 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Dialogue Discourse-Aware Graph Convolutional Networks for Abstractive Meeting Summarization
Dec 07, 2020
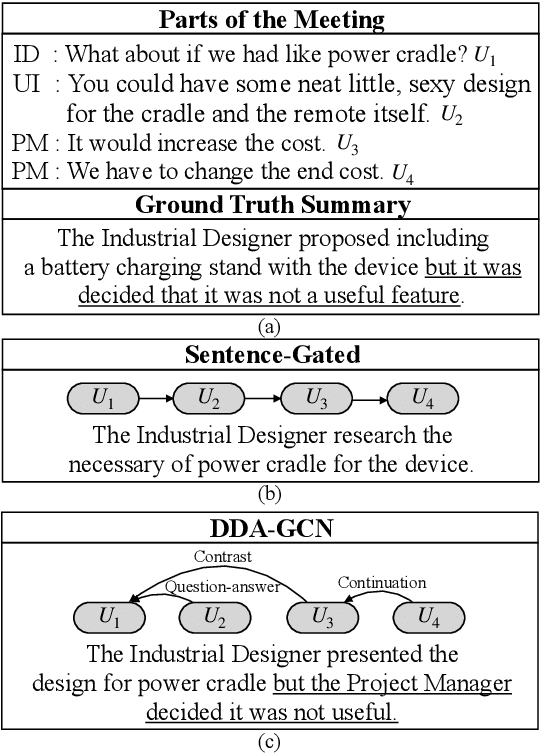
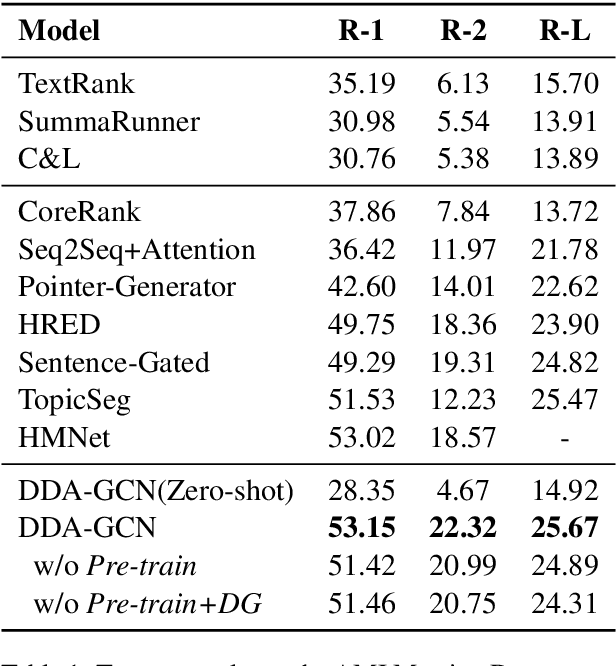
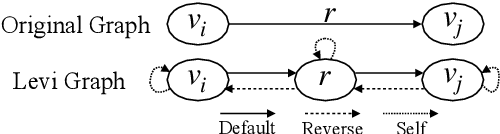
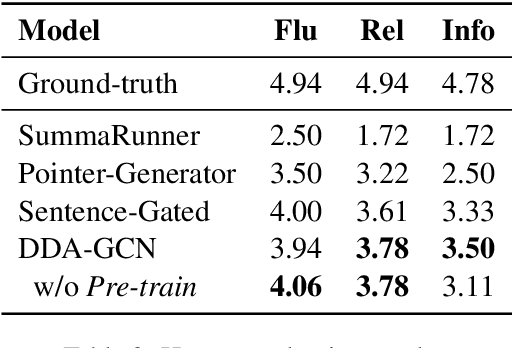
Sequence-to-sequence methods have achieved promising results for textual abstractive meeting summarization. Different from documents like news and scientific papers, a meeting is naturally full of dialogue-specific structural information. However, previous works model a meeting in a sequential manner, while ignoring the rich structural information. In this paper, we develop a Dialogue Discourse-Aware Graph Convolutional Networks (DDA-GCN) for meeting summarization by utilizing dialogue discourse, which is a dialogue-specific structure that can provide pre-defined semantic relationships between each utterance. We first transform the entire meeting text with dialogue discourse relations into a discourse graph and then use DDA-GCN to encode the semantic representation of the graph. Finally, we employ a Recurrent Neural Network to generate the summary. In addition, we utilize the question-answer discourse relation to construct a pseudo-summarization corpus, which can be used to pre-train our model. Experimental results on the AMI dataset show that our model outperforms various baselines and can achieve state-of-the-art performance.
Oracle Complexity in Nonsmooth Nonconvex Optimization
Apr 14, 2021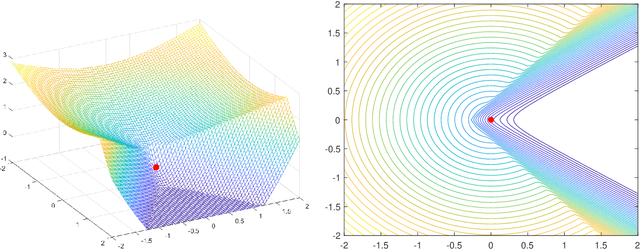
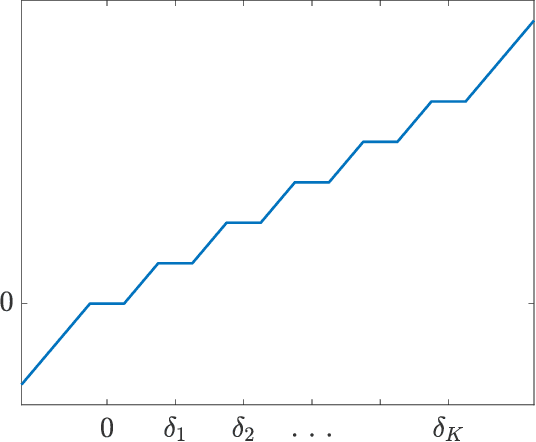
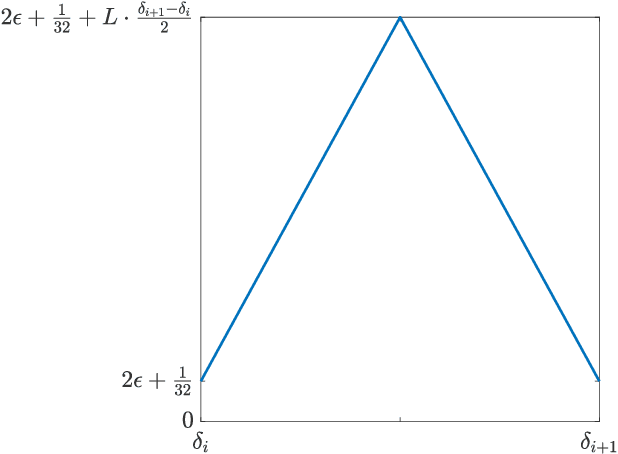
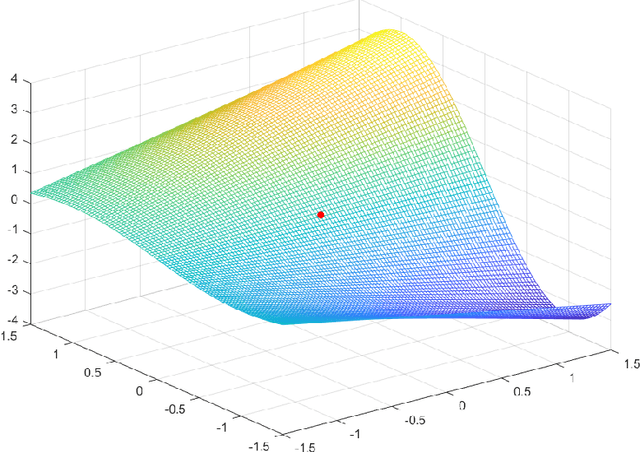
It is well-known that given a smooth, bounded-from-below, and possibly nonconvex function, standard gradient-based methods can find $\epsilon$-stationary points (with gradient norm less than $\epsilon$) in $\mathcal{O}(1/\epsilon^2)$ iterations. However, many important nonconvex optimization problems, such as those associated with training modern neural networks, are inherently not smooth, making these results inapplicable. In this paper, we study nonsmooth nonconvex optimization from an oracle complexity viewpoint, where the algorithm is assumed to be given access only to local information about the function at various points. We provide two main results (under mild assumptions): First, we consider the problem of getting near $\epsilon$-stationary points. This is perhaps the most natural relaxation of finding $\epsilon$-stationary points, which is impossible in the nonsmooth nonconvex case. We prove that this relaxed goal cannot be achieved efficiently, for any distance and $\epsilon$ smaller than some constants. Our second result deals with the possibility of tackling nonsmooth nonconvex optimization by reduction to smooth optimization: Namely, applying smooth optimization methods on a smooth approximation of the objective function. For this approach, we prove an inherent trade-off between oracle complexity and smoothness: On the one hand, smoothing a nonsmooth nonconvex function can be done very efficiently (e.g., by randomized smoothing), but with dimension-dependent factors in the smoothness parameter, which can strongly affect iteration complexity when plugging into standard smooth optimization methods. On the other hand, these dimension factors can be eliminated with suitable smoothing methods, but only by making the oracle complexity of the smoothing process exponentially large.
Structure-Aware Audio-to-Score Alignment using Progressively Dilated Convolutional Neural Networks
Jan 31, 2021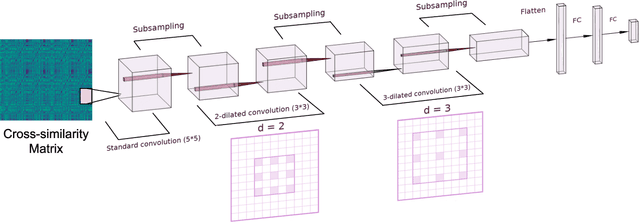
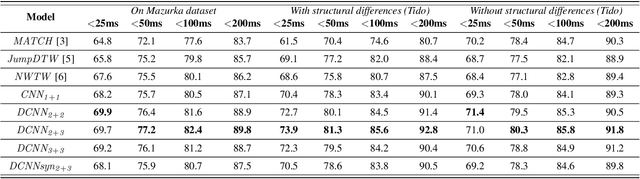
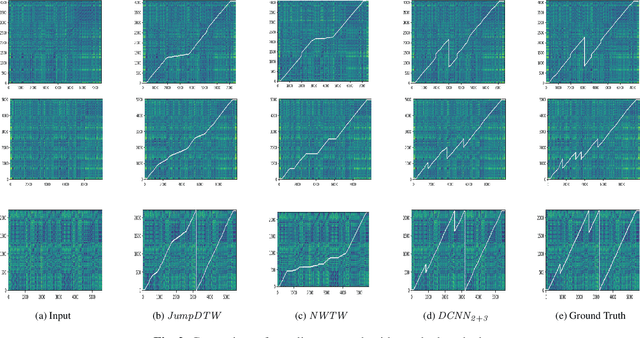
The identification of structural differences between a music performance and the score is a challenging yet integral step of audio-to-score alignment, an important subtask of music information retrieval. We present a novel method to detect such differences between the score and performance for a given piece of music using progressively dilated convolutional neural networks. Our method incorporates varying dilation rates at different layers to capture both short-term and long-term context, and can be employed successfully in the presence of limited annotated data. We conduct experiments on audio recordings of real performances that differ structurally from the score, and our results demonstrate that our models outperform standard methods for structure-aware audio-to-score alignment.
Local Algorithms for Block Models with Side Information
Aug 10, 2015
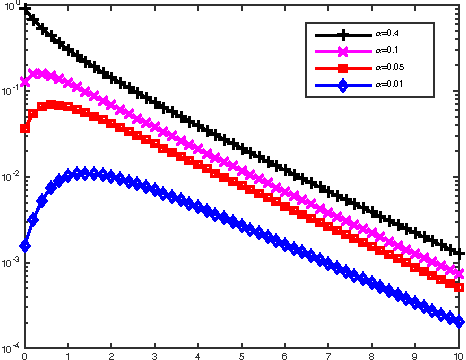
There has been a recent interest in understanding the power of local algorithms for optimization and inference problems on sparse graphs. Gamarnik and Sudan (2014) showed that local algorithms are weaker than global algorithms for finding large independent sets in sparse random regular graphs. Montanari (2015) showed that local algorithms are suboptimal for finding a community with high connectivity in the sparse Erd\H{o}s-R\'enyi random graphs. For the symmetric planted partition problem (also named community detection for the block models) on sparse graphs, a simple observation is that local algorithms cannot have non-trivial performance. In this work we consider the effect of side information on local algorithms for community detection under the binary symmetric stochastic block model. In the block model with side information each of the $n$ vertices is labeled $+$ or $-$ independently and uniformly at random; each pair of vertices is connected independently with probability $a/n$ if both of them have the same label or $b/n$ otherwise. The goal is to estimate the underlying vertex labeling given 1) the graph structure and 2) side information in the form of a vertex labeling positively correlated with the true one. Assuming that the ratio between in and out degree $a/b$ is $\Theta(1)$ and the average degree $ (a+b) / 2 = n^{o(1)}$, we characterize three different regimes under which a local algorithm, namely, belief propagation run on the local neighborhoods, maximizes the expected fraction of vertices labeled correctly. Thus, in contrast to the case of symmetric block models without side information, we show that local algorithms can achieve optimal performance for the block model with side information.
User-Oriented Smart General AI System under Causal Inference
Mar 25, 2021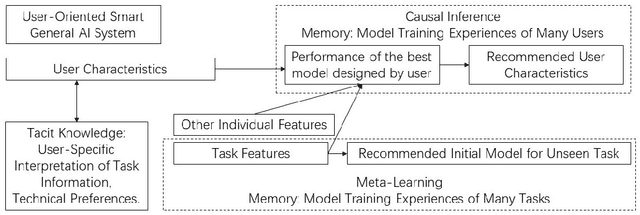
General AI system solves a wide range of tasks with high performance in an automated fashion. The best general AI algorithm designed by one individual is different from that devised by another. The best performance records achieved by different users are also different. An inevitable component of general AI is tacit knowledge that depends upon user-specific comprehension of task information and individual model design preferences that are related to user technical experiences. Tacit knowledge affects model performance but cannot be automatically optimized in general AI algorithms. In this paper, we propose User-Oriented Smart General AI System under Causal Inference, abbreviated as UOGASuCI, where UOGAS represents User-Oriented General AI System and uCI means under the framework of causal inference. User characteristics that have a significant influence upon tacit knowledge can be extracted from observed model training experiences of many users in external memory modules. Under the framework of causal inference, we manage to identify the optimal value of user characteristics that are connected with the best model performance designed by users. We make suggestions to users about how different user characteristics can improve the best model performance achieved by users. By recommending updating user characteristics associated with individualized tacit knowledge comprehension and technical preferences, UOGAS helps users design models with better performance.
Synthesis of Gaussian Trees with Correlation Sign Ambiguity: An Information Theoretic Approach
Jul 07, 2016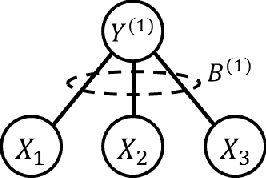
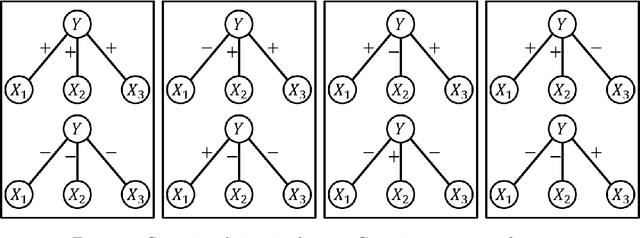
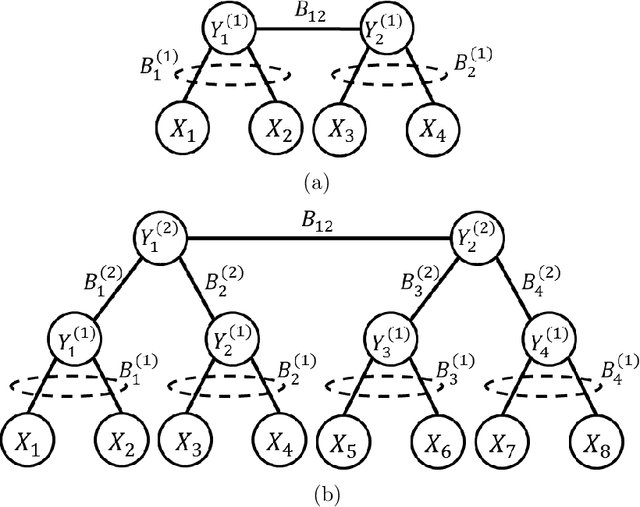
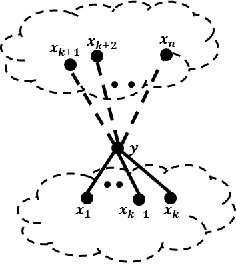
In latent Gaussian trees the pairwise correlation signs between the variables are intrinsically unrecoverable. Such information is vital since it completely determines the direction in which two variables are associated. In this work, we resort to information theoretical approaches to achieve two fundamental goals: First, we quantify the amount of information loss due to unrecoverable sign information. Second, we show the importance of such information in determining the maximum achievable rate region, in which the observed output vector can be synthesized, given its probability density function. In particular, we model the graphical model as a communication channel and propose a new layered encoding framework to synthesize observed data using upper layer Gaussian inputs and independent Bernoulli correlation sign inputs from each layer. We find the achievable rate region for the rate tuples of multi-layer latent Gaussian messages to synthesize the desired observables.
Towards Learning Controllable Representations of Physical Systems
Nov 16, 2020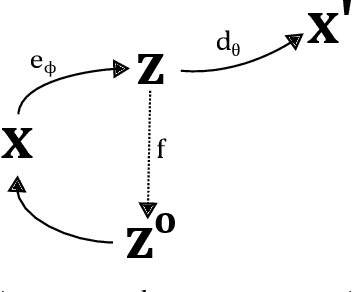
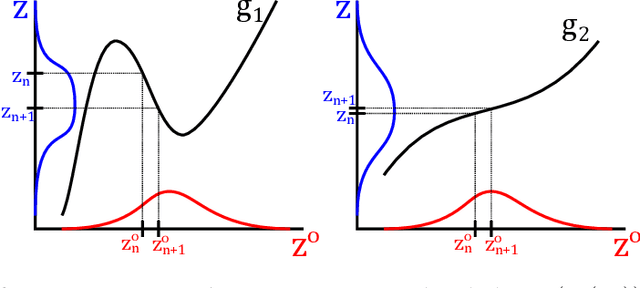
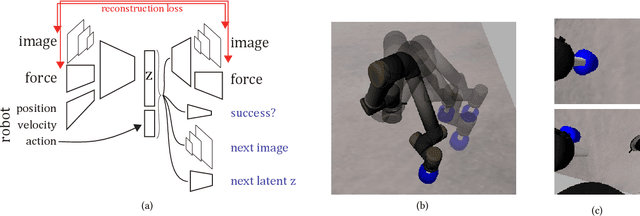
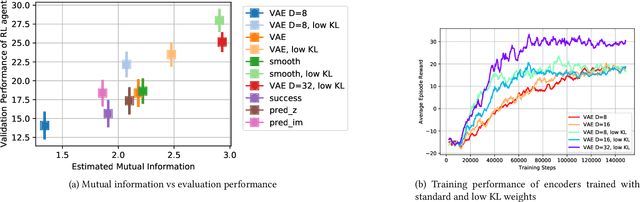
Learned representations of dynamical systems reduce dimensionality, potentially supporting downstream reinforcement learning (RL). However, no established methods predict a representation's suitability for control and evaluation is largely done via downstream RL performance, slowing representation design. Towards a principled evaluation of representations for control, we consider the relationship between the true state and the corresponding representations, proposing that ideally each representation corresponds to a unique true state. This motivates two metrics: temporal smoothness and high mutual information between true state/representation. These metrics are related to established representation objectives, and studied on Lagrangian systems where true state, information requirements, and statistical properties of the state can be formalized for a broad class of systems. These metrics are shown to predict reinforcement learning performance in a simulated peg-in-hole task when comparing variants of autoencoder-based representations.
Temporal Memory Attention for Video Semantic Segmentation
Feb 17, 2021
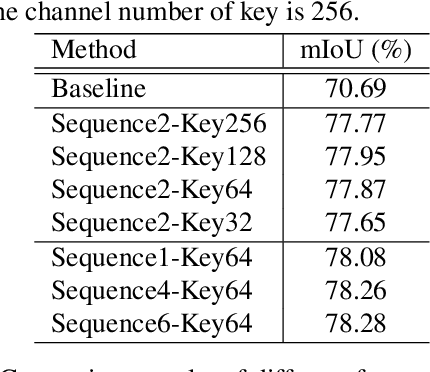
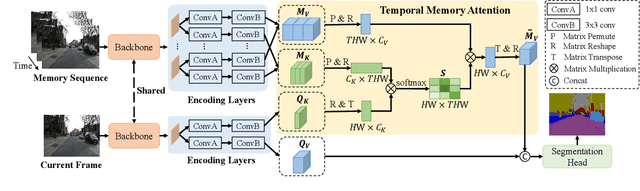

Video semantic segmentation requires to utilize the complex temporal relations between frames of the video sequence. Previous works usually exploit accurate optical flow to leverage the temporal relations, which suffer much from heavy computational cost. In this paper, we propose a Temporal Memory Attention Network (TMANet) to adaptively integrate the long-range temporal relations over the video sequence based on the self-attention mechanism without exhaustive optical flow prediction. Specially, we construct a memory using several past frames to store the temporal information of the current frame. We then propose a temporal memory attention module to capture the relation between the current frame and the memory to enhance the representation of the current frame. Our method achieves new state-of-the-art performances on two challenging video semantic segmentation datasets, particularly 80.3% mIoU on Cityscapes and 76.5% mIoU on CamVid with ResNet-50.
Towards Few-Shot Fact-Checking via Perplexity
Mar 17, 2021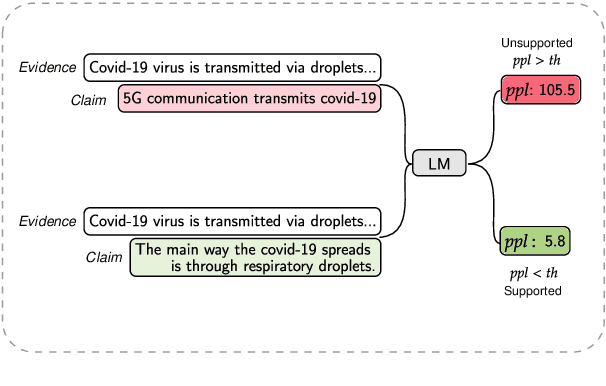

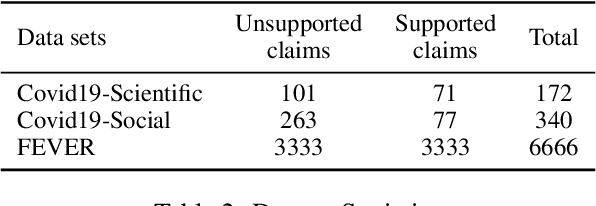
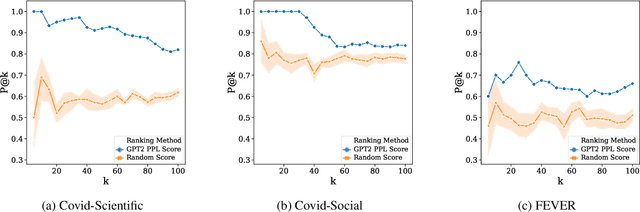
Few-shot learning has drawn researchers' attention to overcome the problem of data scarcity. Recently, large pre-trained language models have shown great performance in few-shot learning for various downstream tasks, such as question answering and machine translation. Nevertheless, little exploration has been made to achieve few-shot learning for the fact-checking task. However, fact-checking is an important problem, especially when the amount of information online is growing exponentially every day. In this paper, we propose a new way of utilizing the powerful transfer learning ability of a language model via a perplexity score. The most notable strength of our methodology lies in its capability in few-shot learning. With only two training samples, our methodology can already outperform the Major Class baseline by more than absolute 10% on the F1-Macro metric across multiple datasets. Through experiments, we empirically verify the plausibility of the rather surprising usage of the perplexity score in the context of fact-checking and highlight the strength of our few-shot methodology by comparing it to strong fine-tuning-based baseline models. Moreover, we construct and publicly release two new fact-checking datasets related to COVID-19.
Domain Controlled Title Generation with Human Evaluation
Mar 08, 2021

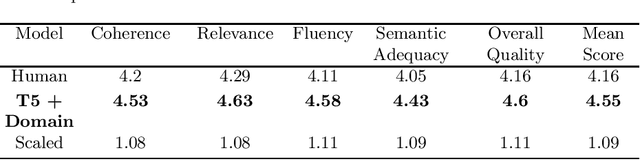
We study automatic title generation and present a method for generating domain-controlled titles for scientific articles. A good title allows you to get the attention that your research deserves. A title can be interpreted as a high-compression description of a document containing information on the implemented process. For domain-controlled titles, we used the pre-trained text-to-text transformer model and the additional token technique. Title tokens are sampled from a local distribution (which is a subset of global vocabulary) of the domain-specific vocabulary and not global vocabulary, thereby generating a catchy title and closely linking it to its corresponding abstract. Generated titles looked realistic, convincing, and very close to the ground truth. We have performed automated evaluation using ROUGE metric and human evaluation using five parameters to make a comparison between human and machine-generated titles. The titles produced were considered acceptable with higher metric ratings in contrast to the original titles. Thus we concluded that our research proposes a promising method for domain-controlled title generation.