 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Channel Leakage and Fundamental Limits of Privacy Leakage for Streaming Data
Aug 25, 2020
In this paper, we first introduce the notion of channel leakage as the minimum mutual information between the channel input and channel output. As its name indicates, channel leakage quantifies the (minimum) information leakage to the malicious receiver. In a broad sense, it can be viewed as a dual concept of channel capacity, which characterizes the (maximum) information transmission to the targeted receiver. We obtain explicit formulas of channel leakage for the white Gaussian case and colored Gaussian case. We also study the implications of channel leakage in characterizing the fundamental limitations of privacy leakage for streaming data.
Future Frame Prediction for Robot-assisted Surgery
Mar 18, 2021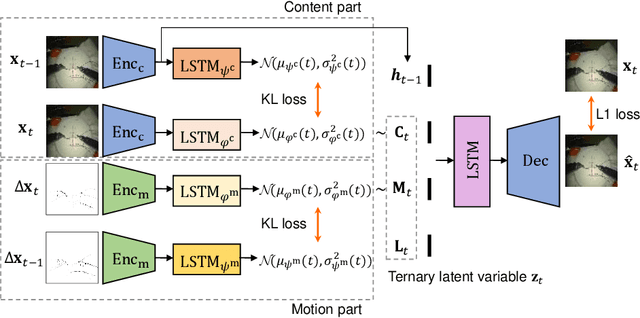
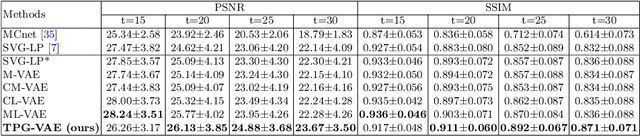

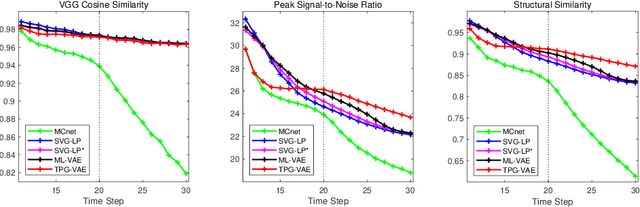
Predicting future frames for robotic surgical video is an interesting, important yet extremely challenging problem, given that the operative tasks may have complex dynamics. Existing approaches on future prediction of natural videos were based on either deterministic models or stochastic models, including deep recurrent neural networks, optical flow, and latent space modeling. However, the potential in predicting meaningful movements of robots with dual arms in surgical scenarios has not been tapped so far, which is typically more challenging than forecasting independent motions of one arm robots in natural scenarios. In this paper, we propose a ternary prior guided variational autoencoder (TPG-VAE) model for future frame prediction in robotic surgical video sequences. Besides content distribution, our model learns motion distribution, which is novel to handle the small movements of surgical tools. Furthermore, we add the invariant prior information from the gesture class into the generation process to constrain the latent space of our model. To our best knowledge, this is the first time that the future frames of dual arm robots are predicted considering their unique characteristics relative to general robotic videos. Experiments demonstrate that our model gains more stable and realistic future frame prediction scenes with the suturing task on the public JIGSAWS dataset.
Reinforcement Learning for Deceiving Reactive Jammers in Wireless Networks
Mar 25, 2021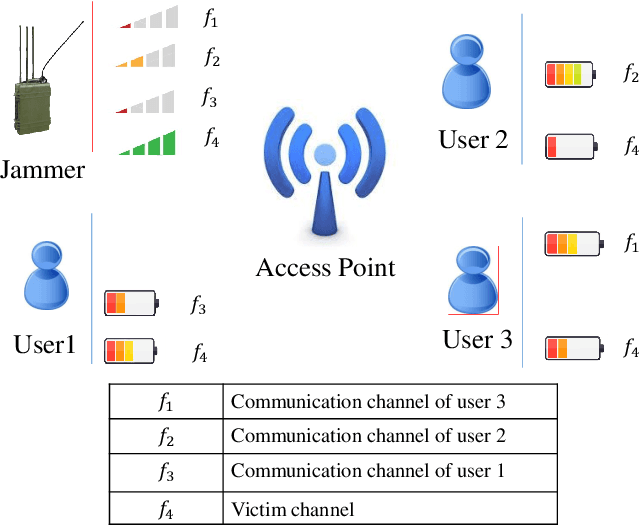
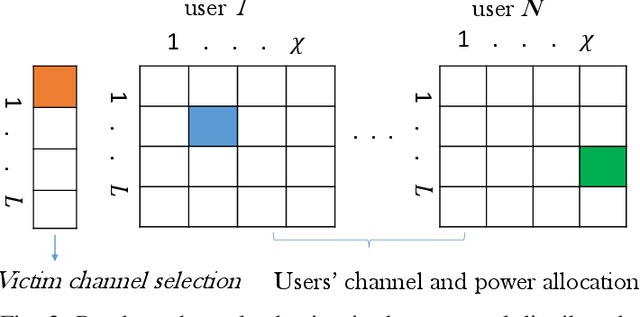
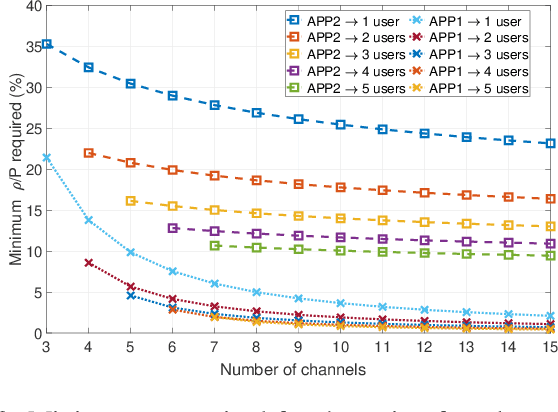
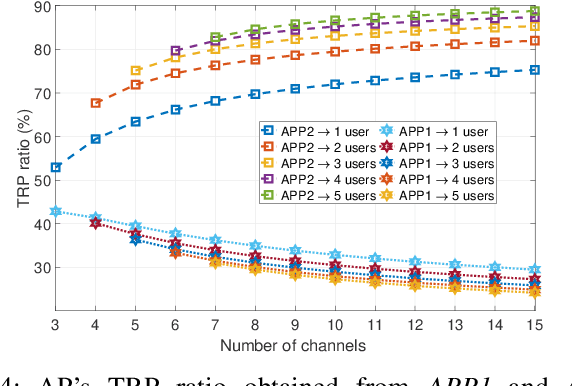
Conventional anti-jamming method mostly rely on frequency hopping to hide or escape from jammer. These approaches are not efficient in terms of bandwidth usage and can also result in a high probability of jamming. Different from existing works, in this paper, a novel anti-jamming strategy is proposed based on the idea of deceiving the jammer into attacking a victim channel while maintaining the communications of legitimate users in safe channels. Since the jammer's channel information is not known to the users, an optimal channel selection scheme and a sub optimal power allocation are proposed using reinforcement learning (RL). The performance of the proposed anti-jamming technique is evaluated by deriving the statistical lower bound of the total received power (TRP). Analytical results show that, for a given access point, over 50 % of the highest achievable TRP, i.e. in the absence of jammers, is achieved for the case of a single user and three frequency channels. Moreover, this value increases with the number of users and available channels. The obtained results are compared with two existing RL based anti-jamming techniques, and random channel allocation strategy without any jamming attacks. Simulation results show that the proposed anti-jamming method outperforms the compared RL based anti-jamming methods and random search method, and yields near optimal achievable TRP.
Beyond Trivial Counterfactual Explanations with Diverse Valuable Explanations
Mar 18, 2021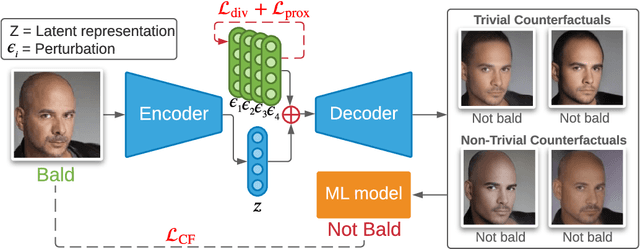
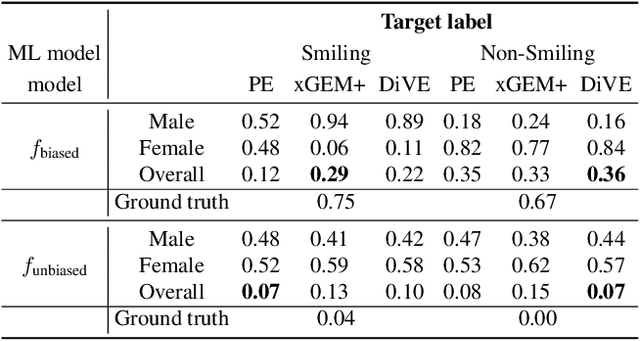

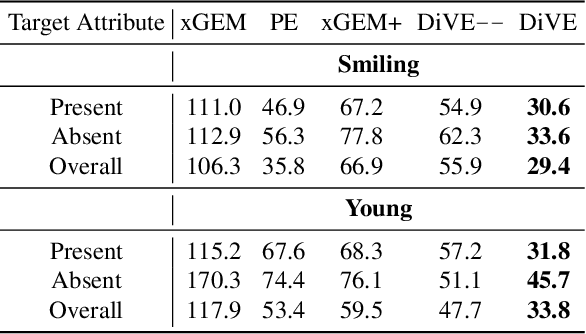
Explainability for machine learning models has gained considerable attention within our research community given the importance of deploying more reliable machine-learning systems. In computer vision applications, generative counterfactual methods indicate how to perturb a model's input to change its prediction, providing details about the model's decision-making. Current counterfactual methods make ambiguous interpretations as they combine multiple biases of the model and the data in a single counterfactual interpretation of the model's decision. Moreover, these methods tend to generate trivial counterfactuals about the model's decision, as they often suggest to exaggerate or remove the presence of the attribute being classified. For the machine learning practitioner, these types of counterfactuals offer little value, since they provide no new information about undesired model or data biases. In this work, we propose a counterfactual method that learns a perturbation in a disentangled latent space that is constrained using a diversity-enforcing loss to uncover multiple valuable explanations about the model's prediction. Further, we introduce a mechanism to prevent the model from producing trivial explanations. Experiments on CelebA and Synbols demonstrate that our model improves the success rate of producing high-quality valuable explanations when compared to previous state-of-the-art methods. We will publish the code.
Lightweight, Dynamic Graph Convolutional Networks for AMR-to-Text Generation
Oct 09, 2020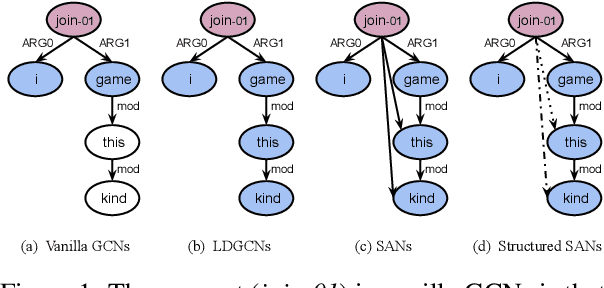
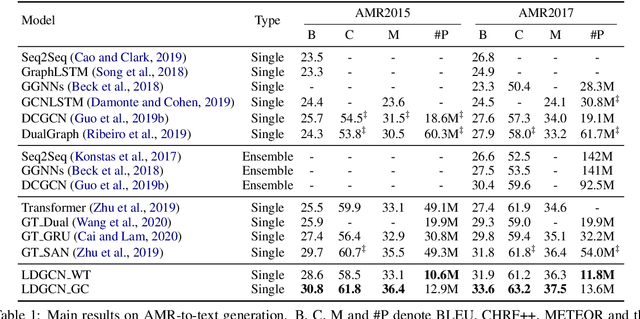
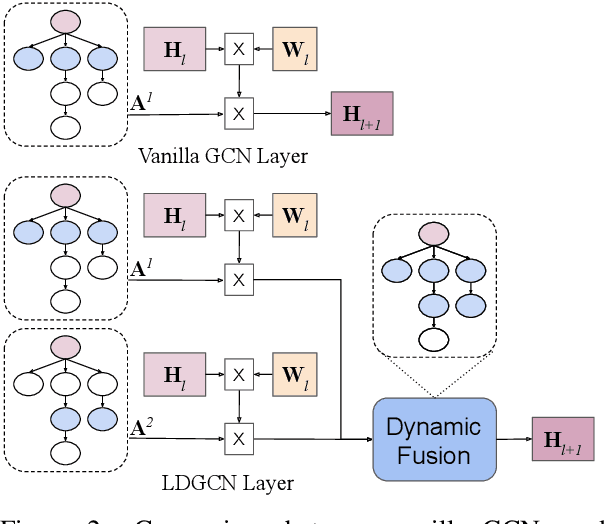
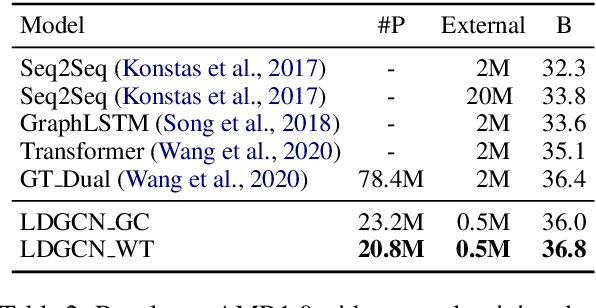
AMR-to-text generation is used to transduce Abstract Meaning Representation structures (AMR) into text. A key challenge in this task is to efficiently learn effective graph representations. Previously, Graph Convolution Networks (GCNs) were used to encode input AMRs, however, vanilla GCNs are not able to capture non-local information and additionally, they follow a local (first-order) information aggregation scheme. To account for these issues, larger and deeper GCN models are required to capture more complex interactions. In this paper, we introduce a dynamic fusion mechanism, proposing Lightweight Dynamic Graph Convolutional Networks (LDGCNs) that capture richer non-local interactions by synthesizing higher order information from the input graphs. We further develop two novel parameter saving strategies based on the group graph convolutions and weight tied convolutions to reduce memory usage and model complexity. With the help of these strategies, we are able to train a model with fewer parameters while maintaining the model capacity. Experiments demonstrate that LDGCNs outperform state-of-the-art models on two benchmark datasets for AMR-to-text generation with significantly fewer parameters.
Linguistic Profiling of a Neural Language Model
Oct 30, 2020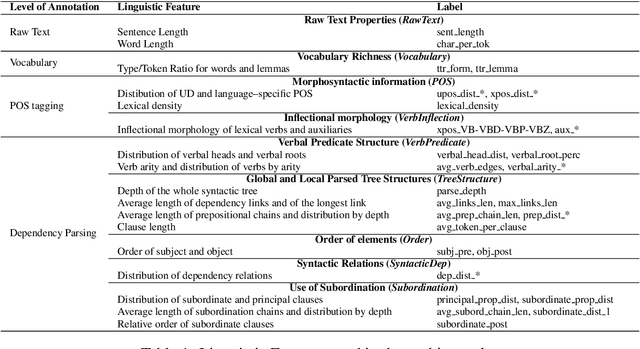
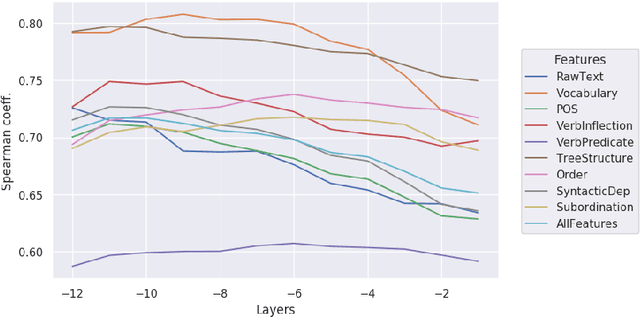

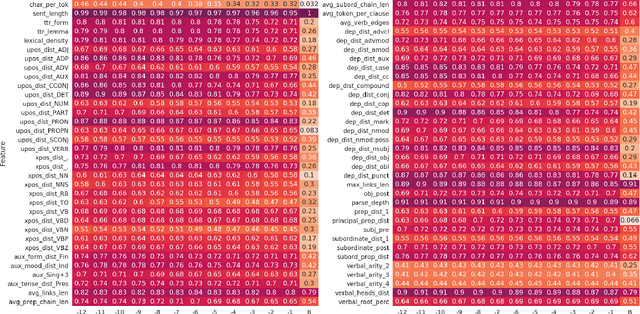
In this paper we investigate the linguistic knowledge learned by a Neural Language Model (NLM) before and after a fine-tuning process and how this knowledge affects its predictions during several classification problems. We use a wide set of probing tasks, each of which corresponds to a distinct sentence-level feature extracted from different levels of linguistic annotation. We show that BERT is able to encode a wide range of linguistic characteristics, but it tends to lose this information when trained on specific downstream tasks. We also find that BERT's capacity to encode different kind of linguistic properties has a positive influence on its predictions: the more it stores readable linguistic information, the higher will be its capacity of predicting the correct label.
Few-Shot Graph Learning for Molecular Property Prediction
Feb 16, 2021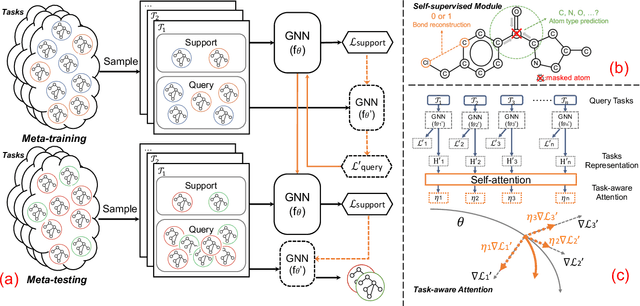
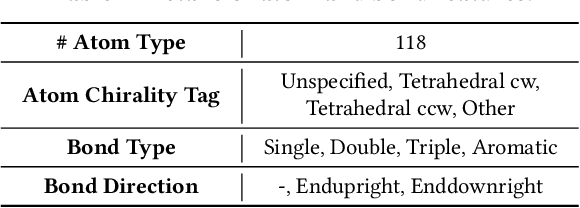
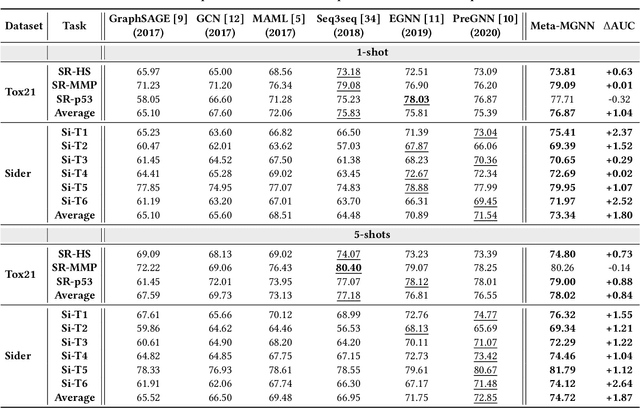
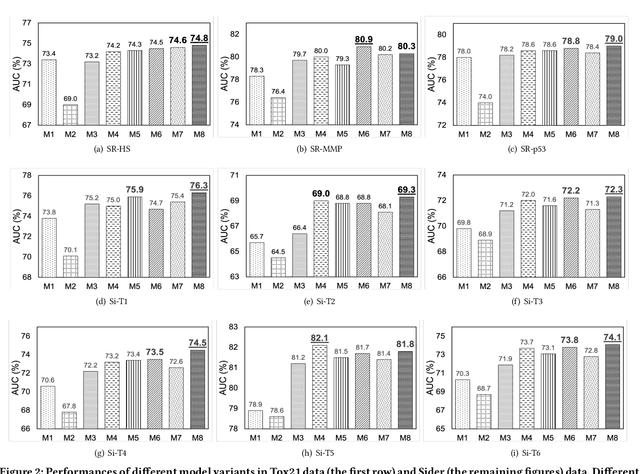
The recent success of graph neural networks has significantly boosted molecular property prediction, advancing activities such as drug discovery. The existing deep neural network methods usually require large training dataset for each property, impairing their performances in cases (especially for new molecular properties) with a limited amount of experimental data, which are common in real situations. To this end, we propose Meta-MGNN, a novel model for few-shot molecular property prediction. Meta-MGNN applies molecular graph neural network to learn molecular representation and builds a meta-learning framework for model optimization. To exploit unlabeled molecular information and address task heterogeneity of different molecular properties, Meta-MGNN further incorporates molecular structure, attribute based self-supervised modules and self-attentive task weights into the former framework, strengthening the whole learning model. Extensive experiments on two public multi-property datasets demonstrate that Meta-MGNN outperforms a variety of state-of-the-art methods.
The impact of using biased performance metrics on software defect prediction research
Mar 18, 2021
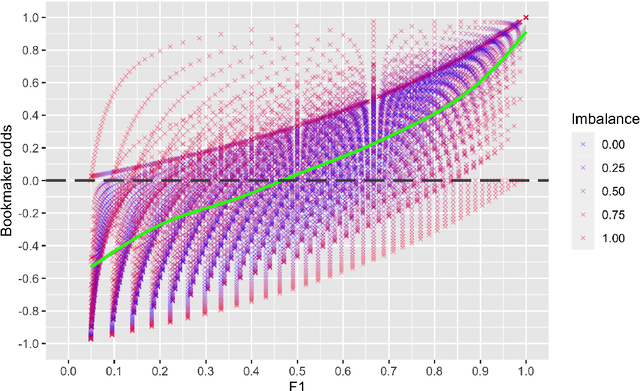
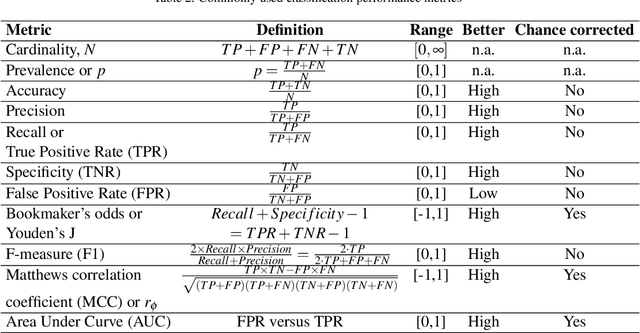
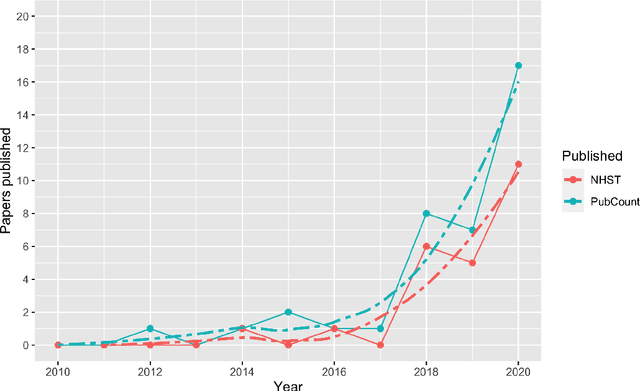
Context: Software engineering researchers have undertaken many experiments investigating the potential of software defect prediction algorithms. Unfortunately, some widely used performance metrics are known to be problematic, most notably F1, but nevertheless F1 is widely used. Objective: To investigate the potential impact of using F1 on the validity of this large body of research. Method: We undertook a systematic review to locate relevant experiments and then extract all pairwise comparisons of defect prediction performance using F1 and the un-biased Matthews correlation coefficient (MCC). Results: We found a total of 38 primary studies. These contain 12,471 pairs of results. Of these, 21.95% changed direction when the MCC metric is used instead of the biased F1 metric. Unfortunately, we also found evidence suggesting that F1 remains widely used in software defect prediction research. Conclusions: We reiterate the concerns of statisticians that the F1 is a problematic metric outside of an information retrieval context, since we are concerned about both classes (defect-prone and not defect-prone units). This inappropriate usage has led to a substantial number (more than one fifth) of erroneous (in terms of direction) results. Therefore we urge researchers to (i) use an unbiased metric and (ii) publish detailed results including confusion matrices such that alternative analyses become possible.
Spectral Decomposition in Deep Networks for Segmentation of Dynamic Medical Images
Sep 30, 2020
Dynamic contrast-enhanced magnetic resonance imaging (DCE- MRI) is a widely used multi-phase technique routinely used in clinical practice. DCE and similar datasets of dynamic medical data tend to contain redundant information on the spatial and temporal components that may not be relevant for detection of the object of interest and result in unnecessarily complex computer models with long training times that may also under-perform at test time due to the abundance of noisy heterogeneous data. This work attempts to increase the training efficacy and performance of deep networks by determining redundant information in the spatial and spectral components and show that the performance of segmentation accuracy can be maintained and potentially improved. Reported experiments include the evaluation of training/testing efficacy on a heterogeneous dataset composed of abdominal images of pediatric DCE patients, showing that drastic data reduction (higher than 80%) can preserve the dynamic information and performance of the segmentation model, while effectively suppressing noise and unwanted portion of the images.
On Modality Bias in the TVQA Dataset
Dec 18, 2020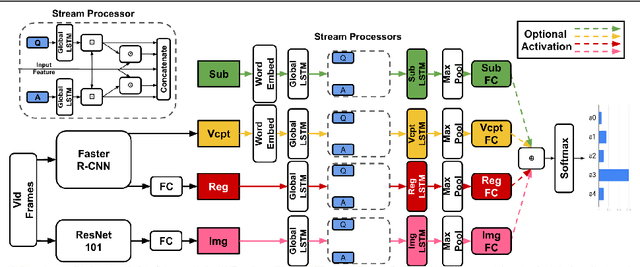
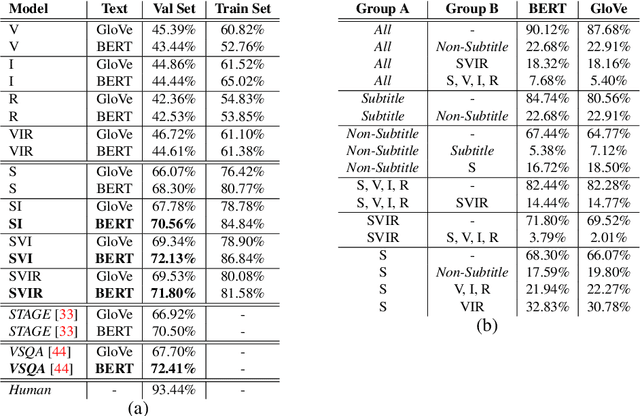
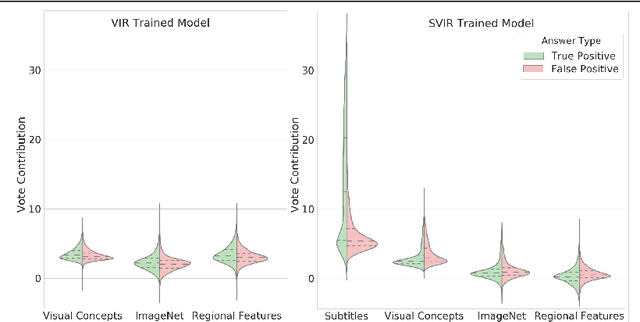

TVQA is a large scale video question answering (video-QA) dataset based on popular TV shows. The questions were specifically designed to require "both vision and language understanding to answer". In this work, we demonstrate an inherent bias in the dataset towards the textual subtitle modality. We infer said bias both directly and indirectly, notably finding that models trained with subtitles learn, on-average, to suppress video feature contribution. Our results demonstrate that models trained on only the visual information can answer ~45% of the questions, while using only the subtitles achieves ~68%. We find that a bilinear pooling based joint representation of modalities damages model performance by 9% implying a reliance on modality specific information. We also show that TVQA fails to benefit from the RUBi modality bias reduction technique popularised in VQA. By simply improving text processing using BERT embeddings with the simple model first proposed for TVQA, we achieve state-of-the-art results (72.13%) compared to the highly complex STAGE model (70.50%). We recommend a multimodal evaluation framework that can highlight biases in models and isolate visual and textual reliant subsets of data. Using this framework we propose subsets of TVQA that respond exclusively to either or both modalities in order to facilitate multimodal modelling as TVQA originally intended.