 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CleftNet: Augmented Deep Learning for Synaptic Cleft Detection from Brain Electron Microscopy
Jan 12, 2021
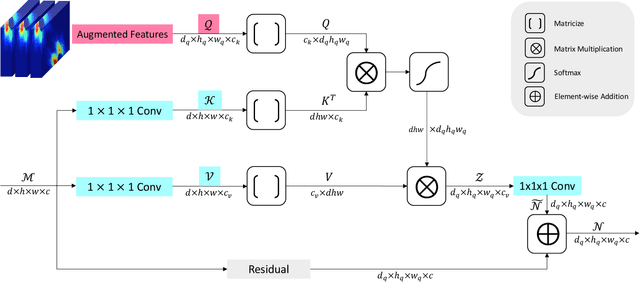
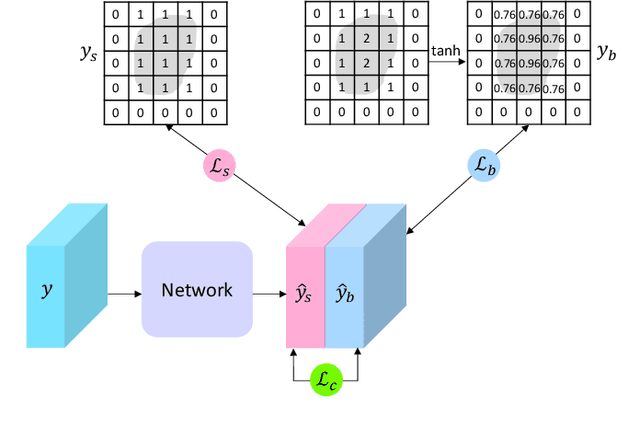
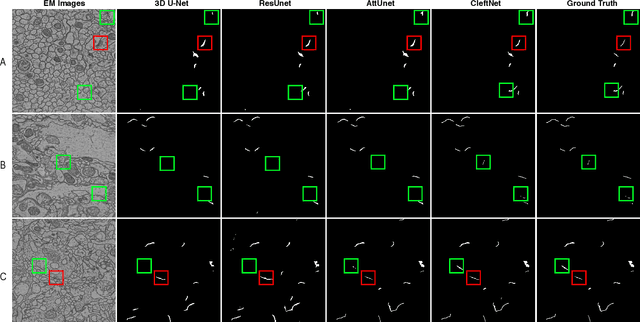

Detecting synaptic clefts is a crucial step to investigate the biological function of synapses. The volume electron microscopy (EM) allows the identification of synaptic clefts by photoing EM images with high resolution and fine details. Machine learning approaches have been employed to automatically predict synaptic clefts from EM images. In this work, we propose a novel and augmented deep learning model, known as CleftNet, for improving synaptic cleft detection from brain EM images. We first propose two novel network components, known as the feature augmentor and the label augmentor, for augmenting features and labels to improve cleft representations. The feature augmentor can fuse global information from inputs and learn common morphological patterns in clefts, leading to augmented cleft features. In addition, it can generate outputs with varying dimensions, making it flexible to be integrated in any deep network. The proposed label augmentor augments the label of each voxel from a value to a vector, which contains both the segmentation label and boundary label. This allows the network to learn important shape information and to produce more informative cleft representations. Based on the proposed feature augmentor and label augmentor, We build the CleftNet as a U-Net like network. The effectiveness of our methods is evaluated on both online and offline tasks. Our CleftNet currently ranks \#1 on the online task of the CREMI open challenge. In addition, both quantitative and qualitative results in the offline tasks show that our method outperforms the baseline approaches significantly.
Robust Reinforcement Learning for General Video Game Playing
Nov 11, 2020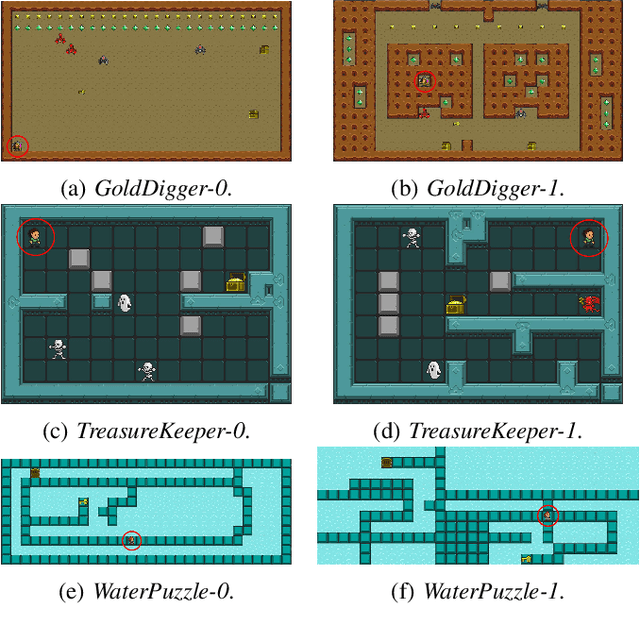
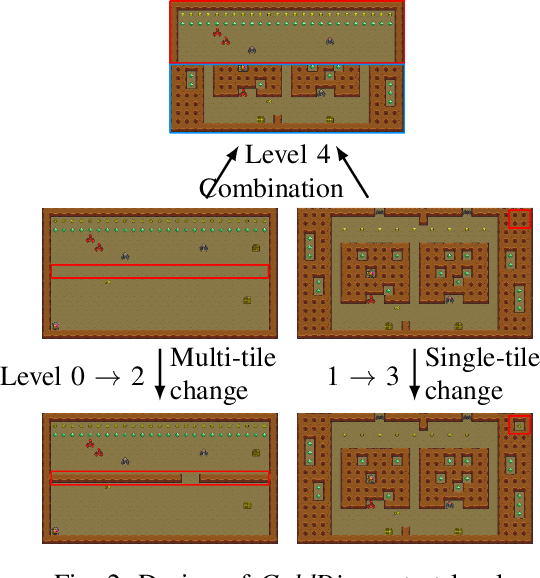
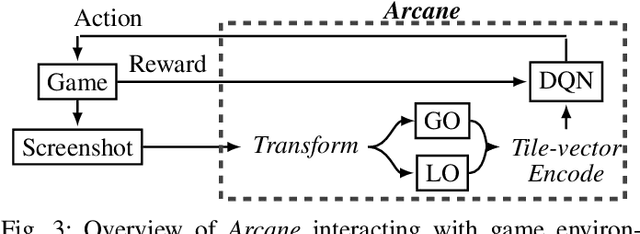
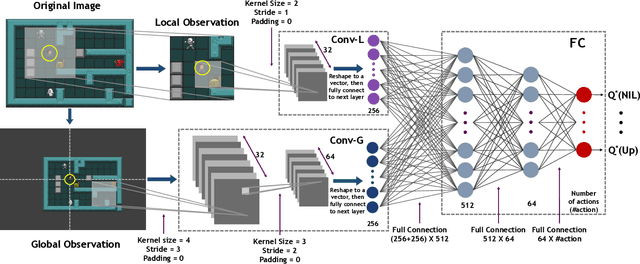
Reinforcement learning has successfully learned to play challenging board and video games. However, its generalization ability remains under-explored. The General Video Game AI Learning Competition aims at designing agents that are capable of learning to play different games levels that were unseen during training. This paper presents the games, entries and results of the 2020 General Video Game AI Learning Competition, held at the Sixteenth International Conference on Parallel Problem Solving from Nature and the 2020 IEEE Conference on Games. Three new games with sparse, periodic and dense rewards, respectively, were designed for this competition and the test levels were generated by adding minor perturbations to training levels or combining training levels. In this paper, we also design a reinforcement learning agent, called Arcane, for general video game playing. We assume that it is more likely to observe similar local information in different levels rather than global information. Therefore, instead of directly inputting a single, raw pixel-based screenshot of current game screen, Arcane takes the encoded, transformed global and local observations of the game screen as two simultaneous inputs, aiming at learning local information for playing new levels. Two versions of Arcane, using a stochastic or deterministic policy for decision-making during test, both show robust performance on the game set of the 2020 General Video Game AI Learning Competition.
Identification of Metallic Objects using Spectral MPT Signatures: Object Characterisation and Invariants
Dec 18, 2020
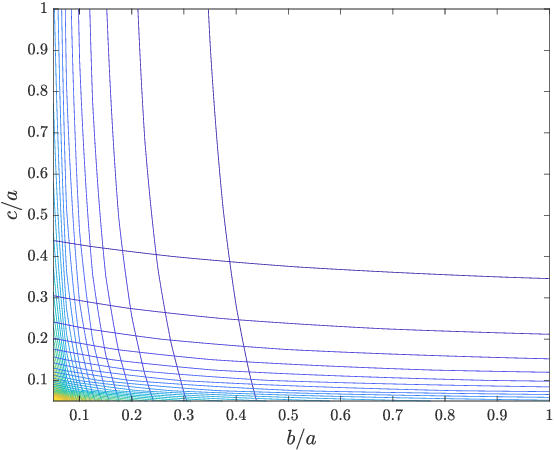
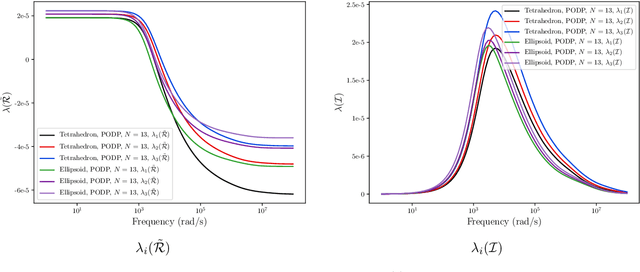
The early detection of terrorist threats, such as guns and knives, through improved metal detection, has the potential to reduce the number of attacks and improve public safety and security. To achieve this, there is considerable potential to use the fields applied and measured by a metal detector to discriminate between different shapes and different metals since, hidden within the field perturbation, is object characterisation information. The magnetic polarizability tensor (MPT) offers an economical characterisation of metallic objects that can be computed for different threat and non-threat objects and has an established theoretical background, which shows that the induced voltage is a function of the hidden object's MPT coefficients. In this paper, we describe the additional characterisation information that measurements of the induced voltage over a range of frequencies offer compared to measurements at a single frequency. We call such object characterisations its MPT spectral signature. Then, we present a series of alternative rotational invariants for the purpose of classifying hidden objects using MPT spectral signatures. Finally, we include examples of computed MPT spectral signature characterisations of realistic threat and non-threat objects that can be used to train machine learning algorithms for classification purposes.
Assessing the Severity of Health States based on Social Media Posts
Sep 21, 2020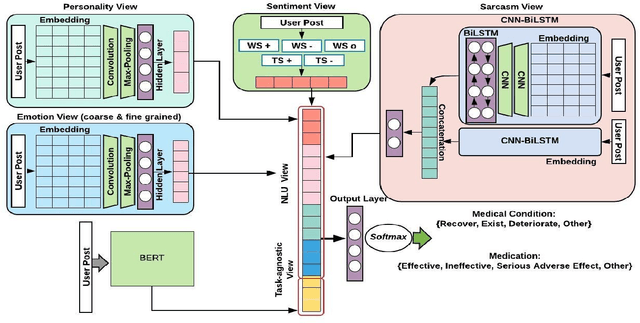
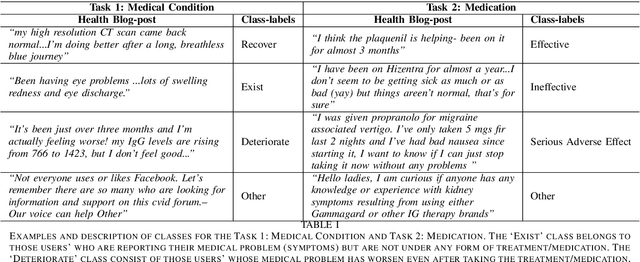


The unprecedented growth of Internet users has resulted in an abundance of unstructured information on social media including health forums, where patients request health-related information or opinions from other users. Previous studies have shown that online peer support has limited effectiveness without expert intervention. Therefore, a system capable of assessing the severity of health state from the patients' social media posts can help health professionals (HP) in prioritizing the user's post. In this study, we inspect the efficacy of different aspects of Natural Language Understanding (NLU) to identify the severity of the user's health state in relation to two perspectives(tasks) (a) Medical Condition (i.e., Recover, Exist, Deteriorate, Other) and (b) Medication (i.e., Effective, Ineffective, Serious Adverse Effect, Other) in online health communities. We propose a multiview learning framework that models both the textual content as well as contextual-information to assess the severity of the user's health state. Specifically, our model utilizes the NLU views such as sentiment, emotions, personality, and use of figurative language to extract the contextual information. The diverse NLU views demonstrate its effectiveness on both the tasks and as well as on the individual disease to assess a user's health.
Entanglement Diagnostics for Efficient Quantum Computation
Feb 24, 2021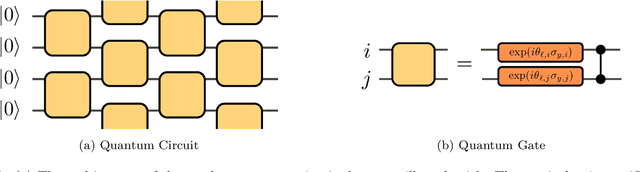
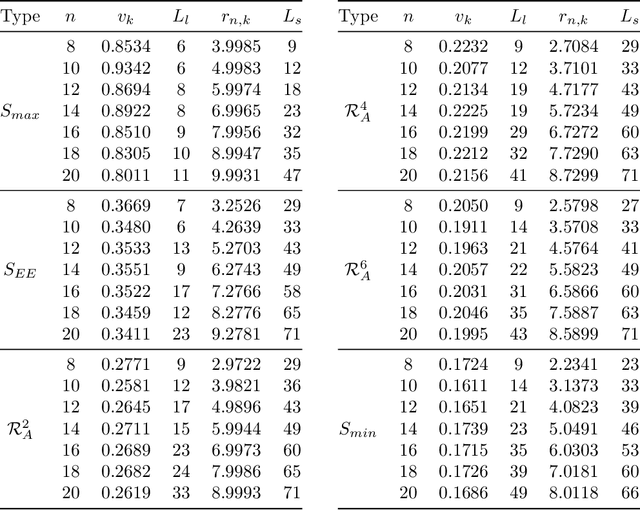
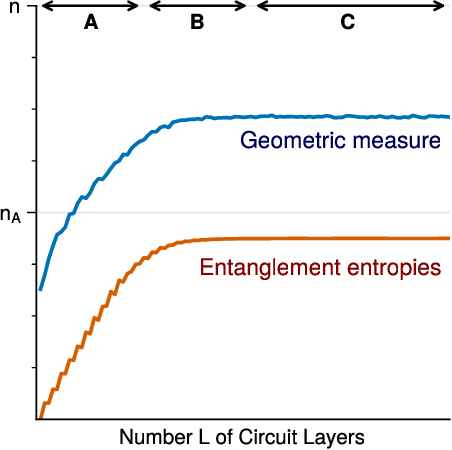
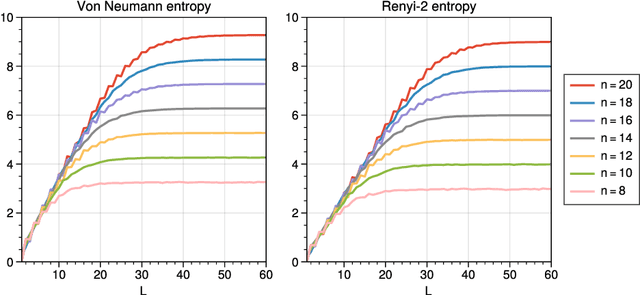
We consider information spreading measures in randomly initialized variational quantum circuits and construct entanglement diagnostics for efficient quantum/classical hybrid computations. Following the Renyi entropies of the random circuit's reduced density matrix, we divide the number of circuit layers into two separate regions with a transitioning zone between them. We identify the high-performance region for solving optimization problems encoded in the cost function of k-local Hamiltonians. We consider three example Hamiltonians, i.e., the nearest-neighbor transverse-field Ising model, the long-range transverse-field Ising model and the Sachdev-Ye-Kitaev model. By analyzing the qualitative and quantitative differences in the respective optimization processes, we demonstrate that the entanglement measures are robust diagnostics that are highly correlated with the optimization performance. We study the advantage of entanglement diagnostics for different circuit architectures and the impact of changing the parameter space dimensionality while maintaining its entanglement structure.
Motion Estimation for Optical Coherence Elastography Using Signal Phase and Intensity
Mar 19, 2021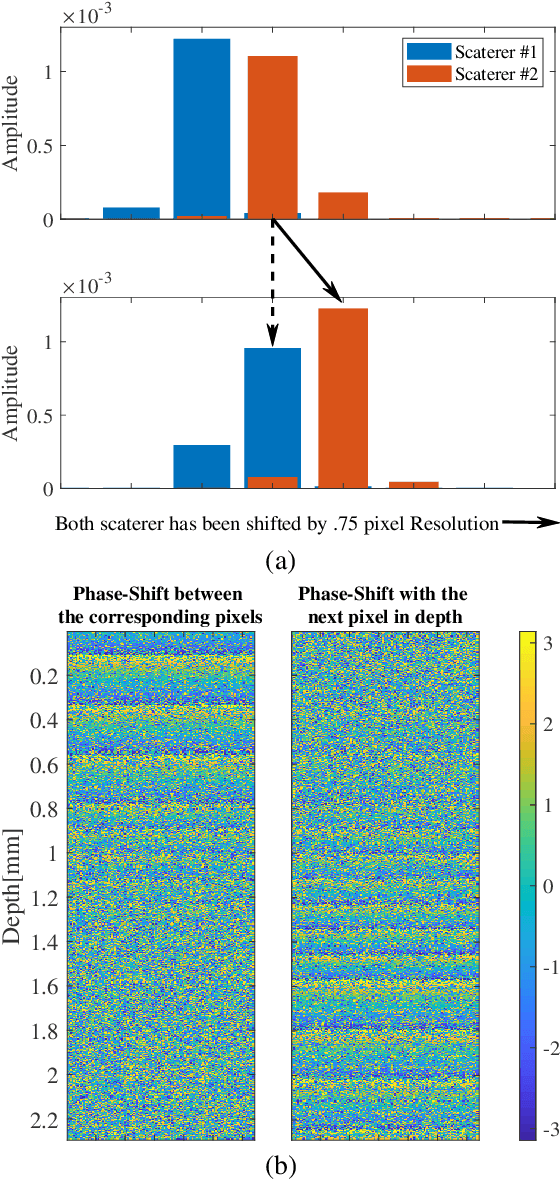
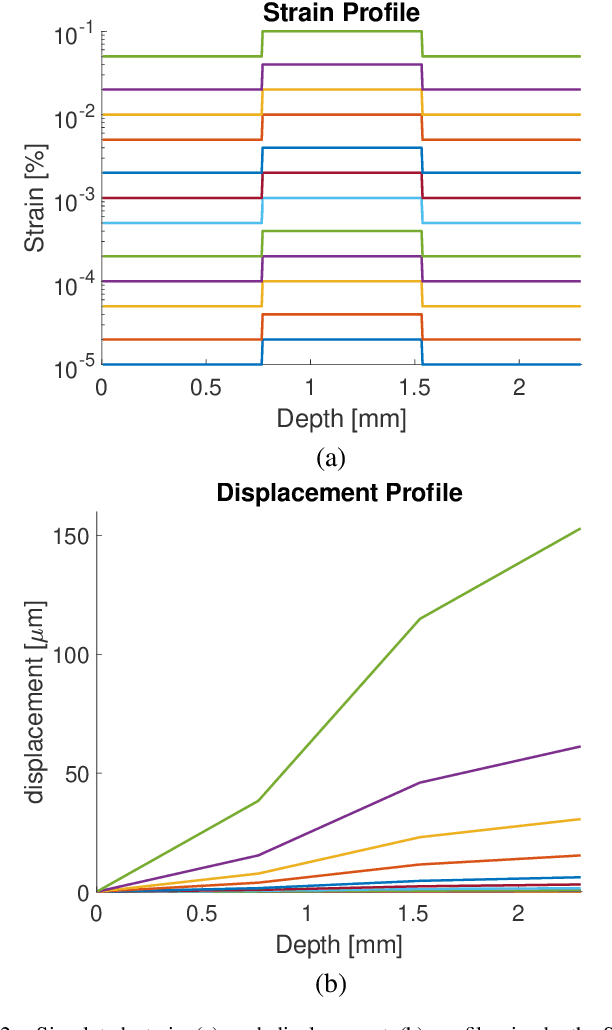
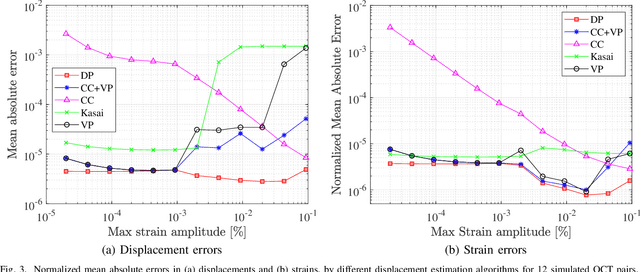

Displacement estimation in optical coherence tomography (OCT) imaging is relevant for several potential applications, e.g. for optical coherence elastography (OCE) for corneal biomechanical characterization. Larger displacements may be resolved using correlation-based block matching techniques, which however are prone to signal de-correlation and imprecise at commonly desired sub-pixel resolutions. Phase-based tracking methods can estimate tiny sub-wavelength motion, but are not suitable for motion magnitudes larger than half the wavelength due to phase wrapping and the difficulty of any unwrapping due to noise. In this paper a robust OCT displacement estimation method is introduced by formulating tracking as an optimization problem that jointly penalizes intensity disparity, phase difference, and motion discontinuity. This is then solved using yynamic programming, utilizing both sub-wavelength-scale phase and pixel-scale intensity information from OCT imaging, while inherently seeking for the number of phase wraps. This allows for effectively tracking axial and lateral displacements, respectively, with sub-wavelength and pixel scale resolution. Results with tissue mimicking phantoms show that our proposed approach substantially outperforms conventional methods in terms of axial tracking precision, in particular for displacements exceeding half the imaging wavelength.
Accelerating Text Mining Using Domain-Specific Stop Word Lists
Nov 18, 2020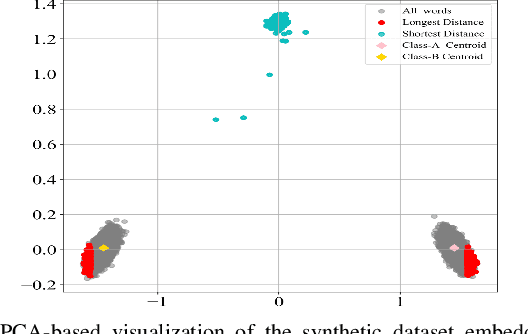
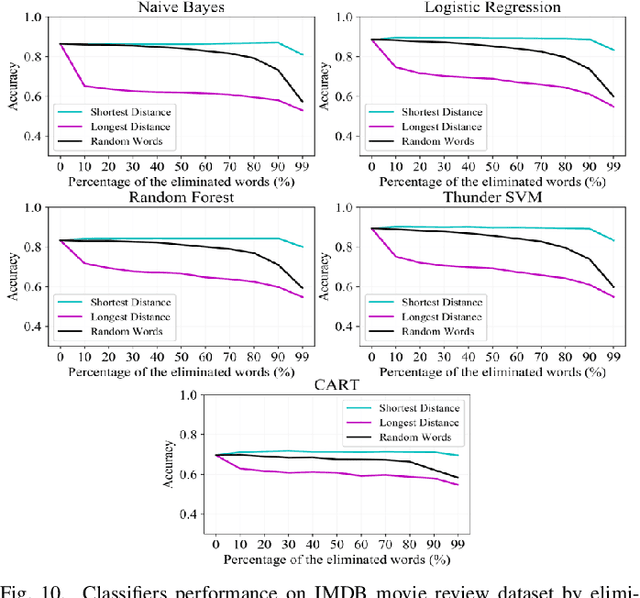
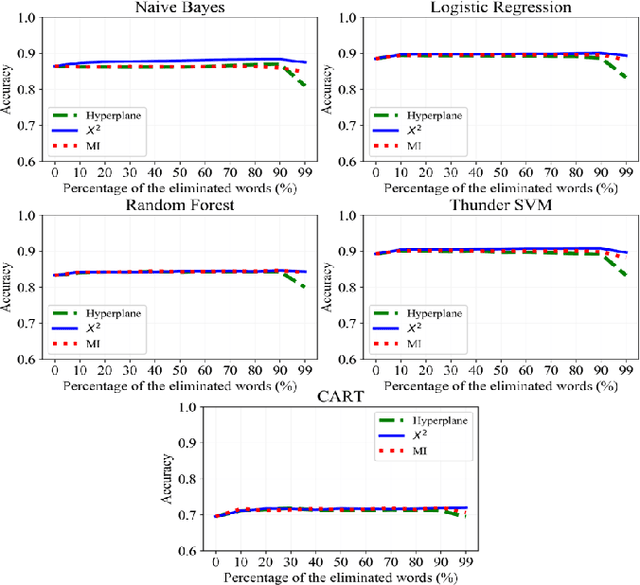
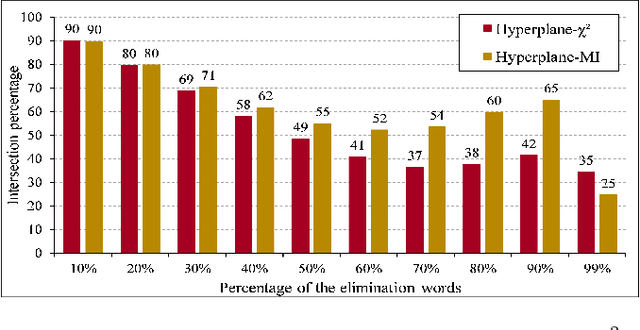
Text preprocessing is an essential step in text mining. Removing words that can negatively impact the quality of prediction algorithms or are not informative enough is a crucial storage-saving technique in text indexing and results in improved computational efficiency. Typically, a generic stop word list is applied to a dataset regardless of the domain. However, many common words are different from one domain to another but have no significance within a particular domain. Eliminating domain-specific common words in a corpus reduces the dimensionality of the feature space, and improves the performance of text mining tasks. In this paper, we present a novel mathematical approach for the automatic extraction of domain-specific words called the hyperplane-based approach. This new approach depends on the notion of low dimensional representation of the word in vector space and its distance from hyperplane. The hyperplane-based approach can significantly reduce text dimensionality by eliminating irrelevant features. We compare the hyperplane-based approach with other feature selection methods, namely \c{hi}2 and mutual information. An experimental study is performed on three different datasets and five classification algorithms, and measure the dimensionality reduction and the increase in the classification performance. Results indicate that the hyperplane-based approach can reduce the dimensionality of the corpus by 90% and outperforms mutual information. The computational time to identify the domain-specific words is significantly lower than mutual information.
Deep Models for Engagement Assessment With Scarce Label Information
Oct 21, 2016
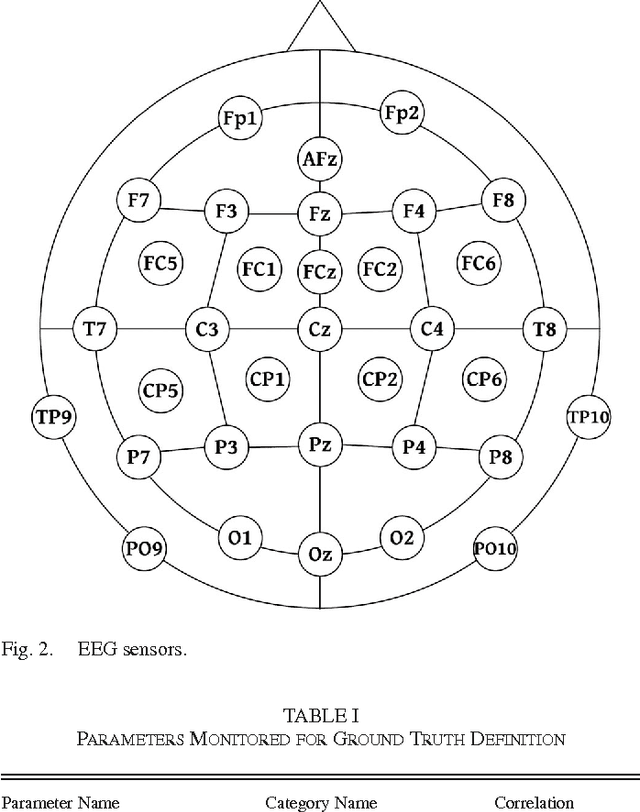
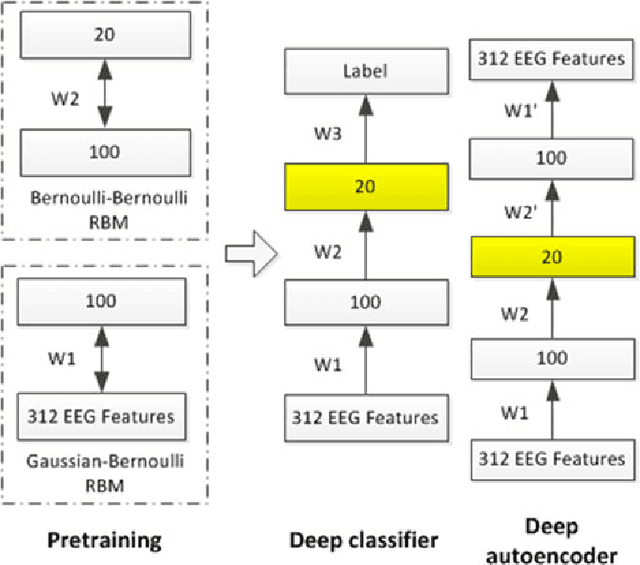
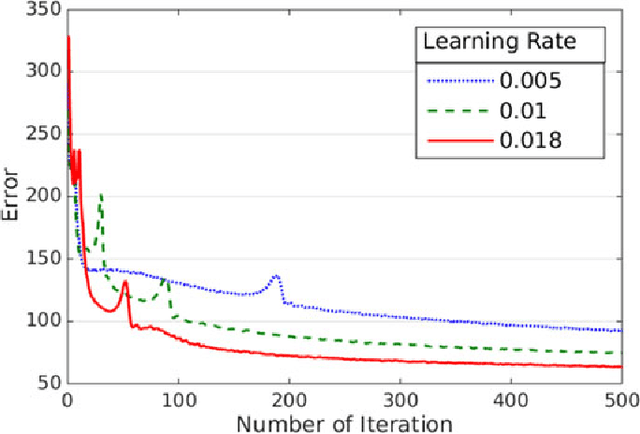
Task engagement is defined as loadings on energetic arousal (affect), task motivation, and concentration (cognition). It is usually challenging and expensive to label cognitive state data, and traditional computational models trained with limited label information for engagement assessment do not perform well because of overfitting. In this paper, we proposed two deep models (i.e., a deep classifier and a deep autoencoder) for engagement assessment with scarce label information. We recruited 15 pilots to conduct a 4-h flight simulation from Seattle to Chicago and recorded their electroencephalograph (EEG) signals during the simulation. Experts carefully examined the EEG signals and labeled 20 min of the EEG data for each pilot. The EEG signals were preprocessed and power spectral features were extracted. The deep models were pretrained by the unlabeled data and were fine-tuned by a different proportion of the labeled data (top 1%, 3%, 5%, 10%, 15%, and 20%) to learn new representations for engagement assessment. The models were then tested on the remaining labeled data. We compared performances of the new data representations with the original EEG features for engagement assessment. Experimental results show that the representations learned by the deep models yielded better accuracies for the six scenarios (77.09%, 80.45%, 83.32%, 85.74%, 85.78%, and 86.52%), based on different proportions of the labeled data for training, as compared with the corresponding accuracies (62.73%, 67.19%, 73.38%, 79.18%, 81.47%, and 84.92%) achieved by the original EEG features. Deep models are effective for engagement assessment especially when less label information was used for training.
Aspects of Terminological and Named Entity Knowledge within Rule-Based Machine Translation Models for Under-Resourced Neural Machine Translation Scenarios
Sep 28, 2020
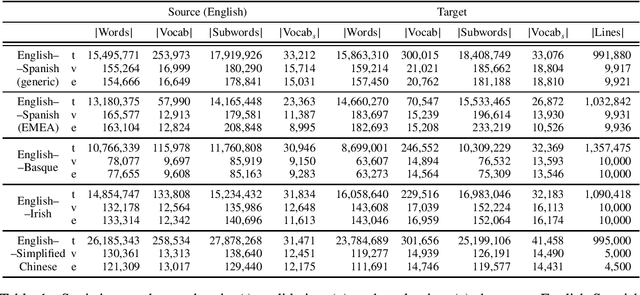
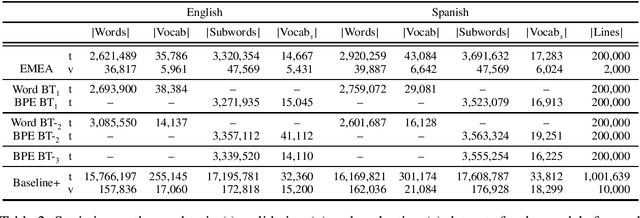

Rule-based machine translation is a machine translation paradigm where linguistic knowledge is encoded by an expert in the form of rules that translate text from source to target language. While this approach grants extensive control over the output of the system, the cost of formalising the needed linguistic knowledge is much higher than training a corpus-based system, where a machine learning approach is used to automatically learn to translate from examples. In this paper, we describe different approaches to leverage the information contained in rule-based machine translation systems to improve a corpus-based one, namely, a neural machine translation model, with a focus on a low-resource scenario. Three different kinds of information were used: morphological information, named entities and terminology. In addition to evaluating the general performance of the system, we systematically analysed the performance of the proposed approaches when dealing with the targeted phenomena. Our results suggest that the proposed models have limited ability to learn from external information, and most approaches do not significantly alter the results of the automatic evaluation, but our preliminary qualitative evaluation shows that in certain cases the hypothesis generated by our system exhibit favourable behaviour such as keeping the use of passive voice.
Estimation of Fiber Orientations Using Neighborhood Information
May 16, 2016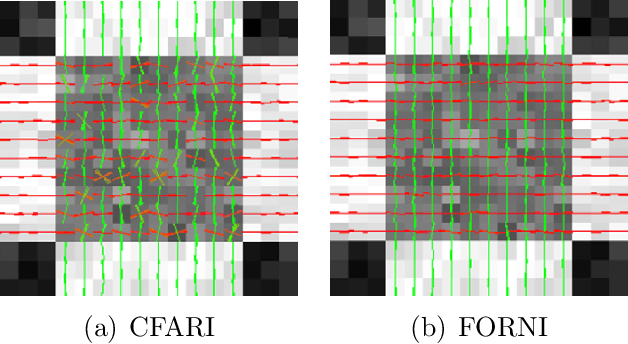

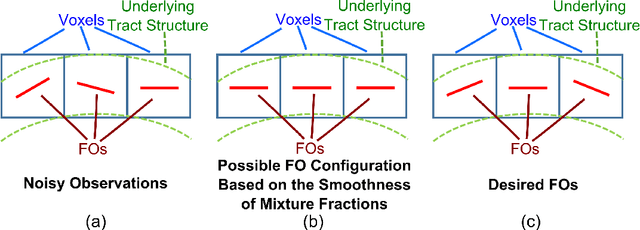

Data from diffusion magnetic resonance imaging (dMRI) can be used to reconstruct fiber tracts, for example, in muscle and white matter. Estimation of fiber orientations (FOs) is a crucial step in the reconstruction process and these estimates can be corrupted by noise. In this paper, a new method called Fiber Orientation Reconstruction using Neighborhood Information (FORNI) is described and shown to reduce the effects of noise and improve FO estimation performance by incorporating spatial consistency. FORNI uses a fixed tensor basis to model the diffusion weighted signals, which has the advantage of providing an explicit relationship between the basis vectors and the FOs. FO spatial coherence is encouraged using weighted l1-norm regularization terms, which contain the interaction of directional information between neighbor voxels. Data fidelity is encouraged using a squared error between the observed and reconstructed diffusion weighted signals. After appropriate weighting of these competing objectives, the resulting objective function is minimized using a block coordinate descent algorithm, and a straightforward parallelization strategy is used to speed up processing. Experiments were performed on a digital crossing phantom, ex vivo tongue dMRI data, and in vivo brain dMRI data for both qualitative and quantitative evaluation. The results demonstrate that FORNI improves the quality of FO estimation over other state of the art algorithms.