 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Perceptions of Diversity in Electronic Music: the Impact of Listener, Artist, and Track Characteristics
Jan 28, 2021
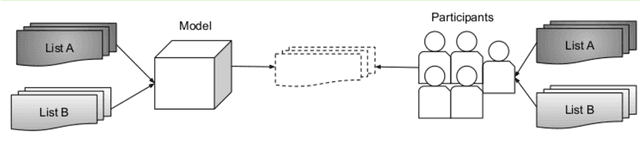
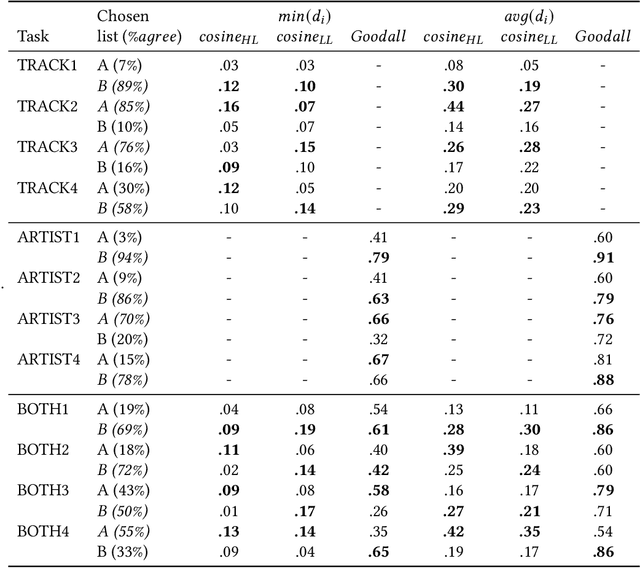
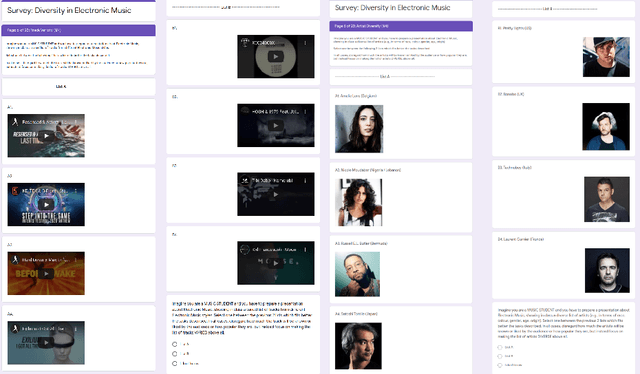
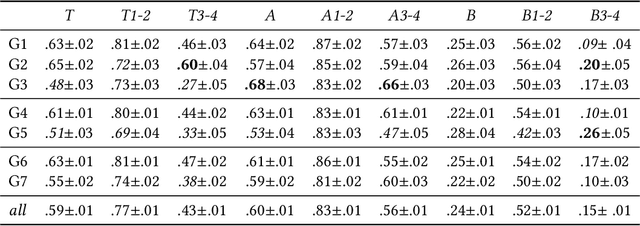
Shared practices to assess the diversity of retrieval system results are still debated in the Information Retrieval community, partly because of the challenges of determining what diversity means in specific scenarios, and of understanding how diversity is perceived by end-users. The field of Music Information Retrieval is not exempt from this issue. Even if fields such as Musicology or Sociology of Music have a long tradition in questioning the representation and the impact of diversity in cultural environments, such knowledge has not been yet embedded into the design and development of music technologies. In this paper, focusing on electronic music, we investigate the characteristics of listeners, artists, and tracks that are influential in the perception of diversity. Specifically, we center our attention on 1) understanding the relationship between perceived diversity and computational methods to measure diversity, and 2) analyzing how listeners' domain knowledge and familiarity influence such perceived diversity. To accomplish this, we design a user-study in which listeners are asked to compare pairs of lists of tracks and artists, and to select the most diverse list from each pair. We compare participants' ratings with results obtained through computational models built using audio tracks' features and artist attributes. We find that such models are generally aligned with participants' choices when most of them agree that one list is more diverse than the other, while they present a mixed behaviour in cases where participants have little agreement. Moreover, we observe how differences in domain knowledge, familiarity, and demographics can influence the level of agreement among listeners, and between listeners and diversity metrics computed automatically.
A Learnable Self-supervised Task for Unsupervised Domain Adaptation on Point Clouds
Apr 12, 2021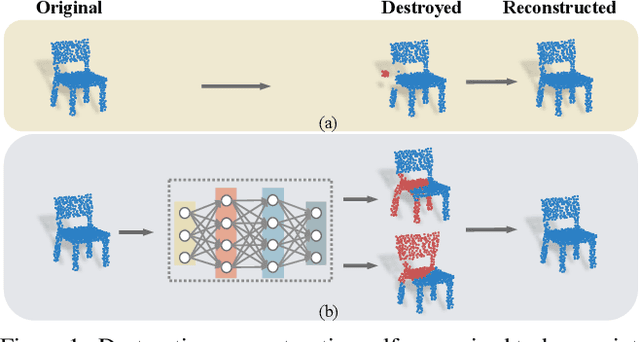
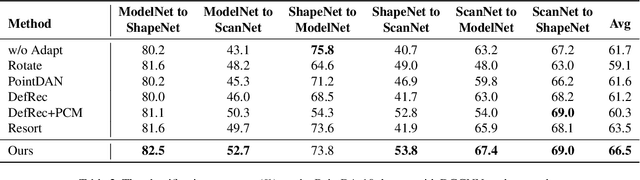
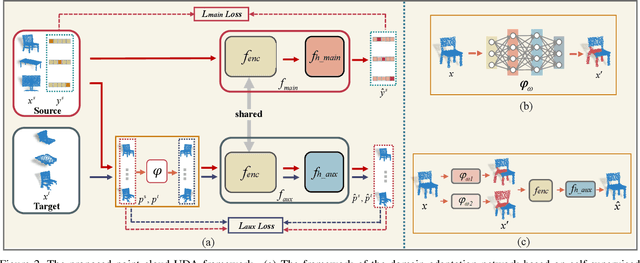
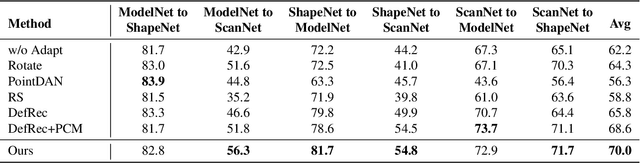
Deep neural networks have achieved promising performance in supervised point cloud applications, but manual annotation is extremely expensive and time-consuming in supervised learning schemes. Unsupervised domain adaptation (UDA) addresses this problem by training a model with only labeled data in the source domain but making the model generalize well in the target domain. Existing studies show that self-supervised learning using both source and target domain data can help improve the adaptability of trained models, but they all rely on hand-crafted designs of the self-supervised tasks. In this paper, we propose a learnable self-supervised task and integrate it into a self-supervision-based point cloud UDA architecture. Specifically, we propose a learnable nonlinear transformation that transforms a part of a point cloud to generate abundant and complicated point clouds while retaining the original semantic information, and the proposed self-supervised task is to reconstruct the original point cloud from the transformed ones. In the UDA architecture, an encoder is shared between the networks for the self-supervised task and the main task of point cloud classification or segmentation, so that the encoder can be trained to extract features suitable for both the source and the target domain data. Experiments on PointDA-10 and PointSegDA datasets show that the proposed method achieves new state-of-the-art performance on both classification and segmentation tasks of point cloud UDA. Code will be made publicly available.
Transformer Tracking
Mar 29, 2021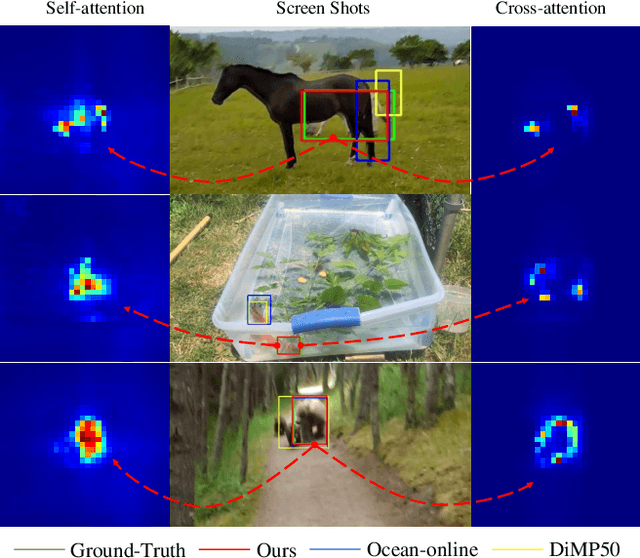
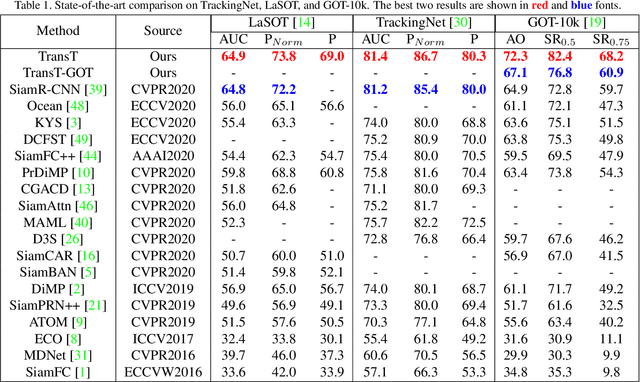
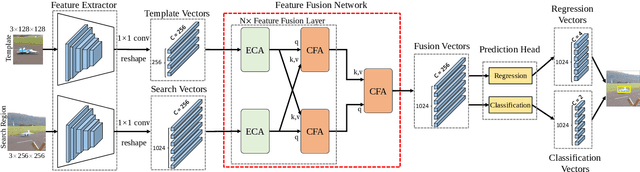
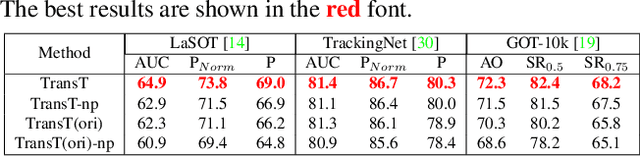
Correlation acts as a critical role in the tracking field, especially in recent popular Siamese-based trackers. The correlation operation is a simple fusion manner to consider the similarity between the template and the search region. However, the correlation operation itself is a local linear matching process, leading to lose semantic information and fall into local optimum easily, which may be the bottleneck of designing high-accuracy tracking algorithms. Is there any better feature fusion method than correlation? To address this issue, inspired by Transformer, this work presents a novel attention-based feature fusion network, which effectively combines the template and search region features solely using attention. Specifically, the proposed method includes an ego-context augment module based on self-attention and a cross-feature augment module based on cross-attention. Finally, we present a Transformer tracking (named TransT) method based on the Siamese-like feature extraction backbone, the designed attention-based fusion mechanism, and the classification and regression head. Experiments show that our TransT achieves very promising results on six challenging datasets, especially on large-scale LaSOT, TrackingNet, and GOT-10k benchmarks. Our tracker runs at approximatively 50 fps on GPU. Code and models are available at https://github.com/chenxin-dlut/TransT.
Comparison of Possibilistic Fuzzy Local Information C-Means and Possibilistic K-Nearest Neighbors for Synthetic Aperture Sonar Image Segmentation
Apr 01, 2019Synthetic aperture sonar (SAS) imagery can generate high resolution images of the seafloor. Thus, segmentation algorithms can be used to partition the images into different seafloor environments. In this paper, we compare two possibilistic segmentation approaches. Possibilistic approaches allow for the ability to detect novel or outlier environments as well as well known classes. The Possibilistic Fuzzy Local Information C-Means (PFLICM) algorithm has been previously applied to segment SAS imagery. Additionally, the Possibilistic K-Nearest Neighbors (PKNN) algorithm has been used in other domains such as landmine detection and hyperspectral imagery. In this paper, we compare the segmentation performance of a semi-supervised approach using PFLICM and a supervised method using Possibilistic K-NN. We include final segmentation results on multiple SAS images and a quantitative assessment of each algorithm.
Deepened Graph Auto-Encoders Help Stabilize and Enhance Link Prediction
Mar 21, 2021
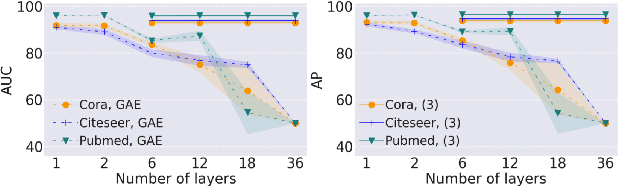
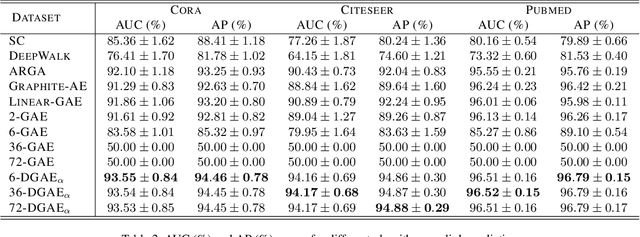
Graph neural networks have been used for a variety of learning tasks, such as link prediction, node classification, and node clustering. Among them, link prediction is a relatively under-studied graph learning task, with current state-of-the-art models based on one- or two-layer of shallow graph auto-encoder (GAE) architectures. In this paper, we focus on addressing a limitation of current methods for link prediction, which can only use shallow GAEs and variational GAEs, and creating effective methods to deepen (variational) GAE architectures to achieve stable and competitive performance. Our proposed methods innovatively incorporate standard auto-encoders (AEs) into the architectures of GAEs, where standard AEs are leveraged to learn essential, low-dimensional representations via seamlessly integrating the adjacency information and node features, while GAEs further build multi-scaled low-dimensional representations via residual connections to learn a compact overall embedding for link prediction. Empirically, extensive experiments on various benchmarking datasets verify the effectiveness of our methods and demonstrate the competitive performance of our deepened graph models for link prediction. Theoretically, we prove that our deep extensions inclusively express multiple polynomial filters with different orders.
Heterogeneous Federated Learning
Aug 15, 2020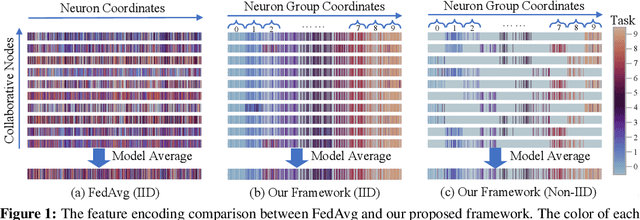
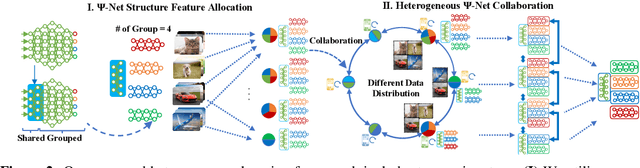
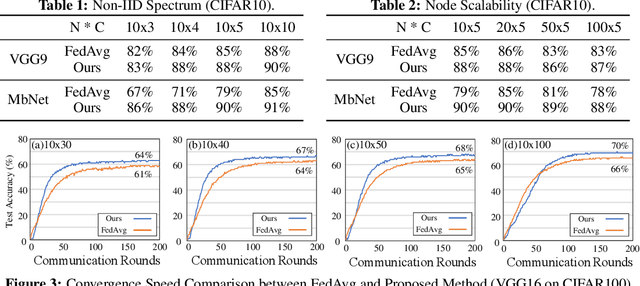
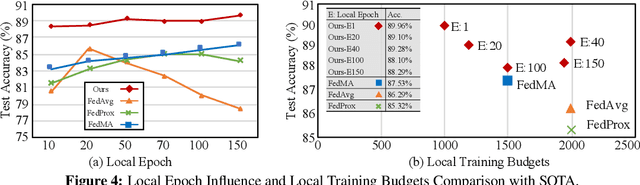
Federated learning learns from scattered data by fusing collaborative models from local nodes. However, due to chaotic information distribution, the model fusion may suffer from structural misalignment with regard to unmatched parameters. In this work, we propose a novel federated learning framework to resolve this issue by establishing a firm structure-information alignment across collaborative models. Specifically, we design a feature-oriented regulation method ({$\Psi$-Net}) to ensure explicit feature information allocation in different neural network structures. Applying this regulating method to collaborative models, matchable structures with similar feature information can be initialized at the very early training stage. During the federated learning process under either IID or non-IID scenarios, dedicated collaboration schemes further guarantee ordered information distribution with definite structure matching, so as the comprehensive model alignment. Eventually, this framework effectively enhances the federated learning applicability to extensive heterogeneous settings, while providing excellent convergence speed, accuracy, and computation/communication efficiency.
Word2vec Skip-gram Dimensionality Selection via Sequential Normalized Maximum Likelihood
Aug 18, 2020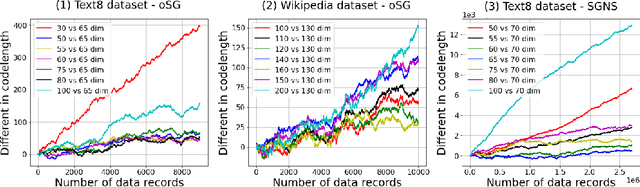

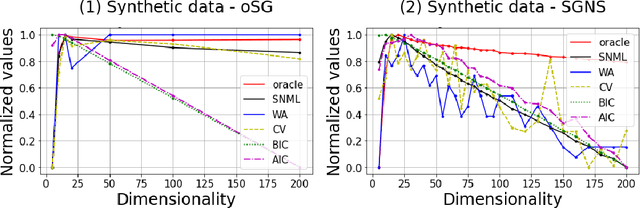
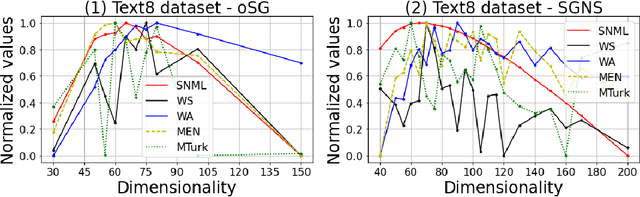
In this paper, we propose a novel information criteria-based approach to select the dimensionality of the word2vec Skip-gram (SG). From the perspective of the probability theory, SG is considered as an implicit probability distribution estimation under the assumption that there exists a true contextual distribution among words. Therefore, we apply information criteria with the aim of selecting the best dimensionality so that the corresponding model can be as close as possible to the true distribution. We examine the following information criteria for the dimensionality selection problem: the Akaike Information Criterion, Bayesian Information Criterion, and Sequential Normalized Maximum Likelihood (SNML) criterion. SNML is the total codelength required for the sequential encoding of a data sequence on the basis of the minimum description length. The proposed approach is applied to both the original SG model and the SG Negative Sampling model to clarify the idea of using information criteria. Additionally, as the original SNML suffers from computational disadvantages, we introduce novel heuristics for its efficient computation. Moreover, we empirically demonstrate that SNML outperforms both BIC and AIC. In comparison with other evaluation methods for word embedding, the dimensionality selected by SNML is significantly closer to the optimal dimensionality obtained by word analogy or word similarity tasks.
Instant-Teaching: An End-to-End Semi-Supervised Object Detection Framework
Mar 21, 2021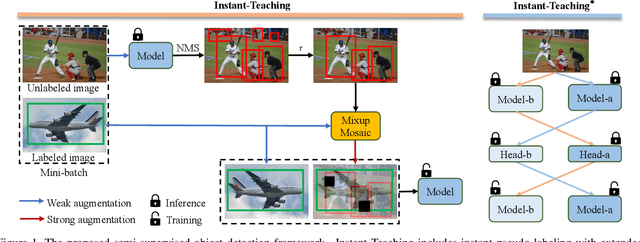

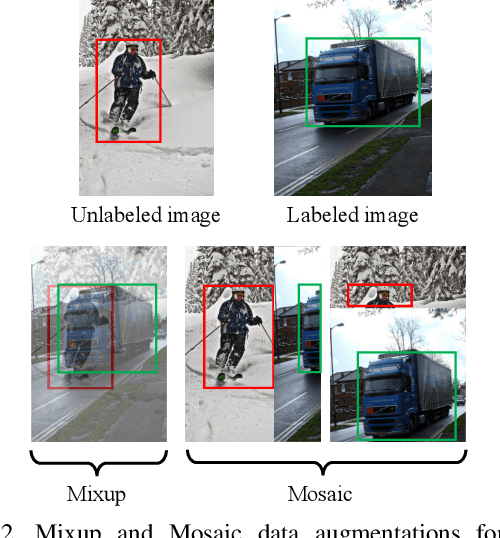
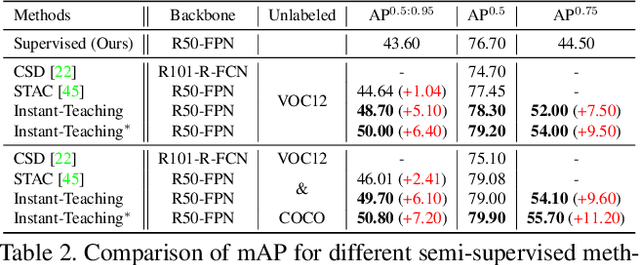
Supervised learning based object detection frameworks demand plenty of laborious manual annotations, which may not be practical in real applications. Semi-supervised object detection (SSOD) can effectively leverage unlabeled data to improve the model performance, which is of great significance for the application of object detection models. In this paper, we revisit SSOD and propose Instant-Teaching, a completely end-to-end and effective SSOD framework, which uses instant pseudo labeling with extended weak-strong data augmentations for teaching during each training iteration. To alleviate the confirmation bias problem and improve the quality of pseudo annotations, we further propose a co-rectify scheme based on Instant-Teaching, denoted as Instant-Teaching$^*$. Extensive experiments on both MS-COCO and PASCAL VOC datasets substantiate the superiority of our framework. Specifically, our method surpasses state-of-the-art methods by 4.2 mAP on MS-COCO when using $2\%$ labeled data. Even with full supervised information of MS-COCO, the proposed method still outperforms state-of-the-art methods by about 1.0 mAP. On PASCAL VOC, we can achieve more than 5 mAP improvement by applying VOC07 as labeled data and VOC12 as unlabeled data.
Natural Language Understanding for Argumentative Dialogue Systems in the Opinion Building Domain
Mar 03, 2021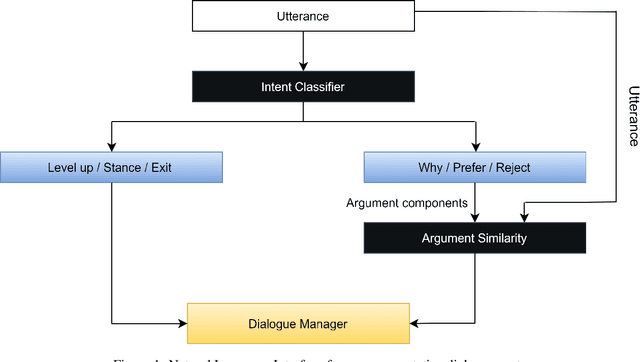

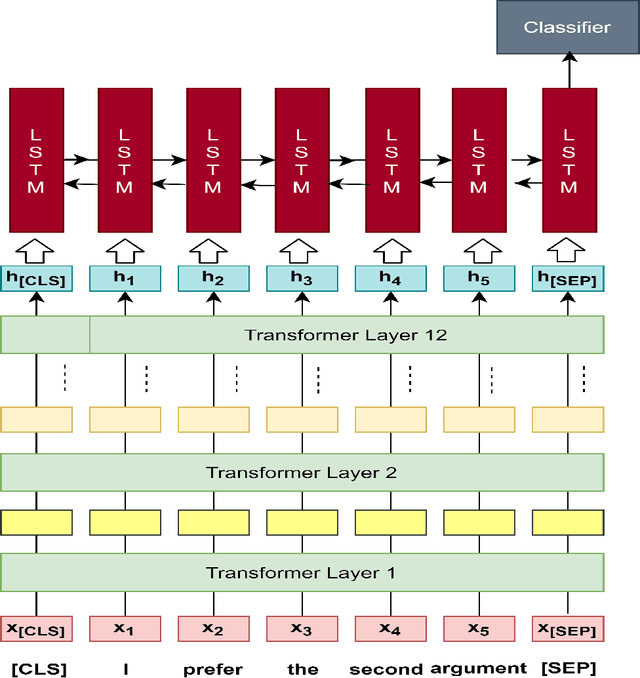

This paper introduces a natural language understanding (NLU) framework for argumentative dialogue systems in the information-seeking and opinion building domain. Our approach distinguishes multiple user intents and identifies system arguments the user refers to in his or her natural language utterances. Our model is applicable in an argumentative dialogue system that allows the user to inform him-/herself about and build his/her opinion towards a controversial topic. In order to evaluate the proposed approach, we collect user utterances for the interaction with the respective system and labeled with intent and reference argument in an extensive online study. The data collection includes multiple topics and two different user types (native speakers from the UK and non-native speakers from China). The evaluation indicates a clear advantage of the utilized techniques over baseline approaches, as well as a robustness of the proposed approach against new topics and different language proficiency as well as cultural background of the user.
3D coherent x-ray imaging via deep convolutional neural networks
Feb 26, 2021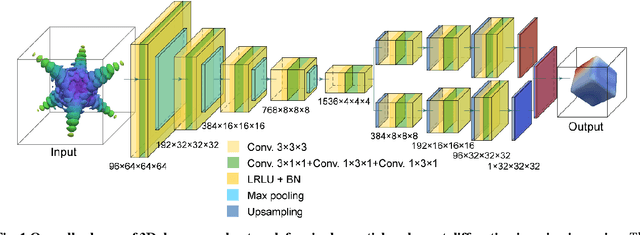
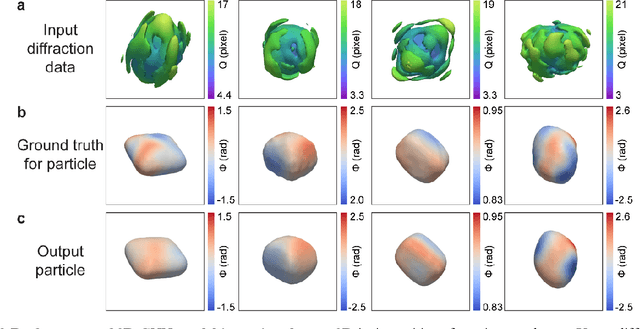
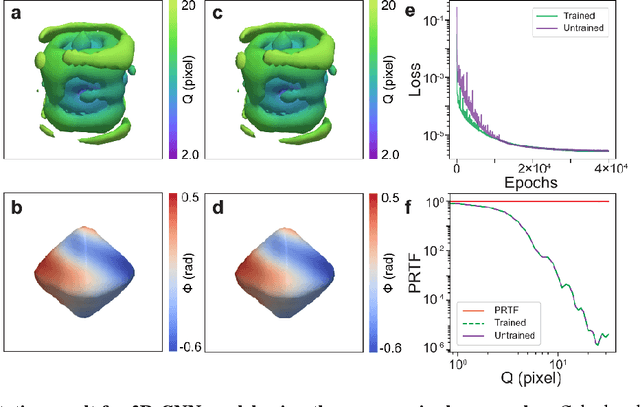
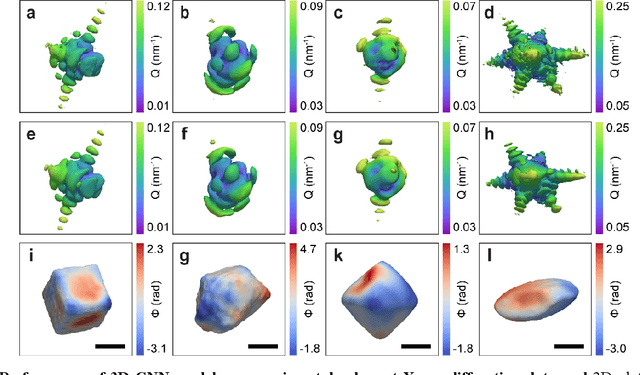
As a critical component of coherent X-ray diffraction imaging (CDI), phase retrieval has been extensively applied in X-ray structural science to recover the 3D morphological information inside measured particles. Despite meeting all the oversampling requirements of Sayre and Shannon, current phase retrieval approaches still have trouble achieving a unique inversion of experimental data in the presence of noise. Here, we propose to overcome this limitation by incorporating a 3D Machine Learning (ML) model combining (optional) supervised training with unsupervised refinement. The trained ML model can rapidly provide an immediate result with high accuracy, which will benefit real-time experiments. More significantly, the Neural Network model can be used without any prior training to learn the missing phases of an image based on minimization of an appropriate loss function alone. We demonstrate significantly improved performance with experimental Bragg CDI data over traditional iterative phase retrieval algorithms.