 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SOON: Scenario Oriented Object Navigation with Graph-based Exploration
Mar 31, 2021
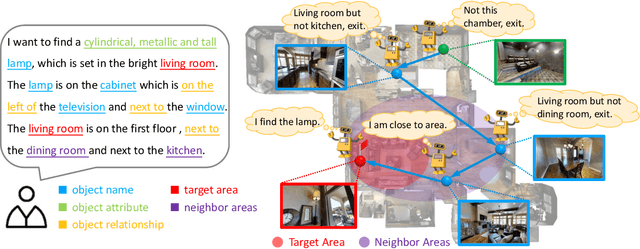
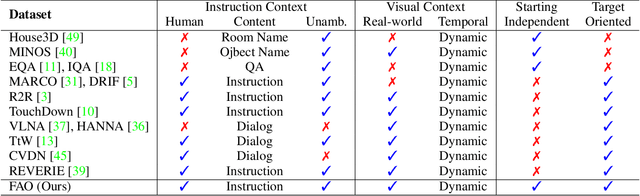
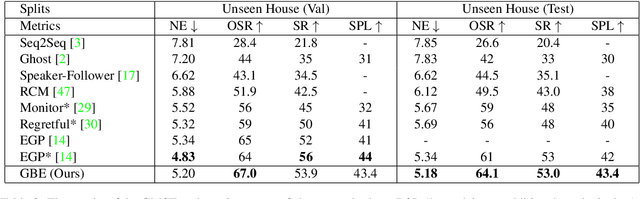
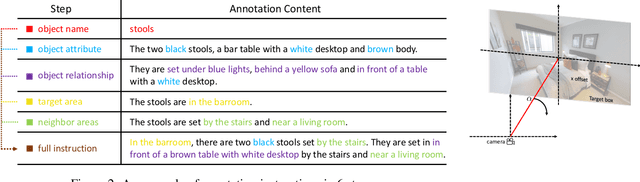
The ability to navigate like a human towards a language-guided target from anywhere in a 3D embodied environment is one of the 'holy grail' goals of intelligent robots. Most visual navigation benchmarks, however, focus on navigating toward a target from a fixed starting point, guided by an elaborate set of instructions that depicts step-by-step. This approach deviates from real-world problems in which human-only describes what the object and its surrounding look like and asks the robot to start navigation from anywhere. Accordingly, in this paper, we introduce a Scenario Oriented Object Navigation (SOON) task. In this task, an agent is required to navigate from an arbitrary position in a 3D embodied environment to localize a target following a scene description. To give a promising direction to solve this task, we propose a novel graph-based exploration (GBE) method, which models the navigation state as a graph and introduces a novel graph-based exploration approach to learn knowledge from the graph and stabilize training by learning sub-optimal trajectories. We also propose a new large-scale benchmark named From Anywhere to Object (FAO) dataset. To avoid target ambiguity, the descriptions in FAO provide rich semantic scene information includes: object attribute, object relationship, region description, and nearby region description. Our experiments reveal that the proposed GBE outperforms various state-of-the-arts on both FAO and R2R datasets. And the ablation studies on FAO validates the quality of the dataset.
P2-Net: Joint Description and Detection of Local Features for Pixel and Point Matching
Mar 01, 2021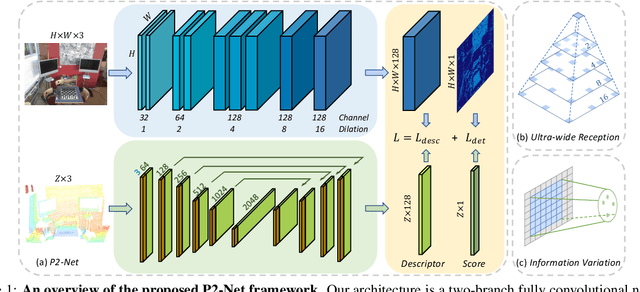
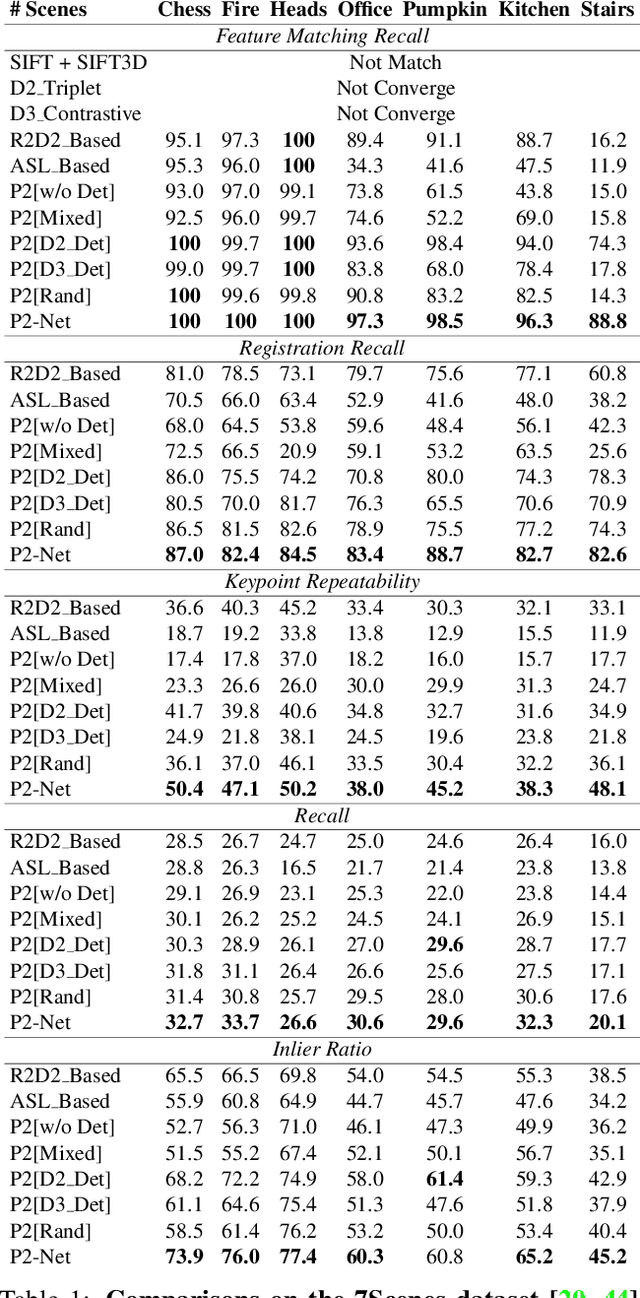
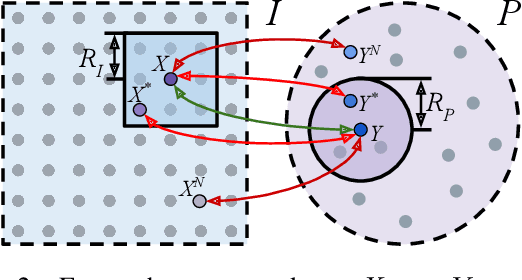
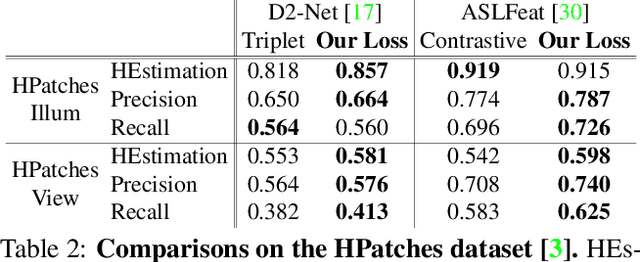
Accurately describing and detecting 2D and 3D keypoints is crucial to establishing correspondences across images and point clouds. Despite a plethora of learning-based 2D or 3D local feature descriptors and detectors having been proposed, the derivation of a shared descriptor and joint keypoint detector that directly matches pixels and points remains under-explored by the community. This work takes the initiative to establish fine-grained correspondences between 2D images and 3D point clouds. In order to directly match pixels and points, a dual fully convolutional framework is presented that maps 2D and 3D inputs into a shared latent representation space to simultaneously describe and detect keypoints. Furthermore, an ultra-wide reception mechanism in combination with a novel loss function are designed to mitigate the intrinsic information variations between pixel and point local regions. Extensive experimental results demonstrate that our framework shows competitive performance in fine-grained matching between images and point clouds and achieves state-of-the-art results for the task of indoor visual localization. Our source code will be available at [no-name-for-blind-review].
SensPick: Sense Picking for Word Sense Disambiguation
Feb 10, 2021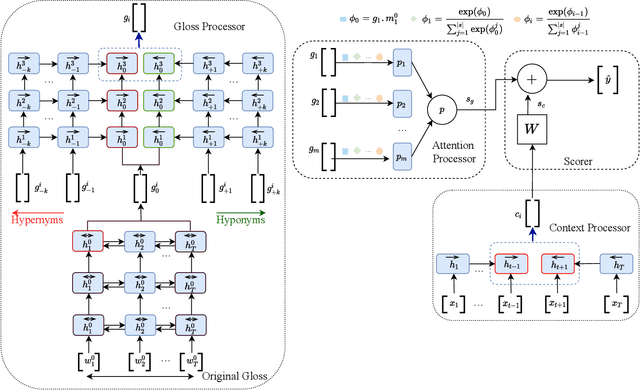
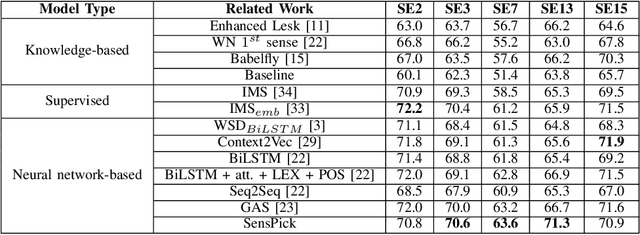
Word sense disambiguation (WSD) methods identify the most suitable meaning of a word with respect to the usage of that word in a specific context. Neural network-based WSD approaches rely on a sense-annotated corpus since they do not utilize lexical resources. In this study, we utilize both context and related gloss information of a target word to model the semantic relationship between the word and the set of glosses. We propose SensPick, a type of stacked bidirectional Long Short Term Memory (LSTM) network to perform the WSD task. The experimental evaluation demonstrates that SensPick outperforms traditional and state-of-the-art models on most of the benchmark datasets with a relative improvement of 3.5% in F-1 score. While the improvement is not significant, incorporating semantic relationships brings SensPick in the leading position compared to others.
Multi-Level Graph Convolutional Network with Automatic Graph Learning for Hyperspectral Image Classification
Sep 19, 2020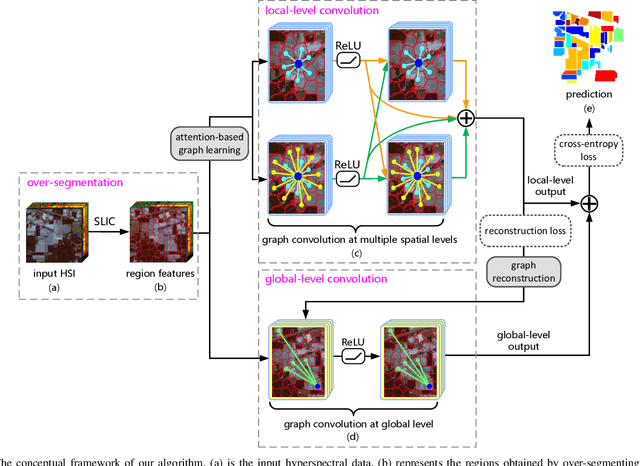
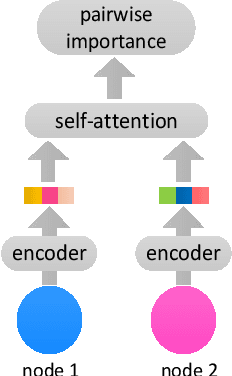
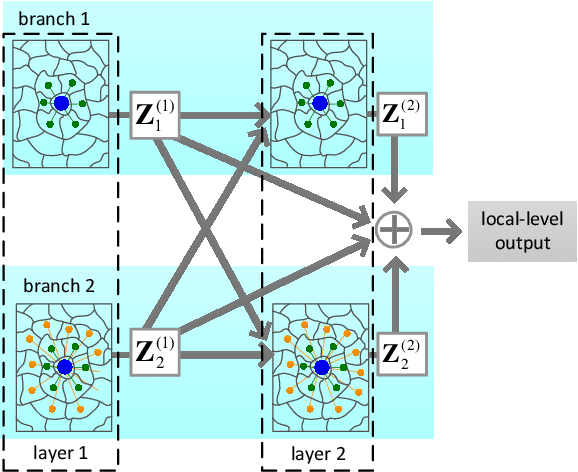
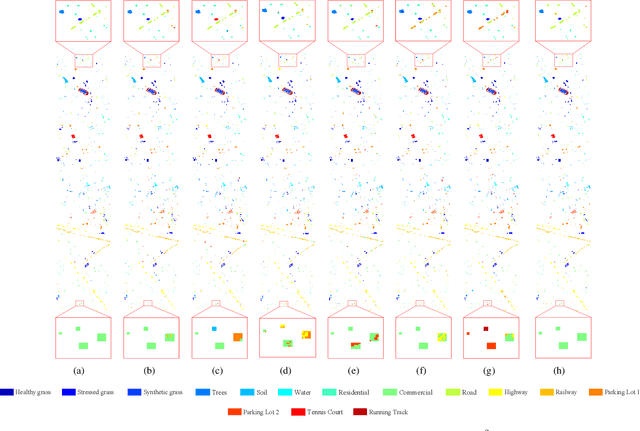
Nowadays, deep learning methods, especially the Graph Convolutional Network (GCN), have shown impressive performance in hyperspectral image (HSI) classification. However, the current GCN-based methods treat graph construction and image classification as two separate tasks, which often results in suboptimal performance. Another defect of these methods is that they mainly focus on modeling the local pairwise importance between graph nodes while lack the capability to capture the global contextual information of HSI. In this paper, we propose a Multi-level GCN with Automatic Graph Learning method (MGCN-AGL) for HSI classification, which can automatically learn the graph information at both local and global levels. By employing attention mechanism to characterize the importance among spatially neighboring regions, the most relevant information can be adaptively incorporated to make decisions, which helps encode the spatial context to form the graph information at local level. Moreover, we utilize multiple pathways for local-level graph convolution, in order to leverage the merits from the diverse spatial context of HSI and to enhance the expressive power of the generated representations. To reconstruct the global contextual relations, our MGCN-AGL encodes the long range dependencies among image regions based on the expressive representations that have been produced at local level. Then inference can be performed along the reconstructed graph edges connecting faraway regions. Finally, the multi-level information is adaptively fused to generate the network output. In this means, the graph learning and image classification can be integrated into a unified framework and benefit each other. Extensive experiments have been conducted on three real-world hyperspectral datasets, which are shown to outperform the state-of-the-art methods.
Target State Estimation and Prediction for High Speed Interception
Oct 04, 2020
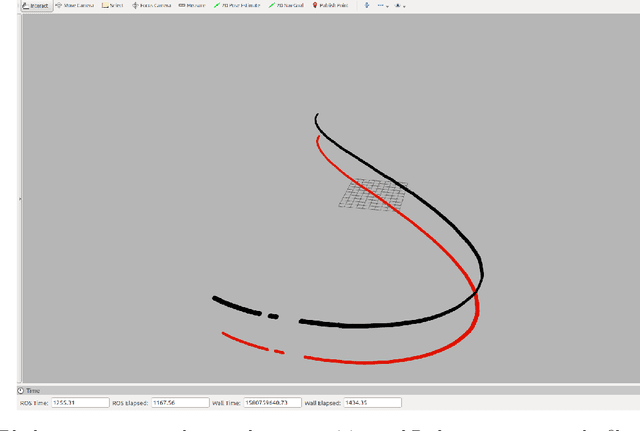
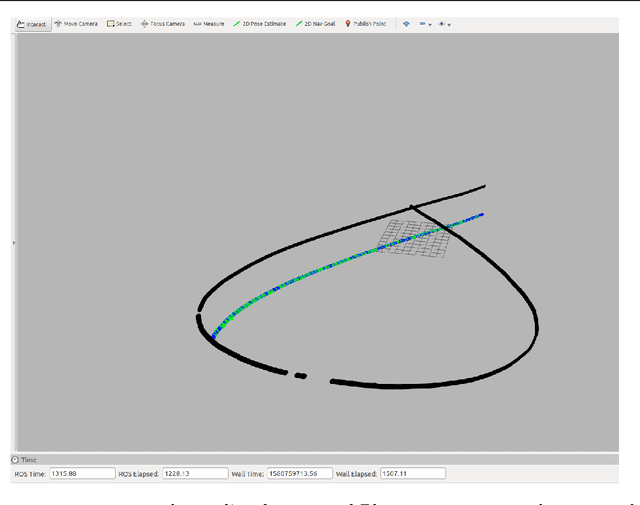
Accurate estimation and prediction of trajectory is essential for interception of any high speed target. In this paper, an extended Kalman filter is used to estimate the current location of target from its visual information and then predict its future position by using the observation sequence. Target motion model is developed considering the approximate known pattern of the target trajectory. In this work, we utilise visual information of the target to carry out the predictions. The proposed algorithm is developed in ROS-Gazebo environment and is verified using hardware implementation.
* arXiv admin note: substantial text overlap with arXiv:2009.00067
Leveraging Acoustic and Linguistic Embeddings from Pretrained speech and language Models for Intent Classification
Feb 15, 2021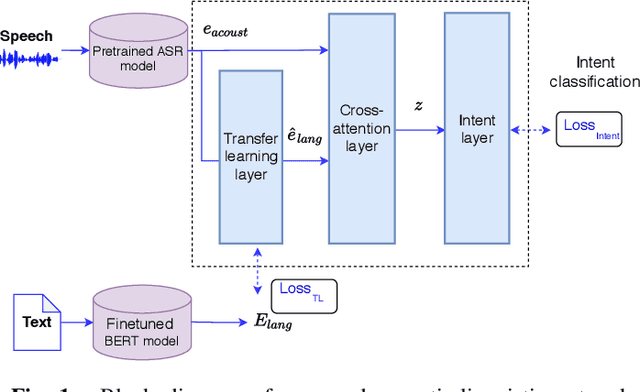
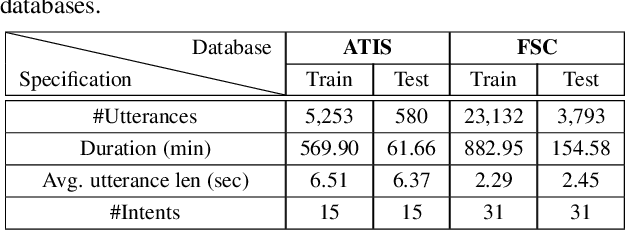
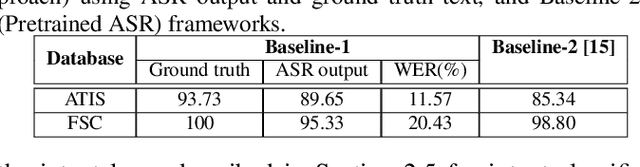
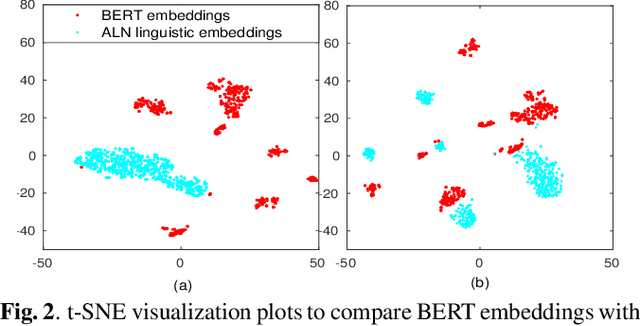
Intent classification is a task in spoken language understanding. An intent classification system is usually implemented as a pipeline process, with a speech recognition module followed by text processing that classifies the intents. There are also studies of end-to-end system that takes acoustic features as input and classifies the intents directly. Such systems don't take advantage of relevant linguistic information, and suffer from limited training data. In this work, we propose a novel intent classification framework that employs acoustic features extracted from a pretrained speech recognition system and linguistic features learned from a pretrained language model. We use knowledge distillation technique to map the acoustic embeddings towards linguistic embeddings. We perform fusion of both acoustic and linguistic embeddings through cross-attention approach to classify intents. With the proposed method, we achieve 90.86% and 99.07% accuracy on ATIS and Fluent speech corpus, respectively.
Infusing Multi-Source Knowledge with Heterogeneous Graph Neural Network for Emotional Conversation Generation
Dec 09, 2020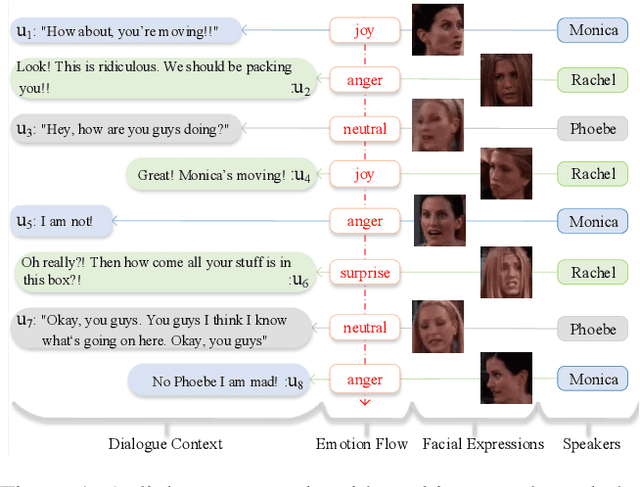
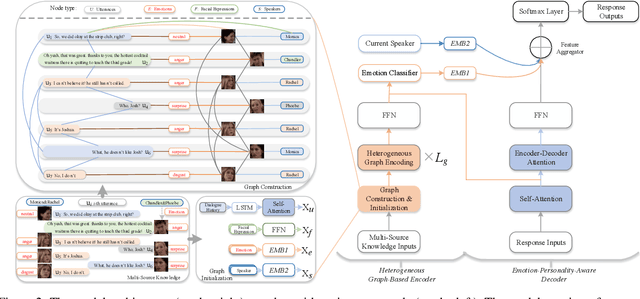
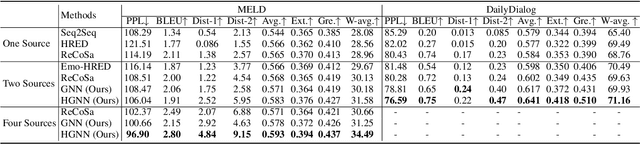
The success of emotional conversation systems depends on sufficient perception and appropriate expression of emotions. In a real-world conversation, we firstly instinctively perceive emotions from multi-source information, including the emotion flow of dialogue history, facial expressions, and personalities of speakers, and then express suitable emotions according to our personalities, but these multiple types of information are insufficiently exploited in emotional conversation fields. To address this issue, we propose a heterogeneous graph-based model for emotional conversation generation. Specifically, we design a Heterogeneous Graph-Based Encoder to represent the conversation content (i.e., the dialogue history, its emotion flow, facial expressions, and speakers' personalities) with a heterogeneous graph neural network, and then predict suitable emotions for feedback. After that, we employ an Emotion-Personality-Aware Decoder to generate a response not only relevant to the conversation context but also with appropriate emotions, by taking the encoded graph representations, the predicted emotions from the encoder and the personality of the current speaker as inputs. Experimental results show that our model can effectively perceive emotions from multi-source knowledge and generate a satisfactory response, which significantly outperforms previous state-of-the-art models.
Robust Classification from Noisy Labels: Integrating Additional Knowledge for Chest Radiography Abnormality Assessment
Apr 12, 2021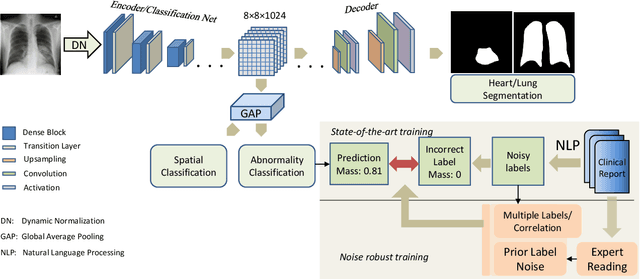
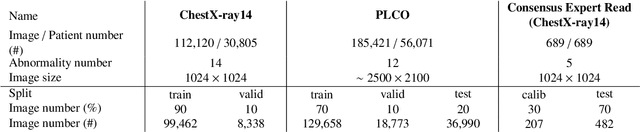
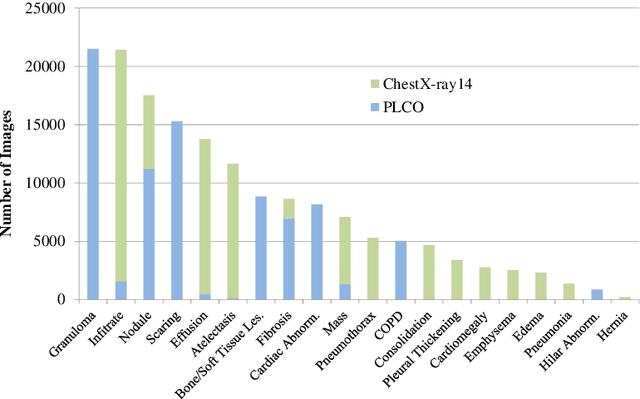
Chest radiography is the most common radiographic examination performed in daily clinical practice for the detection of various heart and lung abnormalities. The large amount of data to be read and reported, with more than 100 studies per day for a single radiologist, poses a challenge in consistently maintaining high interpretation accuracy. The introduction of large-scale public datasets has led to a series of novel systems for automated abnormality classification. However, the labels of these datasets were obtained using natural language processed medical reports, yielding a large degree of label noise that can impact the performance. In this study, we propose novel training strategies that handle label noise from such suboptimal data. Prior label probabilities were measured on a subset of training data re-read by 4 board-certified radiologists and were used during training to increase the robustness of the training model to the label noise. Furthermore, we exploit the high comorbidity of abnormalities observed in chest radiography and incorporate this information to further reduce the impact of label noise. Additionally, anatomical knowledge is incorporated by training the system to predict lung and heart segmentation, as well as spatial knowledge labels. To deal with multiple datasets and images derived from various scanners that apply different post-processing techniques, we introduce a novel image normalization strategy. Experiments were performed on an extensive collection of 297,541 chest radiographs from 86,876 patients, leading to a state-of-the-art performance level for 17 abnormalities from 2 datasets. With an average AUC score of 0.880 across all abnormalities, our proposed training strategies can be used to significantly improve performance scores.
Dual ResGCN for Balanced Scene GraphGeneration
Nov 09, 2020
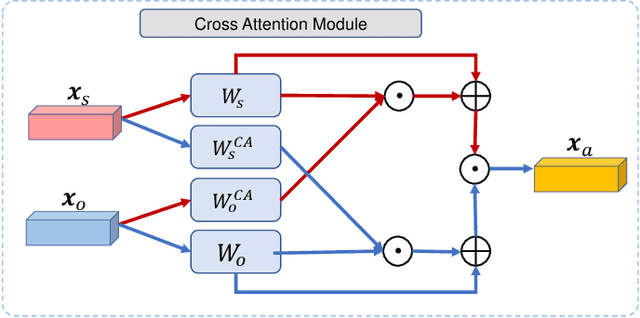
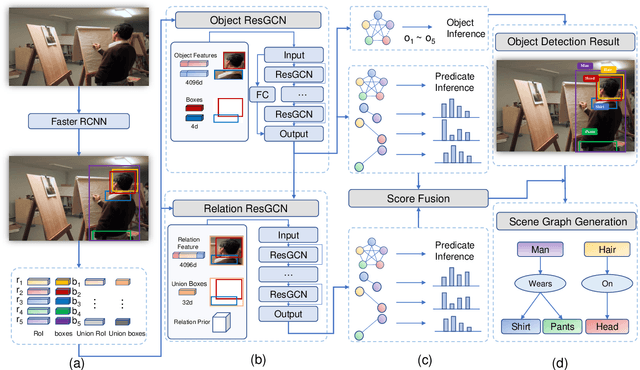
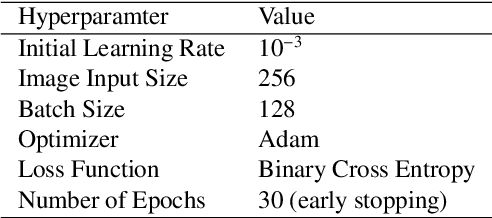
Visual scene graph generation is a challenging task. Previous works have achieved great progress, but most of them do not explicitly consider the class imbalance issue in scene graph generation. Models learned without considering the class imbalance tend to predict the majority classes, which leads to a good performance on trivial frequent predicates, but poor performance on informative infrequent predicates. However, predicates of minority classes often carry more semantic and precise information~(\textit{e.g.}, \emph{`on'} v.s \emph{`parked on'}). % which leads to a good score of recall, but a poor score of mean recall. To alleviate the influence of the class imbalance, we propose a novel model, dubbed \textit{dual ResGCN}, which consists of an object residual graph convolutional network and a relation residual graph convolutional network. The two networks are complementary to each other. The former captures object-level context information, \textit{i.e.,} the connections among objects. We propose a novel ResGCN that enhances object features in a cross attention manner. Besides, we stack multiple contextual coefficients to alleviate the imbalance issue and enrich the prediction diversity. The latter is carefully designed to explicitly capture relation-level context information \textit{i.e.,} the connections among relations. We propose to incorporate the prior about the co-occurrence of relation pairs into the graph to further help alleviate the class imbalance issue. Extensive evaluations of three tasks are performed on the large-scale database VG to demonstrate the superiority of the proposed method.
Anticipation Next -- System-sensitive technology development and integration in work contexts
Mar 01, 2021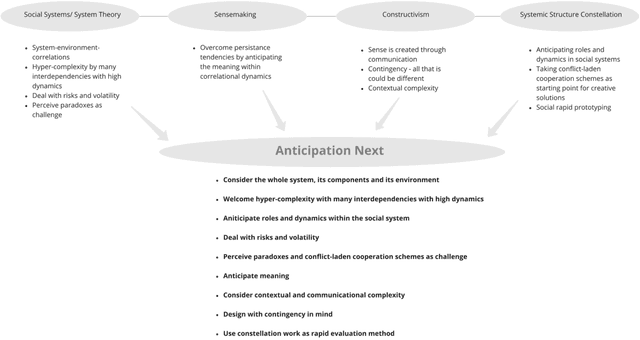
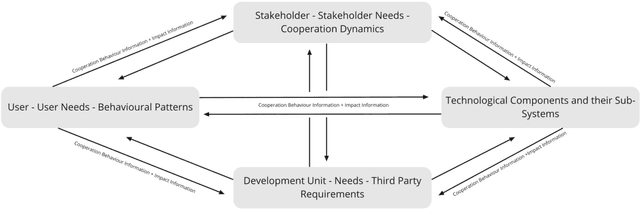
When discussing future concerns within socio-technical systems in work contexts, we often find descriptions of missed technology development and integration. The experience of technology that fails whilst being integrated is often rooted in dysfunctional epistemological approaches within the research and development process. Thus, ultimately leading to sustainable technology-distrust in work contexts. This is true for organisations which integrate new technologies and for organisations that invent them. Organisations in which we find failed technology development and integrations are in their very nature social systems. Nowadays, those complex social systems act within an even more complex environment. This urges for new anticipation methods for technology development and integration. Gathering of and dealing with complex information in the described context is what we call Anticipation Next. This explorative work uses existing literature from the adjoining research fields of system theory, organizational theory, and socio-technical research to combine various concepts. We end with suggesting a conceptual framework that is supposed to be used in very early stages of technology development and integration for and in work contexts.