 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Robust Registration of Multimodal Remote Sensing Images Based on Structural Similarity
Mar 31, 2021

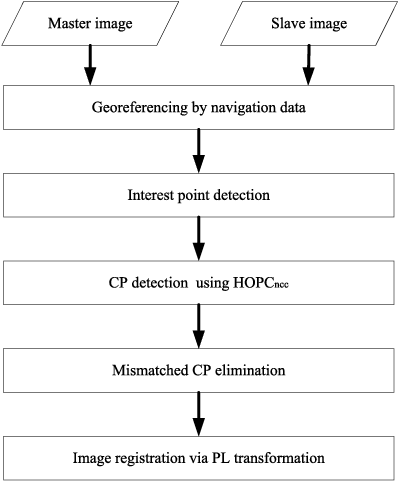


Automatic registration of multimodal remote sensing data (e.g., optical, LiDAR, SAR) is a challenging task due to the significant non-linear radiometric differences between these data. To address this problem, this paper proposes a novel feature descriptor named the Histogram of Orientated Phase Congruency (HOPC), which is based on the structural properties of images. Furthermore, a similarity metric named HOPCncc is defined, which uses the normalized correlation coefficient (NCC) of the HOPC descriptors for multimodal registration. In the definition of the proposed similarity metric, we first extend the phase congruency model to generate its orientation representation, and use the extended model to build HOPCncc. Then a fast template matching scheme for this metric is designed to detect the control points between images. The proposed HOPCncc aims to capture the structural similarity between images, and has been tested with a variety of optical, LiDAR, SAR and map data. The results show that HOPCncc is robust against complex non-linear radiometric differences and outperforms the state-of-the-art similarities metrics (i.e., NCC and mutual information) in matching performance. Moreover, a robust registration method is also proposed in this paper based on HOPCncc, which is evaluated using six pairs of multimodal remote sensing images. The experimental results demonstrate the effectiveness of the proposed method for multimodal image registration.
Bi-level Off-policy Reinforcement Learning for Volt/VAR Control Involving Continuous and Discrete Devices
Apr 13, 2021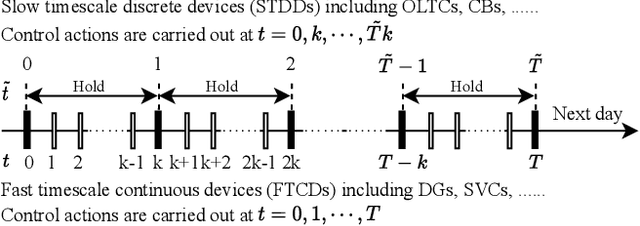
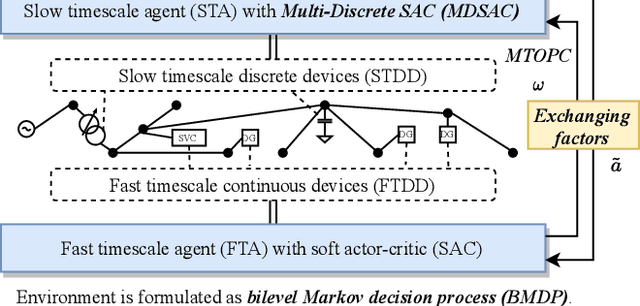
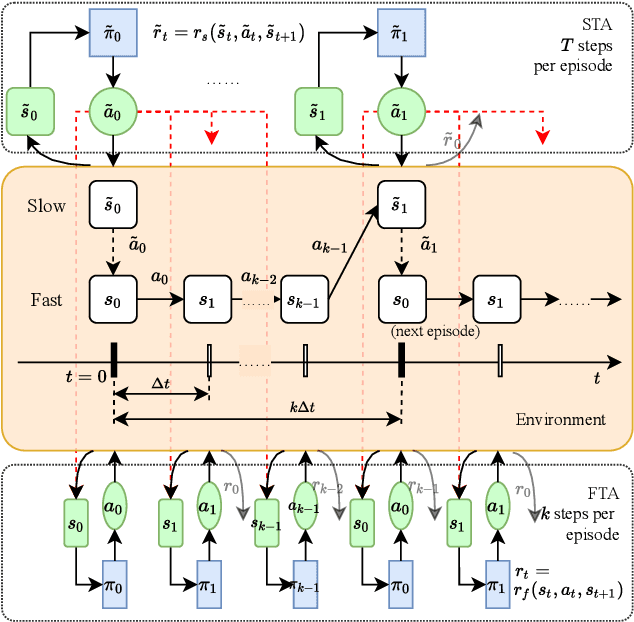
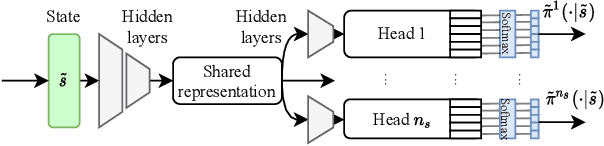
In Volt/Var control (VVC) of active distribution networks(ADNs), both slow timescale discrete devices (STDDs) and fast timescale continuous devices (FTCDs) are involved. The STDDs such as on-load tap changers (OLTC) and FTCDs such as distributed generators should be coordinated in time sequence. Such VCC is formulated as a two-timescale optimization problem to jointly optimize FTCDs and STDDs in ADNs. Traditional optimization methods are heavily based on accurate models of the system, but sometimes impractical because of their unaffordable effort on modelling. In this paper, a novel bi-level off-policy reinforcement learning (RL) algorithm is proposed to solve this problem in a model-free manner. A Bi-level Markov decision process (BMDP) is defined to describe the two-timescale VVC problem and separate agents are set up for the slow and fast timescale sub-problems. For the fast timescale sub-problem, we adopt an off-policy RL method soft actor-critic with high sample efficiency. For the slow one, we develop an off-policy multi-discrete soft actor-critic (MDSAC) algorithm to address the curse of dimensionality with various STDDs. To mitigate the non-stationary issue existing the two agents' learning processes, we propose a multi-timescale off-policy correction (MTOPC) method by adopting importance sampling technique. Comprehensive numerical studies not only demonstrate that the proposed method can achieve stable and satisfactory optimization of both STDDs and FTCDs without any model information, but also support that the proposed method outperforms existing two-timescale VVC methods.
CSFCube -- A Test Collection of Computer Science Research Articles for Faceted Query by Example
Mar 24, 2021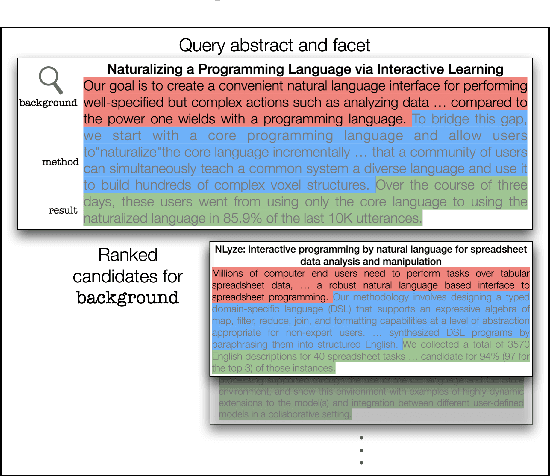
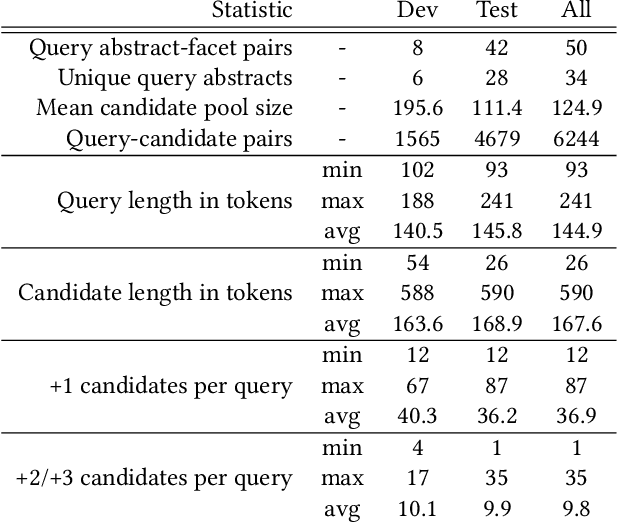
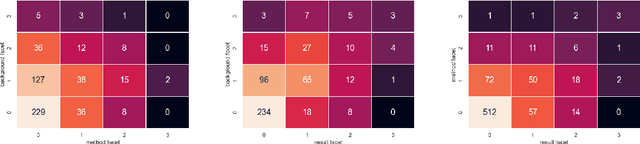
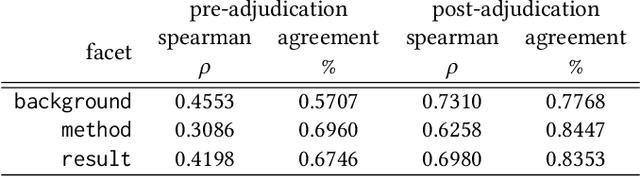
Query by Example is a well-known information retrieval task in which a document is chosen by the user as the search query and the goal is to retrieve relevant documents from a large collection. However, a document often covers multiple aspects of a topic. To address this scenario we introduce the task of faceted Query by Example in which users can also specify a finer grained aspect in addition to the input query document. We focus on the application of this task in scientific literature search. We envision models which are able to retrieve scientific papers analogous to a query scientific paper along specifically chosen rhetorical structure elements as one solution to this problem. In this work, the rhetorical structure elements, which we refer to as facets, indicate "background", "method", or "result" aspects of a scientific paper. We introduce and describe an expert annotated test collection to evaluate models trained to perform this task. Our test collection consists of a diverse set of 50 query documents, drawn from computational linguistics and machine learning venues. We carefully followed the annotation guideline used by TREC for depth-k pooling (k = 100 or 250) and the resulting data collection consists of graded relevance scores with high annotation agreement. The data is freely available for research purposes.
Automatic Flare Spot Artifact Detection and Removal in Photographs
Mar 07, 2021

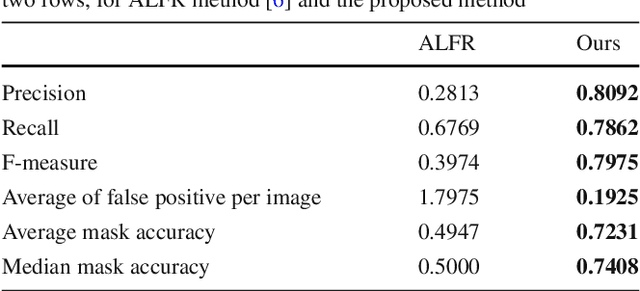
Flare spot is one type of flare artifact caused by a number of conditions, frequently provoked by one or more high-luminance sources within or close to the camera field of view. When light rays coming from a high-luminance source reach the front element of a camera, it can produce intra-reflections within camera elements that emerge at the film plane forming non-image information or flare on the captured image. Even though preventive mechanisms are used, artifacts can appear. In this paper, we propose a robust computational method to automatically detect and remove flare spot artifacts. Our contribution is threefold: firstly, we propose a characterization which is based on intrinsic properties that a flare spot is likely to satisfy; secondly, we define a new confidence measure able to select flare spots among the candidates; and, finally, a method to accurately determine the flare region is given. Then, the detected artifacts are removed by using exemplar-based inpainting. We show that our algorithm achieve top-tier quantitative and qualitative performance.
* Journal of Mathematical Imaging and Vision, 2019
Federated mmWave Beam Selection Utilizing LIDAR Data
Feb 04, 2021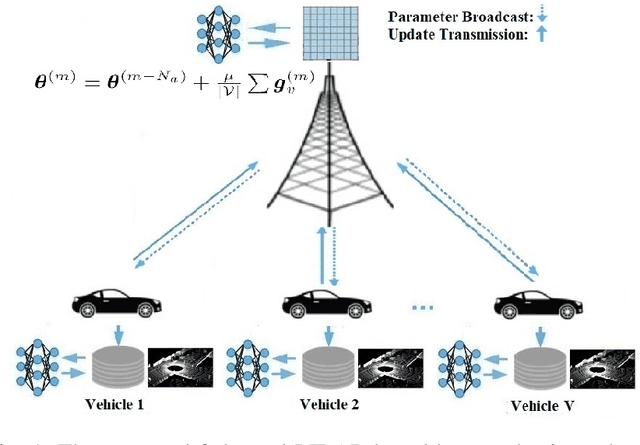

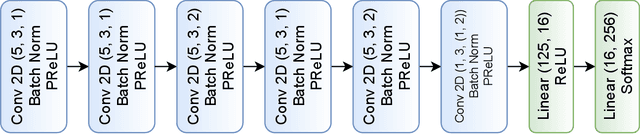
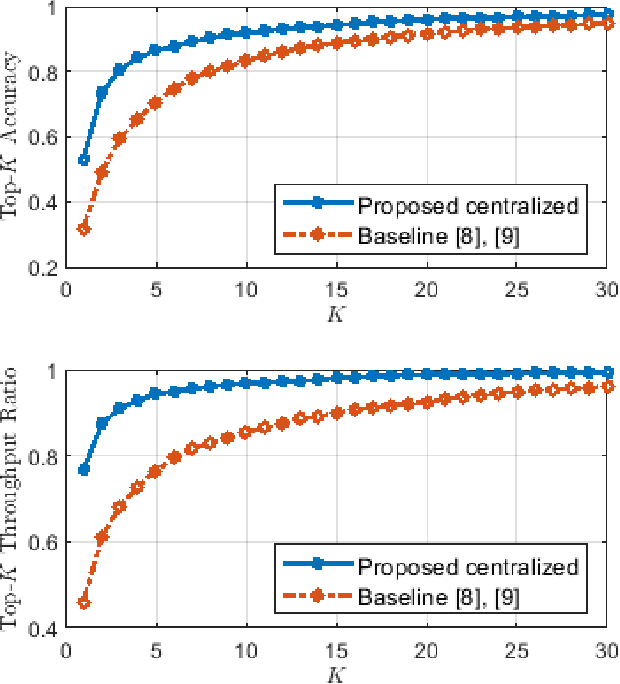
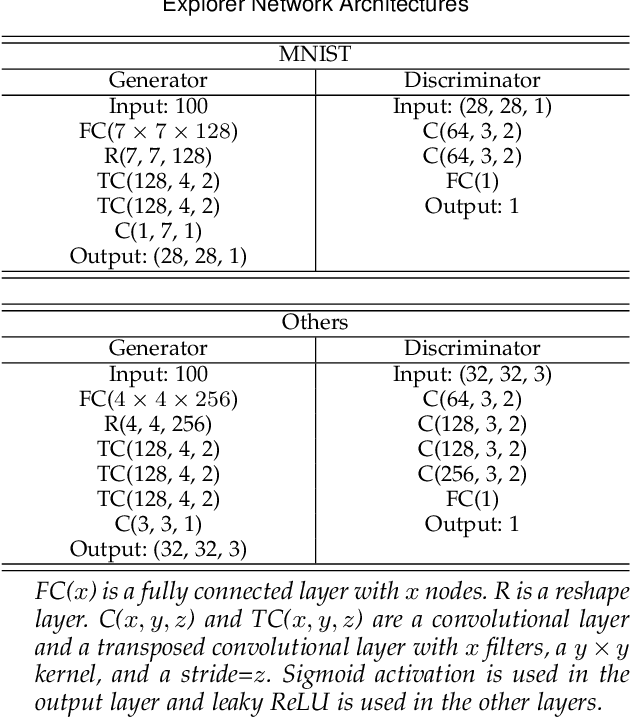
Efficient link configuration in millimeter wave (mmWave) communication systems is a crucial yet challenging task due to the overhead imposed by beam selection on the network performance. For vehicle-to-infrastructure (V2I) networks, side information from LIDAR sensors mounted on the vehicles has been leveraged to reduce the beam search overhead. In this letter, we propose distributed LIDAR aided beam selection for V2I mmWave communication systems utilizing federated training. In the proposed scheme, connected vehicles collaborate to train a shared neural network (NN) on their locally available LIDAR data during normal operation of the system. We also propose an alternative reduced-complexity convolutional NN (CNN) architecture and LIDAR preprocessing, which significantly outperforms previous works in terms of both the performance and the complexity.
Teacher-Explorer-Student Learning: A Novel Learning Method for Open Set Recognition
Mar 23, 2021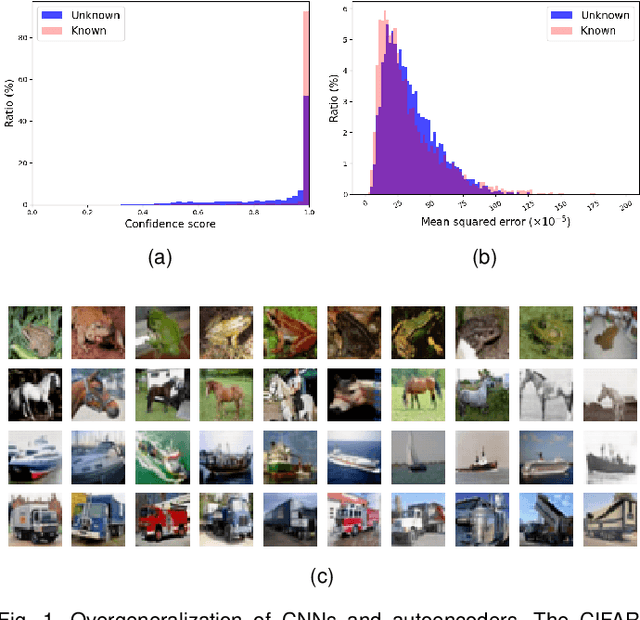
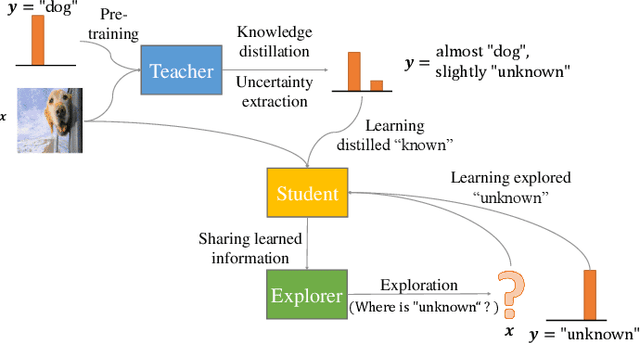
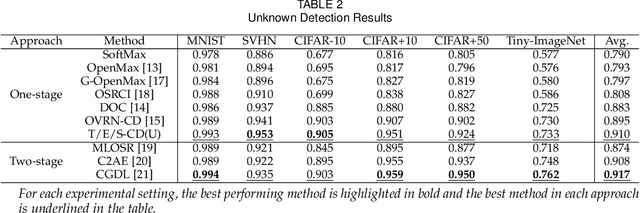
If an unknown example that is not seen during training appears, most recognition systems usually produce overgeneralized results and determine that the example belongs to one of the known classes. To address this problem, teacher-explorer-student (T/E/S) learning, which adopts the concept of open set recognition (OSR) that aims to reject unknown samples while minimizing the loss of classification performance on known samples, is proposed in this study. In this novel learning method, overgeneralization of deep learning classifiers is significantly reduced by exploring various possibilities of unknowns. Here, the teacher network extracts some hints about unknowns by distilling the pretrained knowledge about knowns and delivers this distilled knowledge to the student. After learning the distilled knowledge, the student network shares the learned information with the explorer network. Then, the explorer network shares its exploration results by generating unknown-like samples and feeding the samples to the student network. By repeating this alternating learning process, the student network experiences a variety of synthetic unknowns, reducing overgeneralization. Extensive experiments were conducted, and the experimental results showed that each component proposed in this paper significantly contributes to the improvement in OSR performance. As a result, the proposed T/E/S learning method outperformed current state-of-the-art methods.
Attention, please! A survey of Neural Attention Models in Deep Learning
Mar 31, 2021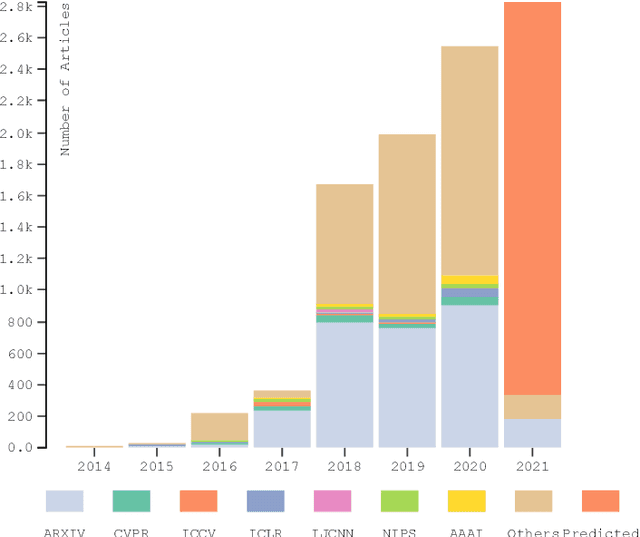
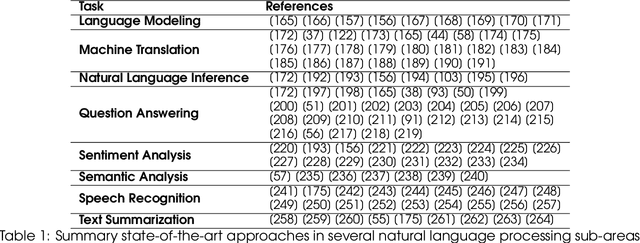
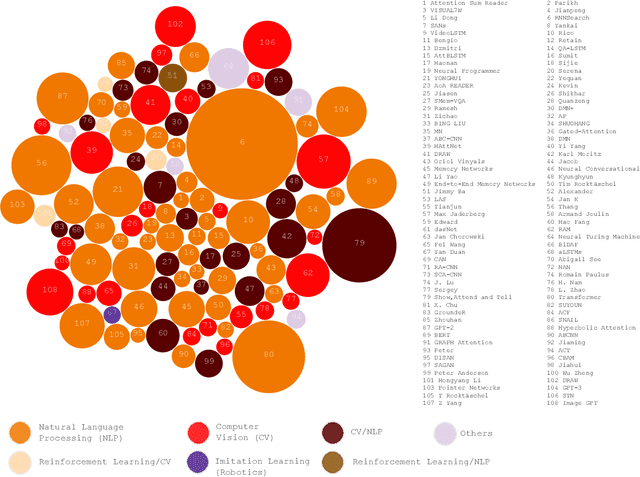
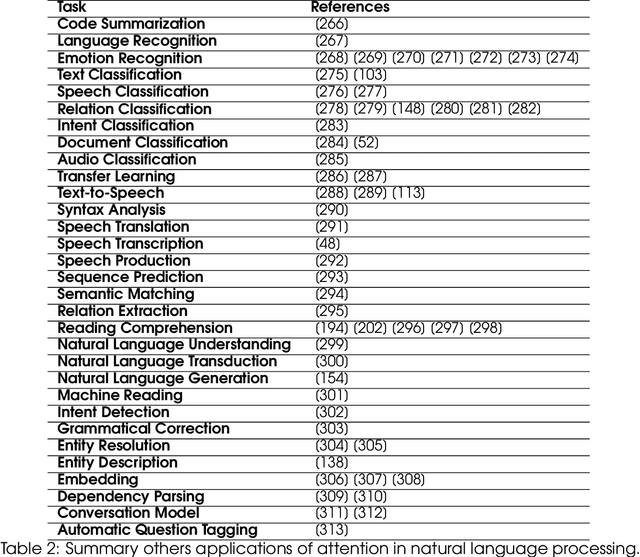
In humans, Attention is a core property of all perceptual and cognitive operations. Given our limited ability to process competing sources, attention mechanisms select, modulate, and focus on the information most relevant to behavior. For decades, concepts and functions of attention have been studied in philosophy, psychology, neuroscience, and computing. For the last six years, this property has been widely explored in deep neural networks. Currently, the state-of-the-art in Deep Learning is represented by neural attention models in several application domains. This survey provides a comprehensive overview and analysis of developments in neural attention models. We systematically reviewed hundreds of architectures in the area, identifying and discussing those in which attention has shown a significant impact. We also developed and made public an automated methodology to facilitate the development of reviews in the area. By critically analyzing 650 works, we describe the primary uses of attention in convolutional, recurrent networks and generative models, identifying common subgroups of uses and applications. Furthermore, we describe the impact of attention in different application domains and their impact on neural networks' interpretability. Finally, we list possible trends and opportunities for further research, hoping that this review will provide a succinct overview of the main attentional models in the area and guide researchers in developing future approaches that will drive further improvements.
Actionable Cognitive Twins for Decision Making in Manufacturing
Mar 23, 2021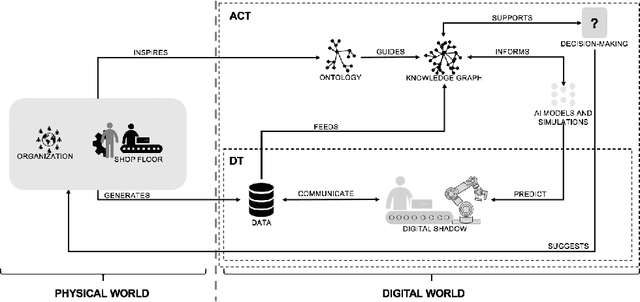
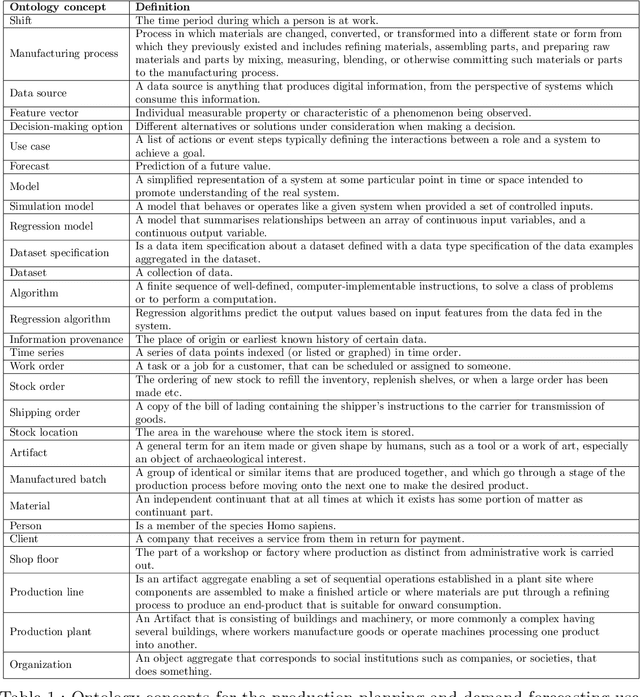
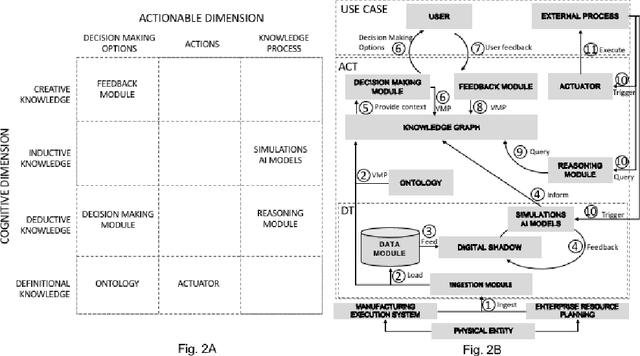
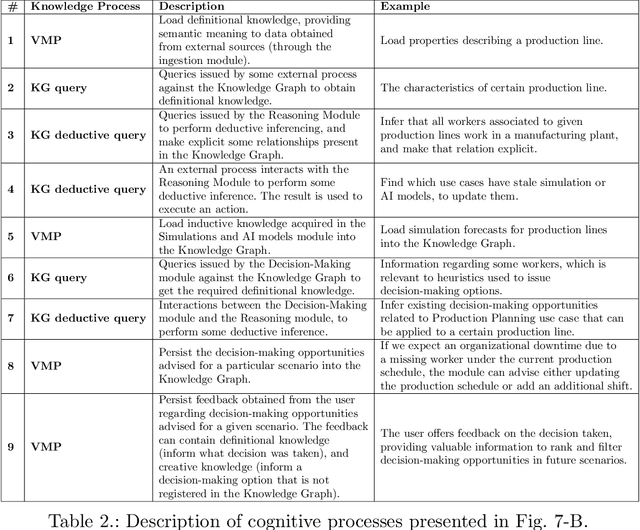
Actionable Cognitive Twins are the next generation Digital Twins enhanced with cognitive capabilities through a knowledge graph and artificial intelligence models that provide insights and decision-making options to the users. The knowledge graph describes the domain-specific knowledge regarding entities and interrelationships related to a manufacturing setting. It also contains information on possible decision-making options that can assist decision-makers, such as planners or logisticians. In this paper, we propose a knowledge graph modeling approach to construct actionable cognitive twins for capturing specific knowledge related to demand forecasting and production planning in a manufacturing plant. The knowledge graph provides semantic descriptions and contextualization of the production lines and processes, including data identification and simulation or artificial intelligence algorithms and forecasts used to support them. Such semantics provide ground for inferencing, relating different knowledge types: creative, deductive, definitional, and inductive. To develop the knowledge graph models for describing the use case completely, systems thinking approach is proposed to design and verify the ontology, develop a knowledge graph and build an actionable cognitive twin. Finally, we evaluate our approach in two use cases developed for a European original equipment manufacturer related to the automotive industry as part of the European Horizon 2020 project FACTLOG.
Covid-19 risk factors: Statistical learning from German healthcare claims data
Feb 04, 2021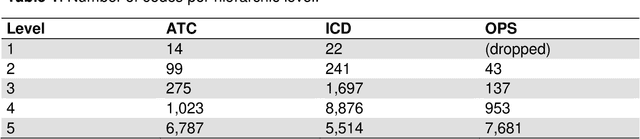
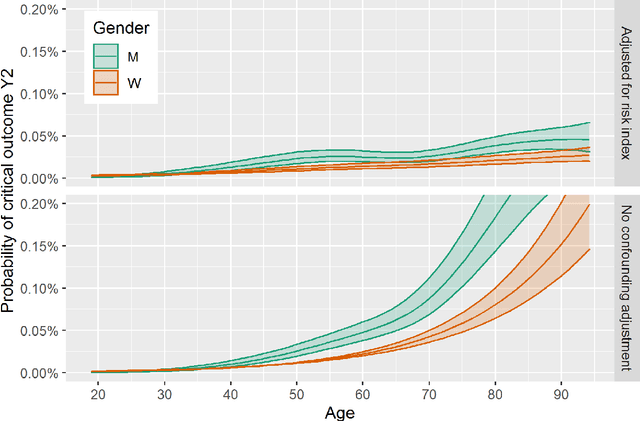
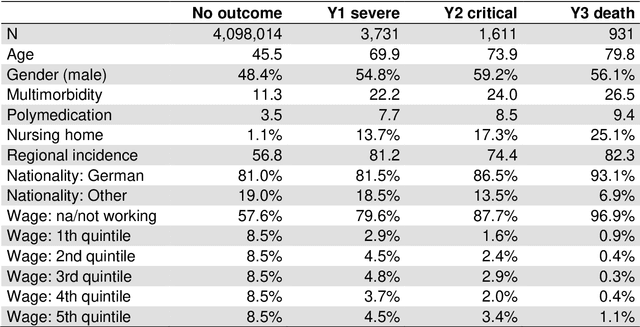
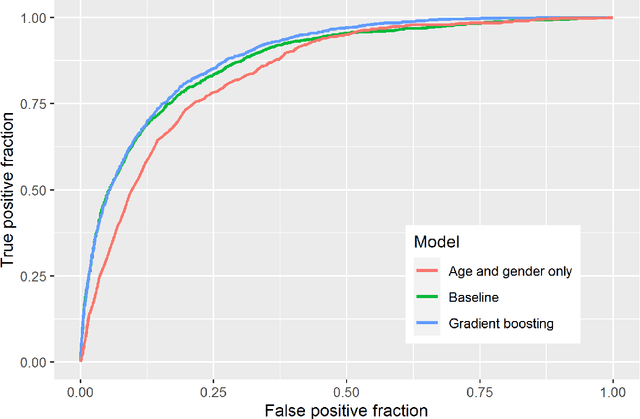
We analyse prior risk factors for severe, critical or fatal courses of Covid-19 based on a retrospective cohort study using claims data of the AOK Bayern. As a methodological contribution, we avoid prior grouping and pre-selection of candidate risk factors and use fine-grained hierarchical information from medical classification systems for diagnoses, pharmaceuticals and procedures, using more than 33,000 covariates. Our approach is competitive to formal analyses using well-specified morbidity groups without needing prior subject-matter knowledge. The methodology and our published coefficients may be of interest for decision makers when prioritizing protective measures towards vulnerable subpopulations as well as for researchers aiming to adjust for confounders in studies of individual risk factors also for smaller cohorts.
Towards More Flexible and Accurate Object Tracking with Natural Language: Algorithms and Benchmark
Mar 31, 2021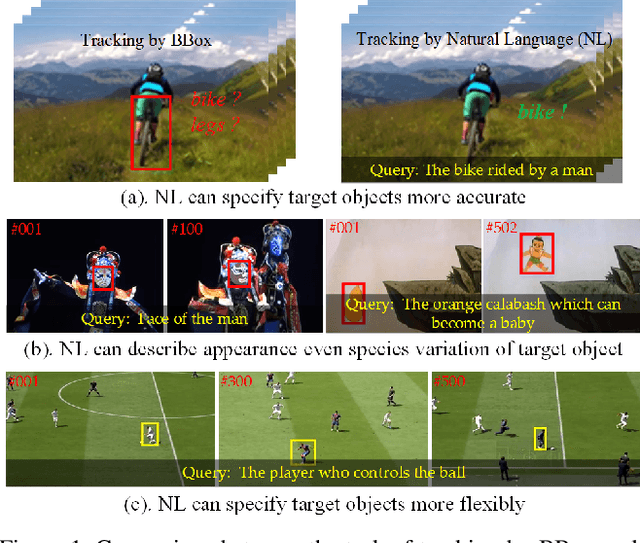
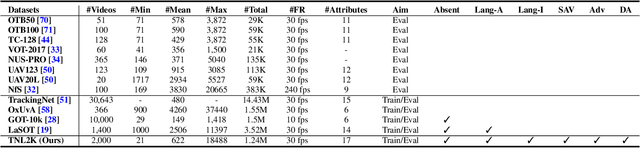

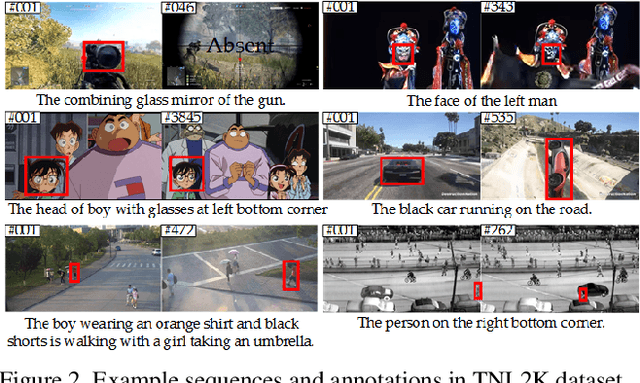
Tracking by natural language specification is a new rising research topic that aims at locating the target object in the video sequence based on its language description. Compared with traditional bounding box (BBox) based tracking, this setting guides object tracking with high-level semantic information, addresses the ambiguity of BBox, and links local and global search organically together. Those benefits may bring more flexible, robust and accurate tracking performance in practical scenarios. However, existing natural language initialized trackers are developed and compared on benchmark datasets proposed for tracking-by-BBox, which can't reflect the true power of tracking-by-language. In this work, we propose a new benchmark specifically dedicated to the tracking-by-language, including a large scale dataset, strong and diverse baseline methods. Specifically, we collect 2k video sequences (contains a total of 1,244,340 frames, 663 words) and split 1300/700 for the train/testing respectively. We densely annotate one sentence in English and corresponding bounding boxes of the target object for each video. We also introduce two new challenges into TNL2K for the object tracking task, i.e., adversarial samples and modality switch. A strong baseline method based on an adaptive local-global-search scheme is proposed for future works to compare. We believe this benchmark will greatly boost related researches on natural language guided tracking.