 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
3D coherent x-ray imaging via deep convolutional neural networks
Feb 26, 2021
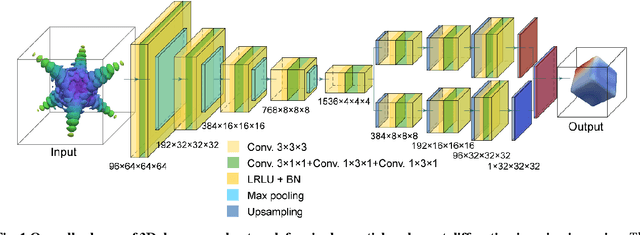
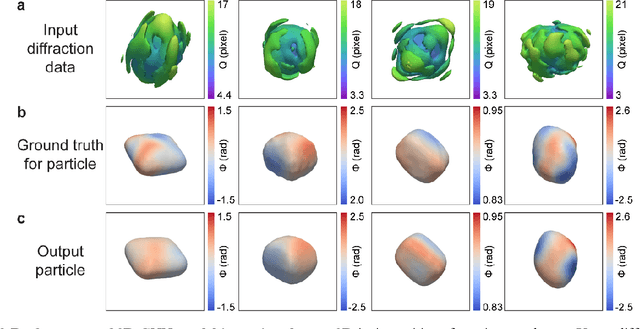
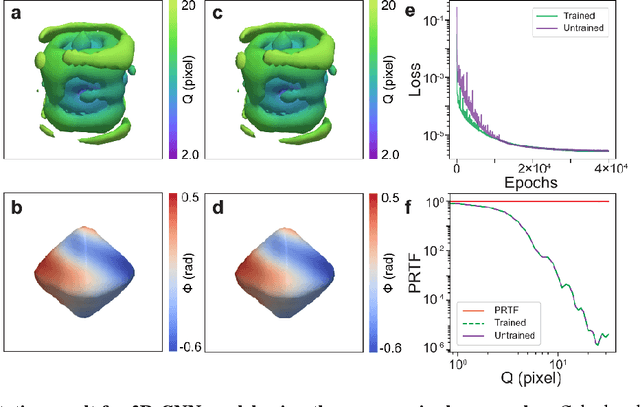
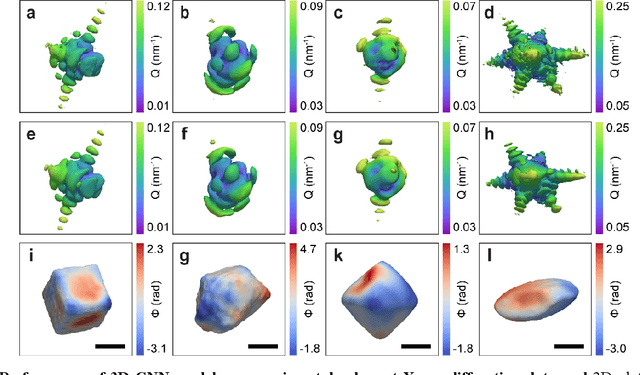
As a critical component of coherent X-ray diffraction imaging (CDI), phase retrieval has been extensively applied in X-ray structural science to recover the 3D morphological information inside measured particles. Despite meeting all the oversampling requirements of Sayre and Shannon, current phase retrieval approaches still have trouble achieving a unique inversion of experimental data in the presence of noise. Here, we propose to overcome this limitation by incorporating a 3D Machine Learning (ML) model combining (optional) supervised training with unsupervised refinement. The trained ML model can rapidly provide an immediate result with high accuracy, which will benefit real-time experiments. More significantly, the Neural Network model can be used without any prior training to learn the missing phases of an image based on minimization of an appropriate loss function alone. We demonstrate significantly improved performance with experimental Bragg CDI data over traditional iterative phase retrieval algorithms.
PURSUhInT: In Search of Informative Hint Points Based on Layer Clustering for Knowledge Distillation
Feb 26, 2021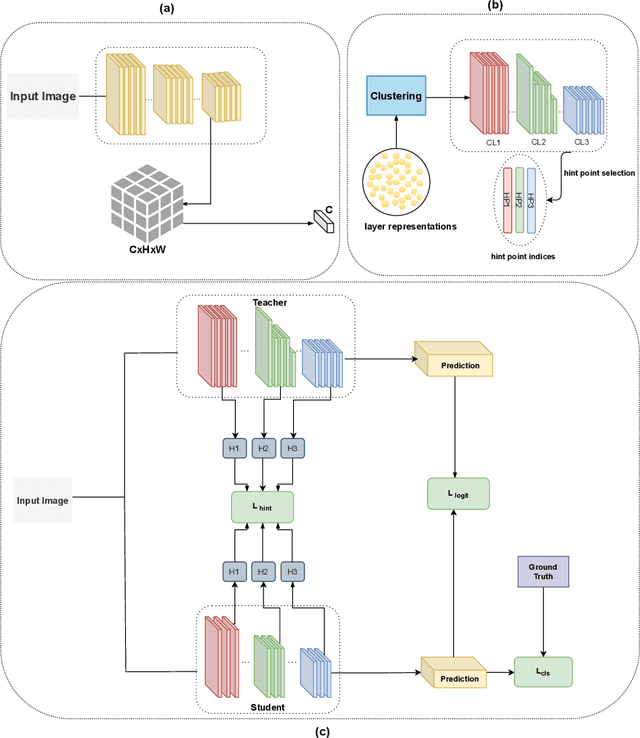
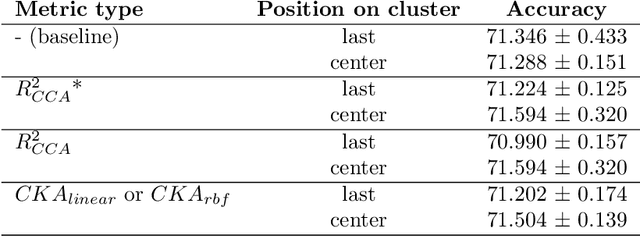
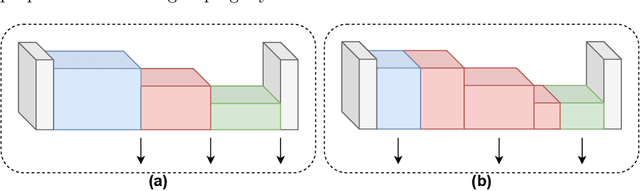
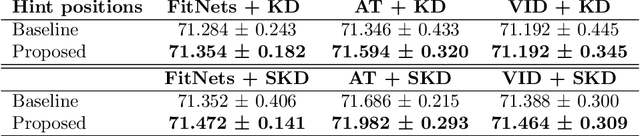
We propose a novel knowledge distillation methodology for compressing deep neural networks. One of the most efficient methods for knowledge distillation is hint distillation, where the student model is injected with information (hints) from several different layers of the teacher model. Although the selection of hint points can drastically alter the compression performance, there is no systematic approach for selecting them, other than brute-force hyper-parameter search. We propose a clustering based hint selection methodology, where the layers of teacher model are clustered with respect to several metrics and the cluster centers are used as the hint points. The proposed approach is validated in CIFAR-100 dataset, where ResNet-110 network was used as the teacher model. Our results show that hint points selected by our algorithm results in superior compression performance with respect to state-of-the-art knowledge distillation algorithms on the same student models and datasets.
Learning Defense Transformers for Counterattacking Adversarial Examples
Mar 13, 2021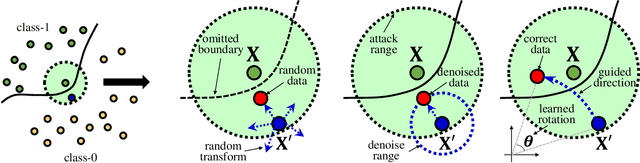
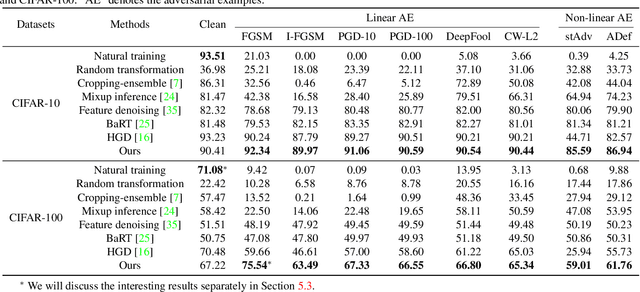
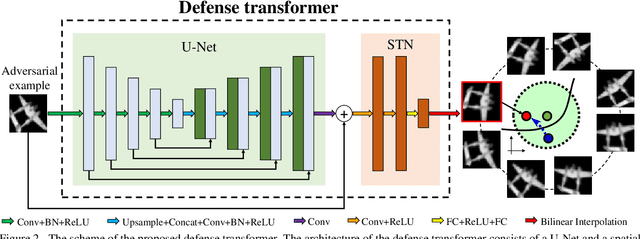
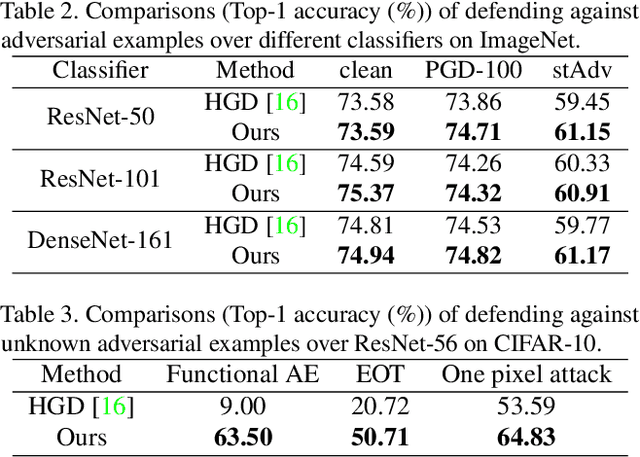
Deep neural networks (DNNs) are vulnerable to adversarial examples with small perturbations. Adversarial defense thus has been an important means which improves the robustness of DNNs by defending against adversarial examples. Existing defense methods focus on some specific types of adversarial examples and may fail to defend well in real-world applications. In practice, we may face many types of attacks where the exact type of adversarial examples in real-world applications can be even unknown. In this paper, motivated by that adversarial examples are more likely to appear near the classification boundary, we study adversarial examples from a new perspective that whether we can defend against adversarial examples by pulling them back to the original clean distribution. We theoretically and empirically verify the existence of defense affine transformations that restore adversarial examples. Relying on this, we learn a defense transformer to counterattack the adversarial examples by parameterizing the affine transformations and exploiting the boundary information of DNNs. Extensive experiments on both toy and real-world datasets demonstrate the effectiveness and generalization of our defense transformer.
Joint User Association and Power Allocation in Heterogeneous Ultra Dense Network via Semi-Supervised Representation Learning
Mar 29, 2021
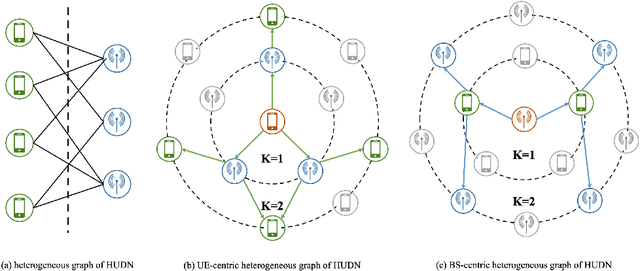
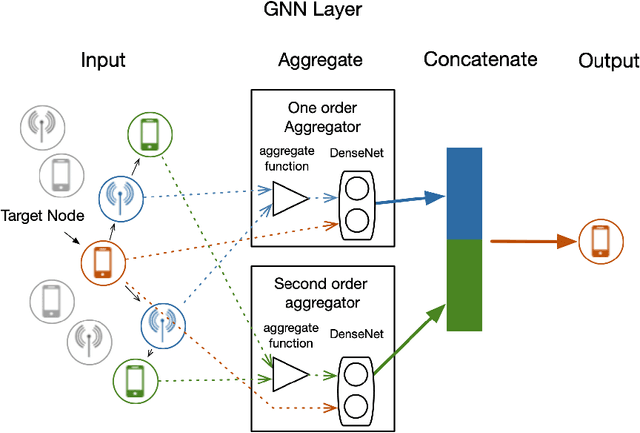
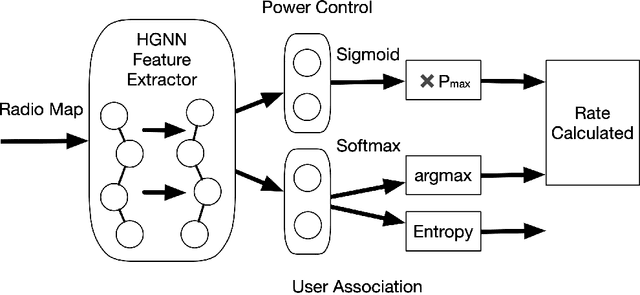
Heterogeneous Ultra-Dense Network (HUDN) is one of the vital networking architectures due to its ability to enable higher connectivity density and ultra-high data rates. Rational user association and power control schedule in HUDN can reduce wireless interference. This paper proposes a novel idea for resolving the joint user association and power control problem: the optimal user association and Base Station transmit power can be represented by channel information. Then, we solve this problem by formulating an optimal representation function. We model the HUDNs as a heterogeneous graph and train a Graph Neural Network (GNN) to approach this representation function by using semi-supervised learning, in which the loss function is composed of the unsupervised part that helps the GNN approach the optimal representation function and the supervised part that utilizes the previous experience to reduce useless exploration. We separate the learning process into two parts, the generalization-representation learning (GRL) part and the specialization-representation learning (SRL) part, which train the GNN for learning representation for generalized scenario quasi-static user distribution scenario, respectively. Simulation results demonstrate that the proposed GRL-based solution has higher computational efficiency than the traditional optimization algorithm, and the performance of SRL outperforms the GRL.
SupMMD: A Sentence Importance Model for Extractive Summarization using Maximum Mean Discrepancy
Oct 06, 2020
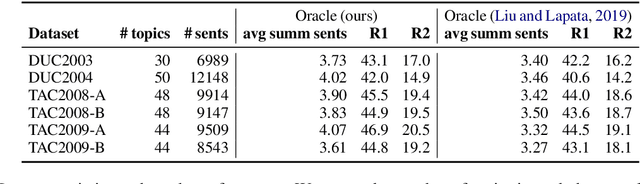
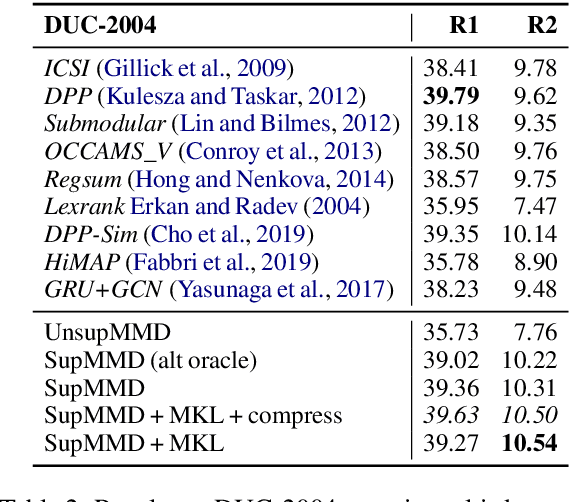

Most work on multi-document summarization has focused on generic summarization of information present in each individual document set. However, the under-explored setting of update summarization, where the goal is to identify the new information present in each set, is of equal practical interest (e.g., presenting readers with updates on an evolving news topic). In this work, we present SupMMD, a novel technique for generic and update summarization based on the maximum mean discrepancy from kernel two-sample testing. SupMMD combines both supervised learning for salience and unsupervised learning for coverage and diversity. Further, we adapt multiple kernel learning to make use of similarity across multiple information sources (e.g., text features and knowledge based concepts). We show the efficacy of SupMMD in both generic and update summarization tasks by meeting or exceeding the current state-of-the-art on the DUC-2004 and TAC-2009 datasets.
* 15 pages
Ptychography Intensity Interferometry Imaging for Dynamic Distant Object
Feb 10, 2021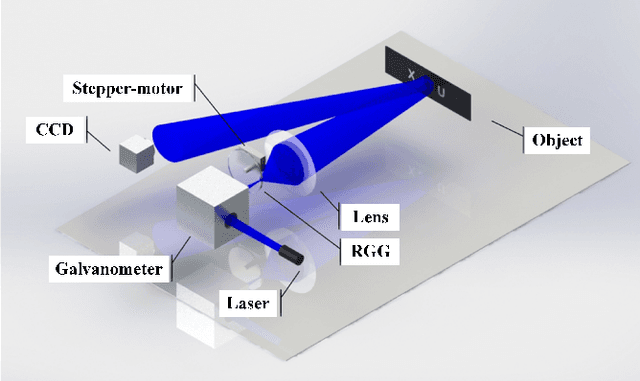



As a promising lensless imaging method for distance objects, intensity interferometry imaging (III) had been suffering from the unreliable phase retrieval process, hindering the development of III for decades. Recently, the introduction of the ptychographic detection in III overcame this challenge, and a method called ptychographic III (PIII) was proposed. We here experimentally demonstrate that PIII can image a dynamic distance object. A reasonable image for the moving object can be retrieved with only two speckle patterns for each probe, and only 10 to 20 iterations are needed. Meanwhile, PIII exhibits robust to the inaccurate information of the probe. Furthermore, PIII successfully recovers the image through a fog obfuscating the imaging light path, under which a conventional camera relying on lenses fails to provide a recognizable image.
Distributed Learning and Democratic Embeddings: Polynomial-Time Source Coding Schemes Can Achieve Minimax Lower Bounds for Distributed Gradient Descent under Communication Constraints
Mar 13, 2021
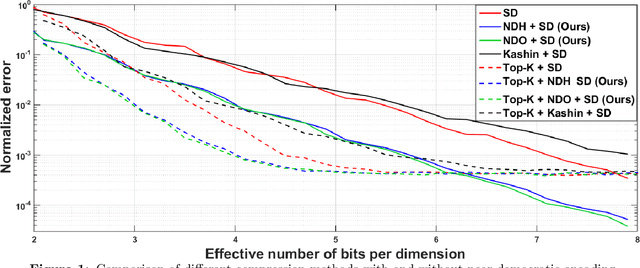
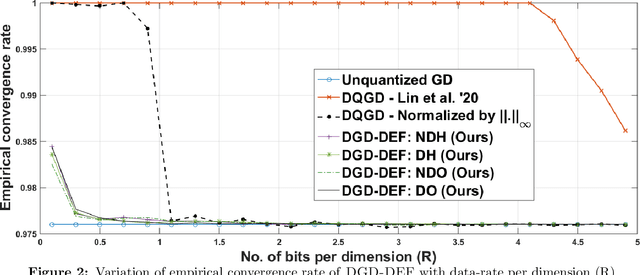
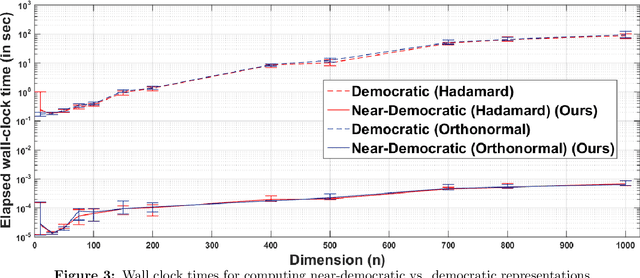
In this work, we consider the distributed optimization setting where information exchange between the computation nodes and the parameter server is subject to a maximum bit-budget. We first consider the problem of compressing a vector in the n-dimensional Euclidean space, subject to a bit-budget of R-bits per dimension, for which we introduce Democratic and Near-Democratic source-coding schemes. We show that these coding schemes are (near) optimal in the sense that the covering efficiency of the resulting quantizer is either dimension independent, or has a very weak logarithmic dependence. Subsequently, we propose a distributed optimization algorithm: DGD-DEF, which employs our proposed coding strategy, and achieves the minimax optimal convergence rate to within (near) constant factors for a class of communication-constrained distributed optimization algorithms. Furthermore, we extend the utility of our proposed source coding scheme by showing that it can remarkably improve the performance when used in conjunction with other compression schemes. We validate our theoretical claims through numerical simulations. Keywords: Fast democratic (Kashin) embeddings, Distributed optimization, Data-rate constraint, Quantized gradient descent, Error feedback.
Multi-Channel and Multi-Microphone Acoustic Echo Cancellation Using A Deep Learning Based Approach
Mar 03, 2021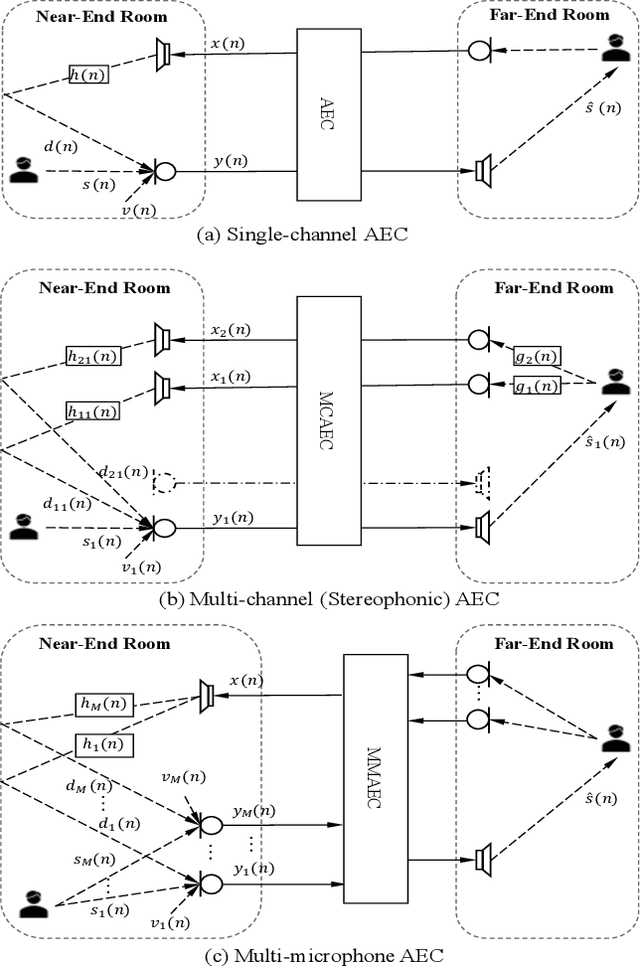
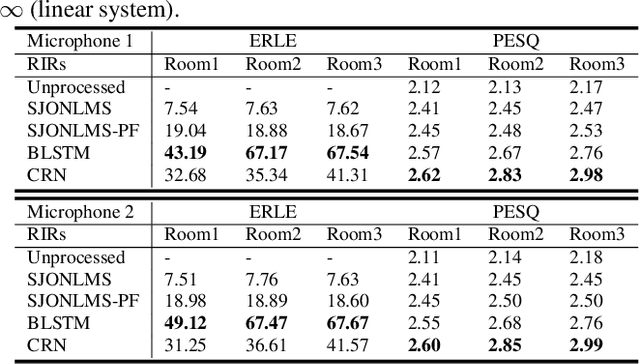
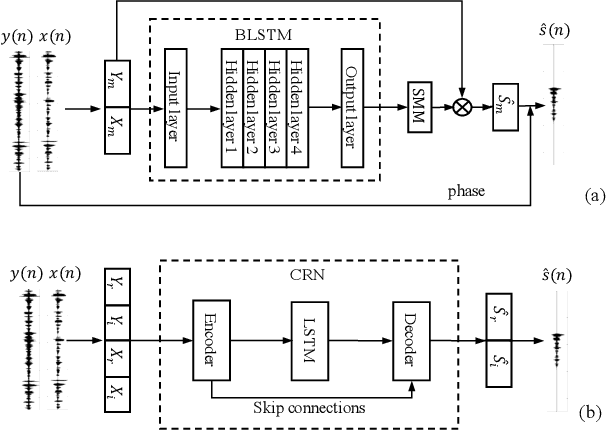
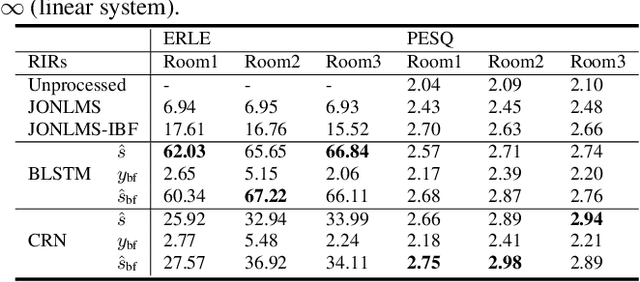
Building on the deep learning based acoustic echo cancellation (AEC) in the single-loudspeaker (single-channel) and single-microphone setup, this paper investigates multi-channel AEC (MCAEC) and multi-microphone AEC (MMAEC). We train a deep neural network (DNN) to predict the near-end speech from microphone signals with far-end signals used as additional information. We find that the deep learning approach avoids the non-uniqueness problem in traditional MCAEC algorithms. For the AEC setup with multiple microphones, rather than employing AEC for each microphone, a single DNN is trained to achieve echo removal for all microphones. Also, combining deep learning based AEC with deep learning based beamforming further improves the system performance. Experimental results show the effectiveness of both bidirectional long short-term memory (BLSTM) and convolutional recurrent network (CRN) based methods for MCAEC and MMAEC. Furthermore, deep learning based methods are capable of removing echo and noise simultaneously and work well in the presence of nonlinear distortions.
De-STT: De-entaglement of unwanted Nuisances and Biases in Speech to Text System using Adversarial Forgetting
Dec 01, 2020

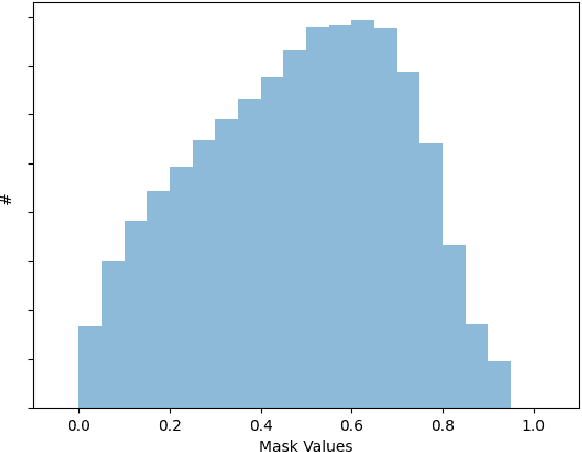
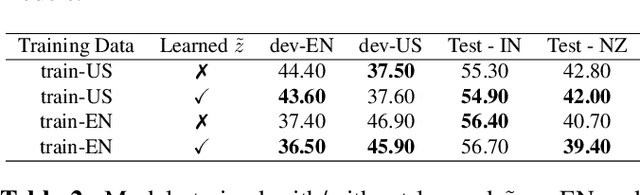
Training robust Speech to Text (STT) system require "tens of thousand" of hours of data. Variability present in the dataset, in the form of unwanted nuisances (noise) and biases (accent, gender or age) is the reason for the need of large datasets to learn general representations, which is unfeasible for low resource languages. A recently proposed deep learning approach to remove these unwanted features, called adversarial forgetting, was able to produce better results on computer vision tasks. Motivated by this, in this paper, we study the effect of de-entangling the accent information from the input speech signal on training STT systems. To this end, we use an information bottleneck architecture based on adversarial forgetting. This training scheme aims to enforce the model to learn general accent invariant speech representations. The trained STT model is tested on two unseen accents in the common voice V1. The results are in favour of STT model trained using the adversarial forgetting scheme.
Extracting a Knowledge Base of Mechanisms from COVID-19 Papers
Oct 08, 2020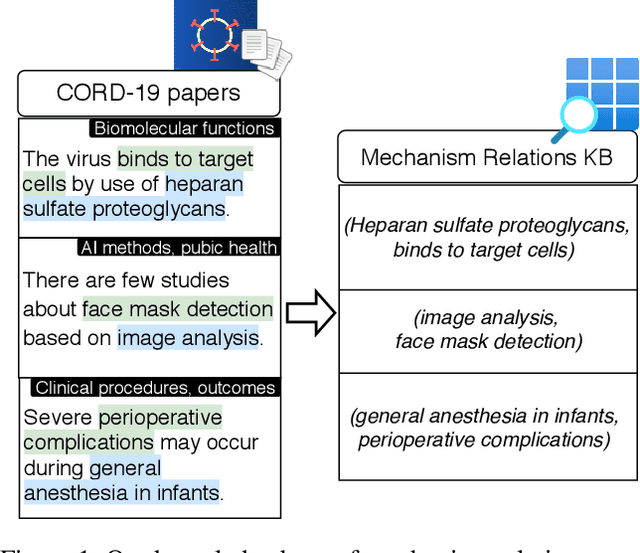
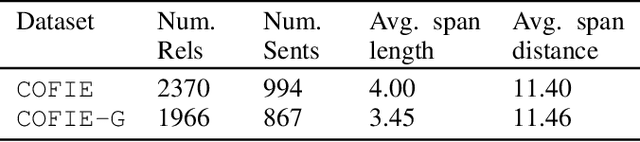

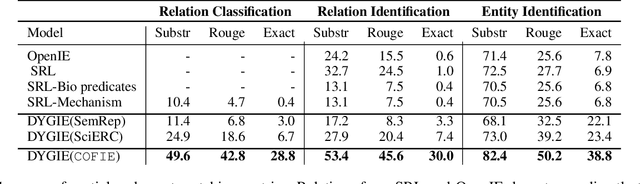
The urgency of mitigating COVID-19 has spawned a large and diverse body of scientific literature that is challenging for researchers to navigate. This explosion of information has stimulated interest in automated tools to help identify useful knowledge. We have pursued the use of methods for extracting diverse forms of mechanism relations from the natural language of scientific papers. We seek to identify concepts in COVID-19 and related literature which represent activities, functions, associations and causal relations, ranging from cellular processes to economic impacts. We formulate a broad, coarse-grained schema targeting mechanism relations between open, free-form entities. Our approach strikes a balance between expressivity and breadth that supports generalization across diverse concepts. We curate a dataset of scientific papers annotated according to our novel schema. Using an information extraction model trained on this new corpus, we construct a knowledge base (KB) of 2M mechanism relations, which we make publicly available. Our model is able to extract relations at an F1 at least twice that of baselines such as open IE or related scientific IE systems. We conduct experiments examining the ability of our system to retrieve relevant information on viral mechanisms of action, and on applications of AI to COVID-19 research. In both cases, our system identifies relevant information from our automatically-constructed knowledge base with high precision.