 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
The fundamental limits of sparse linear regression with sublinear sparsity
Feb 03, 2021
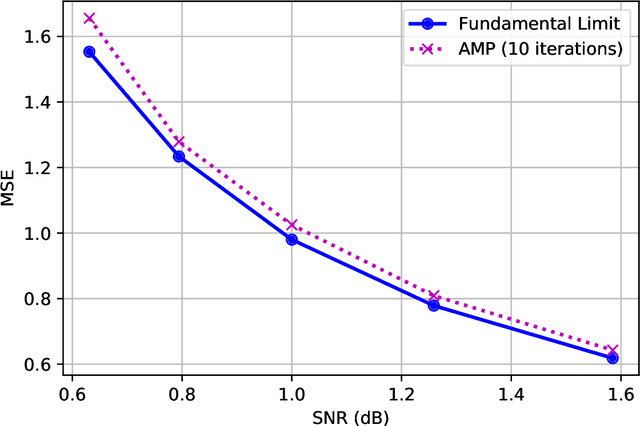
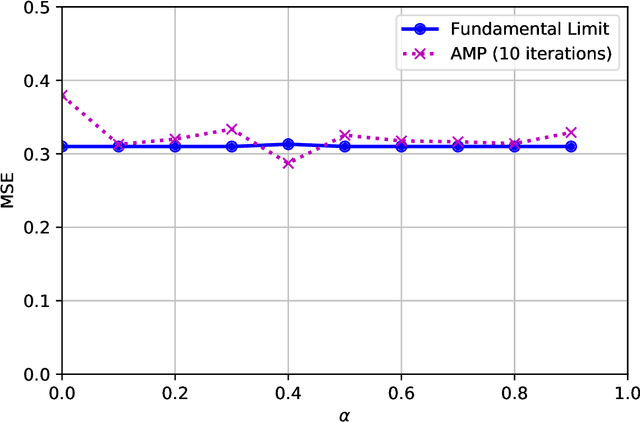
We establish exact asymptotic expressions for the normalized mutual information and minimum mean-square-error (MMSE) of sparse linear regression in the sub-linear sparsity regime. Our result is achieved by a simple generalization of the adaptive interpolation method in Bayesian inference for linear regimes to sub-linear ones. A modification of the well-known approximate message passing algorithm to approach the MMSE fundamental limit is also proposed. Our results show that the traditional linear assumption between the signal dimension and number of observations in the replica and adaptive interpolation methods is not necessary for sparse signals. They also show how to modify the existing well-known AMP algorithms for linear regimes to sub-linear ones.
Multivariate information measures: an experimentalist's perspective
Aug 29, 2012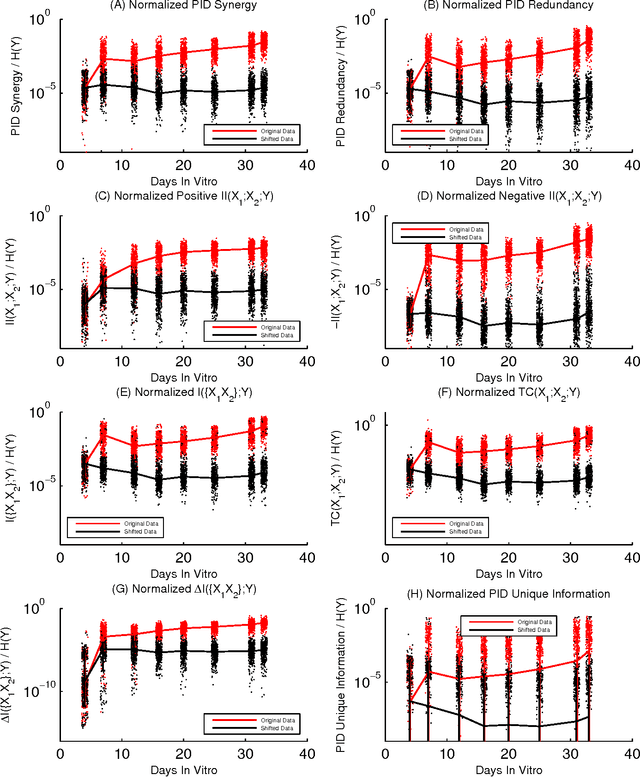
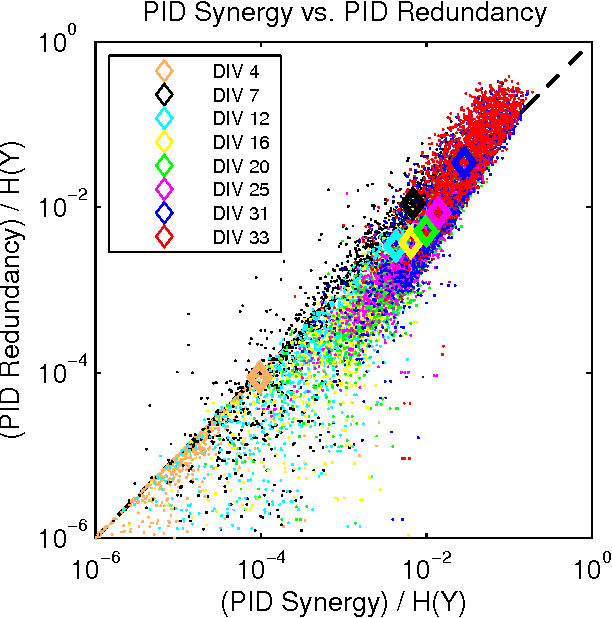


Information theory is widely accepted as a powerful tool for analyzing complex systems and it has been applied in many disciplines. Recently, some central components of information theory - multivariate information measures - have found expanded use in the study of several phenomena. These information measures differ in subtle yet significant ways. Here, we will review the information theory behind each measure, as well as examine the differences between these measures by applying them to several simple model systems. In addition to these systems, we will illustrate the usefulness of the information measures by analyzing neural spiking data from a dissociated culture through early stages of its development. We hope that this work will aid other researchers as they seek the best multivariate information measure for their specific research goals and system. Finally, we have made software available online which allows the user to calculate all of the information measures discussed within this paper.
Optimization meets Big Data: A survey
Feb 03, 2021This paper reviews recent advances in big data optimization, providing the state-of-art of this emerging field. The main focus in this review are optimization techniques being applied in big data analysis environments. Integer linear programming, coordinate descent methods, alternating direction method of multipliers, simulation optimization and metaheuristics like evolutionary and genetic algorithms, particle swarm optimization, differential evolution, fireworks, bat, firefly and cuckoo search algorithms implementations are reviewed and discussed. The relation between big data optimization and software engineering topics like information work-flow styles, software architectures, and software framework is discussed. Comparative analysis in platforms being used in big data optimization environments are highlighted in order to bring a state-or-art of possible architectures and topologies.
ColdGAN: Resolving Cold Start User Recommendation by using Generative Adversarial Networks
Nov 25, 2020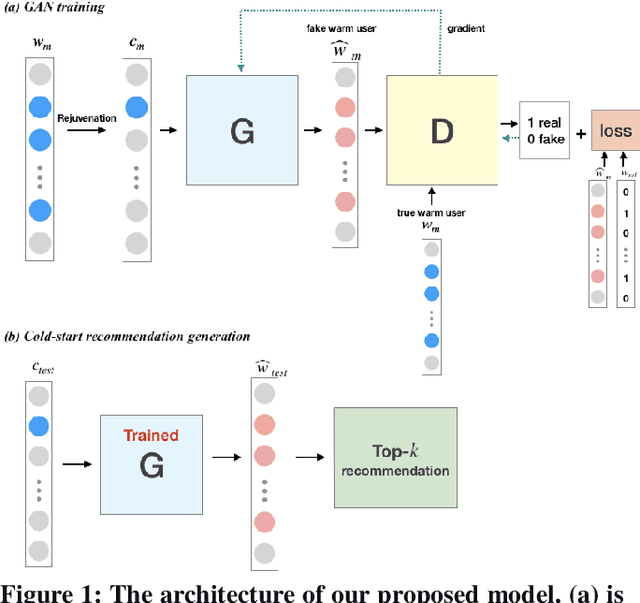
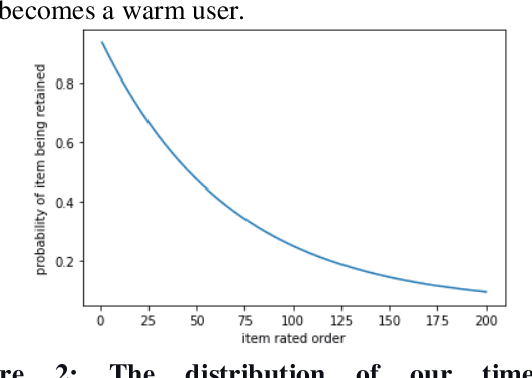
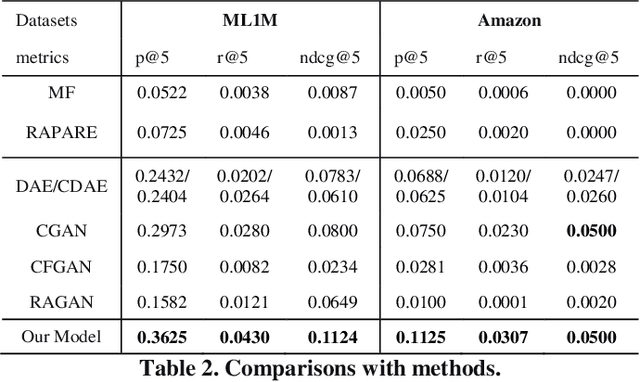
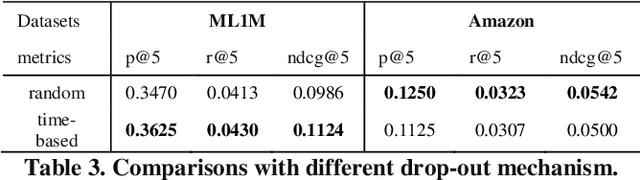
Mitigating the new user cold-start problem has been critical in the recommendation system for online service providers to influence user experience in decision making which can ultimately affect the intention of users to use a particular service. Previous studies leveraged various side information from users and items; however, it may be impractical due to privacy concerns. In this paper, we present ColdGAN, an end-to-end GAN based model with no use of side information to resolve this problem. The main idea of the proposed model is to train a network that learns the rating distributions of experienced users given their cold-start distributions. We further design a time-based function to restore the preferences of users to cold-start states. With extensive experiments on two real-world datasets, the results show that our proposed method achieves significantly improved performance compared with the state-of-the-art recommenders.
DeepMorph: A System for Hiding Bitstrings in Morphable Vector Drawings
Nov 19, 2020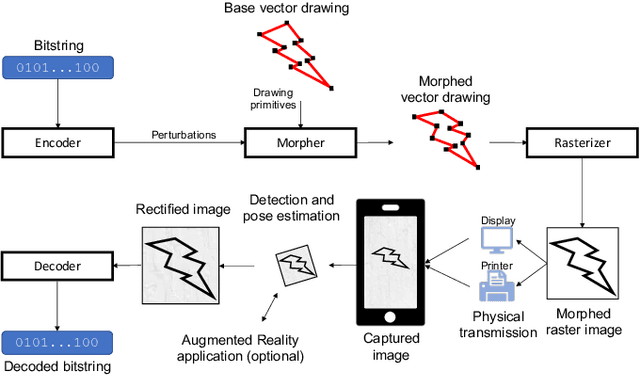

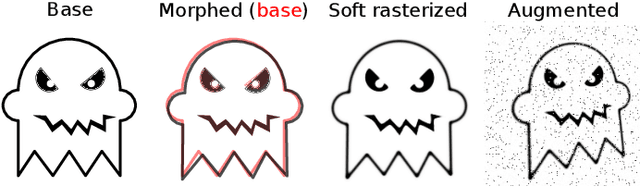

We introduce DeepMorph, an information embedding technique for vector drawings. Provided a vector drawing, such as a Scalable Vector Graphics (SVG) file, our method embeds bitstrings in the image by perturbing the drawing primitives (lines, circles, etc.). This results in a morphed image that can be decoded to recover the original bitstring. The use-case is similar to that of the well-known QR code, but our solution provides creatives with artistic freedom to transfer digital information via drawings of their own design. The method comprises two neural networks, which are trained jointly: an encoder network that transforms a bitstring into a perturbation of the drawing primitives, and a decoder network that recovers the bitstring from an image of the morphed drawing. To enable end-to-end training via back propagation, we introduce a soft rasterizer, which is differentiable with respect to perturbations of the drawing primitives. In order to add robustness towards real-world image capture conditions, image corruptions are injected between the soft rasterizer and the decoder. Further, the addition of an object detection and camera pose estimation system enables decoding of drawings in complex scenes as well as use of the drawings as markers for use in augmented reality applications. We demonstrate that our method reliably recovers bitstrings from real-world photos of printed drawings, thereby providing a novel solution for creatives to transfer digital information via artistic imagery.
Kernel-Based Models for Influence Maximization on Graphs based on Gaussian Process Variance Minimization
Mar 02, 2021
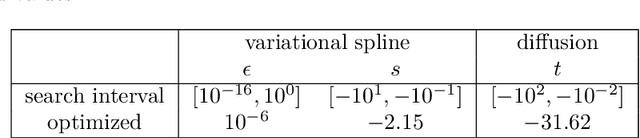
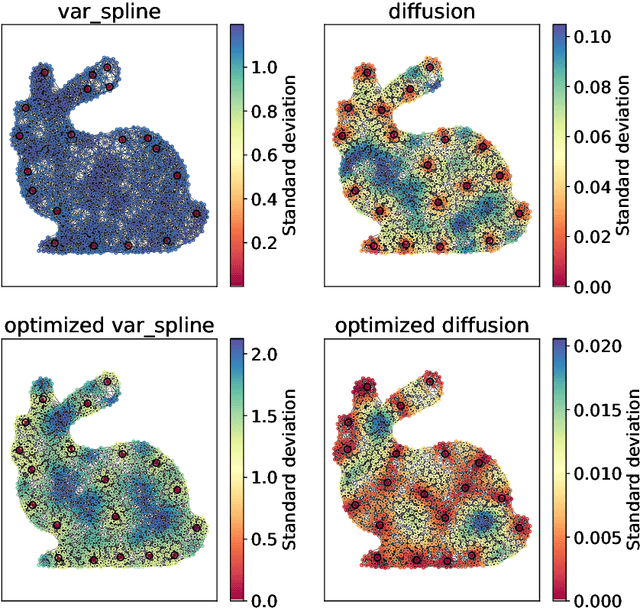
The inference of novel knowledge, the discovery of hidden patterns, and the uncovering of insights from large amounts of data from a multitude of sources make Data Science (DS) to an art rather than just a mere scientific discipline. The study and design of mathematical models able to analyze information represents a central research topic in DS. In this work, we introduce and investigate a novel model for influence maximization (IM) on graphs using ideas from kernel-based approximation, Gaussian process regression, and the minimization of a corresponding variance term. Data-driven approaches can be applied to determine proper kernels for this IM model and machine learning methodologies are adopted to tune the model parameters. Compared to stochastic models in this field that rely on costly Monte-Carlo simulations, our model allows for a simple and cost-efficient update strategy to compute optimal influencing nodes on a graph. In several numerical experiments, we show the properties and benefits of this new model.
Time-Series Imputation with Wasserstein Interpolation for Optimal Look-Ahead-Bias and Variance Tradeoff
Feb 25, 2021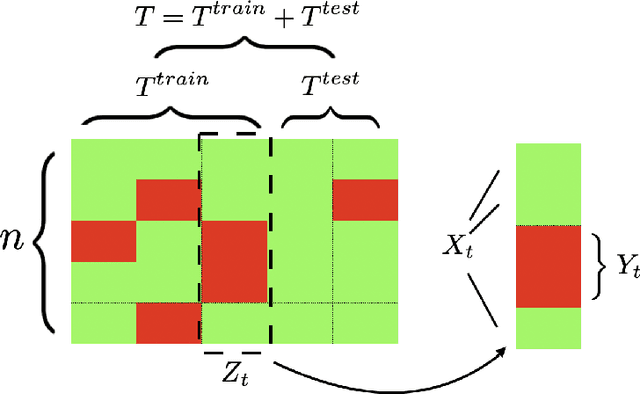
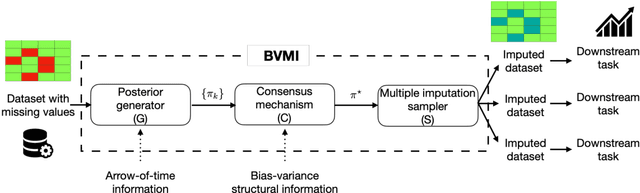
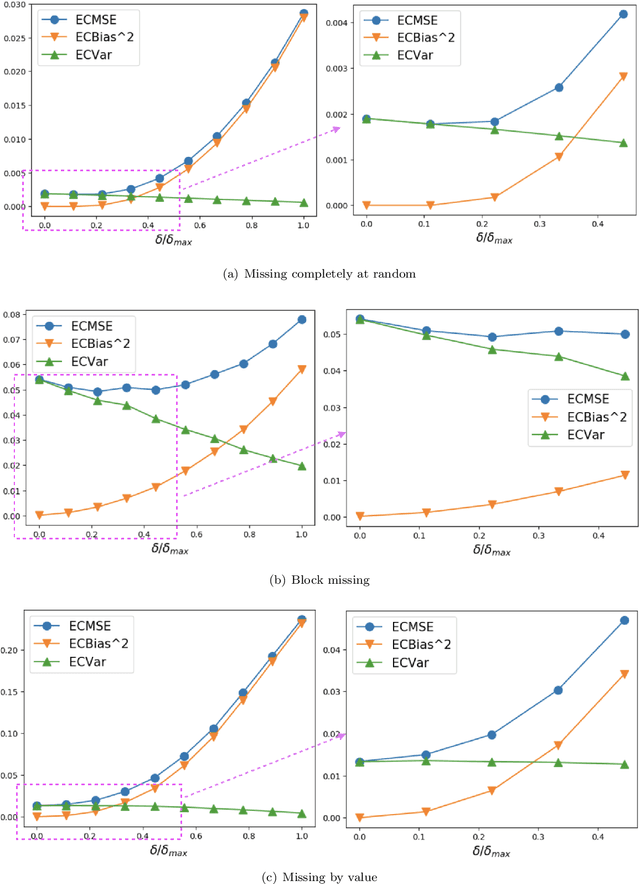
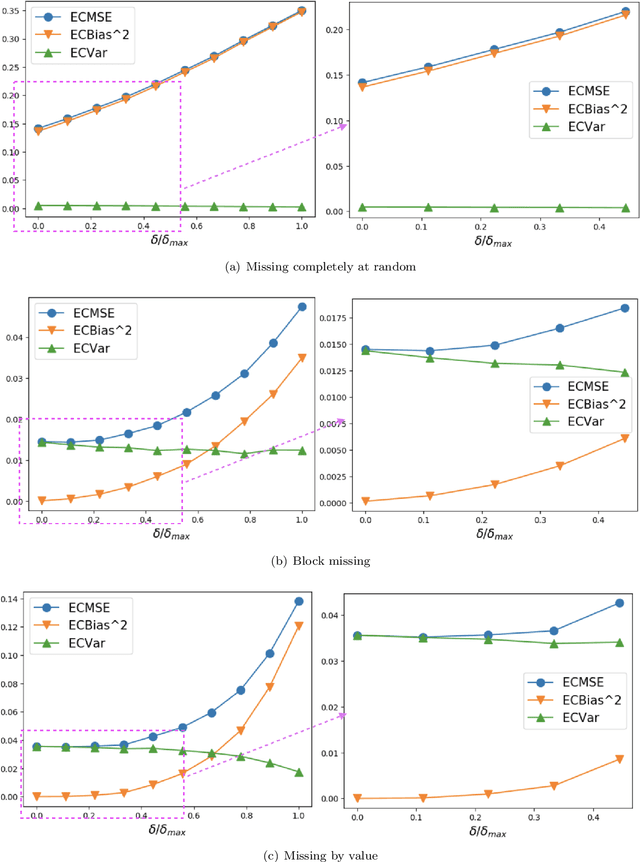
Missing time-series data is a prevalent practical problem. Imputation methods in time-series data often are applied to the full panel data with the purpose of training a model for a downstream out-of-sample task. For example, in finance, imputation of missing returns may be applied prior to training a portfolio optimization model. Unfortunately, this practice may result in a look-ahead-bias in the future performance on the downstream task. There is an inherent trade-off between the look-ahead-bias of using the full data set for imputation and the larger variance in the imputation from using only the training data. By connecting layers of information revealed in time, we propose a Bayesian posterior consensus distribution which optimally controls the variance and look-ahead-bias trade-off in the imputation. We demonstrate the benefit of our methodology both in synthetic and real financial data.
"Attention" for Detecting Unreliable News in the Information Age
Nov 03, 2017
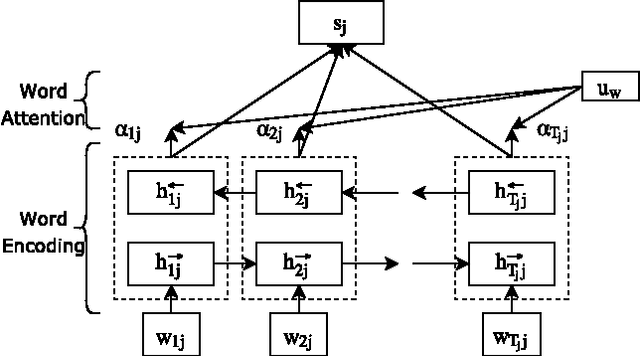
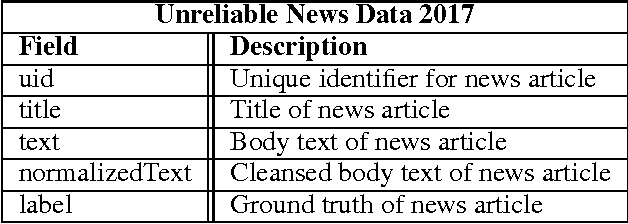
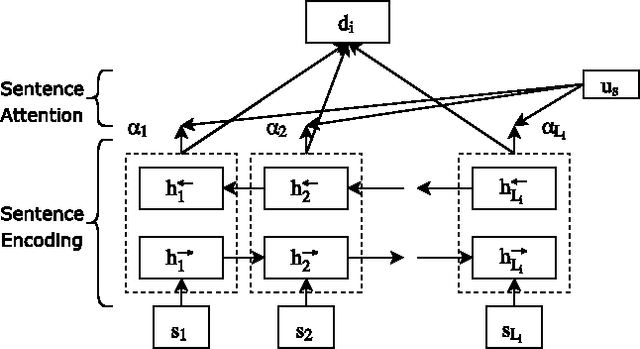
An Unreliable news is any piece of information which is false or misleading, deliberately spread to promote political, ideological and financial agendas. Recently the problem of unreliable news has got a lot of attention as the number instances of using news and social media outlets for propaganda have increased rapidly. This poses a serious threat to society, which calls for technology to automatically and reliably identify unreliable news sources. This paper is an effort made in this direction to build systems for detecting unreliable news articles. In this paper, various NLP algorithms were built and evaluated on Unreliable News Data 2017 dataset. Variants of hierarchical attention networks (HAN) are presented for encoding and classifying news articles which achieve the best results of 0.944 ROC-AUC. Finally, Attention layer weights are visualized to understand and give insight into the decisions made by HANs. The results obtained are very promising and encouraging to deploy and use these systems in the real world to mitigate the problem of unreliable news.
Hybrid Encoder: Towards Efficient and Precise Native AdsRecommendation via Hybrid Transformer Encoding Networks
Apr 22, 2021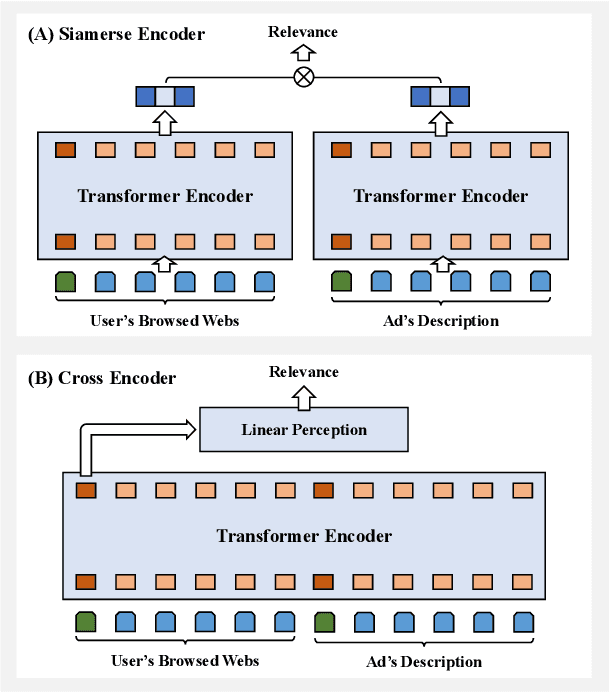
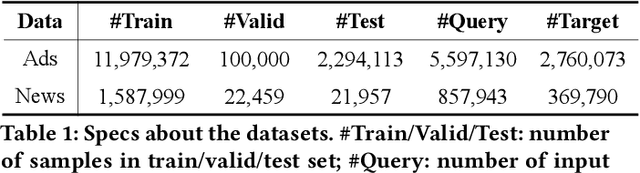
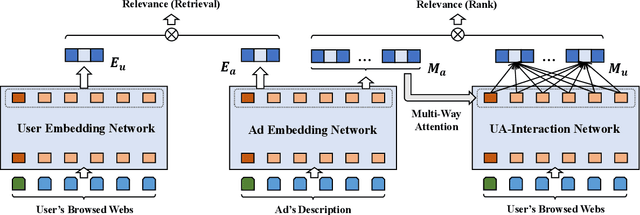
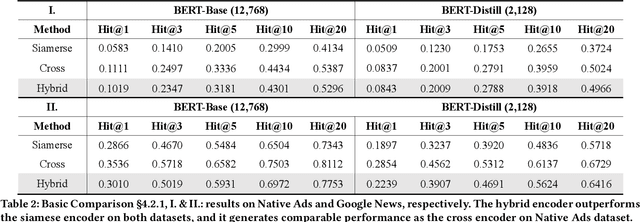
Transformer encoding networks have been proved to be a powerful tool of understanding natural languages. They are playing a critical role in native ads service, which facilitates the recommendation of appropriate ads based on user's web browsing history. For the sake of efficient recommendation, conventional methods would generate user and advertisement embeddings independently with a siamese transformer encoder, such that approximate nearest neighbour search (ANN) can be leveraged. Given that the underlying semantic about user and ad can be complicated, such independently generated embeddings are prone to information loss, which leads to inferior recommendation quality. Although another encoding strategy, the cross encoder, can be much more accurate, it will lead to huge running cost and become infeasible for realtime services, like native ads recommendation. In this work, we propose hybrid encoder, which makes efficient and precise native ads recommendation through two consecutive steps: retrieval and ranking. In the retrieval step, user and ad are encoded with a siamese component, which enables relevant candidates to be retrieved via ANN search. In the ranking step, it further represents each ad with disentangled embeddings and each user with ad-related embeddings, which contributes to the fine-grained selection of high-quality ads from the candidate set. Both steps are light-weighted, thanks to the pre-computed and cached intermedia results. To optimize the hybrid encoder's performance in this two-stage workflow, a progressive training pipeline is developed, which builds up the model's capability in the retrieval and ranking task step-by-step. The hybrid encoder's effectiveness is experimentally verified: with very little additional cost, it outperforms the siamese encoder significantly and achieves comparable recommendation quality as the cross encoder.
Independent Reinforcement Learning for Weakly Cooperative Multiagent Traffic Control Problem
Apr 22, 2021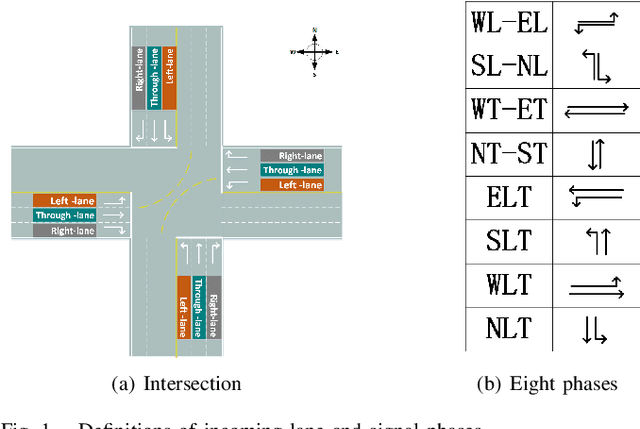

The adaptive traffic signal control (ATSC) problem can be modeled as a multiagent cooperative game among urban intersections, where intersections cooperate to optimize their common goal. Recently, reinforcement learning (RL) has achieved marked successes in managing sequential decision making problems, which motivates us to apply RL in the ASTC problem. Here we use independent reinforcement learning (IRL) to solve a complex traffic cooperative control problem in this study. One of the largest challenges of this problem is that the observation information of intersection is typically partially observable, which limits the learning performance of IRL algorithms. To this, we model the traffic control problem as a partially observable weak cooperative traffic model (PO-WCTM) to optimize the overall traffic situation of a group of intersections. Different from a traditional IRL task that averages the returns of all agents in fully cooperative games, the learning goal of each intersection in PO-WCTM is to reduce the cooperative difficulty of learning, which is also consistent with the traffic environment hypothesis. We also propose an IRL algorithm called Cooperative Important Lenient Double DQN (CIL-DDQN), which extends Double DQN (DDQN) algorithm using two mechanisms: the forgetful experience mechanism and the lenient weight training mechanism. The former mechanism decreases the importance of experiences stored in the experience reply buffer, which deals with the problem of experience failure caused by the strategy change of other agents. The latter mechanism increases the weight experiences with high estimation and `leniently' trains the DDQN neural network, which improves the probability of the selection of cooperative joint strategies. Experimental results show that CIL-DDQN outperforms other methods in almost all performance indicators of the traffic control problem.