 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Covid-19 classification with deep neural network and belief functions
Jan 18, 2021
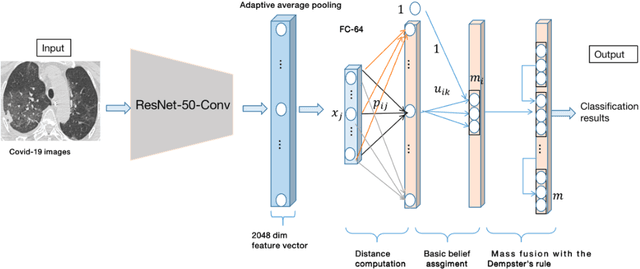


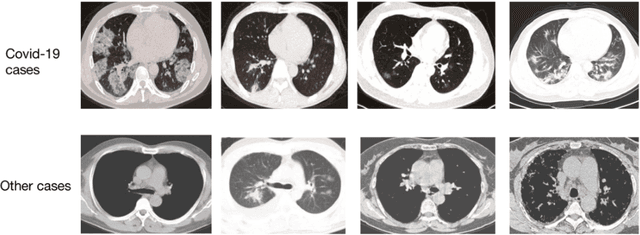
Computed tomography (CT) image provides useful information for radiologists to diagnose Covid-19. However, visual analysis of CT scans is time-consuming. Thus, it is necessary to develop algorithms for automatic Covid-19 detection from CT images. In this paper, we propose a belief function-based convolutional neural network with semi-supervised training to detect Covid-19 cases. Our method first extracts deep features, maps them into belief degree maps and makes the final classification decision. Our results are more reliable and explainable than those of traditional deep learning-based classification models. Experimental results show that our approach is able to achieve a good performance with an accuracy of 0.81, an F1 of 0.812 and an AUC of 0.875.
GraphPB: Graphical Representations of Prosody Boundary in Speech Synthesis
Dec 03, 2020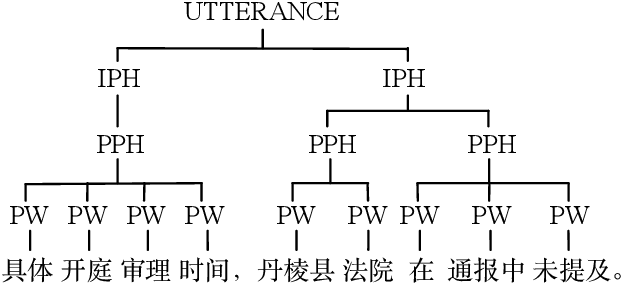

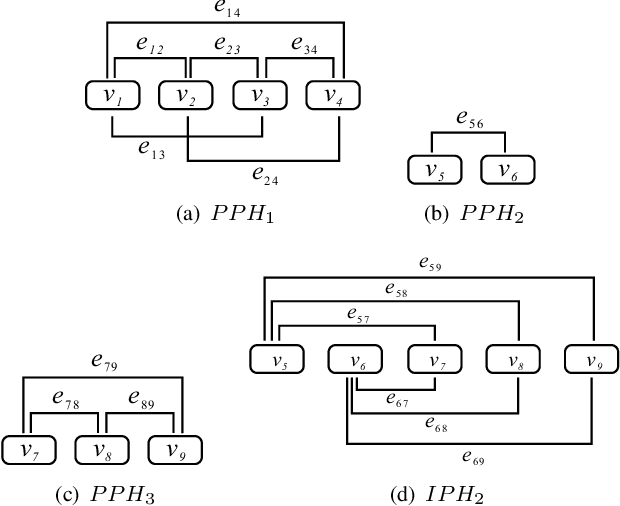

This paper introduces a graphical representation approach of prosody boundary (GraphPB) in the task of Chinese speech synthesis, intending to parse the semantic and syntactic relationship of input sequences in a graphical domain for improving the prosody performance. The nodes of the graph embedding are formed by prosodic words, and the edges are formed by the other prosodic boundaries, namely prosodic phrase boundary (PPH) and intonation phrase boundary (IPH). Different Graph Neural Networks (GNN) like Gated Graph Neural Network (GGNN) and Graph Long Short-term Memory (G-LSTM) are utilised as graph encoders to exploit the graphical prosody boundary information. Graph-to-sequence model is proposed and formed by a graph encoder and an attentional decoder. Two techniques are proposed to embed sequential information into the graph-to-sequence text-to-speech model. The experimental results show that this proposed approach can encode the phonetic and prosody rhythm of an utterance. The mean opinion score (MOS) of these GNN models shows comparative results with the state-of-the-art sequence-to-sequence models with better performance in the aspect of prosody. This provides an alternative approach for prosody modelling in end-to-end speech synthesis.
Semantic Role Labeling Guided Multi-turn Dialogue ReWriter
Oct 03, 2020

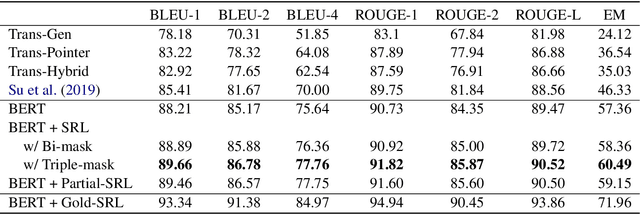
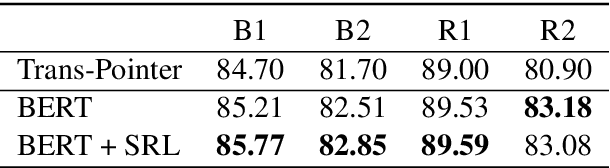
For multi-turn dialogue rewriting, the capacity of effectively modeling the linguistic knowledge in dialog context and getting rid of the noises is essential to improve its performance. Existing attentive models attend to all words without prior focus, which results in inaccurate concentration on some dispensable words. In this paper, we propose to use semantic role labeling (SRL), which highlights the core semantic information of who did what to whom, to provide additional guidance for the rewriter model. Experiments show that this information significantly improves a RoBERTa-based model that already outperforms previous state-of-the-art systems.
TF-CR: Weighting Embeddings for Text Classification
Dec 11, 2020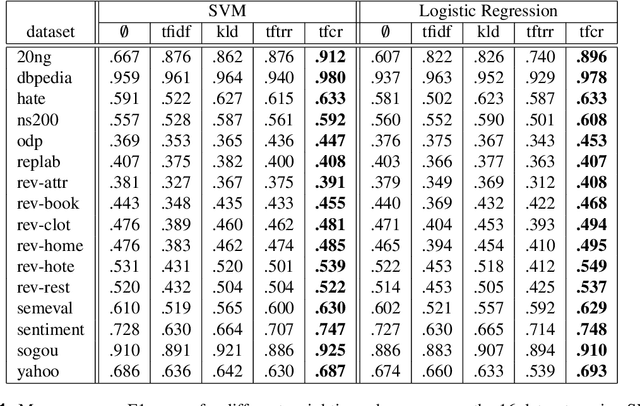
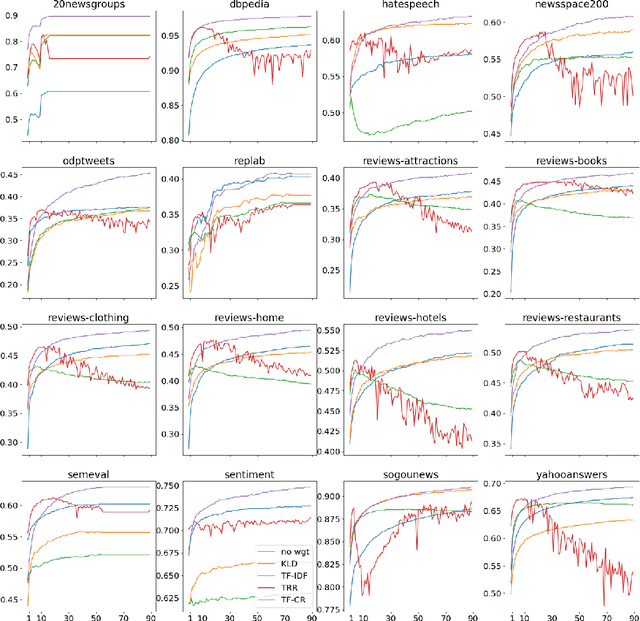
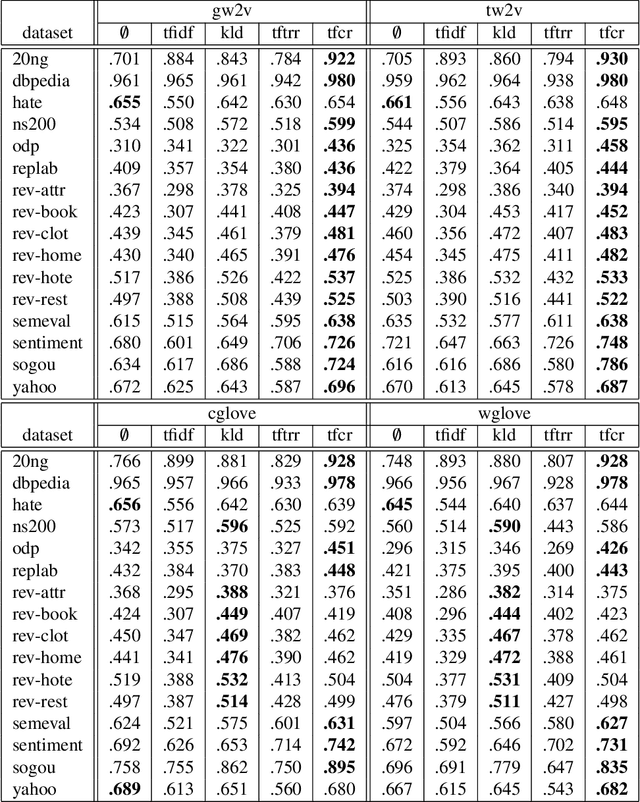
Text classification, as the task consisting in assigning categories to textual instances, is a very common task in information science. Methods learning distributed representations of words, such as word embeddings, have become popular in recent years as the features to use for text classification tasks. Despite the increasing use of word embeddings for text classification, these are generally used in an unsupervised manner, i.e. information derived from class labels in the training data are not exploited. While word embeddings inherently capture the distributional characteristics of words, and contexts observed around them in a large dataset, they aren't optimised to consider the distributions of words across categories in the classification dataset at hand. To optimise text representations based on word embeddings by incorporating class distributions in the training data, we propose the use of weighting schemes that assign a weight to embeddings of each word based on its saliency in each class. To achieve this, we introduce a novel weighting scheme, Term Frequency-Category Ratio (TF-CR), which can weight high-frequency, category-exclusive words higher when computing word embeddings. Our experiments on 16 classification datasets show the effectiveness of TF-CR, leading to improved performance scores over existing weighting schemes, with a performance gap that increases as the size of the training data grows.
Fighting Copycat Agents in Behavioral Cloning from Observation Histories
Oct 28, 2020



Imitation learning trains policies to map from input observations to the actions that an expert would choose. In this setting, distribution shift frequently exacerbates the effect of misattributing expert actions to nuisance correlates among the observed variables. We observe that a common instance of this causal confusion occurs in partially observed settings when expert actions are strongly correlated over time: the imitator learns to cheat by predicting the expert's previous action, rather than the next action. To combat this "copycat problem", we propose an adversarial approach to learn a feature representation that removes excess information about the previous expert action nuisance correlate, while retaining the information necessary to predict the next action. In our experiments, our approach improves performance significantly across a variety of partially observed imitation learning tasks.
Guided Interpolation for Adversarial Training
Feb 15, 2021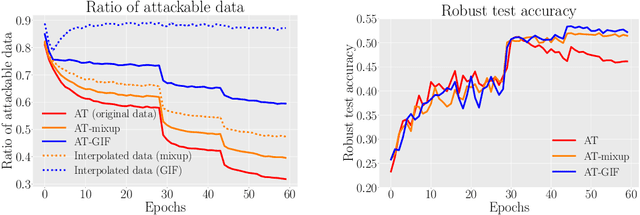

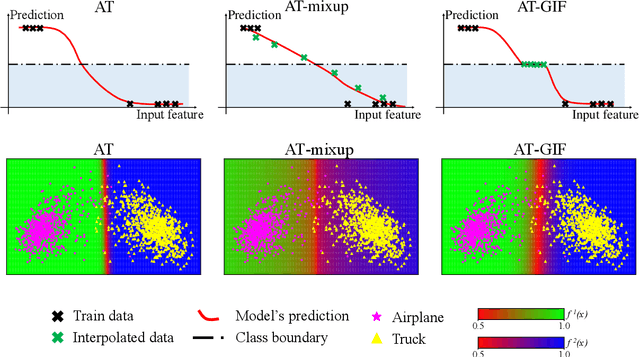

To enhance adversarial robustness, adversarial training learns deep neural networks on the adversarial variants generated by their natural data. However, as the training progresses, the training data becomes less and less attackable, undermining the robustness enhancement. A straightforward remedy is to incorporate more training data, but sometimes incurring an unaffordable cost. In this paper, to mitigate this issue, we propose the guided interpolation framework (GIF): in each epoch, the GIF employs the previous epoch's meta information to guide the data's interpolation. Compared with the vanilla mixup, the GIF can provide a higher ratio of attackable data, which is beneficial to the robustness enhancement; it meanwhile mitigates the model's linear behavior between classes, where the linear behavior is favorable to generalization but not to the robustness. As a result, the GIF encourages the model to predict invariantly in the cluster of each class. Experiments demonstrate that the GIF can indeed enhance adversarial robustness on various adversarial training methods and various datasets.
Statistical and computational thresholds for the planted $k$-densest sub-hypergraph problem
Nov 23, 2020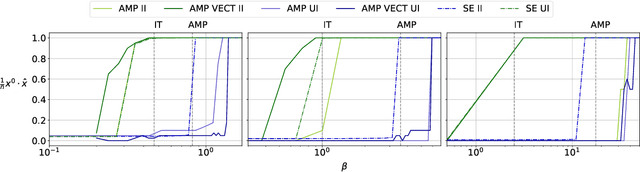

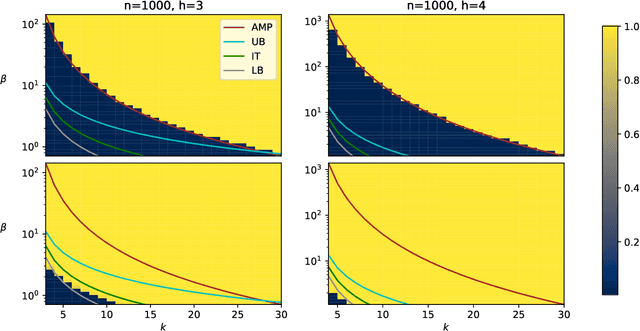
Recovery a planted signal perturbed by noise is a fundamental problem in machine learning. In this work, we consider the problem of recovery a planted $k$-densest sub-hypergraph on $h$-uniform hypergraphs over $n$ nodes. This fundamental problem appears in different contexts, e.g., community detection, average case complexity, and neuroscience applications. We first observe that it can be viewed as a structural variant of tensor PCA in which the hypergraph parameters $k$ and $h$ determine the structure of the signal to be recovered when the observations are contaminated by Gaussian noise. In this work, we provide tight information-theoretic upper and lower bounds for the recovery problem, as well as the first non-trivial algorithmic bounds based on approximate message passing algorithms. The problem exhibits a typical information-to-computational-gap observed in analogous settings, that widens with increasing sparsity of the problem. Interestingly, the bounds show that the structure of the signal does have an impact on the existing bounds of tensor PCA that the unstructured planted signal does not capture.
Artificial intelligence, human rights, democracy, and the rule of law: a primer
Apr 02, 2021In September 2019, the Council of Europe's Committee of Ministers adopted the terms of reference for the Ad Hoc Committee on Artificial Intelligence (CAHAI). The CAHAI is charged with examining the feasibility and potential elements of a legal framework for the design, development, and deployment of AI systems that accord with Council of Europe standards across the interrelated areas of human rights, democracy, and the rule of law. As a first and necessary step in carrying out this responsibility, the CAHAI's Feasibility Study, adopted by its plenary in December 2020, has explored options for an international legal response that fills existing gaps in legislation and tailors the use of binding and non-binding legal instruments to the specific risks and opportunities presented by AI systems. The Study examines how the fundamental rights and freedoms that are already codified in international human rights law can be used as the basis for such a legal framework. The purpose of this primer is to introduce the main concepts and principles presented in the CAHAI's Feasibility Study for a general, non-technical audience. It also aims to provide some background information on the areas of AI innovation, human rights law, technology policy, and compliance mechanisms covered therein. In keeping with the Council of Europe's commitment to broad multi-stakeholder consultations, outreach, and engagement, this primer has been designed to help facilitate the meaningful and informed participation of an inclusive group of stakeholders as the CAHAI seeks feedback and guidance regarding the essential issues raised by the Feasibility Study.
Information Theoretic Limits of Data Shuffling for Distributed Learning
Sep 16, 2016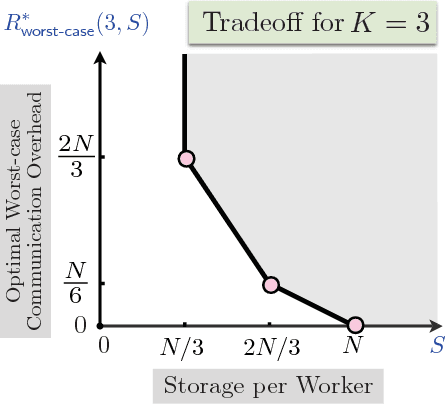
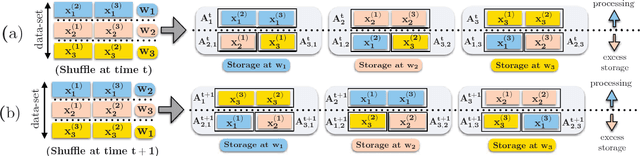
Data shuffling is one of the fundamental building blocks for distributed learning algorithms, that increases the statistical gain for each step of the learning process. In each iteration, different shuffled data points are assigned by a central node to a distributed set of workers to perform local computations, which leads to communication bottlenecks. The focus of this paper is on formalizing and understanding the fundamental information-theoretic trade-off between storage (per worker) and the worst-case communication overhead for the data shuffling problem. We completely characterize the information theoretic trade-off for $K=2$, and $K=3$ workers, for any value of storage capacity, and show that increasing the storage across workers can reduce the communication overhead by leveraging coding. We propose a novel and systematic data delivery and storage update strategy for each data shuffle iteration, which preserves the structural properties of the storage across the workers, and aids in minimizing the communication overhead in subsequent data shuffling iterations.
Liquid Warping GAN with Attention: A Unified Framework for Human Image Synthesis
Nov 23, 2020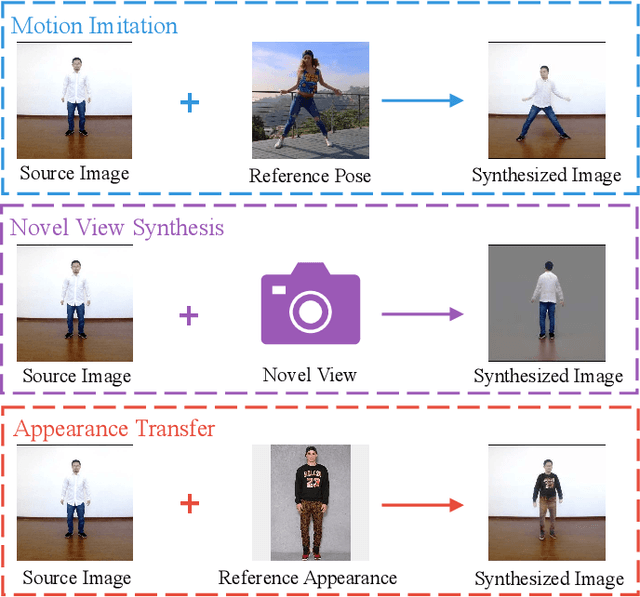
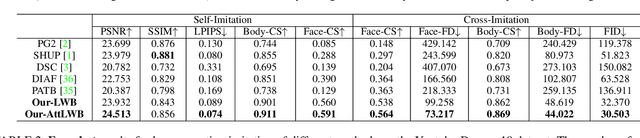
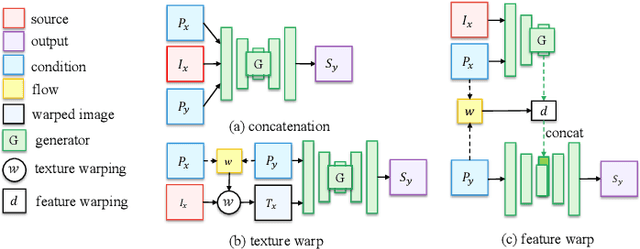
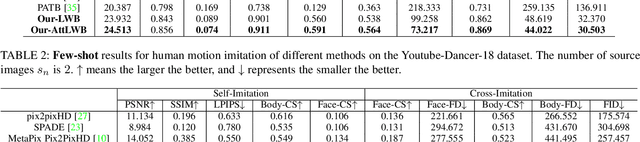
We tackle human image synthesis, including human motion imitation, appearance transfer, and novel view synthesis, within a unified framework. It means that the model, once being trained, can be used to handle all these tasks. The existing task-specific methods mainly use 2D keypoints to estimate the human body structure. However, they only express the position information with no abilities to characterize the personalized shape of the person and model the limb rotations. In this paper, we propose to use a 3D body mesh recovery module to disentangle the pose and shape. It can not only model the joint location and rotation but also characterize the personalized body shape. To preserve the source information, such as texture, style, color, and face identity, we propose an Attentional Liquid Warping GAN with Attentional Liquid Warping Block (AttLWB) that propagates the source information in both image and feature spaces to the synthesized reference. Specifically, the source features are extracted by a denoising convolutional auto-encoder for characterizing the source identity well. Furthermore, our proposed method can support a more flexible warping from multiple sources. To further improve the generalization ability of the unseen source images, a one/few-shot adversarial learning is applied. In detail, it firstly trains a model in an extensive training set. Then, it finetunes the model by one/few-shot unseen image(s) in a self-supervised way to generate high-resolution (512 x 512 and 1024 x 1024) results. Also, we build a new dataset, namely iPER dataset, for the evaluation of human motion imitation, appearance transfer, and novel view synthesis. Extensive experiments demonstrate the effectiveness of our methods in terms of preserving face identity, shape consistency, and clothes details. All codes and dataset are available on https://impersonator.org/work/impersonator-plus-plus.html.