 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DarkShot: Lighting Dark Images with Low-Compute and High-Quality
Jan 10, 2024
Nighttime photography encounters escalating challenges in extremely low-light conditions, primarily attributable to the ultra-low signal-to-noise ratio. For real-world deployment, a practical solution must not only produce visually appealing results but also require minimal computation. However, most existing methods are either focused on improving restoration performance or employ lightweight models at the cost of quality. This paper proposes a lightweight network that outperforms existing state-of-the-art (SOTA) methods in low-light enhancement tasks while minimizing computation. The proposed network incorporates Siamese Self-Attention Block (SSAB) and Skip-Channel Attention (SCA) modules, which enhance the model's capacity to aggregate global information and are well-suited for high-resolution images. Additionally, based on our analysis of the low-light image restoration process, we propose a Two-Stage Framework that achieves superior results. Our model can restore a UHD 4K resolution image with minimal computation while keeping SOTA restoration quality.
VGA: Vision and Graph Fused Attention Network for Rumor Detection
Jan 03, 2024With the development of social media, rumors have been spread broadly on social media platforms, causing great harm to society. Beside textual information, many rumors also use manipulated images or conceal textual information within images to deceive people and avoid being detected, making multimodal rumor detection be a critical problem. The majority of multimodal rumor detection methods mainly concentrate on extracting features of source claims and their corresponding images, while ignoring the comments of rumors and their propagation structures. These comments and structures imply the wisdom of crowds and are proved to be crucial to debunk rumors. Moreover, these methods usually only extract visual features in a basic manner, seldom consider tampering or textual information in images. Therefore, in this study, we propose a novel Vision and Graph Fused Attention Network (VGA) for rumor detection to utilize propagation structures among posts so as to obtain the crowd opinions and further explore visual tampering features, as well as the textual information hidden in images. We conduct extensive experiments on three datasets, demonstrating that VGA can effectively detect multimodal rumors and outperform state-of-the-art methods significantly.
Multichannel AV-wav2vec2: A Framework for Learning Multichannel Multi-Modal Speech Representation
Jan 07, 2024Self-supervised speech pre-training methods have developed rapidly in recent years, which show to be very effective for many near-field single-channel speech tasks. However, far-field multichannel speech processing is suffering from the scarcity of labeled multichannel data and complex ambient noises. The efficacy of self-supervised learning for far-field multichannel and multi-modal speech processing has not been well explored. Considering that visual information helps to improve speech recognition performance in noisy scenes, in this work we propose a multichannel multi-modal speech self-supervised learning framework AV-wav2vec2, which utilizes video and multichannel audio data as inputs. First, we propose a multi-path structure to process multichannel audio streams and a visual stream in parallel, with intra- and inter-channel contrastive losses as training targets to fully exploit the spatiotemporal information in multichannel speech data. Second, based on contrastive learning, we use additional single-channel audio data, which is trained jointly to improve the performance of speech representation. Finally, we use a Chinese multichannel multi-modal dataset in real scenarios to validate the effectiveness of the proposed method on audio-visual speech recognition (AVSR), automatic speech recognition (ASR), visual speech recognition (VSR) and audio-visual speaker diarization (AVSD) tasks.
A Survey on Game Theory Optimal Poker
Jan 02, 2024Poker is in the family of imperfect information games unlike other games such as chess, connect four, etc which are perfect information game instead. While many perfect information games have been solved, no non-trivial imperfect information game has been solved to date. This makes poker a great test bed for Artificial Intelligence research. In this paper we firstly compare Game theory optimal poker to Exploitative poker. Secondly, we discuss the intricacies of abstraction techniques, betting models, and specific strategies employed by successful poker bots like Tartanian[1] and Pluribus[6]. Thirdly, we also explore 2-player vs multi-player games and the limitations that come when playing with more players. Finally, this paper discusses the role of machine learning and theoretical approaches in developing winning strategies and suggests future directions for this rapidly evolving field.
BA-SAM: Scalable Bias-Mode Attention Mask for Segment Anything Model
Jan 08, 2024In this paper, we address the challenge of image resolution variation for the Segment Anything Model (SAM). SAM, known for its zero-shot generalizability, exhibits a performance degradation when faced with datasets with varying image sizes. Previous approaches tend to resize the image to a fixed size or adopt structure modifications, hindering the preservation of SAM's rich prior knowledge. Besides, such task-specific tuning necessitates a complete retraining of the model, which is cost-expensive and unacceptable for deployment in the downstream tasks. In this paper, we reformulate this issue as a length extrapolation problem, where token sequence length varies while maintaining a consistent patch size for images of different sizes. To this end, we propose Scalable Bias-Mode Attention Mask (BA-SAM) to enhance SAM's adaptability to varying image resolutions while eliminating the need for structure modifications. Firstly, we introduce a new scaling factor to ensure consistent magnitude in the attention layer's dot product values when the token sequence length changes. Secondly, we present a bias-mode attention mask that allows each token to prioritize neighboring information, mitigating the impact of untrained distant information. Our BA-SAM demonstrates efficacy in two scenarios: zero-shot and fine-tuning. Extensive evaluation on diverse datasets, including DIS5K, DUTS, ISIC, COD10K, and COCO, reveals its ability to significantly mitigate performance degradation in the zero-shot setting and achieve state-of-the-art performance with minimal fine-tuning. Furthermore, we propose a generalized model and benchmark, showcasing BA-SAM's generalizability across all four datasets simultaneously.
On Age of Information and Energy-Transfer in a STAR-RIS-assisted System
Dec 05, 2023Battery-limited devices and time-sensitive applications are considered as key players in the forthcoming wireless sensor network. Therefore, the main goal of the network is two-fold; Charge battery-limited devices, and provide status updates to users where information-freshness matters. In this paper, a multi-antenna base station (BS) in assistance of simultaneously-transmitting-and-reflecting reconfigurable intelligent surface (STAR-RIS) transmits power to energy-harvesting devices while controlling status update performance at information-users by analyzing age of information (AoI) metric. Therefore, we derive a scheduling policy at BS, and analyze joint transmit beamforming and amplitude-phase optimization at BS and STAR-RIS, respectively, to reduce average sum-AoI for the time-sensitive information-users while satisfying minimum required energy at energy-harvesting users. Moreover, two different energy-splitting and mode switching policies at STAR-RIS are studied. Then, by use of an alternating optimization algorithm, the optimization problem is studied and non-convexity of the problem is tackled by using the successive convex approximation technique. Through numerical results, AoI-metric and energy harvesting requirements of the network are analyzed versus different parameters such as number of antennas at BS, size of STAR-RIS, and transmitted power to highlight how we can improve two fold performance of the system by utilizing STAR-RIS compared to the conventional RIS structure.
Removing Biases from Molecular Representations via Information Maximization
Dec 01, 2023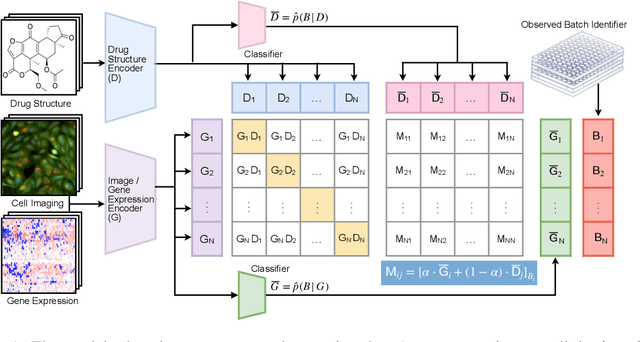
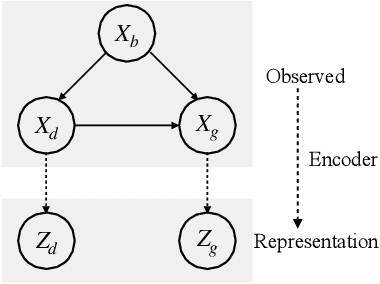
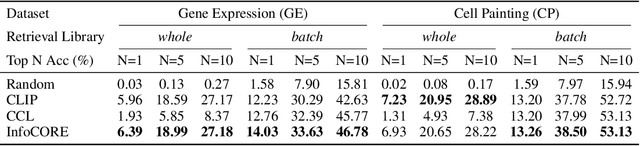
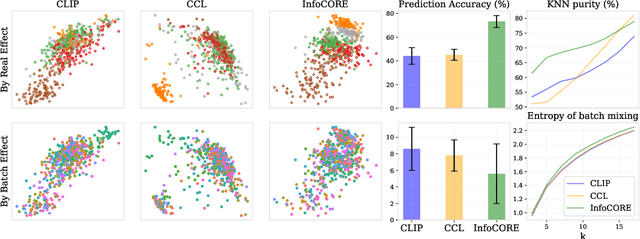
High-throughput drug screening -- using cell imaging or gene expression measurements as readouts of drug effect -- is a critical tool in biotechnology to assess and understand the relationship between the chemical structure and biological activity of a drug. Since large-scale screens have to be divided into multiple experiments, a key difficulty is dealing with batch effects, which can introduce systematic errors and non-biological associations in the data. We propose InfoCORE, an Information maximization approach for COnfounder REmoval, to effectively deal with batch effects and obtain refined molecular representations. InfoCORE establishes a variational lower bound on the conditional mutual information of the latent representations given a batch identifier. It adaptively reweighs samples to equalize their implied batch distribution. Extensive experiments on drug screening data reveal InfoCORE's superior performance in a multitude of tasks including molecular property prediction and molecule-phenotype retrieval. Additionally, we show results for how InfoCORE offers a versatile framework and resolves general distribution shifts and issues of data fairness by minimizing correlation with spurious features or removing sensitive attributes. The code is available at https://github.com/uhlerlab/InfoCORE.
The SemIoE Ontology: A Semantic Model Solution for an IoE-based Industry
Jan 12, 2024Recently, the Industry 5.0 is gaining attention as a novel paradigm, defining the next concrete steps toward more and more intelligent, green-aware and user-centric digital systems. In an era in which smart devices typically adopted in the industry domain are more and more sophisticated and autonomous, the Internet of Things and its evolution, known as the Internet of Everything (IoE, for short), involving also people, robots, processes and data in the network, represent the main driver to allow industries to put the experiences and needs of human beings at the center of their ecosystems. However, due to the extreme heterogeneity of the involved entities, their intrinsic need and capability to cooperate, and the aim to adapt to a dynamic user-centric context, special attention is required for the integration and processing of the data produced by such an IoE. This is the objective of the present paper, in which we propose a novel semantic model that formalizes the fundamental actors, elements and information of an IoE, along with their relationships. In our design, we focus on state-of-the-art design principles, in particular reuse, and abstraction, to build ``SemIoE'', a lightweight ontology inheriting and extending concepts from well-known and consolidated reference ontologies. The defined semantic layer represents a core data model that can be extended to embrace any modern industrial scenario. It represents the base of an IoE Knowledge Graph, on top of which, as an additional contribution, we analyze and define some essential services for an IoE-based industry.
Uncertainty quantification for probabilistic machine learning in earth observation using conformal prediction
Jan 12, 2024Unreliable predictions can occur when using artificial intelligence (AI) systems with negative consequences for downstream applications, particularly when employed for decision-making. Conformal prediction provides a model-agnostic framework for uncertainty quantification that can be applied to any dataset, irrespective of its distribution, post hoc. In contrast to other pixel-level uncertainty quantification methods, conformal prediction operates without requiring access to the underlying model and training dataset, concurrently offering statistically valid and informative prediction regions, all while maintaining computational efficiency. In response to the increased need to report uncertainty alongside point predictions, we bring attention to the promise of conformal prediction within the domain of Earth Observation (EO) applications. To accomplish this, we assess the current state of uncertainty quantification in the EO domain and found that only 20% of the reviewed Google Earth Engine (GEE) datasets incorporated a degree of uncertainty information, with unreliable methods prevalent. Next, we introduce modules that seamlessly integrate into existing GEE predictive modelling workflows and demonstrate the application of these tools for datasets spanning local to global scales, including the Dynamic World and Global Ecosystem Dynamics Investigation (GEDI) datasets. These case studies encompass regression and classification tasks, featuring both traditional and deep learning-based workflows. Subsequently, we discuss the opportunities arising from the use of conformal prediction in EO. We anticipate that the increased availability of easy-to-use implementations of conformal predictors, such as those provided here, will drive wider adoption of rigorous uncertainty quantification in EO, thereby enhancing the reliability of uses such as operational monitoring and decision making.
TOFU: A Task of Fictitious Unlearning for LLMs
Jan 11, 2024Large language models trained on massive corpora of data from the web can memorize and reproduce sensitive or private data raising both legal and ethical concerns. Unlearning, or tuning models to forget information present in their training data, provides us with a way to protect private data after training. Although several methods exist for such unlearning, it is unclear to what extent they result in models equivalent to those where the data to be forgotten was never learned in the first place. To address this challenge, we present TOFU, a Task of Fictitious Unlearning, as a benchmark aimed at helping deepen our understanding of unlearning. We offer a dataset of 200 diverse synthetic author profiles, each consisting of 20 question-answer pairs, and a subset of these profiles called the forget set that serves as the target for unlearning. We compile a suite of metrics that work together to provide a holistic picture of unlearning efficacy. Finally, we provide a set of baseline results from existing unlearning algorithms. Importantly, none of the baselines we consider show effective unlearning motivating continued efforts to develop approaches for unlearning that effectively tune models so that they truly behave as if they were never trained on the forget data at all.