 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Ontology-driven Event Type Classification in Images
Nov 09, 2020

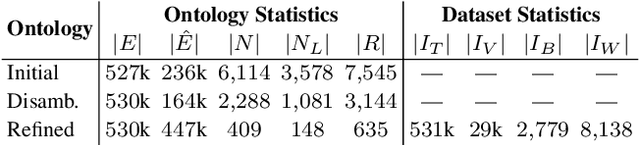
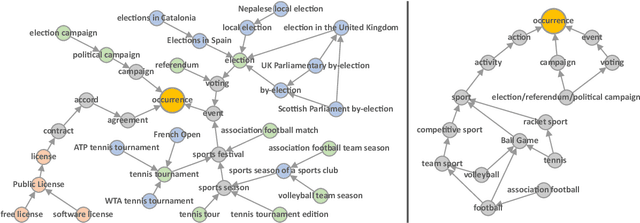
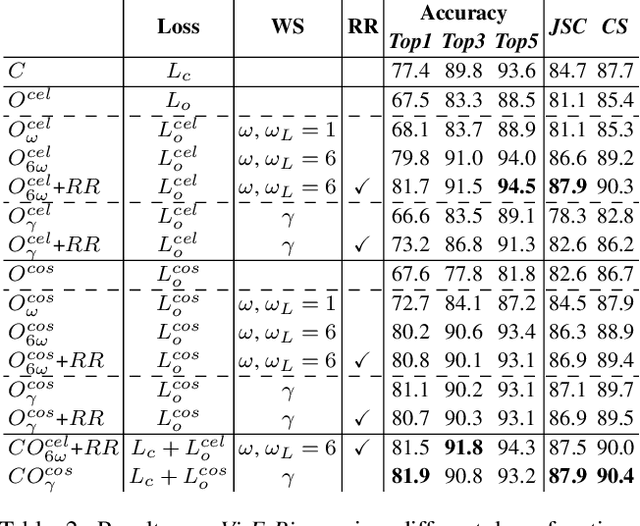
Event classification can add valuable information for semantic search and the increasingly important topic of fact validation in news. So far, only few approaches address image classification for newsworthy event types such as natural disasters, sports events, or elections. Previous work distinguishes only between a limited number of event types and relies on rather small datasets for training. In this paper, we present a novel ontology-driven approach for the classification of event types in images. We leverage a large number of real-world news events to pursue two objectives: First, we create an ontology based on Wikidata comprising the majority of event types. Second, we introduce a novel large-scale dataset that was acquired through Web crawling. Several baselines are proposed including an ontology-driven learning approach that aims to exploit structured information of a knowledge graph to learn relevant event relations using deep neural networks. Experimental results on existing as well as novel benchmark datasets demonstrate the superiority of the proposed ontology-driven approach.
How Privacy-Preserving are Line Clouds? Recovering Scene Details from 3D Lines
Mar 08, 2021

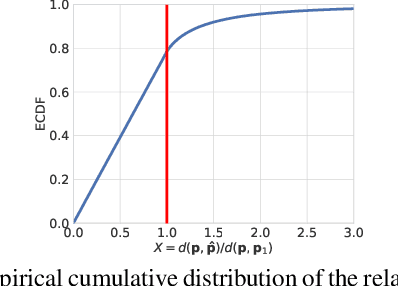

Visual localization is the problem of estimating the camera pose of a given image with respect to a known scene. Visual localization algorithms are a fundamental building block in advanced computer vision applications, including Mixed and Virtual Reality systems. Many algorithms used in practice represent the scene through a Structure-from-Motion (SfM) point cloud and use 2D-3D matches between a query image and the 3D points for camera pose estimation. As recently shown, image details can be accurately recovered from SfM point clouds by translating renderings of the sparse point clouds to images. To address the resulting potential privacy risks for user-generated content, it was recently proposed to lift point clouds to line clouds by replacing 3D points by randomly oriented 3D lines passing through these points. The resulting representation is unintelligible to humans and effectively prevents point cloud-to-image translation. This paper shows that a significant amount of information about the 3D scene geometry is preserved in these line clouds, allowing us to (approximately) recover the 3D point positions and thus to (approximately) recover image content. Our approach is based on the observation that the closest points between lines can yield a good approximation to the original 3D points. Code is available at https://github.com/kunalchelani/Line2Point.
Deep Model Intellectual Property Protection via Deep Watermarking
Mar 08, 2021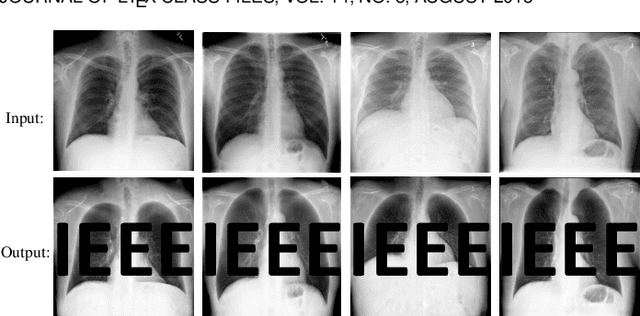
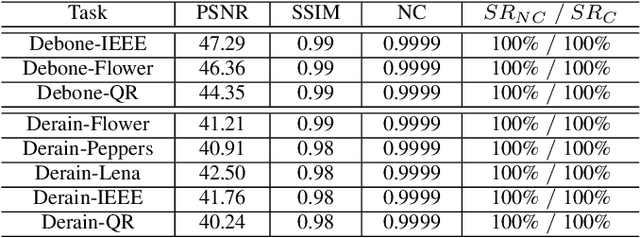
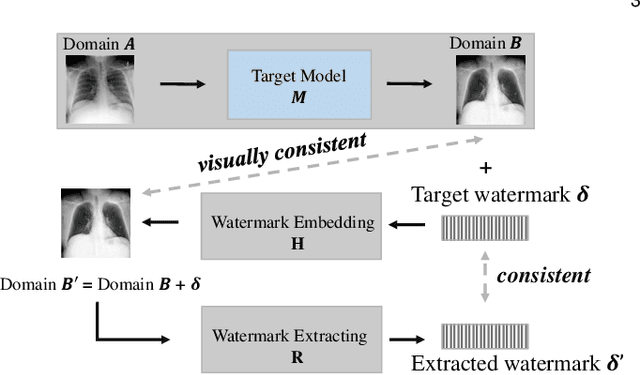

Despite the tremendous success, deep neural networks are exposed to serious IP infringement risks. Given a target deep model, if the attacker knows its full information, it can be easily stolen by fine-tuning. Even if only its output is accessible, a surrogate model can be trained through student-teacher learning by generating many input-output training pairs. Therefore, deep model IP protection is important and necessary. However, it is still seriously under-researched. In this work, we propose a new model watermarking framework for protecting deep networks trained for low-level computer vision or image processing tasks. Specifically, a special task-agnostic barrier is added after the target model, which embeds a unified and invisible watermark into its outputs. When the attacker trains one surrogate model by using the input-output pairs of the barrier target model, the hidden watermark will be learned and extracted afterwards. To enable watermarks from binary bits to high-resolution images, a deep invisible watermarking mechanism is designed. By jointly training the target model and watermark embedding, the extra barrier can even be absorbed into the target model. Through extensive experiments, we demonstrate the robustness of the proposed framework, which can resist attacks with different network structures and objective functions.
SSD: A Unified Framework for Self-Supervised Outlier Detection
Mar 22, 2021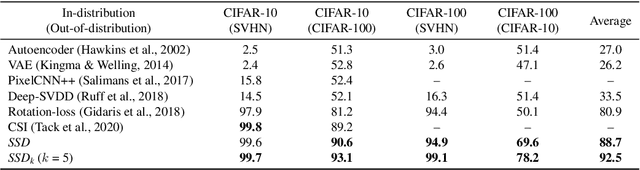
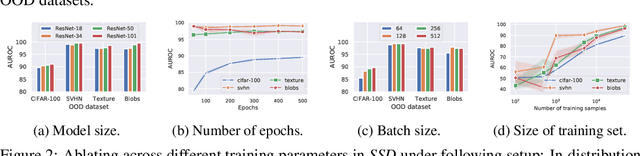
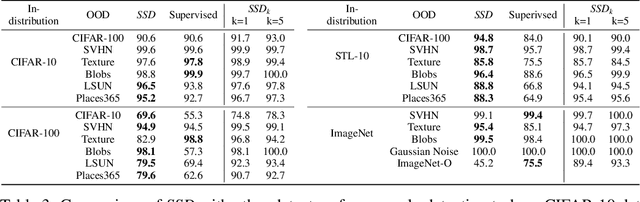
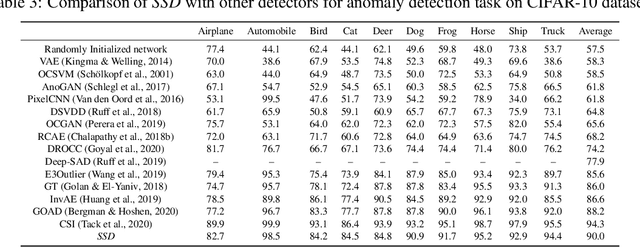
We ask the following question: what training information is required to design an effective outlier/out-of-distribution (OOD) detector, i.e., detecting samples that lie far away from the training distribution? Since unlabeled data is easily accessible for many applications, the most compelling approach is to develop detectors based on only unlabeled in-distribution data. However, we observe that most existing detectors based on unlabeled data perform poorly, often equivalent to a random prediction. In contrast, existing state-of-the-art OOD detectors achieve impressive performance but require access to fine-grained data labels for supervised training. We propose SSD, an outlier detector based on only unlabeled in-distribution data. We use self-supervised representation learning followed by a Mahalanobis distance based detection in the feature space. We demonstrate that SSD outperforms most existing detectors based on unlabeled data by a large margin. Additionally, SSD even achieves performance on par, and sometimes even better, with supervised training based detectors. Finally, we expand our detection framework with two key extensions. First, we formulate few-shot OOD detection, in which the detector has access to only one to five samples from each class of the targeted OOD dataset. Second, we extend our framework to incorporate training data labels, if available. We find that our novel detection framework based on SSD displays enhanced performance with these extensions, and achieves state-of-the-art performance. Our code is publicly available at https://github.com/inspire-group/SSD.
Data-driven Cloud Clustering via a Rotationally Invariant Autoencoder
Mar 08, 2021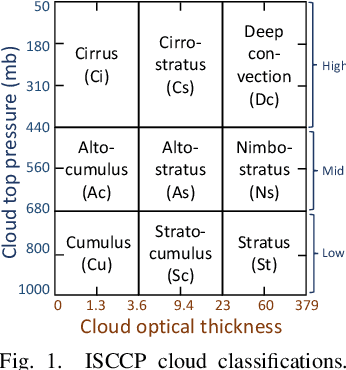


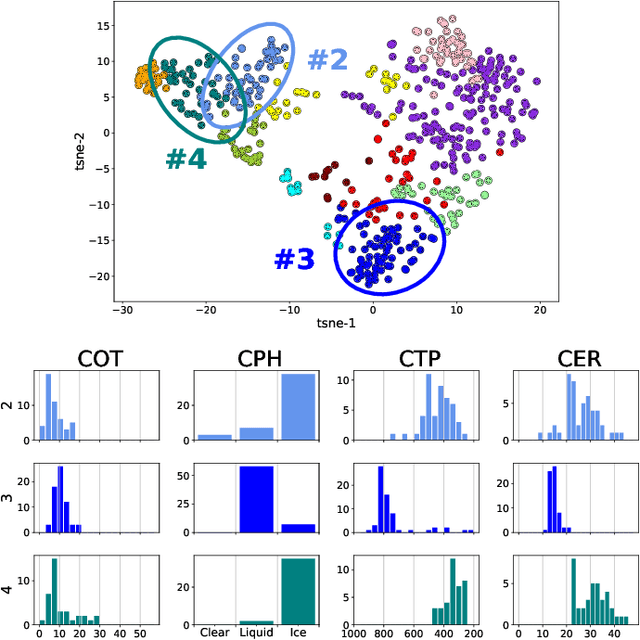
Advanced satellite-born remote sensing instruments produce high-resolution multi-spectral data for much of the globe at a daily cadence. These datasets open up the possibility of improved understanding of cloud dynamics and feedback, which remain the biggest source of uncertainty in global climate model projections. As a step towards answering these questions, we describe an automated rotation-invariant cloud clustering (RICC) method that leverages deep learning autoencoder technology to organize cloud imagery within large datasets in an unsupervised fashion, free from assumptions about predefined classes. We describe both the design and implementation of this method and its evaluation, which uses a sequence of testing protocols to determine whether the resulting clusters: (1) are physically reasonable, (i.e., embody scientifically relevant distinctions); (2) capture information on spatial distributions, such as textures; (3) are cohesive and separable in latent space; and (4) are rotationally invariant, (i.e., insensitive to the orientation of an image). Results obtained when these evaluation protocols are applied to RICC outputs suggest that the resultant novel cloud clusters capture meaningful aspects of cloud physics, are appropriately spatially coherent, and are invariant to orientations of input images. Our results support the possibility of using an unsupervised data-driven approach for automated clustering and pattern discovery in cloud imagery.
LSTM-SAKT: LSTM-Encoded SAKT-like Transformer for Knowledge Tracing
Feb 10, 2021
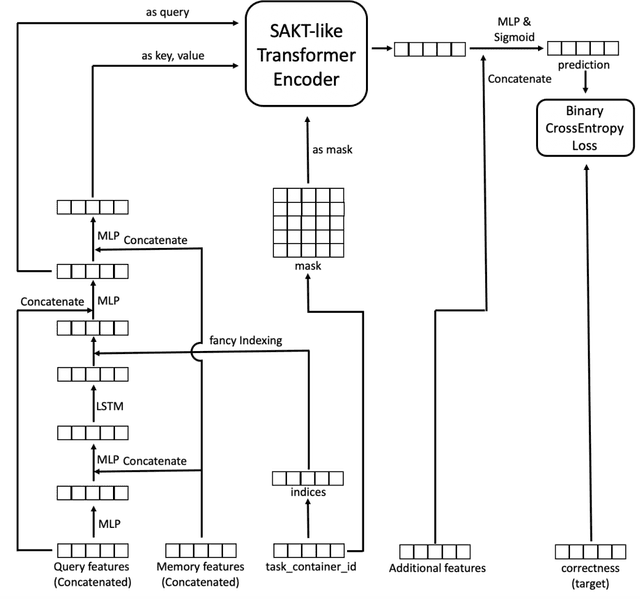

This paper introduces the 2nd place solution for the Riiid! Answer Correctness Prediction in Kaggle, the world's largest data science competition website. This competition was held from October 16, 2020, to January 7, 2021, with 3395 teams and 4387 competitors. The main insights and contributions of this paper are as follows. (i) We pointed out existing Transformer-based models are suffering from a problem that the information which their query/key/value can contain is limited. To solve this problem, we proposed a method that uses LSTM to obtain query/key/value and verified its effectiveness. (ii) We pointed out 'inter-container' leakage problem, which happens in datasets where questions are sometimes served together. To solve this problem, we showed special indexing/masking techniques that are useful when using RNN-variants and Transformer. (iii) We found additional hand-crafted features are effective to overcome the limits of Transformer, which can never consider the samples older than the sequence length.
An Ensemble Deep Convolutional Neural Network Model for Electricity Theft Detection in Smart Grids
Feb 10, 2021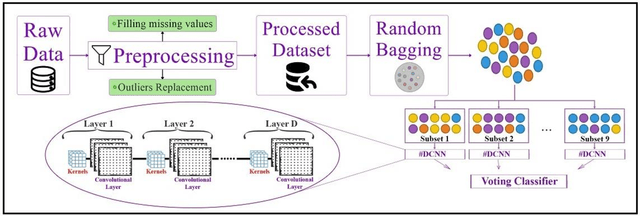

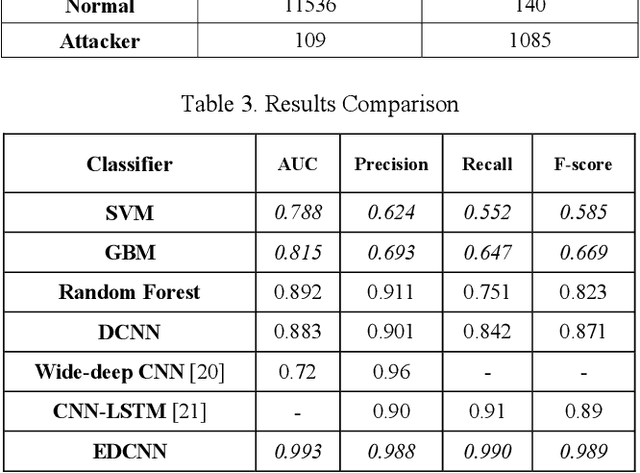
Smart grids extremely rely on Information and Communications Technology (ICT) and smart meters to control and manage numerous parameters of the network. However, using these infrastructures make smart grids more vulnerable to cyber threats especially electricity theft. Electricity Theft Detection (EDT) algorithms are typically used for such purpose since this Non-Technical Loss (NTL) may lead to significant challenges in the power system. In this paper, an Ensemble Deep Convolutional Neural Network (EDCNN) algorithm for ETD in smart grids has been proposed. As the first layer of the model, a random under bagging technique is applied to deal with the imbalance data, and then Deep Convolutional Neural Networks (DCNN) are utilized on each subset. Finally, a voting system is embedded, in the last part. The evaluation results based on the Area Under Curve (AUC), precision, recall, f1-score, and accuracy verify the efficiency of the proposed method compared to the existing method in the literature.
Generalized Image Reconstruction over T-Algebra
Jan 20, 2021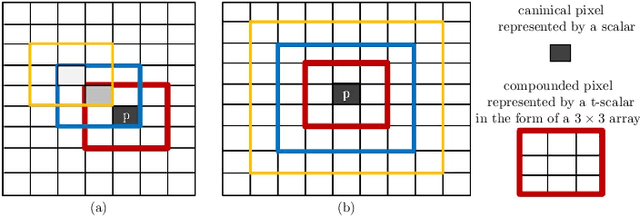
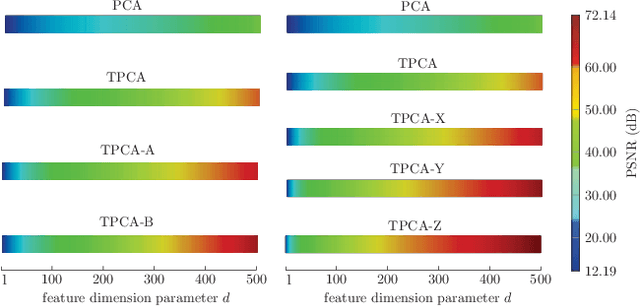
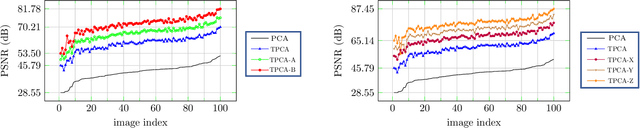
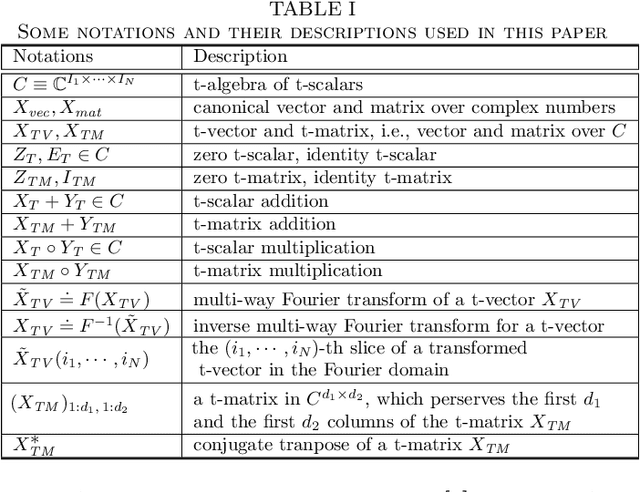
Principal Component Analysis (PCA) is well known for its capability of dimension reduction and data compression. However, when using PCA for compressing/reconstructing images, images need to be recast to vectors. The vectorization of images makes some correlation constraints of neighboring pixels and spatial information lost. To deal with the drawbacks of the vectorizations adopted by PCA, we used small neighborhoods of each pixel to form compounded pixels and use a tensorial version of PCA, called TPCA (Tensorial Principal Component Analysis), to compress and reconstruct a compounded image of compounded pixels. Our experiments on public data show that TPCA compares favorably with PCA in compressing and reconstructing images. We also show in our experiments that the performance of TPCA increases when the order of compounded pixels increases.
Preferential Mixture-of-Experts: Interpretable Models that Rely on Human Expertise as much as Possible
Jan 13, 2021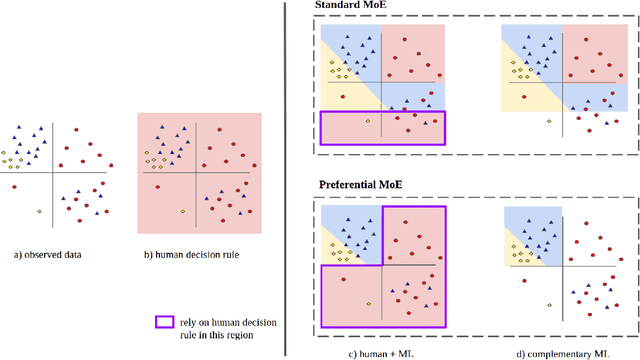
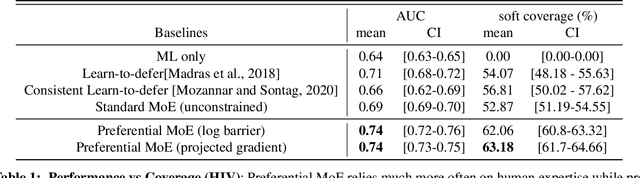
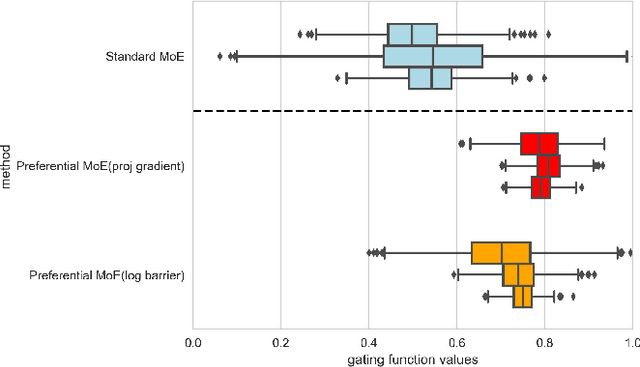
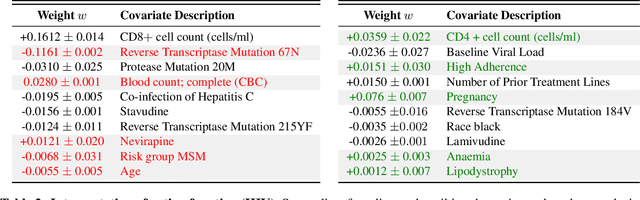
We propose Preferential MoE, a novel human-ML mixture-of-experts model that augments human expertise in decision making with a data-based classifier only when necessary for predictive performance. Our model exhibits an interpretable gating function that provides information on when human rules should be followed or avoided. The gating function is maximized for using human-based rules, and classification errors are minimized. We propose solving a coupled multi-objective problem with convex subproblems. We develop approximate algorithms and study their performance and convergence. Finally, we demonstrate the utility of Preferential MoE on two clinical applications for the treatment of Human Immunodeficiency Virus (HIV) and management of Major Depressive Disorder (MDD).
Multi-Source Domain Adaptation with Collaborative Learning for Semantic Segmentation
Mar 08, 2021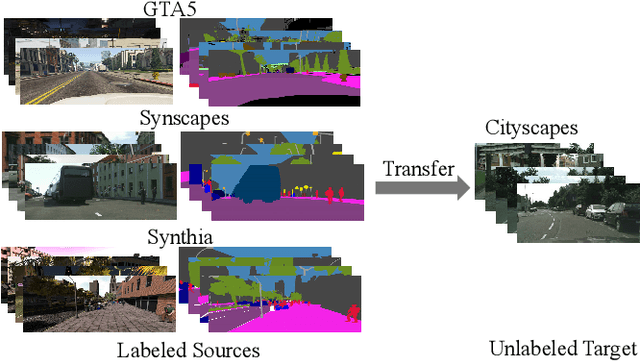
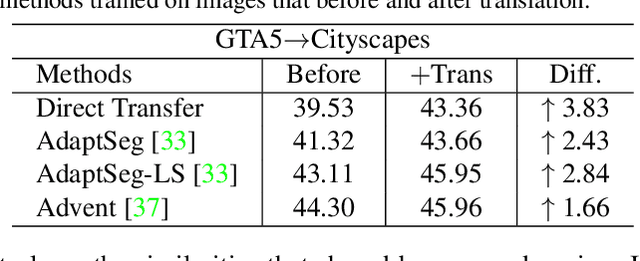
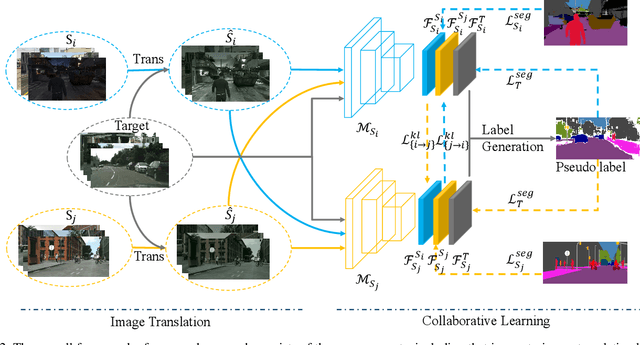
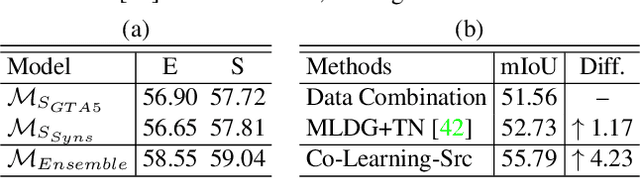
Multi-source unsupervised domain adaptation~(MSDA) aims at adapting models trained on multiple labeled source domains to an unlabeled target domain. In this paper, we propose a novel multi-source domain adaptation framework based on collaborative learning for semantic segmentation. Firstly, a simple image translation method is introduced to align the pixel value distribution to reduce the gap between source domains and target domain to some extent. Then, to fully exploit the essential semantic information across source domains, we propose a collaborative learning method for domain adaptation without seeing any data from target domain. In addition, similar to the setting of unsupervised domain adaptation, unlabeled target domain data is leveraged to further improve the performance of domain adaptation. This is achieved by additionally constraining the outputs of multiple adaptation models with pseudo labels online generated by an ensembled model. Extensive experiments and ablation studies are conducted on the widely-used domain adaptation benchmark datasets in semantic segmentation. Our proposed method achieves 59.0\% mIoU on the validation set of Cityscapes by training on the labeled Synscapes and GTA5 datasets and unlabeled training set of Cityscapes. It significantly outperforms all previous state-of-the-arts single-source and multi-source unsupervised domain adaptation methods.