 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Spectral Decomposition in Deep Networks for Segmentation of Dynamic Medical Images
Sep 30, 2020

Dynamic contrast-enhanced magnetic resonance imaging (DCE- MRI) is a widely used multi-phase technique routinely used in clinical practice. DCE and similar datasets of dynamic medical data tend to contain redundant information on the spatial and temporal components that may not be relevant for detection of the object of interest and result in unnecessarily complex computer models with long training times that may also under-perform at test time due to the abundance of noisy heterogeneous data. This work attempts to increase the training efficacy and performance of deep networks by determining redundant information in the spatial and spectral components and show that the performance of segmentation accuracy can be maintained and potentially improved. Reported experiments include the evaluation of training/testing efficacy on a heterogeneous dataset composed of abdominal images of pediatric DCE patients, showing that drastic data reduction (higher than 80%) can preserve the dynamic information and performance of the segmentation model, while effectively suppressing noise and unwanted portion of the images.
On Modality Bias in the TVQA Dataset
Dec 18, 2020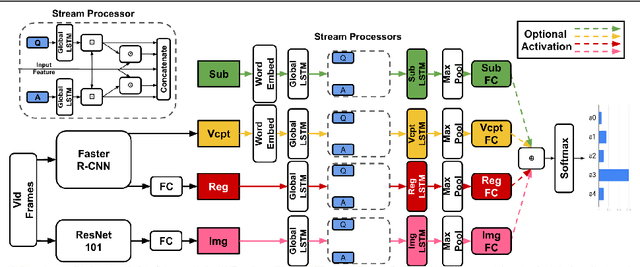
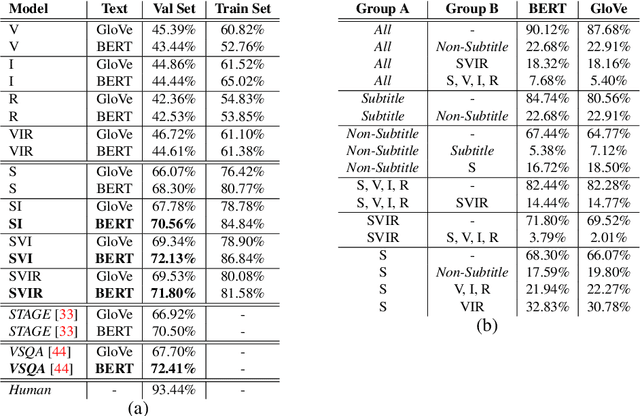
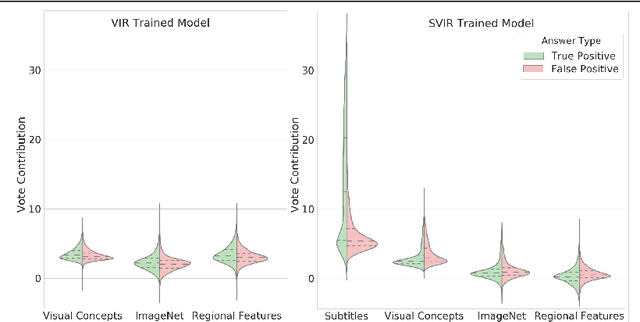

TVQA is a large scale video question answering (video-QA) dataset based on popular TV shows. The questions were specifically designed to require "both vision and language understanding to answer". In this work, we demonstrate an inherent bias in the dataset towards the textual subtitle modality. We infer said bias both directly and indirectly, notably finding that models trained with subtitles learn, on-average, to suppress video feature contribution. Our results demonstrate that models trained on only the visual information can answer ~45% of the questions, while using only the subtitles achieves ~68%. We find that a bilinear pooling based joint representation of modalities damages model performance by 9% implying a reliance on modality specific information. We also show that TVQA fails to benefit from the RUBi modality bias reduction technique popularised in VQA. By simply improving text processing using BERT embeddings with the simple model first proposed for TVQA, we achieve state-of-the-art results (72.13%) compared to the highly complex STAGE model (70.50%). We recommend a multimodal evaluation framework that can highlight biases in models and isolate visual and textual reliant subsets of data. Using this framework we propose subsets of TVQA that respond exclusively to either or both modalities in order to facilitate multimodal modelling as TVQA originally intended.
DEF: Deep Estimation of Sharp Geometric Features in 3D Shapes
Nov 30, 2020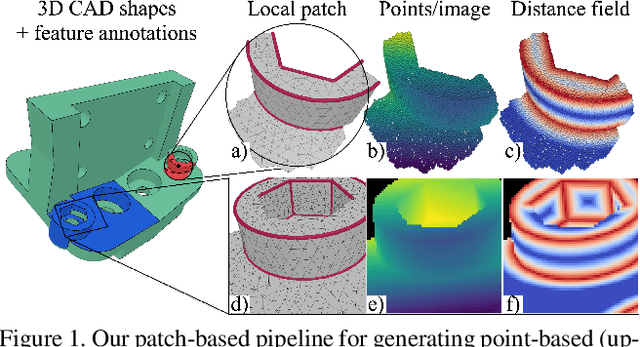
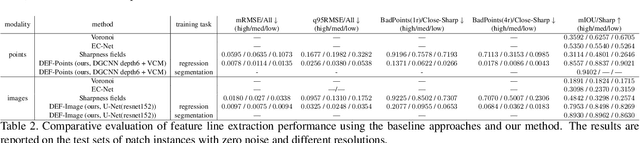
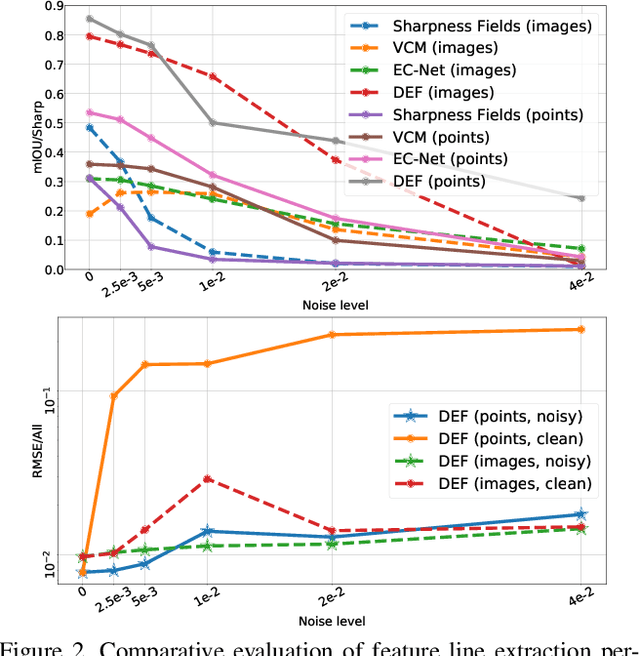
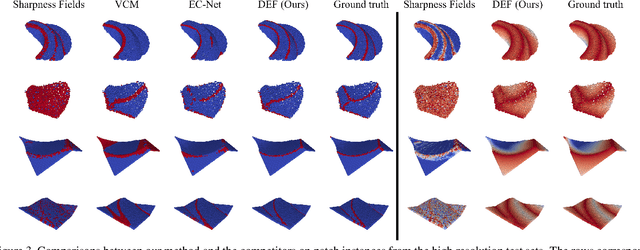
Sharp feature lines carry essential information about human-made objects, enabling compact 3D shape representations, high-quality surface reconstruction, and are a signal source for mesh processing. While extracting high-quality lines from noisy and undersampled data is challenging for traditional methods, deep learning-powered algorithms can leverage global and semantic information from the training data to aid in the process. We propose Deep Estimators of Features (DEFs), a learning-based framework for predicting sharp geometric features in sampled 3D shapes. Differently from existing data-driven methods, which reduce this problem to feature classification, we propose to regress a scalar field representing the distance from point samples to the closest feature line on local patches. By fusing the result of individual patches, we can process large 3D models, which are impossible to process for existing data-driven methods due to their size and complexity. Extensive experimental evaluation of DEFs is implemented on synthetic and real-world 3D shape datasets and suggests advantages of our image- and point-based estimators over competitor methods, as well as improved noise robustness and scalability of our approach.
Contrastive Explanations for Model Interpretability
Mar 02, 2021

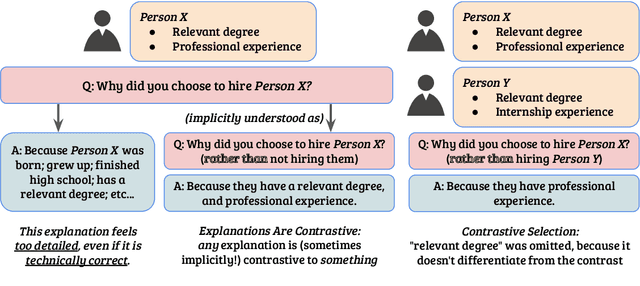
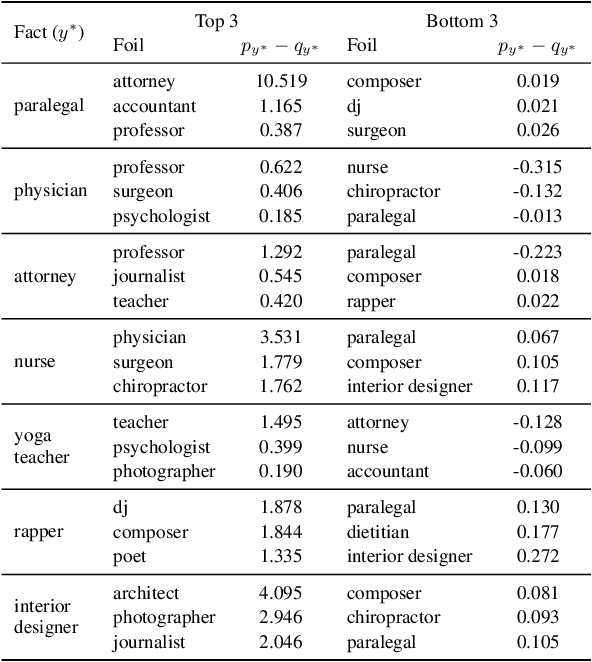
Contrastive explanations clarify why an event occurred in contrast to another. They are more inherently intuitive to humans to both produce and comprehend. We propose a methodology to produce contrastive explanations for classification models by modifying the representation to disregard non-contrastive information, and modifying model behavior to only be based on contrastive reasoning. Our method is based on projecting model representation to a latent space that captures only the features that are useful (to the model) to differentiate two potential decisions. We demonstrate the value of contrastive explanations by analyzing two different scenarios, using both high-level abstract concept attribution and low-level input token/span attribution, on two widely used text classification tasks. Specifically, we produce explanations for answering: for which label, and against which alternative label, is some aspect of the input useful? And which aspects of the input are useful for and against particular decisions? Overall, our findings shed light on the ability of label-contrastive explanations to provide a more accurate and finer-grained interpretability of a model's decision.
An ontology-based chatbot for crises management: use case coronavirus
Nov 02, 2020


Today is the era of intelligence in machines. With the advances in Artificial Intelligence, machines have started to impersonate different human traits, a chatbot is the next big thing in the domain of conversational services. A chatbot is a virtual person who is capable to carry out a natural conversation with people. They can include skills that enable them to converse with the humans in audio, visual, or textual formats. Artificial intelligence conversational entities, also called chatbots, conversational agents, or dialogue system, are an excellent example of such machines. Obtaining the right information at the right time and place is the key to effective disaster management. The term "disaster management" encompasses both natural and human-caused disasters. To assist citizens, our project is to create a COVID Assistant to provide the need of up to date information to be available 24 hours. With the growth in the World Wide Web, it is quite intelligible that users are interested in the swift and relatedly correct information for their hunt. A chatbot can be seen as a question-and-answer system in which experts provide knowledge to solicit users. This master thesis is dedicated to discuss COVID Assistant chatbot and explain each component in detail. The design of the proposed chatbot is introduced by its seven components: Ontology, Web Scraping module, DB, State Machine, keyword Extractor, Trained chatbot, and User Interface.
TSGCNet: Discriminative Geometric Feature Learning with Two-Stream GraphConvolutional Network for 3D Dental Model Segmentation
Dec 26, 2020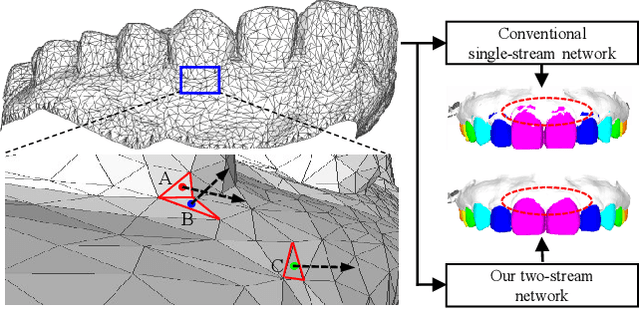

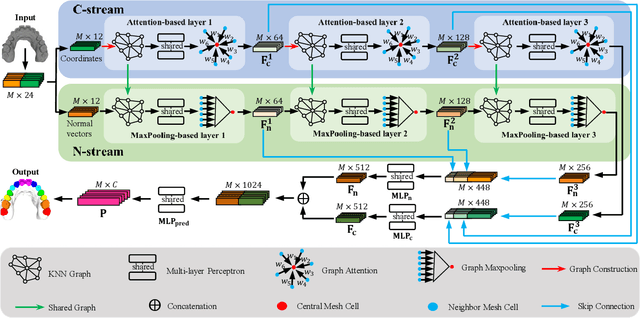
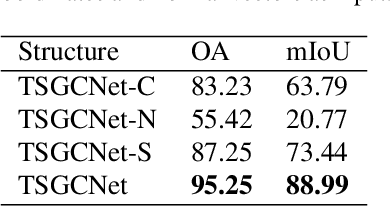
The ability to segment teeth precisely from digitized 3D dental models is an essential task in computer-aided orthodontic surgical planning. To date, deep learning based methods have been popularly used to handle this task. State-of-the-art methods directly concatenate the raw attributes of 3D inputs, namely coordinates and normal vectors of mesh cells, to train a single-stream network for fully-automated tooth segmentation. This, however, has the drawback of ignoring the different geometric meanings provided by those raw attributes. This issue might possibly confuse the network in learning discriminative geometric features and result in many isolated false predictions on the dental model. Against this issue, we propose a two-stream graph convolutional network (TSGCNet) to learn multi-view geometric information from different geometric attributes. Our TSGCNet adopts two graph-learning streams, designed in an input-aware fashion, to extract more discriminative high-level geometric representations from coordinates and normal vectors, respectively. These feature representations learned from the designed two different streams are further fused to integrate the multi-view complementary information for the cell-wise dense prediction task. We evaluate our proposed TSGCNet on a real-patient dataset of dental models acquired by 3D intraoral scanners, and experimental results demonstrate that our method significantly outperforms state-of-the-art methods for 3D shape segmentation.
Guided Source Separation
Nov 09, 2020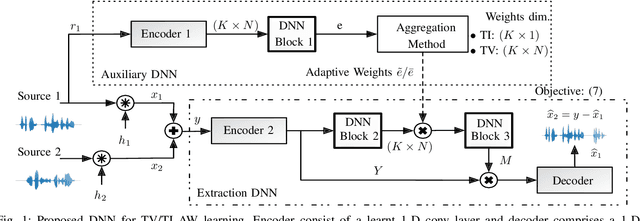
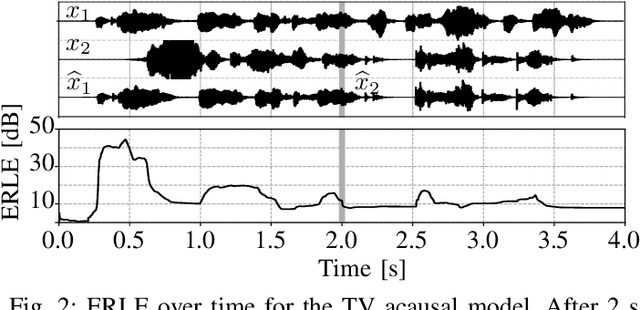

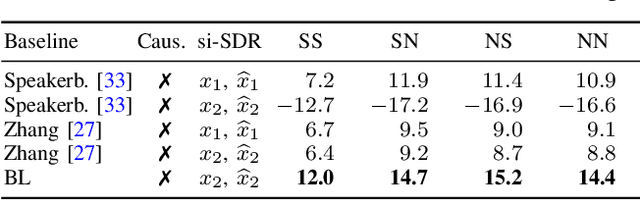
State-of-the-art separation of desired signal components from a mixture is achieved using time-frequency masks or filters estimated by a deep neural network (DNN). The desired components, thereby, are typically defined at the time of training. Recent approaches allow determining the desired components during inference via auxiliary information. Auxiliary information is, thereby, extracted from a reference snippet of the desired components by a second DNN, which estimates a set of adaptive weights (AW) of the first DNN. However, the AW methods require the reference snippet and the desired signal to exhibit time-invariant signal characteristics (SCs) and have only been applied for speaker separation. We show that these AW methods can be used for universal source separation and propose an AW method to extract time-variant auxiliary information from the reference signal. That way, the SCs are allowed to vary across time in the reference and mixture. Applications where the reference and desired signal cannot be assigned to a specific class and vary over time require a time-dependency. An example is acoustic echo cancellation, where the reference is the loudspeaker signal. To avoid strong scaling between the estimate and the mixture, we propose the dual scale-invariant signal-to-distortion ratio in a TASNET inspired DNN as the training objective. We evaluate the proposed AW systems using a wide range of different acoustic conditions and show the scenario dependent advantages of time-variant over time-invariant AW.
Chord Embeddings: Analyzing What They Capture and Their Role for Next Chord Prediction and Artist Attribute Prediction
Feb 04, 2021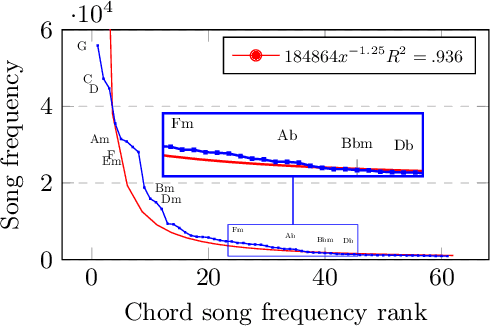
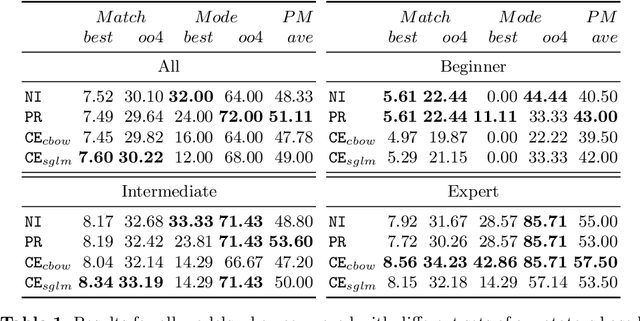
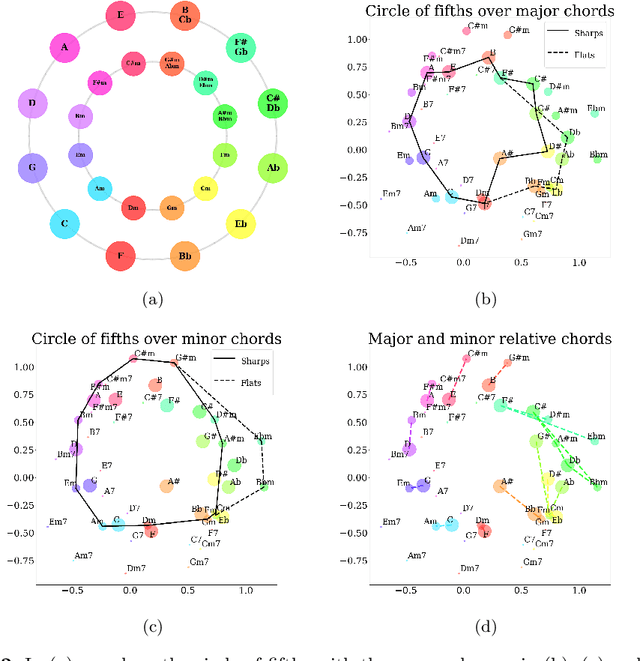
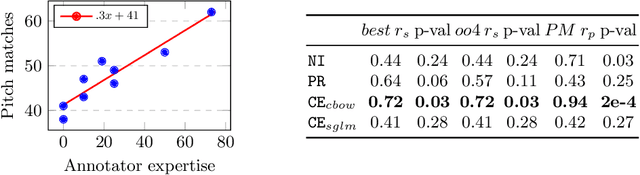
Natural language processing methods have been applied in a variety of music studies, drawing the connection between music and language. In this paper, we expand those approaches by investigating \textit{chord embeddings}, which we apply in two case studies to address two key questions: (1) what musical information do chord embeddings capture?; and (2) how might musical applications benefit from them? In our analysis, we show that they capture similarities between chords that adhere to important relationships described in music theory. In the first case study, we demonstrate that using chord embeddings in a next chord prediction task yields predictions that more closely match those by experienced musicians. In the second case study, we show the potential benefits of using the representations in tasks related to musical stylometrics.
* 16 pages, accepted to EvoMUSART
Decoupling Value and Policy for Generalization in Reinforcement Learning
Feb 20, 2021
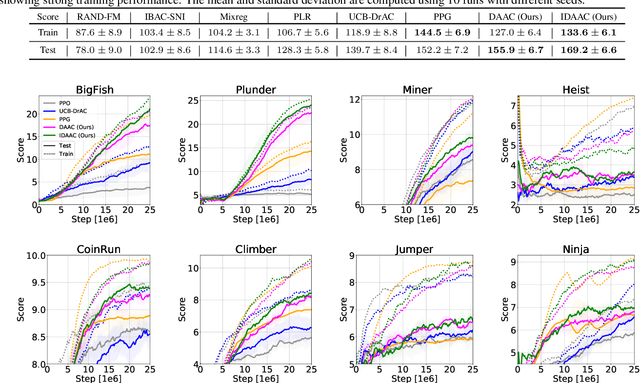
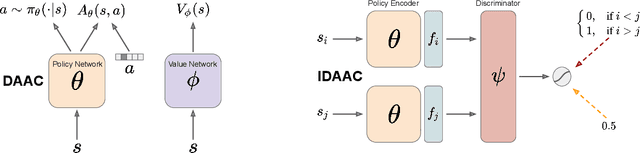
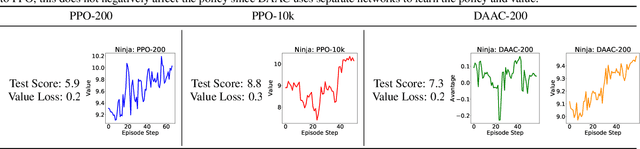
Standard deep reinforcement learning algorithms use a shared representation for the policy and value function. However, we argue that more information is needed to accurately estimate the value function than to learn the optimal policy. Consequently, the use of a shared representation for the policy and value function can lead to overfitting. To alleviate this problem, we propose two approaches which are combined to create IDAAC: Invariant Decoupled Advantage Actor-Critic. First, IDAAC decouples the optimization of the policy and value function, using separate networks to model them. Second, it introduces an auxiliary loss which encourages the representation to be invariant to task-irrelevant properties of the environment. IDAAC shows good generalization to unseen environments, achieving a new state-of-the-art on the Procgen benchmark and outperforming popular methods on DeepMind Control tasks with distractors. Moreover, IDAAC learns representations, value predictions, and policies that are more robust to aesthetic changes in the observations that do not change the underlying state of the environment.
A fully automated end-to-end process for fluorescence microscopy images of yeast cells: From segmentation to detection and classification
Apr 06, 2021

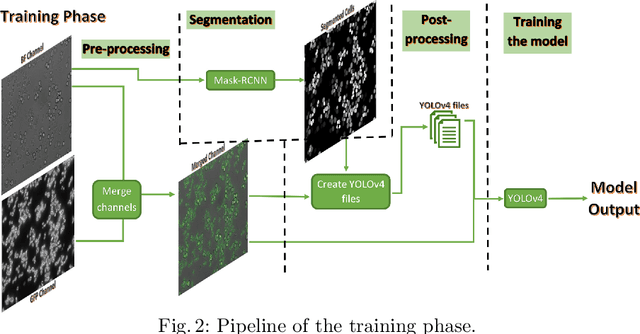
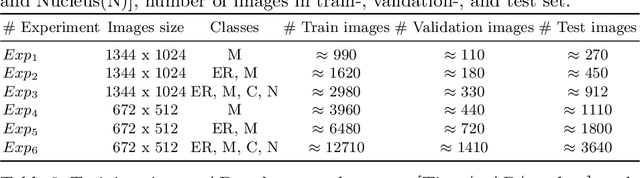
In recent years, an enormous amount of fluorescence microscopy images were collected in high-throughput lab settings. Analyzing and extracting relevant information from all images in a short time is almost impossible. Detecting tiny individual cell compartments is one of many challenges faced by biologists. This paper aims at solving this problem by building an end-to-end process that employs methods from the deep learning field to automatically segment, detect and classify cell compartments of fluorescence microscopy images of yeast cells. With this intention we used Mask R-CNN to automatically segment and label a large amount of yeast cell data, and YOLOv4 to automatically detect and classify individual yeast cell compartments from these images. This fully automated end-to-end process is intended to be integrated into an interactive e-Science server in the PerICo1 project, which can be used by biologists with minimized human effort in training and operation to complete their various classification tasks. In addition, we evaluated the detection and classification performance of state-of-the-art YOLOv4 on data from the NOP1pr-GFP-SWAT yeast-cell data library. Experimental results show that by dividing original images into 4 quadrants YOLOv4 outputs good detection and classification results with an F1-score of 98% in terms of accuracy and speed, which is optimally suited for the native resolution of the microscope and current GPU memory sizes. Although the application domain is optical microscopy in yeast cells, the method is also applicable to multiple-cell images in medical applications