 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Efficient and Accurate Multi-scale Topological Network for Single Image Dehazing
Feb 24, 2021

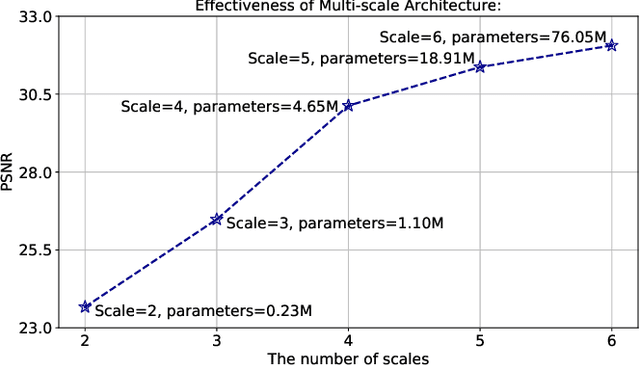
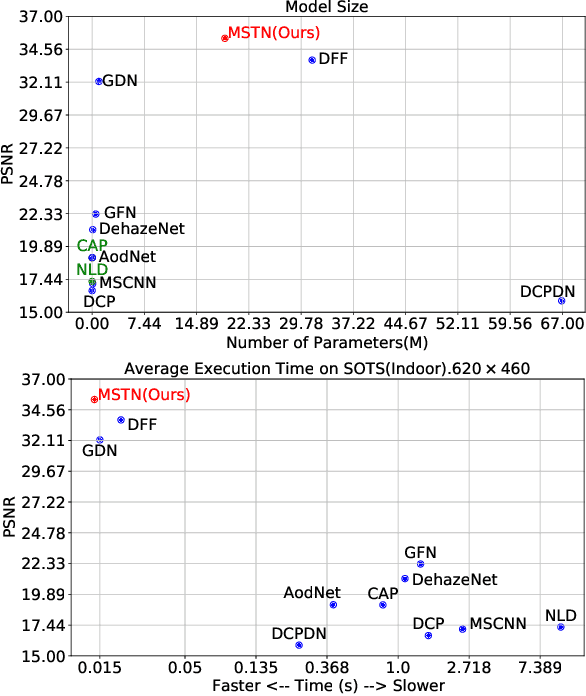
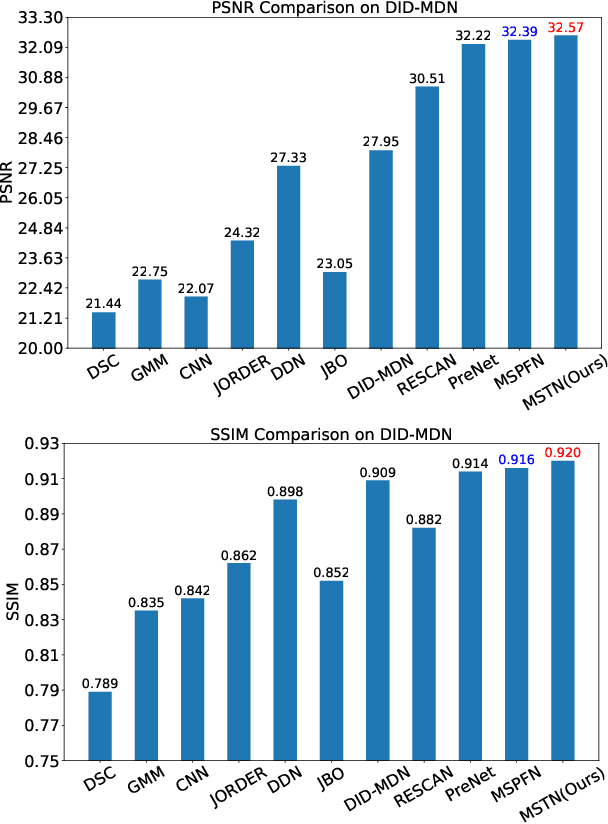
Single image dehazing is a challenging ill-posed problem that has drawn significant attention in the last few years. Recently, convolutional neural networks have achieved great success in image dehazing. However, it is still difficult for these increasingly complex models to recover accurate details from the hazy image. In this paper, we pay attention to the feature extraction and utilization of the input image itself. To achieve this, we propose a Multi-scale Topological Network (MSTN) to fully explore the features at different scales. Meanwhile, we design a Multi-scale Feature Fusion Module (MFFM) and an Adaptive Feature Selection Module (AFSM) to achieve the selection and fusion of features at different scales, so as to achieve progressive image dehazing. This topological network provides a large number of search paths that enable the network to extract abundant image features as well as strong fault tolerance and robustness. In addition, ASFM and MFFM can adaptively select important features and ignore interference information when fusing different scale representations. Extensive experiments are conducted to demonstrate the superiority of our method compared with state-of-the-art methods.
Self-Domain Adaptation for Face Anti-Spoofing
Feb 24, 2021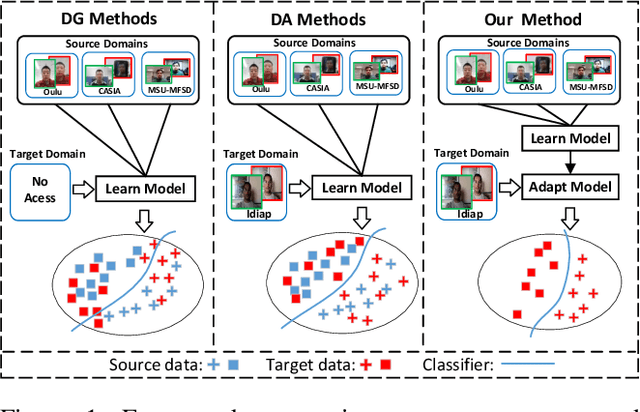
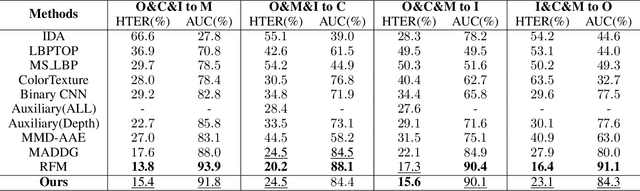
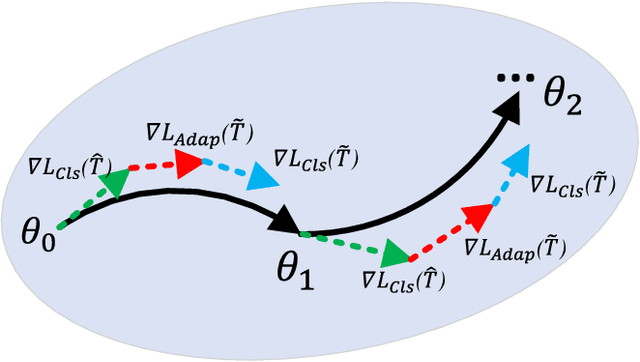

Although current face anti-spoofing methods achieve promising results under intra-dataset testing, they suffer from poor generalization to unseen attacks. Most existing works adopt domain adaptation (DA) or domain generalization (DG) techniques to address this problem. However, the target domain is often unknown during training which limits the utilization of DA methods. DG methods can conquer this by learning domain invariant features without seeing any target data. However, they fail in utilizing the information of target data. In this paper, we propose a self-domain adaptation framework to leverage the unlabeled test domain data at inference. Specifically, a domain adaptor is designed to adapt the model for test domain. In order to learn a better adaptor, a meta-learning based adaptor learning algorithm is proposed using the data of multiple source domains at the training step. At test time, the adaptor is updated using only the test domain data according to the proposed unsupervised adaptor loss to further improve the performance. Extensive experiments on four public datasets validate the effectiveness of the proposed method.
Liquid Warping GAN with Attention: A Unified Framework for Human Image Synthesis
Nov 23, 2020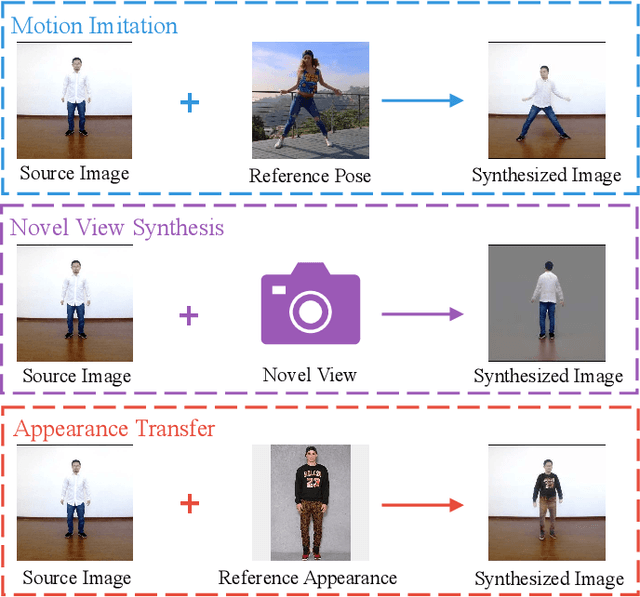
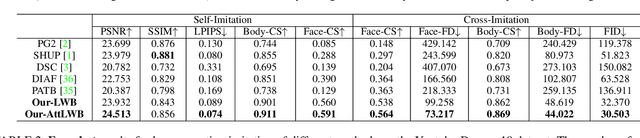
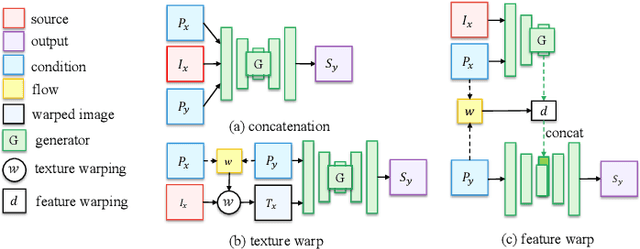
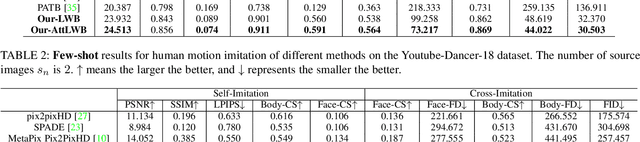
We tackle human image synthesis, including human motion imitation, appearance transfer, and novel view synthesis, within a unified framework. It means that the model, once being trained, can be used to handle all these tasks. The existing task-specific methods mainly use 2D keypoints to estimate the human body structure. However, they only express the position information with no abilities to characterize the personalized shape of the person and model the limb rotations. In this paper, we propose to use a 3D body mesh recovery module to disentangle the pose and shape. It can not only model the joint location and rotation but also characterize the personalized body shape. To preserve the source information, such as texture, style, color, and face identity, we propose an Attentional Liquid Warping GAN with Attentional Liquid Warping Block (AttLWB) that propagates the source information in both image and feature spaces to the synthesized reference. Specifically, the source features are extracted by a denoising convolutional auto-encoder for characterizing the source identity well. Furthermore, our proposed method can support a more flexible warping from multiple sources. To further improve the generalization ability of the unseen source images, a one/few-shot adversarial learning is applied. In detail, it firstly trains a model in an extensive training set. Then, it finetunes the model by one/few-shot unseen image(s) in a self-supervised way to generate high-resolution (512 x 512 and 1024 x 1024) results. Also, we build a new dataset, namely iPER dataset, for the evaluation of human motion imitation, appearance transfer, and novel view synthesis. Extensive experiments demonstrate the effectiveness of our methods in terms of preserving face identity, shape consistency, and clothes details. All codes and dataset are available on https://impersonator.org/work/impersonator-plus-plus.html.
Heterogeneous Graph based Deep Learning for Biomedical Network Link Prediction
Feb 24, 2021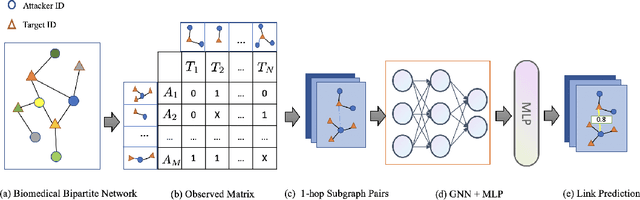
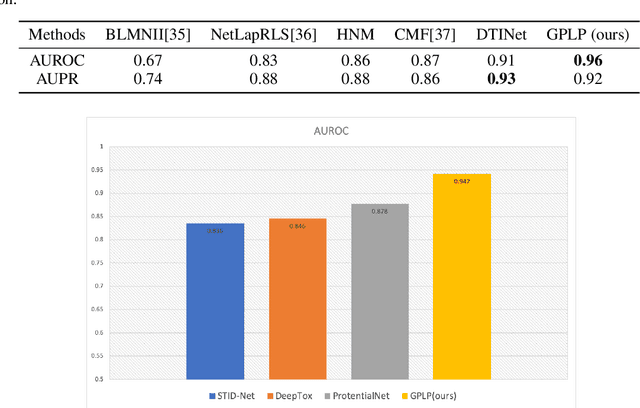
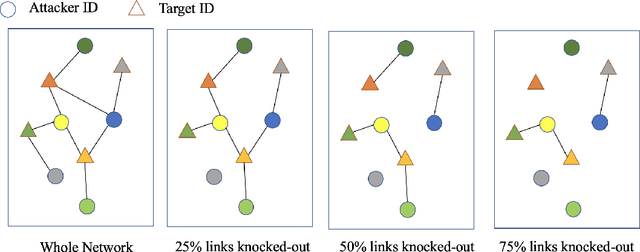
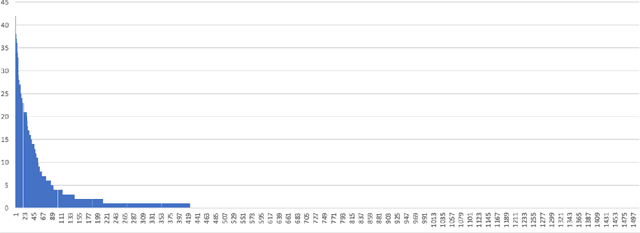
Multi-scale biomedical knowledge networks are expanding with emerging experimental technologies that generates multi-scale biomedical big data. Link prediction is increasingly used especially in bipartite biomedical networks to identify hidden biological interactions and relationshipts between key entities such as compounds, targets, gene and diseases. We propose a Graph Neural Networks (GNN) method, namely Graph Pair based Link Prediction model (GPLP), for predicting biomedical network links simply based on their topological interaction information. In GPLP, 1-hop subgraphs extracted from known network interaction matrix is learnt to predict missing links. To evaluate our method, three heterogeneous biomedical networks were used, i.e. Drug-Target Interaction network (DTI), Compound-Protein Interaction network (CPI) from NIH Tox21, and Compound-Virus Inhibition network (CVI). Our proposed GPLP method significantly outperforms over the state-of-the-art baselines. In addition, different network incompleteness is analysed with our devised protocol, and we also design an effective approach to improve the model robustness towards incomplete networks. Our method demonstrates the potential applications in other biomedical networks.
Continuous Mean-Covariance Bandits
Feb 24, 2021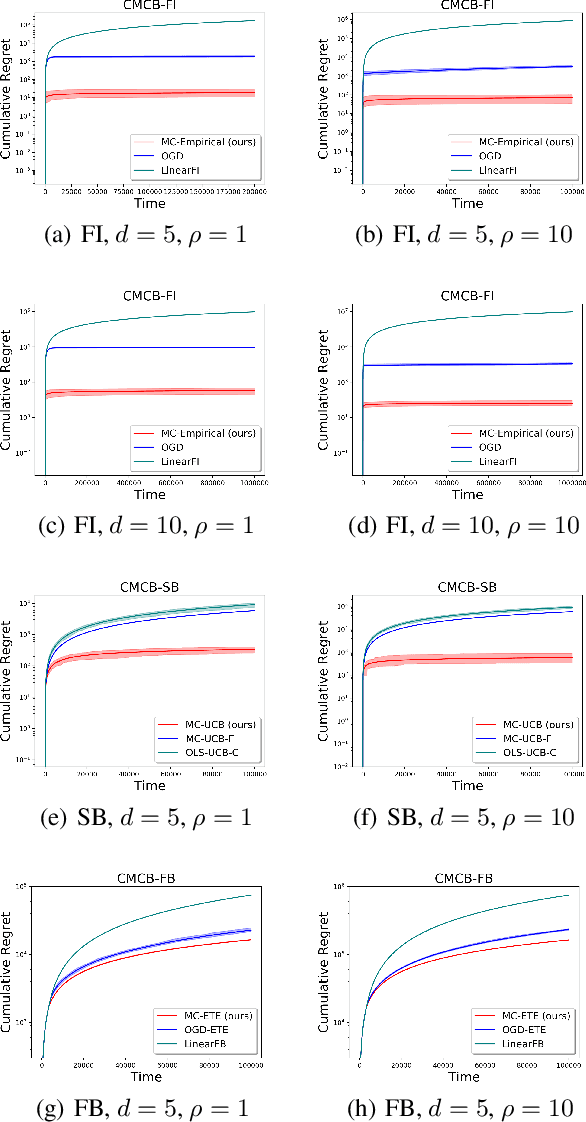
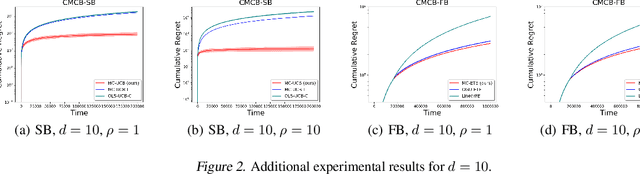
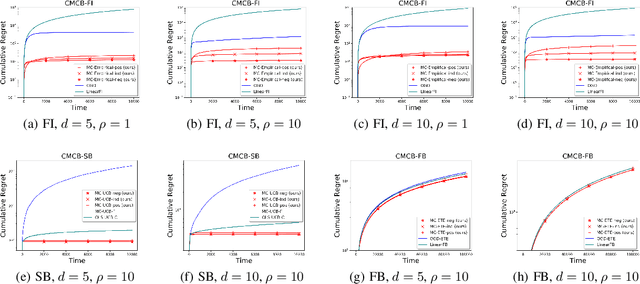
Existing risk-aware multi-armed bandit models typically focus on risk measures of individual options such as variance. As a result, they cannot be directly applied to important real-world online decision making problems with correlated options. In this paper, we propose a novel Continuous Mean-Covariance Bandit (CMCB) model to explicitly take into account option correlation. Specifically, in CMCB, there is a learner who sequentially chooses weight vectors on given options and observes random feedback according to the decisions. The agent's objective is to achieve the best trade-off between reward and risk, measured with option covariance. To capture important reward observation scenarios in practice, we consider three feedback settings, i.e., full-information, semi-bandit and full-bandit feedback. We propose novel algorithms with the optimal regrets (within logarithmic factors), and provide matching lower bounds to validate their optimalities. Our experimental results also demonstrate the superiority of the proposed algorithms. To the best of our knowledge, this is the first work that considers option correlation in risk-aware bandits and explicitly quantifies how arbitrary covariance structures impact the learning performance.
Clustering multilayer graphs with missing nodes
Mar 04, 2021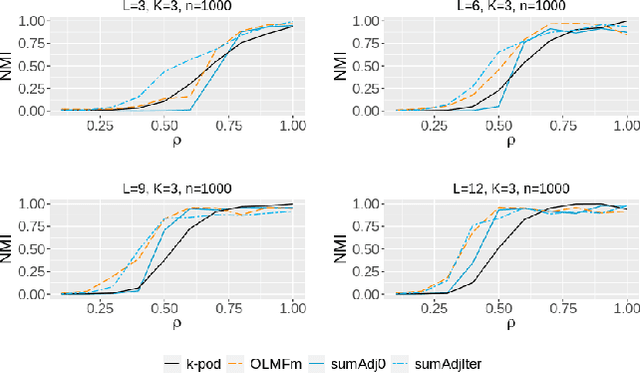
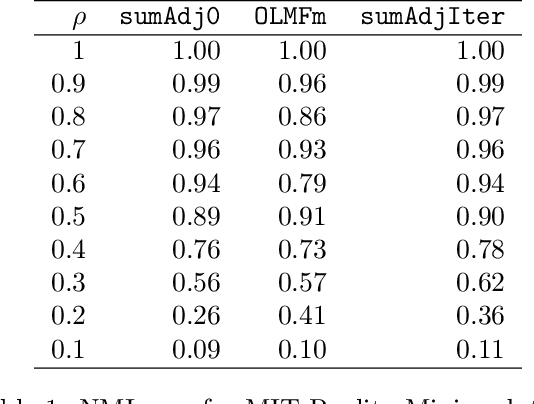
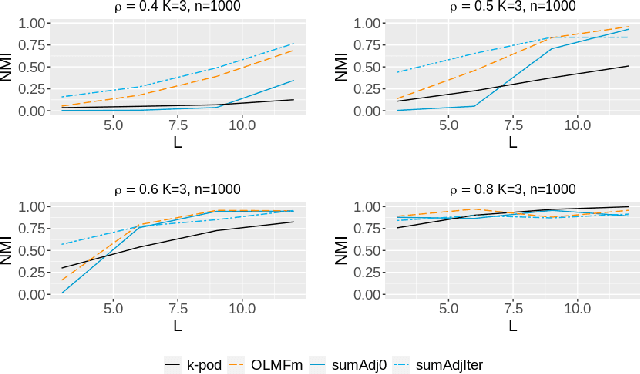
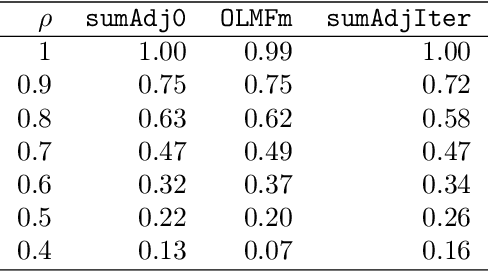
Relationship between agents can be conveniently represented by graphs. When these relationships have different modalities, they are better modelled by multilayer graphs where each layer is associated with one modality. Such graphs arise naturally in many contexts including biological and social networks. Clustering is a fundamental problem in network analysis where the goal is to regroup nodes with similar connectivity profiles. In the past decade, various clustering methods have been extended from the unilayer setting to multilayer graphs in order to incorporate the information provided by each layer. While most existing works assume - rather restrictively - that all layers share the same set of nodes, we propose a new framework that allows for layers to be defined on different sets of nodes. In particular, the nodes not recorded in a layer are treated as missing. Within this paradigm, we investigate several generalizations of well-known clustering methods in the complete setting to the incomplete one and prove some consistency results under the Multi-Layer Stochastic Block Model assumption. Our theoretical results are complemented by thorough numerical comparisons between our proposed algorithms on synthetic data, and also on real datasets, thus highlighting the promising behaviour of our methods in various settings.
Unsupervised Natural Language Inference via Decoupled Multimodal Contrastive Learning
Oct 16, 2020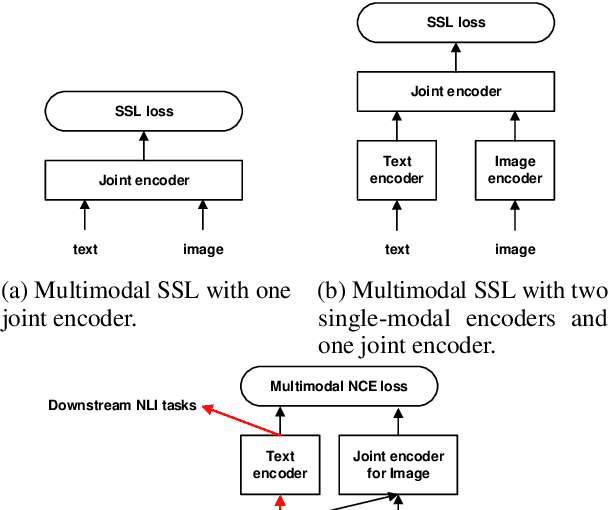
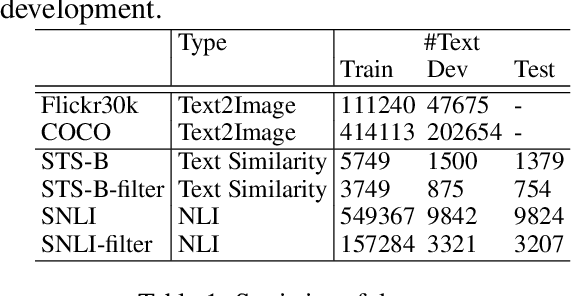
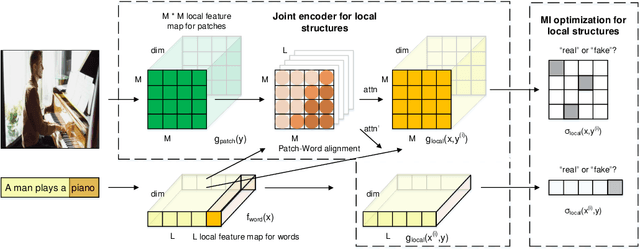
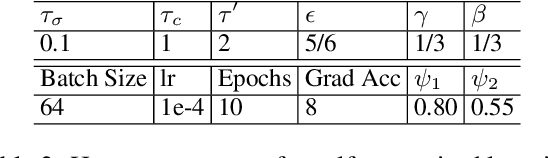
We propose to solve the natural language inference problem without any supervision from the inference labels via task-agnostic multimodal pretraining. Although recent studies of multimodal self-supervised learning also represent the linguistic and visual context, their encoders for different modalities are coupled. Thus they cannot incorporate visual information when encoding plain text alone. In this paper, we propose Multimodal Aligned Contrastive Decoupled learning (MACD) network. MACD forces the decoupled text encoder to represent the visual information via contrastive learning. Therefore, it embeds visual knowledge even for plain text inference. We conducted comprehensive experiments over plain text inference datasets (i.e. SNLI and STS-B). The unsupervised MACD even outperforms the fully-supervised BiLSTM and BiLSTM+ELMO on STS-B.
Event-based Synthetic Aperture Imaging with a Hybrid Network
Mar 04, 2021
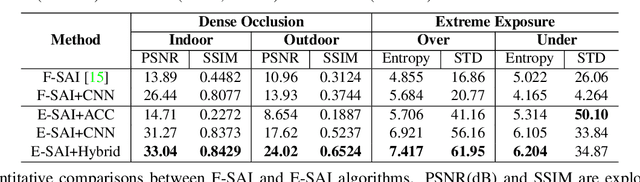


Synthetic aperture imaging (SAI) is able to achieve the see through effect by blurring out the off-focus foreground occlusions and reconstructing the in-focus occluded targets from multi-view images. However, very dense occlusions and extreme lighting conditions may bring significant disturbances to SAI based on conventional frame-based cameras, leading to performance degeneration. To address these problems, we propose a novel SAI system based on the event camera which can produce asynchronous events with extremely low latency and high dynamic range. Thus, it can eliminate the interference of dense occlusions by measuring with almost continuous views, and simultaneously tackle the over/under exposure problems. To reconstruct the occluded targets, we propose a hybrid encoder-decoder network composed of spiking neural networks (SNNs) and convolutional neural networks (CNNs). In the hybrid network, the spatio-temporal information of the collected events is first encoded by SNN layers, and then transformed to the visual image of the occluded targets by a style-transfer CNN decoder. Through experiments, the proposed method shows remarkable performance in dealing with very dense occlusions and extreme lighting conditions, and high quality visual images can be reconstructed using pure event data.
RISA-Net: Rotation-Invariant Structure-Aware Network for Fine-Grained 3D Shape Retrieval
Oct 02, 2020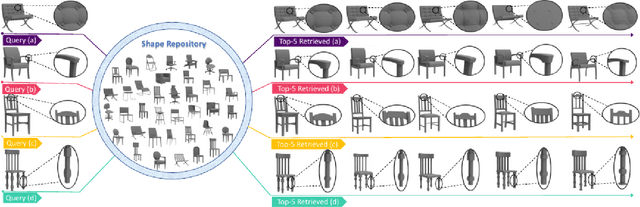
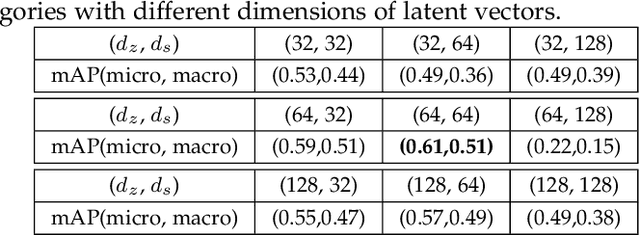
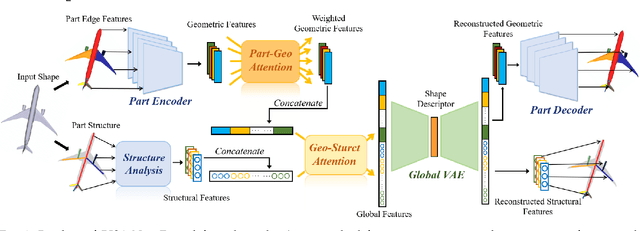
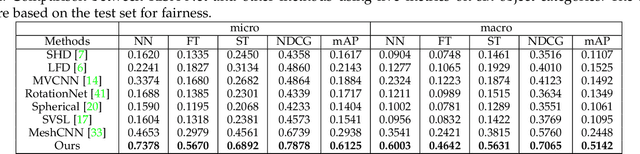
Fine-grained 3D shape retrieval aims to retrieve 3D shapes similar to a query shape in a repository with models belonging to the same class, which requires shape descriptors to be capable of representing detailed geometric information to discriminate shapes with globally similar structures. Moreover, 3D objects can be placed with arbitrary position and orientation in real-world applications, which further requires shape descriptors to be robust to rigid transformations. The shape descriptions used in existing 3D shape retrieval systems fail to meet the above two criteria. In this paper, we introduce a novel deep architecture, RISA-Net, which learns rotation invariant 3D shape descriptors that are capable of encoding fine-grained geometric information and structural information, and thus achieve accurate results on the task of fine-grained 3D object retrieval. RISA-Net extracts a set of compact and detailed geometric features part-wisely and discriminatively estimates the contribution of each semantic part to shape representation. Furthermore, our method is able to learn the importance of geometric and structural information of all the parts when generating the final compact latent feature of a 3D shape for fine-grained retrieval. We also build and publish a new 3D shape dataset with sub-class labels for validating the performance of fine-grained 3D shape retrieval methods. Qualitative and quantitative experiments show that our RISA-Net outperforms state-of-the-art methods on the fine-grained object retrieval task, demonstrating its capability in geometric detail extraction. The code and dataset are available at: https://github.com/IGLICT/RisaNET.
BERTSurv: BERT-Based Survival Models for Predicting Outcomes of Trauma Patients
Mar 19, 2021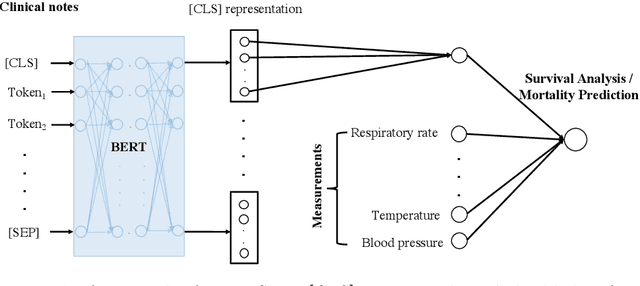
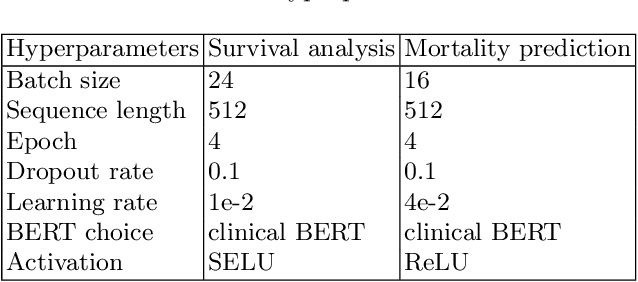
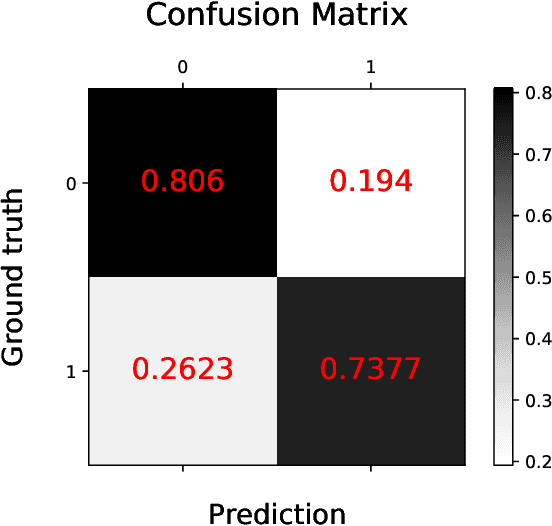
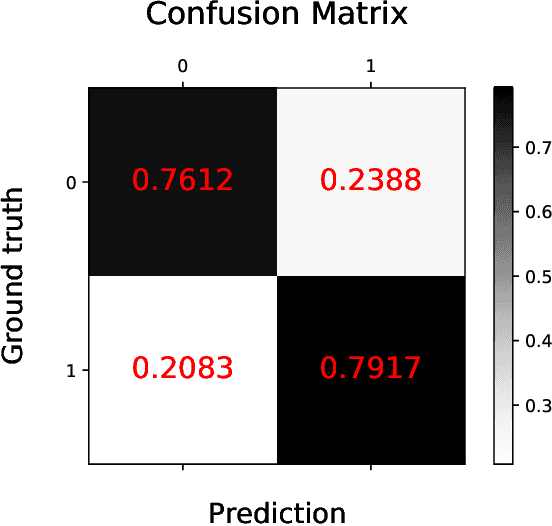
Survival analysis is a technique to predict the times of specific outcomes, and is widely used in predicting the outcomes for intensive care unit (ICU) trauma patients. Recently, deep learning models have drawn increasing attention in healthcare. However, there is a lack of deep learning methods that can model the relationship between measurements, clinical notes and mortality outcomes. In this paper we introduce BERTSurv, a deep learning survival framework which applies Bidirectional Encoder Representations from Transformers (BERT) as a language representation model on unstructured clinical notes, for mortality prediction and survival analysis. We also incorporate clinical measurements in BERTSurv. With binary cross-entropy (BCE) loss, BERTSurv can predict mortality as a binary outcome (mortality prediction). With partial log-likelihood (PLL) loss, BERTSurv predicts the probability of mortality as a time-to-event outcome (survival analysis). We apply BERTSurv on Medical Information Mart for Intensive Care III (MIMIC III) trauma patient data. For mortality prediction, BERTSurv obtained an area under the curve of receiver operating characteristic curve (AUC-ROC) of 0.86, which is an improvement of 3.6% over baseline of multilayer perceptron (MLP) without notes. For survival analysis, BERTSurv achieved a concordance index (C-index) of 0.7. In addition, visualizations of BERT's attention heads help to extract patterns in clinical notes and improve model interpretability by showing how the model assigns weights to different inputs.