 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Constrained Learning with Non-Convex Losses
Mar 08, 2021
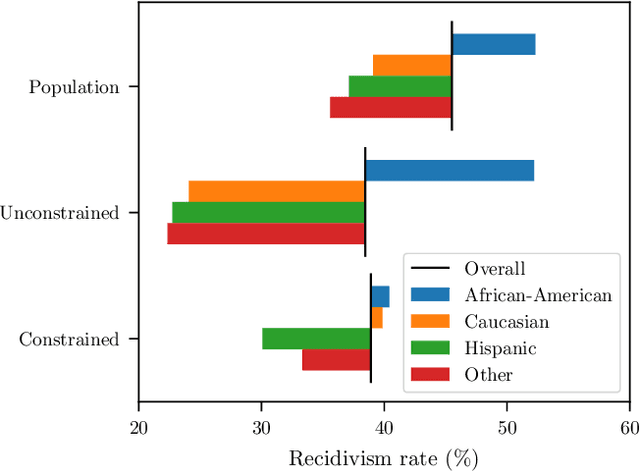
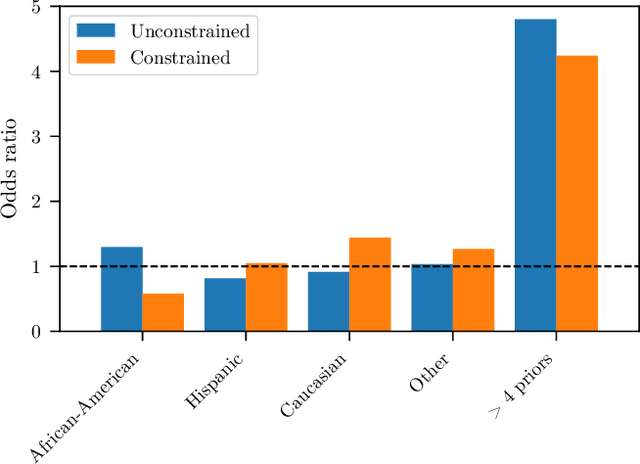
Though learning has become a core technology of modern information processing, there is now ample evidence that it can lead to biased, unsafe, and prejudiced solutions. The need to impose requirements on learning is therefore paramount, especially as it reaches critical applications in social, industrial, and medical domains. However, the non-convexity of most modern learning problems is only exacerbated by the introduction of constraints. Whereas good unconstrained solutions can often be learned using empirical risk minimization (ERM), even obtaining a model that satisfies statistical constraints can be challenging, all the more so a good one. In this paper, we overcome this issue by learning in the empirical dual domain, where constrained statistical learning problems become unconstrained, finite dimensional, and deterministic. We analyze the generalization properties of this approach by bounding the empirical duality gap, i.e., the difference between our approximate, tractable solution and the solution of the original (non-convex)~statistical problem, and provide a practical constrained learning algorithm. These results establish a constrained counterpart of classical learning theory and enable the explicit use of constraints in learning. We illustrate this algorithm and theory in rate-constrained learning applications.
Coarse-to-Fine Object Tracking Using Deep Features and Correlation Filters
Dec 23, 2020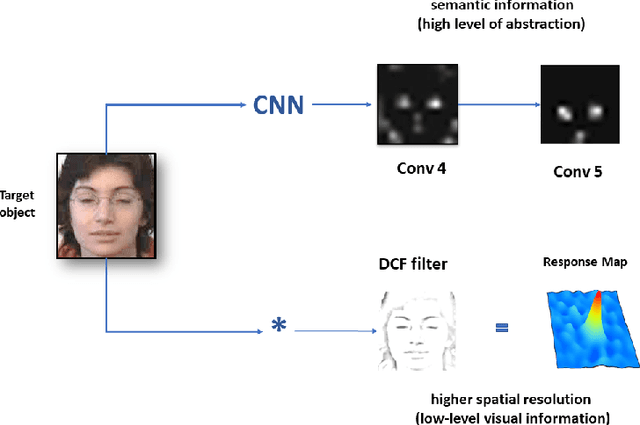
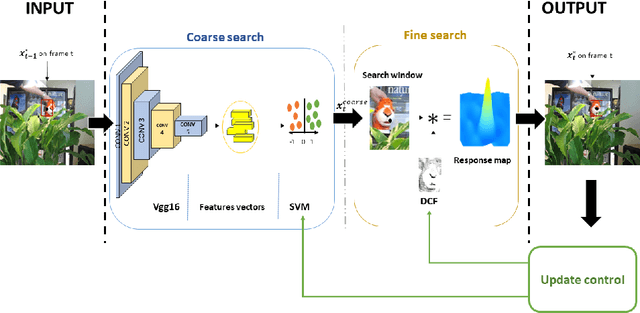
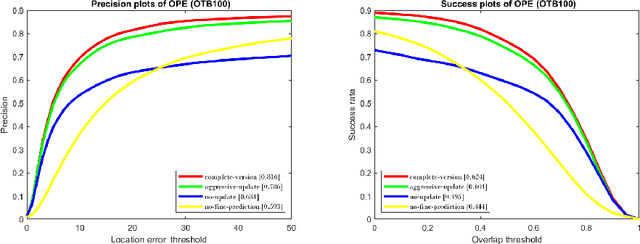
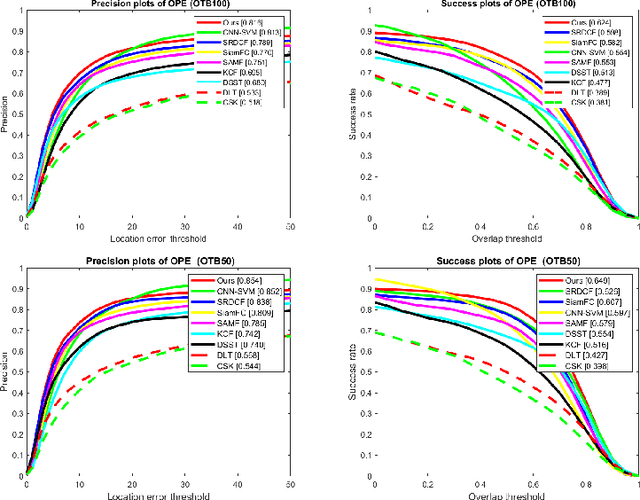
During the last years, deep learning trackers achieved stimulating results while bringing interesting ideas to solve the tracking problem. This progress is mainly due to the use of learned deep features obtained by training deep convolutional neural networks (CNNs) on large image databases. But since CNNs were originally developed for image classification, appearance modeling provided by their deep layers might be not enough discriminative for the tracking task. In fact,such features represent high-level information, that is more related to object category than to a specific instance of the object. Motivated by this observation, and by the fact that discriminative correlation filters(DCFs) may provide a complimentary low-level information, we presenta novel tracking algorithm taking advantage of both approaches. We formulate the tracking task as a two-stage procedure. First, we exploit the generalization ability of deep features to coarsely estimate target translation, while ensuring invariance to appearance change. Then, we capitalize on the discriminative power of correlation filters to precisely localize the tracked object. Furthermore, we designed an update control mechanism to learn appearance change while avoiding model drift. We evaluated the proposed tracker on object tracking benchmarks. Experimental results show the robustness of our algorithm, which performs favorably against CNN and DCF-based trackers. Code is available at: https://github.com/AhmedZgaren/Coarse-to-fine-Tracker
BURT: BERT-inspired Universal Representation from Learning Meaningful Segment
Dec 31, 2020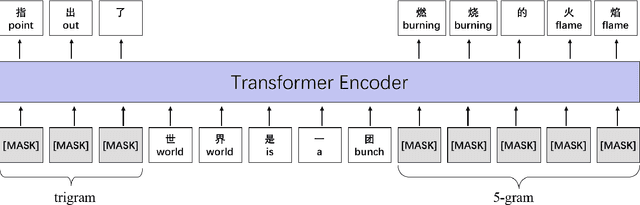
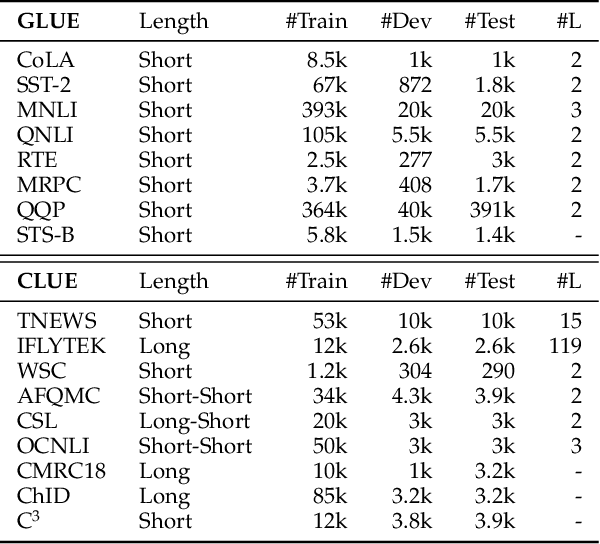
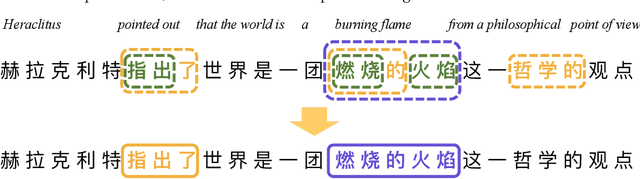
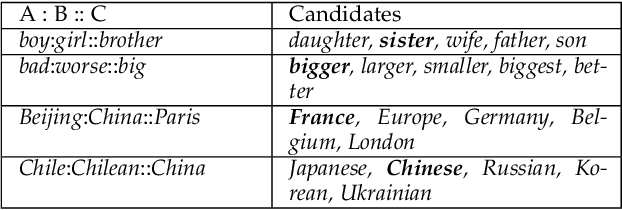
Although pre-trained contextualized language models such as BERT achieve significant performance on various downstream tasks, current language representation still only focuses on linguistic objective at a specific granularity, which may not applicable when multiple levels of linguistic units are involved at the same time. Thus this work introduces and explores the universal representation learning, i.e., embeddings of different levels of linguistic unit in a uniform vector space. We present a universal representation model, BURT (BERT-inspired Universal Representation from learning meaningful segmenT), to encode different levels of linguistic unit into the same vector space. Specifically, we extract and mask meaningful segments based on point-wise mutual information (PMI) to incorporate different granular objectives into the pre-training stage. We conduct experiments on datasets for English and Chinese including the GLUE and CLUE benchmarks, where our model surpasses its baselines and alternatives on a wide range of downstream tasks. We present our approach of constructing analogy datasets in terms of words, phrases and sentences and experiment with multiple representation models to examine geometric properties of the learned vector space through a task-independent evaluation. Finally, we verify the effectiveness of our unified pre-training strategy in two real-world text matching scenarios. As a result, our model significantly outperforms existing information retrieval (IR) methods and yields universal representations that can be directly applied to retrieval-based question-answering and natural language generation tasks.
Chinese Medical Question Answer Matching Based on Interactive Sentence Representation Learning
Nov 27, 2020
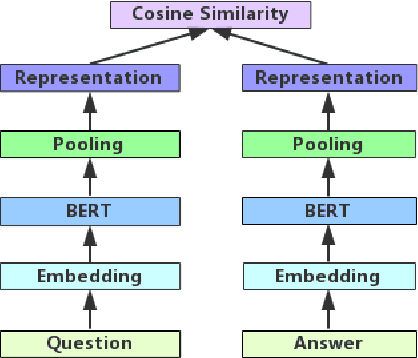
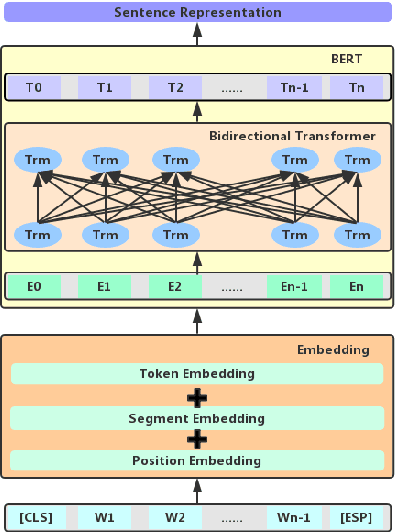

Chinese medical question-answer matching is more challenging than the open-domain question answer matching in English. Even though the deep learning method has performed well in improving the performance of question answer matching, these methods only focus on the semantic information inside sentences, while ignoring the semantic association between questions and answers, thus resulting in performance deficits. In this paper, we design a series of interactive sentence representation learning models to tackle this problem. To better adapt to Chinese medical question-answer matching and take the advantages of different neural network structures, we propose the Crossed BERT network to extract the deep semantic information inside the sentence and the semantic association between question and answer, and then combine with the multi-scale CNNs network or BiGRU network to take the advantage of different structure of neural networks to learn more semantic features into the sentence representation. The experiments on the cMedQA V2.0 and cMedQA V1.0 dataset show that our model significantly outperforms all the existing state-of-the-art models of Chinese medical question answer matching.
Semi-Supervised Off Policy Reinforcement Learning
Jan 21, 2021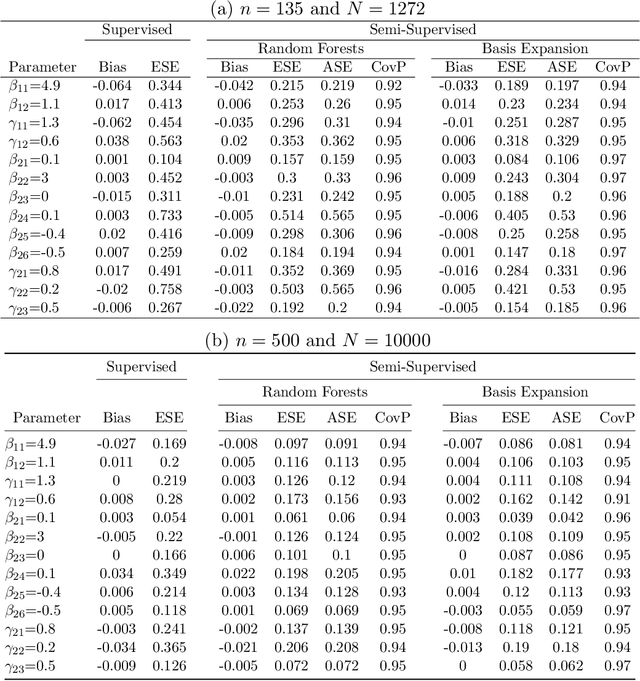
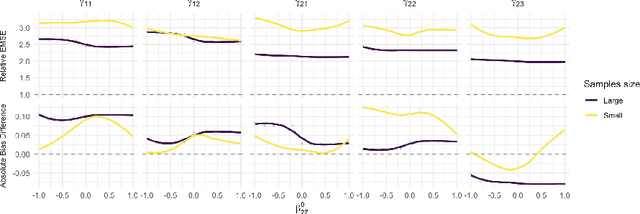
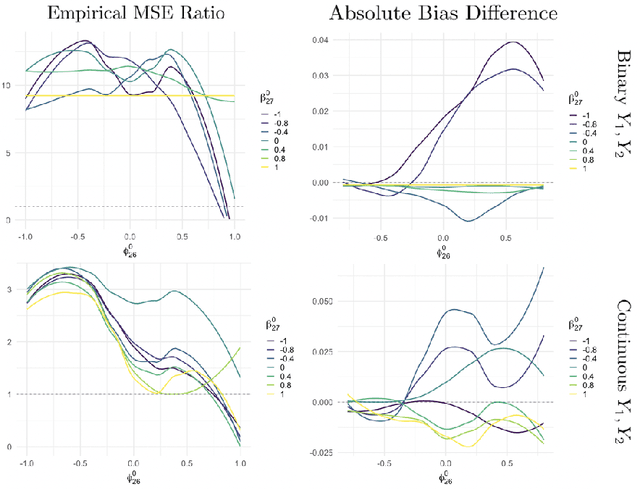
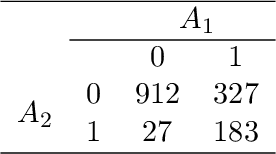
Reinforcement learning (RL) has shown great success in estimating sequential treatment strategies which account for patient heterogeneity. However, health-outcome information is often not well coded but rather embedded in clinical notes. Extracting precise outcome information is a resource intensive task. This translates into only small well-annotated cohorts available. We propose a semi-supervised learning (SSL) approach that can efficiently leverage a small sized labeled data $\mathcal{L}$ with true outcome observed, and a large sized unlabeled data $\mathcal{U}$ with outcome surrogates $\pmb W$. In particular we propose a theoretically justified SSL approach to Q-learning and develop a robust and efficient SSL approach to estimating the value function of the derived optimal STR, defined as the expected counterfactual outcome under the optimal STR. Generalizing SSL to learning STR brings interesting challenges. First, the feature distribution for predicting $Y_t$ is unknown in the $Q$-learning procedure, as it includes unknown $Y_{t-1}$ due to the sequential nature. Our methods for estimating optimal STR and its associated value function, carefully adapts to this sequentially missing data structure. Second, we modify the SSL framework to handle the use of surrogate variables $\pmb W$ which are predictive of the outcome through the joint law $\mathbb{P}_{Y,\pmb O,\pmb W}$, but are not part of the conditional distribution of interest $\mathbb{P}_{Y|\pmb O}$. We provide theoretical results to understand when and to what degree efficiency can be gained from $\pmb W$ and $\pmb O$. Our approach is robust to misspecification of the imputation models. Further, we provide a doubly robust value function estimator for the derived STR. If either the Q functions or the propensity score functions are correctly specified, our value function estimators are consistent for the true value function.
Bayesian Federated Learning over Wireless Networks
Dec 31, 2020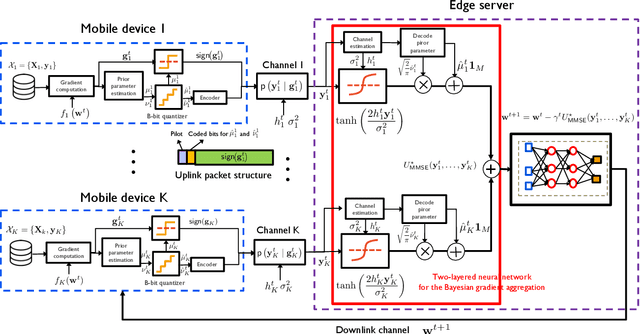
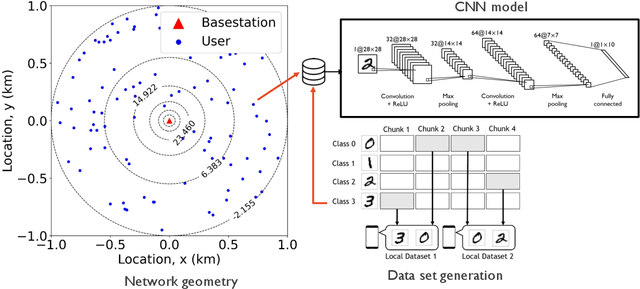
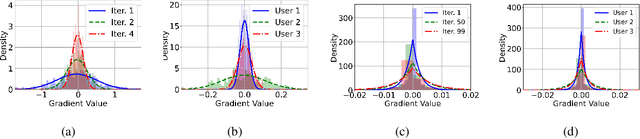
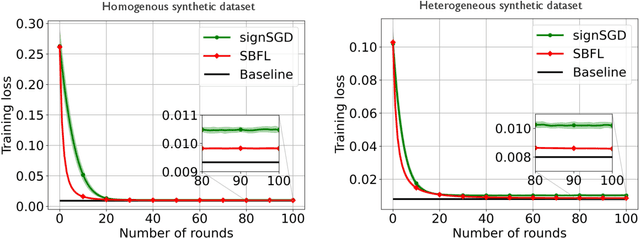
Federated learning is a privacy-preserving and distributed training method using heterogeneous data sets stored at local devices. Federated learning over wireless networks requires aggregating locally computed gradients at a server where the mobile devices send statistically distinct gradient information over heterogenous communication links. This paper proposes a Bayesian federated learning (BFL) algorithm to aggregate the heterogeneous quantized gradient information optimally in the sense of minimizing the mean-squared error (MSE). The idea of BFL is to aggregate the one-bit quantized local gradients at the server by jointly exploiting i) the prior distributions of the local gradients, ii) the gradient quantizer function, and iii) channel distributions. Implementing BFL requires high communication and computational costs as the number of mobile devices increases. To address this challenge, we also present an efficient modified BFL algorithm called scalable-BFL (SBFL). In SBFL, we assume a simplified distribution on the local gradient. Each mobile device sends its one-bit quantized local gradient together with two scalar parameters representing this distribution. The server then aggregates the noisy and faded quantized gradients to minimize the MSE. We provide a convergence analysis of SBFL for a class of non-convex loss functions. Our analysis elucidates how the parameters of communication channels and the gradient priors affect convergence. From simulations, we demonstrate that SBFL considerably outperforms the conventional sign stochastic gradient descent algorithm when training and testing neural networks using MNIST data sets over heterogeneous wireless networks.
Cognitive architecture aided by working-memory for self-supervised multi-modal humans recognition
Mar 16, 2021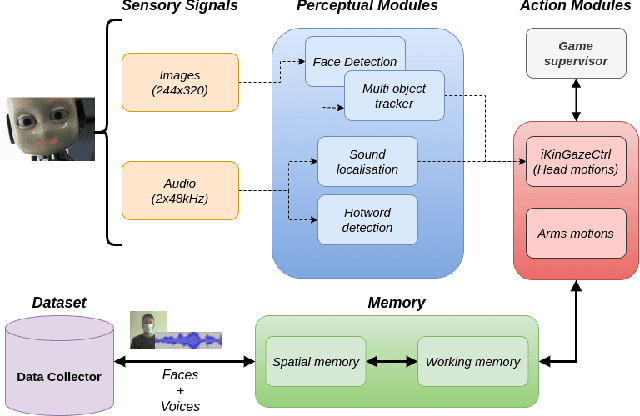
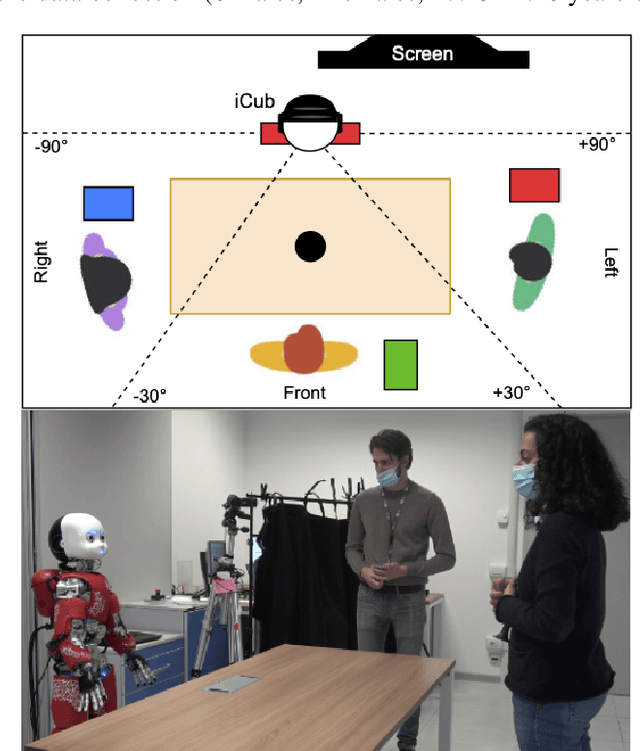
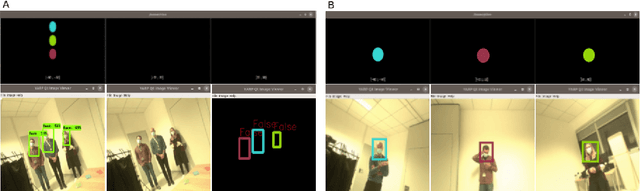
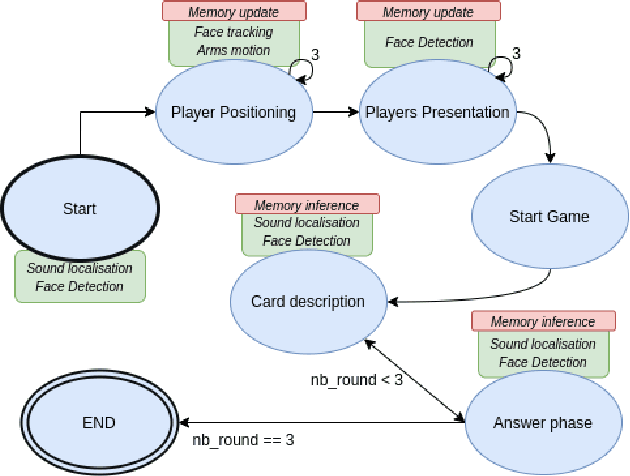
The ability to recognize human partners is an important social skill to build personalized and long-term human-robot interactions, especially in scenarios like education, care-giving, and rehabilitation. Faces and voices constitute two important sources of information to enable artificial systems to reliably recognize individuals. Deep learning networks have achieved state-of-the-art results and demonstrated to be suitable tools to address such a task. However, when those networks are applied to different and unprecedented scenarios not included in the training set, they can suffer a drop in performance. For example, with robotic platforms in ever-changing and realistic environments, where always new sensory evidence is acquired, the performance of those models degrades. One solution is to make robots learn from their first-hand sensory data with self-supervision. This allows coping with the inherent variability of the data gathered in realistic and interactive contexts. To this aim, we propose a cognitive architecture integrating low-level perceptual processes with a spatial working memory mechanism. The architecture autonomously organizes the robot's sensory experience into a structured dataset suitable for human recognition. Our results demonstrate the effectiveness of our architecture and show that it is a promising solution in the quest of making robots more autonomous in their learning process.
Non-linear frequency warping using constant-Q transformation for speech emotion recognition
Feb 08, 2021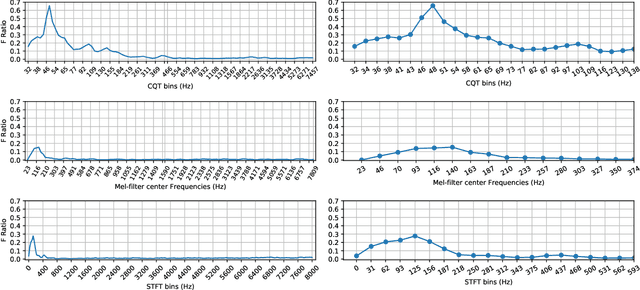
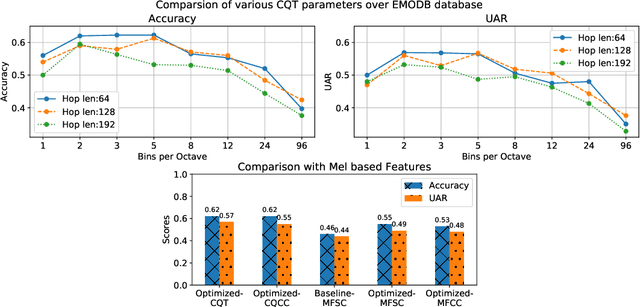

In this work, we explore the constant-Q transform (CQT) for speech emotion recognition (SER). The CQT-based time-frequency analysis provides variable spectro-temporal resolution with higher frequency resolution at lower frequencies. Since lower-frequency regions of speech signal contain more emotion-related information than higher-frequency regions, the increased low-frequency resolution of CQT makes it more promising for SER than standard short-time Fourier transform (STFT). We present a comparative analysis of short-term acoustic features based on STFT and CQT for SER with deep neural network (DNN) as a back-end classifier. We optimize different parameters for both features. The CQT-based features outperform the STFT-based spectral features for SER experiments. Further experiments with cross-corpora evaluation demonstrate that the CQT-based systems provide better generalization with out-of-domain training data.
FBMC Receiver Design and Analysis for Medium and Large Scale Antenna Systems
Mar 23, 2021
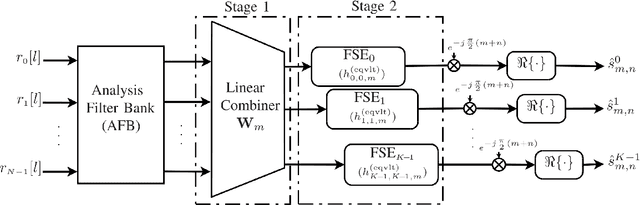
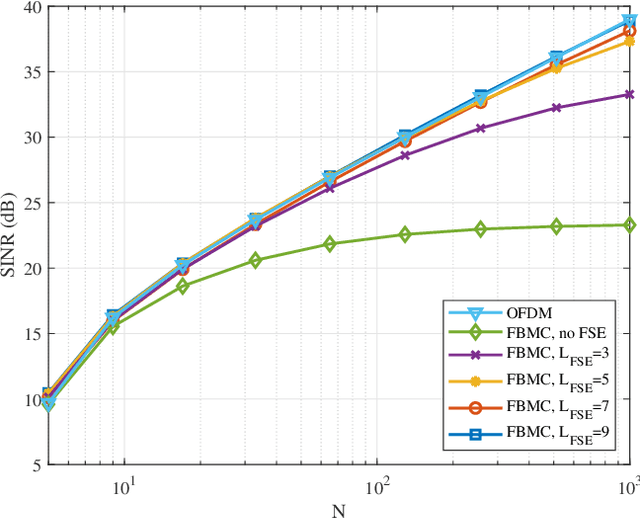
In this paper, we design receivers for filter bank multicarrier-based (FBMC-based) massive MIMO considering practical aspects such as channel estimation and equalization. In particular, we propose a spectrally efficient pilot structure and a channel estimation technique in the uplink to jointly estimate all the users' channel impulse responses. We mathematically analyze our proposed channel estimator and find the statistics of the channel estimation errors. These statistics are incorporated into our proposed equalizers to deal with the imperfect channel state information (CSI) effect. We revisit the channel equalization problem for FBMC-based massive MIMO, address the shortcomings of the existing equalizers in the literature, and make them more applicable to practical scenarios. The proposed receiver in this paper consists of two stages. In the first stage, a linear combining of the received signals at the base station (BS) antennas provides a coarse channel equalization and removes any multiuser interference. In the second stage, a per subcarrier fractionally spaced equalizer (FSE) takes care of any residual distortion of the channel for the user of interest. We propose an FSE design based on the equivalent channel at the linear combiner output. This enables the applicability of our proposed technique to small and/or distributed antenna setups such as cell-free massive MIMO. Finally, the efficacy of the proposed techniques is corroborated through numerical analysis.
Multi-Source Domain Adaptation with Collaborative Learning for Semantic Segmentation
Mar 16, 2021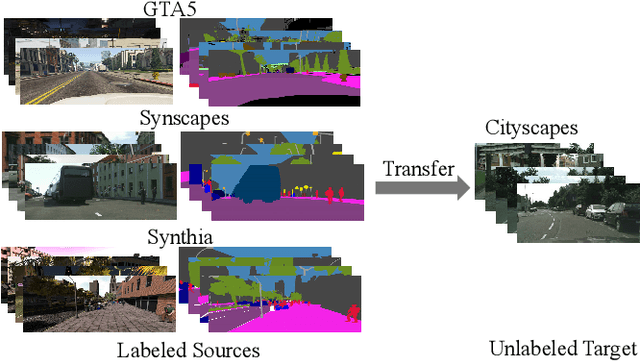
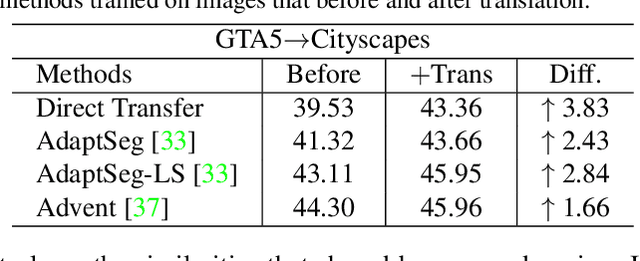
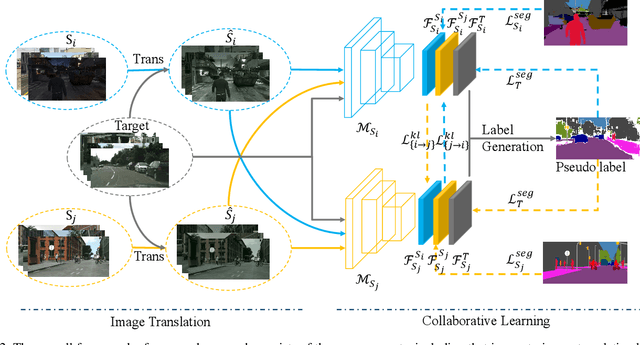
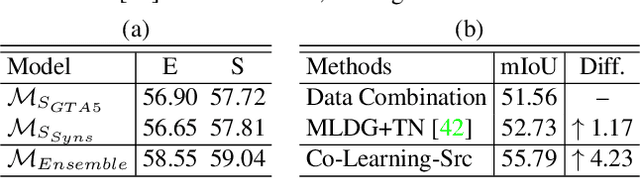
Multi-source unsupervised domain adaptation~(MSDA) aims at adapting models trained on multiple labeled source domains to an unlabeled target domain. In this paper, we propose a novel multi-source domain adaptation framework based on collaborative learning for semantic segmentation. Firstly, a simple image translation method is introduced to align the pixel value distribution to reduce the gap between source domains and target domain to some extent. Then, to fully exploit the essential semantic information across source domains, we propose a collaborative learning method for domain adaptation without seeing any data from target domain. In addition, similar to the setting of unsupervised domain adaptation, unlabeled target domain data is leveraged to further improve the performance of domain adaptation. This is achieved by additionally constraining the outputs of multiple adaptation models with pseudo labels online generated by an ensembled model. Extensive experiments and ablation studies are conducted on the widely-used domain adaptation benchmark datasets in semantic segmentation. Our proposed method achieves 59.0\% mIoU on the validation set of Cityscapes by training on the labeled Synscapes and GTA5 datasets and unlabeled training set of Cityscapes. It significantly outperforms all previous state-of-the-arts single-source and multi-source unsupervised domain adaptation methods.