 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Should I Look at the Head or the Tail? Dual-awareness Attention for Few-Shot Object Detection
Feb 24, 2021
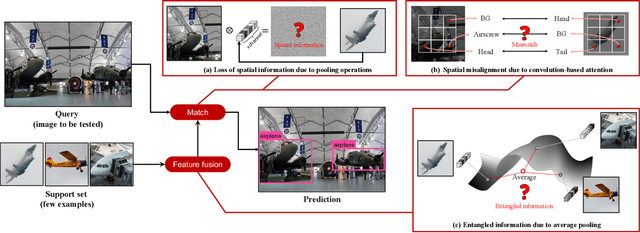

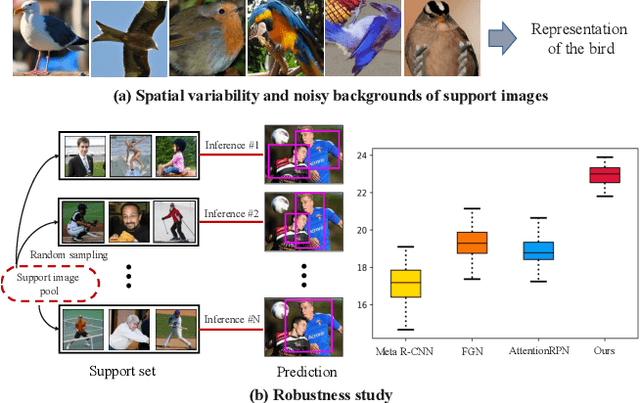
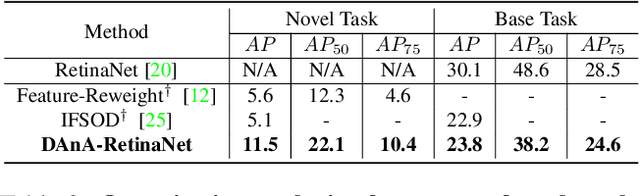
While recent progress has significantly boosted few-shot classification (FSC) performance, few-shot object detection (FSOD) remains challenging for modern learning systems. Existing FSOD systems follow FSC approaches, neglect the problem of spatial misalignment and the risk of information entanglement, and result in low performance. Observing this, we propose a novel Dual-Awareness-Attention (DAnA), which captures the pairwise spatial relationship cross the support and query images. The generated query-position-aware support features are robust to spatial misalignment and used to guide the detection network precisely. Our DAnA component is adaptable to various existing object detection networks and boosts FSOD performance by paying attention to specific semantics conditioned on the query. Experimental results demonstrate that DAnA significantly boosts (48% and 125% relatively) object detection performance on the COCO benchmark. By equipping DAnA, conventional object detection models, Faster-RCNN and RetinaNet, which are not designed explicitly for few-shot learning, reach state-of-the-art performance.
Deep Learning Approach for Singer Voice Classification of Vietnamese Popular Music
Feb 24, 2021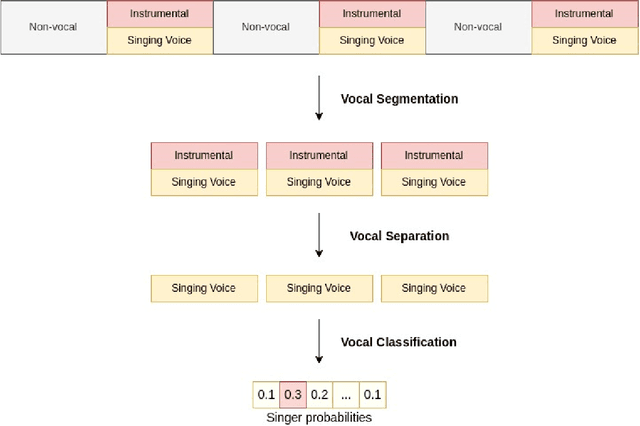
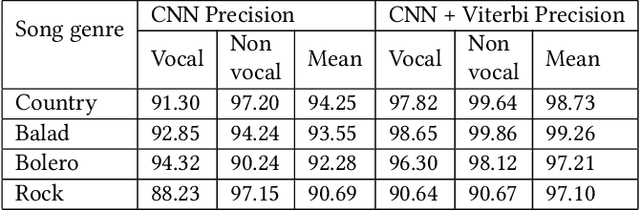
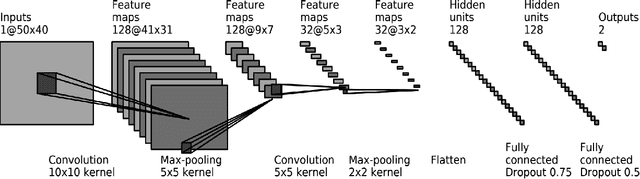

Singer voice classification is a meaningful task in the digital era. With a huge number of songs today, identifying a singer is very helpful for music information retrieval, music properties indexing, and so on. In this paper, we propose a new method to identify the singer's name based on analysis of Vietnamese popular music. We employ the use of vocal segment detection and singing voice separation as the pre-processing steps. The purpose of these steps is to extract the singer's voice from the mixture sound. In order to build a singer classifier, we propose a neural network architecture working with Mel Frequency Cepstral Coefficient as extracted input features from said vocal. To verify the accuracy of our methods, we evaluate on a dataset of 300 Vietnamese songs from 18 famous singers. We achieve an accuracy of 92.84% with 5-fold stratified cross-validation, the best result compared to other methods on the same data set.
* Published in SoICT 2019: Proceedings of the Tenth International Symposium on Information and Communication Technology
Multitask Training with Text Data for End-to-End Speech Recognition
Oct 27, 2020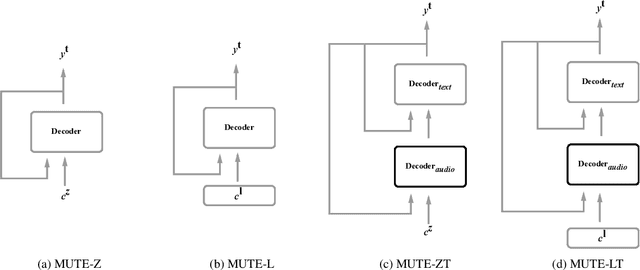
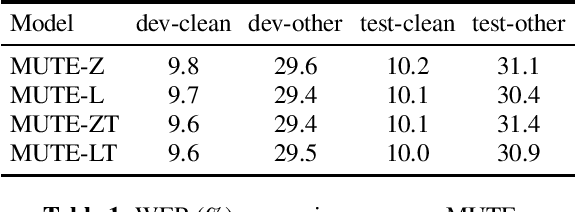

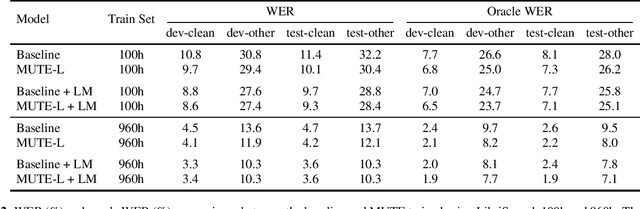
We propose a multitask training method for attention-based end-to-end speech recognition models to better incorporate language level information. We regularize the decoder in a sequence-to-sequence architecture by multitask training it on both the speech recognition task and a next-token prediction language modeling task. Trained on either the 100 hour subset of LibriSpeech or the full 960 hour dataset, the proposed method leads to an 11% relative performance improvement over the baseline and is comparable to language model shallow fusion, without requiring an additional neural network during decoding. Analyses of sample output sentences and the word error rate on rare words demonstrate that the proposed method can incorporate language level information effectively.
Remedies against the Vocabulary Gap in Information Retrieval
Nov 16, 2017
Search engines rely heavily on term-based approaches that represent queries and documents as bags of words. Text---a document or a query---is represented by a bag of its words that ignores grammar and word order, but retains word frequency counts. When presented with a search query, the engine then ranks documents according to their relevance scores by computing, among other things, the matching degrees between query and document terms. While term-based approaches are intuitive and effective in practice, they are based on the hypothesis that documents that exactly contain the query terms are highly relevant regardless of query semantics. Inversely, term-based approaches assume documents that do not contain query terms as irrelevant. However, it is known that a high matching degree at the term level does not necessarily mean high relevance and, vice versa, documents that match null query terms may still be relevant. Consequently, there exists a vocabulary gap between queries and documents that occurs when both use different words to describe the same concepts. It is the alleviation of the effect brought forward by this vocabulary gap that is the topic of this dissertation. More specifically, we propose (1) methods to formulate an effective query from complex textual structures and (2) latent vector space models that circumvent the vocabulary gap in information retrieval.
Syntactic representation learning for neural network based TTS with syntactic parse tree traversal
Dec 13, 2020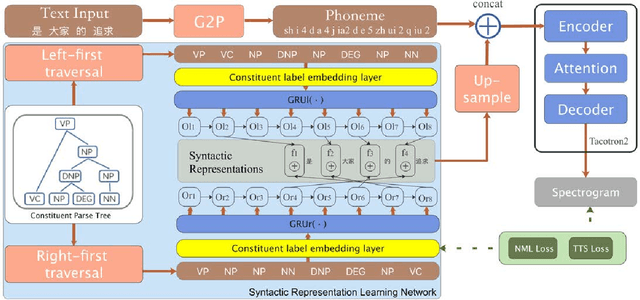

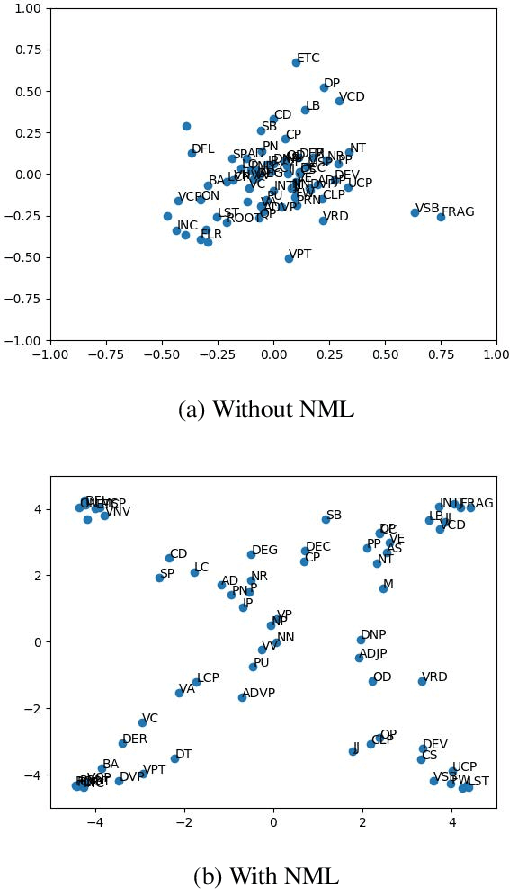
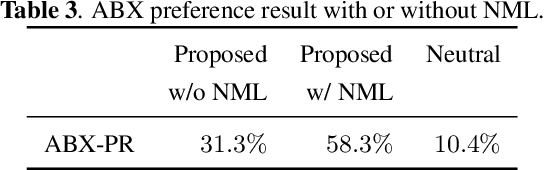
Syntactic structure of a sentence text is correlated with the prosodic structure of the speech that is crucial for improving the prosody and naturalness of a text-to-speech (TTS) system. Nowadays TTS systems usually try to incorporate syntactic structure information with manually designed features based on expert knowledge. In this paper, we propose a syntactic representation learning method based on syntactic parse tree traversal to automatically utilize the syntactic structure information. Two constituent label sequences are linearized through left-first and right-first traversals from constituent parse tree. Syntactic representations are then extracted at word level from each constituent label sequence by a corresponding uni-directional gated recurrent unit (GRU) network. Meanwhile, nuclear-norm maximization loss is introduced to enhance the discriminability and diversity of the embeddings of constituent labels. Upsampled syntactic representations and phoneme embeddings are concatenated to serve as the encoder input of Tacotron2. Experimental results demonstrate the effectiveness of our proposed approach, with mean opinion score (MOS) increasing from 3.70 to 3.82 and ABX preference exceeding by 17% compared with the baseline. In addition, for sentences with multiple syntactic parse trees, prosodic differences can be clearly perceived from the synthesized speeches.
Frequency-Temporal Attention Network for Singing Melody Extraction
Feb 19, 2021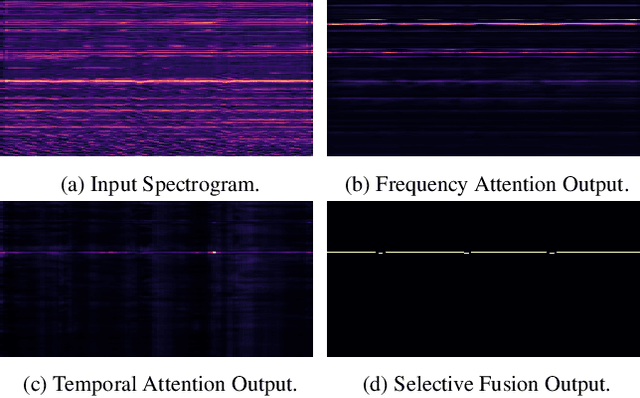
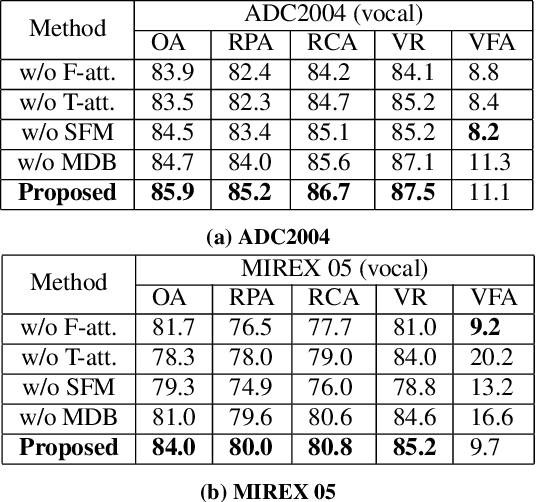
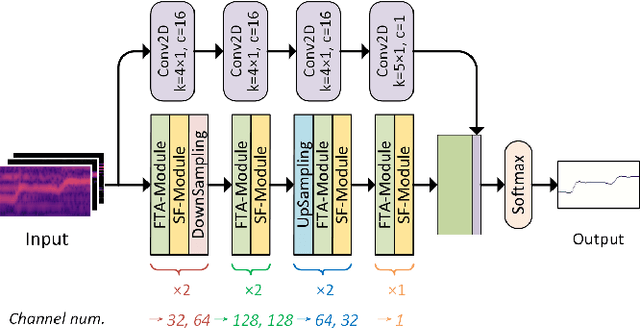
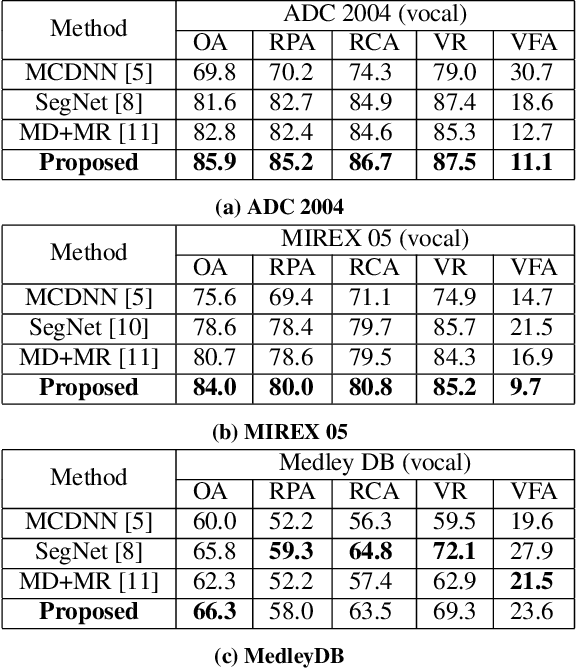
Musical audio is generally composed of three physical properties: frequency, time and magnitude. Interestingly, human auditory periphery also provides neural codes for each of these dimensions to perceive music. Inspired by these intrinsic characteristics, a frequency-temporal attention network is proposed to mimic human auditory for singing melody extraction. In particular, the proposed model contains frequency-temporal attention modules and a selective fusion module corresponding to these three physical properties. The frequency attention module is used to select the same activation frequency bands as did in cochlear and the temporal attention module is responsible for analyzing temporal patterns. Finally, the selective fusion module is suggested to recalibrate magnitudes and fuse the raw information for prediction. In addition, we propose to use another branch to simultaneously predict the presence of singing voice melody. The experimental results show that the proposed model outperforms existing state-of-the-art methods.
Robust Egocentric Photo-realistic Facial Expression Transfer for Virtual Reality
Apr 10, 2021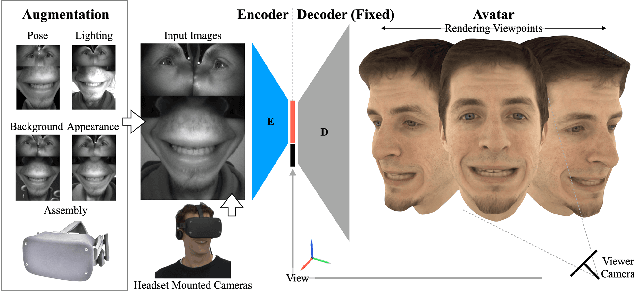
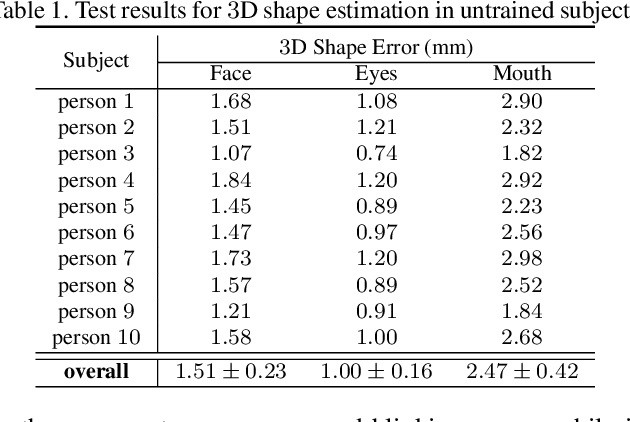

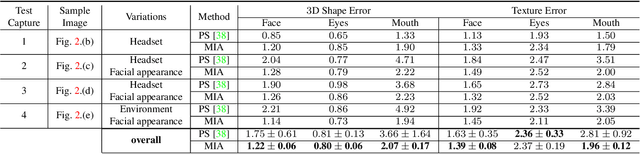
Social presence, the feeling of being there with a real person, will fuel the next generation of communication systems driven by digital humans in virtual reality (VR). The best 3D video-realistic VR avatars that minimize the uncanny effect rely on person-specific (PS) models. However, these PS models are time-consuming to build and are typically trained with limited data variability, which results in poor generalization and robustness. Major sources of variability that affects the accuracy of facial expression transfer algorithms include using different VR headsets (e.g., camera configuration, slop of the headset), facial appearance changes over time (e.g., beard, make-up), and environmental factors (e.g., lighting, backgrounds). This is a major drawback for the scalability of these models in VR. This paper makes progress in overcoming these limitations by proposing an end-to-end multi-identity architecture (MIA) trained with specialized augmentation strategies. MIA drives the shape component of the avatar from three cameras in the VR headset (two eyes, one mouth), in untrained subjects, using minimal personalized information (i.e., neutral 3D mesh shape). Similarly, if the PS texture decoder is available, MIA is able to drive the full avatar (shape+texture) robustly outperforming PS models in challenging scenarios. Our key contribution to improve robustness and generalization, is that our method implicitly decouples, in an unsupervised manner, the facial expression from nuisance factors (e.g., headset, environment, facial appearance). We demonstrate the superior performance and robustness of the proposed method versus state-of-the-art PS approaches in a variety of experiments.
They are Not Completely Useless: Towards Recycling Transferable Unlabeled Data for Class-Mismatched Semi-Supervised Learning
Nov 27, 2020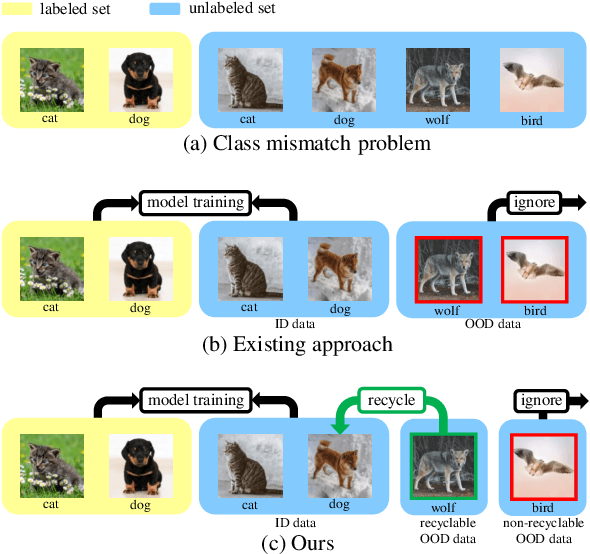
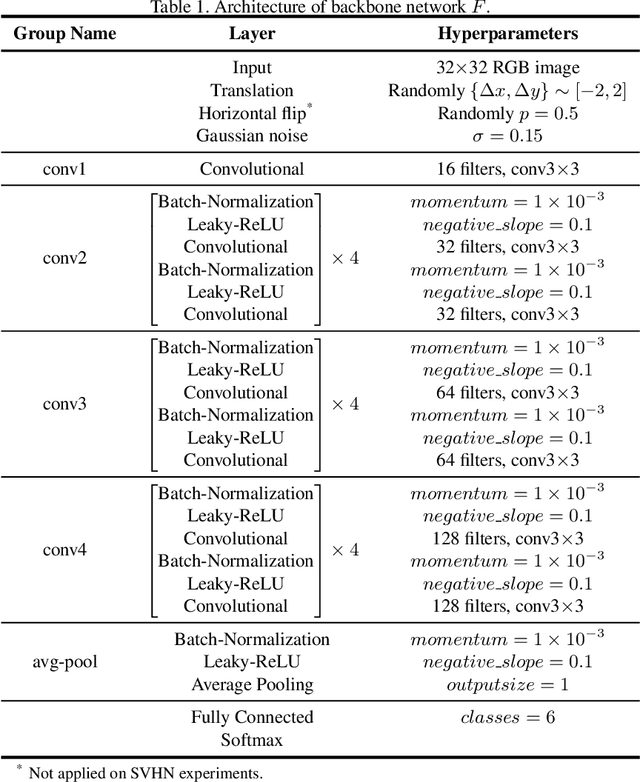
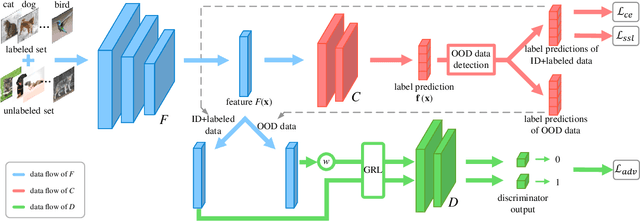
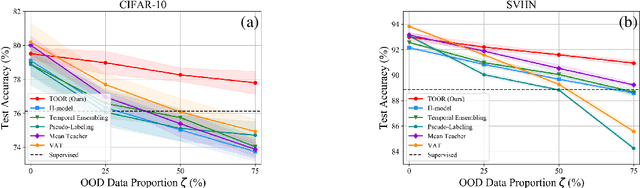
Semi-Supervised Learning (SSL) with mismatched classes deals with the problem that the classes-of-interests in the limited labeled data is only a subset of the classes in massive unlabeled data. As a result, the classes only possessed by the unlabeled data may mislead the classifier training and thus hindering the realistic landing of various SSL methods. To solve this problem, existing methods usually divide unlabeled data to in-distribution (ID) data and out-of-distribution (OOD) data, and directly discard or weaken the OOD data to avoid their adverse impact. In other words, they treat OOD data as completely useless and thus the potential valuable information for classification contained by them is totally ignored. To remedy this defect, this paper proposes a "Transferable OOD data Recycling" (TOOR) method which properly utilizes ID data as well as the "recyclable" OOD data to enrich the information for conducting class-mismatched SSL. Specifically, TOOR firstly attributes all unlabeled data to ID data or OOD data, among which the ID data are directly used for training. Then we treat the OOD data that have a close relationship with ID data and labeled data as recyclable, and employ adversarial domain adaptation to project them to the space of ID data and labeled data. In other words, the recyclability of an OOD datum is evaluated by its transferability, and the recyclable OOD data are transferred so that they are compatible with the distribution of known classes-of-interests. Consequently, our TOOR method extracts more information from unlabeled data than existing approaches, so it can achieve the improved performance which is demonstrated by the experiments on typical benchmark datasets.
Exploiting Vulnerability of Pooling in Convolutional Neural Networks by Strict Layer-Output Manipulation for Adversarial Attacks
Dec 21, 2020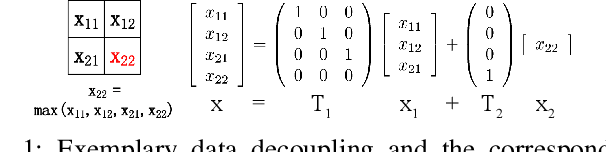
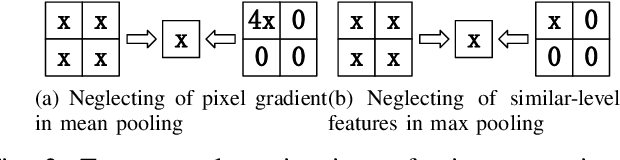


Convolutional neural networks (CNN) have been more and more applied in mobile robotics such as intelligent vehicles. Security of CNNs in robotics applications is an important issue, for which potential adversarial attacks on CNNs are worth research. Pooling is a typical step of dimension reduction and information discarding in CNNs. Such information discarding may result in mis-deletion and mis-preservation of data features which largely influence the output of the network. This may aggravate the vulnerability of CNNs to adversarial attacks. In this paper, we conduct adversarial attacks on CNNs from the perspective of network structure by investigating and exploiting the vulnerability of pooling. First, a novel adversarial attack methodology named Strict Layer-Output Manipulation (SLOM) is proposed. Then an attack method based on Strict Pooling Manipulation (SPM) which is an instantiation of the SLOM spirit is designed to effectively realize both type I and type II adversarial attacks on a target CNN. Performances of attacks based on SPM at different depths are also investigated and compared. Moreover, performances of attack methods designed by instantiating the SLOM spirit with different operation layers of CNNs are compared. Experiment results reflect that pooling tends to be more vulnerable to adversarial attacks than other operations in CNNs.
Visual analytics of set data for knowledge discovery and member selection support
Apr 04, 2021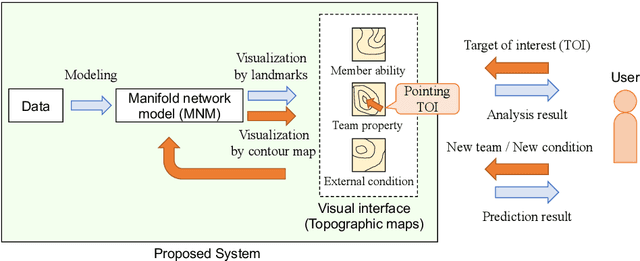
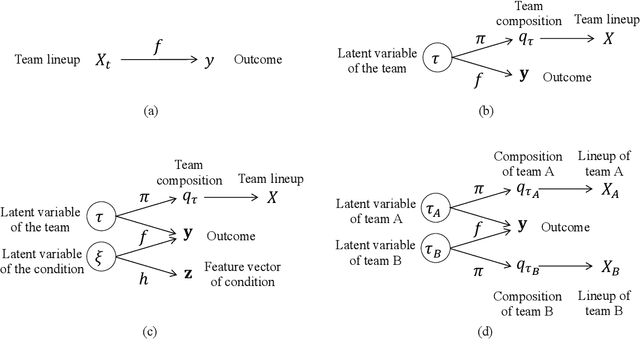
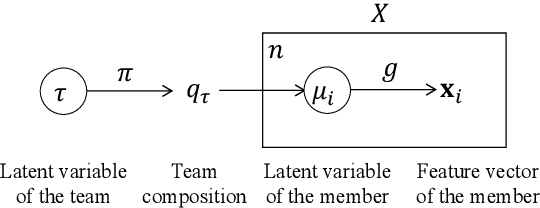
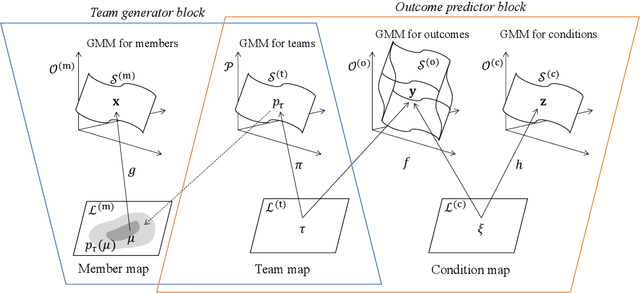
Visual analytics (VA) is a visually assisted exploratory analysis approach in which knowledge discovery is executed interactively between the user and system. The purpose of this study is to develop a method for the VA of set data aimed at supporting knowledge discovery and member selection. A typical target application is a visual support system for team analysis and member selection, by which users can analyze past teams and examine candidate lineups for new teams. Because there are several difficulties, such as the combinatorial explosion problem, developing a VA system of set data is challenging. In this study, we first define the requirements that the target system should satisfy and clarify the accompanying challenges. Then we propose a method for the VA of set data, which satisfies the requirements. The key idea is to model the generation process of sets and their outputs using a manifold network model. The proposed method visualizes the relevant factors as a set of topographic maps on which various information is visualized. Furthermore, using the topographic maps as a bidirectional interface, users can indicate their targets of interest in the system on these maps. We demonstrate the proposed method by applying it to basketball teams, showing how past teams are analyzed and how new lineups are examined. Because the method can be adapted to individual application cases by extending the network structure, it can be a general method by which practical systems can be built.