 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Should I Look at the Head or the Tail? Dual-awareness Attention for Few-Shot Object Detection
Feb 24, 2021
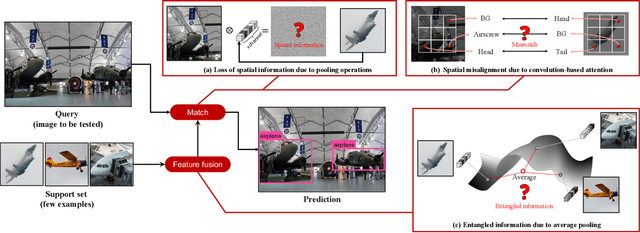

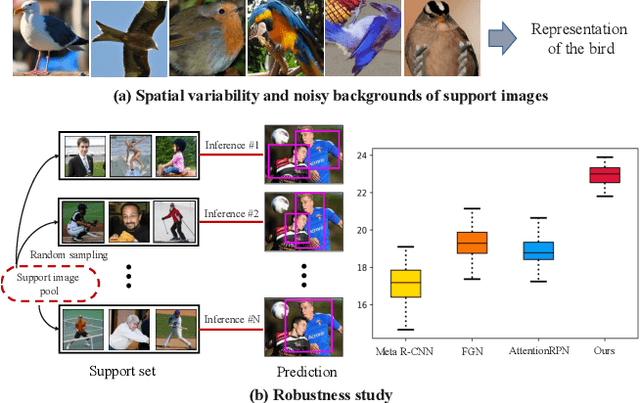
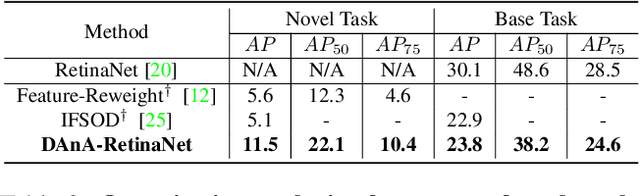
While recent progress has significantly boosted few-shot classification (FSC) performance, few-shot object detection (FSOD) remains challenging for modern learning systems. Existing FSOD systems follow FSC approaches, neglect the problem of spatial misalignment and the risk of information entanglement, and result in low performance. Observing this, we propose a novel Dual-Awareness-Attention (DAnA), which captures the pairwise spatial relationship cross the support and query images. The generated query-position-aware support features are robust to spatial misalignment and used to guide the detection network precisely. Our DAnA component is adaptable to various existing object detection networks and boosts FSOD performance by paying attention to specific semantics conditioned on the query. Experimental results demonstrate that DAnA significantly boosts (48% and 125% relatively) object detection performance on the COCO benchmark. By equipping DAnA, conventional object detection models, Faster-RCNN and RetinaNet, which are not designed explicitly for few-shot learning, reach state-of-the-art performance.
Learning for Biomedical Information Extraction: Methodological Review of Recent Advances
Jun 26, 2016
Biomedical information extraction (BioIE) is important to many applications, including clinical decision support, integrative biology, and pharmacovigilance, and therefore it has been an active research. Unlike existing reviews covering a holistic view on BioIE, this review focuses on mainly recent advances in learning based approaches, by systematically summarizing them into different aspects of methodological development. In addition, we dive into open information extraction and deep learning, two emerging and influential techniques and envision next generation of BioIE.
Deep Learning Approach for Singer Voice Classification of Vietnamese Popular Music
Feb 24, 2021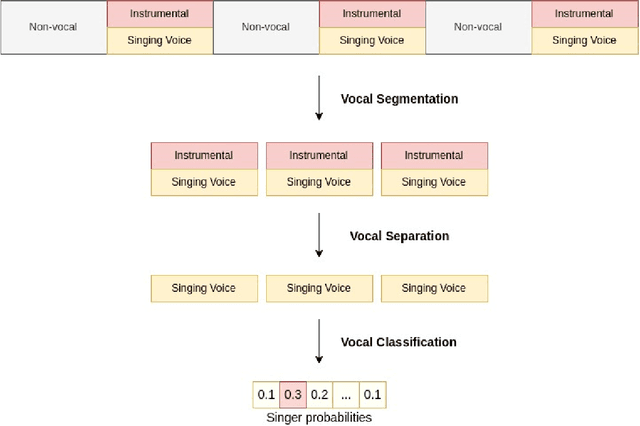
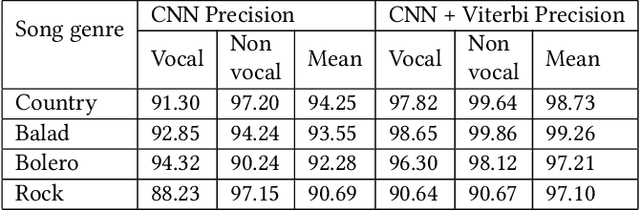
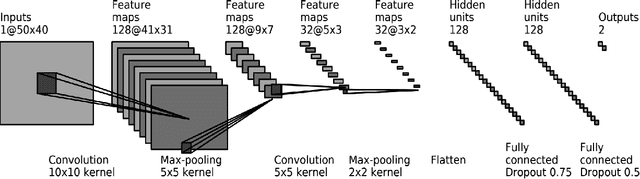

Singer voice classification is a meaningful task in the digital era. With a huge number of songs today, identifying a singer is very helpful for music information retrieval, music properties indexing, and so on. In this paper, we propose a new method to identify the singer's name based on analysis of Vietnamese popular music. We employ the use of vocal segment detection and singing voice separation as the pre-processing steps. The purpose of these steps is to extract the singer's voice from the mixture sound. In order to build a singer classifier, we propose a neural network architecture working with Mel Frequency Cepstral Coefficient as extracted input features from said vocal. To verify the accuracy of our methods, we evaluate on a dataset of 300 Vietnamese songs from 18 famous singers. We achieve an accuracy of 92.84% with 5-fold stratified cross-validation, the best result compared to other methods on the same data set.
* Published in SoICT 2019: Proceedings of the Tenth International Symposium on Information and Communication Technology
Performance Analysis and Optimization of Bidirectional Overlay Cognitive Radio Networks with Hybrid-SWIPT
Jan 06, 2021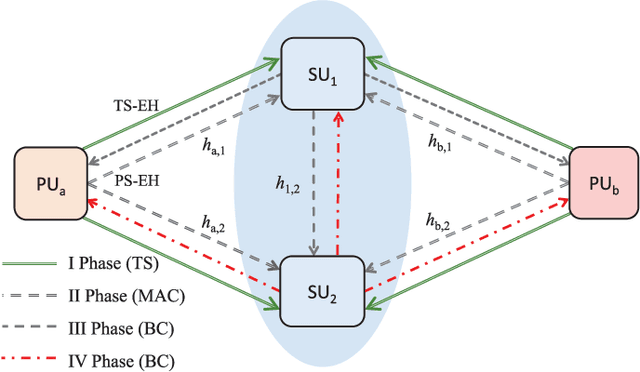
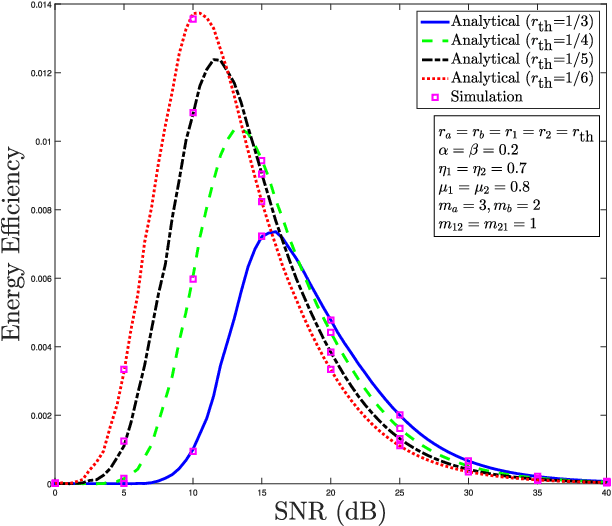
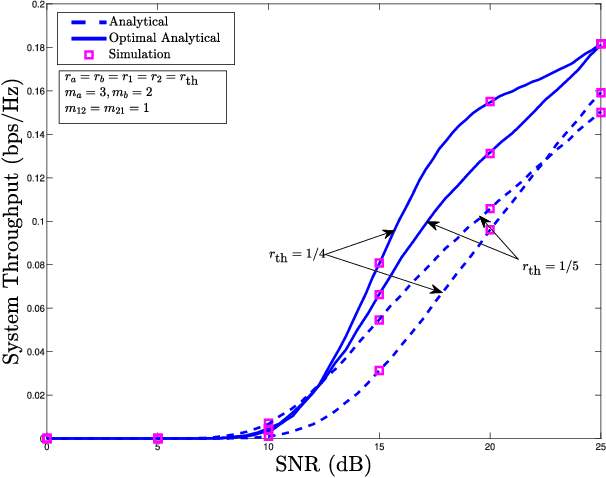
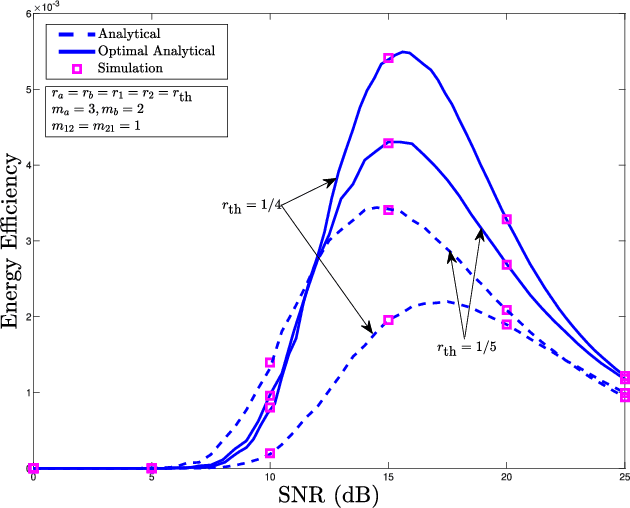
This paper considers a cooperative cognitive radio network with two primary users (PUs) and two secondary users (SUs) that enables two-way communications of primary and secondary systems in conjunction with non-linear energy harvesting based simultaneous wireless information and power transfer (SWIPT). With the considered network, SUs are able to realize their communications over the licensed spectrum while extending relay assistance to the PUs. The overall bidirectional end-to-end transmission takes place in four phases, which include both energy harvesting (EH) and information transfer. A non-linear energy harvester with a hybrid SWIPT scheme is adopted in which both power-splitting and time-switching EH techniques are used. The SUs aid in relay cooperation by performing an amplify-and-forward operation, whereas selection combining technique is adopted at the PUs to extract the intended signal from multiple received signals broadcasted by the SUs. Accurate outage probability expressions for the primary and secondary links are derived under the Nakagami-$m$ fading environment. Further, the system behavior is analyzed with respect to achievable system throughput and energy efficiency. Since the performance of the considered system is strongly affected by the spectrum sharing factor and hybrid SWIPT parameters, particle swarm optimization is implemented to optimize the system parameters so as to maximize the system throughput and energy efficiency. Simulation results are provided to corroborate the performance analysis and give useful insights into the system behavior concerning various system/channel parameters.
* 15 pages, 12 figures
Frequency-Temporal Attention Network for Singing Melody Extraction
Feb 19, 2021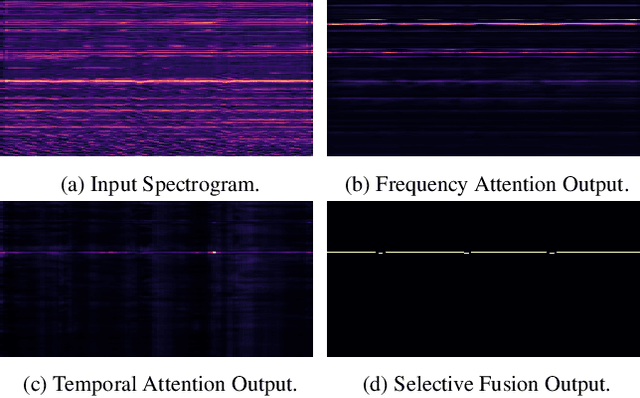
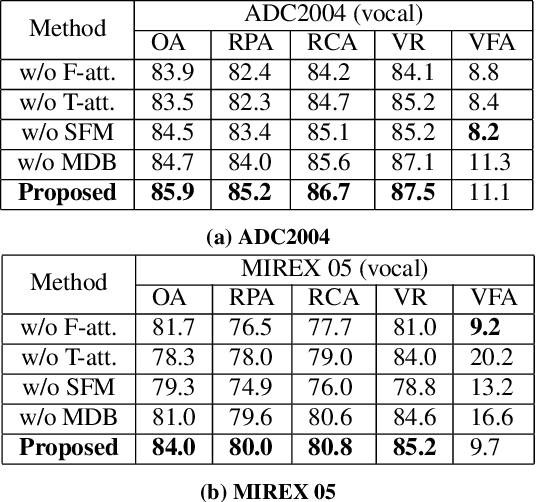
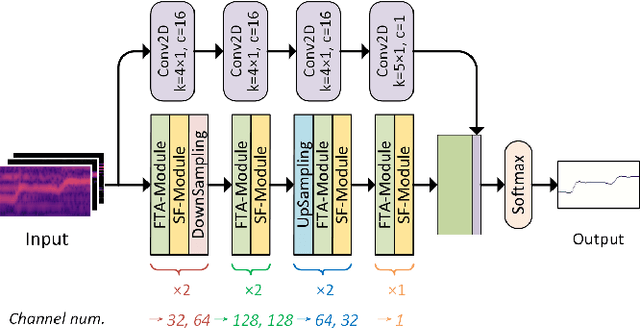
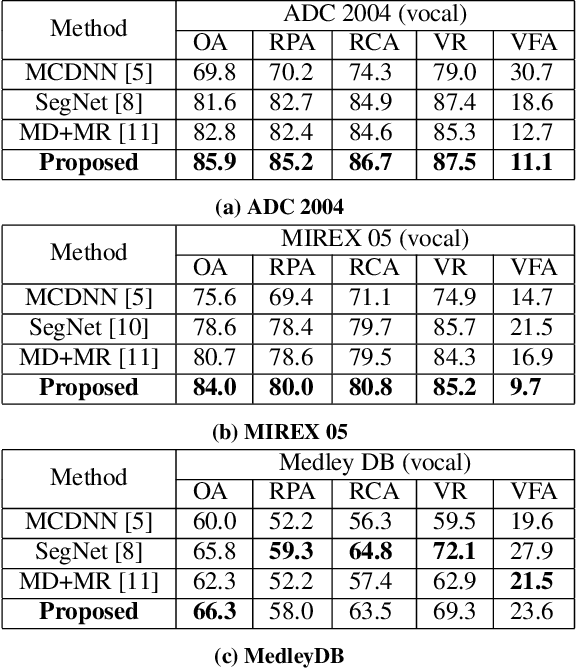
Musical audio is generally composed of three physical properties: frequency, time and magnitude. Interestingly, human auditory periphery also provides neural codes for each of these dimensions to perceive music. Inspired by these intrinsic characteristics, a frequency-temporal attention network is proposed to mimic human auditory for singing melody extraction. In particular, the proposed model contains frequency-temporal attention modules and a selective fusion module corresponding to these three physical properties. The frequency attention module is used to select the same activation frequency bands as did in cochlear and the temporal attention module is responsible for analyzing temporal patterns. Finally, the selective fusion module is suggested to recalibrate magnitudes and fuse the raw information for prediction. In addition, we propose to use another branch to simultaneously predict the presence of singing voice melody. The experimental results show that the proposed model outperforms existing state-of-the-art methods.
Adversarial Stylometry in the Wild: Transferable Lexical Substitution Attacks on Author Profiling
Jan 27, 2021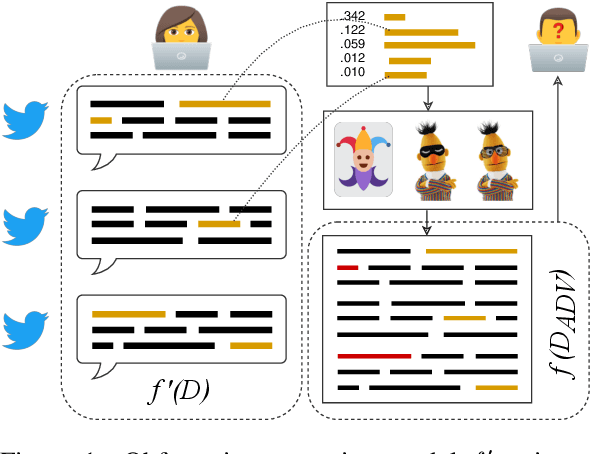


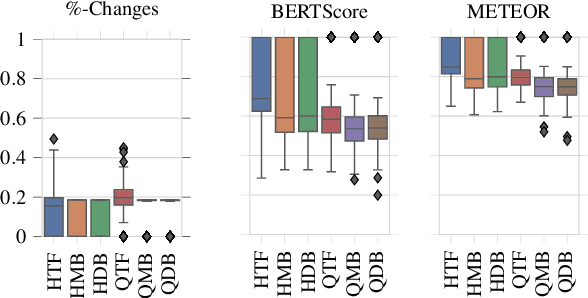
Written language contains stylistic cues that can be exploited to automatically infer a variety of potentially sensitive author information. Adversarial stylometry intends to attack such models by rewriting an author's text. Our research proposes several components to facilitate deployment of these adversarial attacks in the wild, where neither data nor target models are accessible. We introduce a transformer-based extension of a lexical replacement attack, and show it achieves high transferability when trained on a weakly labeled corpus -- decreasing target model performance below chance. While not completely inconspicuous, our more successful attacks also prove notably less detectable by humans. Our framework therefore provides a promising direction for future privacy-preserving adversarial attacks.
Integrating Domain Knowledge in Data-driven Earth Observation with Process Convolutions
Apr 16, 2021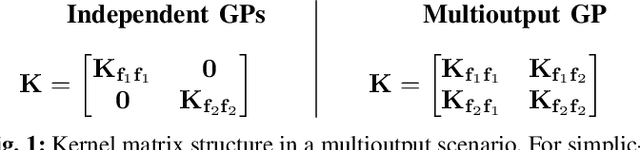
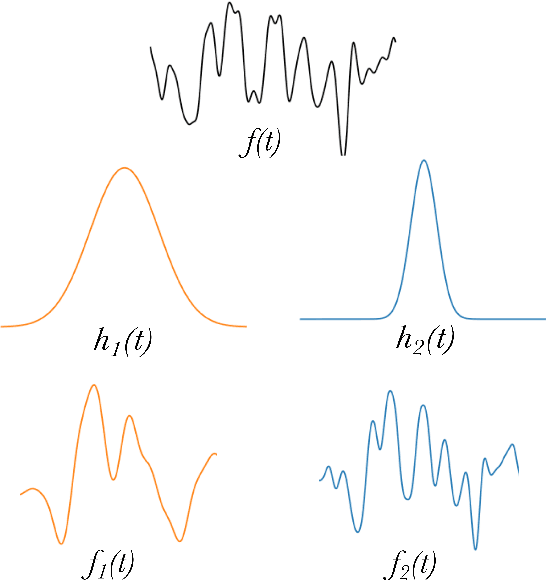
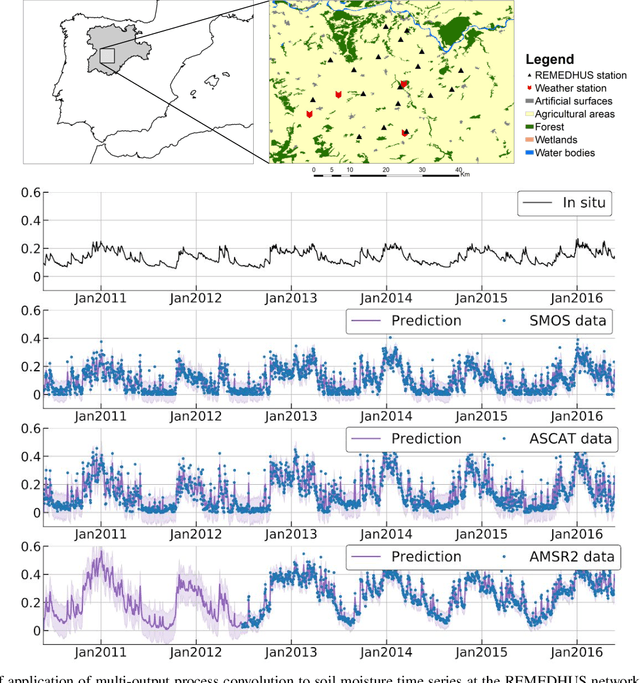
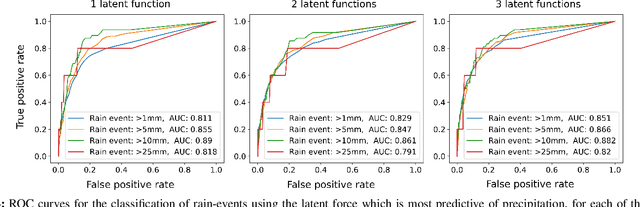
The modelling of Earth observation data is a challenging problem, typically approached by either purely mechanistic or purely data-driven methods. Mechanistic models encode the domain knowledge and physical rules governing the system. Such models, however, need the correct specification of all interactions between variables in the problem and the appropriate parameterization is a challenge in itself. On the other hand, machine learning approaches are flexible data-driven tools, able to approximate arbitrarily complex functions, but lack interpretability and struggle when data is scarce or in extrapolation regimes. In this paper, we argue that hybrid learning schemes that combine both approaches can address all these issues efficiently. We introduce Gaussian process (GP) convolution models for hybrid modelling in Earth observation (EO) problems. We specifically propose the use of a class of GP convolution models called latent force models (LFMs) for EO time series modelling, analysis and understanding. LFMs are hybrid models that incorporate physical knowledge encoded in differential equations into a multioutput GP model. LFMs can transfer information across time-series, cope with missing observations, infer explicit latent functions forcing the system, and learn parameterizations which are very helpful for system analysis and interpretability. We consider time series of soil moisture from active (ASCAT) and passive (SMOS, AMSR2) microwave satellites. We show how assuming a first order differential equation as governing equation, the model automatically estimates the e-folding time or decay rate related to soil moisture persistence and discovers latent forces related to precipitation. The proposed hybrid methodology reconciles the two main approaches in remote sensing parameter estimation by blending statistical learning and mechanistic modeling.
Deep Positional and Relational Feature Learning for Rotation-Invariant Point Cloud Analysis
Nov 18, 2020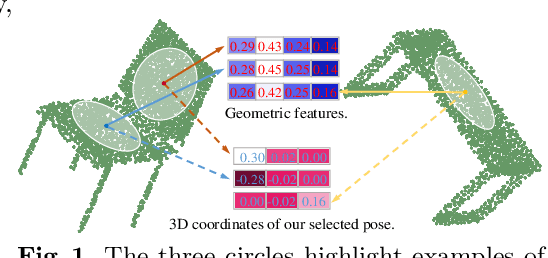
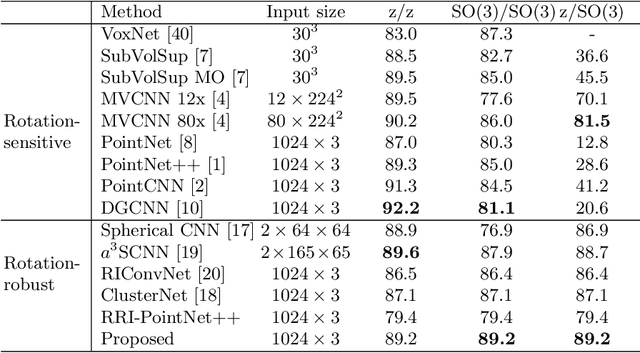
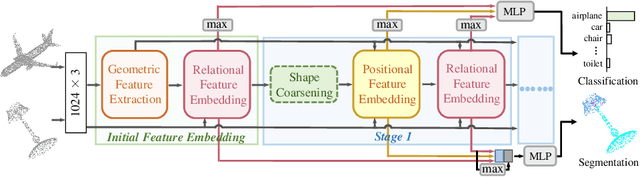
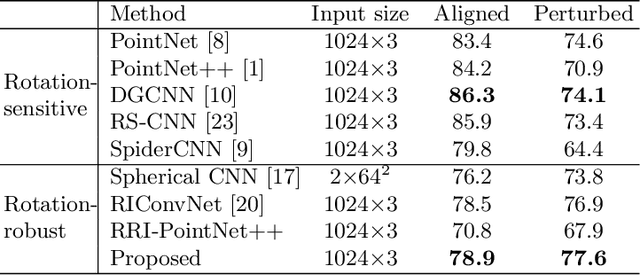
In this paper we propose a rotation-invariant deep network for point clouds analysis. Point-based deep networks are commonly designed to recognize roughly aligned 3D shapes based on point coordinates, but suffer from performance drops with shape rotations. Some geometric features, e.g., distances and angles of points as inputs of network, are rotation-invariant but lose positional information of points. In this work, we propose a novel deep network for point clouds by incorporating positional information of points as inputs while yielding rotation-invariance. The network is hierarchical and relies on two modules: a positional feature embedding block and a relational feature embedding block. Both modules and the whole network are proven to be rotation-invariant when processing point clouds as input. Experiments show state-of-the-art classification and segmentation performances on benchmark datasets, and ablation studies demonstrate effectiveness of the network design.
AI-driven Bayesian inference of statistical microstructure descriptors from finite-frequency waves
Apr 16, 2021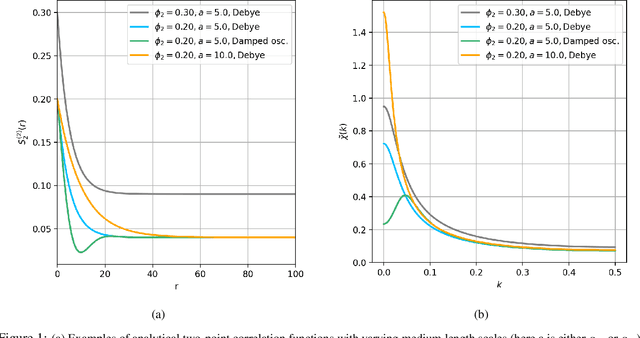
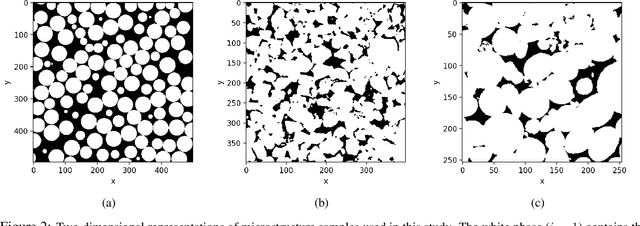
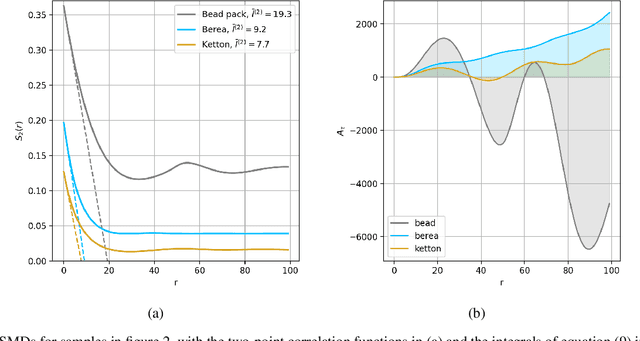
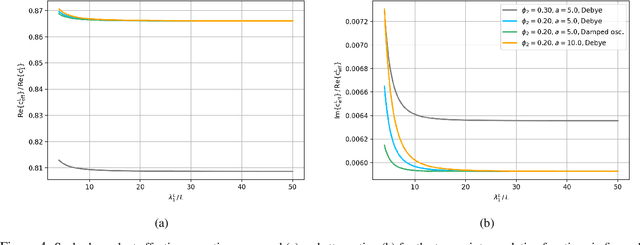
The ability to image materials at the microscale from long-wavelength wave data is a major challenge to the geophysical, engineering and medical fields. Here, we present a framework to constrain microstructure geometry and properties from long-scale waves. To realistically quantify microstructures we use two-point statistics, from which we derive scale-dependent effective wave properties - wavespeed and attenuation - using strong-contrast expansions (SCE) for (visco)elastic wavefields. By evaluating various two-point correlation functions we observe that both effective wavespeeds and attenuation of long-scale waves predominantly depend on volume fraction and phase properties, and that especially attenuation at small scales is highly sensitive to the geometry of microstructure heterogeneity (e.g. geometric hyperuniformity) due to incoherent inference of sub-wavelength multiple scattering. Our goal is to infer microstructure properties from observed effective wave parameters. To this end, we use the supervised machine learning method of Random Forests (RF) to construct a Bayesian inference approach. We can accurately resolve two-point correlation functions sampled from various microstructural configurations, including: a bead pack, Berea sandstone and Ketton limestone samples. Importantly, we show that inversion of small scale-induced effective elastic waves yields the best results, particularly compared to single-wave-mode (e.g., acoustic only) information. Additionally, we show that the retrieval of microscale medium contrasts is more difficult - as it is highly ill-posed - and can only be achieved with specific a priori knowledge. Our results are promising for many applications, such as earthquake hazard monitoring,non-destructive testing, imaging fluid flow in porous media, quantifying tissue properties in medical ultrasound, or designing materials with tailor-made wave properties.
HI-Net: Hyperdense Inception 3D UNet for Brain Tumor Segmentation
Dec 12, 2020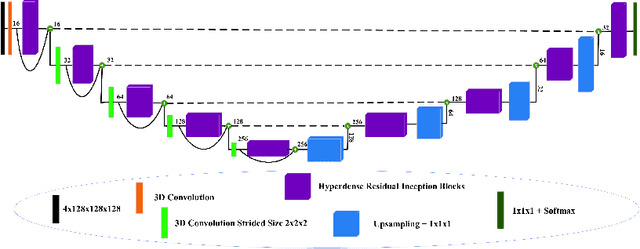
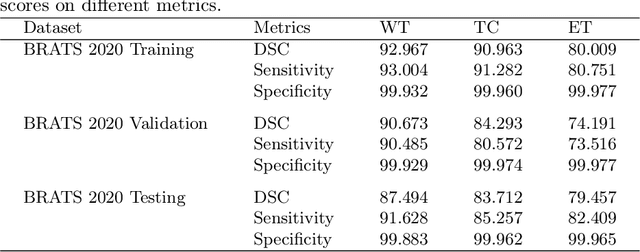
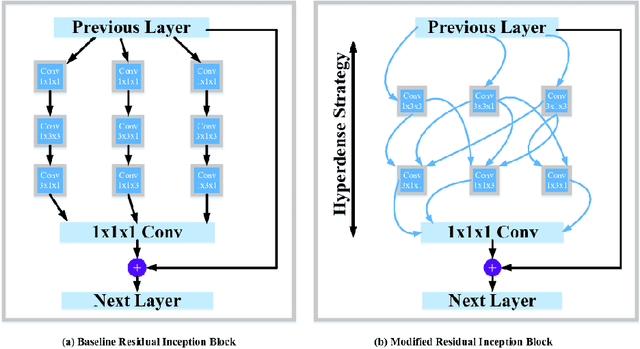

The brain tumor segmentation task aims to classify tissue into the whole tumor (WT), tumor core (TC), and enhancing tumor (ET) classes using multimodel MRI images. Quantitative analysis of brain tumors is critical for clinical decision making. While manual segmentation is tedious, time-consuming, and subjective, this task is at the same time very challenging to automatic segmentation methods. Thanks to the powerful learning ability, convolutional neural networks (CNNs), mainly fully convolutional networks, have shown promising brain tumor segmentation. This paper further boosts the performance of brain tumor segmentation by proposing hyperdense inception 3D UNet (HI-Net), which captures multi-scale information by stacking factorization of 3D weighted convolutional layers in the residual inception block. We use hyper dense connections among factorized convolutional layers to extract more contexual information, with the help of features reusability. We use a dice loss function to cope with class imbalances. We validate the proposed architecture on the multi-modal brain tumor segmentation challenges (BRATS) 2020 testing dataset. Preliminary results on the BRATS 2020 testing set show that achieved by our proposed approach, the dice (DSC) scores of ET, WT, and TC are 0.79457, 0.87494, and 0.83712, respectively.