 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MedSumm: A Multimodal Approach to Summarizing Code-Mixed Hindi-English Clinical Queries
Jan 03, 2024
In the healthcare domain, summarizing medical questions posed by patients is critical for improving doctor-patient interactions and medical decision-making. Although medical data has grown in complexity and quantity, the current body of research in this domain has primarily concentrated on text-based methods, overlooking the integration of visual cues. Also prior works in the area of medical question summarisation have been limited to the English language. This work introduces the task of multimodal medical question summarization for codemixed input in a low-resource setting. To address this gap, we introduce the Multimodal Medical Codemixed Question Summarization MMCQS dataset, which combines Hindi-English codemixed medical queries with visual aids. This integration enriches the representation of a patient's medical condition, providing a more comprehensive perspective. We also propose a framework named MedSumm that leverages the power of LLMs and VLMs for this task. By utilizing our MMCQS dataset, we demonstrate the value of integrating visual information from images to improve the creation of medically detailed summaries. This multimodal strategy not only improves healthcare decision-making but also promotes a deeper comprehension of patient queries, paving the way for future exploration in personalized and responsive medical care. Our dataset, code, and pre-trained models will be made publicly available.
Towards Mitigating Dimensional Collapse of Representations in Collaborative Filtering
Dec 29, 2023Contrastive Learning (CL) has shown promising performance in collaborative filtering. The key idea is to generate augmentation-invariant embeddings by maximizing the Mutual Information between different augmented views of the same instance. However, we empirically observe that existing CL models suffer from the \textsl{dimensional collapse} issue, where user/item embeddings only span a low-dimension subspace of the entire feature space. This suppresses other dimensional information and weakens the distinguishability of embeddings. Here we propose a non-contrastive learning objective, named nCL, which explicitly mitigates dimensional collapse of representations in collaborative filtering. Our nCL aims to achieve geometric properties of \textsl{Alignment} and \textsl{Compactness} on the embedding space. In particular, the alignment tries to push together representations of positive-related user-item pairs, while compactness tends to find the optimal coding length of user/item embeddings, subject to a given distortion. More importantly, our nCL does not require data augmentation nor negative sampling during training, making it scalable to large datasets. Experimental results demonstrate the superiority of our nCL.
GENET: Unleashing the Power of Side Information for Recommendation via Hypergraph Pre-training
Nov 22, 2023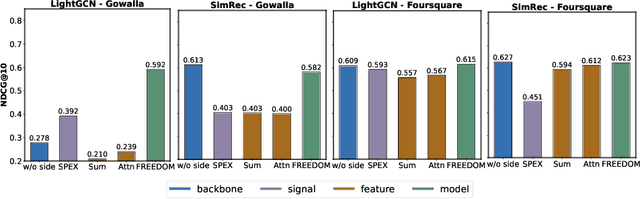

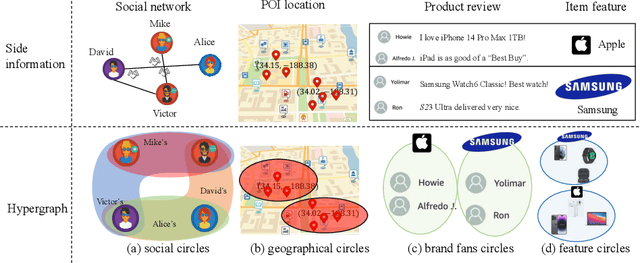
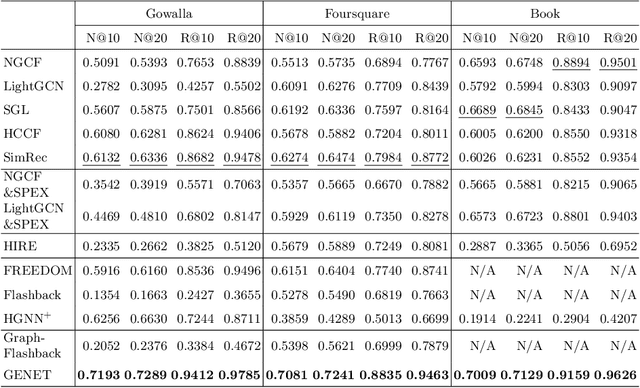
Recommendation with side information has drawn significant research interest due to its potential to mitigate user feedback sparsity. However, existing models struggle with generalization across diverse domains and types of side information. In particular, three challenges have not been addressed, and they are (1) the diverse formats of side information, including text sequences. (2) The diverse semantics of side information that describes items and users from multi-level in a context different from recommendation systems. (3) The diverse correlations in side information to measure similarity over multiple objects beyond pairwise relations. In this paper, we introduce GENET (Generalized hypErgraph pretraiNing on sidE informaTion), which pre-trains user and item representations on feedback-irrelevant side information and fine-tunes the representations on user feedback data. GENET leverages pre-training as a means to prevent side information from overshadowing critical ID features and feedback signals. It employs a hypergraph framework to accommodate various types of diverse side information. During pre-training, GENET integrates tasks for hyperlink prediction and self-supervised contrast to capture fine-grained semantics at both local and global levels. Additionally, it introduces a unique strategy to enhance pre-training robustness by perturbing positive samples while maintaining high-order relations. Extensive experiments demonstrate that GENET exhibits strong generalization capabilities, outperforming the SOTA method by up to 38% in TOP-N recommendation and Sequential recommendation tasks on various datasets with different side information.
AI-driven emergence of frequency information non-uniform distribution via THz metasurface spectrum prediction
Dec 05, 2023Recently, artificial intelligence has been extensively deployed across various scientific disciplines, optimizing and guiding the progression of experiments through the integration of abundant datasets, whilst continuously probing the vast theoretical space encapsulated within the data. Particularly, deep learning models, due to their end-to-end adaptive learning capabilities, are capable of autonomously learning intrinsic data features, thereby transcending the limitations of traditional experience to a certain extent. Here, we unveil previously unreported information characteristics pertaining to different frequencies emerged during our work on predicting the terahertz spectral modulation effects of metasurfaces based on AI-prediction. Moreover, we have substantiated that our proposed methodology of simply adding supplementary multi-frequency inputs to the existing dataset during the target spectral prediction process can significantly enhance the predictive accuracy of the network. This approach effectively optimizes the utilization of existing datasets and paves the way for interdisciplinary research and applications in artificial intelligence, chemistry, composite material design, biomedicine, and other fields.
DAS: A Deformable Attention to Capture Salient Information in CNNs
Nov 20, 2023Convolutional Neural Networks (CNNs) excel in local spatial pattern recognition. For many vision tasks, such as object recognition and segmentation, salient information is also present outside CNN's kernel boundaries. However, CNNs struggle in capturing such relevant information due to their confined receptive fields. Self-attention can improve a model's access to global information but increases computational overhead. We present a fast and simple fully convolutional method called DAS that helps focus attention on relevant information. It uses deformable convolutions for the location of pertinent image regions and separable convolutions for efficiency. DAS plugs into existing CNNs and propagates relevant information using a gating mechanism. Compared to the O(n^2) computational complexity of transformer-style attention, DAS is O(n). Our claim is that DAS's ability to pay increased attention to relevant features results in performance improvements when added to popular CNNs for Image Classification and Object Detection. For example, DAS yields an improvement on Stanford Dogs (4.47%), ImageNet (1.91%), and COCO AP (3.3%) with base ResNet50 backbone. This outperforms other CNN attention mechanisms while using similar or less FLOPs. Our code will be publicly available.
IG Captioner: Information Gain Captioners are Strong Zero-shot Classifiers
Nov 27, 2023Generative training has been demonstrated to be powerful for building visual-language models. However, on zero-shot discriminative benchmarks, there is still a performance gap between models trained with generative and discriminative objectives. In this paper, we aim to narrow this gap by improving the efficacy of generative training on classification tasks, without any finetuning processes or additional modules. Specifically, we focus on narrowing the gap between the generative captioner and the CLIP classifier. We begin by analysing the predictions made by the captioner and classifier and observe that the caption generation inherits the distribution bias from the language model trained with pure text modality, making it less grounded on the visual signal. To tackle this problem, we redesign the scoring objective for the captioner to alleviate the distributional bias and focus on measuring the gain of information brought by the visual inputs. We further design a generative training objective to match the evaluation objective. We name our model trained and evaluated from the novel procedures as Information Gain (IG) captioner. We pretrain the models on the public Laion-5B dataset and perform a series of discriminative evaluations. For the zero-shot classification on ImageNet, IG captioner achieves $> 18\%$ improvements over the standard captioner, achieving comparable performances with the CLIP classifier. IG captioner also demonstrated strong performance on zero-shot image-text retrieval tasks on MSCOCO and Flickr30K. We hope this paper inspires further research towards unifying generative and discriminative training procedures for visual-language models.
Zero-Shot Position Debiasing for Large Language Models
Jan 02, 2024Fine-tuning has been demonstrated to be an effective method to improve the domain performance of large language models (LLMs). However, LLMs might fit the dataset bias and shortcuts for prediction, leading to poor generation performance. Experimental result shows that LLMs are prone to exhibit position bias, i.e., leveraging information positioned at the beginning or end, or specific positional cues within the input. Existing works on mitigating position bias require external bias knowledge or annotated non-biased samples, which is unpractical in reality. In this work, we propose a zero-shot position debiasing (ZOE) framework to mitigate position bias for LLMs. ZOE leverages unsupervised responses from pre-trained LLMs for debiasing, thus without any external knowledge or datasets. To improve the quality of unsupervised responses, we propose a master-slave alignment (MSA) module to prune these responses. Experiments on eight datasets and five tasks show that ZOE consistently outperforms existing methods in mitigating four types of position biases. Besides, ZOE achieves this by sacrificing only a small performance on biased samples, which is simple and effective.
Utilizing Autoregressive Networks for Full Lifecycle Data Generation of Rolling Bearings for RUL Prediction
Jan 02, 2024The prediction of rolling bearing lifespan is of significant importance in industrial production. However, the scarcity of high-quality, full lifecycle data has been a major constraint in achieving precise predictions. To address this challenge, this paper introduces the CVGAN model, a novel framework capable of generating one-dimensional vibration signals in both horizontal and vertical directions, conditioned on historical vibration data and remaining useful life. In addition, we propose an autoregressive generation method that can iteratively utilize previously generated vibration information to guide the generation of current signals. The effectiveness of the CVGAN model is validated through experiments conducted on the PHM 2012 dataset. Our findings demonstrate that the CVGAN model, in terms of both MMD and FID metrics, outperforms many advanced methods in both autoregressive and non-autoregressive generation modes. Notably, training using the full lifecycle data generated by the CVGAN model significantly improves the performance of the predictive model. This result highlights the effectiveness of the data generated by CVGans in enhancing the predictive power of these models.
BEV-CLIP: Multi-modal BEV Retrieval Methodology for Complex Scene in Autonomous Driving
Jan 02, 2024The demand for the retrieval of complex scene data in autonomous driving is increasing, especially as passenger vehicles have been equipped with the ability to navigate urban settings, with the imperative to address long-tail scenarios. Meanwhile, under the pre-existing two dimensional image retrieval method, some problems may arise with scene retrieval, such as lack of global feature representation and subpar text retrieval ability. To address these issues, we have proposed \textbf{BEV-CLIP}, the first multimodal Bird's-Eye View(BEV) retrieval methodology that utilizes descriptive text as an input to retrieve corresponding scenes. This methodology applies the semantic feature extraction abilities of a large language model (LLM) to facilitate zero-shot retrieval of extensive text descriptions, and incorporates semi-structured information from a knowledge graph to improve the semantic richness and variety of the language embedding. Our experiments result in 87.66% accuracy on NuScenes dataset in text-to-BEV feature retrieval. The demonstrated cases in our paper support that our retrieval method is also indicated to be effective in identifying certain long-tail corner scenes.
Learning the Dynamic Correlations and Mitigating Noise by Hierarchical Convolution for Long-term Sequence Forecasting
Dec 28, 2023Deep learning algorithms, especially Transformer-based models, have achieved significant performance by capturing long-range dependencies and historical information. However, the power of convolution has not been fully investigated. Moreover, most existing works ignore the dynamic interaction among variables and evolutionary noise in series. Addressing these issues, we propose a Hierarchical Memorizing Network (HMNet). In particular, a hierarchical convolution structure is introduced to extract the information from the series at various scales. Besides, we propose a dynamic variable interaction module to learn the varying correlation and an adaptive denoising module to search and exploit similar patterns to alleviate noises. These modules can cooperate with the hierarchical structure from the perspective of fine to coarse grain. Experiments on five benchmarks demonstrate that HMNet significantly outperforms the state-of-the-art models by 10.6% on MSE and 5.7% on MAE. Our code is released at https://github.com/yzhHoward/HMNet.