 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Phenotyping Clusters of Patient Trajectories suffering from Chronic Complex Disease
Nov 17, 2020
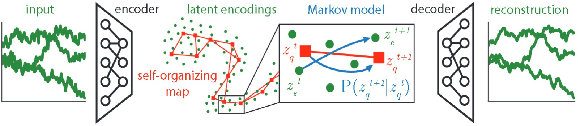
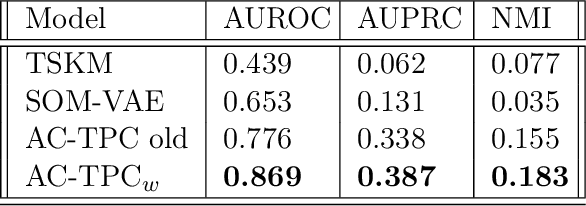
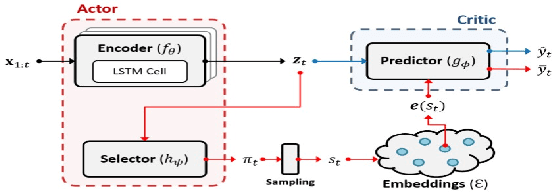
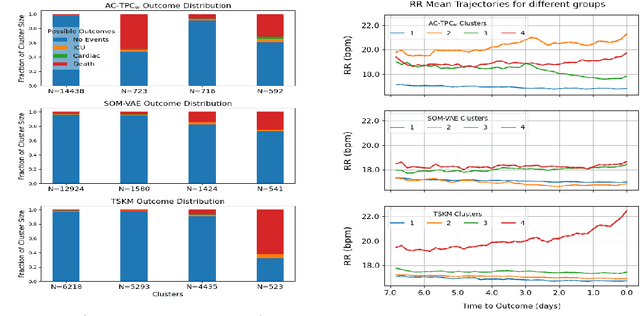
Recent years have seen an increased focus into the tasks of predicting hospital inpatient risk of deterioration and trajectory evolution due to the availability of electronic patient data. A common approach to these problems involves clustering patients time-series information such as vital sign observations) to determine dissimilar subgroups of the patient population. Most clustering methods assume time-invariance of vital-signs and are unable to provide interpretability in clusters that is clinically relevant, for instance, event or outcome information. In this work, we evaluate three different clustering models on a large hospital dataset of vital-sign observations from patients suffering from Chronic Obstructive Pulmonary Disease. We further propose novel modifications to deal with unevenly sampled time-series data and unbalanced class distribution to improve phenotype separation. Lastly, we discuss further avenues of investigation for models to learn patient subgroups with distinct behaviour and phenotype.
Reinforcement Learning Trajectory Generation and Control for Aggressive Perching on Vertical Walls with Quadrotors
Mar 04, 2021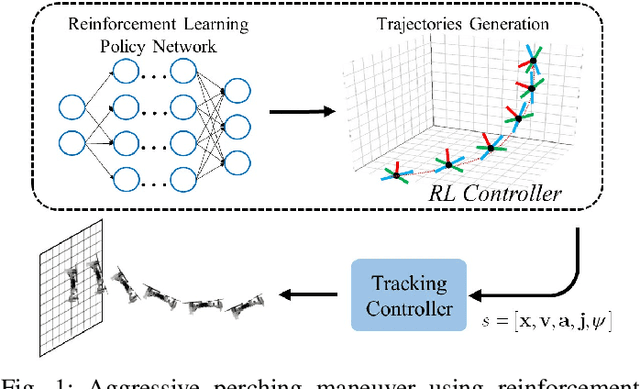
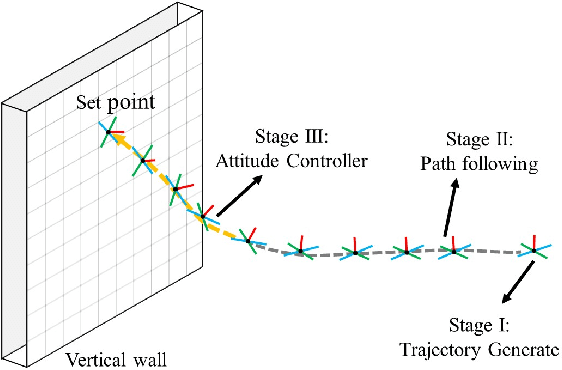
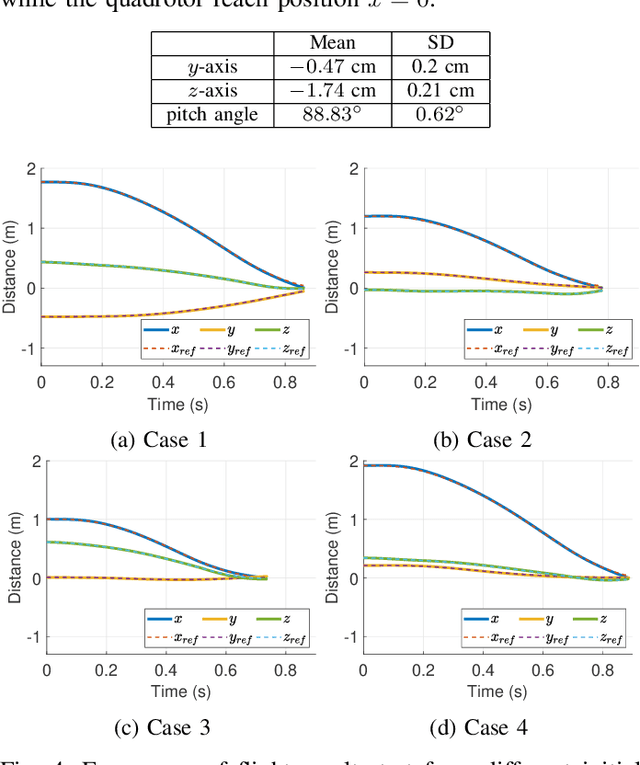
Micro aerial vehicles are widely being researched and employed due to their relative low operation costs and high flexibility in various applications. We study the under-actuated quadrotor perching problem, designing a trajectory planner and controller which generates feasible trajectories and drives quadrotors to desired state in state space. This paper proposes a trajectory generating and tracking method for quadrotor perching that takes the advantages of reinforcement learning controller and traditional controller. The trained low-level reinforcement learning controller would manipulate quadrotor toward the perching point in simulation environment. Once the simulated quadrotor has successfully perched, the relative trajectory information in simulation will be sent to tracking controller on real quadrotor and start the actual perching task. Generating feasible trajectories via the trained reinforcement learning controller requires less time, and the traditional trajectory tracking controller could easily be modified to control the quadrotor and mathematically analysis its stability and robustness. We show that this approach permits the control structure of trajectories and controllers enabling such aggressive maneuvers perching on vertical surfaces with high precision.
High Data Rate Near-Ultrasonic Communication with Consumer Devices
Mar 20, 2021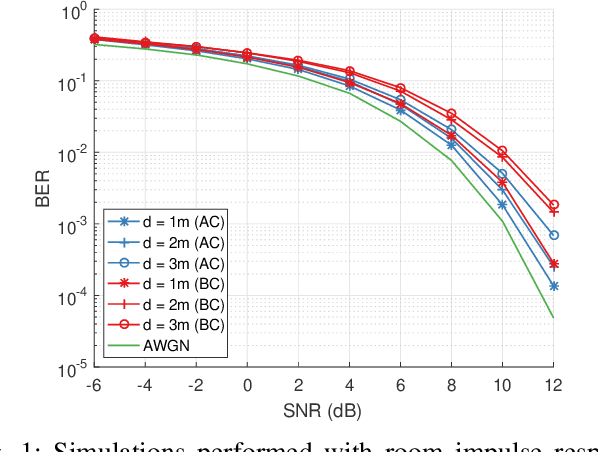
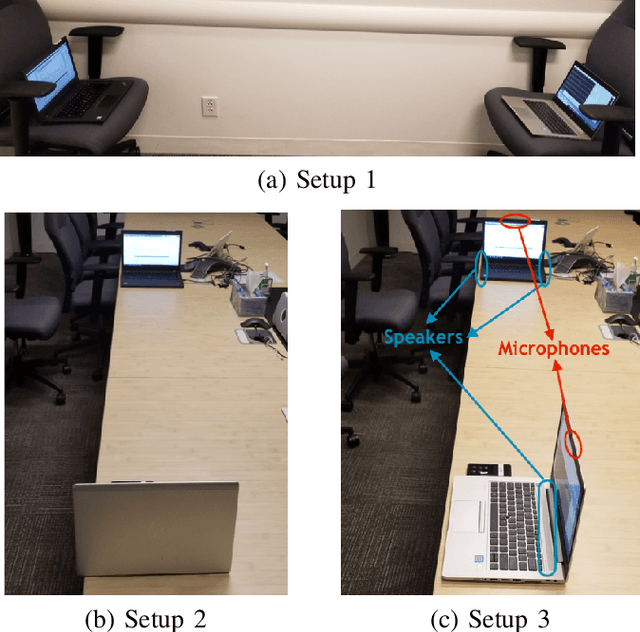
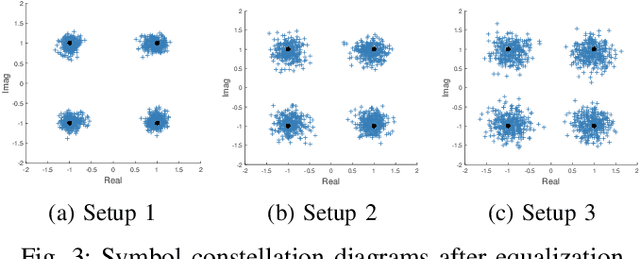
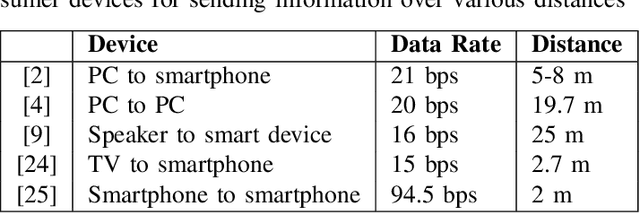
Automating device pairing and credential exchange in consumer devices reduce the time users spend with mundane tasks and improve the user experience. Acoustic communication is gaining traction as a practical alternative to Bluetooth or Wi-Fi because it can enable quick and localized information transfer between consumer devices with built-in hardware. However, achieving high data rates (>1 kbps) in such systems has been a challenge because the systems and methods chosen for communication were not tailored to the application. In this work, a high data rate, near-ultrasonic communication (NUSC) system is proposed to transfer personal identification numbers (PINs) to establish a connection between consumer laptops using built-in microphones and speakers. The similarities between indoor near-ultrasonic and underwater acoustic communication (UWAC) channels are identified, and appropriate UWAC techniques are tailored to the NUSC system. The proposed system uses the near-ultrasonic band at 18-20 kHz, and employs coherent modulation and phase-coherent adaptive equalization. The capability of the proposed system is explored in simulated and field experiments that span different device orientations and distances. The experiments demonstrate data rates of 4 kbps over distances of up to 5 meters, which is an order of magnitude higher than the data rates reported with similar systems in the literature.
Multimodal data visualization, denoising and clustering with integrated diffusion
Feb 12, 2021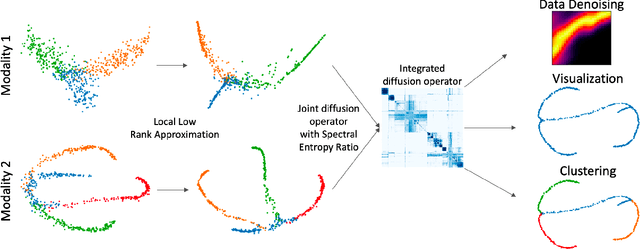
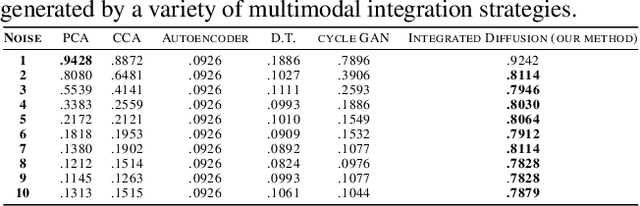

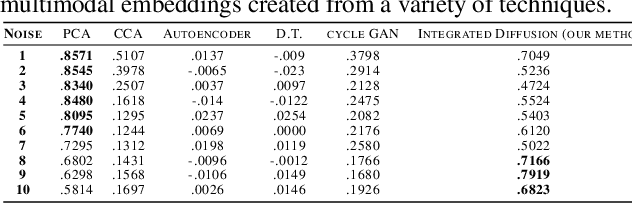
We propose a method called integrated diffusion for combining multimodal datasets, or data gathered via several different measurements on the same system, to create a joint data diffusion operator. As real world data suffers from both local and global noise, we introduce mechanisms to optimally calculate a diffusion operator that reflects the combined information from both modalities. We show the utility of this joint operator in data denoising, visualization and clustering, performing better than other methods to integrate and analyze multimodal data. We apply our method to multi-omic data generated from blood cells, measuring both gene expression and chromatin accessibility. Our approach better visualizes the geometry of the joint data, captures known cross-modality associations and identifies known cellular populations. More generally, integrated diffusion is broadly applicable to multimodal datasets generated in many medical and biological systems.
Delayed Rewards Calibration via Reward Empirical Sufficiency
Feb 23, 2021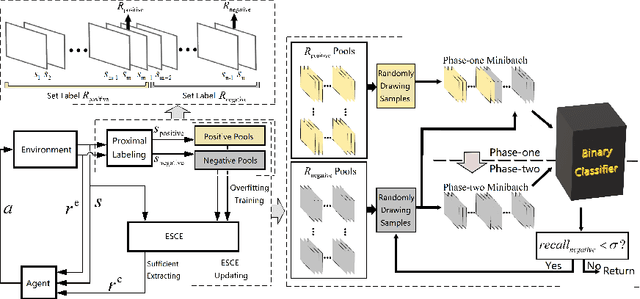
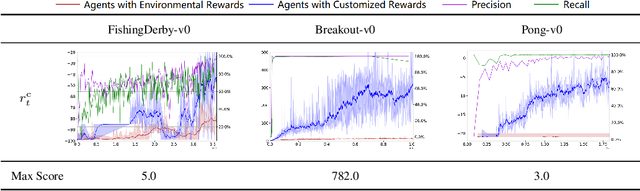
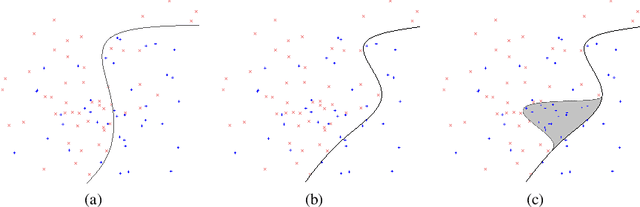
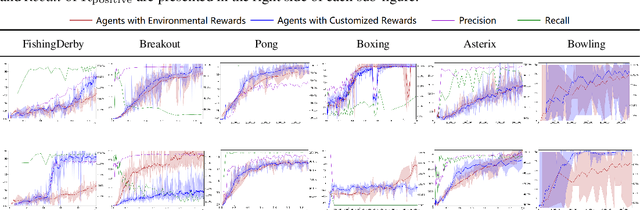
Appropriate credit assignment for delay rewards is a fundamental challenge for reinforcement learning. To tackle this problem, we introduce a delay reward calibration paradigm inspired from a classification perspective. We hypothesize that well-represented state vectors share similarities with each other since they contain the same or equivalent essential information. To this end, we define an empirical sufficient distribution, where the state vectors within the distribution will lead agents to environmental reward signals in the consequent steps. Therefore, a purify-trained classifier is designed to obtain the distribution and generate the calibrated rewards. We examine the correctness of sufficient state extraction by tracking the real-time extraction and building different reward functions in environments. The results demonstrate that the classifier could generate timely and accurate calibrated rewards. Moreover, the rewards are able to make the model training process more efficient. Finally, we identify and discuss that the sufficient states extracted by our model resonate with the observations of humans.
3D-ANAS: 3D Asymmetric Neural Architecture Search for Fast Hyperspectral Image Classification
Jan 12, 2021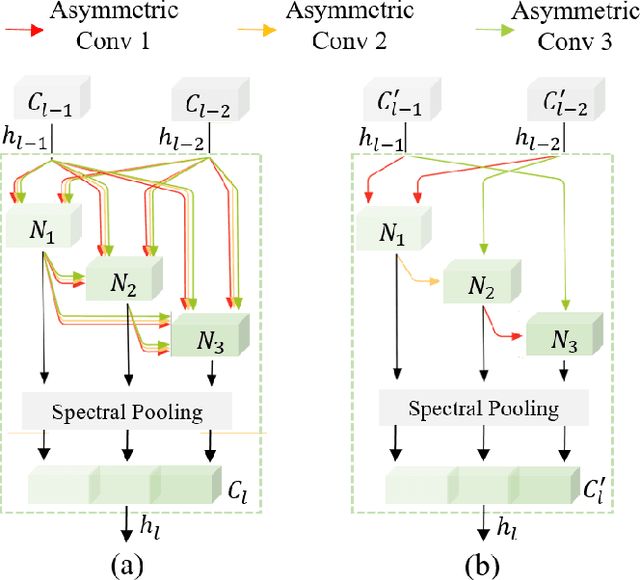
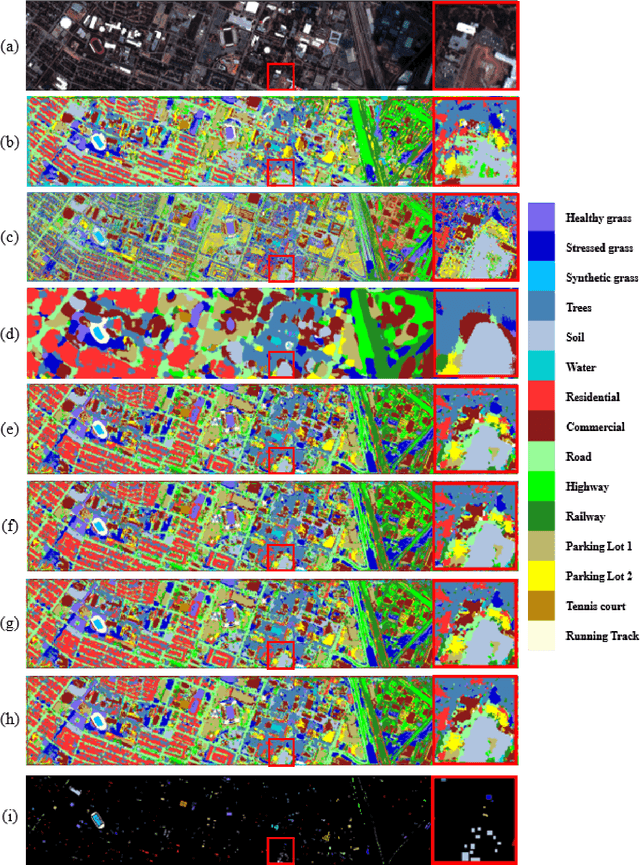
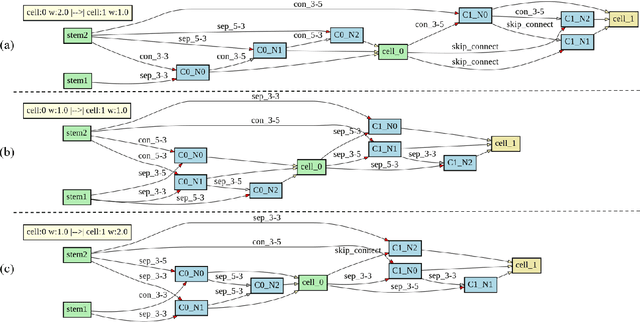
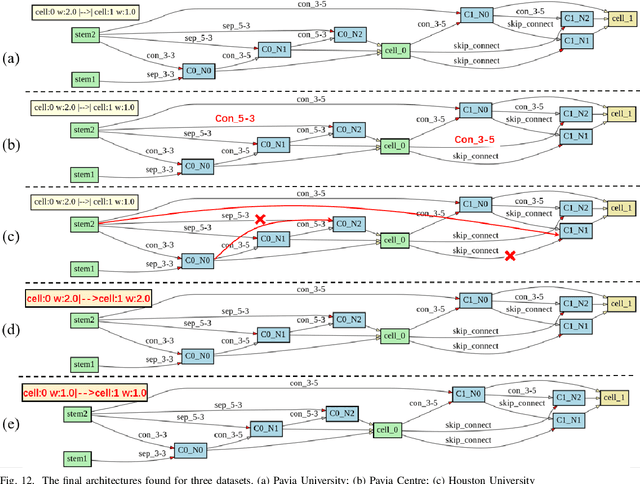
Hyperspectral images involve abundant spectral and spatial information, playing an irreplaceable role in land-cover classification. Recently, based on deep learning technologies, an increasing number of HSI classification approaches have been proposed, which demonstrate promising performance. However, previous studies suffer from two major drawbacks: 1) the architecture of most deep learning models is manually designed, relies on specialized knowledge, and is relatively tedious. Moreover, in HSI classifications, datasets captured by different sensors have different physical properties. Correspondingly, different models need to be designed for different datasets, which further increases the workload of designing architectures; 2) the mainstream framework is a patch-to-pixel framework. The overlap regions of patches of adjacent pixels are calculated repeatedly, which increases computational cost and time cost. Besides, the classification accuracy is sensitive to the patch size, which is artificially set based on extensive investigation experiments. To overcome the issues mentioned above, we firstly propose a 3D asymmetric neural network search algorithm and leverage it to automatically search for efficient architectures for HSI classifications. By analysing the characteristics of HSIs, we specifically build a 3D asymmetric decomposition search space, where spectral and spatial information are processed with different decomposition convolutions. Furthermore, we propose a new fast classification framework, i,e., pixel-to-pixel classification framework, which has no repetitive operations and reduces the overall cost. Experiments on three public HSI datasets captured by different sensors demonstrate the networks designed by our 3D-ANAS achieve competitive performance compared to several state-of-the-art methods, while having a much faster inference speed.
Deep encoding of etymological information in TEI
Nov 30, 2016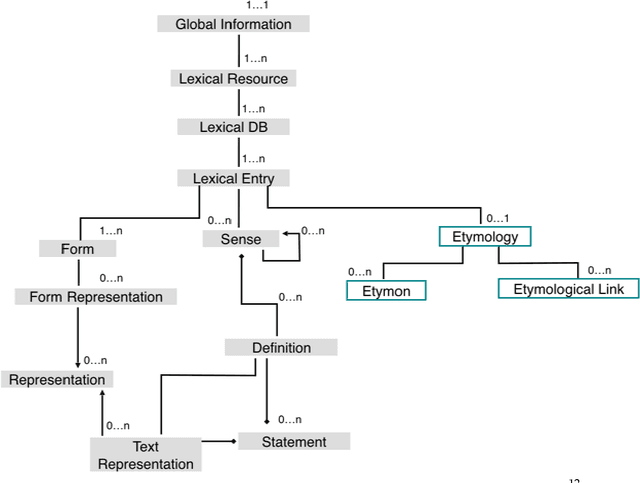
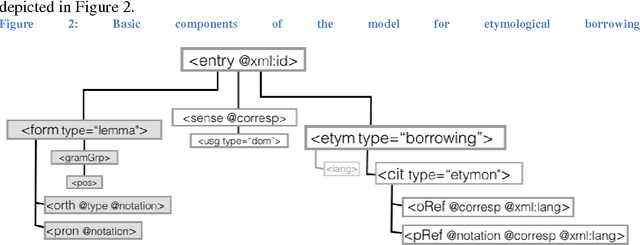
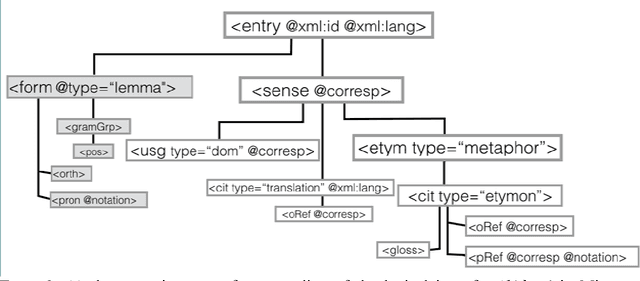
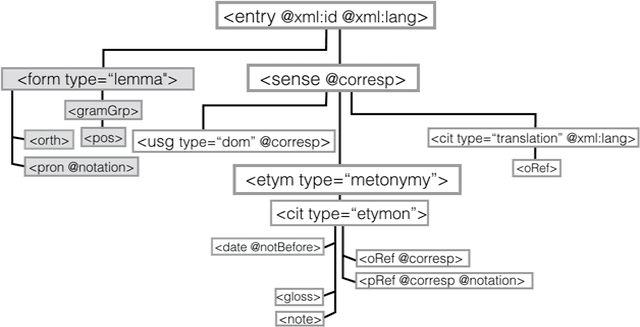
This paper aims to provide a comprehensive modeling and representation of etymological data in digital dictionaries. The purpose is to integrate in one coherent framework both digital representations of legacy dictionaries, and also born-digital lexical databases that are constructed manually or semi-automatically. We want to propose a systematic and coherent set of modeling principles for a variety of etymological phenomena that may contribute to the creation of a continuum between existing and future lexical constructs, where anyone interested in tracing the history of words and their meanings will be able to seamlessly query lexical resources.Instead of designing an ad hoc model and representation language for digital etymological data, we will focus on identifying all the possibilities offered by the TEI guidelines for the representation of lexical information.
TapNet: The Design, Training, Implementation, and Applications of a Multi-Task Learning CNN for Off-Screen Mobile Input
Feb 18, 2021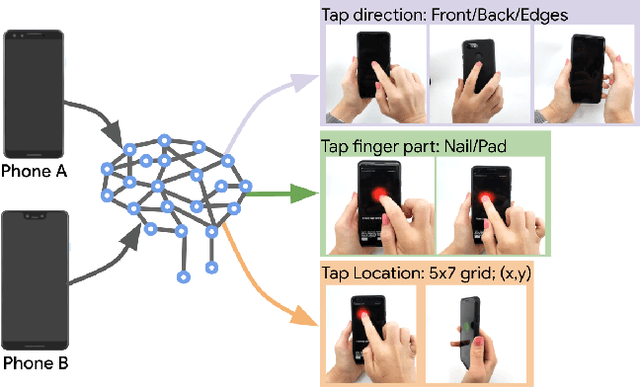
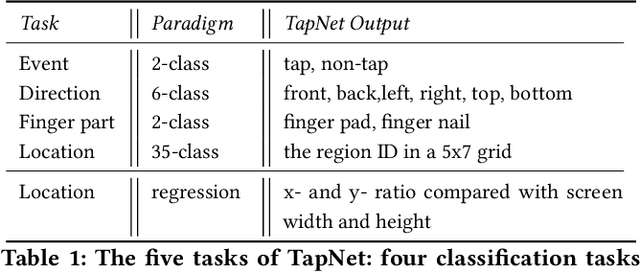
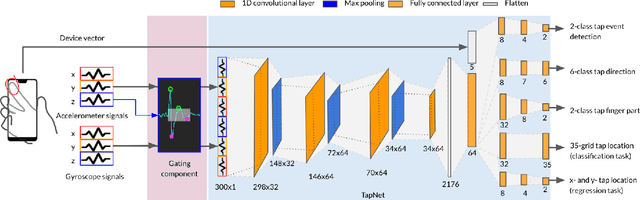
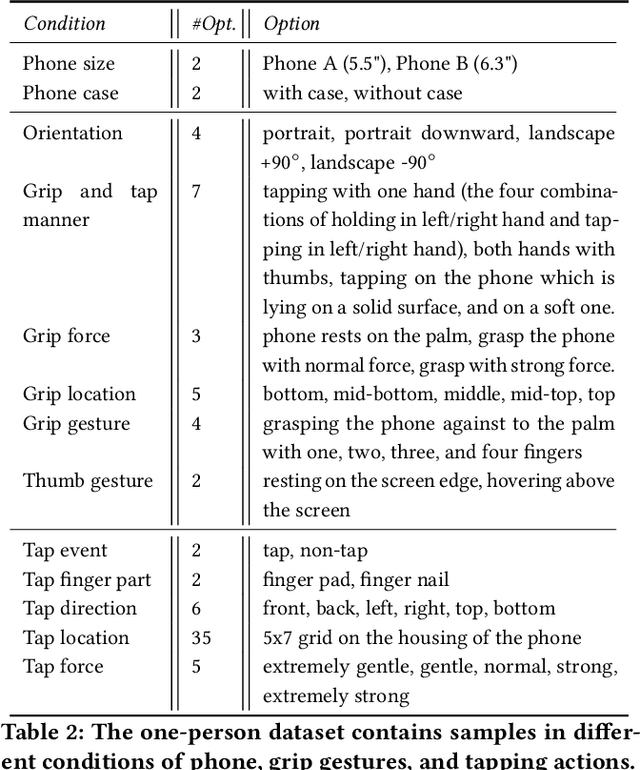
To make off-screen interaction without specialized hardware practical, we investigate using deep learning methods to process the common built-in IMU sensor (accelerometers and gyroscopes) on mobile phones into a useful set of one-handed interaction events. We present the design, training, implementation and applications of TapNet, a multi-task network that detects tapping on the smartphone. With phone form factor as auxiliary information, TapNet can jointly learn from data across devices and simultaneously recognize multiple tap properties, including tap direction and tap location. We developed two datasets consisting of over 135K training samples, 38K testing samples, and 32 participants in total. Experimental evaluation demonstrated the effectiveness of the TapNet design and its significant improvement over the state of the art. Along with the datasets, (https://sites.google.com/site/michaelxlhuang/datasets/tapnet-dataset), and extensive experiments, TapNet establishes a new technical foundation for off-screen mobile input.
A Generative Model for Hallucinating Diverse Versions of Super Resolution Images
Feb 12, 2021
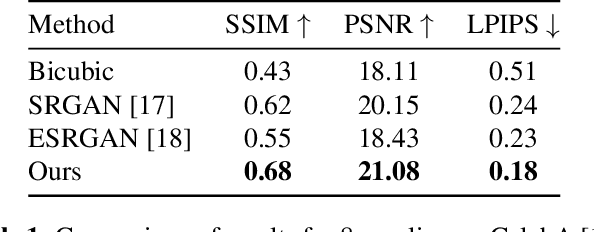
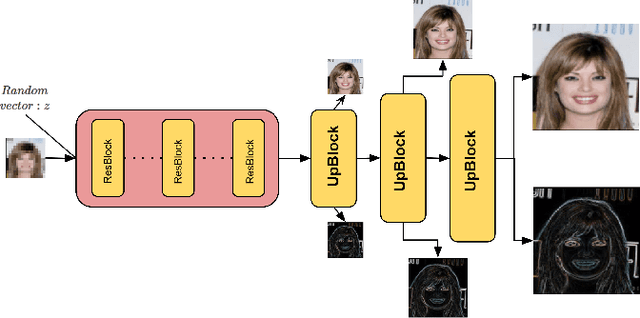
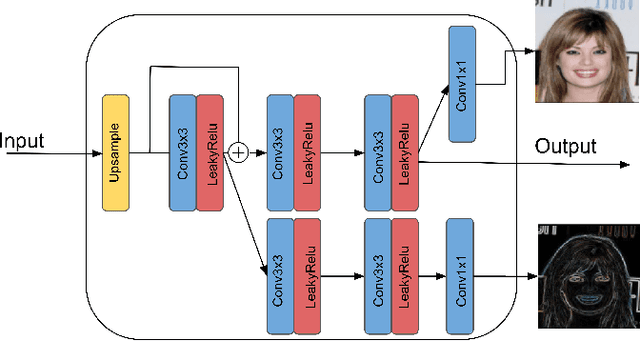
Traditionally, the main focus of image super-resolution techniques is on recovering the most likely high-quality images from low-quality images, using a one-to-one low- to high-resolution mapping. Proceeding that way, we ignore the fact that there are generally many valid versions of high-resolution images that map to a given low-resolution image. We are tackling in this work the problem of obtaining different high-resolution versions from the same low-resolution image using Generative Adversarial Models. Our learning approach makes use of high frequencies available in the training high-resolution images for preserving and exploring in an unsupervised manner the structural information available within these images. Experimental results on the CelebA dataset confirm the effectiveness of the proposed method, which allows the generation of both realistic and diverse high-resolution images from low-resolution images.
EQG-RACE: Examination-Type Question Generation
Dec 11, 2020
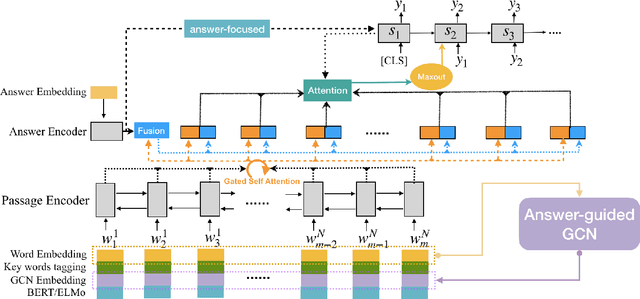

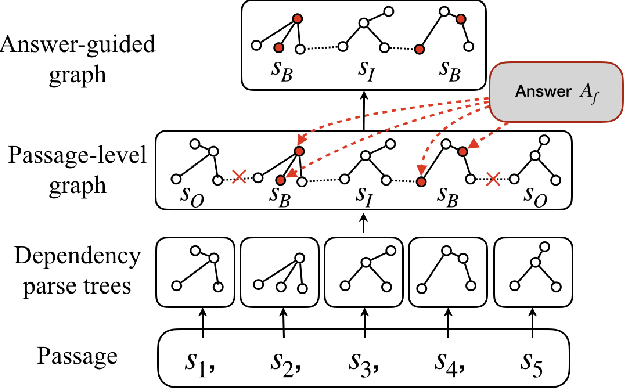
Question Generation (QG) is an essential component of the automatic intelligent tutoring systems, which aims to generate high-quality questions for facilitating the reading practice and assessments. However, existing QG technologies encounter several key issues concerning the biased and unnatural language sources of datasets which are mainly obtained from the Web (e.g. SQuAD). In this paper, we propose an innovative Examination-type Question Generation approach (EQG-RACE) to generate exam-like questions based on a dataset extracted from RACE. Two main strategies are employed in EQG-RACE for dealing with discrete answer information and reasoning among long contexts. A Rough Answer and Key Sentence Tagging scheme is utilized to enhance the representations of input. An Answer-guided Graph Convolutional Network (AG-GCN) is designed to capture structure information in revealing the inter-sentences and intra-sentence relations. Experimental results show a state-of-the-art performance of EQG-RACE, which is apparently superior to the baselines. In addition, our work has established a new QG prototype with a reshaped dataset and QG method, which provides an important benchmark for related research in future work. We will make our data and code publicly available for further research.