 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Knowledge-Based Hierarchical POMDPs for Task Planning
Mar 19, 2021
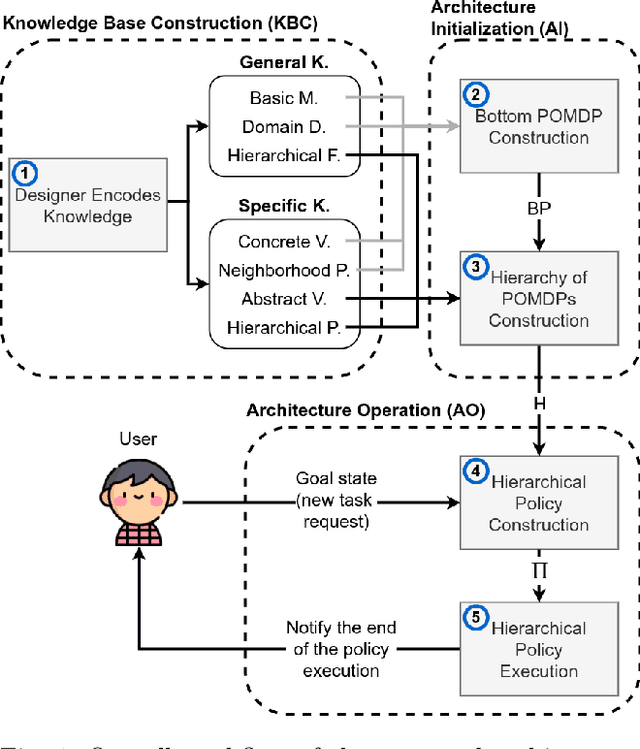

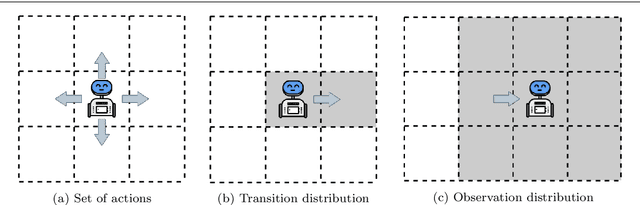
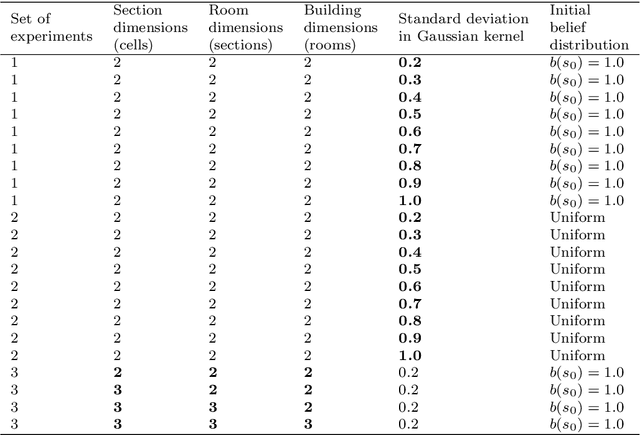
The main goal in task planning is to build a sequence of actions that takes an agent from an initial state to a goal state. In robotics, this is particularly difficult because actions usually have several possible results, and sensors are prone to produce measurements with error. Partially observable Markov decision processes (POMDPs) are commonly employed, thanks to their capacity to model the uncertainty of actions that modify and monitor the state of a system. However, since solving a POMDP is computationally expensive, their usage becomes prohibitive for most robotic applications. In this paper, we propose a task planning architecture for service robotics. In the context of service robot design, we present a scheme to encode knowledge about the robot and its environment, that promotes the modularity and reuse of information. Also, we introduce a new recursive definition of a POMDP that enables our architecture to autonomously build a hierarchy of POMDPs, so that it can be used to generate and execute plans that solve the task at hand. Experimental results show that, in comparison to baseline methods, by following a recursive hierarchical approach the architecture is able to significantly reduce the planning time, while maintaining (or even improving) the robustness under several scenarios that vary in uncertainty and size.
Differentially Private Quantiles
Feb 16, 2021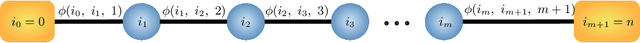

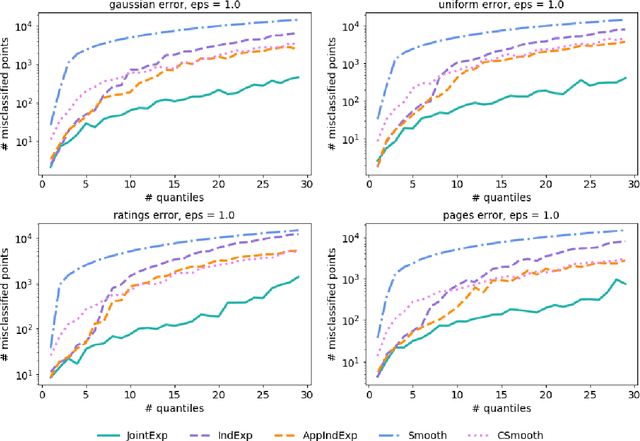
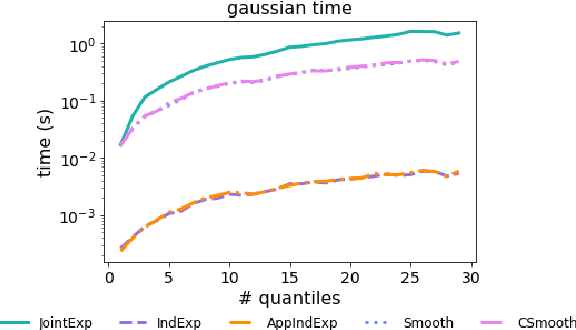
Quantiles are often used for summarizing and understanding data. If that data is sensitive, it may be necessary to compute quantiles in a way that is differentially private, providing theoretical guarantees that the result does not reveal private information. However, in the common case where multiple quantiles are needed, existing differentially private algorithms scale poorly: they compute each quantile individually, splitting their privacy budget and thus decreasing accuracy. In this work we propose an instance of the exponential mechanism that simultaneously estimates $m$ quantiles from $n$ data points while guaranteeing differential privacy. The utility function is carefully structured to allow for an efficient implementation that avoids exponential dependence on $m$ and returns estimates of all $m$ quantiles in time $O(mn^2 + m^2n)$. Experiments show that our method significantly outperforms the current state of the art on both real and synthetic data while remaining efficient enough to be practical.
DDR-Net: Learning Multi-Stage Multi-View Stereo With Dynamic Depth Range
Mar 26, 2021
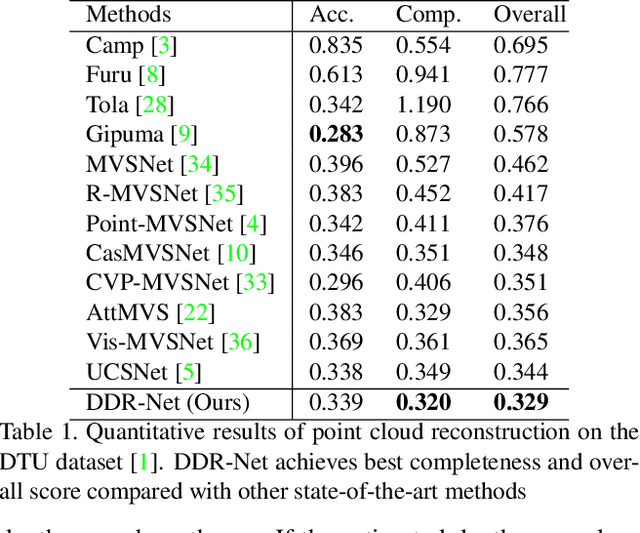
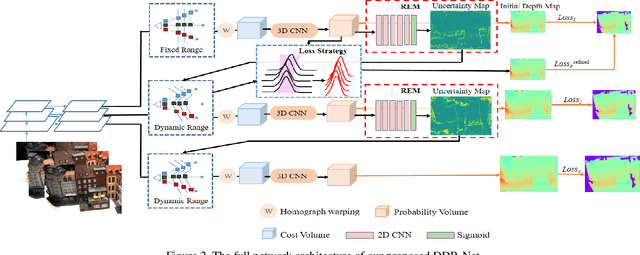

To obtain high-resolution depth maps, some previous learning-based multi-view stereo methods build a cost volume pyramid in a coarse-to-fine manner. These approaches leverage fixed depth range hypotheses to construct cascaded plane sweep volumes. However, it is inappropriate to set identical range hypotheses for each pixel since the uncertainties of previous per-pixel depth predictions are spatially varying. Distinct from these approaches, we propose a Dynamic Depth Range Network (DDR-Net) to determine the depth range hypotheses dynamically by applying a range estimation module (REM) to learn the uncertainties of range hypotheses in the former stages. Specifically, in our DDR-Net, we first build an initial depth map at the coarsest resolution of an image across the entire depth range. Then the range estimation module (REM) leverages the probability distribution information of the initial depth to estimate the depth range hypotheses dynamically for the following stages. Moreover, we develop a novel loss strategy, which utilizes learned dynamic depth ranges to generate refined depth maps, to keep the ground truth value of each pixel covered in the range hypotheses of the next stage. Extensive experimental results show that our method achieves superior performance over other state-of-the-art methods on the DTU benchmark and obtains comparable results on the Tanks and Temples benchmark. The code is available at https://github.com/Tangshengku/DDR-Net.
Fusion-FlowNet: Energy-Efficient Optical Flow Estimation using Sensor Fusion and Deep Fused Spiking-Analog Network Architectures
Mar 19, 2021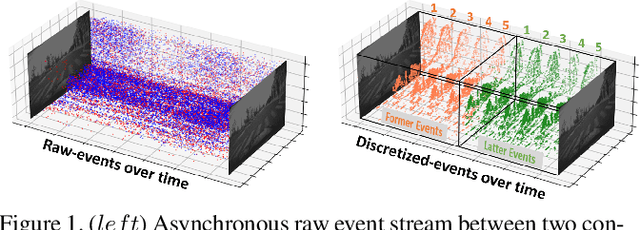
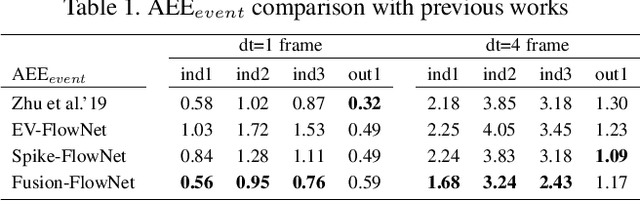
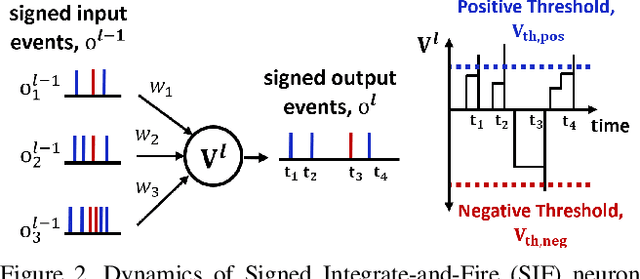
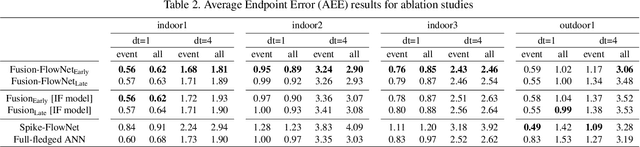
Standard frame-based cameras that sample light intensity frames are heavily impacted by motion blur for high-speed motion and fail to perceive scene accurately when the dynamic range is high. Event-based cameras, on the other hand, overcome these limitations by asynchronously detecting the variation in individual pixel intensities. However, event cameras only provide information about pixels in motion, leading to sparse data. Hence, estimating the overall dense behavior of pixels is difficult. To address such issues associated with the sensors, we present Fusion-FlowNet, a sensor fusion framework for energy-efficient optical flow estimation using both frame- and event-based sensors, leveraging their complementary characteristics. Our proposed network architecture is also a fusion of Spiking Neural Networks (SNNs) and Analog Neural Networks (ANNs) where each network is designed to simultaneously process asynchronous event streams and regular frame-based images, respectively. Our network is end-to-end trained using unsupervised learning to avoid expensive video annotations. The method generalizes well across distinct environments (rapid motion and challenging lighting conditions) and demonstrates state-of-the-art optical flow prediction on the Multi-Vehicle Stereo Event Camera (MVSEC) dataset. Furthermore, our network offers substantial savings in terms of the number of network parameters and computational energy cost.
Mixing-AdaSIN: Constructing a de-biased dataset using Adaptive Structural Instance Normalization and texture Mixing
Mar 26, 2021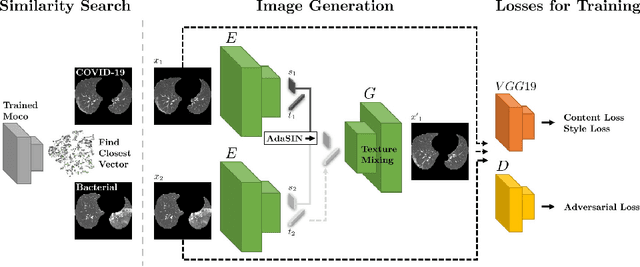
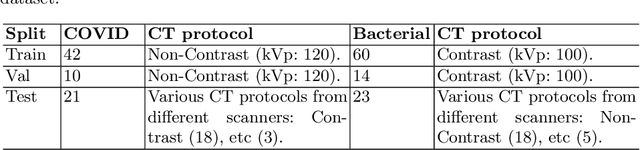
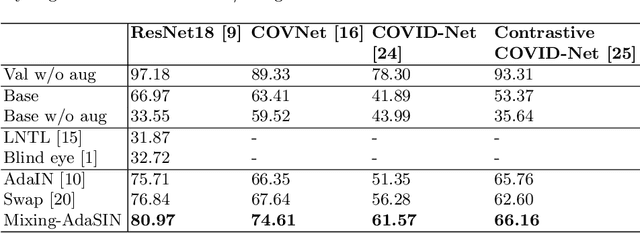
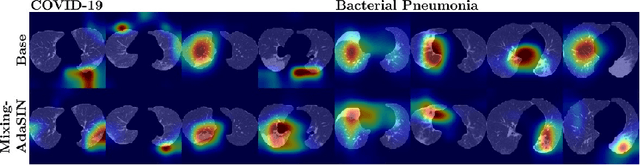
Following the pandemic outbreak, several works have proposed to diagnose COVID-19 with deep learning in computed tomography (CT); reporting performance on-par with experts. However, models trained/tested on the same in-distribution data may rely on the inherent data biases for successful prediction, failing to generalize on out-of-distribution samples or CT with different scanning protocols. Early attempts have partly addressed bias-mitigation and generalization through augmentation or re-sampling, but are still limited by collection costs and the difficulty of quantifying bias in medical images. In this work, we propose Mixing-AdaSIN; a bias mitigation method that uses a generative model to generate de-biased images by mixing texture information between different labeled CT scans with semantically similar features. Here, we use Adaptive Structural Instance Normalization (AdaSIN) to enhance de-biasing generation quality and guarantee structural consistency. Following, a classifier trained with the generated images learns to correctly predict the label without bias and generalizes better. To demonstrate the efficacy of our method, we construct a biased COVID-19 vs. bacterial pneumonia dataset based on CT protocols and compare with existing state-of-the-art de-biasing methods. Our experiments show that classifiers trained with de-biased generated images report improved in-distribution performance and generalization on an external COVID-19 dataset.
CNN AE: Convolution Neural Network combined with Autoencoder approach to detect survival chance of COVID 19 patients
Apr 18, 2021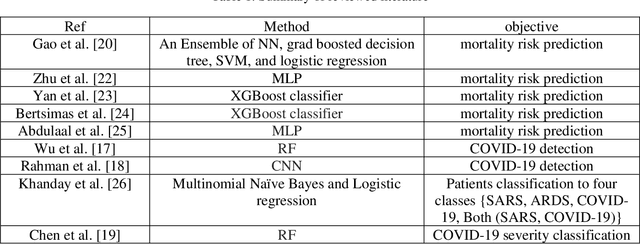
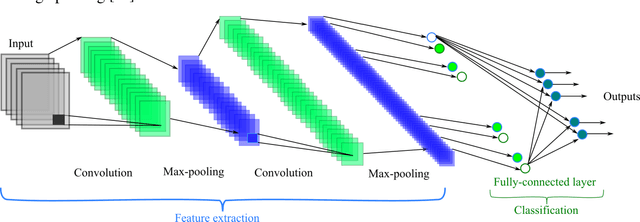
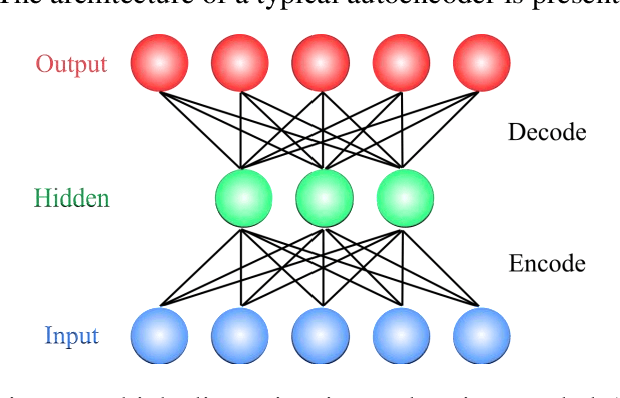
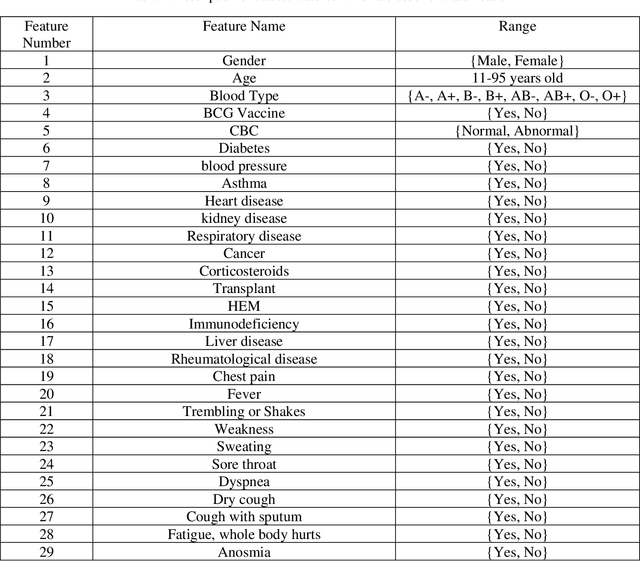
In this paper, we propose a novel method named CNN-AE to predict survival chance of COVID-19 patients using a CNN trained on clinical information. To further increase the prediction accuracy, we use the CNN in combination with an autoencoder. Our method is one of the first that aims to predict survival chance of already infected patients. We rely on clinical data to carry out the prediction. The motivation is that the required resources to prepare CT images are expensive and limited compared to the resources required to collect clinical data such as blood pressure, liver disease, etc. We evaluate our method on a publicly available clinical dataset of deceased and recovered patients which we have collected. Careful analysis of the dataset properties is also presented which consists of important features extraction and correlation computation between features. Since most of COVID-19 patients are usually recovered, the number of deceased samples of our dataset is low leading to data imbalance. To remedy this issue, a data augmentation procedure based on autoencoders is proposed. To demonstrate the generality of our augmentation method, we train random forest and Na\"ive Bayes on our dataset with and without augmentation and compare their performance. We also evaluate our method on another dataset for further generality verification. Experimental results reveal the superiority of CNN-AE method compared to the standard CNN as well as other methods such as random forest and Na\"ive Bayes. COVID-19 detection average accuracy of CNN-AE is 96.05% which is higher than CNN average accuracy of 92.49%. To show that clinical data can be used as a reliable dataset for COVID-19 survival chance prediction, CNN-AE is compared with a standard CNN which is trained on CT images.
Residual Recurrent CRNN for End-to-End Optical Music Recognition on Monophonic Scores
Oct 26, 2020
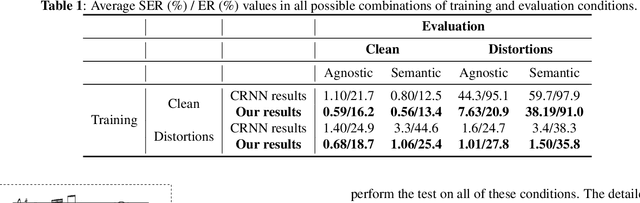

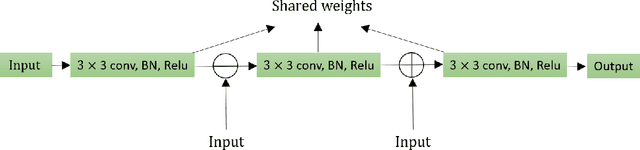
Optical Music Recognition is a field that attempts to extract digital information from images of either the printed music scores or the handwritten music scores. One of the challenges of the Optical Music Recognition task is to transcript the symbols of the camera-captured images into digital music notations. Previous end-to-end model, based on deep learning, was developed as a Convolutional Recurrent Neural Network. However, it does not explore sufficient contextual information from full scales and there is still a large room for improvement. In this paper, we propose an innovative end-to-end framework that combines a block of Residual Recurrent Convolutional Neural Network with a recurrent Encoder-Decoder network to map a sequence of monophonic music symbols corresponding to the notations present in the image. The Residual Recurrent Convolutional block can improve the ability of the model to enrich the context information while the number of parameter will not be increasing. The experiment results were benchmarked against a publicly available dataset called CAMERA-PRIMUS. We evaluate the performances of our model on both the images with ideal conditions and that with non-ideal conditions. The experiments show that our approach surpass the state-of-the-art end-to-end method using Convolutional Recurrent Neural Network.
Improving Few-Shot Learning with Auxiliary Self-Supervised Pretext Tasks
Jan 24, 2021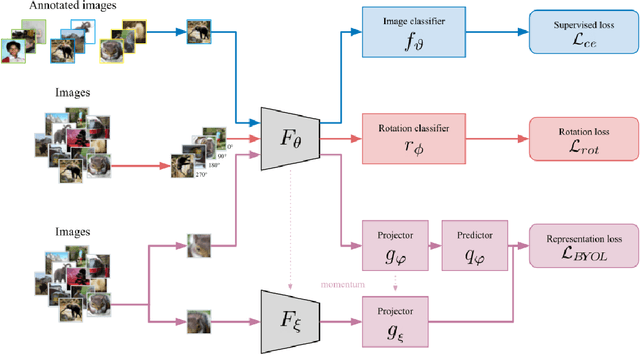
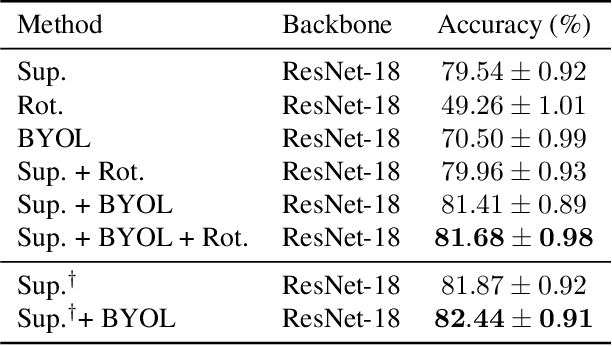
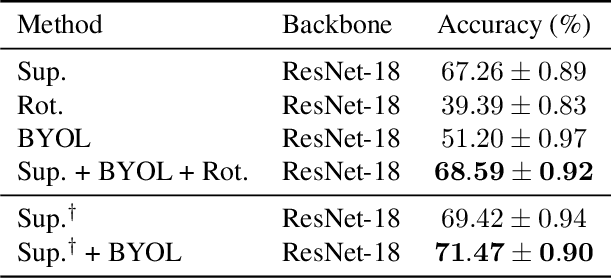
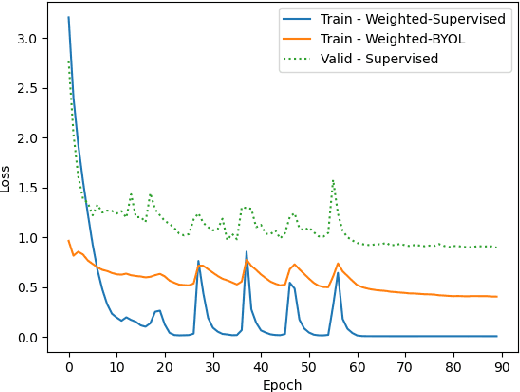
Recent work on few-shot learning \cite{tian2020rethinking} showed that quality of learned representations plays an important role in few-shot classification performance. On the other hand, the goal of self-supervised learning is to recover useful semantic information of the data without the use of class labels. In this work, we exploit the complementarity of both paradigms via a multi-task framework where we leverage recent self-supervised methods as auxiliary tasks. We found that combining multiple tasks is often beneficial, and that solving them simultaneously can be done efficiently. Our results suggest that self-supervised auxiliary tasks are effective data-dependent regularizers for representation learning. Our code is available at: \url{https://github.com/nathanielsimard/improving-fs-ssl}.
Channel Leakage and Fundamental Limits of Privacy Leakage for Streaming Data
Aug 25, 2020In this paper, we first introduce the notion of channel leakage as the minimum mutual information between the channel input and channel output. As its name indicates, channel leakage quantifies the (minimum) information leakage to the malicious receiver. In a broad sense, it can be viewed as a dual concept of channel capacity, which characterizes the (maximum) information transmission to the targeted receiver. We obtain explicit formulas of channel leakage for the white Gaussian case and colored Gaussian case. We also study the implications of channel leakage in characterizing the fundamental limitations of privacy leakage for streaming data.
Deep encoding of etymological information in TEI
Nov 30, 2016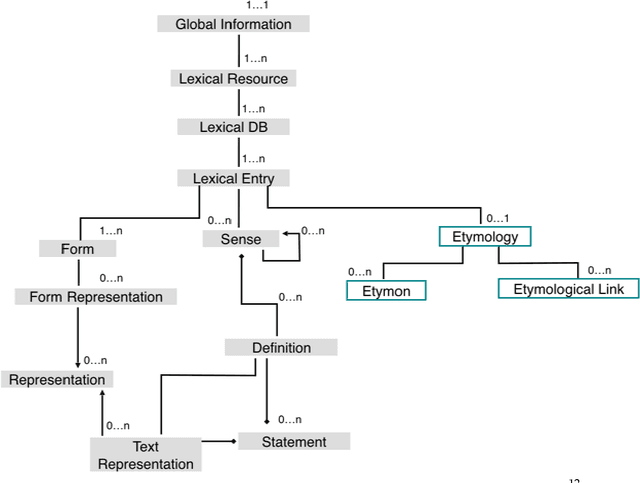
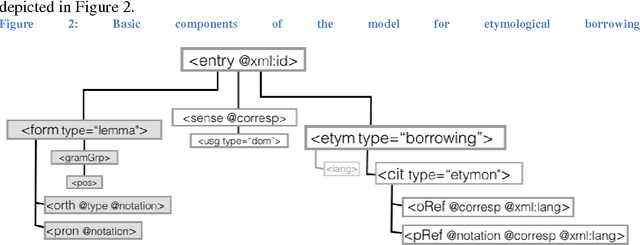
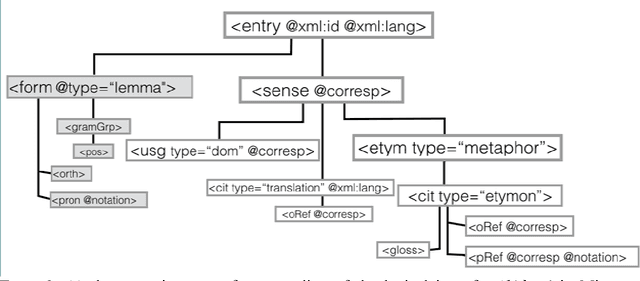
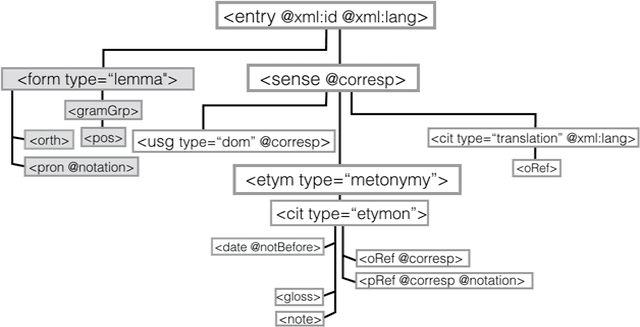
This paper aims to provide a comprehensive modeling and representation of etymological data in digital dictionaries. The purpose is to integrate in one coherent framework both digital representations of legacy dictionaries, and also born-digital lexical databases that are constructed manually or semi-automatically. We want to propose a systematic and coherent set of modeling principles for a variety of etymological phenomena that may contribute to the creation of a continuum between existing and future lexical constructs, where anyone interested in tracing the history of words and their meanings will be able to seamlessly query lexical resources.Instead of designing an ad hoc model and representation language for digital etymological data, we will focus on identifying all the possibilities offered by the TEI guidelines for the representation of lexical information.