 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Conditional Negative Sampling for Contrastive Learning of Visual Representations
Oct 05, 2020
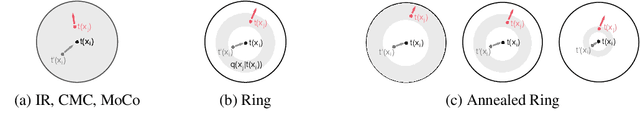
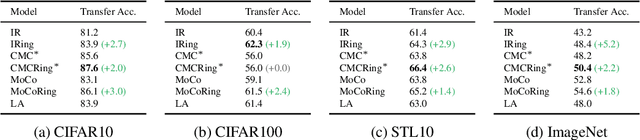

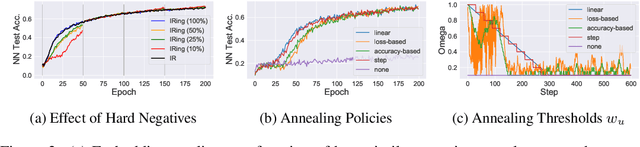
Recent methods for learning unsupervised visual representations, dubbed contrastive learning, optimize the noise-contrastive estimation (NCE) bound on mutual information between two views of an image. NCE uses randomly sampled negative examples to normalize the objective. In this paper, we show that choosing difficult negatives, or those more similar to the current instance, can yield stronger representations. To do this, we introduce a family of mutual information estimators that sample negatives conditionally -- in a "ring" around each positive. We prove that these estimators lower-bound mutual information, with higher bias but lower variance than NCE. Experimentally, we find our approach, applied on top of existing models (IR, CMC, and MoCo) improves accuracy by 2-5% points in each case, measured by linear evaluation on four standard image datasets. Moreover, we find continued benefits when transferring features to a variety of new image distributions from the Meta-Dataset collection and to a variety of downstream tasks such as object detection, instance segmentation, and keypoint detection.
Hyperbolic Graph Embedding with Enhanced Semi-Implicit Variational Inference
Oct 31, 2020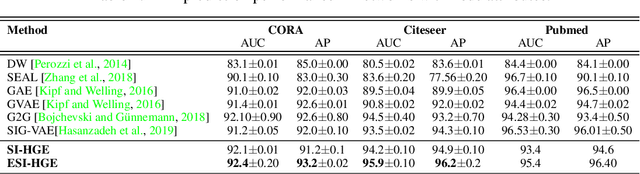
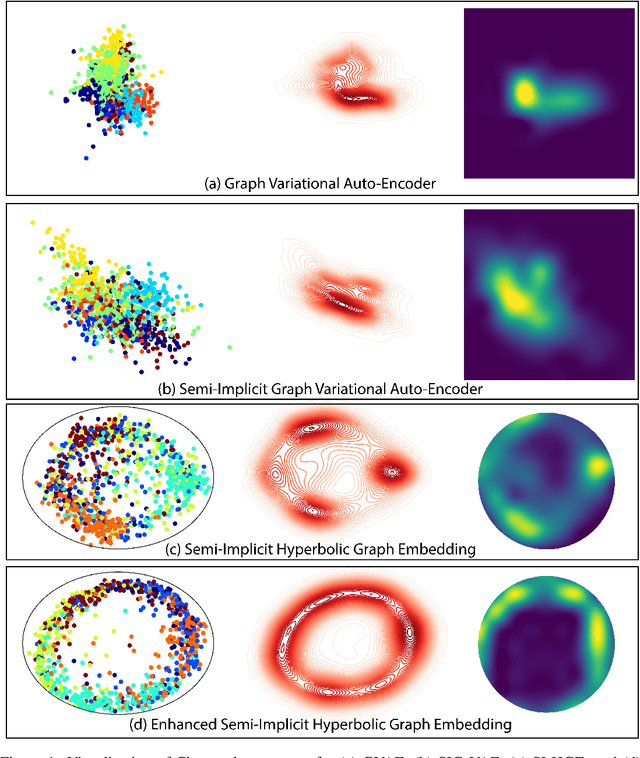
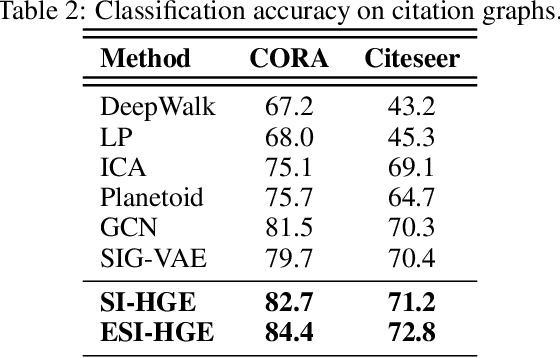
Efficient modeling of relational data arising in physical, social, and information sciences is challenging due to complicated dependencies within the data. In this work we build off of semi-implicit graph variational auto-encoders to capture higher order statistics in a low-dimensional graph latent representation. We incorporate hyperbolic geometry in the latent space through a \poincare embedding to efficiently represent graphs exhibiting hierarchical structure. To address the naive posterior latent distribution assumptions in classical variational inference, we use semi-implicit hierarchical variational Bayes to implicitly capture posteriors of given graph data, which may exhibit heavy tails, multiple modes, skewness, and highly correlated latent structures. We show that the existing semi-implicit variational inference objective provably reduces information in the observed graph. Based on this observation, we estimate and add an additional mutual information term to the semi-implicit variational inference learning objective to capture rich correlations arising between the input and latent spaces. We show that the inclusion of this regularization term in conjunction with the \poincare embedding boosts the quality of learned high-level representations and enables more flexible and faithful graphical modeling. We experimentally demonstrate that our approach outperforms existing graph variational auto-encoders both in Euclidean and in hyperbolic spaces for edge link prediction and node classification.
Visualizing MuZero Models
Feb 25, 2021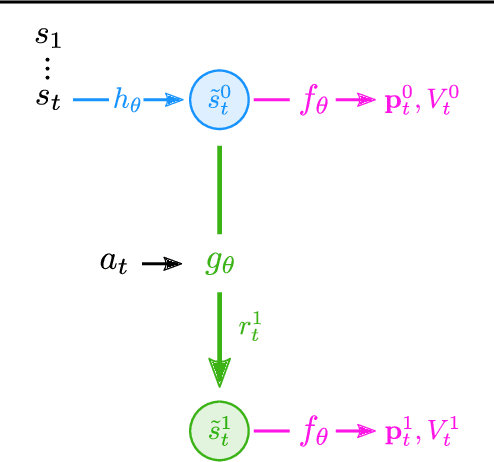
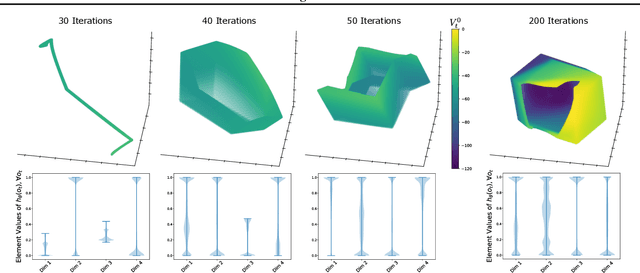
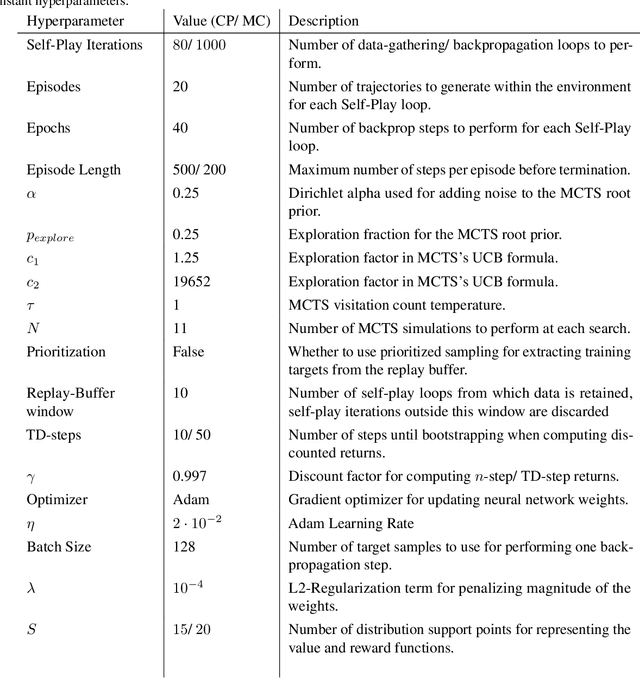
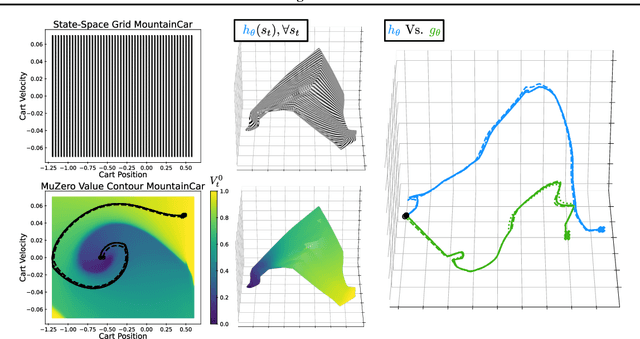
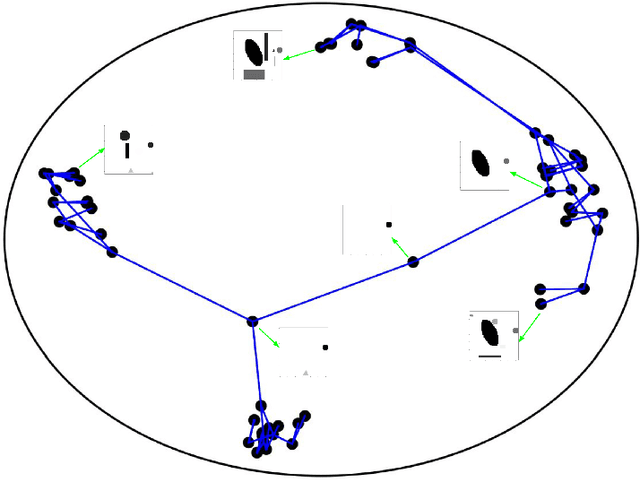
MuZero, a model-based reinforcement learning algorithm that uses a value equivalent dynamics model, achieved state-of-the-art performance in Chess, Shogi and the game of Go. In contrast to standard forward dynamics models that predict a full next state, value equivalent models are trained to predict a future value, thereby emphasizing value relevant information in the representations. While value equivalent models have shown strong empirical success, there is no research yet that visualizes and investigates what types of representations these models actually learn. Therefore, in this paper we visualize the latent representation of MuZero agents. We find that action trajectories may diverge between observation embeddings and internal state transition dynamics, which could lead to instability during planning. Based on this insight, we propose two regularization techniques to stabilize MuZero's performance. Additionally, we provide an open-source implementation of MuZero along with an interactive visualizer of learned representations, which may aid further investigation of value equivalent algorithms.
Few-Shot Learning for Video Object Detection in a Transfer-Learning Scheme
Mar 30, 2021
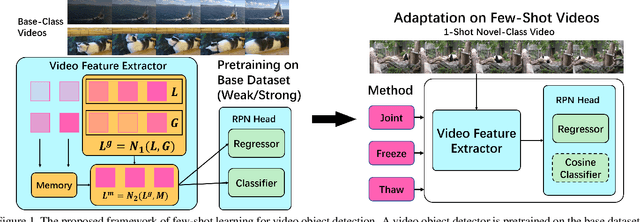
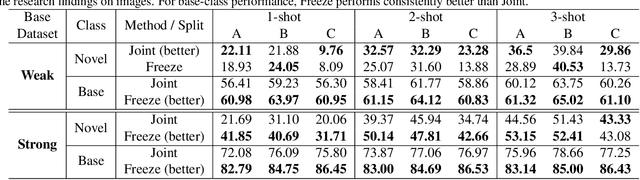
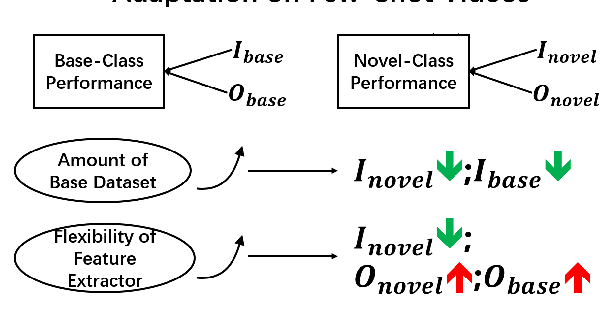
Different from static images, videos contain additional temporal and spatial information for better object detection. However, it is costly to obtain a large number of videos with bounding box annotations that are required for supervised deep learning. Although humans can easily learn to recognize new objects by watching only a few video clips, deep learning usually suffers from overfitting. This leads to an important question: how to effectively learn a video object detector from only a few labeled video clips? In this paper, we study the new problem of few-shot learning for video object detection. We first define the few-shot setting and create a new benchmark dataset for few-shot video object detection derived from the widely used ImageNet VID dataset. We employ a transfer-learning framework to effectively train the video object detector on a large number of base-class objects and a few video clips of novel-class objects. By analyzing the results of two methods under this framework (Joint and Freeze) on our designed weak and strong base datasets, we reveal insufficiency and overfitting problems. A simple but effective method, called Thaw, is naturally developed to trade off the two problems and validate our analysis. Extensive experiments on our proposed benchmark datasets with different scenarios demonstrate the effectiveness of our novel analysis in this new few-shot video object detection problem.
Adversarial Shape Learning for Building Extraction in VHR Remote Sensing Images
Feb 25, 2021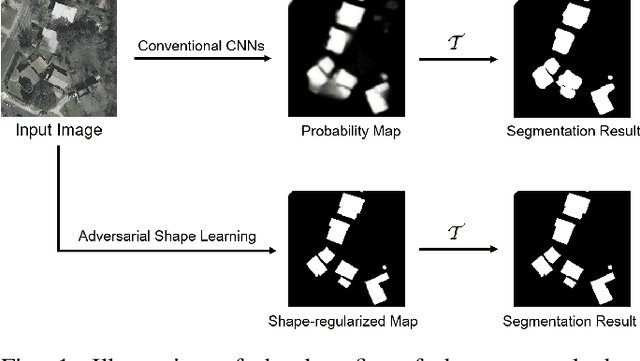
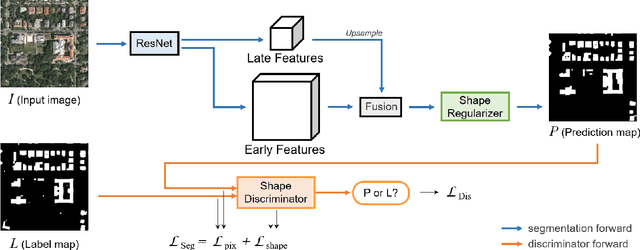
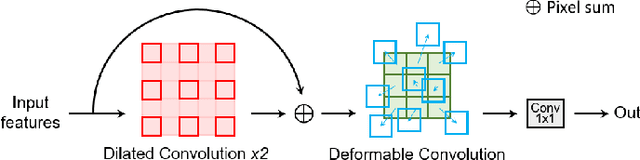
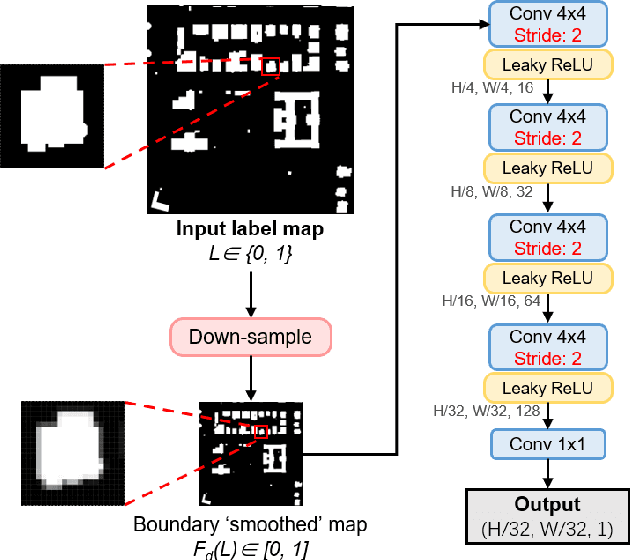
Building extraction in VHR RSIs remains to be a challenging task due to occlusion and boundary ambiguity problems. Although conventional convolutional neural networks (CNNs) based methods are capable of exploiting local texture and context information, they fail to capture the shape patterns of buildings, which is a necessary constraint in the human recognition. In this context, we propose an adversarial shape learning network (ASLNet) to model the building shape patterns, thus improving the accuracy of building segmentation. In the proposed ASLNet, we introduce the adversarial learning strategy to explicitly model the shape constraints, as well as a CNN shape regularizer to strengthen the embedding of shape features. To assess the geometric accuracy of building segmentation results, we further introduced several object-based assessment metrics. Experiments on two open benchmark datasets show that the proposed ASLNet improves both the pixel-based accuracy and the object-based measurements by a large margin. The code is available at: https://github.com/ggsDing/ASLNet
Energy Disaggregation using Variational Autoencoders
Mar 22, 2021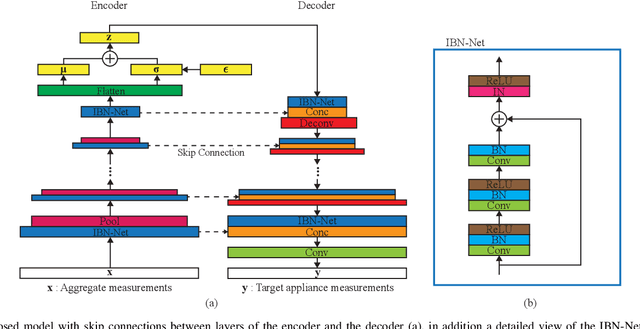
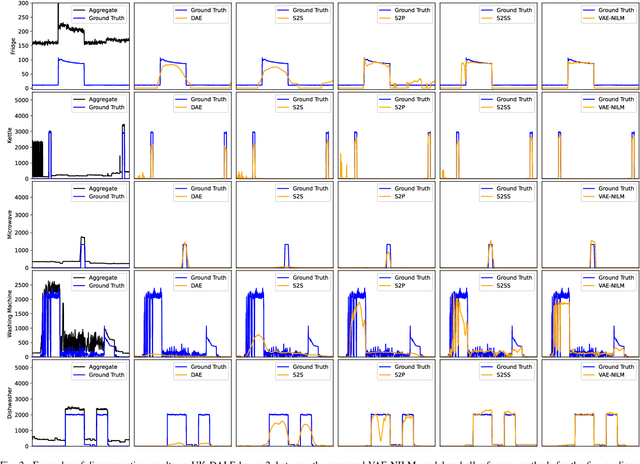
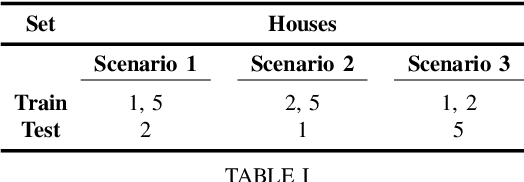
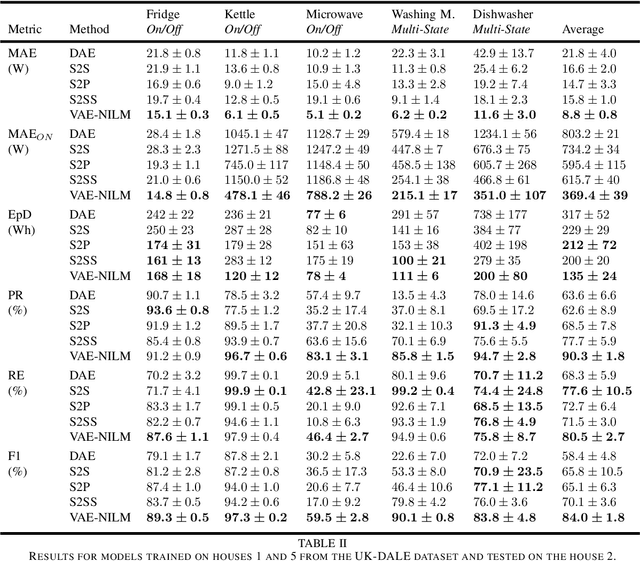
Non-intrusive load monitoring (NILM) is a technique that uses a single sensor to measure the total power consumption of a building. Using an energy disaggregation method, the consumption of individual appliances can be estimated from the aggregate measurement. Recent disaggregation algorithms have significantly improved the performance of NILM systems. However, the generalization capability of these methods to different houses as well as the disaggregation of multi-state appliances are still major challenges. In this paper we address these issues and propose an energy disaggregation approach based on the variational autoencoders (VAE) framework. The probabilistic encoder makes this approach an efficient model for encoding information relevant to the reconstruction of the target appliance consumption. In particular, the proposed model accurately generates more complex load profiles, thus improving the power signal reconstruction of multi-state appliances. Moreover, its regularized latent space improves the generalization capabilities of the model across different houses. The proposed model is compared to state-of-the-art NILM approaches on the UK-DALE dataset, and yields competitive results. The mean absolute error reduces by 18% on average across all appliances compared to the state-of-the-art. The F1-Score increases by more than 11%, showing improvements for the detection of the target appliance in the aggregate measurement.
Global Guidance Network for Breast Lesion Segmentation in Ultrasound Images
Apr 05, 2021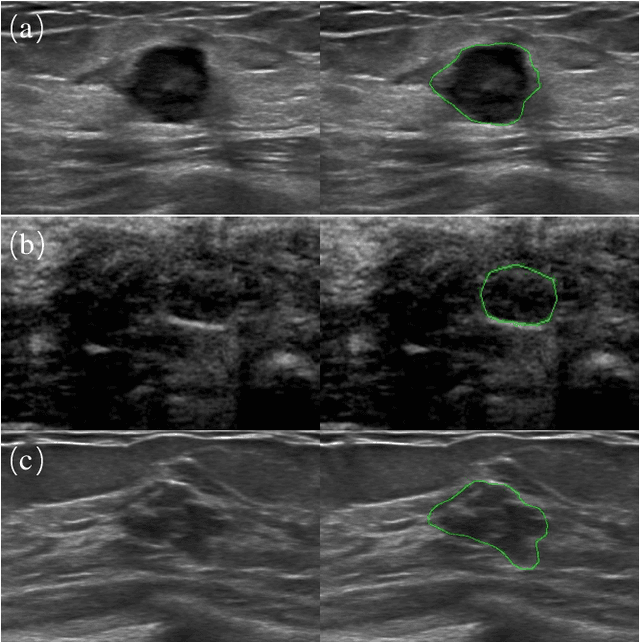
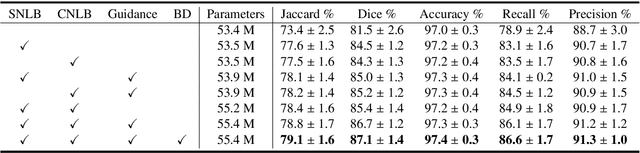
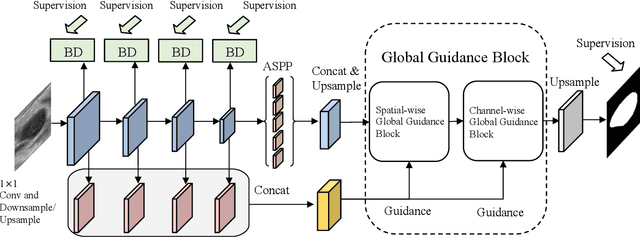

Automatic breast lesion segmentation in ultrasound helps to diagnose breast cancer, which is one of the dreadful diseases that affect women globally. Segmenting breast regions accurately from ultrasound image is a challenging task due to the inherent speckle artifacts, blurry breast lesion boundaries, and inhomogeneous intensity distributions inside the breast lesion regions. Recently, convolutional neural networks (CNNs) have demonstrated remarkable results in medical image segmentation tasks. However, the convolutional operations in a CNN often focus on local regions, which suffer from limited capabilities in capturing long-range dependencies of the input ultrasound image, resulting in degraded breast lesion segmentation accuracy. In this paper, we develop a deep convolutional neural network equipped with a global guidance block (GGB) and breast lesion boundary detection (BD) modules for boosting the breast ultrasound lesion segmentation. The GGB utilizes the multi-layer integrated feature map as a guidance information to learn the long-range non-local dependencies from both spatial and channel domains. The BD modules learn additional breast lesion boundary map to enhance the boundary quality of a segmentation result refinement. Experimental results on a public dataset and a collected dataset show that our network outperforms other medical image segmentation methods and the recent semantic segmentation methods on breast ultrasound lesion segmentation. Moreover, we also show the application of our network on the ultrasound prostate segmentation, in which our method better identifies prostate regions than state-of-the-art networks.
HyperSAGE: Generalizing Inductive Representation Learning on Hypergraphs
Oct 09, 2020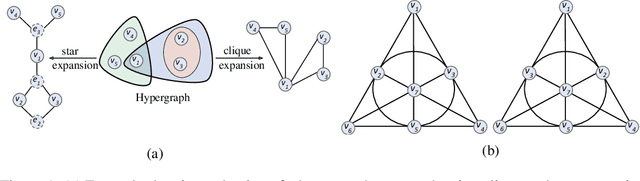
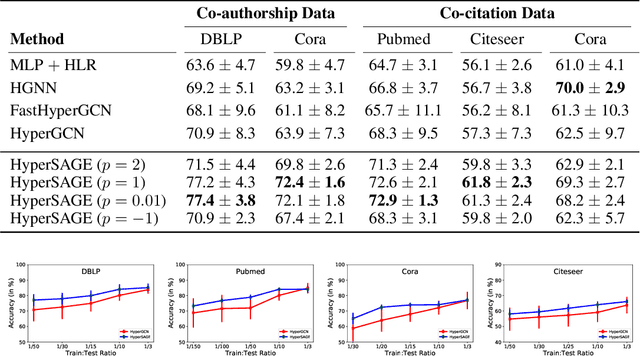
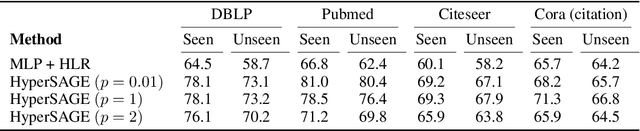
Graphs are the most ubiquitous form of structured data representation used in machine learning. They model, however, only pairwise relations between nodes and are not designed for encoding the higher-order relations found in many real-world datasets. To model such complex relations, hypergraphs have proven to be a natural representation. Learning the node representations in a hypergraph is more complex than in a graph as it involves information propagation at two levels: within every hyperedge and across the hyperedges. Most current approaches first transform a hypergraph structure to a graph for use in existing geometric deep learning algorithms. This transformation leads to information loss, and sub-optimal exploitation of the hypergraph's expressive power. We present HyperSAGE, a novel hypergraph learning framework that uses a two-level neural message passing strategy to accurately and efficiently propagate information through hypergraphs. The flexible design of HyperSAGE facilitates different ways of aggregating neighborhood information. Unlike the majority of related work which is transductive, our approach, inspired by the popular GraphSAGE method, is inductive. Thus, it can also be used on previously unseen nodes, facilitating deployment in problems such as evolving or partially observed hypergraphs. Through extensive experimentation, we show that HyperSAGE outperforms state-of-the-art hypergraph learning methods on representative benchmark datasets. We also demonstrate that the higher expressive power of HyperSAGE makes it more stable in learning node representations as compared to the alternatives.
Multi-Agent Decentralized Belief Propagation on Graphs
Nov 10, 2020We consider the problem of interactive partially observable Markov decision processes (I-POMDPs), where the agents are located at the nodes of a communication network. Specifically, we assume a certain message type for all messages. Moreover, each agent makes individual decisions based on the interactive belief states, the information observed locally and the messages received from its neighbors over the network. Within this setting, the collective goal of the agents is to maximize the globally averaged return over the network through exchanging information with their neighbors. We propose a decentralized belief propagation algorithm for the problem, and prove the convergence of our algorithm. Finally we show multiple applications of our framework. Our work appears to be the first study of decentralized belief propagation algorithm for networked multi-agent I-POMDPs.
Local Algorithms for Block Models with Side Information
Aug 10, 2015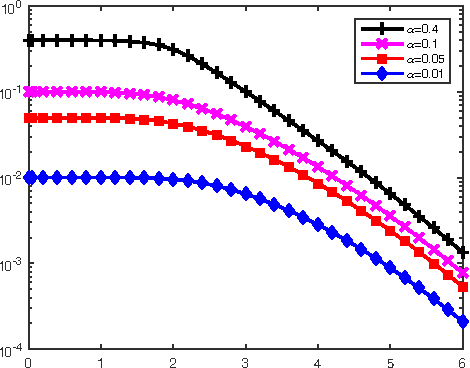
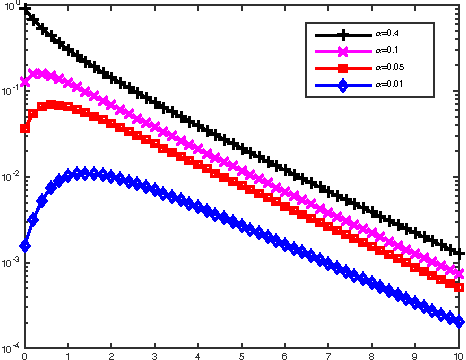
There has been a recent interest in understanding the power of local algorithms for optimization and inference problems on sparse graphs. Gamarnik and Sudan (2014) showed that local algorithms are weaker than global algorithms for finding large independent sets in sparse random regular graphs. Montanari (2015) showed that local algorithms are suboptimal for finding a community with high connectivity in the sparse Erd\H{o}s-R\'enyi random graphs. For the symmetric planted partition problem (also named community detection for the block models) on sparse graphs, a simple observation is that local algorithms cannot have non-trivial performance. In this work we consider the effect of side information on local algorithms for community detection under the binary symmetric stochastic block model. In the block model with side information each of the $n$ vertices is labeled $+$ or $-$ independently and uniformly at random; each pair of vertices is connected independently with probability $a/n$ if both of them have the same label or $b/n$ otherwise. The goal is to estimate the underlying vertex labeling given 1) the graph structure and 2) side information in the form of a vertex labeling positively correlated with the true one. Assuming that the ratio between in and out degree $a/b$ is $\Theta(1)$ and the average degree $ (a+b) / 2 = n^{o(1)}$, we characterize three different regimes under which a local algorithm, namely, belief propagation run on the local neighborhoods, maximizes the expected fraction of vertices labeled correctly. Thus, in contrast to the case of symmetric block models without side information, we show that local algorithms can achieve optimal performance for the block model with side information.