 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Detecting Media Bias in News Articles using Gaussian Bias Distributions
Oct 20, 2020

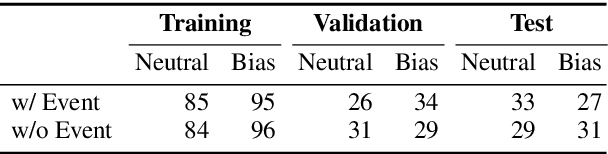
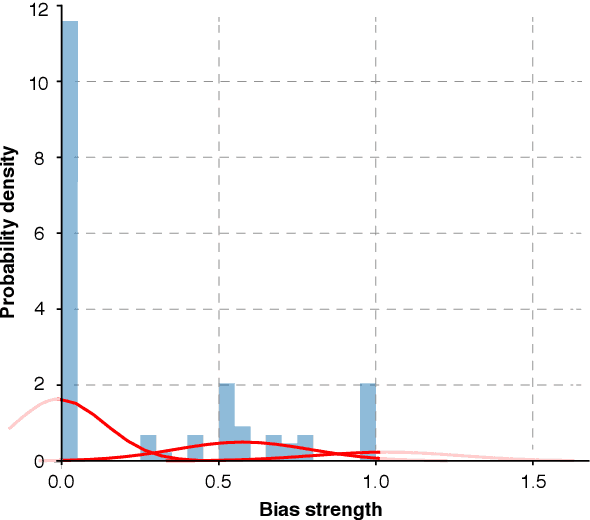
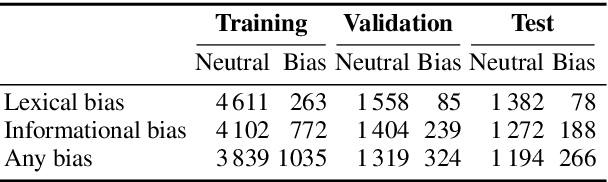
Media plays an important role in shaping public opinion. Biased media can influence people in undesirable directions and hence should be unmasked as such. We observe that featurebased and neural text classification approaches which rely only on the distribution of low-level lexical information fail to detect media bias. This weakness becomes most noticeable for articles on new events, where words appear in new contexts and hence their "bias predictiveness" is unclear. In this paper, we therefore study how second-order information about biased statements in an article helps to improve detection effectiveness. In particular, we utilize the probability distributions of the frequency, positions, and sequential order of lexical and informational sentence-level bias in a Gaussian Mixture Model. On an existing media bias dataset, we find that the frequency and positions of biased statements strongly impact article-level bias, whereas their exact sequential order is secondary. Using a standard model for sentence-level bias detection, we provide empirical evidence that article-level bias detectors that use second-order information clearly outperform those without.
Document-Level Relation Extraction with Reconstruction
Dec 21, 2020
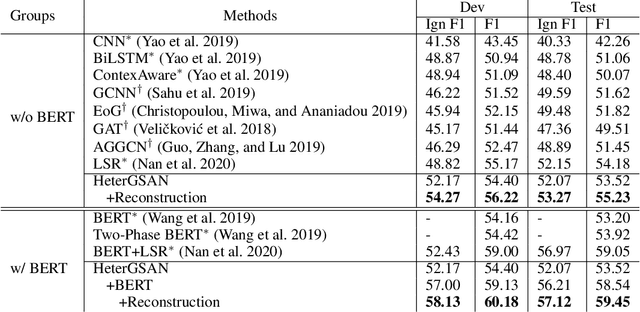
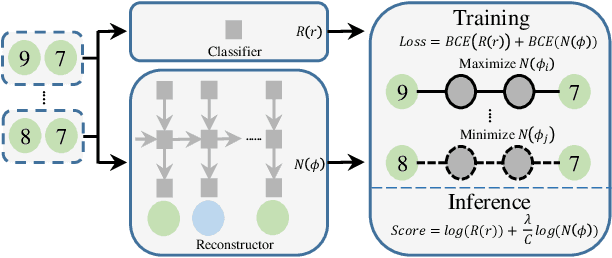
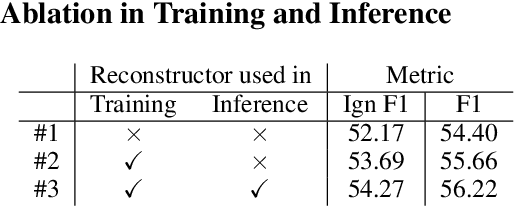
In document-level relation extraction (DocRE), graph structure is generally used to encode relation information in the input document to classify the relation category between each entity pair, and has greatly advanced the DocRE task over the past several years. However, the learned graph representation universally models relation information between all entity pairs regardless of whether there are relationships between these entity pairs. Thus, those entity pairs without relationships disperse the attention of the encoder-classifier DocRE for ones with relationships, which may further hind the improvement of DocRE. To alleviate this issue, we propose a novel encoder-classifier-reconstructor model for DocRE. The reconstructor manages to reconstruct the ground-truth path dependencies from the graph representation, to ensure that the proposed DocRE model pays more attention to encode entity pairs with relationships in the training. Furthermore, the reconstructor is regarded as a relationship indicator to assist relation classification in the inference, which can further improve the performance of DocRE model. Experimental results on a large-scale DocRE dataset show that the proposed model can significantly improve the accuracy of relation extraction on a strong heterogeneous graph-based baseline.
Sim-to-real for high-resolution optical tactile sensing: From images to 3D contact force distributions
Dec 21, 2020
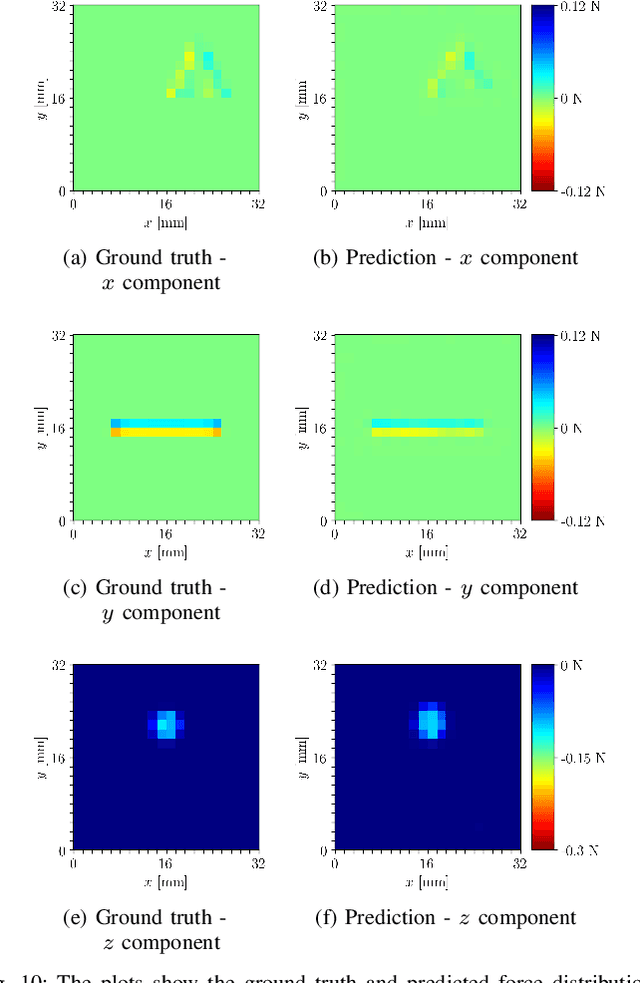


The images captured by vision-based tactile sensors carry information about high-resolution tactile fields, such as the distribution of the contact forces applied to their soft sensing surface. However, extracting the information encoded in the images is challenging and often addressed with learning-based approaches, which generally require a large amount of training data. This article proposes a strategy to generate tactile images in simulation for a vision-based tactile sensor based on an internal camera that tracks the motion of spherical particles within a soft material. The deformation of the material is simulated in a finite element environment under a diverse set of contact conditions, and spherical particles are projected to a simulated image. Features extracted from the images are mapped to the 3D contact force distribution, with the ground truth also obtained via finite-element simulations, with an artificial neural network that is therefore entirely trained on synthetic data avoiding the need for real-world data collection. The resulting model exhibits high accuracy when evaluated on real-world tactile images, is transferable across multiple tactile sensors without further training, and is suitable for efficient real-time inference.
Comparison of Possibilistic Fuzzy Local Information C-Means and Possibilistic K-Nearest Neighbors for Synthetic Aperture Sonar Image Segmentation
Apr 01, 2019Synthetic aperture sonar (SAS) imagery can generate high resolution images of the seafloor. Thus, segmentation algorithms can be used to partition the images into different seafloor environments. In this paper, we compare two possibilistic segmentation approaches. Possibilistic approaches allow for the ability to detect novel or outlier environments as well as well known classes. The Possibilistic Fuzzy Local Information C-Means (PFLICM) algorithm has been previously applied to segment SAS imagery. Additionally, the Possibilistic K-Nearest Neighbors (PKNN) algorithm has been used in other domains such as landmine detection and hyperspectral imagery. In this paper, we compare the segmentation performance of a semi-supervised approach using PFLICM and a supervised method using Possibilistic K-NN. We include final segmentation results on multiple SAS images and a quantitative assessment of each algorithm.
The Inductive Logic of Information Systems
Mar 27, 2013An inductive logic can be formulated in which the elements are not propositions or probability distributions, but information systems. The logic is complete for information systems with binary hypotheses, i.e., it applies to all such systems. It is not complete for information systems with more than two hypotheses, but applies to a subset of such systems. The logic is inductive in that conclusions are more informative than premises. Inferences using the formalism have a strong justification in terms of the expected value of the derived information system.
Multi-Modal Hybrid Architecture for Pedestrian Action Prediction
Nov 16, 2020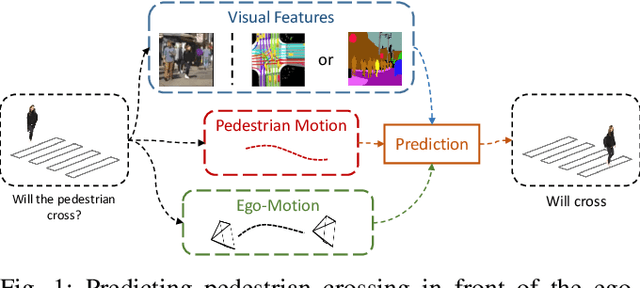
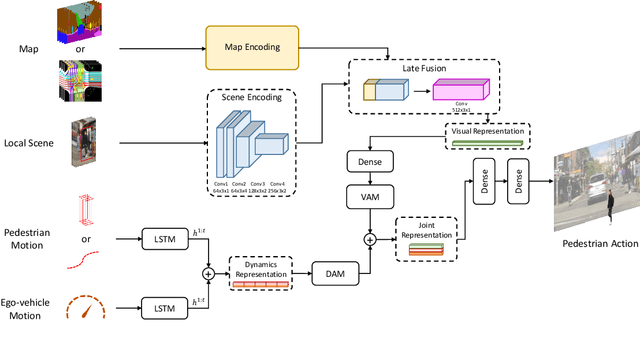
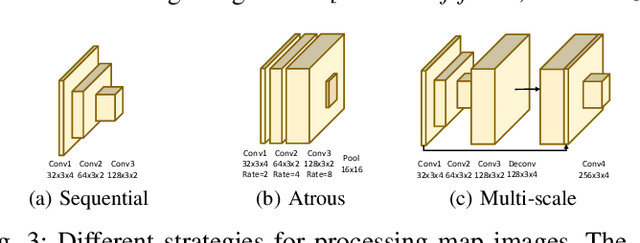

Pedestrian behavior prediction is one of the major challenges for intelligent driving systems in urban environments. Pedestrians often exhibit a wide range of behaviors and adequate interpretations of those depend on various sources of information such as pedestrian appearance, states of other road users, the environment layout, etc. To address this problem, we propose a novel multi-modal prediction algorithm that incorporates different sources of information captured from the environment to predict future crossing actions of pedestrians. The proposed model benefits from a hybrid learning architecture consisting of feedforward and recurrent networks for analyzing visual features of the environment and dynamics of the scene. Using the existing 2D pedestrian behavior benchmarks and a newly annotated 3D driving dataset, we show that our proposed model achieves state-of-the-art performance in pedestrian crossing prediction.
GraphHop: An Enhanced Label Propagation Method for Node Classification
Jan 07, 2021
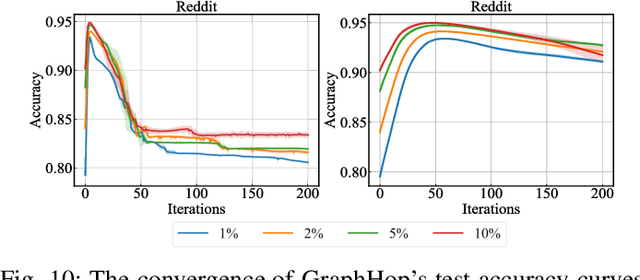
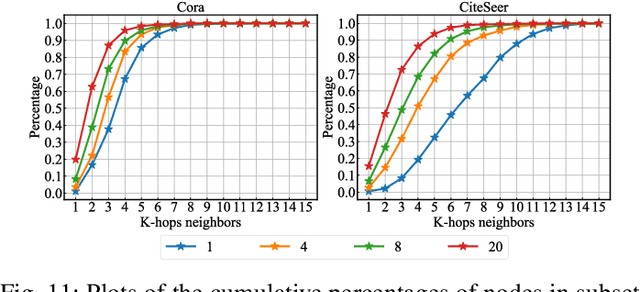
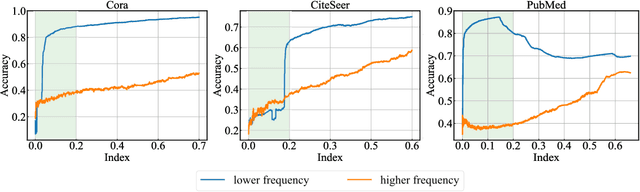
A scalable semi-supervised node classification method on graph-structured data, called GraphHop, is proposed in this work. The graph contains attributes of all nodes but labels of a few nodes. The classical label propagation (LP) method and the emerging graph convolutional network (GCN) are two popular semi-supervised solutions to this problem. The LP method is not effective in modeling node attributes and labels jointly or facing a slow convergence rate on large-scale graphs. GraphHop is proposed to its shortcoming. With proper initial label vector embeddings, each iteration of GraphHop contains two steps: 1) label aggregation and 2) label update. In Step 1, each node aggregates its neighbors' label vectors obtained in the previous iteration. In Step 2, a new label vector is predicted for each node based on the label of the node itself and the aggregated label information obtained in Step 1. This iterative procedure exploits the neighborhood information and enables GraphHop to perform well in an extremely small label rate setting and scale well for very large graphs. Experimental results show that GraphHop outperforms state-of-the-art graph learning methods on a wide range of tasks (e.g., multi-label and multi-class classification on citation networks, social graphs, and commodity consumption graphs) in graphs of various sizes. Our codes are publicly available on GitHub (https://github.com/TianXieUSC/GraphHop).
Towards Accurate Camouflaged Object Detection with Mixture Convolution and Interactive Fusion
Jan 14, 2021
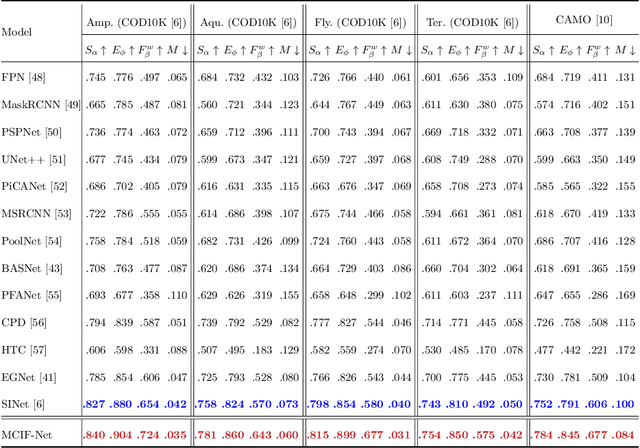
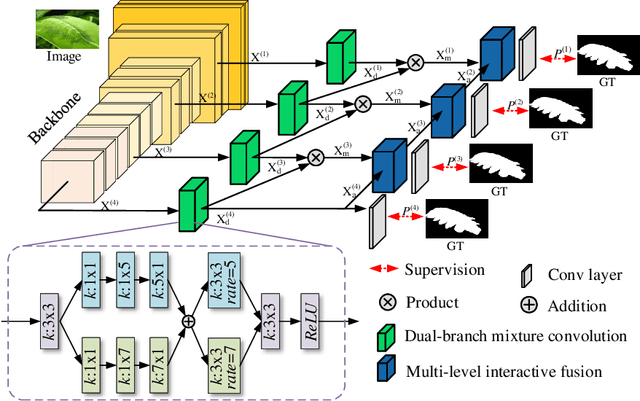
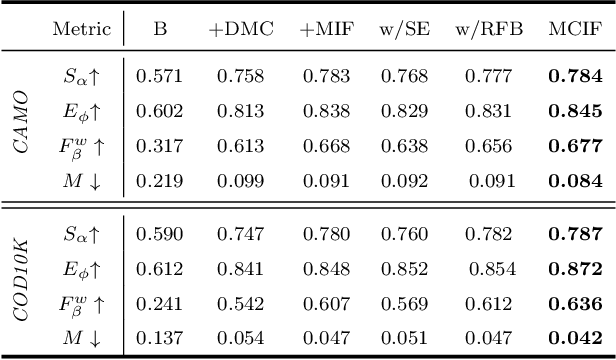
Camouflaged object detection (COD), which aims to identify the objects that conceal themselves into the surroundings, has recently drawn increasing research efforts in the field of computer vision. In practice, the success of deep learning based COD is mainly determined by two key factors, including (i) A significantly large receptive field, which provides rich context information, and (ii) An effective fusion strategy, which aggregates the rich multi-level features for accurate COD. Motivated by these observations, in this paper, we propose a novel deep learning based COD approach, which integrates the large receptive field and effective feature fusion into a unified framework. Specifically, we first extract multi-level features from a backbone network. The resulting features are then fed to the proposed dual-branch mixture convolution modules, each of which utilizes multiple asymmetric convolutional layers and two dilated convolutional layers to extract rich context features from a large receptive field. Finally, we fuse the features using specially-designed multi-level interactive fusion modules, each of which employs an attention mechanism along with feature interaction for effective feature fusion. Our method detects camouflaged objects with an effective fusion strategy, which aggregates the rich context information from a large receptive field. All of these designs meet the requirements of COD well, allowing the accurate detection of camouflaged objects. Extensive experiments on widely-used benchmark datasets demonstrate that our method is capable of accurately detecting camouflaged objects and outperforms the state-of-the-art methods.
Learning to Learn Variational Semantic Memory
Oct 20, 2020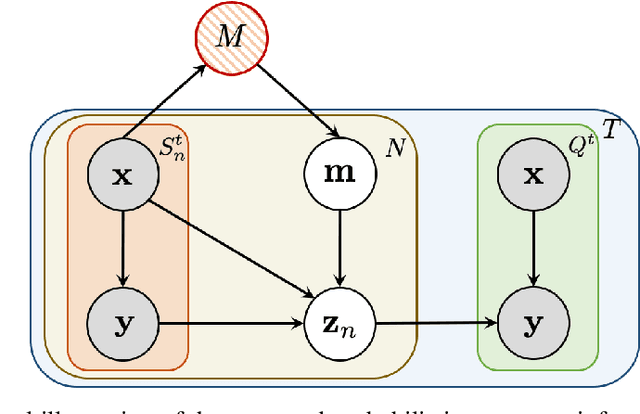

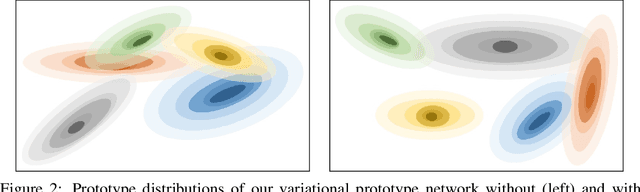

In this paper, we introduce variational semantic memory into meta-learning to acquire long-term knowledge for few-shot learning. The variational semantic memory accrues and stores semantic information for the probabilistic inference of class prototypes in a hierarchical Bayesian framework. The semantic memory is grown from scratch and gradually consolidated by absorbing information from tasks it experiences. By doing so, it is able to accumulate long-term, general knowledge that enables it to learn new concepts of objects. We formulate memory recall as the variational inference of a latent memory variable from addressed contents, which offers a principled way to adapt the knowledge to individual tasks. Our variational semantic memory, as a new long-term memory module, confers principled recall and update mechanisms that enable semantic information to be efficiently accrued and adapted for few-shot learning. Experiments demonstrate that the probabilistic modelling of prototypes achieves a more informative representation of object classes compared to deterministic vectors. The consistent new state-of-the-art performance on four benchmarks shows the benefit of variational semantic memory in boosting few-shot recognition.
Hybrid Relay-Reflecting Intelligent Surface-Aided Wireless Communications: Opportunities, Challenges, and Future Perspectives
Apr 05, 2021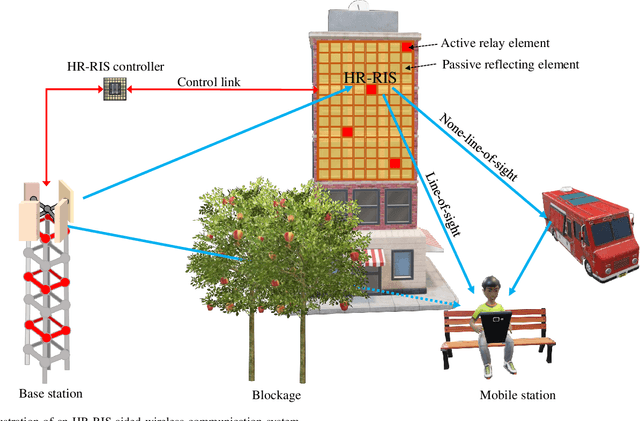
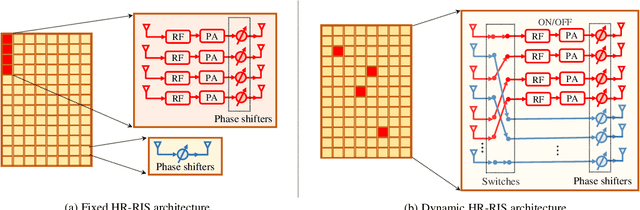
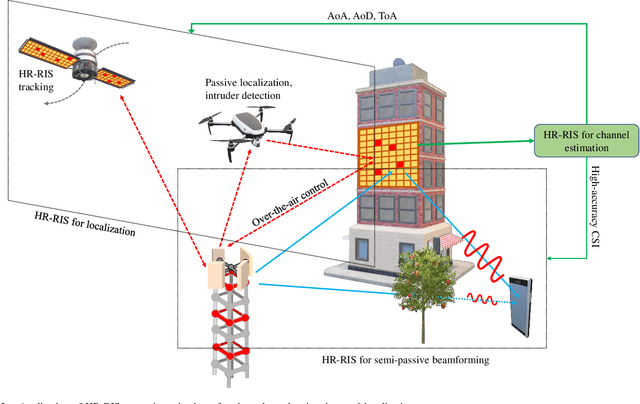
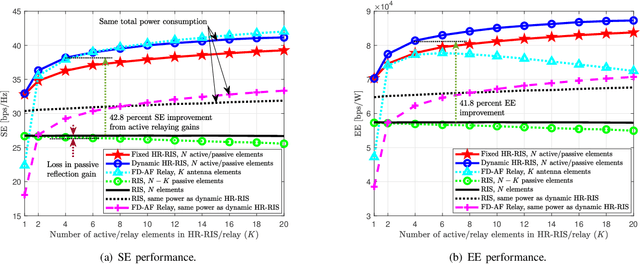
Reconfigurable intelligent surfaces (RISs) have emerged as a cost- and energy-efficient technology that can customize and program the physical propagation environment by reflecting radio waves in preferred directions. However, the purely passive reflection of RISs not only limits the end-to-end channel beamforming gains, but also hinders the acquisition of accurate channel state information for the phase control at RISs. In this paper, we provide an overview of a hybrid relay-reflecting intelligent surface (HR-RIS) architecture, in which only a few elements are active and connected to power amplifiers and radio frequency chains. The introduction of a small number of active elements enables a remarkable system performance improvement which can also compensate for losses due to hardware impairments such as the deployment of limited-resolution phase shifters. Particularly, the active processing facilitates efficient channel estimation and localization at HR-RISs. We present two practical architectures for HR-RISs, namely, fixed and dynamic HR-RISs, and discuss their applications to beamforming, channel estimation, and localization. The benefits, key challenges, and future research directions for HR-RIS-aided communications are also highlighted. Numerical results for an exemplary deployment scenario show that HR-RISs with only four active elements can attain up to 42.8 percent and 41.8 percent improvement in spectral efficiency and energy efficiency, respectively, compared with conventional RISs.