 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Structure-aware Pre-training for Table Understanding with Tree-based Transformers
Oct 21, 2020
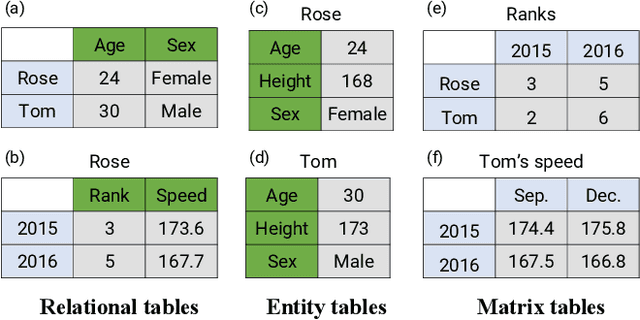
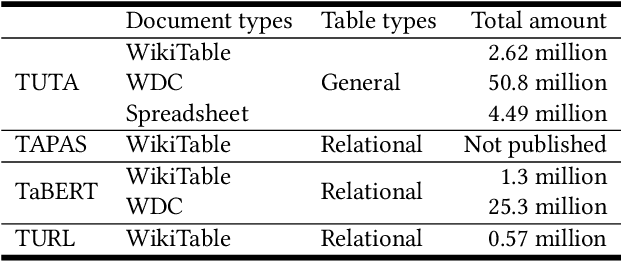
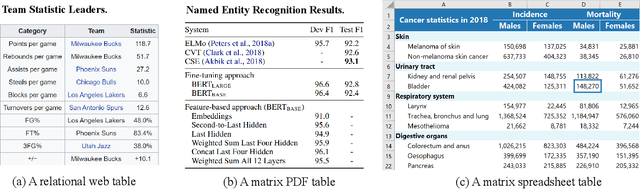

Tables are widely used with various structures to organize and present data. Recent attempts on table understanding mainly focus on relational tables, yet overlook to other common table structures. In this paper, we propose TUTA, a unified pre-training architecture for understanding generally structured tables. Since understanding a table needs to leverage both spatial, hierarchical, and semantic information, we adapt the self-attention strategy with several key structure-aware mechanisms. First, we propose a novel tree-based structure called a bi-dimensional coordinate tree, to describe both the spatial and hierarchical information in tables. Upon this, we extend the pre-training architecture with two core mechanisms, namely the tree-based attention and tree-based position embedding. Moreover, to capture table information in a progressive manner, we devise three pre-training objectives to enable representations at the token, cell, and table levels. TUTA pre-trains on a wide range of unlabeled tables and fine-tunes on a critical task in the field of table structure understanding, i.e. cell type classification. Experiment results show that TUTA is highly effective, achieving state-of-the-art on four well-annotated cell type classification datasets.
A Hierarchical Reasoning Graph Neural Network for The Automatic Scoring of Answer Transcriptions in Video Job Interviews
Dec 22, 2020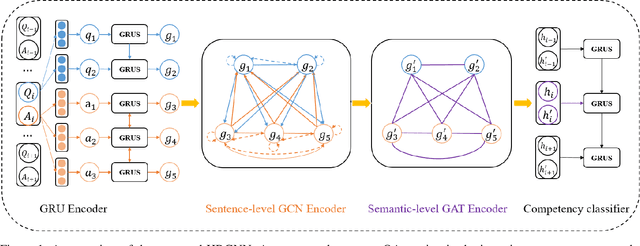
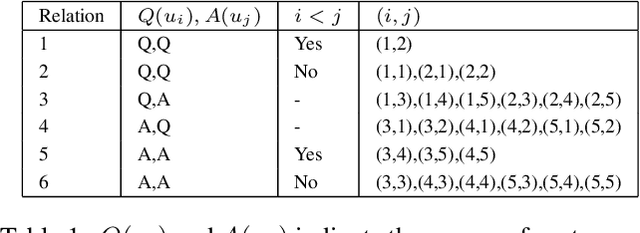
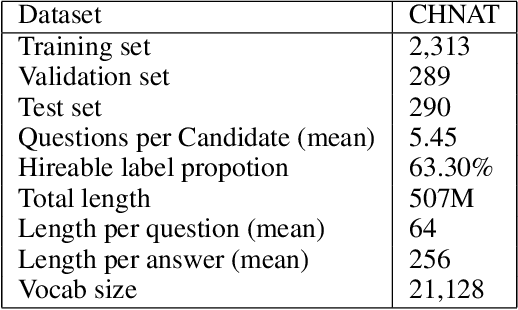
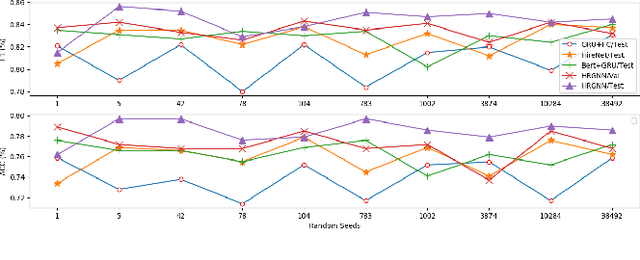
We address the task of automatically scoring the competency of candidates based on textual features, from the automatic speech recognition (ASR) transcriptions in the asynchronous video job interview (AVI). The key challenge is how to construct the dependency relation between questions and answers, and conduct the semantic level interaction for each question-answer (QA) pair. However, most of the recent studies in AVI focus on how to represent questions and answers better, but ignore the dependency information and interaction between them, which is critical for QA evaluation. In this work, we propose a Hierarchical Reasoning Graph Neural Network (HRGNN) for the automatic assessment of question-answer pairs. Specifically, we construct a sentence-level relational graph neural network to capture the dependency information of sentences in or between the question and the answer. Based on these graphs, we employ a semantic-level reasoning graph attention network to model the interaction states of the current QA session. Finally, we propose a gated recurrent unit encoder to represent the temporal question-answer pairs for the final prediction. Empirical results conducted on CHNAT (a real-world dataset) validate that our proposed model significantly outperforms text-matching based benchmark models. Ablation studies and experimental results with 10 random seeds also show the effectiveness and stability of our models.
Remedies against the Vocabulary Gap in Information Retrieval
Nov 16, 2017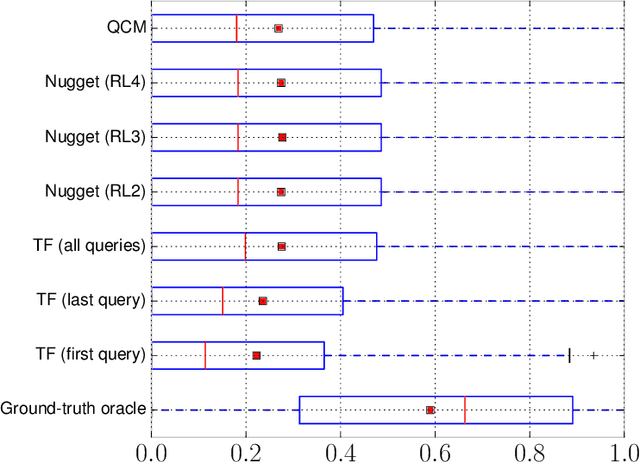
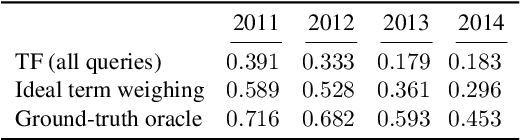
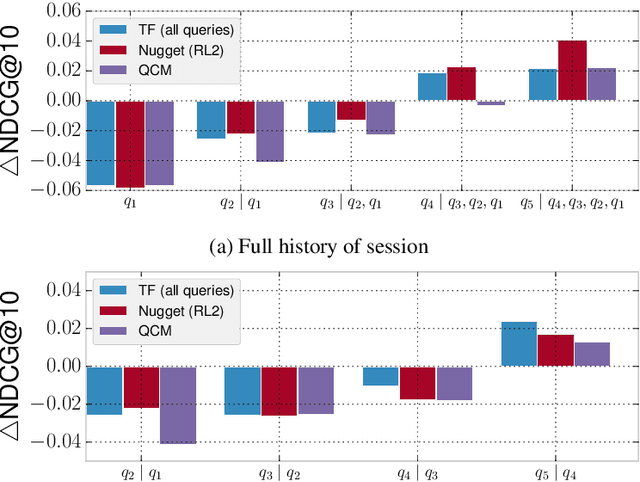
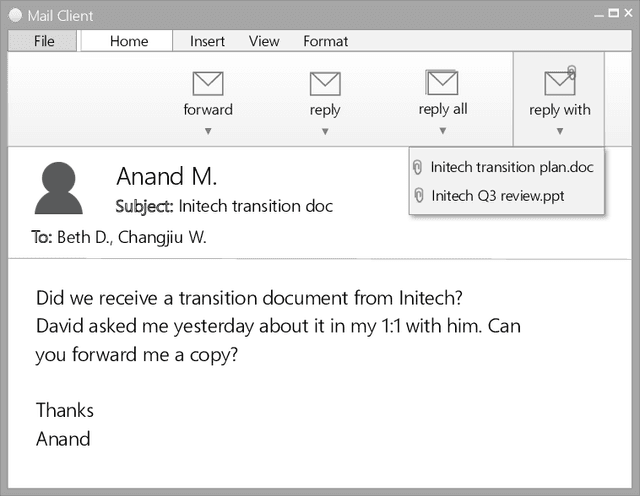
Search engines rely heavily on term-based approaches that represent queries and documents as bags of words. Text---a document or a query---is represented by a bag of its words that ignores grammar and word order, but retains word frequency counts. When presented with a search query, the engine then ranks documents according to their relevance scores by computing, among other things, the matching degrees between query and document terms. While term-based approaches are intuitive and effective in practice, they are based on the hypothesis that documents that exactly contain the query terms are highly relevant regardless of query semantics. Inversely, term-based approaches assume documents that do not contain query terms as irrelevant. However, it is known that a high matching degree at the term level does not necessarily mean high relevance and, vice versa, documents that match null query terms may still be relevant. Consequently, there exists a vocabulary gap between queries and documents that occurs when both use different words to describe the same concepts. It is the alleviation of the effect brought forward by this vocabulary gap that is the topic of this dissertation. More specifically, we propose (1) methods to formulate an effective query from complex textual structures and (2) latent vector space models that circumvent the vocabulary gap in information retrieval.
Network topology change-point detection from graph signals with prior spectral signatures
Oct 21, 2020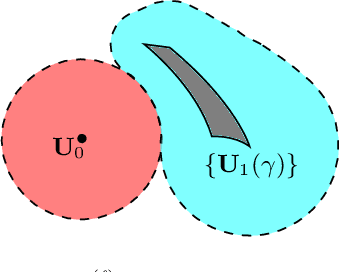
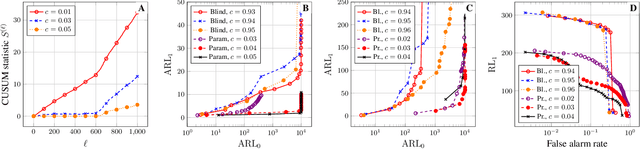
We consider the problem of sequential graph topology change-point detection from graph signals. We assume that signals on the nodes of the graph are regularized by the underlying graph structure via a graph filtering model, which we then leverage to distill the graph topology change-point detection problem to a subspace detection problem. We demonstrate how prior information on the spectral signature of the post-change graph can be incorporated to implicitly denoise the observed sequential data, thus leading to a natural CUSUM-based algorithm for change-point detection. Numerical experiments illustrate the performance of our proposed approach, particularly underscoring the benefits of (potentially noisy) prior information.
Uniting Heterogeneity, Inductiveness, and Efficiency for Graph Representation Learning
Apr 11, 2021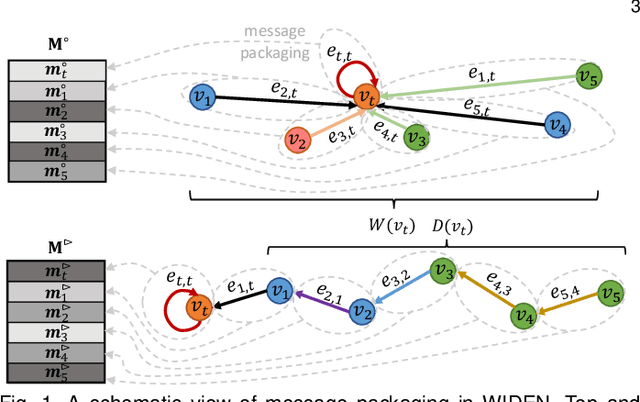
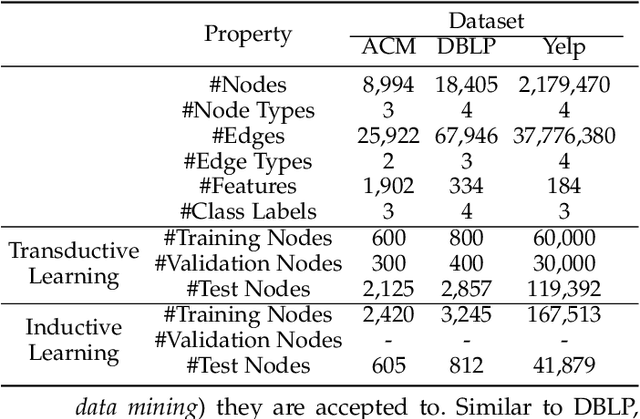
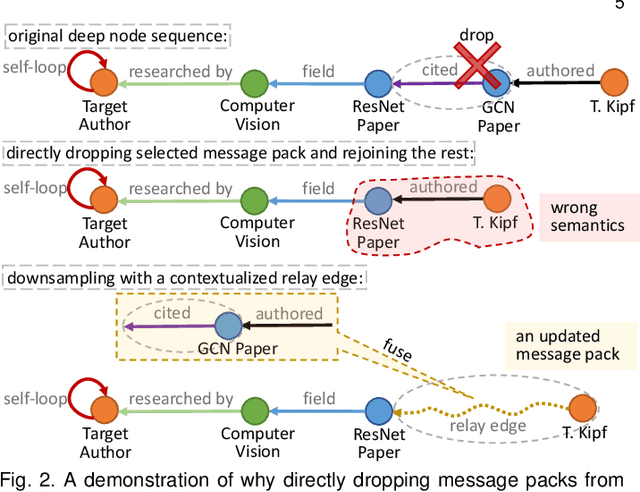
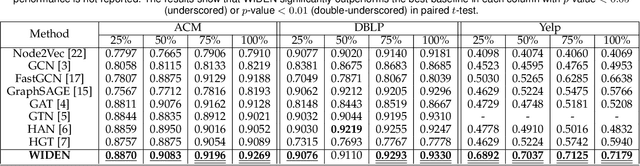
With the ubiquitous graph-structured data in various applications, models that can learn compact but expressive vector representations of nodes have become highly desirable. Recently, bearing the message passing paradigm, graph neural networks (GNNs) have greatly advanced the performance of node representation learning on graphs. However, a majority class of GNNs are only designed for homogeneous graphs, leading to inferior adaptivity to the more informative heterogeneous graphs with various types of nodes and edges. Also, despite the necessity of inductively producing representations for completely new nodes (e.g., in streaming scenarios), few heterogeneous GNNs can bypass the transductive learning scheme where all nodes must be known during training. Furthermore, the training efficiency of most heterogeneous GNNs has been hindered by their sophisticated designs for extracting the semantics associated with each meta path or relation. In this paper, we propose WIde and DEep message passing Network (WIDEN) to cope with the aforementioned problems about heterogeneity, inductiveness, and efficiency that are rarely investigated together in graph representation learning. In WIDEN, we propose a novel inductive, meta path-free message passing scheme that packs up heterogeneous node features with their associated edges from both low- and high-order neighbor nodes. To further improve the training efficiency, we innovatively present an active downsampling strategy that drops unimportant neighbor nodes to facilitate faster information propagation. Experiments on three real-world heterogeneous graphs have further validated the efficacy of WIDEN on both transductive and inductive node representation learning, as well as the superior training efficiency against state-of-the-art baselines.
Unmanned Aerial Vehicle Visual Detection and Tracking using Deep Neural Networks: A Performance Benchmark
Mar 29, 2021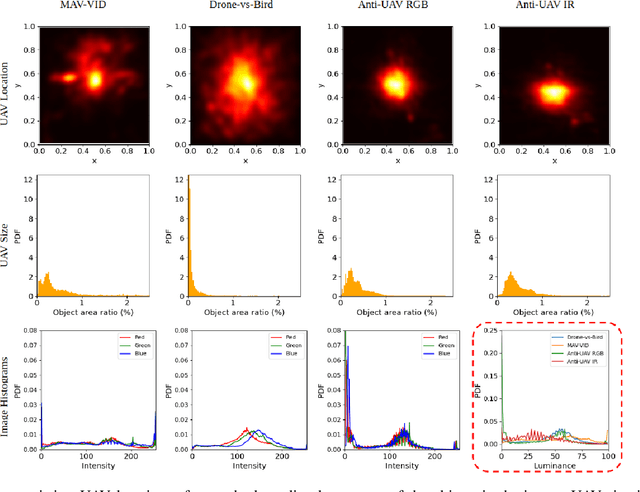
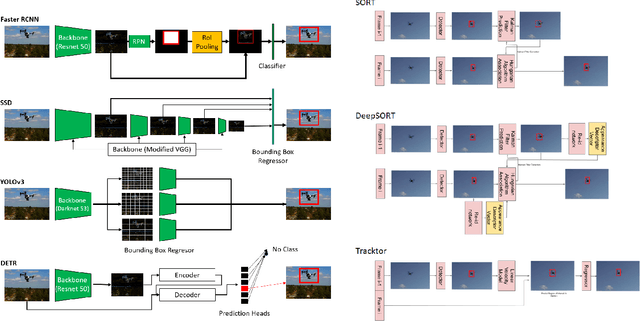
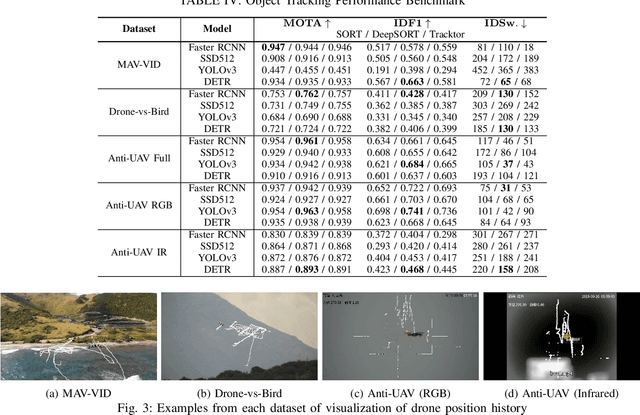
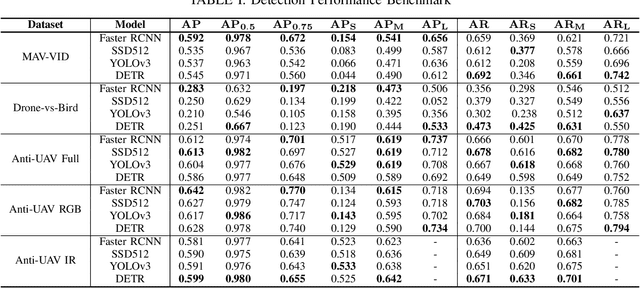
Unmanned Aerial Vehicles (UAV) can pose a major risk for aviation safety, due to both negligent and malicious use. For this reason, the automated detection and tracking of UAV is a fundamental task in aerial security systems. Common technologies for UAV detection include visible-band and thermal infrared imaging, radio frequency and radar. Recent advances in deep neural networks (DNNs) for image-based object detection open the possibility to use visual information for this detection and tracking task. Furthermore, these detection architectures can be implemented as backbones for visual tracking systems, thereby enabling persistent tracking of UAV incursions. To date, no comprehensive performance benchmark exists that applies DNNs to visible-band imagery for UAV detection and tracking. To this end, three datasets with varied environmental conditions for UAV detection and tracking, comprising a total of 241 videos (331,486 images), are assessed using four detection architectures and three tracking frameworks. The best performing detector architecture obtains an mAP of 98.6% and the best performing tracking framework obtains a MOTA of 96.3%. Cross-modality evaluation is carried out between visible and infrared spectrums, achieving a maximal 82.8% mAP on visible images when training in the infrared modality. These results provide the first public multi-approach benchmark for state-of-the-art deep learning-based methods and give insight into which detection and tracking architectures are effective in the UAV domain.
Zero-shot Learning for Relation Extraction
Nov 13, 2020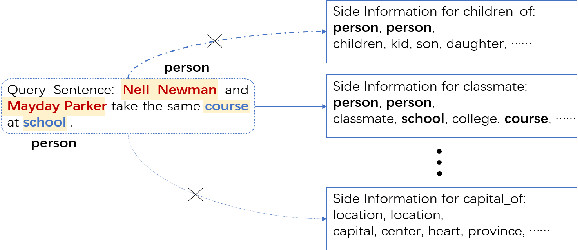

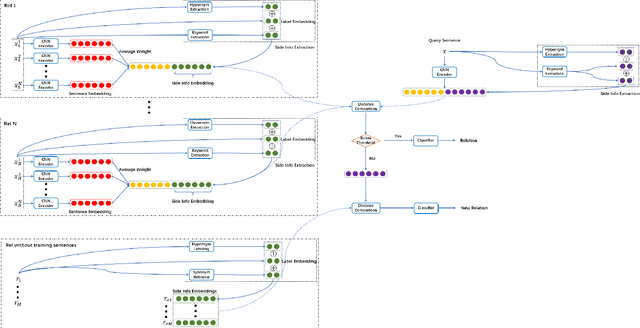
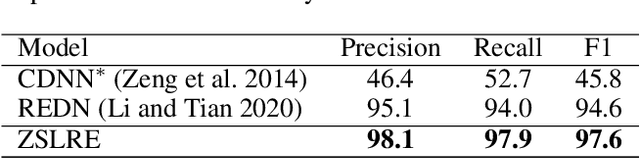
Most existing supervised and few-shot learning relation extraction methods have relied on labeled training data. However, in real-world scenarios, there exist many relations for which there is no available training data. We address this issue from the perspective of zero-shot learning (ZSL) which is similar to the way humans learn and recognize new concepts with no prior knowledge. We propose a zero-shot learning relation extraction (ZSLRE) framework, which focuses on recognizing novel relations that have no corresponding labeled data available for training. Our proposed ZSLRE model aims to recognize new relations based on prototypical networks that are modified to utilize side (auxiliary) information. The additional use of side information allows those modified prototype networks to recognize novel relations in addition to recognized previously known relations. We construct side information from labels and their synonyms, hypernyms of name entities, and keywords. We build an automatic hypernym extraction framework to help get hypernyms of various name entities directly from the web. We demonstrate using extensive experiments on two public datasets (NYT and FewRel) that our proposed model significantly outperforms state-of-the-art methods on supervised learning, few-shot learning, and zero-shot learning tasks. Our experimental results also demonstrate the effectiveness and robustness of our proposed model in a combination scenario. Once accepted for publication, we will publish ZSLRE's source code and datasets to enable reproducibility and encourage further research.
Learning Audio-Visual Correlations from Variational Cross-Modal Generation
Feb 14, 2021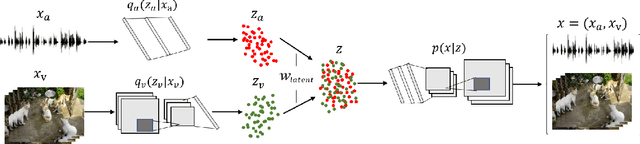
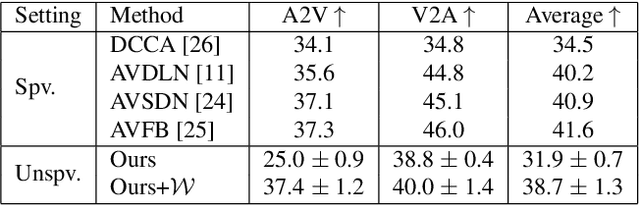

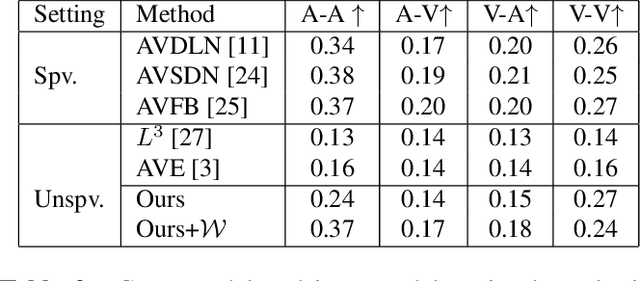
People can easily imagine the potential sound while seeing an event. This natural synchronization between audio and visual signals reveals their intrinsic correlations. To this end, we propose to learn the audio-visual correlations from the perspective of cross-modal generation in a self-supervised manner, the learned correlations can be then readily applied in multiple downstream tasks such as the audio-visual cross-modal localization and retrieval. We introduce a novel Variational AutoEncoder (VAE) framework that consists of Multiple encoders and a Shared decoder (MS-VAE) with an additional Wasserstein distance constraint to tackle the problem. Extensive experiments demonstrate that the optimized latent representation of the proposed MS-VAE can effectively learn the audio-visual correlations and can be readily applied in multiple audio-visual downstream tasks to achieve competitive performance even without any given label information during training.
Retrieving Event-related Human Brain Dynamics from Natural Sentence Reading
Mar 29, 2021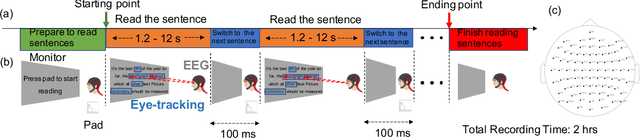
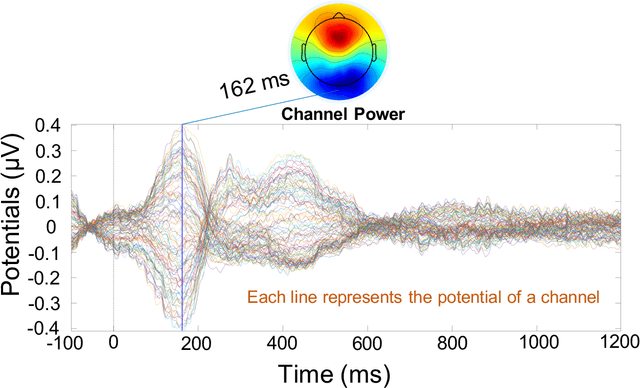
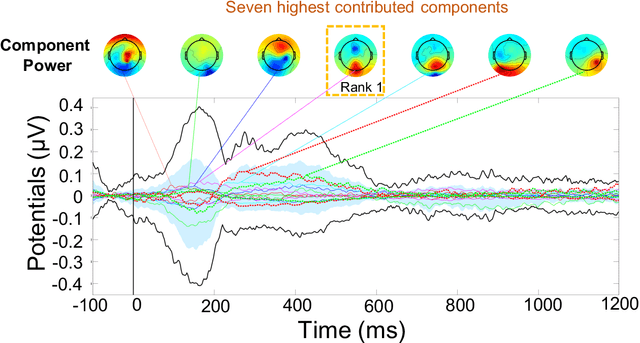
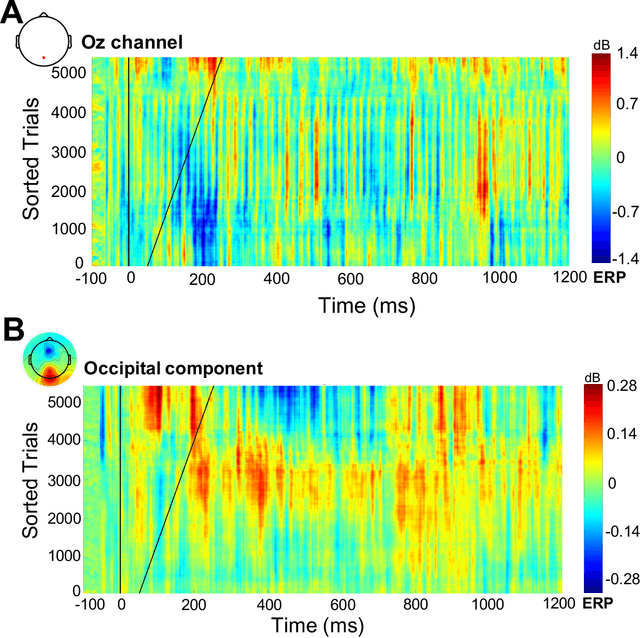
Electroencephalography (EEG) signals recordings when people reading natural languages are commonly used as a cognitive method to interpret human language understanding in neuroscience and psycholinguistics. Previous studies have demonstrated that the human fixation and activation in word reading associated with some brain regions, but it is not clear when and how to measure the brain dynamics across time and frequency domains. In this study, we propose the first analysis of event-related brain potentials (ERPs), and event-related spectral perturbations (ERSPs) on benchmark datasets which consist of sentence-level simultaneous EEG and related eye-tracking recorded from human natural reading experiment tasks. Our results showed peaks evoked at around 162 ms after the stimulus (starting to read each sentence) in the occipital area, indicating the brain retriving lexical and semantic visual information processing approaching 200 ms from the sentence onset. Furthermore, the occipital ERP around 200ms presents negative power and positive power in short and long reaction times. In addition, the occipital ERSP around 200ms demonstrated increased high gamma and decreased low beta and low gamma power, relative to the baseline. Our results implied that most of the semantic-perception responses occurred around the 200ms in alpha, beta and gamma bands of EEG signals. Our findings also provide potential impacts on promoting cognitive natural language processing models evaluation from EEG dynamics.
Project-Level Encoding for Neural Source Code Summarization of Subroutines
Mar 22, 2021
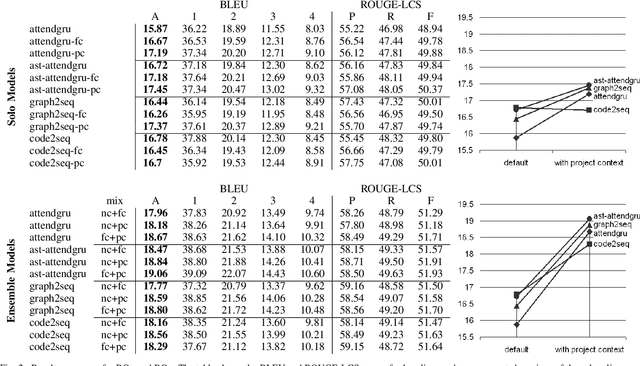
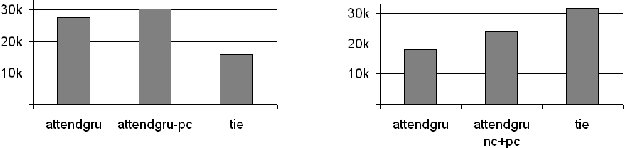
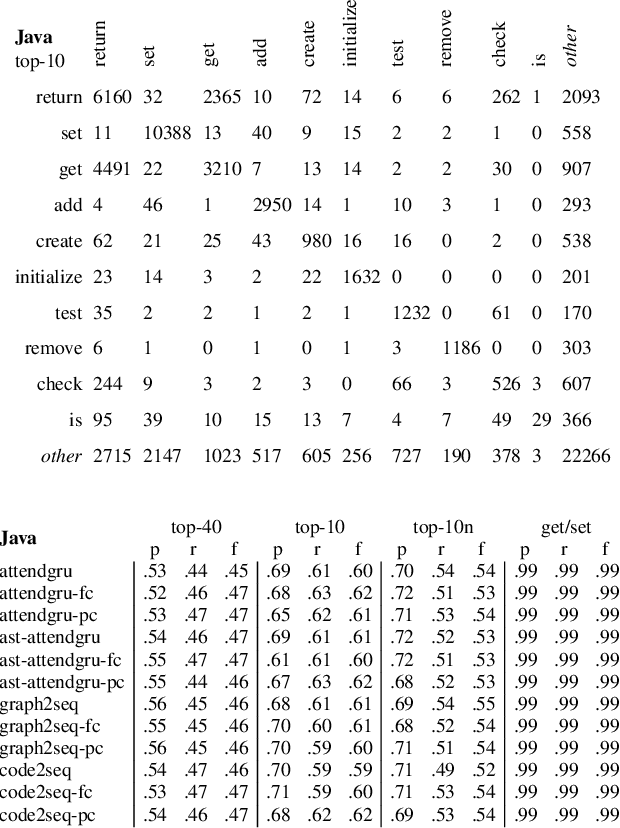
Source code summarization of a subroutine is the task of writing a short, natural language description of that subroutine. The description usually serves in documentation aimed at programmers, where even brief phrase (e.g. "compresses data to a zip file") can help readers rapidly comprehend what a subroutine does without resorting to reading the code itself. Techniques based on neural networks (and encoder-decoder model designs in particular) have established themselves as the state-of-the-art. Yet a problem widely recognized with these models is that they assume the information needed to create a summary is present within the code being summarized itself - an assumption which is at odds with program comprehension literature. Thus a current research frontier lies in the question of encoding source code context into neural models of summarization. In this paper, we present a project-level encoder to improve models of code summarization. By project-level, we mean that we create a vectorized representation of selected code files in a software project, and use that representation to augment the encoder of state-of-the-art neural code summarization techniques. We demonstrate how our encoder improves several existing models, and provide guidelines for maximizing improvement while controlling time and resource costs in model size.