 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
S3M: Siamese Stack (Trace) Similarity Measure
Mar 18, 2021
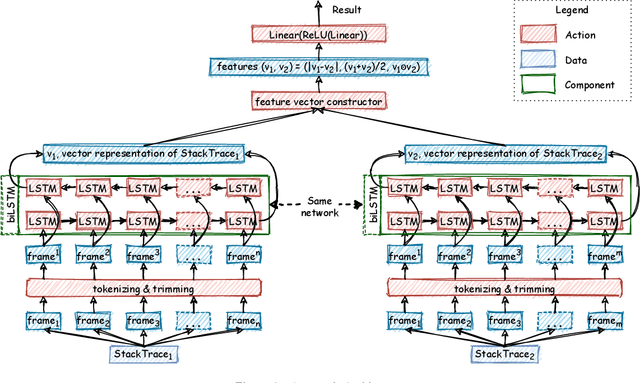
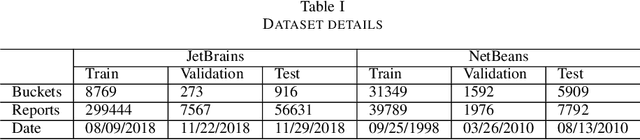
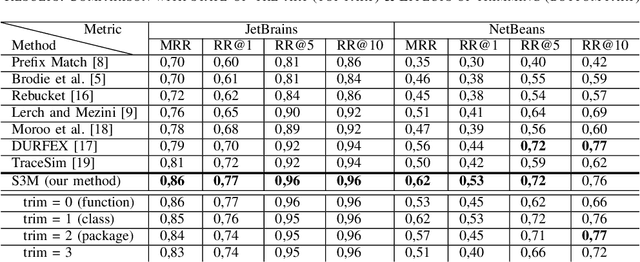
Automatic crash reporting systems have become a de-facto standard in software development. These systems monitor target software, and if a crash occurs they send details to a backend application. Later on, these reports are aggregated and used in the development process to 1) understand whether it is a new or an existing issue, 2) assign these bugs to appropriate developers, and 3) gain a general overview of the application's bug landscape. The efficiency of report aggregation and subsequent operations heavily depends on the quality of the report similarity metric. However, a distinctive feature of this kind of report is that no textual input from the user (i.e., bug description) is available: it contains only stack trace information. In this paper, we present S3M ("extreme") -- the first approach to computing stack trace similarity based on deep learning. It is based on a siamese architecture that uses a biLSTM encoder and a fully-connected classifier to compute similarity. Our experiments demonstrate the superiority of our approach over the state-of-the-art on both open-sourced data and a private JetBrains dataset. Additionally, we review the impact of stack trace trimming on the quality of the results.
Deep Models for Engagement Assessment With Scarce Label Information
Oct 21, 2016
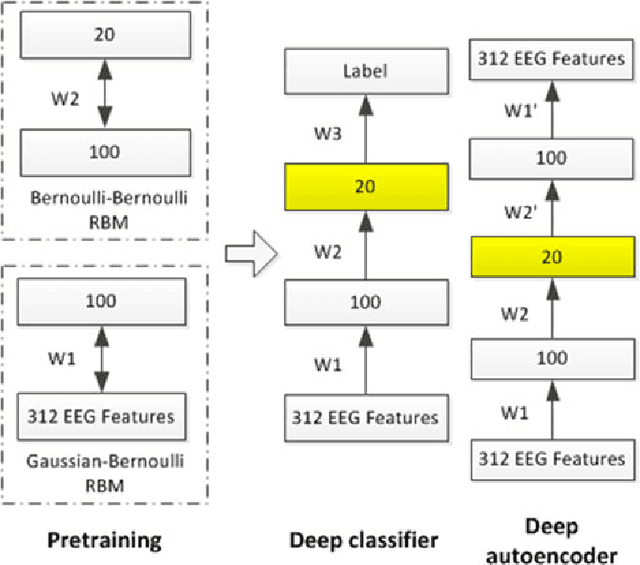
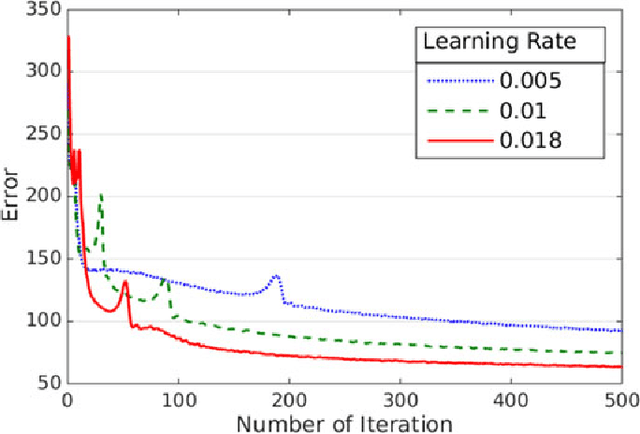
Task engagement is defined as loadings on energetic arousal (affect), task motivation, and concentration (cognition). It is usually challenging and expensive to label cognitive state data, and traditional computational models trained with limited label information for engagement assessment do not perform well because of overfitting. In this paper, we proposed two deep models (i.e., a deep classifier and a deep autoencoder) for engagement assessment with scarce label information. We recruited 15 pilots to conduct a 4-h flight simulation from Seattle to Chicago and recorded their electroencephalograph (EEG) signals during the simulation. Experts carefully examined the EEG signals and labeled 20 min of the EEG data for each pilot. The EEG signals were preprocessed and power spectral features were extracted. The deep models were pretrained by the unlabeled data and were fine-tuned by a different proportion of the labeled data (top 1%, 3%, 5%, 10%, 15%, and 20%) to learn new representations for engagement assessment. The models were then tested on the remaining labeled data. We compared performances of the new data representations with the original EEG features for engagement assessment. Experimental results show that the representations learned by the deep models yielded better accuracies for the six scenarios (77.09%, 80.45%, 83.32%, 85.74%, 85.78%, and 86.52%), based on different proportions of the labeled data for training, as compared with the corresponding accuracies (62.73%, 67.19%, 73.38%, 79.18%, 81.47%, and 84.92%) achieved by the original EEG features. Deep models are effective for engagement assessment especially when less label information was used for training.
Estimation of Fiber Orientations Using Neighborhood Information
May 16, 2016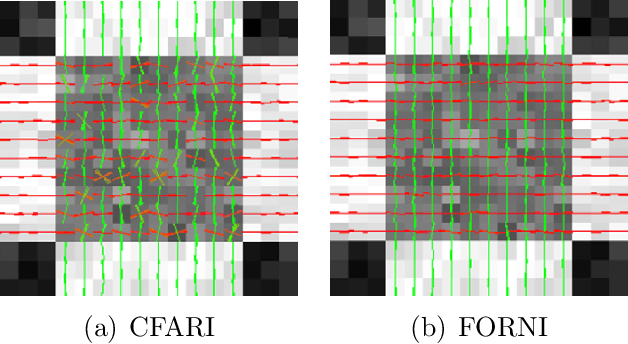

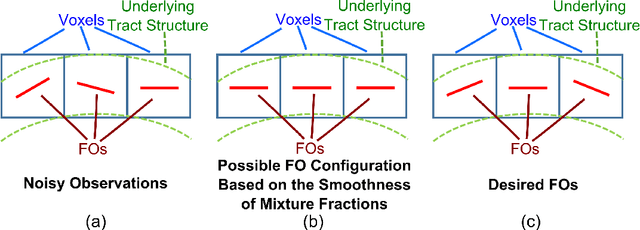

Data from diffusion magnetic resonance imaging (dMRI) can be used to reconstruct fiber tracts, for example, in muscle and white matter. Estimation of fiber orientations (FOs) is a crucial step in the reconstruction process and these estimates can be corrupted by noise. In this paper, a new method called Fiber Orientation Reconstruction using Neighborhood Information (FORNI) is described and shown to reduce the effects of noise and improve FO estimation performance by incorporating spatial consistency. FORNI uses a fixed tensor basis to model the diffusion weighted signals, which has the advantage of providing an explicit relationship between the basis vectors and the FOs. FO spatial coherence is encouraged using weighted l1-norm regularization terms, which contain the interaction of directional information between neighbor voxels. Data fidelity is encouraged using a squared error between the observed and reconstructed diffusion weighted signals. After appropriate weighting of these competing objectives, the resulting objective function is minimized using a block coordinate descent algorithm, and a straightforward parallelization strategy is used to speed up processing. Experiments were performed on a digital crossing phantom, ex vivo tongue dMRI data, and in vivo brain dMRI data for both qualitative and quantitative evaluation. The results demonstrate that FORNI improves the quality of FO estimation over other state of the art algorithms.
On the Assessment of Benchmark Suites for Algorithm Comparison
Apr 15, 2021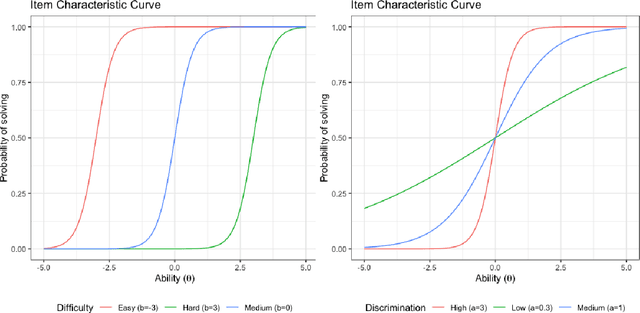
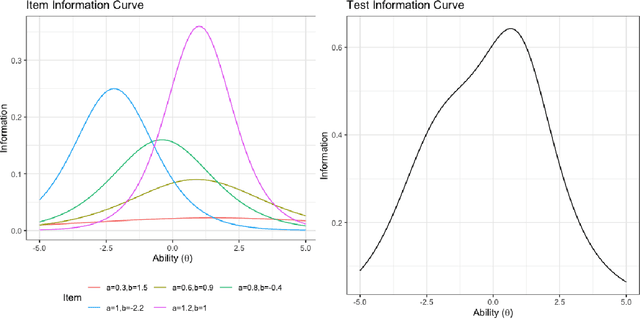
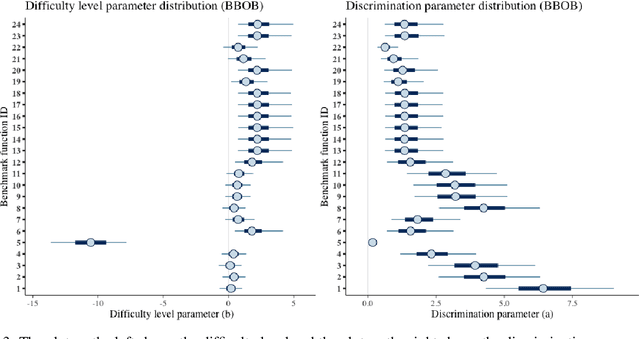
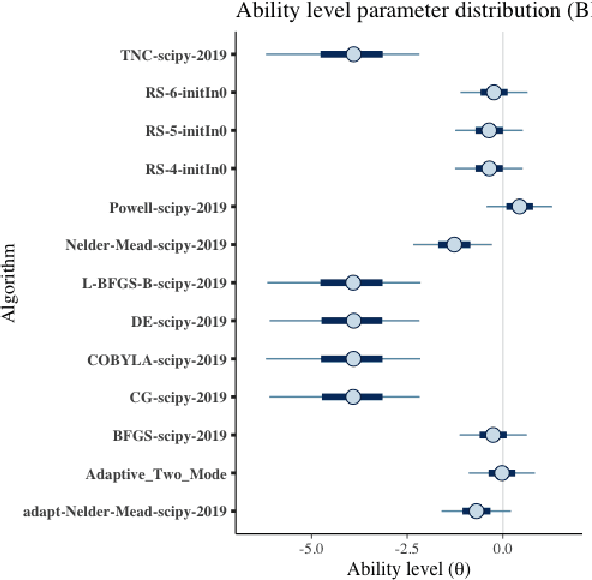
Benchmark suites, i.e. a collection of benchmark functions, are widely used in the comparison of black-box optimization algorithms. Over the years, research has identified many desired qualities for benchmark suites, such as diverse topology, different difficulties, scalability, representativeness of real-world problems among others. However, while the topology characteristics have been subjected to previous studies, there is no study that has statistically evaluated the difficulty level of benchmark functions, how well they discriminate optimization algorithms and how suitable is a benchmark suite for algorithm comparison. In this paper, we propose the use of an item response theory (IRT) model, the Bayesian two-parameter logistic model for multiple attempts, to statistically evaluate these aspects with respect to the empirical success rate of algorithms. With this model, we can assess the difficulty level of each benchmark, how well they discriminate different algorithms, the ability score of an algorithm, and how much information the benchmark suite adds in the estimation of the ability scores. We demonstrate the use of this model in two well-known benchmark suites, the Black-Box Optimization Benchmark (BBOB) for continuous optimization and the Pseudo Boolean Optimization (PBO) for discrete optimization. We found that most benchmark functions of BBOB suite have high difficulty levels (compared to the optimization algorithms) and low discrimination. For the PBO, most functions have good discrimination parameters but are often considered too easy. We discuss potential uses of IRT in benchmarking, including its use to improve the design of benchmark suites, to measure multiple aspects of the algorithms, and to design adaptive suites.
Learning-Based Vulnerability Analysis of Cyber-Physical Systems
Mar 10, 2021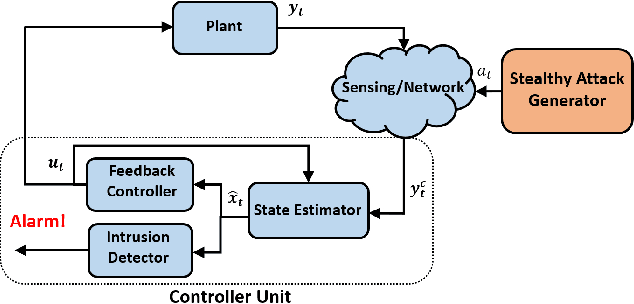

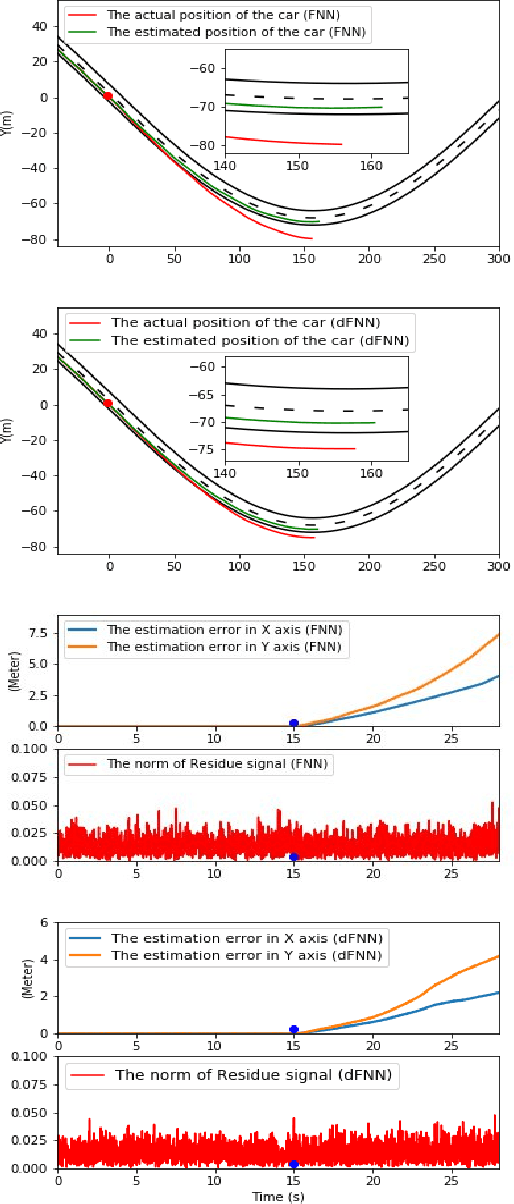
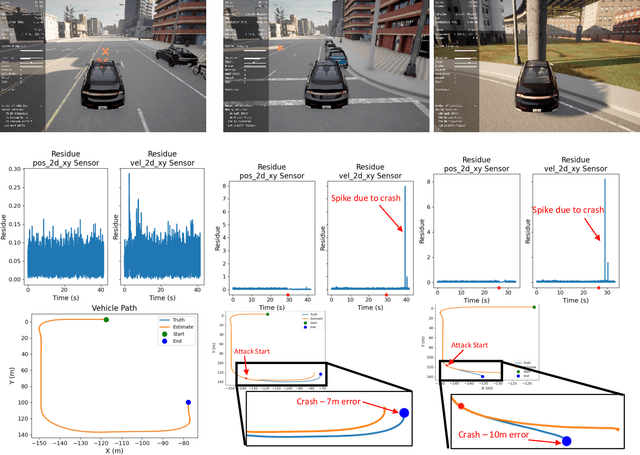
This work focuses on the use of deep learning for vulnerability analysis of cyber-physical systems (CPS). Specifically, we consider a control architecture widely used in CPS (e.g., robotics), where the low-level control is based on e.g., the extended Kalman filter (EKF) and an anomaly detector. To facilitate analyzing the impact potential sensing attacks could have, our objective is to develop learning-enabled attack generators capable of designing stealthy attacks that maximally degrade system operation. We show how such problem can be cast within a learning-based grey-box framework where parts of the runtime information are known to the attacker, and introduce two models based on feed-forward neural networks (FNN); both models are trained offline, using a cost function that combines the attack effects on the estimation error and the residual signal used for anomaly detection, so that the trained models are capable of recursively generating such effective sensor attacks in real-time. The effectiveness of the proposed methods is illustrated on several case studies.
Massively parallel hybrid search for the partial Latin square extension problem
Mar 18, 2021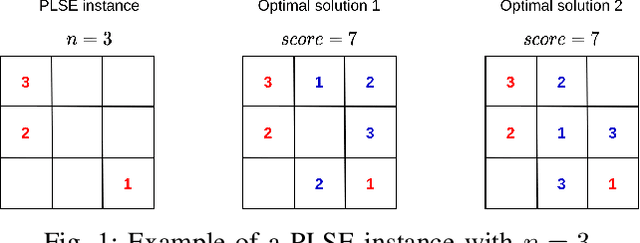
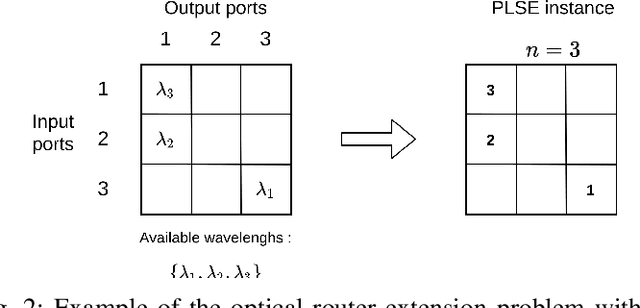
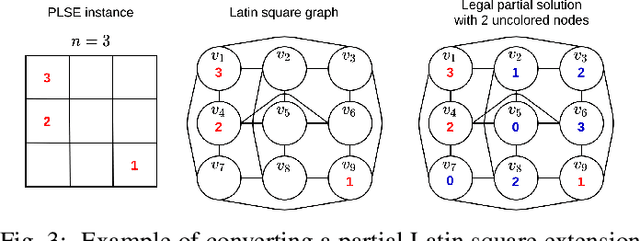
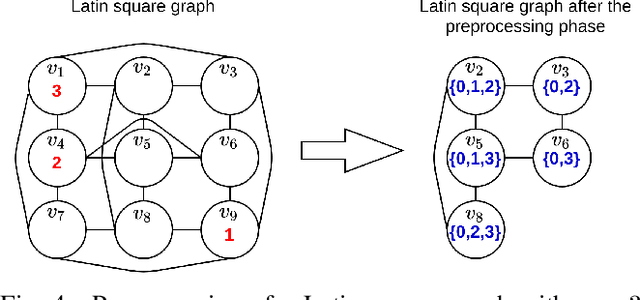
The partial Latin square extension problem is to fill as many as possible empty cells of a partially filled Latin square. This problem is a useful model for a wide range of relevant applications in diverse domains. This paper presents the first massively parallel hybrid search algorithm for this computationally challenging problem based on a transformation of the problem to partial graph coloring. The algorithm features the following original elements. Based on a very large population (with more than $10^4$ individuals) and modern graphical processing units, the algorithm performs many local searches in parallel to ensure an intensified exploitation of the search space. It employs a dedicated crossover with a specific parent matching strategy to create a large number of diversified and information-preserving offspring at each generation. Extensive experiments on 1800 benchmark instances show a high competitiveness of the algorithm compared with the current best performing methods. Competitive results are also reported on the related Latin square completion problem. Analyses are performed to shed lights on the understanding of the main algorithmic components. The code of the algorithm will be made publicly available.
Operator inference of non-Markovian terms for learning reduced models from partially observed state trajectories
Mar 26, 2021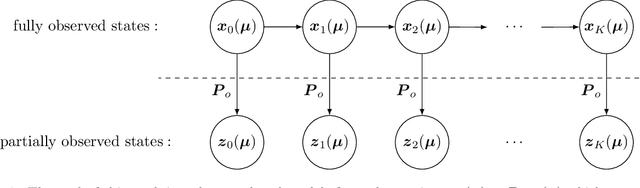
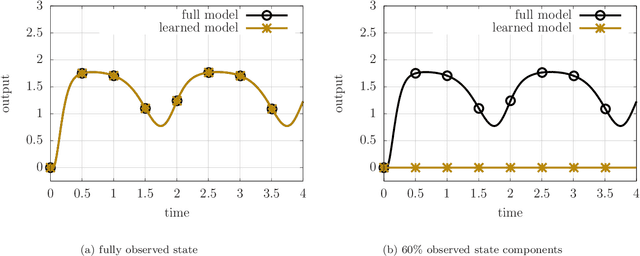
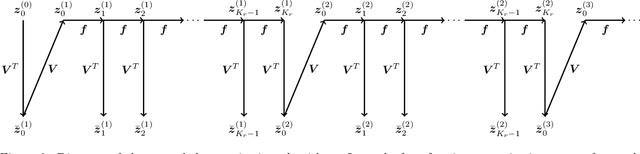
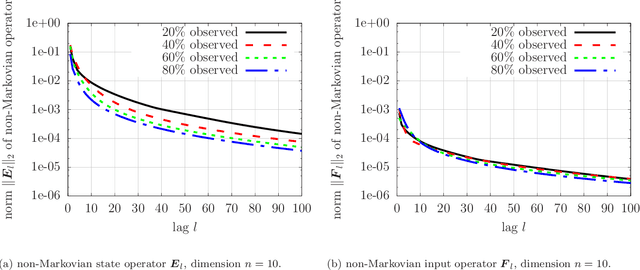
This work introduces a non-intrusive model reduction approach for learning reduced models from partially observed state trajectories of high-dimensional dynamical systems. The proposed approach compensates for the loss of information due to the partially observed states by constructing non-Markovian reduced models that make future-state predictions based on a history of reduced states, in contrast to traditional Markovian reduced models that rely on the current reduced state alone to predict the next state. The core contributions of this work are a data sampling scheme to sample partially observed states from high-dimensional dynamical systems and a formulation of a regression problem to fit the non-Markovian reduced terms to the sampled states. Under certain conditions, the proposed approach recovers from data the very same non-Markovian terms that one obtains with intrusive methods that require the governing equations and discrete operators of the high-dimensional dynamical system. Numerical results demonstrate that the proposed approach leads to non-Markovian reduced models that are predictive far beyond the training regime. Additionally, in the numerical experiments, the proposed approach learns non-Markovian reduced models from trajectories with only 20% observed state components that are about as accurate as traditional Markovian reduced models fitted to trajectories with 99% observed components.
A computationally efficient neural network for predicting weather forecast probabilities
Mar 26, 2021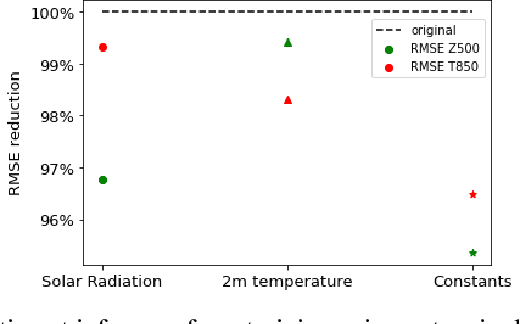
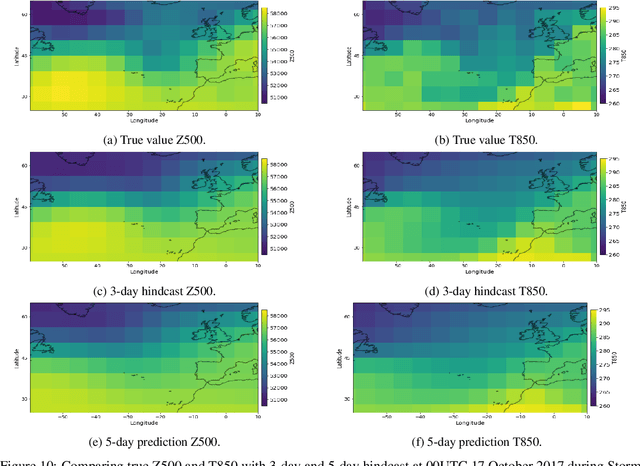
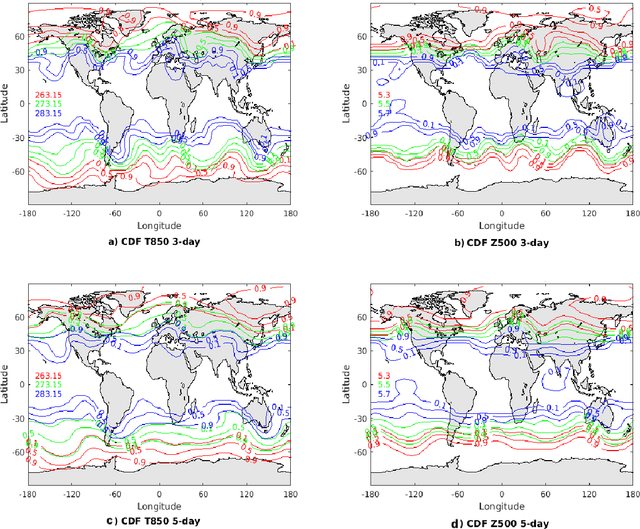
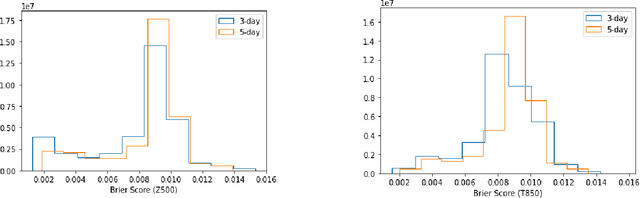
The success of deep learning techniques over the last decades has opened up a new avenue of research for weather forecasting. Here, we take the novel approach of using a neural network to predict probability density functions rather than a single output value, thus producing a probabilistic weather forecast. This enables the calculation of both uncertainty and skill metrics for the neural network predictions, and overcomes the common difficulty of inferring uncertainty from these predictions. This approach is purely data-driven and the neural network is trained on the WeatherBench dataset (processed ERA5 data) to forecast geopotential and temperature 3 and 5 days ahead. An extensive data exploration leads to the identification of the most important input variables, which are also found to agree with physical reasoning, thereby validating our approach. In order to increase computational efficiency further, each neural network is trained on a small subset of these variables. The outputs are then combined through a stacked neural network, the first time such a technique has been applied to weather data. Our approach is found to be more accurate than some numerical weather prediction models and as accurate as more complex alternative neural networks, with the added benefit of providing key probabilistic information necessary for making informed weather forecasts.
Modular Vehicle Control for Transferring Semantic Information Between Weather Conditions Using GANs
Oct 01, 2018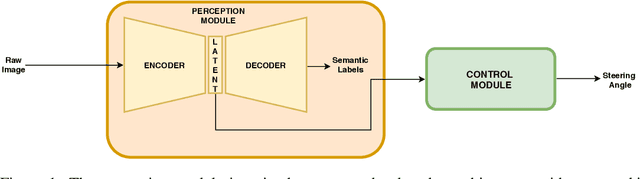

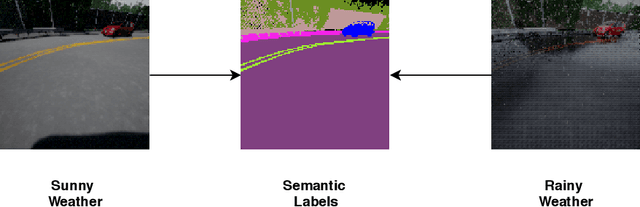
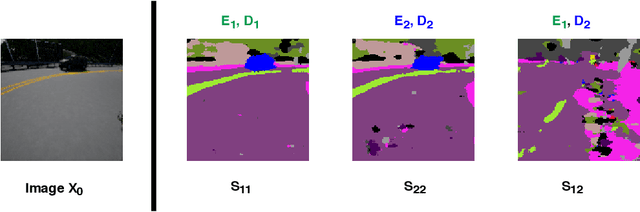
Even though end-to-end supervised learning has shown promising results for sensorimotor control of self-driving cars, its performance is greatly affected by the weather conditions under which it was trained, showing poor generalization to unseen conditions. In this paper, we show how knowledge can be transferred using semantic maps to new weather conditions without the need to obtain new ground truth data. To this end, we propose to divide the task of vehicle control into two independent modules: a control module which is only trained on one weather condition for which labeled steering data is available, and a perception module which is used as an interface between new weather conditions and the fixed control module. To generate the semantic data needed to train the perception module, we propose to use a generative adversarial network (GAN)-based model to retrieve the semantic information for the new conditions in an unsupervised manner. We introduce a master-servant architecture, where the master model (semantic labels available) trains the servant model (semantic labels not available). We show that our proposed method trained with ground truth data for a single weather condition is capable of achieving similar results on the task of steering angle prediction as an end-to-end model trained with ground truth data of 15 different weather conditions.
Context Aware 3D UNet for Brain Tumor Segmentation
Oct 25, 2020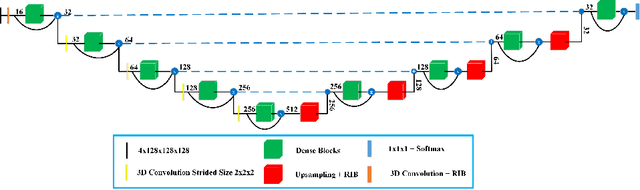
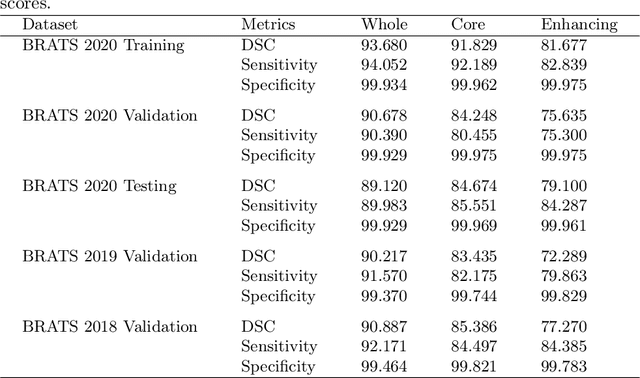
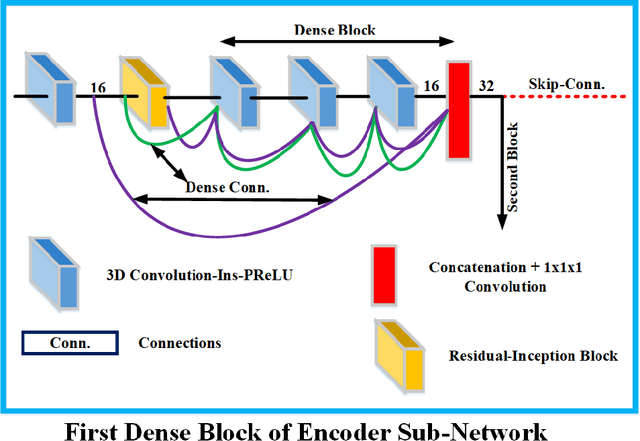

Deep convolutional neural network (CNN) achieves remarkable performance for medical image analysis. UNet is the primary source in the performance of 3D CNN architectures for medical imaging tasks, including brain tumor segmentation. The skip connection in the UNet architecture concatenates features from both encoder and decoder paths to extract multi-contexual information from image data. The multi-scaled features play an essential role in brain tumor segmentation. However, the limited use of features can degrade the performance of the UNet approach for segmentation. In this paper, we propose a modified UNet architecture for brain tumor segmentation. In the proposed architecture, we used densely connected blocks in both encoder and decoder paths to extract multi-contexual information from the concept of feature reusability. The proposed residual inception blocks (RIB) are used to extract local and global information by merging features of different kernel sizes. We validate the proposed architecture on the multimodal brain tumor segmentation challenges (BRATS) 2020 testing dataset. The dice (DSC) scores of the whole tumor (WT), tumor core (TC), and enhancement tumor (ET) are 89.12%, 84.74%, and 79.12%, respectively. Our proposed work is in the top ten methods based on the dice scores of the testing dataset.