 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Aligned with LLM: a new multi-modal training paradigm for encoding fMRI activity in visual cortex
Jan 08, 2024
Recently, there has been a surge in the popularity of pre trained large language models (LLMs) (such as GPT-4), sweeping across the entire Natural Language Processing (NLP) and Computer Vision (CV) communities. These LLMs have demonstrated advanced multi-modal understanding capabilities and showcased strong performance across various benchmarks. The LLM has started to embody traits of artificial general intelligence, which holds vital guidance for enhancing brain-like characteristics within visual encoding models. Hence, This paper proposes a new multi-modal training paradigm, aligning with LLM, for encoding fMRI activity in visual cortex. Based on this paradigm, we trained an encoding model in fMRI data named the LLM-Visual Encoding Model (LLM-VEM). Specifically, we utilize LLM (miniGPT4) to generate descriptive text for all stimulus images, forming a high-quality textual description set. Moreover, we use the pre-trained text encoder (CLIP) to process these detailed descriptions, obtaining the text embedding features. Next, we use the contrast loss function to minimize the distance between the image embedding features and the text embedding features to complete the alignment operation of the stimulus image and text information. With the assistance of the pre-trained LLM, this alignment process facilitates better learning of the visual encoding model, resulting in higher precision. The final experimental results indicate that our training paradigm has significantly aided in enhancing the performance of the visual encoding model.
Inverse-like Antagonistic Scene Text Spotting via Reading-Order Estimation and Dynamic Sampling
Jan 08, 2024Scene text spotting is a challenging task, especially for inverse-like scene text, which has complex layouts, e.g., mirrored, symmetrical, or retro-flexed. In this paper, we propose a unified end-to-end trainable inverse-like antagonistic text spotting framework dubbed IATS, which can effectively spot inverse-like scene texts without sacrificing general ones. Specifically, we propose an innovative reading-order estimation module (REM) that extracts reading-order information from the initial text boundary generated by an initial boundary module (IBM). To optimize and train REM, we propose a joint reading-order estimation loss consisting of a classification loss, an orthogonality loss, and a distribution loss. With the help of IBM, we can divide the initial text boundary into two symmetric control points and iteratively refine the new text boundary using a lightweight boundary refinement module (BRM) for adapting to various shapes and scales. To alleviate the incompatibility between text detection and recognition, we propose a dynamic sampling module (DSM) with a thin-plate spline that can dynamically sample appropriate features for recognition in the detected text region. Without extra supervision, the DSM can proactively learn to sample appropriate features for text recognition through the gradient returned by the recognition module. Extensive experiments on both challenging scene text and inverse-like scene text datasets demonstrate that our method achieves superior performance both on irregular and inverse-like text spotting.
Bringing Back the Context: Camera Trap Species Identification as Link Prediction on Multimodal Knowledge Graphs
Jan 08, 2024Camera traps are valuable tools in animal ecology for biodiversity monitoring and conservation. However, challenges like poor generalization to deployment at new unseen locations limit their practical application. Images are naturally associated with heterogeneous forms of context possibly in different modalities. In this work, we leverage the structured context associated with the camera trap images to improve out-of-distribution generalization for the task of species identification in camera traps. For example, a photo of a wild animal may be associated with information about where and when it was taken, as well as structured biology knowledge about the animal species. While typically overlooked by existing work, bringing back such context offers several potential benefits for better image understanding, such as addressing data scarcity and enhancing generalization. However, effectively integrating such heterogeneous context into the visual domain is a challenging problem. To address this, we propose a novel framework that reformulates species classification as link prediction in a multimodal knowledge graph (KG). This framework seamlessly integrates various forms of multimodal context for visual recognition. We apply this framework for out-of-distribution species classification on the iWildCam2020-WILDS and Snapshot Mountain Zebra datasets and achieve competitive performance with state-of-the-art approaches. Furthermore, our framework successfully incorporates biological taxonomy for improved generalization and enhances sample efficiency for recognizing under-represented species.
Expand BERT Representation with Visual Information via Grounded Language Learning with Multimodal Partial Alignment
Dec 04, 2023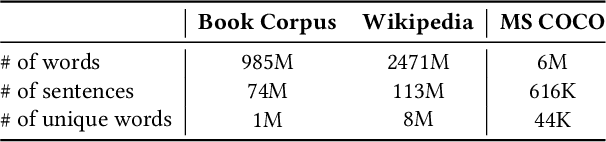

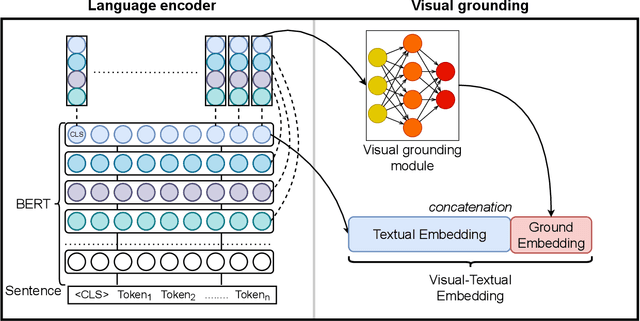
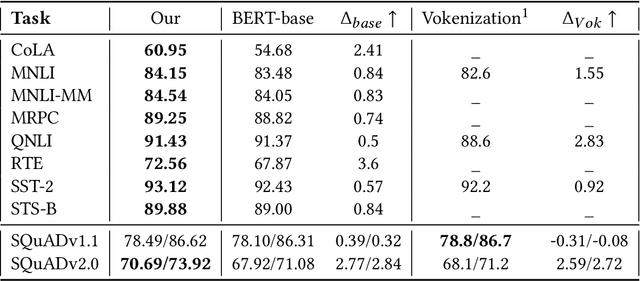
Language models have been supervised with both language-only objective and visual grounding in existing studies of visual-grounded language learning. However, due to differences in the distribution and scale of visual-grounded datasets and language corpora, the language model tends to mix up the context of the tokens that occurred in the grounded data with those that do not. As a result, during representation learning, there is a mismatch between the visual information and the contextual meaning of the sentence. To overcome this limitation, we propose GroundedBERT - a grounded language learning method that enhances the BERT representation with visually grounded information. GroundedBERT comprises two components: (i) the original BERT which captures the contextual representation of words learned from the language corpora, and (ii) a visual grounding module which captures visual information learned from visual-grounded datasets. Moreover, we employ Optimal Transport (OT), specifically its partial variant, to solve the fractional alignment problem between the two modalities. Our proposed method significantly outperforms the baseline language models on various language tasks of the GLUE and SQuAD datasets.
Phase-shifted remote photoplethysmography for estimating heart rate and blood pressure from facial video
Jan 09, 2024Human health can be critically affected by cardiovascular diseases, such as hypertension, arrhythmias, and stroke. Heart rate and blood pressure are important biometric information for the monitoring of cardiovascular system and early diagnosis of cardiovascular diseases. Existing methods for estimating the heart rate are based on electrocardiography and photoplethyomography, which require contacting the sensor to the skin surface. Moreover, catheter and cuff-based methods for measuring blood pressure cause inconvenience and have limited applicability. Therefore, in this thesis, we propose a vision-based method for estimating the heart rate and blood pressure. This thesis proposes a 2-stage deep learning framework consisting of a dual remote photoplethysmography network (DRP-Net) and bounded blood pressure network (BBP-Net). In the first stage, DRP-Net infers remote photoplethysmography (rPPG) signals for the acral and facial regions, and these phase-shifted rPPG signals are utilized to estimate the heart rate. In the second stage, BBP-Net integrates temporal features and analyzes phase discrepancy between the acral and facial rPPG signals to estimate SBP and DBP values. To improve the accuracy of estimating the heart rate, we employed a data augmentation method based on a frame interpolation model. Moreover, we designed BBP-Net to infer blood pressure within a predefined range by incorporating a scaled sigmoid function. Our method resulted in estimating the heart rate with the mean absolute error (MAE) of 1.78 BPM, reducing the MAE by 34.31 % compared to the recent method, on the MMSE-HR dataset. The MAE for estimating the systolic blood pressure (SBP) and diastolic blood pressure (DBP) were 10.19 mmHg and 7.09 mmHg. On the V4V dataset, the MAE for the heart rate, SBP, and DBP were 3.83 BPM, 13.64 mmHg, and 9.4 mmHg, respectively.
Tensor Networks for Explainable Machine Learning in Cybersecurity
Jan 05, 2024In this paper we show how tensor networks help in developing explainability of machine learning algorithms. Specifically, we develop an unsupervised clustering algorithm based on Matrix Product States (MPS) and apply it in the context of a real use-case of adversary-generated threat intelligence. Our investigation proves that MPS rival traditional deep learning models such as autoencoders and GANs in terms of performance, while providing much richer model interpretability. Our approach naturally facilitates the extraction of feature-wise probabilities, Von Neumann Entropy, and mutual information, offering a compelling narrative for classification of anomalies and fostering an unprecedented level of transparency and interpretability, something fundamental to understand the rationale behind artificial intelligence decisions.
Perceptual Image Compression with Cooperative Cross-Modal Side Information
Nov 28, 2023The explosion of data has resulted in more and more associated text being transmitted along with images. Inspired by from distributed source coding, many works utilize image side information to enhance image compression. However, existing methods generally do not consider using text as side information to enhance perceptual compression of images, even though the benefits of multimodal synergy have been widely demonstrated in research. This begs the following question: How can we effectively transfer text-level semantic dependencies to help image compression, which is only available to the decoder? In this work, we propose a novel deep image compression method with text-guided side information to achieve a better rate-perception-distortion tradeoff. Specifically, we employ the CLIP text encoder and an effective Semantic-Spatial Aware block to fuse the text and image features. This is done by predicting a semantic mask to guide the learned text-adaptive affine transformation at the pixel level. Furthermore, we design a text-conditional generative adversarial networks to improve the perceptual quality of reconstructed images. Extensive experiments involving four datasets and ten image quality assessment metrics demonstrate that the proposed approach achieves superior results in terms of rate-perception trade-off and semantic distortion.
Uncertainty Resolution in Misinformation Detection
Jan 02, 2024Misinformation poses a variety of risks, such as undermining public trust and distorting factual discourse. Large Language Models (LLMs) like GPT-4 have been shown effective in mitigating misinformation, particularly in handling statements where enough context is provided. However, they struggle to assess ambiguous or context-deficient statements accurately. This work introduces a new method to resolve uncertainty in such statements. We propose a framework to categorize missing information and publish category labels for the LIAR-New dataset, which is adaptable to cross-domain content with missing information. We then leverage this framework to generate effective user queries for missing context. Compared to baselines, our method improves the rate at which generated questions are answerable by the user by 38 percentage points and classification performance by over 10 percentage points macro F1. Thus, this approach may provide a valuable component for future misinformation mitigation pipelines.
Navigating Uncertainty: Optimizing API Dependency for Hallucination Reduction in Closed-Book Question Answering
Jan 03, 2024While Large Language Models (LLM) are able to accumulate and restore knowledge, they are still prone to hallucination. Especially when faced with factual questions, LLM cannot only rely on knowledge stored in parameters to guarantee truthful and correct answers. Augmenting these models with the ability to search on external information sources, such as the web, is a promising approach to ground knowledge to retrieve information. However, searching in a large collection of documents introduces additional computational/time costs. An optimal behavior would be to query external resources only when the LLM is not confident about answers. In this paper, we propose a new LLM able to self-estimate if it is able to answer directly or needs to request an external tool. We investigate a supervised approach by introducing a hallucination masking mechanism in which labels are generated using a close book question-answering task. In addition, we propose to leverage parameter-efficient fine-tuning techniques to train our model on a small amount of data. Our model directly provides answers for $78.2\%$ of the known queries and opts to search for $77.2\%$ of the unknown ones. This results in the API being utilized only $62\%$ of the time.
STAF: 3D Human Mesh Recovery from Video with Spatio-Temporal Alignment Fusion
Jan 03, 2024The recovery of 3D human mesh from monocular images has significantly been developed in recent years. However, existing models usually ignore spatial and temporal information, which might lead to mesh and image misalignment and temporal discontinuity. For this reason, we propose a novel Spatio-Temporal Alignment Fusion (STAF) model. As a video-based model, it leverages coherence clues from human motion by an attention-based Temporal Coherence Fusion Module (TCFM). As for spatial mesh-alignment evidence, we extract fine-grained local information through predicted mesh projection on the feature maps. Based on the spatial features, we further introduce a multi-stage adjacent Spatial Alignment Fusion Module (SAFM) to enhance the feature representation of the target frame. In addition to the above, we propose an Average Pooling Module (APM) to allow the model to focus on the entire input sequence rather than just the target frame. This method can remarkably improve the smoothness of recovery results from video. Extensive experiments on 3DPW, MPII3D, and H36M demonstrate the superiority of STAF. We achieve a state-of-the-art trade-off between precision and smoothness. Our code and more video results are on the project page https://yw0208.github.io/staf/