 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Graph Language Models
Jan 13, 2024
While Language Models have become workhorses for NLP, their interplay with textual knowledge graphs (KGs) - structured memories of general or domain knowledge - is actively researched. Current embedding methodologies for such graphs typically either (i) linearize graphs for embedding them using sequential Language Models (LMs), which underutilize structural information, or (ii) use Graph Neural Networks (GNNs) to preserve graph structure, while GNNs cannot represent textual features as well as a pre-trained LM could. In this work we introduce a novel language model, the Graph Language Model (GLM), that integrates the strengths of both approaches, while mitigating their weaknesses. The GLM parameters are initialized from a pretrained LM, to facilitate nuanced understanding of individual concepts and triplets. Simultaneously, its architectural design incorporates graph biases, thereby promoting effective knowledge distribution within the graph. Empirical evaluations on relation classification tasks on ConceptNet subgraphs reveal that GLM embeddings surpass both LM- and GNN-based baselines in supervised and zero-shot settings.
TemporalAugmenter: An Ensemble Recurrent Based Deep Learning Approach for Signal Classification
Jan 13, 2024Ensemble modeling has been widely used to solve complex problems as it helps to improve overall performance and generalization. In this paper, we propose a novel TemporalAugmenter approach based on ensemble modeling for augmenting the temporal information capturing for long-term and short-term dependencies in data integration of two variations of recurrent neural networks in two learning streams to obtain the maximum possible temporal extraction. Thus, the proposed model augments the extraction of temporal dependencies. In addition, the proposed approach reduces the preprocessing and prior stages of feature extraction, which reduces the required energy to process the models built upon the proposed TemporalAugmenter approach, contributing towards green AI. Moreover, the proposed model can be simply integrated into various domains including industrial, medical, and human-computer interaction applications. Our proposed approach empirically evaluated the speech emotion recognition, electrocardiogram signal, and signal quality examination tasks as three different signals with varying complexity and different temporal dependency features.
Progressive Feature Fusion Network for Enhancing Image Quality Assessment
Jan 13, 2024Image compression has been applied in the fields of image storage and video broadcasting. However, it's formidably tough to distinguish the subtle quality differences between those distorted images generated by different algorithms. In this paper, we propose a new image quality assessment framework to decide which image is better in an image group. To capture the subtle differences, a fine-grained network is adopted to acquire multi-scale features. Subsequently, we design a cross subtract block for separating and gathering the information within positive and negative image pairs. Enabling image comparison in feature space. After that, a progressive feature fusion block is designed, which fuses multi-scale features in a novel progressive way. Hierarchical spatial 2D features can thus be processed gradually. Experimental results show that compared with the current mainstream image quality assessment methods, the proposed network can achieve more accurate image quality assessment and ranks second in the benchmark of CLIC in the image perceptual model track.
A Visually Attentive Splice Localization Network with Multi-Domain Feature Extractor and Multi-Receptive Field Upsampler
Jan 13, 2024Image splice manipulation presents a severe challenge in today's society. With easy access to image manipulation tools, it is easier than ever to modify images that can mislead individuals, organizations or society. In this work, a novel, "Visually Attentive Splice Localization Network with Multi-Domain Feature Extractor and Multi-Receptive Field Upsampler" has been proposed. It contains a unique "visually attentive multi-domain feature extractor" (VA-MDFE) that extracts attentional features from the RGB, edge and depth domains. Next, a "visually attentive downsampler" (VA-DS) is responsible for fusing and downsampling the multi-domain features. Finally, a novel "visually attentive multi-receptive field upsampler" (VA-MRFU) module employs multiple receptive field-based convolutions to upsample attentional features by focussing on different information scales. Experimental results conducted on the public benchmark dataset CASIA v2.0 prove the potency of the proposed model. It comfortably beats the existing state-of-the-arts by achieving an IoU score of 0.851, pixel F1 score of 0.9195 and pixel AUC score of 0.8989.
An ADRC-Incorporated Stochastic Gradient Descent Algorithm for Latent Factor Analysis
Jan 13, 2024High-dimensional and incomplete (HDI) matrix contains many complex interactions between numerous nodes. A stochastic gradient descent (SGD)-based latent factor analysis (LFA) model is remarkably effective in extracting valuable information from an HDI matrix. However, such a model commonly encounters the problem of slow convergence because a standard SGD algorithm only considers the current learning error to compute the stochastic gradient without considering the historical and future state of the learning error. To address this critical issue, this paper innovatively proposes an ADRC-incorporated SGD (ADS) algorithm by refining the instance learning error by considering the historical and future state by following the principle of an ADRC controller. With it, an ADS-based LFA model is further achieved for fast and accurate latent factor analysis on an HDI matrix. Empirical studies on two HDI datasets demonstrate that the proposed model outperforms the state-of-the-art LFA models in terms of computational efficiency and accuracy for predicting the missing data of an HDI matrix.
TaCo: Targeted Concept Removal in Output Embeddings for NLP via Information Theory and Explainability
Dec 11, 2023The fairness of Natural Language Processing (NLP) models has emerged as a crucial concern. Information theory indicates that to achieve fairness, a model should not be able to predict sensitive variables, such as gender, ethnicity, and age. However, information related to these variables often appears implicitly in language, posing a challenge in identifying and mitigating biases effectively. To tackle this issue, we present a novel approach that operates at the embedding level of an NLP model, independent of the specific architecture. Our method leverages insights from recent advances in XAI techniques and employs an embedding transformation to eliminate implicit information from a selected variable. By directly manipulating the embeddings in the final layer, our approach enables a seamless integration into existing models without requiring significant modifications or retraining. In evaluation, we show that the proposed post-hoc approach significantly reduces gender-related associations in NLP models while preserving the overall performance and functionality of the models. An implementation of our method is available: https://github.com/fanny-jourdan/TaCo
From OTFS to AFDM: A Comparative Study of Next-Generation Waveforms for ISAC in Doubly-Dispersive Channels
Jan 15, 2024Next-generation wireless systems will offer integrated sensing and communications (ISAC) functionalities not only in order to enable new applications, but also as a means to mitigate challenges such as doubly-dispersive channels, which arise in high mobility scenarios and/or at millimeter-wave (mmWave) and Terahertz (THz) bands. An emerging approach to accomplish these goals is the design of new waveforms, which draw from the inherent relationship between the doubly-dispersive nature of time-variant (TV) channels and the environmental features of scatterers manifested in the form of multi-path delays and Doppler shifts. Examples of such waveforms are the delay-Doppler domain orthogonal time frequency space (OTFS) and the recently proposed chirp domain affine frequency division multiplexing (AFDM), both of which seek to simultaneously combat the detrimental effects of double selectivity and exploit them for the estimation (or sensing) of environmental information. This article aims to provide a consolidated and comprehensive overview of the signal processing techniques required to support reliable ISAC over doubly-dispersive channels in beyond fifth generation (B5G)/sixth generation (6G) systems, with an emphasis on OTFS and AFDM waveforms, as those, together with the traditional orthogonal frequency division multiplexing (OFDM) waveform, suffice to elaborate on the most relevant properties of the trend. The analysis shows that OTFS and AFDM indeed enable significantly improved robustness against inter-carrier interference (ICI) arising from Doppler shifts compared to OFDM. In addition, the inherent delay-Doppler domain orthogonality of the OTFS and AFDM effective channels is found to provide significant advantages for the design and the performance of integrated sensing functionalities.
RecRanker: Instruction Tuning Large Language Model as Ranker for Top-k Recommendation
Jan 15, 2024Large language models (LLMs) have demonstrated remarkable capabilities and have been extensively deployed across various domains, including recommender systems. Numerous studies have employed specialized \textit{prompts} to harness the in-context learning capabilities intrinsic to LLMs. For example, LLMs are prompted to act as zero-shot rankers for listwise ranking, evaluating candidate items generated by a retrieval model for recommendation. Recent research further uses instruction tuning techniques to align LLM with human preference for more promising recommendations. Despite its potential, current research overlooks the integration of multiple ranking tasks to enhance model performance. Moreover, the signal from the conventional recommendation model is not integrated into the LLM, limiting the current system performance. In this paper, we introduce RecRanker, tailored for instruction tuning LLM to serve as the \textbf{Ranker} for top-\textit{k} \textbf{Rec}ommendations. Specifically, we introduce importance-aware sampling, clustering-based sampling, and penalty for repetitive sampling for sampling high-quality, representative, and diverse training data. To enhance the prompt, we introduce position shifting strategy to mitigate position bias and augment the prompt with auxiliary information from conventional recommendation models, thereby enriching the contextual understanding of the LLM. Subsequently, we utilize the sampled data to assemble an instruction-tuning dataset with the augmented prompt comprising three distinct ranking tasks: pointwise, pairwise, and listwise rankings. We further propose a hybrid ranking method to enhance the model performance by ensembling these ranking tasks. Our empirical evaluations demonstrate the effectiveness of our proposed RecRanker in both direct and sequential recommendation scenarios.
A Sparse Cross Attention-based Graph Convolution Network with Auxiliary Information Awareness for Traffic Flow Prediction
Dec 14, 2023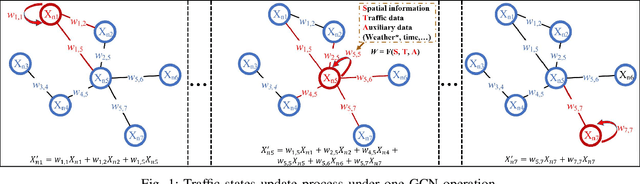
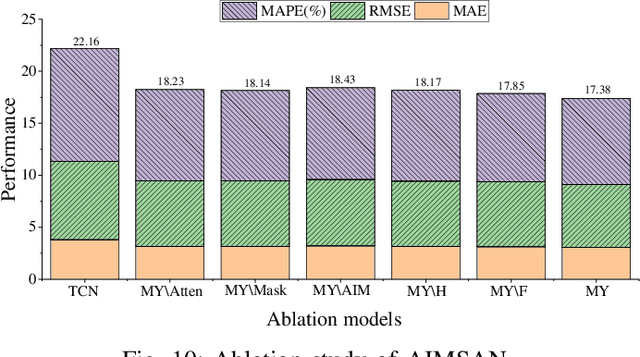
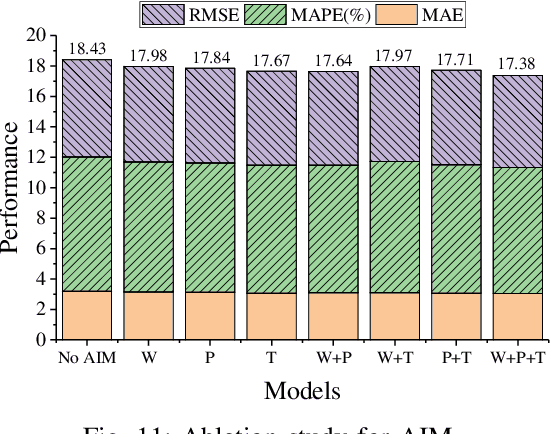
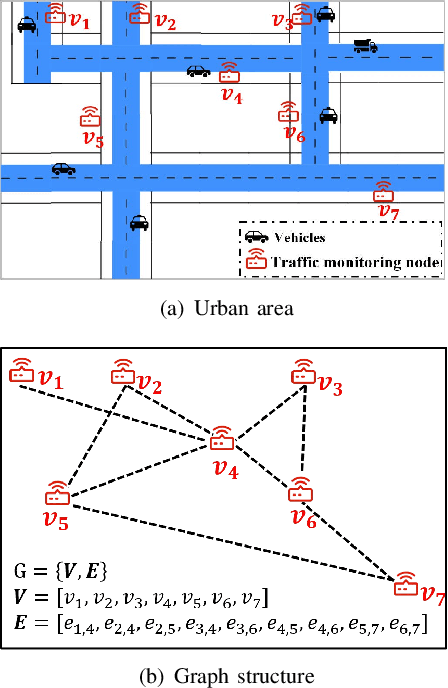
Deep graph convolution networks (GCNs) have recently shown excellent performance in traffic prediction tasks. However, they face some challenges. First, few existing models consider the influence of auxiliary information, i.e., weather and holidays, which may result in a poor grasp of spatial-temporal dynamics of traffic data. Second, both the construction of a dynamic adjacent matrix and regular graph convolution operations have quadratic computation complexity, which restricts the scalability of GCN-based models. To address such challenges, this work proposes a deep encoder-decoder model entitled AIMSAN. It contains an auxiliary information-aware module (AIM) and sparse cross attention-based graph convolution network (SAN). The former learns multi-attribute auxiliary information and obtains its embedded presentation of different time-window sizes. The latter uses a cross-attention mechanism to construct dynamic adjacent matrices by fusing traffic data and embedded auxiliary data. Then, SAN applies diffusion GCN on traffic data to mine rich spatial-temporal dynamics. Furthermore, AIMSAN considers and uses the spatial sparseness of traffic nodes to reduce the quadratic computation complexity. Experimental results on three public traffic datasets demonstrate that the proposed method outperforms other counterparts in terms of various performance indices. Specifically, the proposed method has competitive performance with the state-of-the-art algorithms but saves 35.74% of GPU memory usage, 42.25% of training time, and 45.51% of validation time on average.
AGSPNet: A framework for parcel-scale crop fine-grained semantic change detection from UAV high-resolution imagery with agricultural geographic scene constraints
Jan 11, 2024Real-time and accurate information on fine-grained changes in crop cultivation is of great significance for crop growth monitoring, yield prediction and agricultural structure adjustment. Aiming at the problems of serious spectral confusion in visible high-resolution unmanned aerial vehicle (UAV) images of different phases, interference of large complex background and salt-and-pepper noise by existing semantic change detection (SCD) algorithms, in order to effectively extract deep image features of crops and meet the demand of agricultural practical engineering applications, this paper designs and proposes an agricultural geographic scene and parcel-scale constrained SCD framework for crops (AGSPNet). AGSPNet framework contains three parts: agricultural geographic scene (AGS) division module, parcel edge extraction module and crop SCD module. Meanwhile, we produce and introduce an UAV image SCD dataset (CSCD) dedicated to agricultural monitoring, encompassing multiple semantic variation types of crops in complex geographical scene. We conduct comparative experiments and accuracy evaluations in two test areas of this dataset, and the results show that the crop SCD results of AGSPNet consistently outperform other deep learning SCD models in terms of quantity and quality, with the evaluation metrics F1-score, kappa, OA, and mIoU obtaining improvements of 0.038, 0.021, 0.011 and 0.062, respectively, on average over the sub-optimal method. The method proposed in this paper can clearly detect the fine-grained change information of crop types in complex scenes, which can provide scientific and technical support for smart agriculture monitoring and management, food policy formulation and food security assurance.