 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
BAM: A Lightweight and Efficient Balanced Attention Mechanism for Single Image Super Resolution
Apr 15, 2021
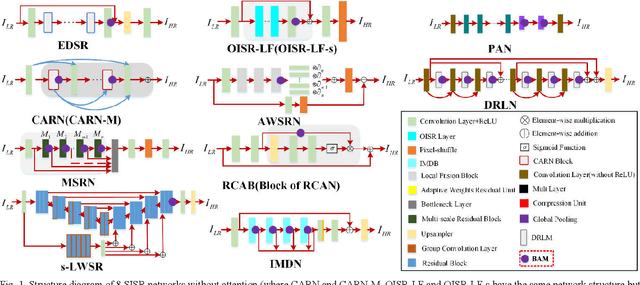

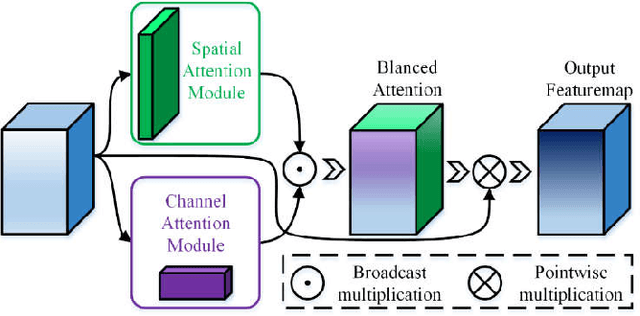
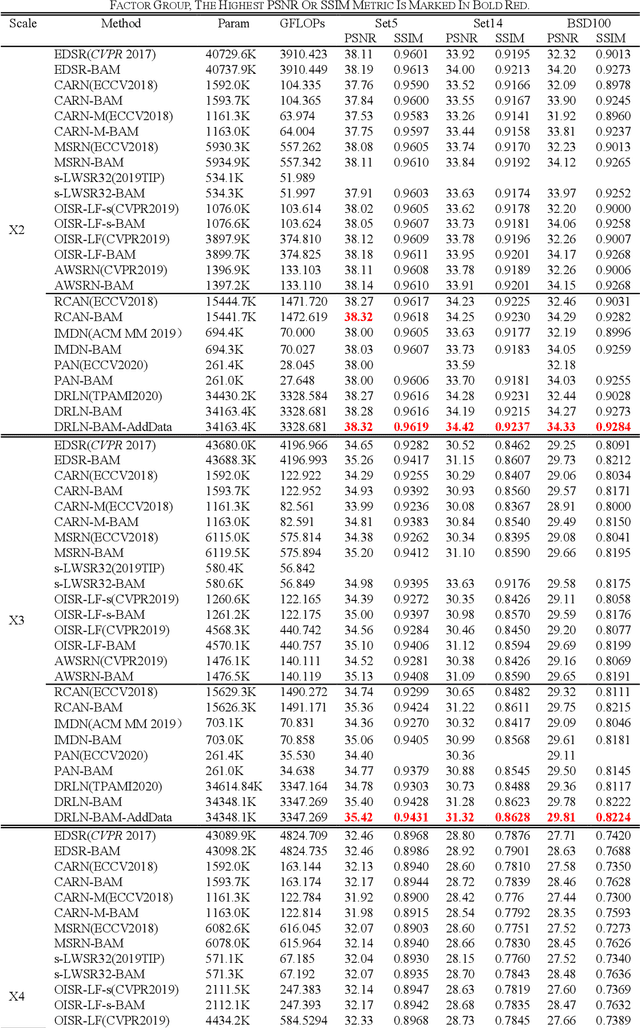
Single image super-resolution (SISR) is one of the most challenging problems in the field of computer vision. Among the deep convolutional neural network based methods, attention mechanism has shown the enormous potential. However, due to the diverse network architectures, there is a lack of a universal attention mechanism for the SISR task. In this paper, we propose a lightweight and efficient Balanced Attention Mechanism (BAM), which can be generally applicable for different SISR networks. It consists of Avgpool Channel Attention Module (ACAM) and Maxpool Spatial Attention Module (MSAM). These two modules are connected in parallel to minimize the error accumulation and the crosstalk. To reduce the undesirable effect of redundant information on the attention generation, we only apply Avgpool for channel attention because Maxpool could pick up the illusive extreme points in the feature map across the spatial dimensions, and we only apply Maxpool for spatial attention because the useful features along the channel dimension usually exist in the form of maximum values for SISR task. To verify the efficiency and robustness of BAM, we apply it to 12 state-of-the-art SISR networks, among which eight were without attention thus we plug BAM in and four were with attention thus we replace its original attention module with BAM. We experiment on Set5, Set14 and BSD100 benchmark datasets with the scale factor of x2 , x3 and x4 . The results demonstrate that BAM can generally improve the network performance. Moreover, we conduct the ablation experiments to prove the minimalism of BAM. Our results show that the parallel structure of BAM can better balance channel and spatial attentions, thus outperforming the series structure of prior Convolutional Block Attention Module (CBAM).
3D Vessel Reconstruction in OCT-Angiography via Depth Map Estimation
Feb 26, 2021
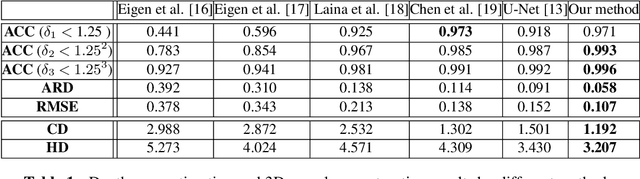
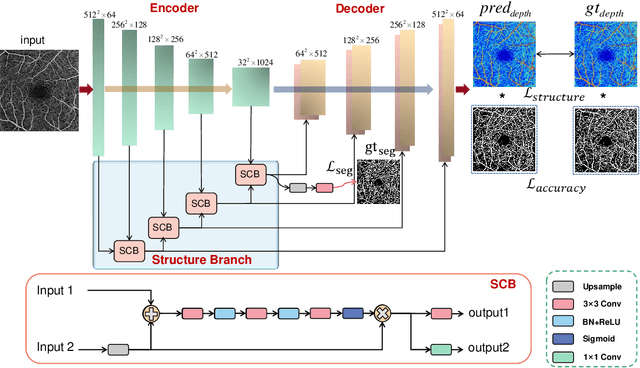
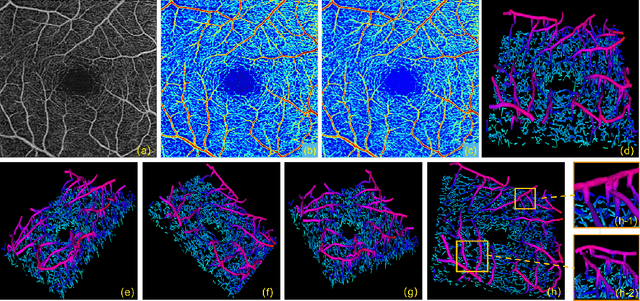
Optical Coherence Tomography Angiography (OCTA) has been increasingly used in the management of eye and systemic diseases in recent years. Manual or automatic analysis of blood vessel in 2D OCTA images (en face angiograms) is commonly used in clinical practice, however it may lose rich 3D spatial distribution information of blood vessels or capillaries that are useful for clinical decision-making. In this paper, we introduce a novel 3D vessel reconstruction framework based on the estimation of vessel depth maps from OCTA images. First, we design a network with structural constraints to predict the depth of blood vessels in OCTA images. In order to promote the accuracy of the predicted depth map at both the overall structure- and pixel- level, we combine MSE and SSIM loss as the training loss function. Finally, the 3D vessel reconstruction is achieved by utilizing the estimated depth map and 2D vessel segmentation results. Experimental results demonstrate that our method is effective in the depth prediction and 3D vessel reconstruction for OCTA images.% results may be used to guide subsequent vascular analysis
Constrained plasticity reserve as a natural way to control frequency and weights in spiking neural networks
Mar 15, 2021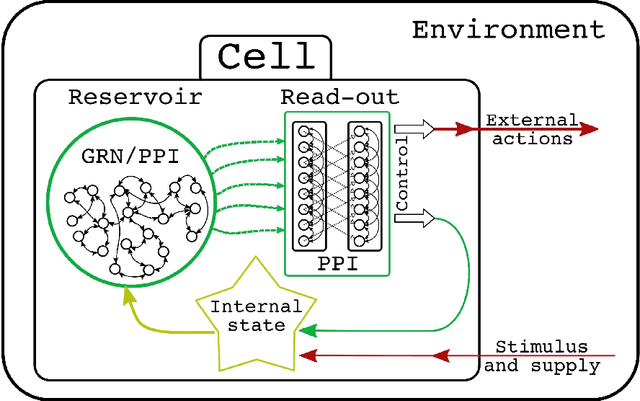
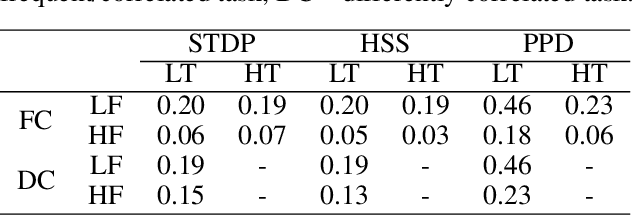
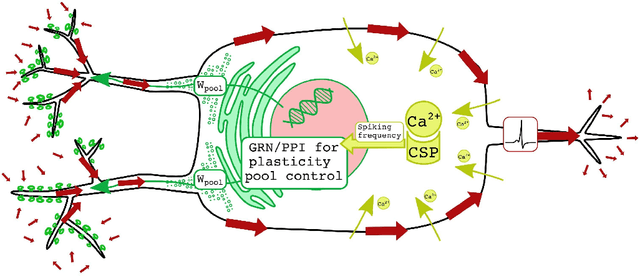
Biological neurons have adaptive nature and perform complex computations involving the filtering of redundant information. Such processing is often associated with Bayesian inference. Yet most common models of neural cells, including biologically plausible, such as Hodgkin-Huxley or Izhikevich do not possess predictive dynamics on the level of a single cell. The modern rules of synaptic plasticity or interconnections weights adaptation also do not provide grounding for the ability of neurons to adapt to the ever-changing input signal intensity. While natural neuron synaptic growth is precisely controlled and restricted by protein supply and recycling, weight correction rules such as widely used STDP are efficiently unlimited in change rate and scale. In the present article, we will introduce new mechanics of interconnection between neuron firing rate homeostasis and weight change by means of STDP growth bounded by abstract protein reserve, controlled by the intracellular optimization algorithm. We will show, how these cellular dynamics help neurons to filter out the intense signals to help neurons keep a stable firing rate. We will also examine that such filtering does not affect the ability of neurons to recognize the correlated inputs in unsupervised mode. Such an approach might be used in the machine learning domain to improve the robustness of AI systems.
Sparse approximation in learning via neural ODEs
Feb 26, 2021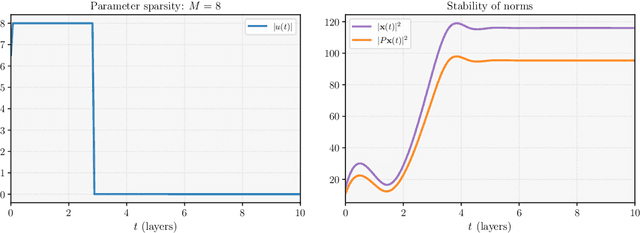
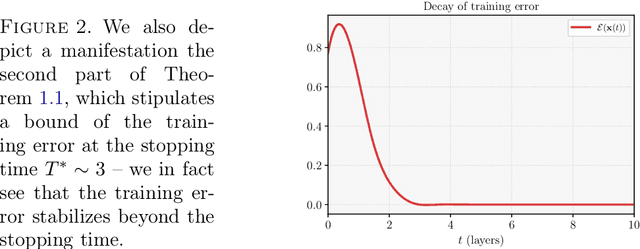
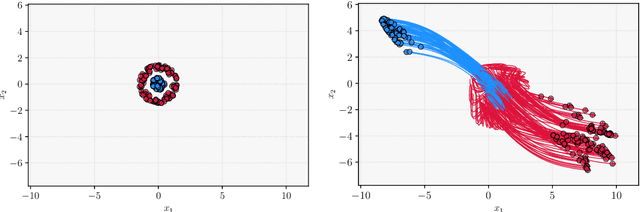
We consider the continuous-time, neural ordinary differential equation (neural ODE) perspective of deep supervised learning, and study the impact of the final time horizon $T$ in training. We focus on a cost consisting of an integral of the empirical risk over the time interval, and $L^1$--parameter regularization. Under homogeneity assumptions on the dynamics (typical for ReLU activations), we prove that any global minimizer is sparse, in the sense that there exists a positive stopping time $T^*$ beyond which the optimal parameters vanish. Moreover, under appropriate interpolation assumptions on the neural ODE, we provide quantitative estimates of the stopping time $T^\ast$, and of the training error of the trajectories at the stopping time. The latter stipulates a quantitative approximation property of neural ODE flows with sparse parameters. In practical terms, a shorter time-horizon in the training problem can be interpreted as considering a shallower residual neural network (ResNet), and since the optimal parameters are concentrated over a shorter time horizon, such a consideration may lower the computational cost of training without discarding relevant information.
Intuitively Assessing ML Model Reliability through Example-Based Explanations and Editing Model Inputs
Feb 17, 2021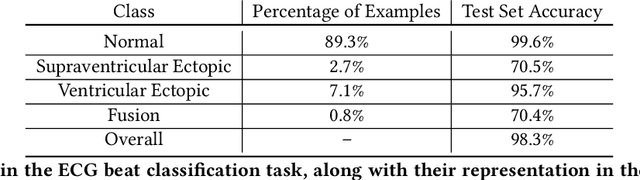
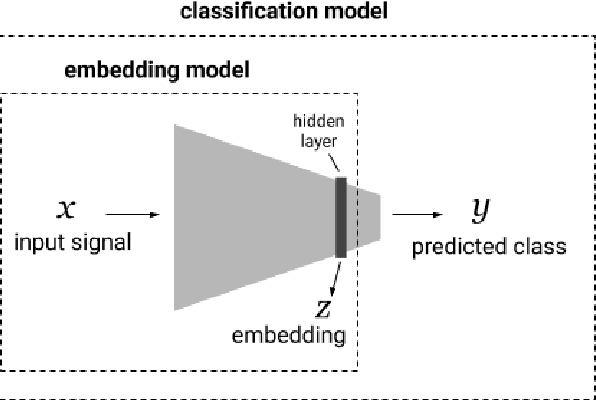
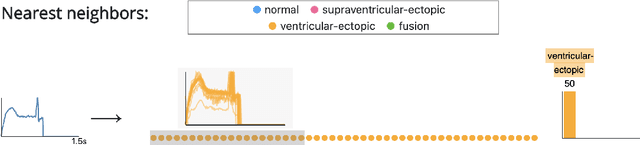
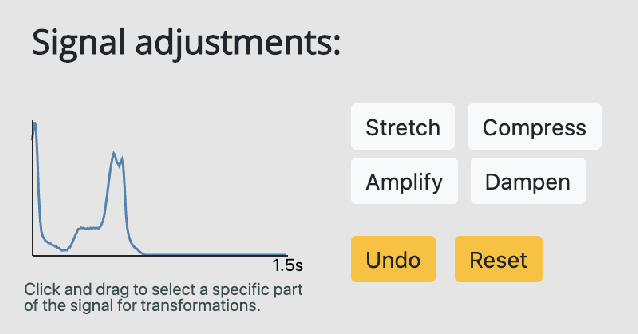
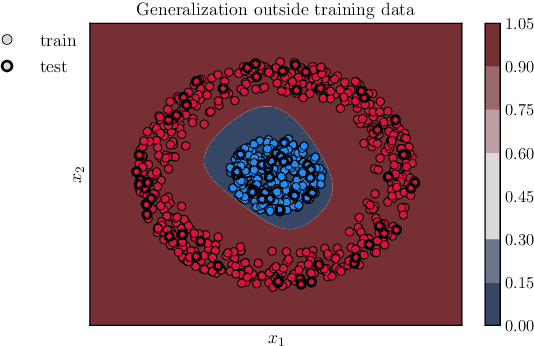
Interpretability methods aim to help users build trust in and understand the capabilities of machine learning models. However, existing approaches often rely on abstract, complex visualizations that poorly map to the task at hand or require non-trivial ML expertise to interpret. Here, we present two interface modules to facilitate a more intuitive assessment of model reliability. To help users better characterize and reason about a model's uncertainty, we visualize raw and aggregate information about a given input's nearest neighbors in the training dataset. Using an interactive editor, users can manipulate this input in semantically-meaningful ways, determine the effect on the output, and compare against their prior expectations. We evaluate our interface using an electrocardiogram beat classification case study. Compared to a baseline feature importance interface, we find that 9 physicians are better able to align the model's uncertainty with clinically relevant factors and build intuition about its capabilities and limitations.
Revising FUNSD dataset for key-value detection in document images
Oct 11, 2020
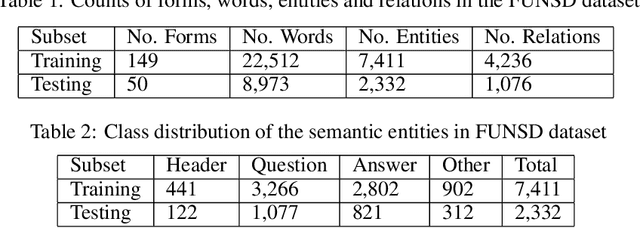
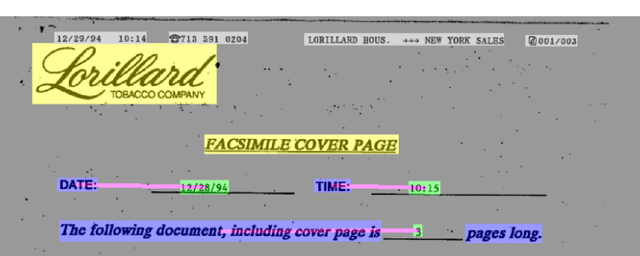

FUNSD is one of the limited publicly available datasets for information extraction from document im-ages. The information in the FUNSD dataset is defined by text areas of four categories ("key", "value", "header", "other", and "background") and connectivity between areas as key-value relations. In-specting FUNSD, we found several inconsistency in labeling, which impeded its applicability to thekey-value extraction problem. In this report, we described some labeling issues in FUNSD and therevision we made to the dataset. We also reported our implementation of for key-value detection onFUNSD using a UNet model as baseline results and an improved UNet model with Channel-InvariantDeformable Convolution.
Spatio-temporal encoding improves neuromorphic tactile texture classification
Oct 27, 2020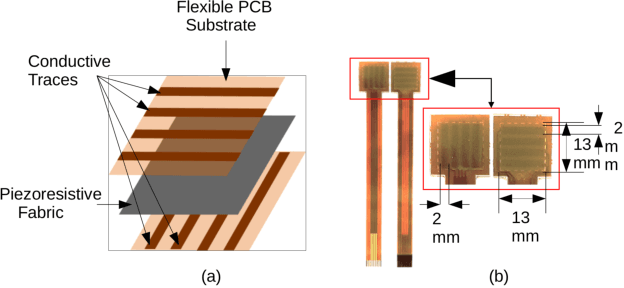


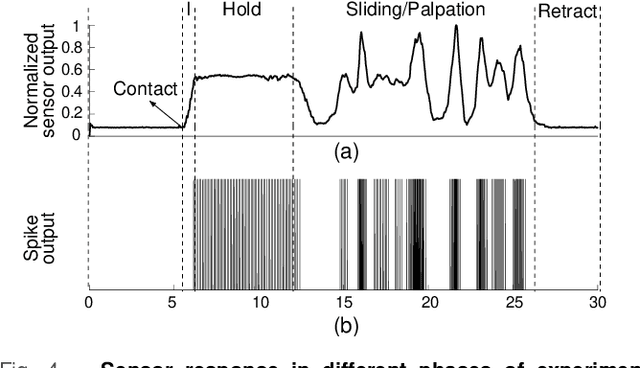
With the increase in interest in deployment of robots in unstructured environments to work alongside humans, the development of human-like sense of touch for robots becomes important. In this work, we implement a multi-channel neuromorphic tactile system that encodes contact events as discrete spike events that mimic the behavior of slow adapting mechanoreceptors. We study the impact of information pooling across artificial mechanoreceptors on classification performance of spatially non-uniform naturalistic textures. We encoded the spatio-temporal activation patterns of mechanoreceptors through gray-level co-occurrence matrix computed from time-varying mean spiking rate-based tactile response volume. We found that this approach greatly improved texture classification in comparison to use of individual mechanoreceptor response alone. In addition, the performance was also more robust to changes in sliding velocity. The importance of exploiting precise spatial and temporal correlations between sensory channels is evident from the fact that on either removal of precise temporal information or altering of spatial structure of response pattern, a significant performance drop was observed. This study thus demonstrates the superiority of population coding approaches that can exploit the precise spatio-temporal information encoded in activation patterns of mechanoreceptor populations. It, therefore, makes an advance in the direction of development of bio-inspired tactile systems required for realistic touch applications in robotics and prostheses.
MHSA-Net: Multi-Head Self-Attention Network for Occluded Person Re-Identification
Aug 11, 2020
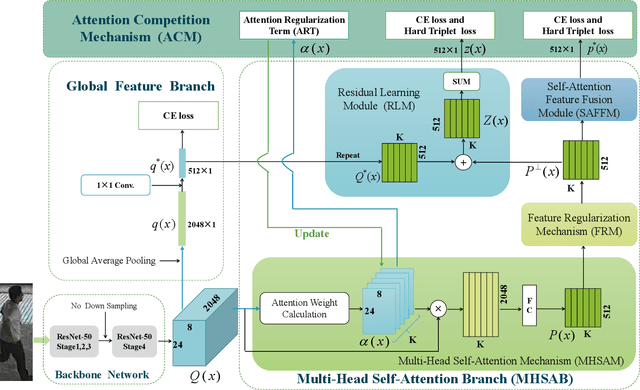
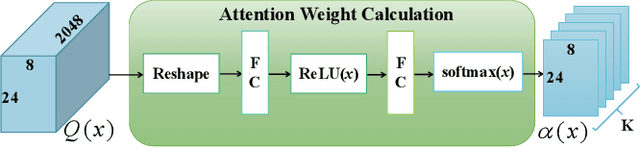
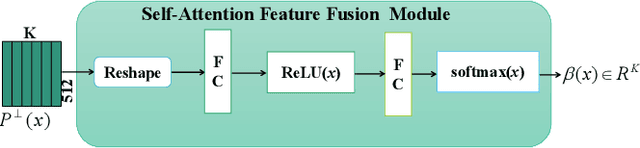
This paper presents a novel person re-identification model, named Multi-Head Self-Attention Network (MHSA-Net), to prune unimportant information and capture key local information from person images. MHSA-Net contains two main novel components: Multi-Head Self-Attention Branch (MHSAB) and Attention Competition Mechanism (ACM). The MHSAM adaptively captures key local person information, and then produces effective diversity embeddings of an image for the person matching. The ACM further helps filter out attention noise and non-key information. Through extensive ablation studies, we verified that the Structured Self-Attention Branch and Attention Competition Mechanism both contribute to the performance improvement of the MHSA-Net. Our MHSA-Net achieves state-of-the-art performance especially on images with occlusions. We have released our models (and will release the source codes after the paper is accepted) on https://github.com/hongchenphd/MHSA-Net.
Exploiting Local Geometry for Feature and Graph Construction for Better 3D Point Cloud Processing with Graph Neural Networks
Mar 28, 2021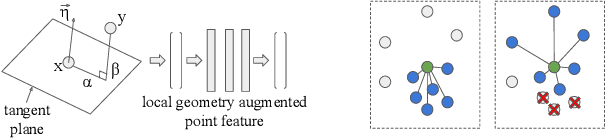
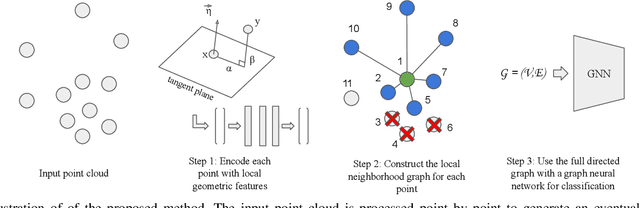
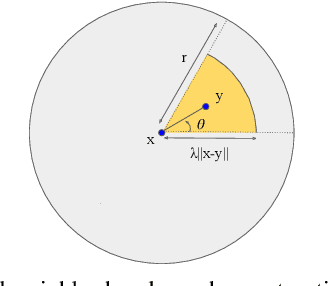
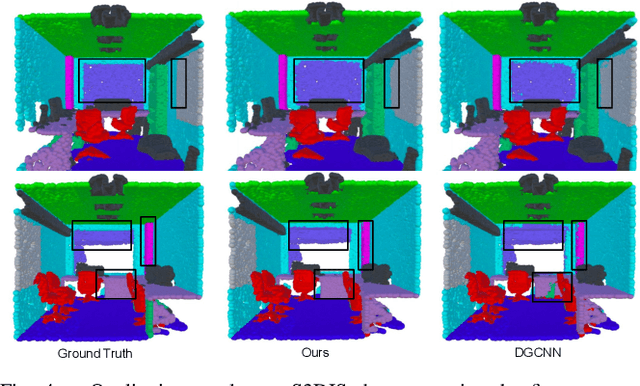
We propose simple yet effective improvements in point representations and local neighborhood graph construction within the general framework of graph neural networks (GNNs) for 3D point cloud processing. As a first contribution, we propose to augment the vertex representations with important local geometric information of the points, followed by nonlinear projection using a MLP. As a second contribution, we propose to improve the graph construction for GNNs for 3D point clouds. The existing methods work with a k-nn based approach for constructing the local neighborhood graph. We argue that it might lead to reduction in coverage in case of dense sampling by sensors in some regions of the scene. The proposed methods aims to counter such problems and improve coverage in such cases. As the traditional GNNs were designed to work with general graphs, where vertices may have no geometric interpretations, we see both our proposals as augmenting the general graphs to incorporate the geometric nature of 3D point clouds. While being simple, we demonstrate with multiple challenging benchmarks, with relatively clean CAD models, as well as with real world noisy scans, that the proposed method achieves state of the art results on benchmarks for 3D classification (ModelNet40) , part segmentation (ShapeNet) and semantic segmentation (Stanford 3D Indoor Scenes Dataset). We also show that the proposed network achieves faster training convergence, i.e. ~40% less epochs for classification. The project details are available at https://siddharthsrivastava.github.io/publication/geomgcnn/
Degrade is Upgrade: Learning Degradation for Low-light Image Enhancement
Mar 22, 2021
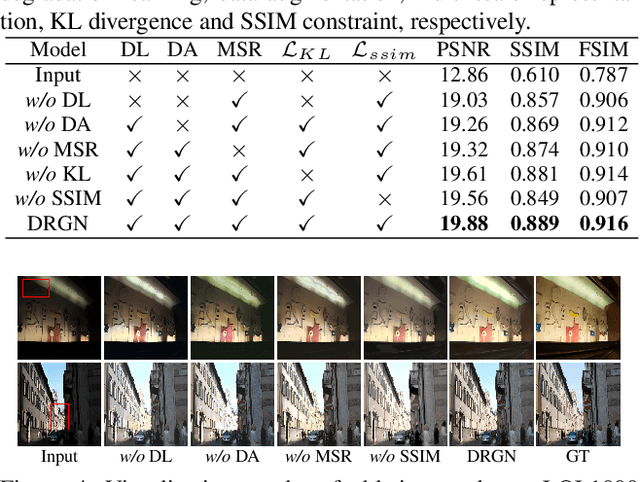
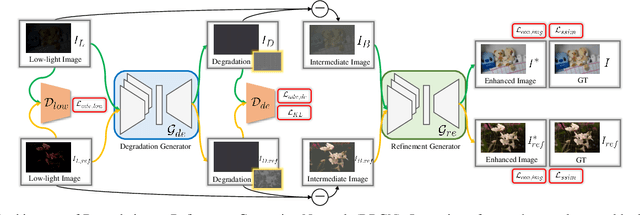
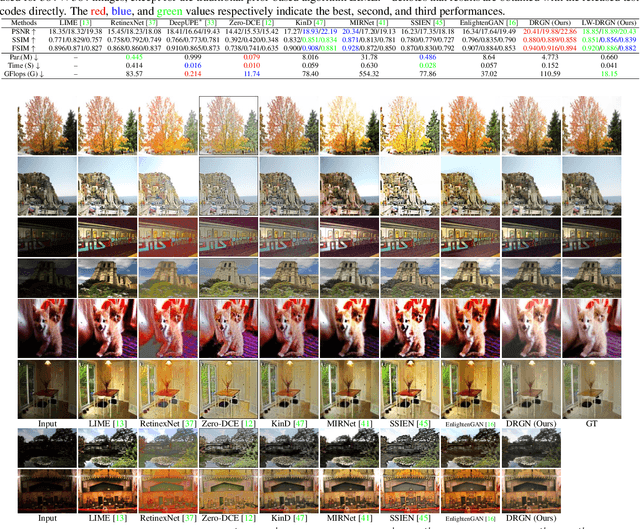
Low-light image enhancement aims to improve an image's visibility while keeping its visual naturalness. Different from existing methods, which tend to accomplish the enhancement task directly, we investigate the intrinsic degradation and relight the low-light image while refining the details and color in two steps. Inspired by the color image formulation (diffuse illumination color plus environment illumination color), we first estimate the degradation from low-light inputs to simulate the distortion of environment illumination color, and then refine the content to recover the loss of diffuse illumination color. To this end, we propose a novel Degradation-to-Refinement Generation Network (DRGN). Its distinctive features can be summarized as 1) A novel two-step generation network for degradation learning and content refinement. It is not only superior to one-step methods, but also is capable of synthesizing sufficient paired samples to benefit the model training; 2) A multi-resolution fusion network to represent the target information (degradation or contents) in a multi-scale cooperative manner, which is more effective to address the complex unmixing problems. Extensive experiments on both the enhancement task and the joint detection task have verified the effectiveness and efficiency of our proposed method, surpassing the SOTA by 0.95dB in PSNR on LOL1000 dataset and 3.18\% in mAP on ExDark dataset. Our code is available at \url{https://github.com/kuijiang0802/DRGN}