 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Ta'keed: The First Generative Fact-Checking System for Arabic Claims
Jan 25, 2024
This paper introduces Ta'keed, an explainable Arabic automatic fact-checking system. While existing research often focuses on classifying claims as "True" or "False," there is a limited exploration of generating explanations for claim credibility, particularly in Arabic. Ta'keed addresses this gap by assessing claim truthfulness based on retrieved snippets, utilizing two main components: information retrieval and LLM-based claim verification. We compiled the ArFactEx, a testing gold-labelled dataset with manually justified references, to evaluate the system. The initial model achieved a promising F1 score of 0.72 in the classification task. Meanwhile, the system's generated explanations are compared with gold-standard explanations syntactically and semantically. The study recommends evaluating using semantic similarities, resulting in an average cosine similarity score of 0.76. Additionally, we explored the impact of varying snippet quantities on claim classification accuracy, revealing a potential correlation, with the model using the top seven hits outperforming others with an F1 score of 0.77.
* 9 pages, conference paper
Parameter-Efficient Conversational Recommender System as a Language Processing Task
Jan 25, 2024Conversational recommender systems (CRS) aim to recommend relevant items to users by eliciting user preference through natural language conversation. Prior work often utilizes external knowledge graphs for items' semantic information, a language model for dialogue generation, and a recommendation module for ranking relevant items. This combination of multiple components suffers from a cumbersome training process, and leads to semantic misalignment issues between dialogue generation and item recommendation. In this paper, we represent items in natural language and formulate CRS as a natural language processing task. Accordingly, we leverage the power of pre-trained language models to encode items, understand user intent via conversation, perform item recommendation through semantic matching, and generate dialogues. As a unified model, our PECRS (Parameter-Efficient CRS), can be optimized in a single stage, without relying on non-textual metadata such as a knowledge graph. Experiments on two benchmark CRS datasets, ReDial and INSPIRED, demonstrate the effectiveness of PECRS on recommendation and conversation. Our code is available at: https://github.com/Ravoxsg/efficient_unified_crs.
MOSformer: Momentum encoder-based inter-slice fusion transformer for medical image segmentation
Jan 22, 2024Medical image segmentation takes an important position in various clinical applications. Deep learning has emerged as the predominant solution for automated segmentation of volumetric medical images. 2.5D-based segmentation models bridge computational efficiency of 2D-based models and spatial perception capabilities of 3D-based models. However, prevailing 2.5D-based models often treat each slice equally, failing to effectively learn and exploit inter-slice information, resulting in suboptimal segmentation performances. In this paper, a novel Momentum encoder-based inter-slice fusion transformer (MOSformer) is proposed to overcome this issue by leveraging inter-slice information at multi-scale feature maps extracted by different encoders. Specifically, dual encoders are employed to enhance feature distinguishability among different slices. One of the encoders is moving-averaged to maintain the consistency of slice representations. Moreover, an IF-Swin transformer module is developed to fuse inter-slice multi-scale features. The MOSformer is evaluated on three benchmark datasets (Synapse, ACDC, and AMOS), establishing a new state-of-the-art with 85.63%, 92.19%, and 85.43% of DSC, respectively. These promising results indicate its competitiveness in medical image segmentation. Codes and models of MOSformer will be made publicly available upon acceptance.
T2MAC: Targeted and Trusted Multi-Agent Communication through Selective Engagement and Evidence-Driven Integration
Jan 19, 2024Communication stands as a potent mechanism to harmonize the behaviors of multiple agents. However, existing works primarily concentrate on broadcast communication, which not only lacks practicality, but also leads to information redundancy. This surplus, one-fits-all information could adversely impact the communication efficiency. Furthermore, existing works often resort to basic mechanisms to integrate observed and received information, impairing the learning process. To tackle these difficulties, we propose Targeted and Trusted Multi-Agent Communication (T2MAC), a straightforward yet effective method that enables agents to learn selective engagement and evidence-driven integration. With T2MAC, agents have the capability to craft individualized messages, pinpoint ideal communication windows, and engage with reliable partners, thereby refining communication efficiency. Following the reception of messages, the agents integrate information observed and received from different sources at an evidence level. This process enables agents to collectively use evidence garnered from multiple perspectives, fostering trusted and cooperative behaviors. We evaluate our method on a diverse set of cooperative multi-agent tasks, with varying difficulties, involving different scales and ranging from Hallway, MPE to SMAC. The experiments indicate that the proposed model not only surpasses the state-of-the-art methods in terms of cooperative performance and communication efficiency, but also exhibits impressive generalization.
Learning Position-Aware Implicit Neural Network for Real-World Face Inpainting
Jan 19, 2024Face inpainting requires the model to have a precise global understanding of the facial position structure. Benefiting from the powerful capabilities of deep learning backbones, recent works in face inpainting have achieved decent performance in ideal setting (square shape with $512px$). However, existing methods often produce a visually unpleasant result, especially in the position-sensitive details (e.g., eyes and nose), when directly applied to arbitrary-shaped images in real-world scenarios. The visually unpleasant position-sensitive details indicate the shortcomings of existing methods in terms of position information processing capability. In this paper, we propose an \textbf{I}mplicit \textbf{N}eural \textbf{I}npainting \textbf{N}etwork (IN$^2$) to handle arbitrary-shape face images in real-world scenarios by explicit modeling for position information. Specifically, a downsample processing encoder is proposed to reduce information loss while obtaining the global semantic feature. A neighbor hybrid attention block is proposed with a hybrid attention mechanism to improve the facial understanding ability of the model without restricting the shape of the input. Finally, an implicit neural pyramid decoder is introduced to explicitly model position information and bridge the gap between low-resolution features and high-resolution output. Extensive experiments demonstrate the superiority of the proposed method in real-world face inpainting task.
LIV-GaussMap: LiDAR-Inertial-Visual Fusion for Real-time 3D Radiance Field Map Rendering
Jan 26, 2024We introduce an integrated precise LiDAR, Inertial, and Visual (LIV) multi-modal sensor fused mapping system that builds on the differentiable surface splatting to improve the mapping fidelity, quality, and structural accuracy. Notably, this is also a novel form of tightly coupled map for LiDAR-visual-inertial sensor fusion. This system leverages the complementary characteristics of LiDAR and visual data to capture the geometric structures of large-scale 3D scenes and restore their visual surface information with high fidelity. The initial poses for surface Gaussian scenes are obtained using a LiDAR-inertial system with size-adaptive voxels. Then, we optimized and refined the Gaussians by visual-derived photometric gradients to optimize the quality and density of LiDAR measurements. Our method is compatible with various types of LiDAR, including solid-state and mechanical LiDAR, supporting both repetitive and non-repetitive scanning modes. bolstering structure construction through LiDAR and facilitating real-time generation of photorealistic renderings across diverse LIV datasets. It showcases notable resilience and versatility in generating real-time photorealistic scenes potentially for digital twins and virtual reality while also holding potential applicability in real-time SLAM and robotics domains. We release our software and hardware and self-collected datasets on Github\footnote[3]{https://github.com/sheng00125/LIV-GaussMap} to benefit the community.
Employing Iterative Feature Selection in Fuzzy Rule-Based Binary Classification
Jan 26, 2024The feature selection in a traditional binary classification algorithm is always used in the stage of dataset preprocessing, which makes the obtained features not necessarily the best ones for the classification algorithm, thus affecting the classification performance. For a traditional rule-based binary classification algorithm, classification rules are usually deterministic, which results in the fuzzy information contained in the rules being ignored. To do so, this paper employs iterative feature selection in fuzzy rule-based binary classification. The proposed algorithm combines feature selection based on fuzzy correlation family with rule mining based on biclustering. It first conducts biclustering on the dataset after feature selection. Then it conducts feature selection again for the biclusters according to the feedback of biclusters evaluation. In this way, an iterative feature selection framework is build. During the iteration process, it stops until the obtained bicluster meets the requirements. In addition, the rule membership function is introduced to extract vectorized fuzzy rules from the bicluster and construct weak classifiers. The weak classifiers with good classification performance are selected by Adaptive Boosting and the strong classifier is constructed by "weighted average". Finally, we perform the proposed algorithm on different datasets and compare it with other peers. Experimental results show that it achieves good classification performance and outperforms its peers.
From Blurry to Brilliant Detection: YOLOv5-Based Aerial Object Detection with Super Resolution
Jan 26, 2024The demand for accurate object detection in aerial imagery has surged with the widespread use of drones and satellite technology. Traditional object detection models, trained on datasets biased towards large objects, struggle to perform optimally in aerial scenarios where small, densely clustered objects are prevalent. To address this challenge, we present an innovative approach that combines super-resolution and an adapted lightweight YOLOv5 architecture. We employ a range of datasets, including VisDrone-2023, SeaDroneSee, VEDAI, and NWPU VHR-10, to evaluate our model's performance. Our Super Resolved YOLOv5 architecture features Transformer encoder blocks, allowing the model to capture global context and context information, leading to improved detection results, especially in high-density, occluded conditions. This lightweight model not only delivers improved accuracy but also ensures efficient resource utilization, making it well-suited for real-time applications. Our experimental results demonstrate the model's superior performance in detecting small and densely clustered objects, underlining the significance of dataset choice and architectural adaptation for this specific task. In particular, the method achieves 52.5% mAP on VisDrone, exceeding top prior works. This approach promises to significantly advance object detection in aerial imagery, contributing to more accurate and reliable results in a variety of real-world applications.
GeoDecoder: Empowering Multimodal Map Understanding
Jan 26, 2024This paper presents GeoDecoder, a dedicated multimodal model designed for processing geospatial information in maps. Built on the BeitGPT architecture, GeoDecoder incorporates specialized expert modules for image and text processing. On the image side, GeoDecoder utilizes GaoDe Amap as the underlying base map, which inherently encompasses essential details about road and building shapes, relative positions, and other attributes. Through the utilization of rendering techniques, the model seamlessly integrates external data and features such as symbol markers, drive trajectories, heatmaps, and user-defined markers, eliminating the need for extra feature engineering. The text module of GeoDecoder accepts various context texts and question prompts, generating text outputs in the style of GPT. Furthermore, the GPT-based model allows for the training and execution of multiple tasks within the same model in an end-to-end manner. To enhance map cognition and enable GeoDecoder to acquire knowledge about the distribution of geographic entities in Beijing, we devised eight fundamental geospatial tasks and conducted pretraining of the model using large-scale text-image samples. Subsequently, rapid fine-tuning was performed on three downstream tasks, resulting in significant performance improvements. The GeoDecoder model demonstrates a comprehensive understanding of map elements and their associated operations, enabling efficient and high-quality application of diverse geospatial tasks in different business scenarios.
Solving Label Variation in Scientific Information Extraction via Multi-Task Learning
Dec 25, 2023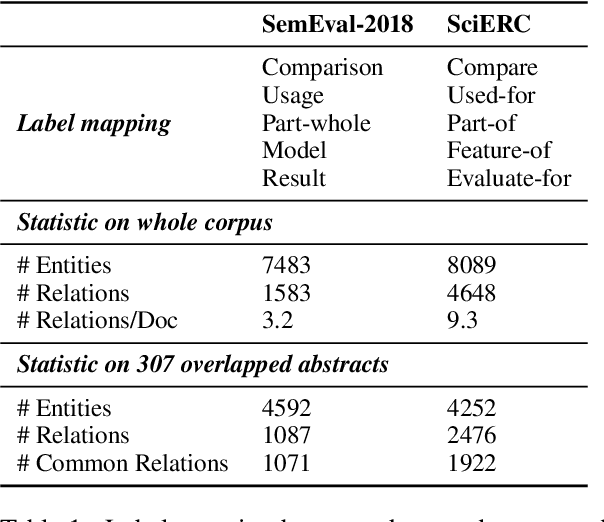
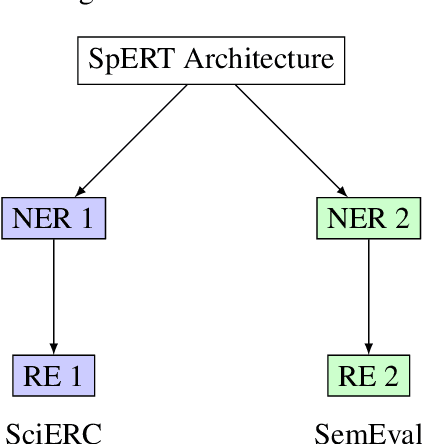
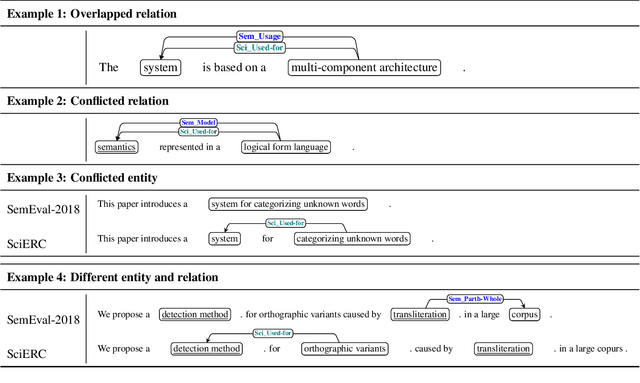
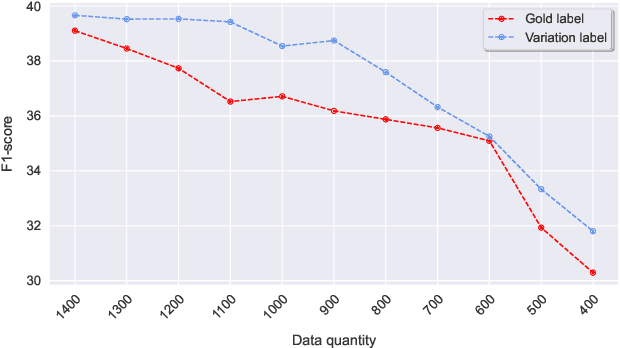
Scientific Information Extraction (ScientificIE) is a critical task that involves the identification of scientific entities and their relationships. The complexity of this task is compounded by the necessity for domain-specific knowledge and the limited availability of annotated data. Two of the most popular datasets for ScientificIE are SemEval-2018 Task-7 and SciERC. They have overlapping samples and differ in their annotation schemes, which leads to conflicts. In this study, we first introduced a novel approach based on multi-task learning to address label variations. We then proposed a soft labeling technique that converts inconsistent labels into probabilistic distributions. The experimental results demonstrated that the proposed method can enhance the model robustness to label noise and improve the end-to-end performance in both ScientificIE tasks. The analysis revealed that label variations can be particularly effective in handling ambiguous instances. Furthermore, the richness of the information captured by label variations can potentially reduce data size requirements. The findings highlight the importance of releasing variation labels and promote future research on other tasks in other domains. Overall, this study demonstrates the effectiveness of multi-task learning and the potential of label variations to enhance the performance of ScientificIE.