 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Estimating continuous data of wrist joint angles using ultrasound images
Jan 04, 2024
Ultrasound imaging has recently been introduced as a sensing interface for joint motion estimation. The use of ultrasound images as an estimation method is expected to improve the control performance of assistive devices and human--machine interfaces. This study aimed to estimate continuous wrist joint angles using ultrasound images. Specifically, in an experiment, joint angle information was obtained during extension--flexion movements, and ultrasound images of the associated muscles were acquired. Using the features obtained from ultrasound images, a multivariate linear regression model was used to estimate the joint angles. The coordinates of the feature points obtained using optical flow from the ultrasound images were used as explanatory variables of the multivariate linear regression model. The model was trained and tested for each trial by each participant to verify the estimation accuracy. The results show that the mean and standard deviation of the estimation accuracy for all trials were root mean square error (RMSE)=1.82 $\pm$ 0.54 deg and coefficient of determination (R2)=0.985 $\pm$ 0.009. Our method achieves a highly accurate estimation of joint angles compared with previous studies using other signals, such as surface electromyography, while the multivariate linear regression model is simple and both computational and model training costs are low.
Enhancing Zero-Shot Multi-Speaker TTS with Negated Speaker Representations
Jan 04, 2024Zero-shot multi-speaker TTS aims to synthesize speech with the voice of a chosen target speaker without any fine-tuning. Prevailing methods, however, encounter limitations at adapting to new speakers of out-of-domain settings, primarily due to inadequate speaker disentanglement and content leakage. To overcome these constraints, we propose an innovative negation feature learning paradigm that models decoupled speaker attributes as deviations from the complete audio representation by utilizing the subtraction operation. By eliminating superfluous content information from the speaker representation, our negation scheme not only mitigates content leakage, thereby enhancing synthesis robustness, but also improves speaker fidelity. In addition, to facilitate the learning of diverse speaker attributes, we leverage multi-stream Transformers, which retain multiple hypotheses and instigate a training paradigm akin to ensemble learning. To unify these hypotheses and realize the final speaker representation, we employ attention pooling. Finally, in light of the imperative to generate target text utterances in the desired voice, we adopt adaptive layer normalizations to effectively fuse the previously generated speaker representation with the target text representations, as opposed to mere concatenation of the text and audio modalities. Extensive experiments and validations substantiate the efficacy of our proposed approach in preserving and harnessing speaker-specific attributes vis-`a-vis alternative baseline models.
A-Scan2BIM: Assistive Scan to Building Information Modeling
Nov 30, 2023This paper proposes an assistive system for architects that converts a large-scale point cloud into a standardized digital representation of a building for Building Information Modeling (BIM) applications. The process is known as Scan-to-BIM, which requires many hours of manual work even for a single building floor by a professional architect. Given its challenging nature, the paper focuses on helping architects on the Scan-to-BIM process, instead of replacing them. Concretely, we propose an assistive Scan-to-BIM system that takes the raw sensor data and edit history (including the current BIM model), then auto-regressively predicts a sequence of model editing operations as APIs of a professional BIM software (i.e., Autodesk Revit). The paper also presents the first building-scale Scan2BIM dataset that contains a sequence of model editing operations as the APIs of Autodesk Revit. The dataset contains 89 hours of Scan2BIM modeling processes by professional architects over 16 scenes, spanning over 35,000 m^2. We report our system's reconstruction quality with standard metrics, and we introduce a novel metric that measures how natural the order of reconstructed operations is. A simple modification to the reconstruction module helps improve performance, and our method is far superior to two other baselines in the order metric. We will release data, code, and models at a-scan2bim.github.io.
Mirror: A Universal Framework for Various Information Extraction Tasks
Nov 26, 2023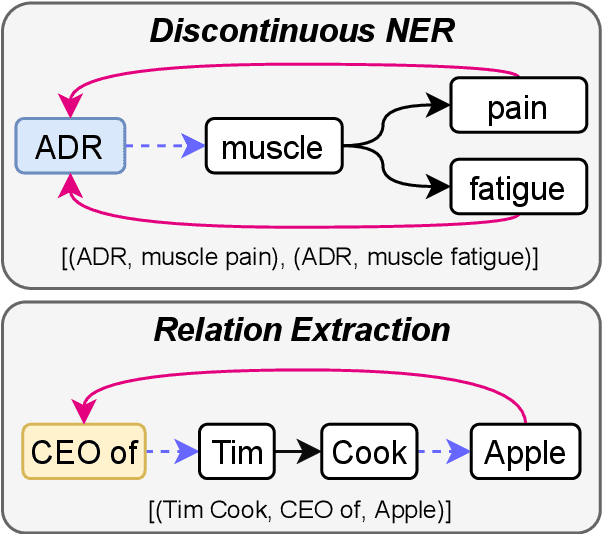
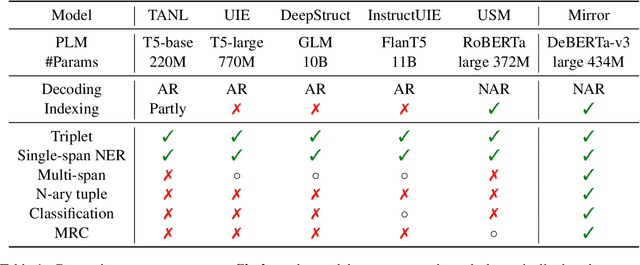
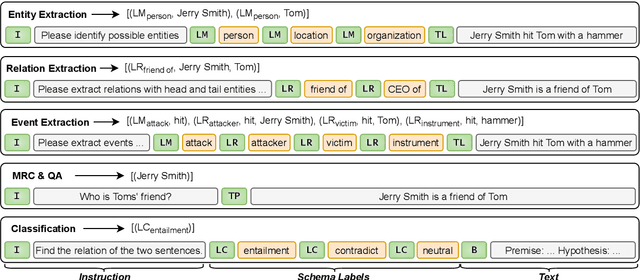
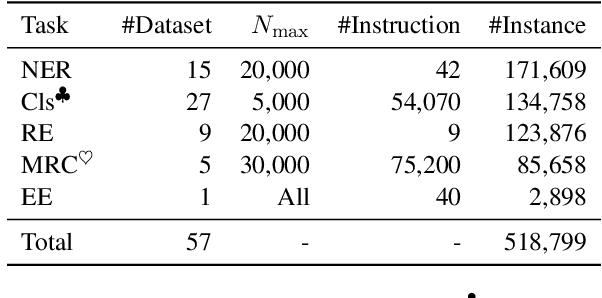
Sharing knowledge between information extraction tasks has always been a challenge due to the diverse data formats and task variations. Meanwhile, this divergence leads to information waste and increases difficulties in building complex applications in real scenarios. Recent studies often formulate IE tasks as a triplet extraction problem. However, such a paradigm does not support multi-span and n-ary extraction, leading to weak versatility. To this end, we reorganize IE problems into unified multi-slot tuples and propose a universal framework for various IE tasks, namely Mirror. Specifically, we recast existing IE tasks as a multi-span cyclic graph extraction problem and devise a non-autoregressive graph decoding algorithm to extract all spans in a single step. It is worth noting that this graph structure is incredibly versatile, and it supports not only complex IE tasks, but also machine reading comprehension and classification tasks. We manually construct a corpus containing 57 datasets for model pretraining, and conduct experiments on 30 datasets across 8 downstream tasks. The experimental results demonstrate that our model has decent compatibility and outperforms or reaches competitive performance with SOTA systems under few-shot and zero-shot settings. The code, model weights, and pretraining corpus are available at https://github.com/Spico197/Mirror .
Cross-Scope Spatial-Spectral Information Aggregation for Hyperspectral Image Super-Resolution
Nov 29, 2023Hyperspectral image super-resolution has attained widespread prominence to enhance the spatial resolution of hyperspectral images. However, convolution-based methods have encountered challenges in harnessing the global spatial-spectral information. The prevailing transformer-based methods have not adequately captured the long-range dependencies in both spectral and spatial dimensions. To alleviate this issue, we propose a novel cross-scope spatial-spectral Transformer (CST) to efficiently investigate long-range spatial and spectral similarities for single hyperspectral image super-resolution. Specifically, we devise cross-attention mechanisms in spatial and spectral dimensions to comprehensively model the long-range spatial-spectral characteristics. By integrating global information into the rectangle-window self-attention, we first design a cross-scope spatial self-attention to facilitate long-range spatial interactions. Then, by leveraging appropriately characteristic spatial-spectral features, we construct a cross-scope spectral self-attention to effectively capture the intrinsic correlations among global spectral bands. Finally, we elaborate a concise feed-forward neural network to enhance the feature representation capacity in the Transformer structure. Extensive experiments over three hyperspectral datasets demonstrate that the proposed CST is superior to other state-of-the-art methods both quantitatively and visually. The code is available at \url{https://github.com/Tomchenshi/CST.git}.
An Autoregressive Text-to-Graph Framework for Joint Entity and Relation Extraction
Jan 02, 2024In this paper, we propose a novel method for joint entity and relation extraction from unstructured text by framing it as a conditional sequence generation problem. In contrast to conventional generative information extraction models that are left-to-right token-level generators, our approach is \textit{span-based}. It generates a linearized graph where nodes represent text spans and edges represent relation triplets. Our method employs a transformer encoder-decoder architecture with pointing mechanism on a dynamic vocabulary of spans and relation types. Our model can capture the structural characteristics and boundaries of entities and relations through span representations while simultaneously grounding the generated output in the original text thanks to the pointing mechanism. Evaluation on benchmark datasets validates the effectiveness of our approach, demonstrating competitive results. Code is available at https://github.com/urchade/ATG.
Active Third-Person Imitation Learning
Dec 27, 2023We consider the problem of third-person imitation learning with the additional challenge that the learner must select the perspective from which they observe the expert. In our setting, each perspective provides only limited information about the expert's behavior, and the learning agent must carefully select and combine information from different perspectives to achieve competitive performance. This setting is inspired by real-world imitation learning applications, e.g., in robotics, a robot might observe a human demonstrator via camera and receive information from different perspectives depending on the camera's position. We formalize the aforementioned active third-person imitation learning problem, theoretically analyze its characteristics, and propose a generative adversarial network-based active learning approach. Empirically, we demstrate that our proposed approach can effectively learn from expert demonstrations and explore the importance of different architectural choices for the learner's performance.
Integrating Chemical Language and Molecular Graph in Multimodal Fused Deep Learning for Drug Property Prediction
Dec 29, 2023Accurately predicting molecular properties is a challenging but essential task in drug discovery. Recently, many mono-modal deep learning methods have been successfully applied to molecular property prediction. However, the inherent limitation of mono-modal learning arises from relying solely on one modality of molecular representation, which restricts a comprehensive understanding of drug molecules and hampers their resilience against data noise. To overcome the limitations, we construct multimodal deep learning models to cover different molecular representations. We convert drug molecules into three molecular representations, SMILES-encoded vectors, ECFP fingerprints, and molecular graphs. To process the modal information, Transformer-Encoder, bi-directional gated recurrent units (BiGRU), and graph convolutional network (GCN) are utilized for feature learning respectively, which can enhance the model capability to acquire complementary and naturally occurring bioinformatics information. We evaluated our triple-modal model on six molecule datasets. Different from bi-modal learning models, we adopt five fusion methods to capture the specific features and leverage the contribution of each modal information better. Compared with mono-modal models, our multimodal fused deep learning (MMFDL) models outperform single models in accuracy, reliability, and resistance capability against noise. Moreover, we demonstrate its generalization ability in the prediction of binding constants for protein-ligand complex molecules in the refined set of PDBbind. The advantage of the multimodal model lies in its ability to process diverse sources of data using proper models and suitable fusion methods, which would enhance the noise resistance of the model while obtaining data diversity.
FlexSSL : A Generic and Efficient Framework for Semi-Supervised Learning
Dec 28, 2023Semi-supervised learning holds great promise for many real-world applications, due to its ability to leverage both unlabeled and expensive labeled data. However, most semi-supervised learning algorithms still heavily rely on the limited labeled data to infer and utilize the hidden information from unlabeled data. We note that any semi-supervised learning task under the self-training paradigm also hides an auxiliary task of discriminating label observability. Jointly solving these two tasks allows full utilization of information from both labeled and unlabeled data, thus alleviating the problem of over-reliance on labeled data. This naturally leads to a new generic and efficient learning framework without the reliance on any domain-specific information, which we call FlexSSL. The key idea of FlexSSL is to construct a semi-cooperative "game", which forges cooperation between a main self-interested semi-supervised learning task and a companion task that infers label observability to facilitate main task training. We show with theoretical derivation of its connection to loss re-weighting on noisy labels. Through evaluations on a diverse range of tasks, we demonstrate that FlexSSL can consistently enhance the performance of semi-supervised learning algorithms.
Joint Channel Estimation and Data Recovery for Millimeter Massive MIMO: Using Pilot to Capture Principal Components
Jan 03, 2024Channel state information (CSI) is important to reap the full benefits of millimeter wave (mmWave) massive multiple-input multiple-output (MIMO) systems. The traditional channel estimation methods using pilot frames (PF) lead to excessive overhead. To reduce the demand for PF, data frames (DF) can be adopted for joint channel estimation and data recovery. However, the computational complexity of the DF-based methods is prohibitively high. To reduce the computational complexity, we propose a joint channel estimation and data recovery (JCD) method assisted by a small number of PF for mmWave massive MIMO systems. The proposed method has two stages. In Stage 1, differing from the traditional PF-based methods, the proposed PF-assisted method is utilized to capture the angle of arrival (AoA) of principal components (PC) of channels. In Stage 2, JCD is designed for parallel implementation based on the multi-user decoupling strategy. The theoretical analysis demonstrates that the PF-assisted JCD method can achieve equivalent performance to the Bayesian-optimal DF-based method, while greatly reducing the computational complexity. Simulation results are also presented to validate the analytical results.