to eavesdropping attacks, particularly when multiple eavesdroppers collude. In this work, we aim to introduce distributed collaborative beamforming (DCB) into UAV swarms and handle the eavesdropper collusion by controlling the corresponding signal distributions. Specifically, we consider a two-way DCB-enabled aerial communication between two UAV swarms and construct these swarms as two UAV virtual antenna arrays. Then, we minimize the two-way known secrecy capacity and the maximum sidelobe level to avoid information leakage from the known and unknown eavesdroppers, respectively. Simultaneously, we also minimize the energy consumption of UAVs for constructing virtual antenna arrays. Due to the conflicting relationships between secure performance and energy efficiency, we consider these objectives as a multi-objective optimization problem. Following this, we propose an enhanced multi-objective swarm intelligence algorithm via the characterized properties of the problem. Simulation results show that our proposed algorithm can obtain a set of informative solutions and outperform other state-of-the-art baseline algorithms. Experimental tests demonstrate that our method can be deployed in limited computing power platforms of UAVs and is beneficial for saving computational resources.
RULER: What's the Real Context Size of Your Long-Context Language Models?
Apr 11, 2024The needle-in-a-haystack (NIAH) test, which examines the ability to retrieve a piece of information (the "needle") from long distractor texts (the "haystack"), has been widely adopted to evaluate long-context language models (LMs). However, this simple retrieval-based test is indicative of only a superficial form of long-context understanding. To provide a more comprehensive evaluation of long-context LMs, we create a new synthetic benchmark RULER with flexible configurations for customized sequence length and task complexity. RULER expands upon the vanilla NIAH test to encompass variations with diverse types and quantities of needles. Moreover, RULER introduces new task categories multi-hop tracing and aggregation to test behaviors beyond searching from context. We evaluate ten long-context LMs with 13 representative tasks in RULER. Despite achieving nearly perfect accuracy in the vanilla NIAH test, all models exhibit large performance drops as the context length increases. While these models all claim context sizes of 32K tokens or greater, only four models (GPT-4, Command-R, Yi-34B, and Mixtral) can maintain satisfactory performance at the length of 32K. Our analysis of Yi-34B, which supports context length of 200K, reveals large room for improvement as we increase input length and task complexity. We open source RULER to spur comprehensive evaluation of long-context LMs.