 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SceneRec: Scene-Based Graph Neural Networks for Recommender Systems
Feb 12, 2021
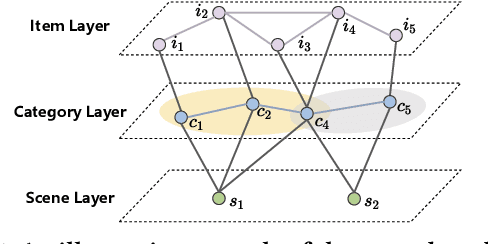
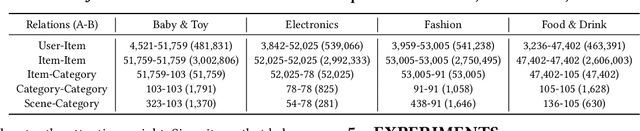
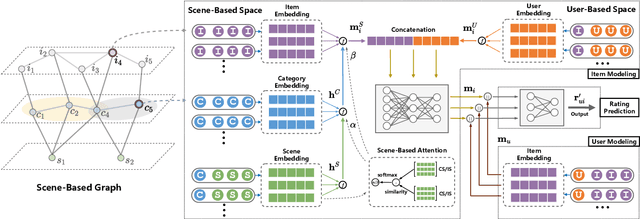
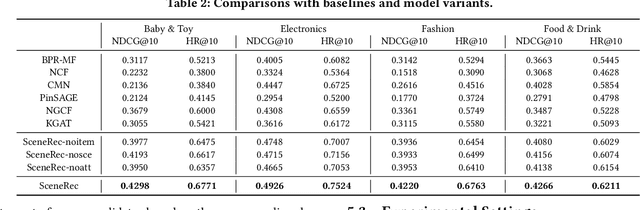
Collaborative filtering has been largely used to advance modern recommender systems to predict user preference. A key component in collaborative filtering is representation learning, which aims to project users and items into a low dimensional space to capture collaborative signals. However, the scene information, which has effectively guided many recommendation tasks, is rarely considered in existing collaborative filtering methods. To bridge this gap, we focus on scene-based collaborative recommendation and propose a novel representation model SceneRec. SceneRec formally defines a scene as a set of pre-defined item categories that occur simultaneously in real-life situations and creatively designs an item-category-scene hierarchical structure to build a scene-based graph. In the scene-based graph, we adopt graph neural networks to learn scene-specific representation on each item node, which is further aggregated with latent representation learned from collaborative interactions to make recommendations. We perform extensive experiments on real-world E-commerce datasets and the results demonstrate the effectiveness of the proposed method.
FairMixRep : Self-supervised Robust Representation Learning for Heterogeneous Data with Fairness constraints
Oct 07, 2020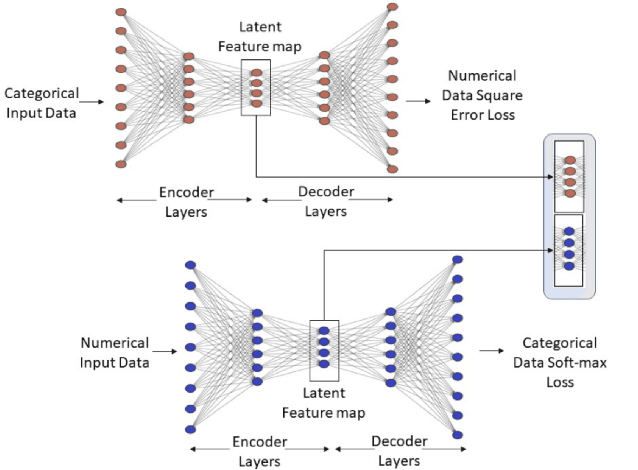
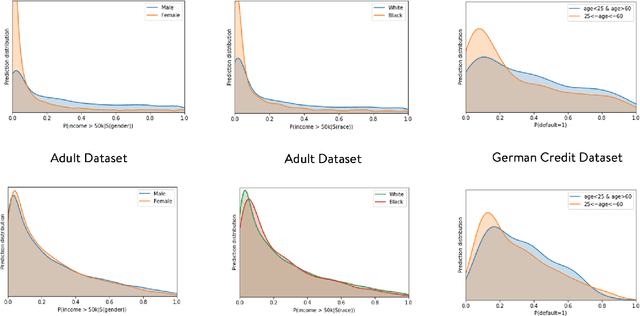
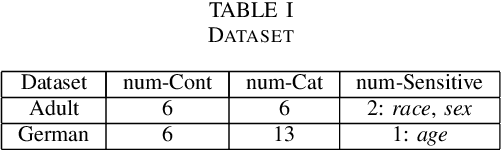
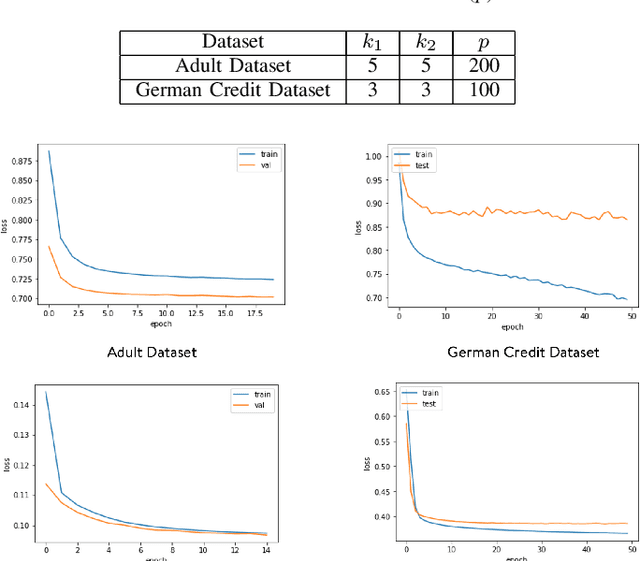
Representation Learning in a heterogeneous space with mixed variables of numerical and categorical types has interesting challenges due to its complex feature manifold. Moreover, feature learning in an unsupervised setup, without class labels and a suitable learning loss function, add to the problem complexity further. Further, the learned representation and subsequent predictions should not reflect discriminatory behavior toward certain sensitive groups or attributes. The proposed feature map should preserve maximum variations present in the data and needs to be fair with respect to the sensitive variables. We propose, in the first phase of our work, an efficient encoder-decoder framework to capture the mixed-domain information. The second phase of our work focuses on de-biasing the mixed space representations by adding relevant fairness constraints. This ensures minimal information loss between the representations before and after the fairness-preserving projections. Both the information content and the fairness aspect of the final representation learned has been validated through several metrics where it shows excellent performance. Our work (FairMixRep) addresses the problem of Mixed Space Fair Representation learning from an unsupervised perspective and learns a Universal representation which is timely, unique and a novel research contribution.
Glioblastoma Multiforme Prognosis: MRI Missing Modality Generation, Segmentation and Radiogenomic Survival Prediction
Mar 17, 2021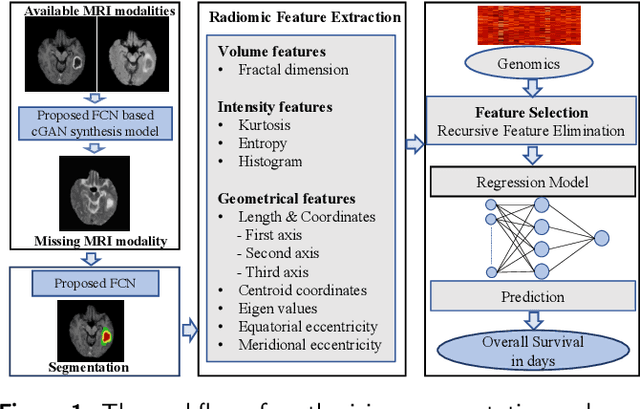
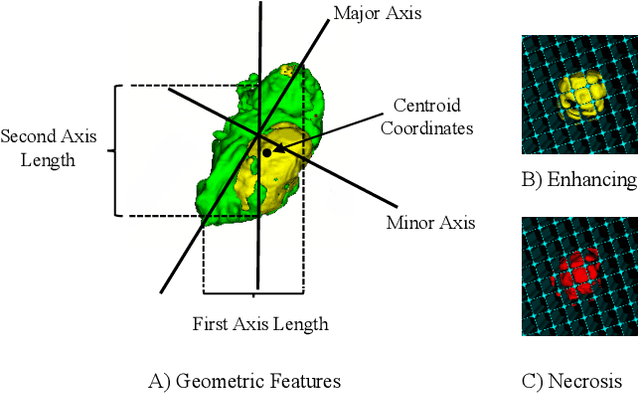
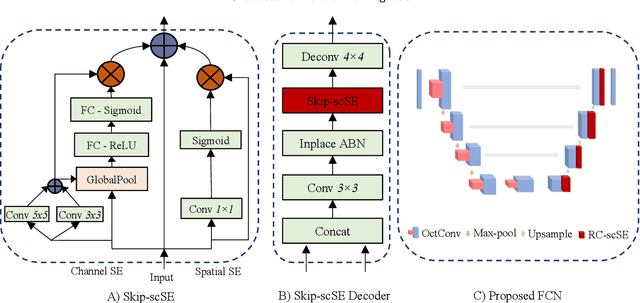
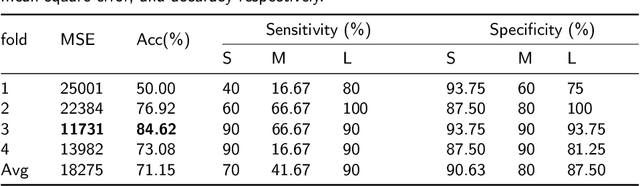
The accurate prognosis of Glioblastoma Multiforme (GBM) plays an essential role in planning correlated surgeries and treatments. The conventional models of survival prediction rely on radiomic features using magnetic resonance imaging (MRI). In this paper, we propose a radiogenomic overall survival (OS) prediction approach by incorporating gene expression data with radiomic features such as shape, geometry, and clinical information. We exploit TCGA (The Cancer Genomic Atlas) dataset and synthesize the missing MRI modalities using a fully convolutional network (FCN) in a conditional Generative Adversarial Network (cGAN). Meanwhile, the same FCN architecture enables the tumor segmentation from the available and the synthesized MRI modalities. The proposed FCN architecture comprises octave convolution (OctConv) and a novel decoder, with skip connections in spatial and channel squeeze & excitation (skip-scSE) block. The OctConv can process low and high-frequency features individually and improve model efficiency by reducing channel-wise redundancy. Skip-scSE applies spatial and channel-wise excitation to signify the essential features and reduces the sparsity in deeper layers learning parameters using skip connections. The proposed approaches are evaluated by comparative experiments with state-of-the-art models in synthesis, segmentation, and overall survival (OS) prediction. We observe that adding missing MRI modality improves the segmentation prediction, and expression levels of gene markers have a high contribution in the GBM prognosis prediction, and fused radiogenomic features boost the OS estimation.
Learning with User-Level Privacy
Mar 02, 2021We propose and analyze algorithms to solve a range of learning tasks under user-level differential privacy constraints. Rather than guaranteeing only the privacy of individual samples, user-level DP protects a user's entire contribution ($m \ge 1$ samples), providing more stringent but more realistic protection against information leaks. We show that for high-dimensional mean estimation, empirical risk minimization with smooth losses, stochastic convex optimization, and learning hypothesis class with finite metric entropy, the privacy cost decreases as $O(1/\sqrt{m})$ as users provide more samples. In contrast, when increasing the number of users $n$, the privacy cost decreases at a faster $O(1/n)$ rate. We complement these results with lower bounds showing the worst-case optimality of our algorithm for mean estimation and stochastic convex optimization. Our algorithms rely on novel techniques for private mean estimation in arbitrary dimension with error scaling as the concentration radius $\tau$ of the distribution rather than the entire range. Under uniform convergence, we derive an algorithm that privately answers a sequence of $K$ adaptively chosen queries with privacy cost proportional to $\tau$, and apply it to solve the learning tasks we consider.
Information Directed Sampling for Stochastic Bandits with Graph Feedback
Nov 08, 2017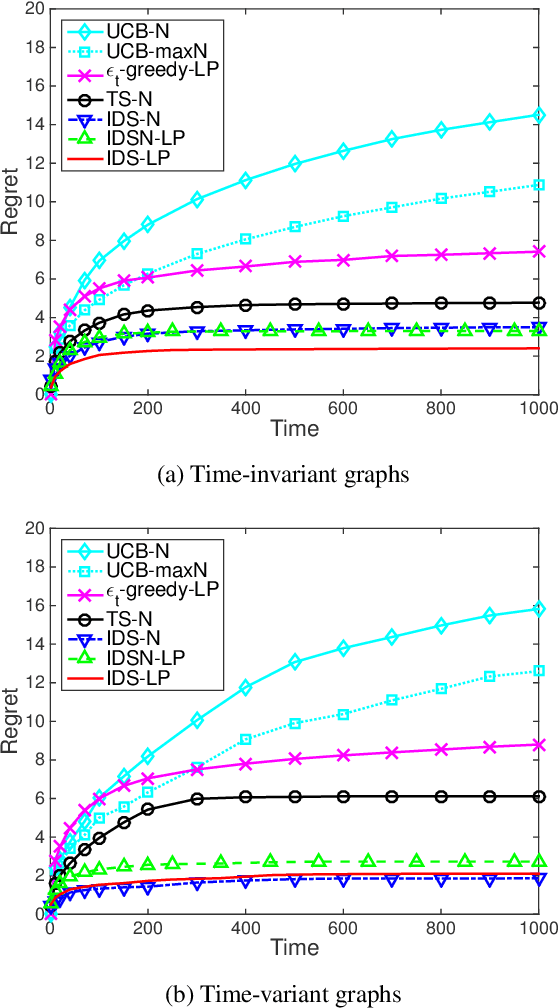
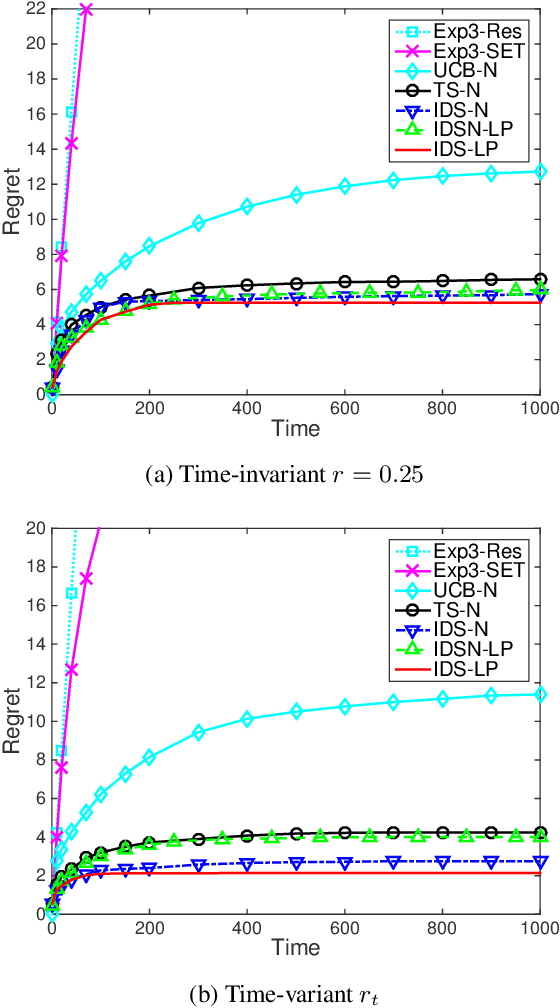
We consider stochastic multi-armed bandit problems with graph feedback, where the decision maker is allowed to observe the neighboring actions of the chosen action. We allow the graph structure to vary with time and consider both deterministic and Erd\H{o}s-R\'enyi random graph models. For such a graph feedback model, we first present a novel analysis of Thompson sampling that leads to tighter performance bound than existing work. Next, we propose new Information Directed Sampling based policies that are graph-aware in their decision making. Under the deterministic graph case, we establish a Bayesian regret bound for the proposed policies that scales with the clique cover number of the graph instead of the number of actions. Under the random graph case, we provide a Bayesian regret bound for the proposed policies that scales with the ratio of the number of actions over the expected number of observations per iteration. To the best of our knowledge, this is the first analytical result for stochastic bandits with random graph feedback. Finally, using numerical evaluations, we demonstrate that our proposed IDS policies outperform existing approaches, including adaptions of upper confidence bound, $\epsilon$-greedy and Exp3 algorithms.
Tell Me Why You Feel That Way: Processing Compositional Dependency for Tree-LSTM Aspect Sentiment Triplet Extraction (TASTE)
Mar 10, 2021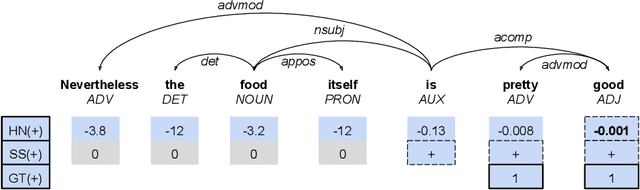
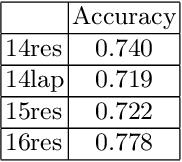
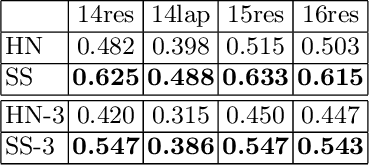
Sentiment analysis has transitioned from classifying the sentiment of an entire sentence to providing the contextual information of what targets exist in a sentence, what sentiment the individual targets have, and what the causal words responsible for that sentiment are. However, this has led to elaborate requirements being placed on the datasets needed to train neural networks on the joint triplet task of determining an entity, its sentiment, and the causal words for that sentiment. Requiring this kind of data for training systems is problematic, as they suffer from stacking subjective annotations and domain over-fitting leading to poor model generalisation when applied in new contexts. These problems are also likely to be compounded as we attempt to jointly determine additional contextual elements in the future. To mitigate these problems, we present a hybrid neural-symbolic method utilising a Dependency Tree-LSTM's compositional sentiment parse structure and complementary symbolic rules to correctly extract target-sentiment-cause triplets from sentences without the need for triplet training data. We show that this method has the potential to perform in line with state-of-the-art approaches while also simplifying the data required and providing a degree of interpretability through the Tree-LSTM.
Joint Active and Passive Beam Training for IRS-Assisted Millimeter Wave Systems
Mar 10, 2021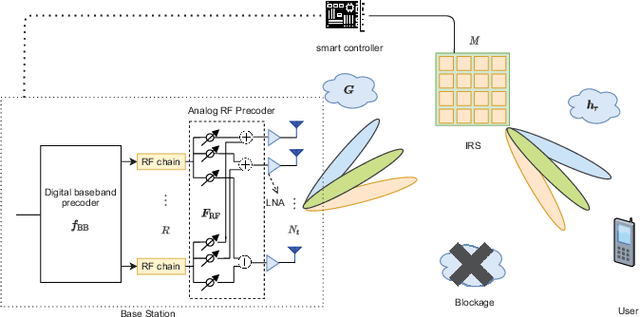

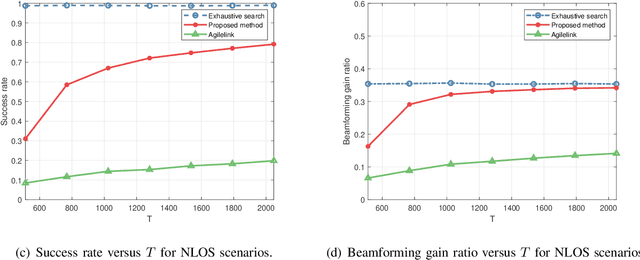
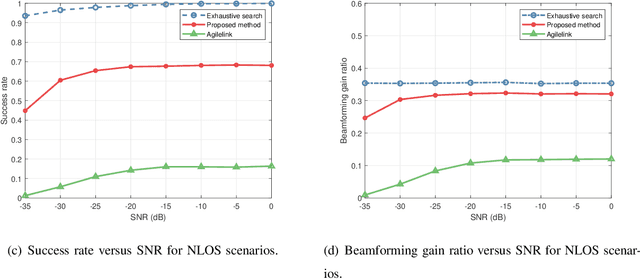
Intelligent reflecting surface (IRS) has emerged as a competitive solution to address blockage issues in millimeter wave (mmWave) and Terahertz (THz) communications due to its capability of reshaping wireless transmission environments. Nevertheless, obtaining the channel state information of IRS-assisted systems is quite challenging because of the passive characteristics of the IRS. In this paper, we consider the problem of beam training/alignment for IRS-assisted downlink mmWave/THz systems, where a multi-antenna base station (BS) with a hybrid structure serves a single-antenna user aided by IRS. By exploiting the inherent sparse structure of the BS-IRS-user cascade channel, the beam training problem is formulated as a joint sparse sensing and phaseless estimation problem, which involves devising a sparse sensing matrix and developing an efficient estimation algorithm to identify the best beam alignment from compressive phaseless measurements. Theoretical analysis reveals that the proposed method can identify the best alignment with only a modest amount of training overhead. Simulation results show that, for both line-of-sight (LOS) and NLOS scenarios, the proposed method obtains a significant performance improvement over existing state-of-art methods. Notably, it can achieve performance close to that of the exhaustive beam search scheme, while reducing the training overhead by 95%.
Teaching with Commentaries
Nov 05, 2020
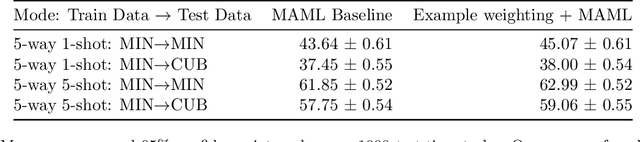
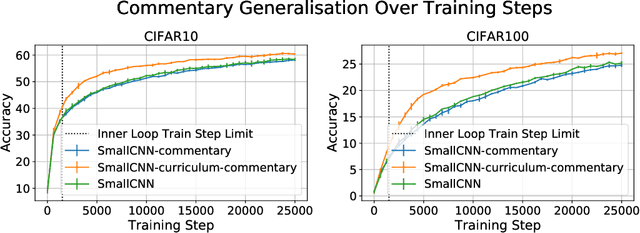

Effective training of deep neural networks can be challenging, and there remain many open questions on how to best learn these models. Recently developed methods to improve neural network training examine teaching: providing learned information during the training process to improve downstream model performance. In this paper, we take steps towards extending the scope of teaching. We propose a flexible teaching framework using commentaries, meta-learned information helpful for training on a particular task or dataset. We present an efficient and scalable gradient-based method to learn commentaries, leveraging recent work on implicit differentiation. We explore diverse applications of commentaries, from learning weights for individual training examples, to parameterizing label-dependent data augmentation policies, to representing attention masks that highlight salient image regions. In these settings, we find that commentaries can improve training speed and/or performance and also provide fundamental insights about the dataset and training process.
README: REpresentation learning by fairness-Aware Disentangling MEthod
Jul 07, 2020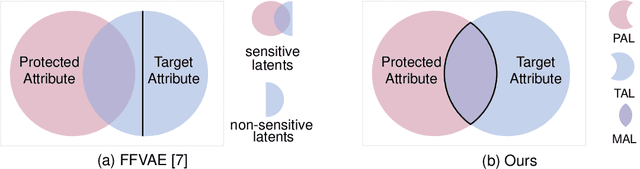

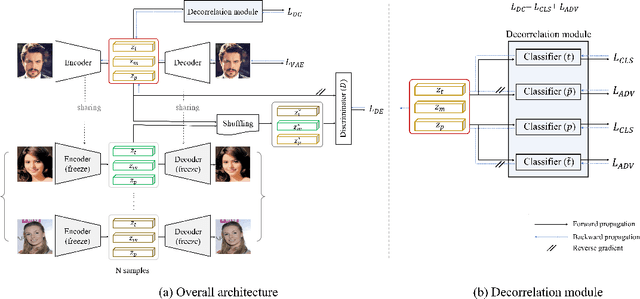
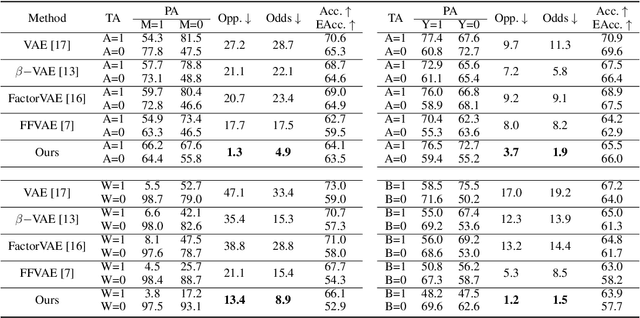
Fair representation learning aims to encode invariant representation with respect to the protected attribute, such as gender or age. In this paper, we design Fairness-aware Disentangling Variational AutoEncoder (FD-VAE) for fair representation learning. This network disentangles latent space into three subspaces with a decorrelation loss that encourages each subspace to contain independent information: 1) target attribute information, 2) protected attribute information, 3) mutual attribute information. After the representation learning, this disentangled representation is leveraged for fairer downstream classification by excluding the subspace with the protected attribute information. We demonstrate the effectiveness of our model through extensive experiments on CelebA and UTK Face datasets. Our method outperforms the previous state-of-the-art method by large margins in terms of equal opportunity and equalized odds.
Semi-Global Shape-aware Network
Dec 17, 2020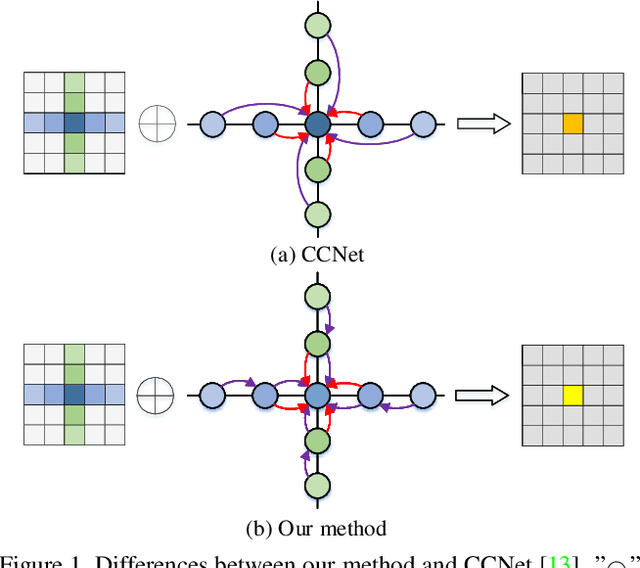

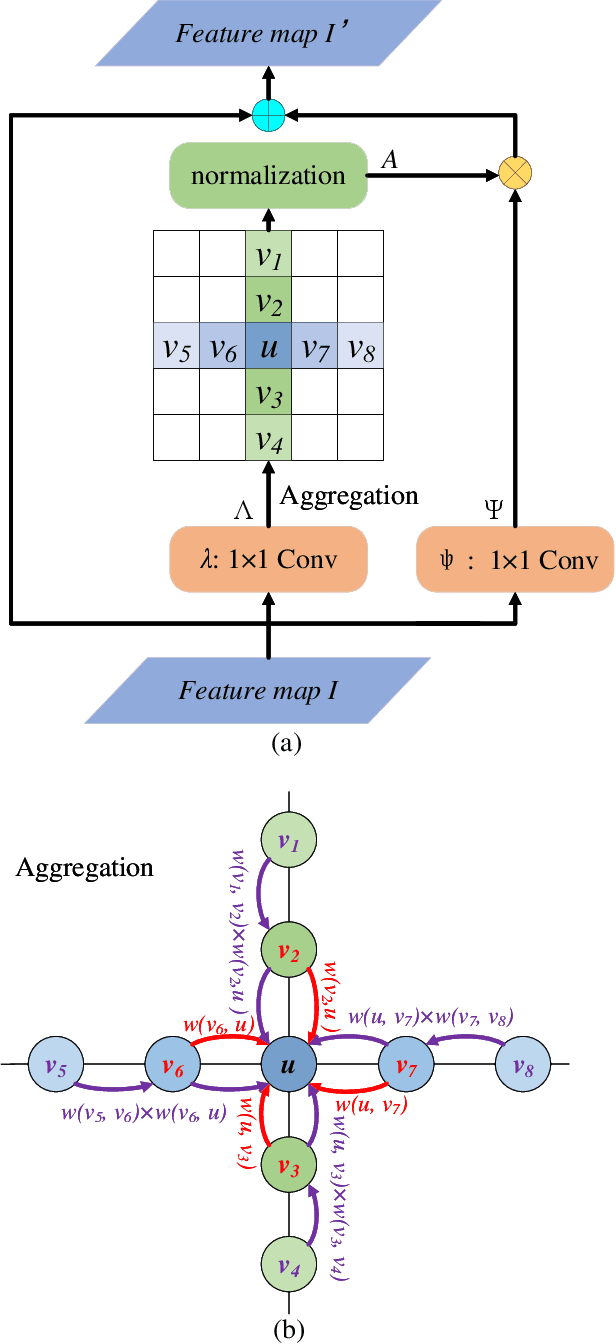
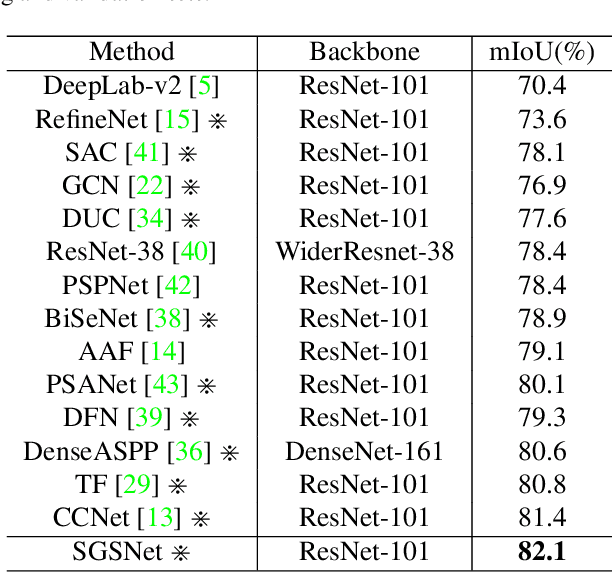
Non-local operations are usually used to capture long-range dependencies via aggregating global context to each position recently. However, most of the methods cannot preserve object shapes since they only focus on feature similarity but ignore proximity between central and other positions for capturing long-range dependencies, while shape-awareness is beneficial to many computer vision tasks. In this paper, we propose a Semi-Global Shape-aware Network (SGSNet) considering both feature similarity and proximity for preserving object shapes when modeling long-range dependencies. A hierarchical way is taken to aggregate global context. In the first level, each position in the whole feature map only aggregates contextual information in vertical and horizontal directions according to both similarity and proximity. And then the result is input into the second level to do the same operations. By this hierarchical way, each central position gains supports from all other positions, and the combination of similarity and proximity makes each position gain supports mostly from the same semantic object. Moreover, we also propose a linear time algorithm for the aggregation of contextual information, where each of rows and columns in the feature map is treated as a binary tree to reduce similarity computation cost. Experiments on semantic segmentation and image retrieval show that adding SGSNet to existing networks gains solid improvements on both accuracy and efficiency.