 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Local Algorithms for Block Models with Side Information
Aug 10, 2015
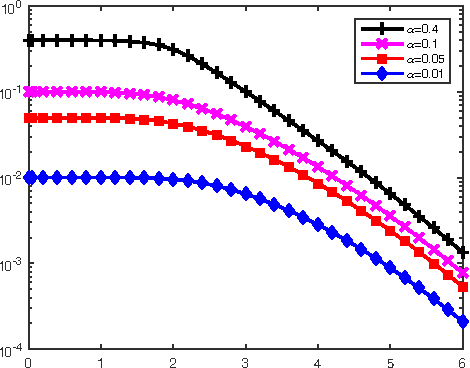
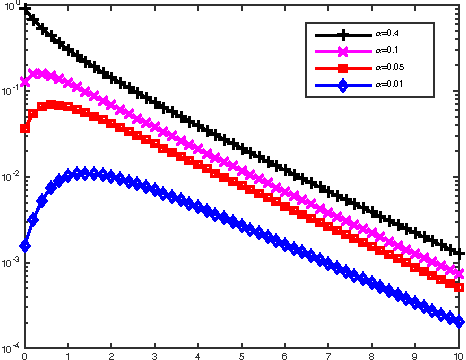
There has been a recent interest in understanding the power of local algorithms for optimization and inference problems on sparse graphs. Gamarnik and Sudan (2014) showed that local algorithms are weaker than global algorithms for finding large independent sets in sparse random regular graphs. Montanari (2015) showed that local algorithms are suboptimal for finding a community with high connectivity in the sparse Erd\H{o}s-R\'enyi random graphs. For the symmetric planted partition problem (also named community detection for the block models) on sparse graphs, a simple observation is that local algorithms cannot have non-trivial performance. In this work we consider the effect of side information on local algorithms for community detection under the binary symmetric stochastic block model. In the block model with side information each of the $n$ vertices is labeled $+$ or $-$ independently and uniformly at random; each pair of vertices is connected independently with probability $a/n$ if both of them have the same label or $b/n$ otherwise. The goal is to estimate the underlying vertex labeling given 1) the graph structure and 2) side information in the form of a vertex labeling positively correlated with the true one. Assuming that the ratio between in and out degree $a/b$ is $\Theta(1)$ and the average degree $ (a+b) / 2 = n^{o(1)}$, we characterize three different regimes under which a local algorithm, namely, belief propagation run on the local neighborhoods, maximizes the expected fraction of vertices labeled correctly. Thus, in contrast to the case of symmetric block models without side information, we show that local algorithms can achieve optimal performance for the block model with side information.
PoseTrackReID: Dataset Description
Nov 12, 2020Current datasets for video-based person re-identification (re-ID) do not include structural knowledge in form of human pose annotations for the persons of interest. Nonetheless, pose information is very helpful to disentangle useful feature information from background or occlusion noise. Especially real-world scenarios, such as surveillance, contain a lot of occlusions in human crowds or by obstacles. On the other hand, video-based person re-ID can benefit other tasks such as multi-person pose tracking in terms of robust feature matching. For that reason, we present PoseTrackReID, a large-scale dataset for multi-person pose tracking and video-based person re-ID. With PoseTrackReID, we want to bridge the gap between person re-ID and multi-person pose tracking. Additionally, this dataset provides a good benchmark for current state-of-the-art methods on multi-frame person re-ID.
Delayed Rewards Calibration via Reward Empirical Sufficiency
Feb 23, 2021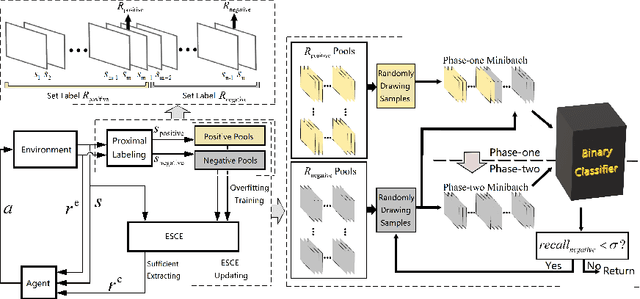
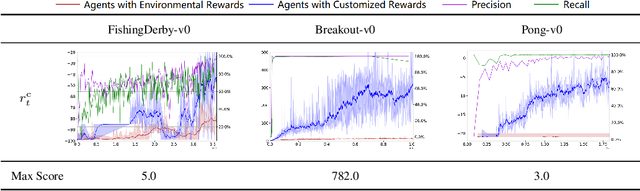
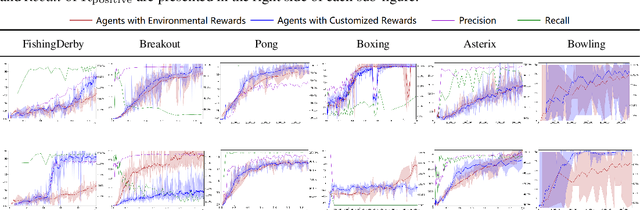
Appropriate credit assignment for delay rewards is a fundamental challenge for reinforcement learning. To tackle this problem, we introduce a delay reward calibration paradigm inspired from a classification perspective. We hypothesize that well-represented state vectors share similarities with each other since they contain the same or equivalent essential information. To this end, we define an empirical sufficient distribution, where the state vectors within the distribution will lead agents to environmental reward signals in the consequent steps. Therefore, a purify-trained classifier is designed to obtain the distribution and generate the calibrated rewards. We examine the correctness of sufficient state extraction by tracking the real-time extraction and building different reward functions in environments. The results demonstrate that the classifier could generate timely and accurate calibrated rewards. Moreover, the rewards are able to make the model training process more efficient. Finally, we identify and discuss that the sufficient states extracted by our model resonate with the observations of humans.
Neuralizing Efficient Higher-order Belief Propagation
Oct 19, 2020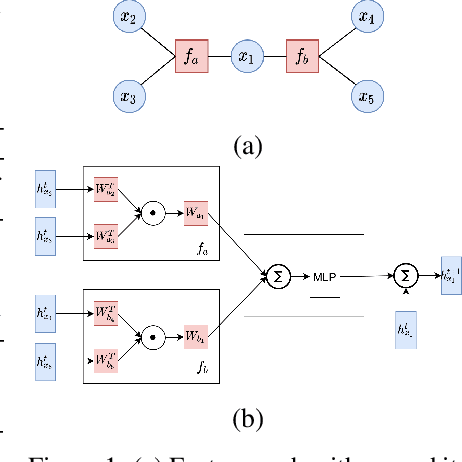
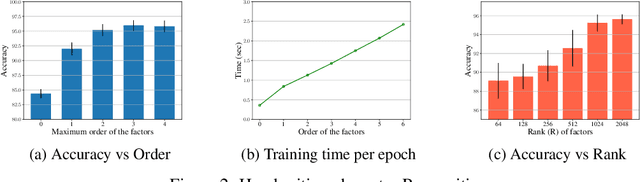
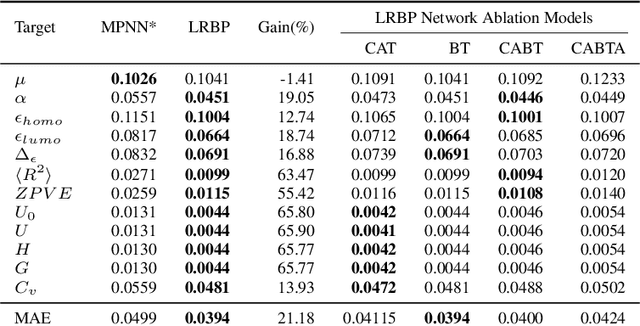
Graph neural network models have been extensively used to learn node representations for graph structured data in an end-to-end setting. These models often rely on localized first order approximations of spectral graph convolutions and hence are unable to capture higher-order relational information between nodes. Probabilistic Graphical Models form another class of models that provide rich flexibility in incorporating such relational information but are limited by inefficient approximate inference algorithms at higher order. In this paper, we propose to combine these approaches to learn better node and graph representations. First, we derive an efficient approximate sum-product loopy belief propagation inference algorithm for higher-order PGMs. We then embed the message passing updates into a neural network to provide the inductive bias of the inference algorithm in end-to-end learning. This gives us a model that is flexible enough to accommodate domain knowledge while maintaining the computational advantage. We further propose methods for constructing higher-order factors that are conditioned on node and edge features and share parameters wherever necessary. Our experimental evaluation shows that our model indeed captures higher-order information, substantially outperforming state-of-the-art $k$-order graph neural networks in molecular datasets.
Multimodal data visualization, denoising and clustering with integrated diffusion
Feb 12, 2021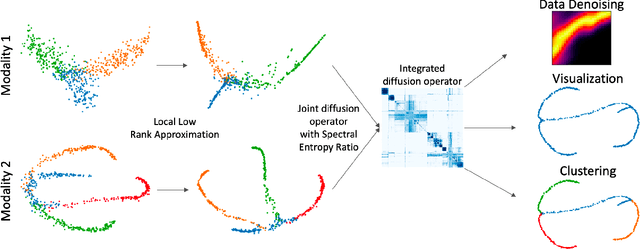
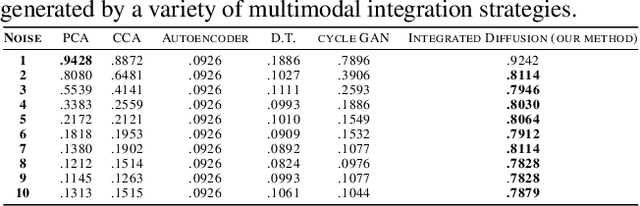

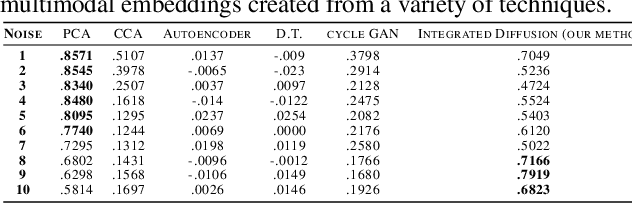
We propose a method called integrated diffusion for combining multimodal datasets, or data gathered via several different measurements on the same system, to create a joint data diffusion operator. As real world data suffers from both local and global noise, we introduce mechanisms to optimally calculate a diffusion operator that reflects the combined information from both modalities. We show the utility of this joint operator in data denoising, visualization and clustering, performing better than other methods to integrate and analyze multimodal data. We apply our method to multi-omic data generated from blood cells, measuring both gene expression and chromatin accessibility. Our approach better visualizes the geometry of the joint data, captures known cross-modality associations and identifies known cellular populations. More generally, integrated diffusion is broadly applicable to multimodal datasets generated in many medical and biological systems.
TapNet: The Design, Training, Implementation, and Applications of a Multi-Task Learning CNN for Off-Screen Mobile Input
Feb 18, 2021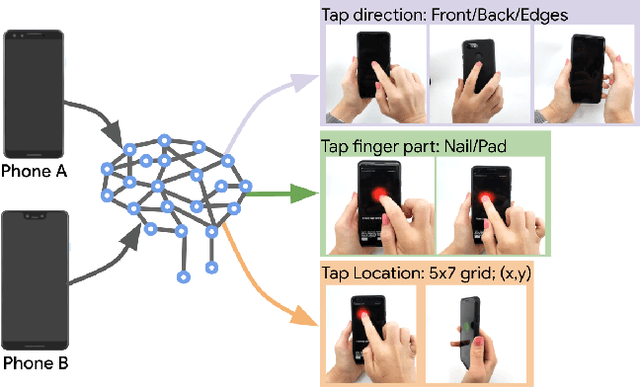
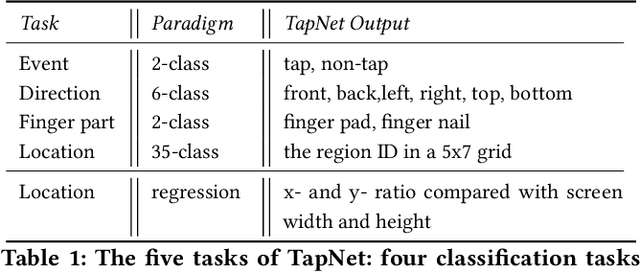
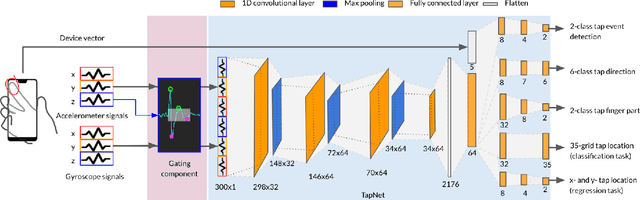
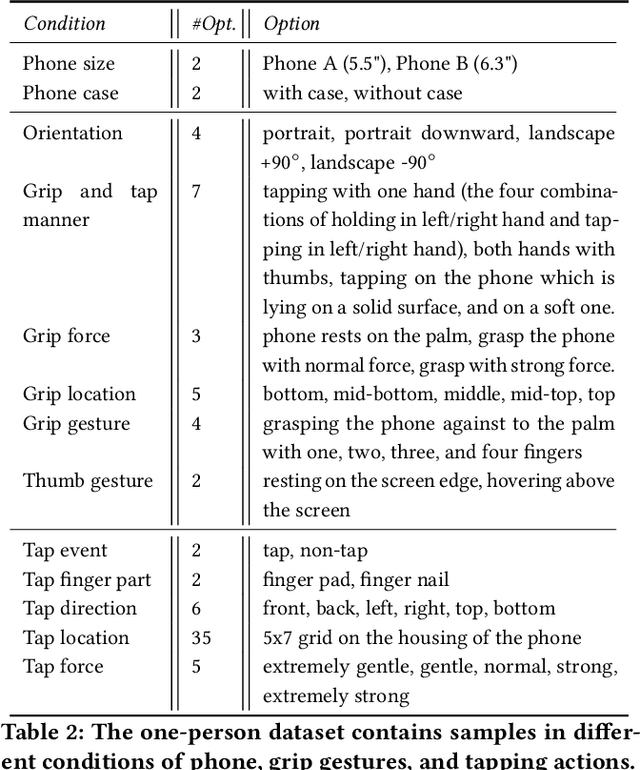
To make off-screen interaction without specialized hardware practical, we investigate using deep learning methods to process the common built-in IMU sensor (accelerometers and gyroscopes) on mobile phones into a useful set of one-handed interaction events. We present the design, training, implementation and applications of TapNet, a multi-task network that detects tapping on the smartphone. With phone form factor as auxiliary information, TapNet can jointly learn from data across devices and simultaneously recognize multiple tap properties, including tap direction and tap location. We developed two datasets consisting of over 135K training samples, 38K testing samples, and 32 participants in total. Experimental evaluation demonstrated the effectiveness of the TapNet design and its significant improvement over the state of the art. Along with the datasets, (https://sites.google.com/site/michaelxlhuang/datasets/tapnet-dataset), and extensive experiments, TapNet establishes a new technical foundation for off-screen mobile input.
Contextual Fusion For Adversarial Robustness
Nov 18, 2020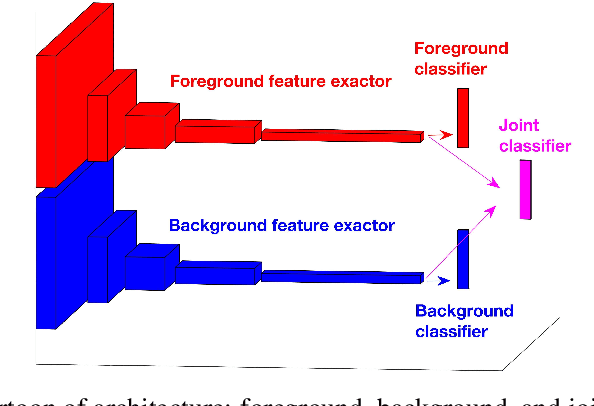
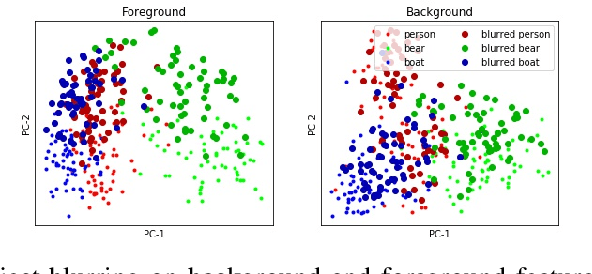
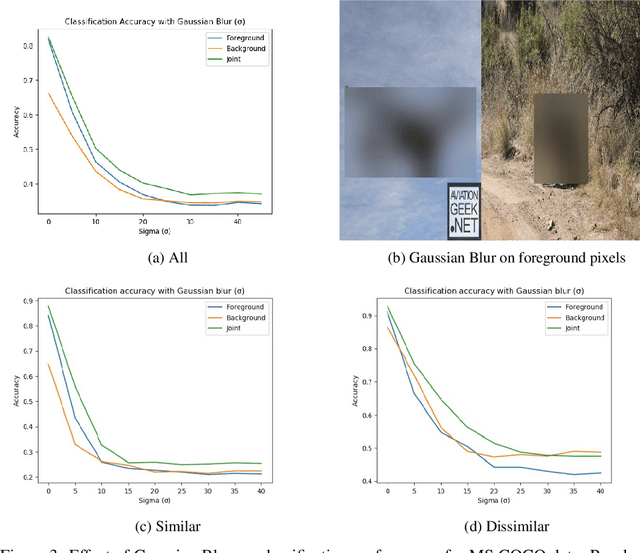
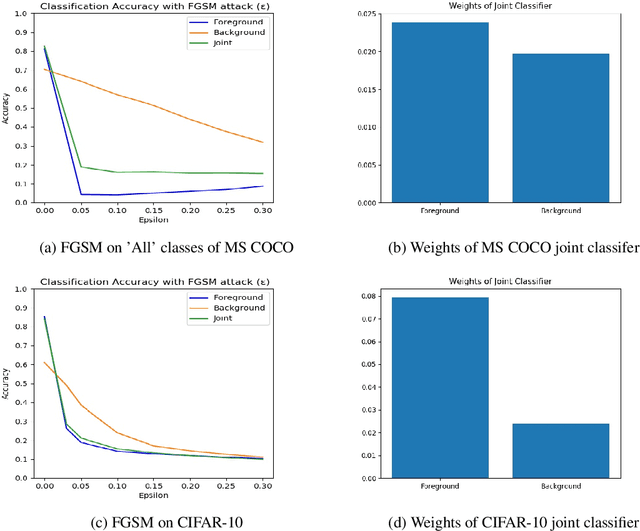
Mammalian brains handle complex reasoning tasks in a gestalt manner by integrating information from regions of the brain that are specialised to individual sensory modalities. This allows for improved robustness and better generalisation ability. In contrast, deep neural networks are usually designed to process one particular information stream and susceptible to various types of adversarial perturbations. While many methods exist for detecting and defending against adversarial attacks, they do not generalise across a range of attacks and negatively affect performance on clean, unperturbed data. We developed a fusion model using a combination of background and foreground features extracted in parallel from Places-CNN and Imagenet-CNN. We tested the benefits of the fusion approach on preserving adversarial robustness for human perceivable (e.g., Gaussian blur) and network perceivable (e.g., gradient-based) attacks for CIFAR-10 and MS COCO data sets. For gradient based attacks, our results show that fusion allows for significant improvements in classification without decreasing performance on unperturbed data and without need to perform adversarial retraining. Our fused model revealed improvements for Gaussian blur type perturbations as well. The increase in performance from fusion approach depended on the variability of the image contexts; larger increases were seen for classes of images with larger differences in their contexts. We also demonstrate the effect of regularization to bias the classifier decision in the presence of a known adversary. We propose that this biologically inspired approach to integrate information across multiple modalities provides a new way to improve adversarial robustness that can be complementary to current state of the art approaches.
Generating Human-Like Movement: A Comparison Between Two Approaches Based on Environmental Features
Dec 11, 2020
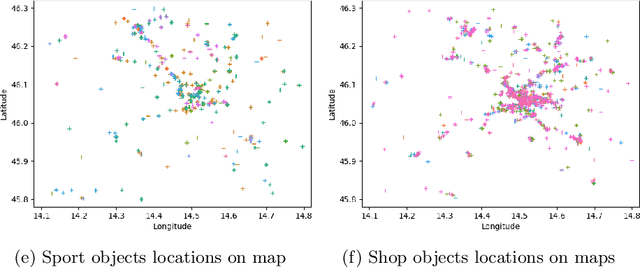

Modelling realistic human behaviours in simulation is an ongoing challenge that resides between several fields like social sciences, philosophy, and artificial intelligence. Human movement is a special type of behaviour driven by intent (e.g. to get groceries) and the surrounding environment (e.g. curiosity to see new interesting places). Services available online and offline do not normally consider the environment when planning a path, which is decisive especially on a leisure trip. Two novel algorithms have been presented to generate human-like trajectories based on environmental features. The Attraction-Based A* algorithm includes in its computation information from the environmental features meanwhile, the Feature-Based A* algorithm also injects information from the real trajectories in its computation. The human-likeness aspect has been tested by a human expert judging the final generated trajectories as realistic. This paper presents a comparison between the two approaches in some key metrics like efficiency, efficacy, and hyper-parameters sensitivity. We show how, despite generating trajectories that are closer to the real one according to our predefined metrics, the Feature-Based A* algorithm fall short in time efficiency compared to the Attraction-Based A* algorithm, hindering the usability of the model in the real world.
Learning Low-dimensional Manifolds for Scoring of Tissue Microarray Images
Feb 22, 2021
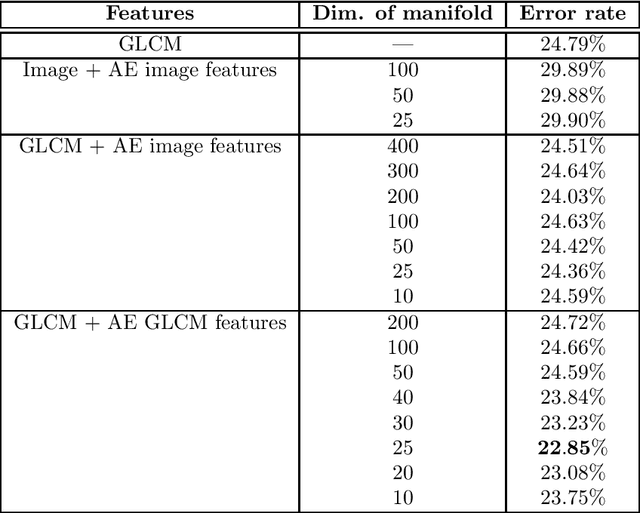
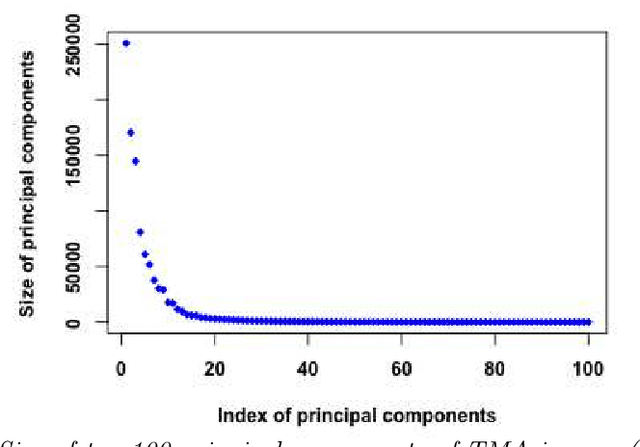
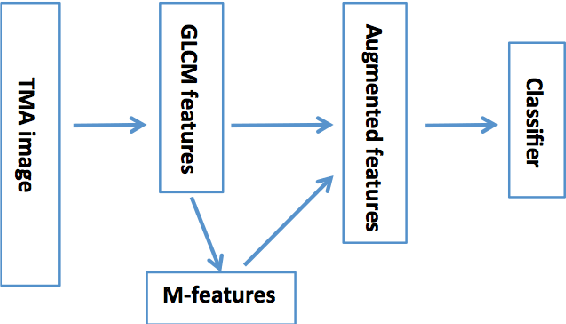
Tissue microarray (TMA) images have emerged as an important high-throughput tool for cancer study and the validation of biomarkers. Efforts have been dedicated to further improve the accuracy of TACOMA, a cutting-edge automatic scoring algorithm for TMA images. One major advance is due to deepTacoma, an algorithm that incorporates suitable deep representations of a group nature. Inspired by the recent advance in semi-supervised learning and deep learning, we propose mfTacoma to learn alternative deep representations in the context of TMA image scoring. In particular, mfTacoma learns the low-dimensional manifolds, a common latent structure in high dimensional data. Deep representation learning and manifold learning typically requires large data. By encoding deep representation of the manifolds as regularizing features, mfTacoma effectively leverages the manifold information that is potentially crude due to small data. Our experiments show that deep features by manifolds outperforms two alternatives -- deep features by linear manifolds with principal component analysis or by leveraging the group property.
RFNet: Riemannian Fusion Network for EEG-based Brain-Computer Interfaces
Aug 19, 2020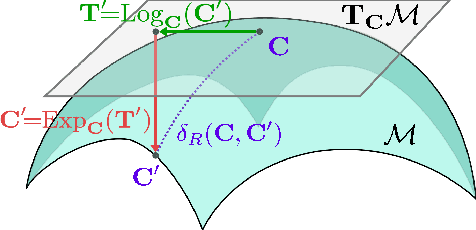
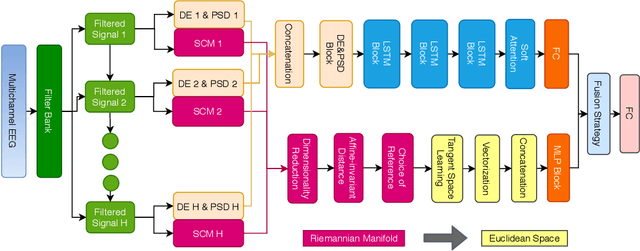
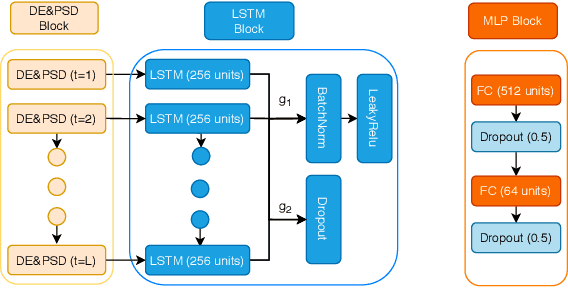
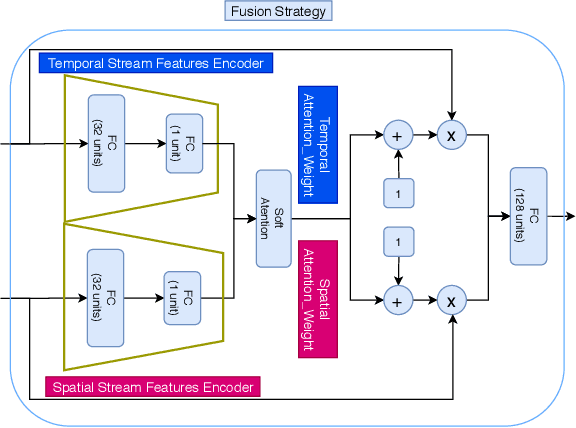
This paper presents the novel Riemannian Fusion Network (RFNet), a deep neural architecture for learning spatial and temporal information from Electroencephalogram (EEG) for a number of different EEG-based Brain Computer Interface (BCI) tasks and applications. The spatial information relies on Spatial Covariance Matrices (SCM) of multi-channel EEG, whose space form a Riemannian Manifold due to the Symmetric and Positive Definite structure. We exploit a Riemannian approach to map spatial information onto feature vectors in Euclidean space. The temporal information characterized by features based on differential entropy and logarithm power spectrum density is extracted from different windows through time. Our network then learns the temporal information by employing a deep long short-term memory network with a soft attention mechanism. The output of the attention mechanism is used as the temporal feature vector. To effectively fuse spatial and temporal information, we use an effective fusion strategy, which learns attention weights applied to embedding-specific features for decision making. We evaluate our proposed framework on four public datasets from three popular fields of BCI, notably emotion recognition, vigilance estimation, and motor imagery classification, containing various types of tasks such as binary classification, multi-class classification, and regression. RFNet approaches the state-of-the-art on one dataset (SEED) and outperforms other methods on the other three datasets (SEED-VIG, BCI-IV 2A, and BCI-IV 2B), setting new state-of-the-art values and showing the robustness of our framework in EEG representation learning.