 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
PowerEvaluationBALD: Efficient Evaluation-Oriented Deep (Bayesian) Active Learning with Stochastic Acquisition Functions
Jan 10, 2021
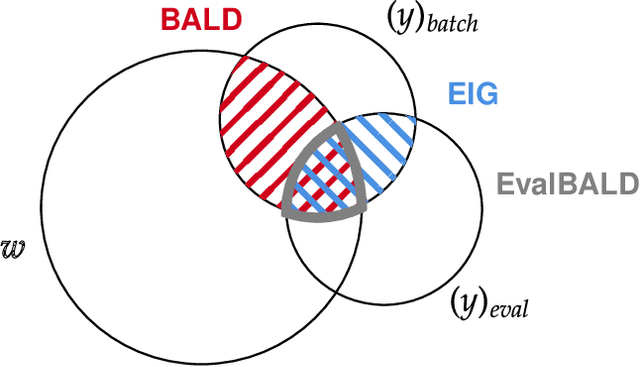
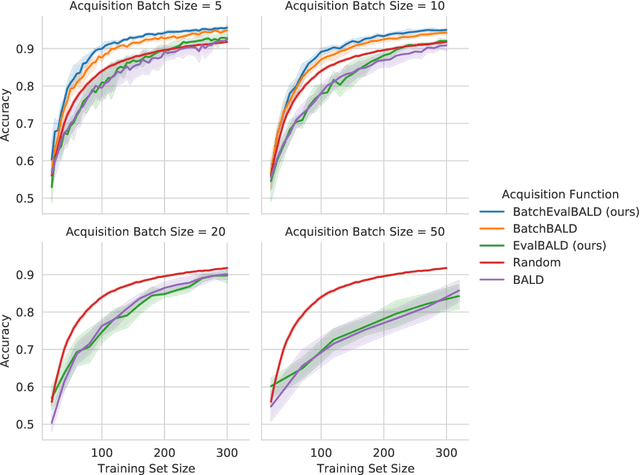
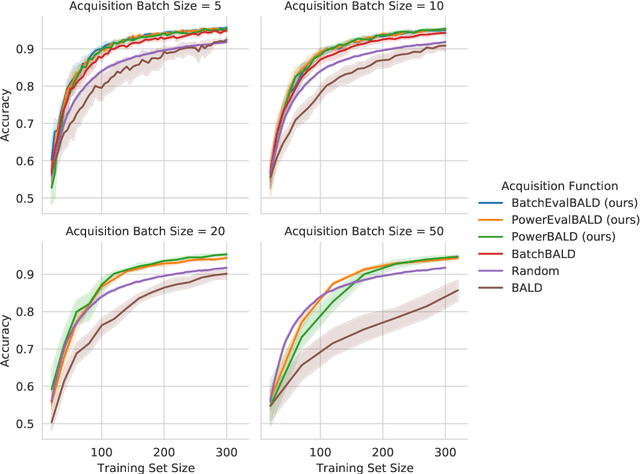
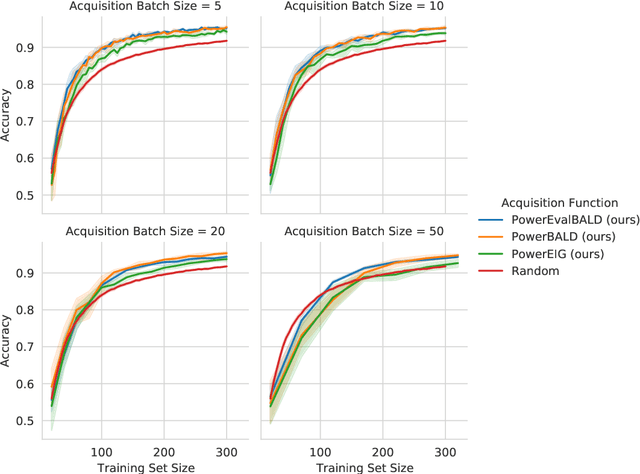
We develop BatchEvaluationBALD, a new acquisition function for deep Bayesian active learning, as an expansion of BatchBALD that takes into account an evaluation set of unlabeled data, for example, the pool set. We also develop a variant for the non-Bayesian setting, which we call Evaluation Information Gain. To reduce computational requirements and allow these methods to scale to larger acquisition batch sizes, we introduce stochastic acquisition functions that use importance-sampling of tempered acquisition scores. We call this method PowerEvaluationBALD. We show in first experiments that PowerEvaluationBALD works on par with BatchEvaluationBALD, which outperforms BatchBALD on Repeated MNIST (MNISTx2), while massively reducing the computational requirements compared to BatchBALD or BatchEvaluationBALD.
FastHand: Fast Hand Pose Estimation From A Monocular Camera
Feb 14, 2021
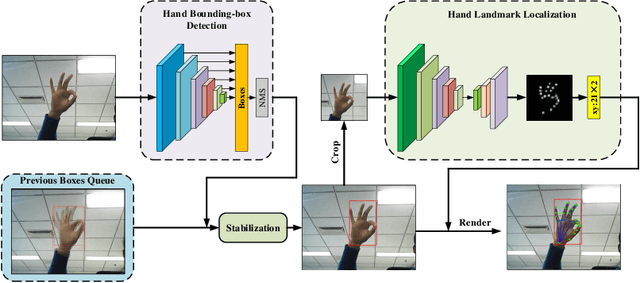
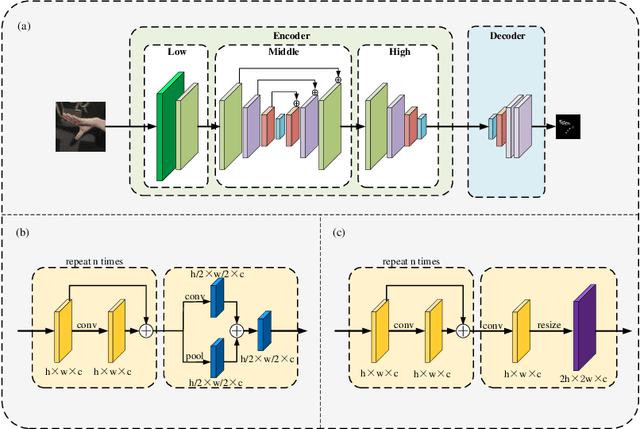

Hand gesture recognition constitutes the initial step in most methods related to human-robot interaction. There are two key challenges in this task. The first one corresponds to the difficulty of achieving stable and accurate hand landmark predictions in real-world scenarios, while the second to the decreased time of forward inference. In this paper, we propose a fast and accurate framework for hand pose estimation, dubbed as "FastHand". Using a lightweight encoder-decoder network architecture, we achieve to fulfil the requirements of practical applications running on embedded devices. The encoder consists of deep layers with a small number of parameters, while the decoder makes use of spatial location information to obtain more accurate results. The evaluation took place on two publicly available datasets demonstrating the improved performance of the proposed pipeline compared to other state-of-the-art approaches. FastHand offers high accuracy scores while reaching a speed of 25 frames per second on an NVIDIA Jetson TX2 graphics processing unit.
Smart and Reconfigurable Wireless Communications: From IRS Modeling to Algorithm Design
Mar 12, 2021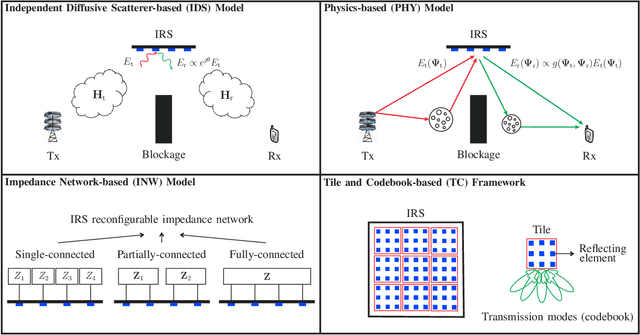
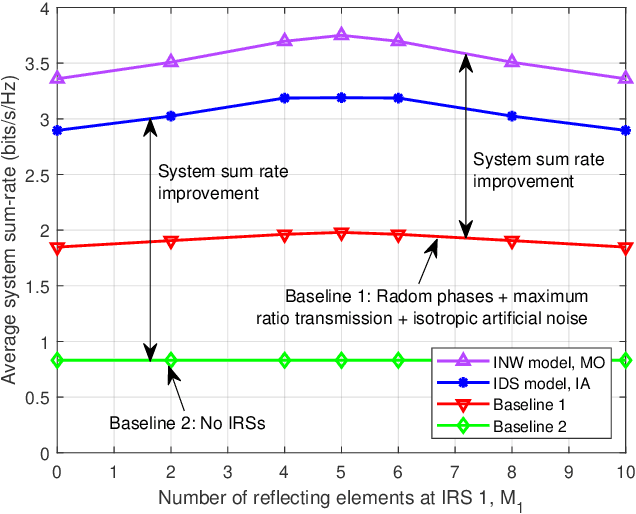
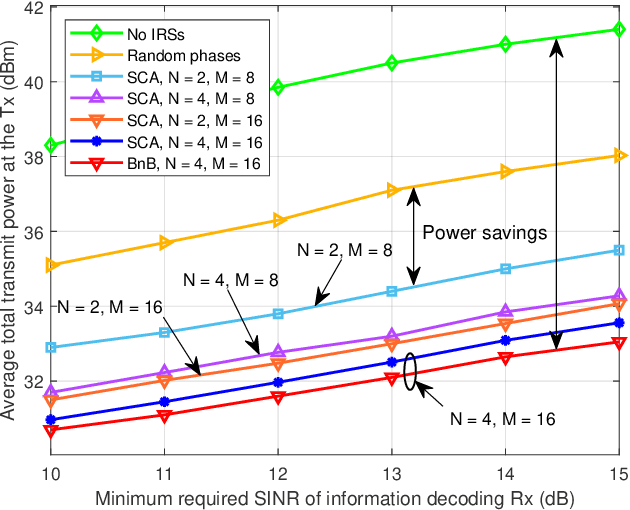
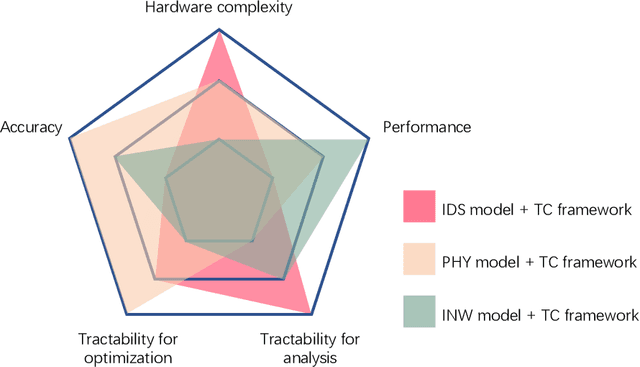
Intelligent reflecting surfaces (IRSs) have been introduced into wireless communications systems due to their great potential to smartly customize and reconfigure radio propagation environments in a cost-effective manner. Despite the promising advantages of IRSs, academic research on IRSs is still in its infancy. In particular, the design and analysis of IRS-assisted wireless communication systems critically depend on an accurate and tractable modeling of the IRS. In this article, we first present and compare three IRS models, namely the conventional independent diffusive scatterer-based model, physics-based model, and impedance network-based model, in terms of their accuracy, tractability, and hardware complexity. Besides, a new framework based on partitioning the IRS into tiles and employing codebooks of transmission modes is introduced to enable scalable IRS optimization. Then, we investigate the impact of the three considered IRS models on system design, where several crucial technical challenges for the efficient design of IRS-assisted wireless systems are identified and the corresponding solutions are unraveled. Furthermore, to illustrate the properties of the considered models and the efficiency of the proposed solution concepts, IRS-assisted secure wireless systems and simultaneous wireless information and power transfer (SWIPT) systems are studied in more detail. Finally, several promising future research directions for IRS-assisted wireless systems are highlighted.
ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases
Mar 19, 2021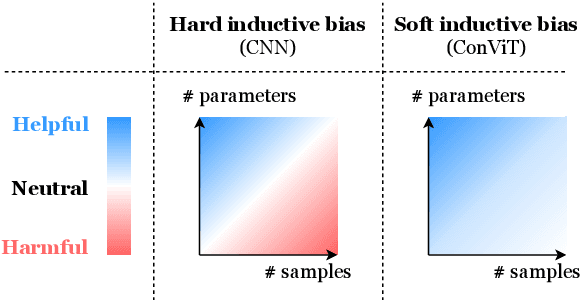
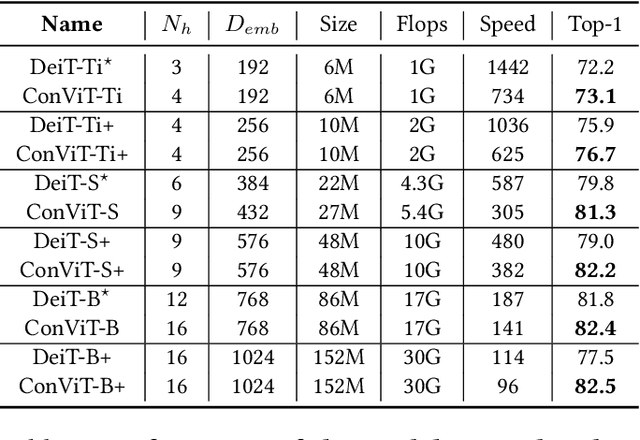
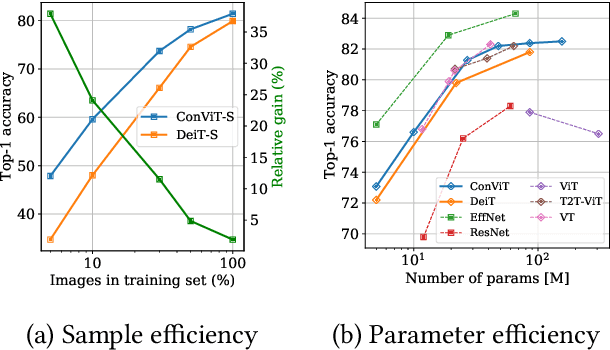
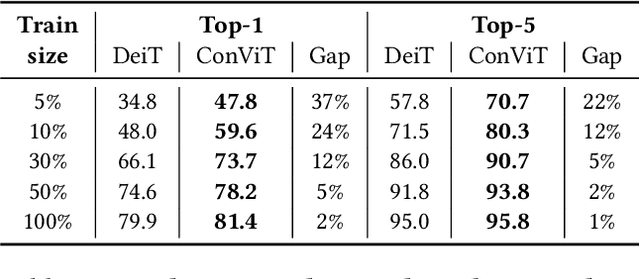
Convolutional architectures have proven extremely successful for vision tasks. Their hard inductive biases enable sample-efficient learning, but come at the cost of a potentially lower performance ceiling. Vision Transformers (ViTs) rely on more flexible self-attention layers, and have recently outperformed CNNs for image classification. However, they require costly pre-training on large external datasets or distillation from pre-trained convolutional networks. In this paper, we ask the following question: is it possible to combine the strengths of these two architectures while avoiding their respective limitations? To this end, we introduce gated positional self-attention (GPSA), a form of positional self-attention which can be equipped with a "soft" convolutional inductive bias. We initialize the GPSA layers to mimic the locality of convolutional layers, then give each attention head the freedom to escape locality by adjusting a gating parameter regulating the attention paid to position versus content information. The resulting convolutional-like ViT architecture, ConViT, outperforms the DeiT on ImageNet, while offering a much improved sample efficiency. We further investigate the role of locality in learning by first quantifying how it is encouraged in vanilla self-attention layers, then analyzing how it is escaped in GPSA layers. We conclude by presenting various ablations to better understand the success of the ConViT. Our code and models are released publicly.
Models we Can Trust: Toward a Systematic Discipline of (Agent-Based) Model Interpretation and Validation
Feb 23, 2021We advocate the development of a discipline of interacting with and extracting information from models, both mathematical (e.g. game-theoretic ones) and computational (e.g. agent-based models). We outline some directions for the development of a such a discipline: - the development of logical frameworks for the systematic formal specification of stylized facts and social mechanisms in (mathematical and computational) social science. Such frameworks would bring to attention new issues, such as phase transitions, i.e. dramatical changes in the validity of the stylized facts beyond some critical values in parameter space. We argue that such statements are useful for those logical frameworks describing properties of ABM. - the adaptation of tools from the theory of reactive systems (such as bisimulation) to obtain practically relevant notions of two systems "having the same behavior". - the systematic development of an adversarial theory of model perturbations, that investigates the robustness of conclusions derived from models of social behavior to variations in several features of the social dynamics. These may include: activation order, the underlying social network, individual agent behavior.
Steps Towards a Theory of Visual Information: Active Perception, Signal-to-Symbol Conversion and the Interplay Between Sensing and Control
Dec 27, 2017



This manuscript describes the elements of a theory of information tailored to control and decision tasks and specifically to visual data. The concept of Actionable Information is described, that relates to a notion of information championed by J. Gibson, and a notion of "complete information" that relates to the minimal sufficient statistics of a complete representation. It is shown that the "actionable information gap" between the two can be reduced by exercising control on the sensing process. Thus, senging, control and information are inextricably tied. This has consequences in the so-called "signal-to-symbol barrier" problem, as well as in the analysis and design of active sensing systems. It has ramifications in vision-based control, navigation, 3-D reconstruction and rendering, as well as detection, localization, recognition and categorization of objects and scenes in live video. This manuscript has been developed from a set of lecture notes for a summer course at the First International Computer Vision Summer School (ICVSS) in Scicli, Italy, in July of 2008. They were later expanded and amended for subsequent lectures in the same School in July 2009. Starting on November 1, 2009, they were further expanded for a special topics course, CS269, taught at UCLA in the Spring term of 2010.
Scaling up learning with GAIT-prop
Feb 23, 2021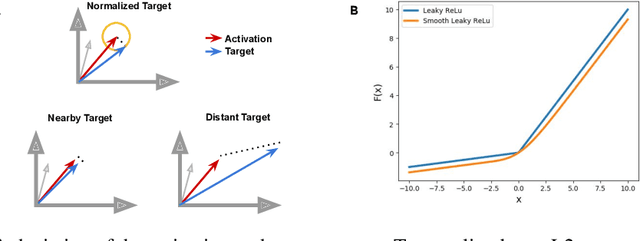
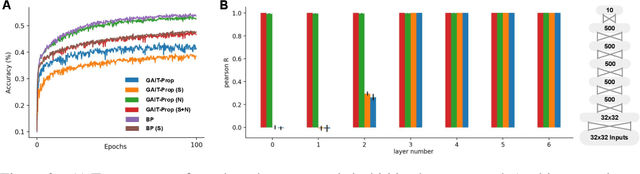
Backpropagation of error (BP) is a widely used and highly successful learning algorithm. However, its reliance on non-local information in propagating error gradients makes it seem an unlikely candidate for learning in the brain. In the last decade, a number of investigations have been carried out focused upon determining whether alternative more biologically plausible computations can be used to approximate BP. This work builds on such a local learning algorithm - Gradient Adjusted Incremental Target Propagation (GAIT-prop) - which has recently been shown to approximate BP in a manner which appears biologically plausible. This method constructs local, layer-wise weight update targets in order to enable plausible credit assignment. However, in deep networks, the local weight updates computed by GAIT-prop can deviate from BP for a number of reasons. Here, we provide and test methods to overcome such sources of error. In particular, we adaptively rescale the locally-computed errors and show that this significantly increases the performance and stability of the GAIT-prop algorithm when applied to the CIFAR-10 dataset.
Feature Boosting, Suppression, and Diversification for Fine-Grained Visual Classification
Mar 04, 2021
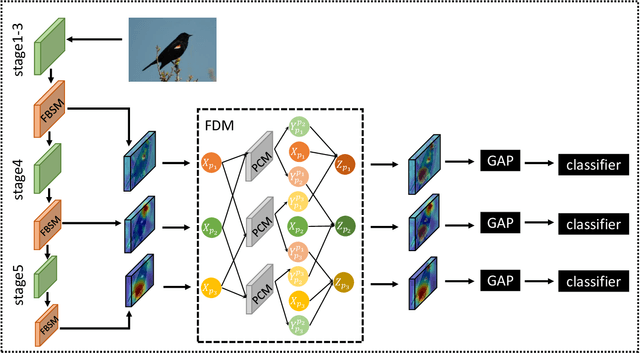
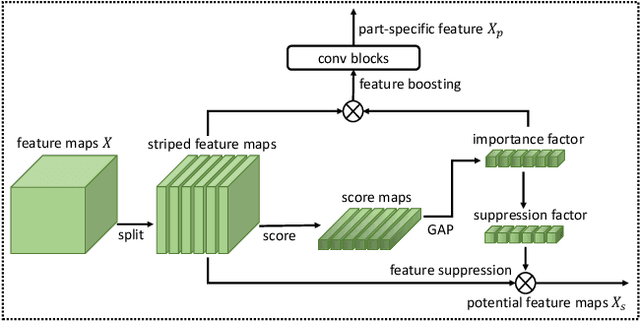
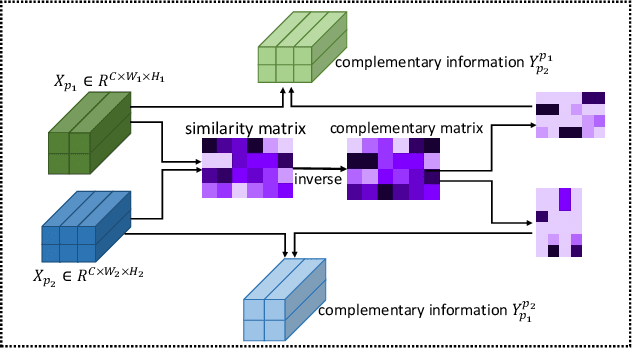
Learning feature representation from discriminative local regions plays a key role in fine-grained visual classification. Employing attention mechanisms to extract part features has become a trend. However, there are two major limitations in these methods: First, they often focus on the most salient part while neglecting other inconspicuous but distinguishable parts. Second, they treat different part features in isolation while neglecting their relationships. To handle these limitations, we propose to locate multiple different distinguishable parts and explore their relationships in an explicit way. In this pursuit, we introduce two lightweight modules that can be easily plugged into existing convolutional neural networks. On one hand, we introduce a feature boosting and suppression module that boosts the most salient part of feature maps to obtain a part-specific representation and suppresses it to force the following network to mine other potential parts. On the other hand, we introduce a feature diversification module that learns semantically complementary information from the correlated part-specific representations. Our method does not need bounding boxes/part annotations and can be trained end-to-end. Extensive experimental results show that our method achieves state-of-the-art performances on several benchmark fine-grained datasets.
MPG-Net: Multi-Prediction Guided Network for Segmentation of Retinal Layers in OCT Images
Sep 28, 2020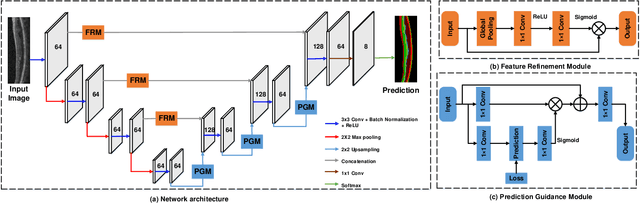
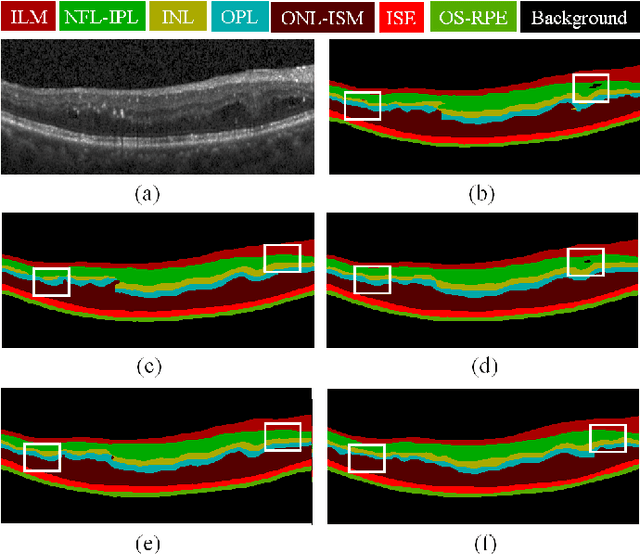
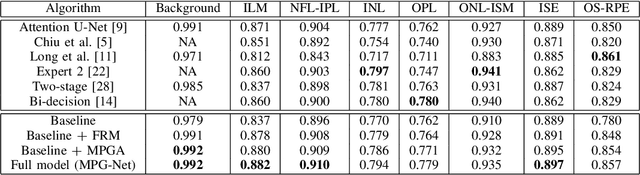
Optical coherence tomography (OCT) is a commonly-used method of extracting high resolution retinal information. Moreover there is an increasing demand for the automated retinal layer segmentation which facilitates the retinal disease diagnosis. In this paper, we propose a novel multiprediction guided attention network (MPG-Net) for automated retinal layer segmentation in OCT images. The proposed method consists of two major steps to strengthen the discriminative power of a U-shape Fully convolutional network (FCN) for reliable automated segmentation. Firstly, the feature refinement module which adaptively re-weights the feature channels is exploited in the encoder to capture more informative features and discard information in irrelevant regions. Furthermore, we propose a multi-prediction guided attention mechanism which provides pixel-wise semantic prediction guidance to better recover the segmentation mask at each scale. This mechanism which transforms the deep supervision to supervised attention is able to guide feature aggregation with more semantic information between intermediate layers. Experiments on the publicly available Duke OCT dataset confirm the effectiveness of the proposed method as well as an improved performance over other state-of-the-art approaches.
Towards Socially Intelligent Agents with Mental State Transition and Human Utility
Mar 12, 2021

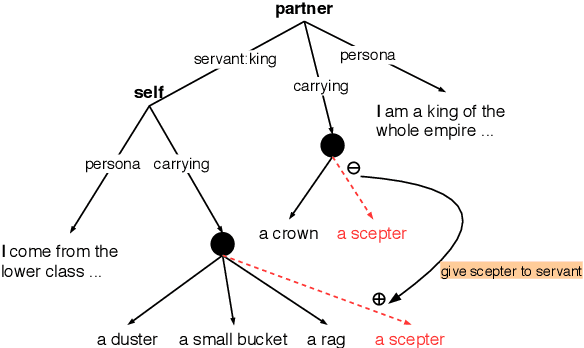
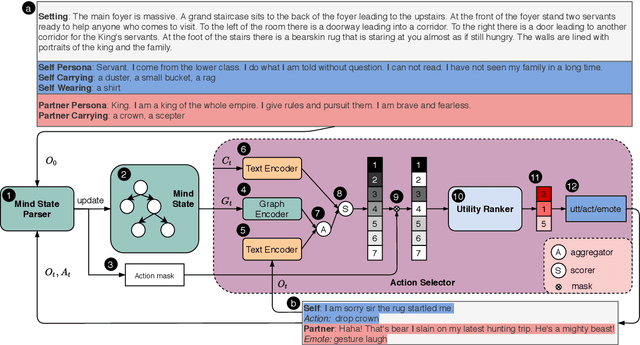
Building a socially intelligent agent involves many challenges, one of which is to track the agent's mental state transition and teach the agent to make rational decisions guided by its utility like a human. Towards this end, we propose to incorporate a mental state parser and utility model into dialogue agents. The hybrid mental state parser extracts information from both the dialogue and event observations and maintains a graphical representation of the agent's mind; Meanwhile, the utility model is a ranking model that learns human preferences from a crowd-sourced social commonsense dataset, Social IQA. Empirical results show that the proposed model attains state-of-the-art performance on the dialogue/action/emotion prediction task in the fantasy text-adventure game dataset, LIGHT. We also show example cases to demonstrate: (\textit{i}) how the proposed mental state parser can assist agent's decision by grounding on the context like locations and objects, and (\textit{ii}) how the utility model can help the agent make reasonable decisions in a dilemma. To the best of our knowledge, we are the first work that builds a socially intelligent agent by incorporating a hybrid mental state parser for both discrete events and continuous dialogues parsing and human-like utility modeling.