 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CodePrompt: Improving Source Code-Related Classification with Knowledge Features through Prompt Learning
Jan 10, 2024
Researchers have explored the potential of utilizing pre-trained language models, such as CodeBERT, to improve source code-related tasks. Previous studies have mainly relied on CodeBERT's text embedding capability and the `[CLS]' sentence embedding information as semantic representations for fine-tuning downstream source code-related tasks. However, these methods require additional neural network layers to extract effective features, resulting in higher computational costs. Furthermore, existing approaches have not leveraged the rich knowledge contained in both source code and related text, which can lead to lower accuracy. This paper presents a novel approach, CodePrompt, which utilizes rich knowledge recalled from a pre-trained model by prompt learning and an attention mechanism to improve source code-related classification tasks. Our approach initially motivates the language model with prompt information to retrieve abundant knowledge associated with the input as representative features, thus avoiding the need for additional neural network layers and reducing computational costs. Subsequently, we employ an attention mechanism to aggregate multiple layers of related knowledge for each task as final features to boost their accuracy. We conducted extensive experiments on four downstream source code-related tasks to evaluate our approach and our results demonstrate that CodePrompt achieves new state-of-the-art performance on the accuracy metric while also exhibiting computation cost-saving capabilities.
Multi S-Graphs: an Efficient Real-time Distributed Semantic-Relational Collaborative SLAM
Jan 10, 2024Collaborative Simultaneous Localization and Mapping (CSLAM) is critical to enable multiple robots to operate in complex environments. Most CSLAM techniques rely on raw sensor measurement or low-level features such as keyframe descriptors, which can lead to wrong loop closures due to the lack of deep understanding of the environment. Moreover, the exchange of these measurements and low-level features among the robots requires the transmission of a significant amount of data, which limits the scalability of the system. To overcome these limitations, we present Multi S-Graphs, a decentralized CSLAM system that utilizes high-level semantic-relational information embedded in the four-layered hierarchical and optimizable situational graphs for cooperative map generation and localization while minimizing the information exchanged between the robots. To support this, we present a novel room-based descriptor which, along with its connected walls, is used to perform inter-robot loop closures, addressing the challenges of multi-robot kidnapped problem initialization. Multiple experiments in simulated and real environments validate the improvement in accuracy and robustness of the proposed approach while reducing the amount of data exchanged between robots compared to other state-of-the-art approaches. Software available within a docker image: https://github.com/snt-arg/multi_s_graphs_docker
MapGPT: Map-Guided Prompting for Unified Vision-and-Language Navigation
Jan 14, 2024Embodied agents equipped with GPT as their brain have exhibited extraordinary thinking and decision-making abilities across various tasks. However, existing zero-shot agents for vision-and-language navigation (VLN) only prompt the GPT to handle excessive environmental information and select potential locations within localized environments, without constructing an effective ''global-view'' (e.g., a commonly-used map) for the agent to understand the overall environment. In this work, we present a novel map-guided GPT-based path-planning agent, dubbed MapGPT, for the zero-shot VLN task. Specifically, we convert a topological map constructed online into prompts to encourage map-guided global exploration, and require the agent to explicitly output and update multi-step path planning to avoid getting stuck in local exploration. Extensive experiments demonstrate that our MapGPT is effective, achieving impressive performance on both the R2R and REVERIE datasets (38.8% and 28.4% success rate, respectively) and showcasing the newly emerged global thinking and path planning capabilities of the GPT model. Unlike previous VLN agents, which require separate parameters fine-tuning or specific prompt design to accommodate various instruction styles across different datasets, our MapGPT is more unified as it can adapt to different instruction styles seamlessly, which is the first of its kind in this field.
Diagnosing epilepsy using entropy measures and embedding parameters of EEG signals
Jan 14, 2024Epilepsy is a neurological disorder that affects normal neural activity. These electrical activities can be recorded as signals containing information about the brain known as Electroencephalography (EEG) signals. Analysis of the EEG signals by individuals for epilepsy diagnosis is subjective and time-consuming. So, an automatic classification system with high detection accuracy is required to overcome possible errors. In this study, the discrete wavelet transform has been applied to EEG signals. Then, entropy measures and embedding parameters have been extracted. These features have been investigated individually to find the most discriminating ones. The significance level of each feature was evaluated by statistical analysis. Consequently, LDA and SVM algorithms have been employed to categorize the EEG signals. The results have indicated that the features of Embedding parameters, PermutationEntropy, FuzzyEntropy, SampleEntropy, NormEntropy, SureEntropy, LogEntropy, and ThresholdEntropy have the potential to discriminate epileptic patients from healthy subjects significantly. Also, SVM classifier has achieved the highest classification accuracy. In this study, we could find effective embedding-based and entropy-based features as appropriate single measures for identifying abnormal activities that can efficiently discriminate the EEG signals of epileptics from healthy individuals. According to the results, they can be used for automatic classification of epileptic EEG signals that are difficult to examine visually.
The Effects of Data Imbalance Under a Federated Learning Approach for Credit Risk Forecasting
Jan 14, 2024Credit risk forecasting plays a crucial role for commercial banks and other financial institutions in granting loans to customers and minimise the potential loss. However, traditional machine learning methods require the sharing of sensitive client information with an external server to build a global model, potentially posing a risk of security threats and privacy leakage. A newly developed privacy-preserving distributed machine learning technique known as Federated Learning (FL) allows the training of a global model without the necessity of accessing private local data directly. This investigation examined the feasibility of federated learning in credit risk assessment and showed the effects of data imbalance on model performance. Two neural network architectures, Multilayer Perceptron (MLP) and Long Short-Term Memory (LSTM), and one tree ensemble architecture, Extreme Gradient Boosting (XGBoost), were explored across three different datasets under various scenarios involving different numbers of clients and data distribution configurations. We demonstrate that federated models consistently outperform local models on non-dominant clients with smaller datasets. This trend is especially pronounced in highly imbalanced data scenarios, yielding a remarkable average improvement of 17.92% in model performance. However, for dominant clients (clients with more data), federated models may not exhibit superior performance, suggesting the need for special incentives for this type of clients to encourage their participation.
A Sparse Cross Attention-based Graph Convolution Network with Auxiliary Information Awareness for Traffic Flow Prediction
Dec 14, 2023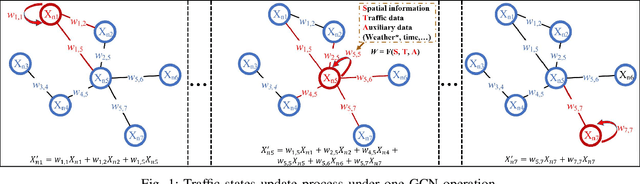
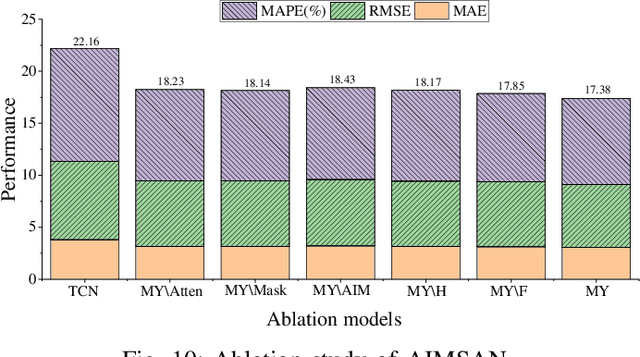
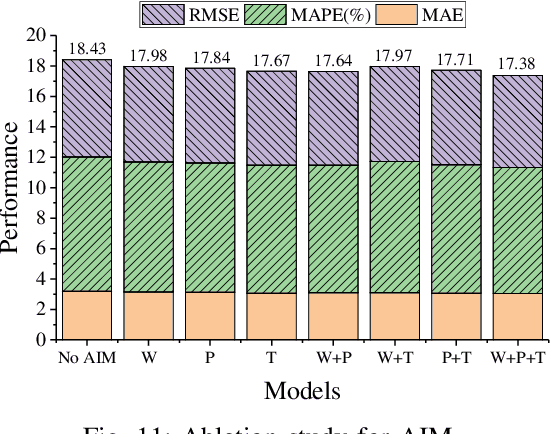
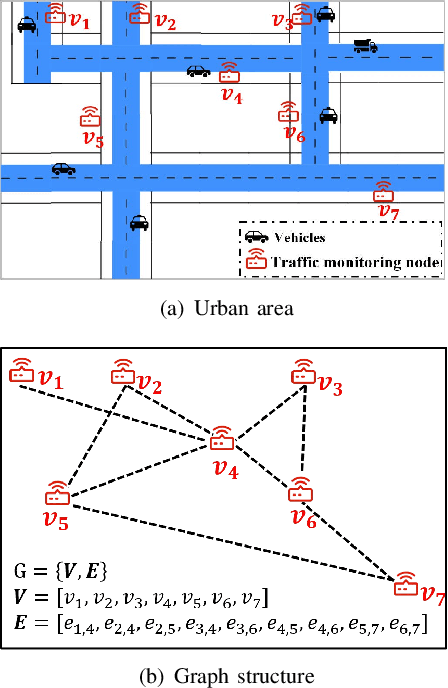
Deep graph convolution networks (GCNs) have recently shown excellent performance in traffic prediction tasks. However, they face some challenges. First, few existing models consider the influence of auxiliary information, i.e., weather and holidays, which may result in a poor grasp of spatial-temporal dynamics of traffic data. Second, both the construction of a dynamic adjacent matrix and regular graph convolution operations have quadratic computation complexity, which restricts the scalability of GCN-based models. To address such challenges, this work proposes a deep encoder-decoder model entitled AIMSAN. It contains an auxiliary information-aware module (AIM) and sparse cross attention-based graph convolution network (SAN). The former learns multi-attribute auxiliary information and obtains its embedded presentation of different time-window sizes. The latter uses a cross-attention mechanism to construct dynamic adjacent matrices by fusing traffic data and embedded auxiliary data. Then, SAN applies diffusion GCN on traffic data to mine rich spatial-temporal dynamics. Furthermore, AIMSAN considers and uses the spatial sparseness of traffic nodes to reduce the quadratic computation complexity. Experimental results on three public traffic datasets demonstrate that the proposed method outperforms other counterparts in terms of various performance indices. Specifically, the proposed method has competitive performance with the state-of-the-art algorithms but saves 35.74% of GPU memory usage, 42.25% of training time, and 45.51% of validation time on average.
FunnyNet-W: Multimodal Learning of Funny Moments in Videos in the Wild
Jan 08, 2024Automatically understanding funny moments (i.e., the moments that make people laugh) when watching comedy is challenging, as they relate to various features, such as body language, dialogues and culture. In this paper, we propose FunnyNet-W, a model that relies on cross- and self-attention for visual, audio and text data to predict funny moments in videos. Unlike most methods that rely on ground truth data in the form of subtitles, in this work we exploit modalities that come naturally with videos: (a) video frames as they contain visual information indispensable for scene understanding, (b) audio as it contains higher-level cues associated with funny moments, such as intonation, pitch and pauses and (c) text automatically extracted with a speech-to-text model as it can provide rich information when processed by a Large Language Model. To acquire labels for training, we propose an unsupervised approach that spots and labels funny audio moments. We provide experiments on five datasets: the sitcoms TBBT, MHD, MUStARD, Friends, and the TED talk UR-Funny. Extensive experiments and analysis show that FunnyNet-W successfully exploits visual, auditory and textual cues to identify funny moments, while our findings reveal FunnyNet-W's ability to predict funny moments in the wild. FunnyNet-W sets the new state of the art for funny moment detection with multimodal cues on all datasets with and without using ground truth information.
LLMRS: Unlocking Potentials of LLM-Based Recommender Systems for Software Purchase
Jan 12, 2024Recommendation systems are ubiquitous, from Spotify playlist suggestions to Amazon product suggestions. Nevertheless, depending on the methodology or the dataset, these systems typically fail to capture user preferences and generate general recommendations. Recent advancements in Large Language Models (LLM) offer promising results for analyzing user queries. However, employing these models to capture user preferences and efficiency remains an open question. In this paper, we propose LLMRS, an LLM-based zero-shot recommender system where we employ pre-trained LLM to encode user reviews into a review score and generate user-tailored recommendations. We experimented with LLMRS on a real-world dataset, the Amazon product reviews, for software purchase use cases. The results show that LLMRS outperforms the ranking-based baseline model while successfully capturing meaningful information from product reviews, thereby providing more reliable recommendations.
Deep Neural Network Solutions for Oscillatory Fredholm Integral Equations
Jan 13, 2024We studied the use of deep neural networks (DNNs) in the numerical solution of the oscillatory Fredholm integral equation of the second kind. It is known that the solution of the equation exhibits certain oscillatory behaviors due to the oscillation of the kernel. It was pointed out recently that standard DNNs favour low frequency functions, and as a result, they often produce poor approximation for functions containing high frequency components. We addressed this issue in this study. We first developed a numerical method for solving the equation with DNNs as an approximate solution by designing a numerical quadrature that tailors to computing oscillatory integrals involving DNNs. We proved that the error of the DNN approximate solution of the equation is bounded by the training loss and the quadrature error. We then proposed a multi-grade deep learning (MGDL) model to overcome the spectral bias issue of neural networks. Numerical experiments demonstrate that the MGDL model is effective in extracting multiscale information of the oscillatory solution and overcoming the spectral bias issue from which a standard DNN model suffers.
Contrastive Learning with Negative Sampling Correction
Jan 13, 2024As one of the most effective self-supervised representation learning methods, contrastive learning (CL) relies on multiple negative pairs to contrast against each positive pair. In the standard practice of contrastive learning, data augmentation methods are utilized to generate both positive and negative pairs. While existing works have been focusing on improving the positive sampling, the negative sampling process is often overlooked. In fact, the generated negative samples are often polluted by positive samples, which leads to a biased loss and performance degradation. To correct the negative sampling bias, we propose a novel contrastive learning method named Positive-Unlabeled Contrastive Learning (PUCL). PUCL treats the generated negative samples as unlabeled samples and uses information from positive samples to correct bias in contrastive loss. We prove that the corrected loss used in PUCL only incurs a negligible bias compared to the unbiased contrastive loss. PUCL can be applied to general contrastive learning problems and outperforms state-of-the-art methods on various image and graph classification tasks. The code of PUCL is in the supplementary file.