 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Debiasing Evaluations That are Biased by Evaluations
Dec 01, 2020
It is common to evaluate a set of items by soliciting people to rate them. For example, universities ask students to rate the teaching quality of their instructors, and conference organizers ask authors of submissions to evaluate the quality of the reviews. However, in these applications, students often give a higher rating to a course if they receive higher grades in a course, and authors often give a higher rating to the reviews if their papers are accepted to the conference. In this work, we call these external factors the "outcome" experienced by people, and consider the problem of mitigating these outcome-induced biases in the given ratings when some information about the outcome is available. We formulate the information about the outcome as a known partial ordering on the bias. We propose a debiasing method by solving a regularized optimization problem under this ordering constraint, and also provide a carefully designed cross-validation method that adaptively chooses the appropriate amount of regularization. We provide theoretical guarantees on the performance of our algorithm, as well as experimental evaluations.
Deep encoding of etymological information in TEI
Nov 30, 2016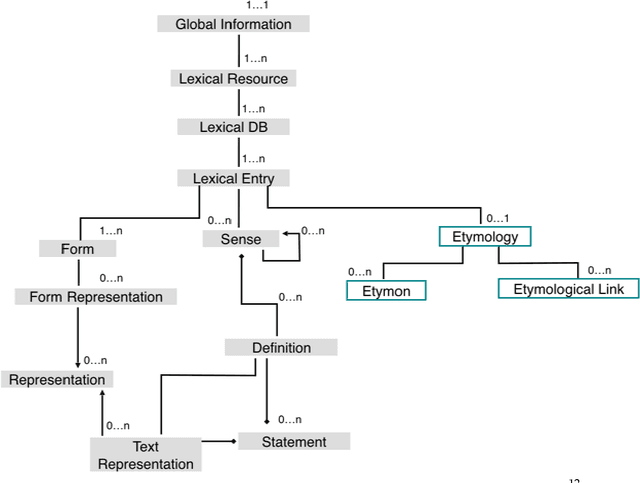
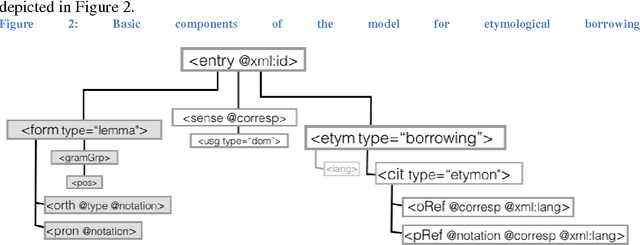
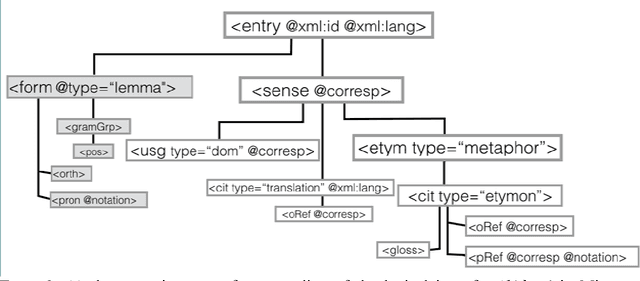
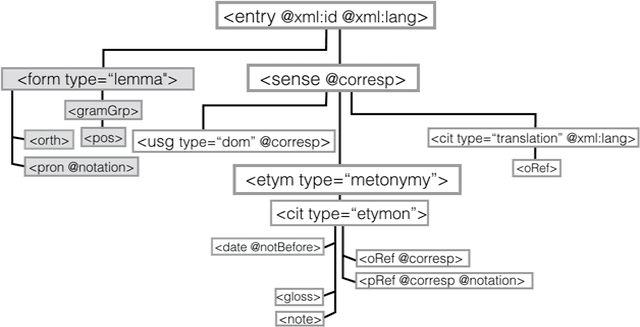
This paper aims to provide a comprehensive modeling and representation of etymological data in digital dictionaries. The purpose is to integrate in one coherent framework both digital representations of legacy dictionaries, and also born-digital lexical databases that are constructed manually or semi-automatically. We want to propose a systematic and coherent set of modeling principles for a variety of etymological phenomena that may contribute to the creation of a continuum between existing and future lexical constructs, where anyone interested in tracing the history of words and their meanings will be able to seamlessly query lexical resources.Instead of designing an ad hoc model and representation language for digital etymological data, we will focus on identifying all the possibilities offered by the TEI guidelines for the representation of lexical information.
Graph Convolution for Semi-Supervised Classification: Improved Linear Separability and Out-of-Distribution Generalization
Feb 22, 2021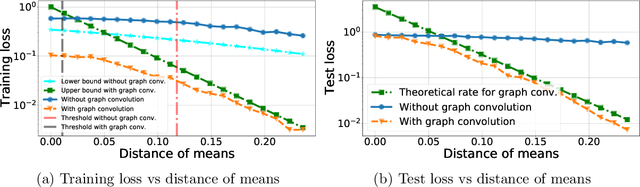
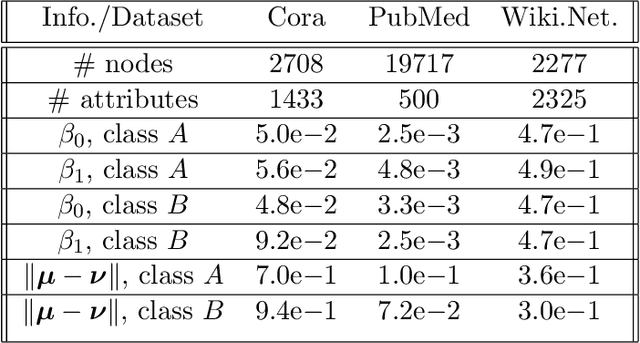
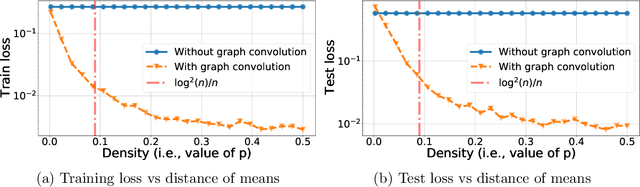
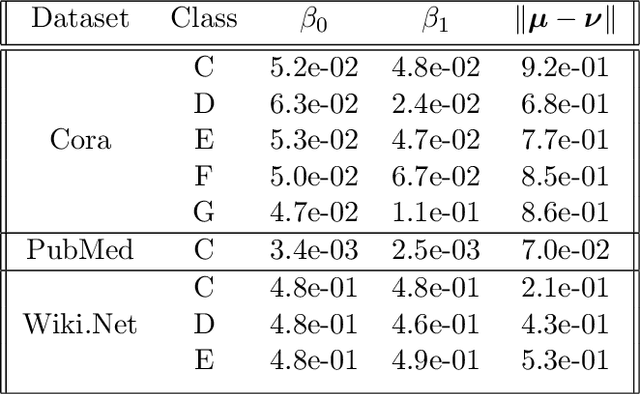
Recently there has been increased interest in semi-supervised classification in the presence of graphical information. A new class of learning models has emerged that relies, at its most basic level, on classifying the data after first applying a graph convolution. To understand the merits of this approach, we study the classification of a mixture of Gaussians, where the data corresponds to the node attributes of a stochastic block model. We show that graph convolution extends the regime in which the data is linearly separable by a factor of roughly $1/\sqrt{D}$, where $D$ is the expected degree of a node, as compared to the mixture model data on its own. Furthermore, we find that the linear classifier obtained by minimizing the cross-entropy loss after the graph convolution generalizes to out-of-distribution data where the unseen data can have different intra- and inter-class edge probabilities from the training data.
Residual Recurrent CRNN for End-to-End Optical Music Recognition on Monophonic Scores
Oct 26, 2020
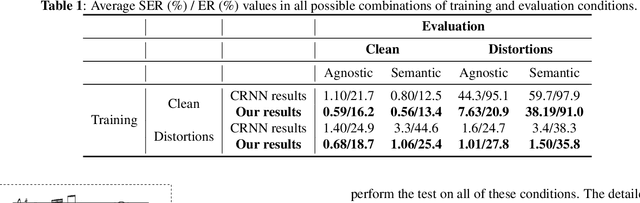

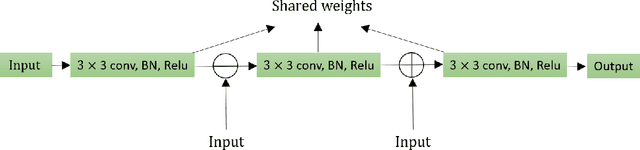
Optical Music Recognition is a field that attempts to extract digital information from images of either the printed music scores or the handwritten music scores. One of the challenges of the Optical Music Recognition task is to transcript the symbols of the camera-captured images into digital music notations. Previous end-to-end model, based on deep learning, was developed as a Convolutional Recurrent Neural Network. However, it does not explore sufficient contextual information from full scales and there is still a large room for improvement. In this paper, we propose an innovative end-to-end framework that combines a block of Residual Recurrent Convolutional Neural Network with a recurrent Encoder-Decoder network to map a sequence of monophonic music symbols corresponding to the notations present in the image. The Residual Recurrent Convolutional block can improve the ability of the model to enrich the context information while the number of parameter will not be increasing. The experiment results were benchmarked against a publicly available dataset called CAMERA-PRIMUS. We evaluate the performances of our model on both the images with ideal conditions and that with non-ideal conditions. The experiments show that our approach surpass the state-of-the-art end-to-end method using Convolutional Recurrent Neural Network.
Spectral Decomposition in Deep Networks for Segmentation of Dynamic Medical Images
Sep 30, 2020
Dynamic contrast-enhanced magnetic resonance imaging (DCE- MRI) is a widely used multi-phase technique routinely used in clinical practice. DCE and similar datasets of dynamic medical data tend to contain redundant information on the spatial and temporal components that may not be relevant for detection of the object of interest and result in unnecessarily complex computer models with long training times that may also under-perform at test time due to the abundance of noisy heterogeneous data. This work attempts to increase the training efficacy and performance of deep networks by determining redundant information in the spatial and spectral components and show that the performance of segmentation accuracy can be maintained and potentially improved. Reported experiments include the evaluation of training/testing efficacy on a heterogeneous dataset composed of abdominal images of pediatric DCE patients, showing that drastic data reduction (higher than 80%) can preserve the dynamic information and performance of the segmentation model, while effectively suppressing noise and unwanted portion of the images.
Adversarial Shape Learning for Building Extraction in VHR Remote Sensing Images
Feb 22, 2021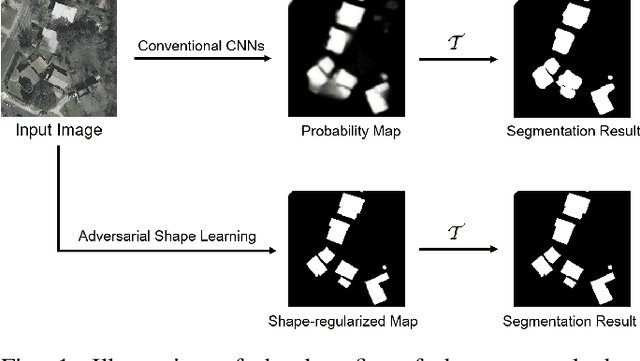
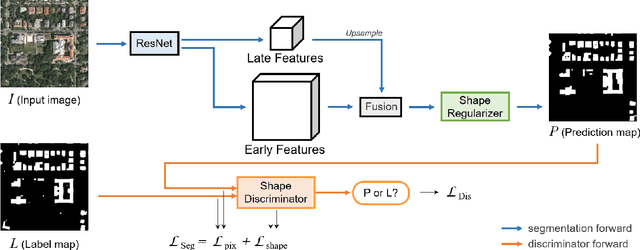
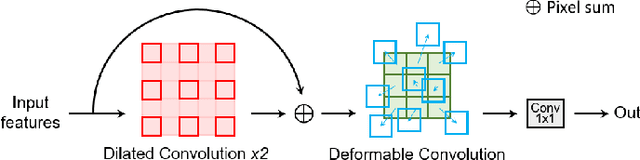
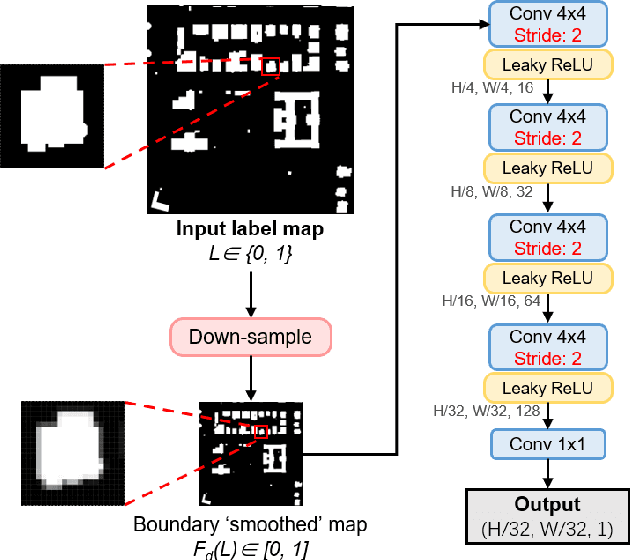
Building extraction in VHR RSIs remains to be a challenging task due to occlusion and boundary ambiguity problems. Although conventional convolutional neural networks (CNNs) based methods are capable of exploiting local texture and context information, they fail to capture the shape patterns of buildings, which is a necessary constraint in the human recognition. In this context, we propose an adversarial shape learning network (ASLNet) to model the building shape patterns, thus improving the accuracy of building segmentation. In the proposed ASLNet, we introduce the adversarial learning strategy to explicitly model the shape constraints, as well as a CNN shape regularizer to strengthen the embedding of shape features. To assess the geometric accuracy of building segmentation results, we further introduced several object-based assessment metrics. Experiments on two open benchmark datasets show that the proposed ASLNet improves both the pixel-based accuracy and the object-based measurements by a large margin. The code is available at: https://github.com/ggsDing/ASLNet
Robust Bandit Learning with Imperfect Context
Mar 04, 2021
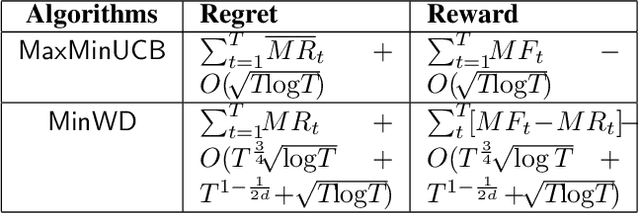
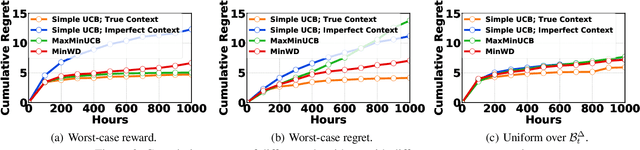

A standard assumption in contextual multi-arm bandit is that the true context is perfectly known before arm selection. Nonetheless, in many practical applications (e.g., cloud resource management), prior to arm selection, the context information can only be acquired by prediction subject to errors or adversarial modification. In this paper, we study a contextual bandit setting in which only imperfect context is available for arm selection while the true context is revealed at the end of each round. We propose two robust arm selection algorithms: MaxMinUCB (Maximize Minimum UCB) which maximizes the worst-case reward, and MinWD (Minimize Worst-case Degradation) which minimizes the worst-case regret. Importantly, we analyze the robustness of MaxMinUCB and MinWD by deriving both regret and reward bounds compared to an oracle that knows the true context. Our results show that as time goes on, MaxMinUCB and MinWD both perform as asymptotically well as their optimal counterparts that know the reward function. Finally, we apply MaxMinUCB and MinWD to online edge datacenter selection, and run synthetic simulations to validate our theoretical analysis.
Lightweight, Dynamic Graph Convolutional Networks for AMR-to-Text Generation
Oct 09, 2020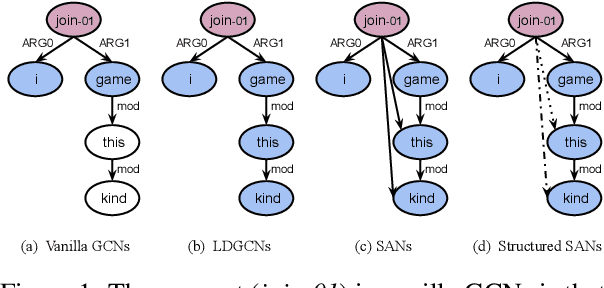
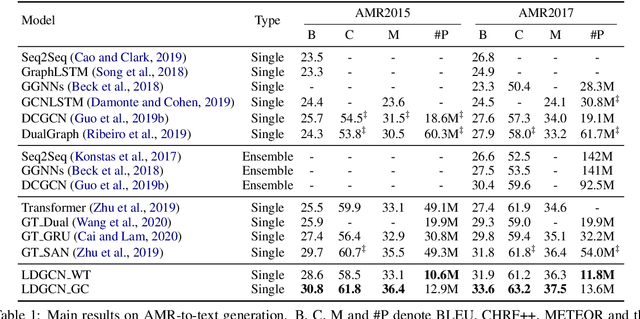
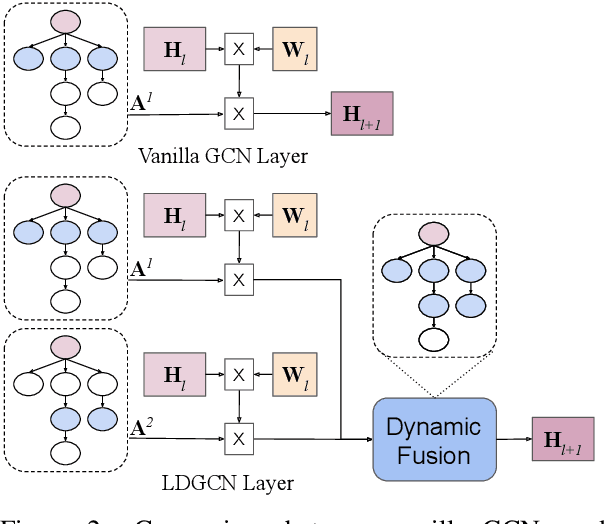
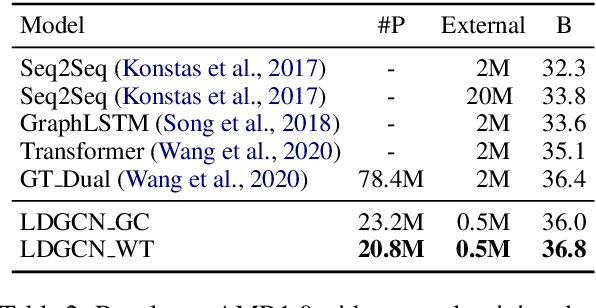
AMR-to-text generation is used to transduce Abstract Meaning Representation structures (AMR) into text. A key challenge in this task is to efficiently learn effective graph representations. Previously, Graph Convolution Networks (GCNs) were used to encode input AMRs, however, vanilla GCNs are not able to capture non-local information and additionally, they follow a local (first-order) information aggregation scheme. To account for these issues, larger and deeper GCN models are required to capture more complex interactions. In this paper, we introduce a dynamic fusion mechanism, proposing Lightweight Dynamic Graph Convolutional Networks (LDGCNs) that capture richer non-local interactions by synthesizing higher order information from the input graphs. We further develop two novel parameter saving strategies based on the group graph convolutions and weight tied convolutions to reduce memory usage and model complexity. With the help of these strategies, we are able to train a model with fewer parameters while maintaining the model capacity. Experiments demonstrate that LDGCNs outperform state-of-the-art models on two benchmark datasets for AMR-to-text generation with significantly fewer parameters.
An Improvement of Object Detection Performance using Multi-step Machine Learnings
Jan 19, 2021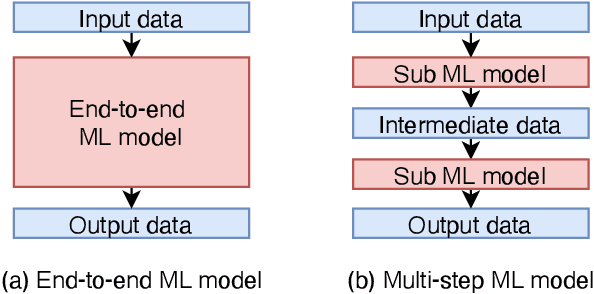


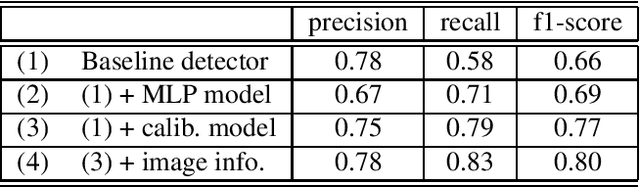
Connecting multiple machine learning models into a pipeline is effective for handling complex problems. By breaking down the problem into steps, each tackled by a specific component model of the pipeline, the overall solution can be made accurate and explainable. This paper describes an enhancement of object detection based on this multi-step concept, where a post-processing step called the calibration model is introduced. The calibration model consists of a convolutional neural network, and utilizes rich contextual information based on the domain knowledge of the input. Improvements of object detection performance by 0.8-1.9 in average precision metric over existing object detectors have been observed using the new model.
Hybrid Interference Mitigation Using Analog Prewhitening
Mar 04, 2021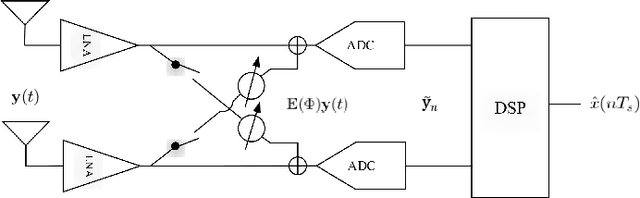
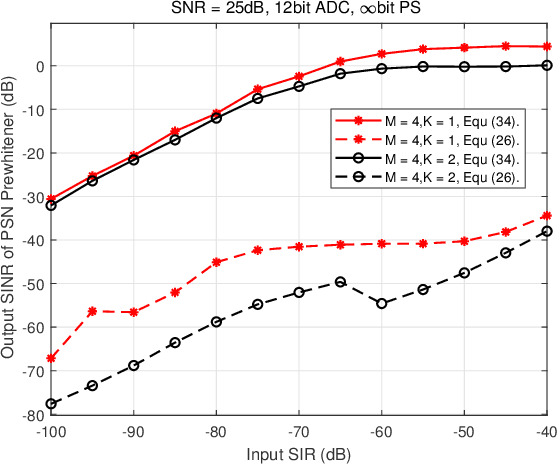
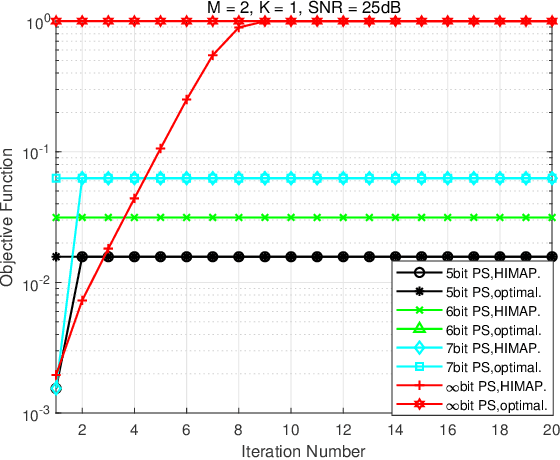
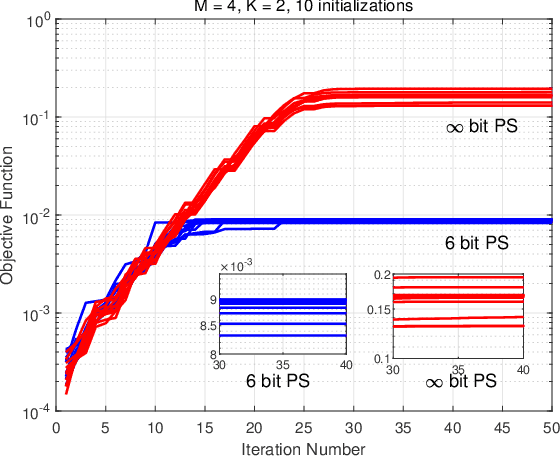
This paper proposes a novel scheme for mitigating strong interferences, which is applicable to various wireless scenarios, including full-duplex wireless communications and uncoordinated heterogenous networks. As strong interferences can saturate the receiver's analog-to-digital converters (ADC), they need to be mitigated both before and after the ADCs, i.e., via hybrid processing. The key idea of the proposed scheme, namely the Hybrid Interference Mitigation using Analog Prewhitening (HIMAP), is to insert an M-input M-output analog phase shifter network (PSN) between the receive antennas and the ADCs to spatially prewhiten the interferences, which requires no signal information but only an estimate of the covariance matrix. After interference mitigation by the PSN prewhitener, the preamble can be synchronized, the signal channel response can be estimated, and thus a minimum mean squared error (MMSE) beamformer can be applied in the digital domain to further mitigate the residual interferences. The simulation results verify that the HIMAP scheme can suppress interferences 80dB stronger than the signal by using off-the-shelf phase shifters (PS) of 6-bit resolution.