 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Knowledge-enriched, Type-constrained and Grammar-guided Question Generation over Knowledge Bases
Oct 23, 2020

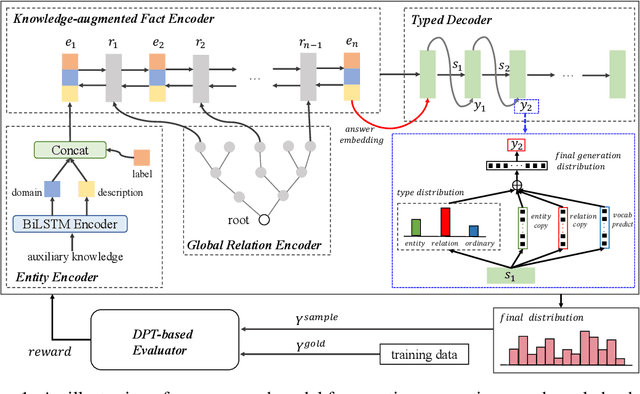
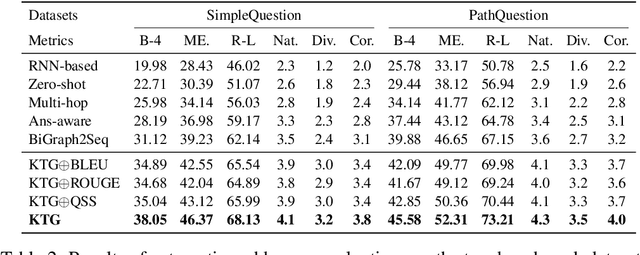
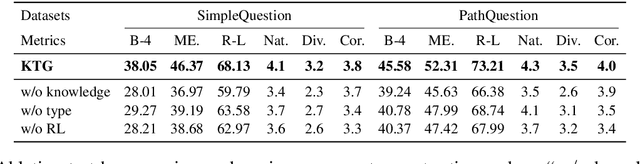
Question generation over knowledge bases (KBQG) aims at generating natural-language questions about a subgraph, i.e. a set of (connected) triples. Two main challenges still face the current crop of encoder-decoder-based methods, especially on small subgraphs: (1) low diversity and poor fluency due to the limited information contained in the subgraphs, and (2) semantic drift due to the decoder's oblivion of the semantics of the answer entity. We propose an innovative knowledge-enriched, type-constrained and grammar-guided KBQG model, named KTG, to addresses the above challenges. In our model, the encoder is equipped with auxiliary information from the KB, and the decoder is constrained with word types during QG. Specifically, entity domain and description, as well as relation hierarchy information are considered to construct question contexts, while a conditional copy mechanism is incorporated to modulate question semantics according to current word types. Besides, a novel reward function featuring grammatical similarity is designed to improve both generative richness and syntactic correctness via reinforcement learning. Extensive experiments show that our proposed model outperforms existing methods by a significant margin on two widely-used benchmark datasets SimpleQuestion and PathQuestion.
Federated mmWave Beam Selection Utilizing LIDAR Data
Feb 04, 2021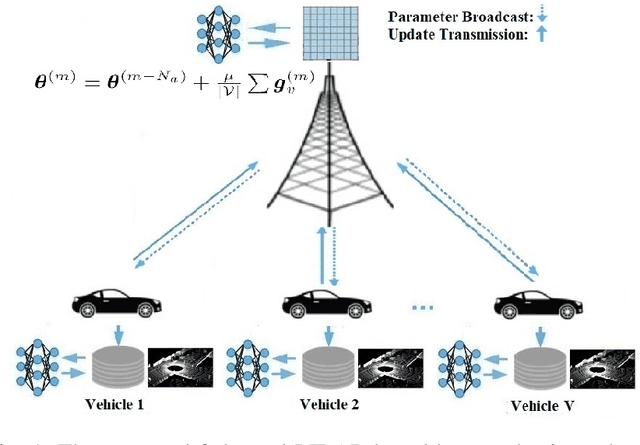

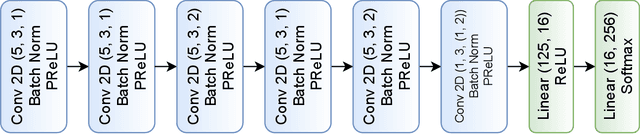
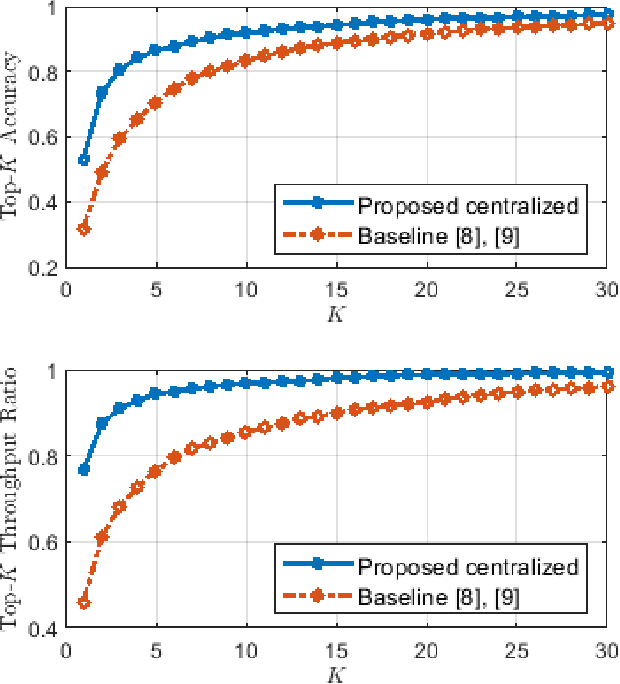
Efficient link configuration in millimeter wave (mmWave) communication systems is a crucial yet challenging task due to the overhead imposed by beam selection on the network performance. For vehicle-to-infrastructure (V2I) networks, side information from LIDAR sensors mounted on the vehicles has been leveraged to reduce the beam search overhead. In this letter, we propose distributed LIDAR aided beam selection for V2I mmWave communication systems utilizing federated training. In the proposed scheme, connected vehicles collaborate to train a shared neural network (NN) on their locally available LIDAR data during normal operation of the system. We also propose an alternative reduced-complexity convolutional NN (CNN) architecture and LIDAR preprocessing, which significantly outperforms previous works in terms of both the performance and the complexity.
"Attention" for Detecting Unreliable News in the Information Age
Nov 03, 2017
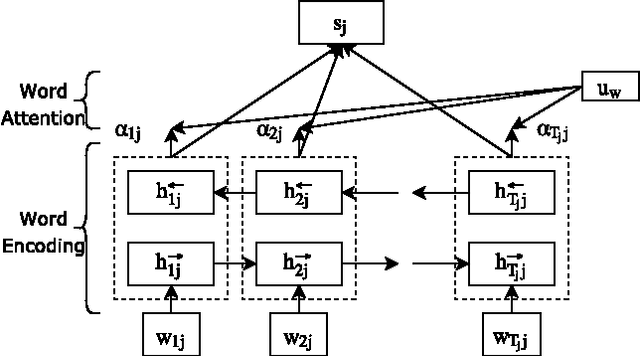
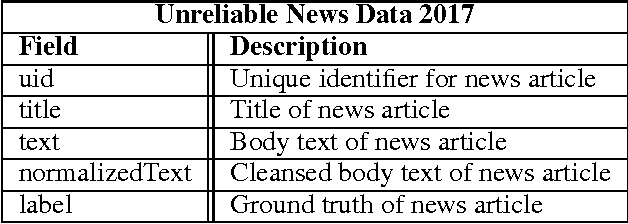
An Unreliable news is any piece of information which is false or misleading, deliberately spread to promote political, ideological and financial agendas. Recently the problem of unreliable news has got a lot of attention as the number instances of using news and social media outlets for propaganda have increased rapidly. This poses a serious threat to society, which calls for technology to automatically and reliably identify unreliable news sources. This paper is an effort made in this direction to build systems for detecting unreliable news articles. In this paper, various NLP algorithms were built and evaluated on Unreliable News Data 2017 dataset. Variants of hierarchical attention networks (HAN) are presented for encoding and classifying news articles which achieve the best results of 0.944 ROC-AUC. Finally, Attention layer weights are visualized to understand and give insight into the decisions made by HANs. The results obtained are very promising and encouraging to deploy and use these systems in the real world to mitigate the problem of unreliable news.
Contrastive Neural Architecture Search with Neural Architecture Comparators
Apr 06, 2021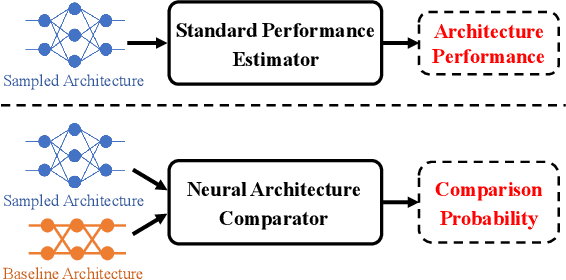
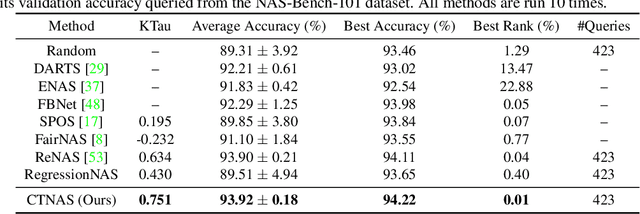
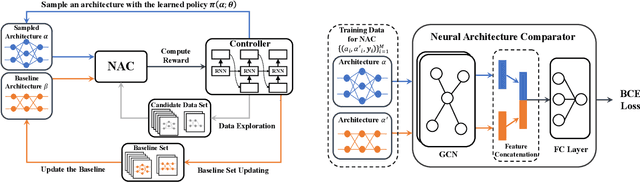
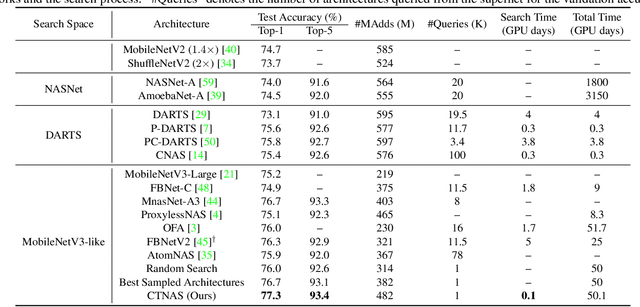
One of the key steps in Neural Architecture Search (NAS) is to estimate the performance of candidate architectures. Existing methods either directly use the validation performance or learn a predictor to estimate the performance. However, these methods can be either computationally expensive or very inaccurate, which may severely affect the search efficiency and performance. Moreover, as it is very difficult to annotate architectures with accurate performance on specific tasks, learning a promising performance predictor is often non-trivial due to the lack of labeled data. In this paper, we argue that it may not be necessary to estimate the absolute performance for NAS. On the contrary, we may need only to understand whether an architecture is better than a baseline one. However, how to exploit this comparison information as the reward and how to well use the limited labeled data remains two great challenges. In this paper, we propose a novel Contrastive Neural Architecture Search (CTNAS) method which performs architecture search by taking the comparison results between architectures as the reward. Specifically, we design and learn a Neural Architecture Comparator (NAC) to compute the probability of candidate architectures being better than a baseline one. Moreover, we present a baseline updating scheme to improve the baseline iteratively in a curriculum learning manner. More critically, we theoretically show that learning NAC is equivalent to optimizing the ranking over architectures. Extensive experiments in three search spaces demonstrate the superiority of our CTNAS over existing methods.
Design of an Optoelectronically Innervated Gripper for Rigid-Soft Interactive Grasping
Dec 06, 2020

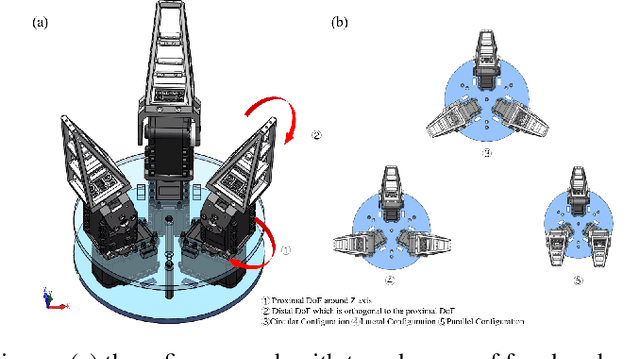
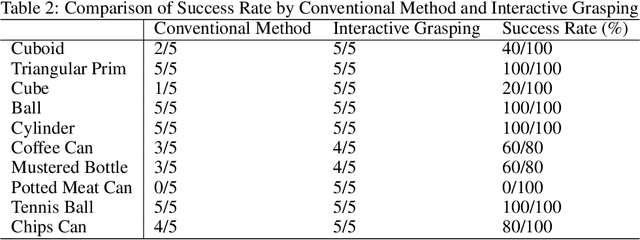
Over the past few decades, efforts have been made towards robust robotic grasping, and therefore dexterous manipulation. The soft gripper has shown their potential in robust grasping due to their inherent properties-low, control complexity, and high adaptability. However, the deformation of the soft gripper when interacting with objects bring inaccuracy of grasped objects, which causes instability for robust grasping and further manipulation. In this paper, we present an omni-directional adaptive soft finger that can sense deformation based on embedded optical fibers and the application of machine learning methods to interpret transmitted light intensities. Furthermore, to use tactile information provided by a soft finger, we design a low-cost and multi degrees of freedom gripper to conform to the shape of objects actively and optimize grasping policy, which is called Rigid-Soft Interactive Grasping. Two main advantages of this grasping policy are provided: one is that a more robust grasping could be achieved through an active adaptation; the other is that the tactile information collected could be helpful for further manipulation.
Hyperbolic Graph Embedding with Enhanced Semi-Implicit Variational Inference
Oct 31, 2020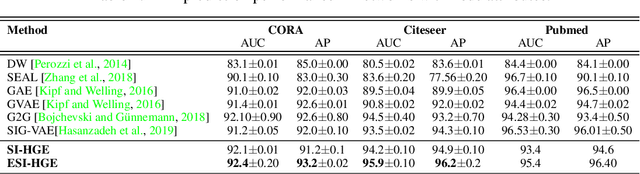
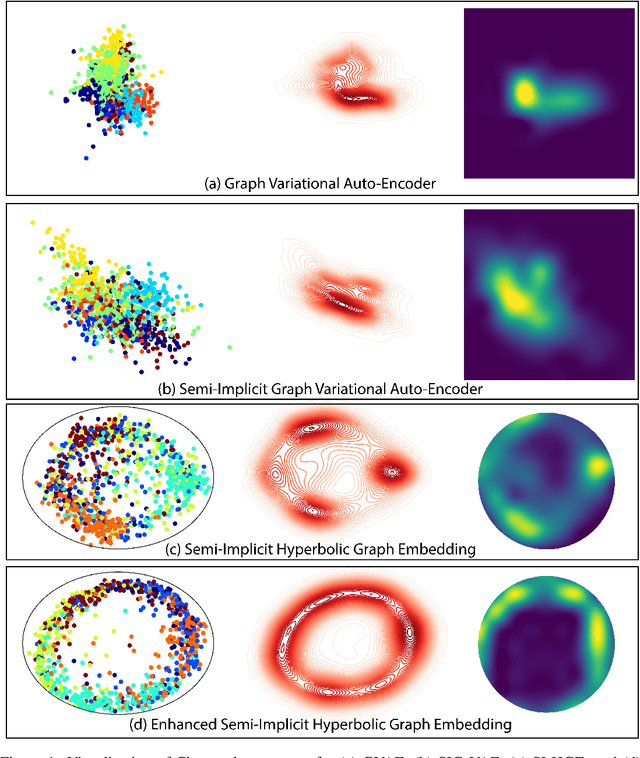
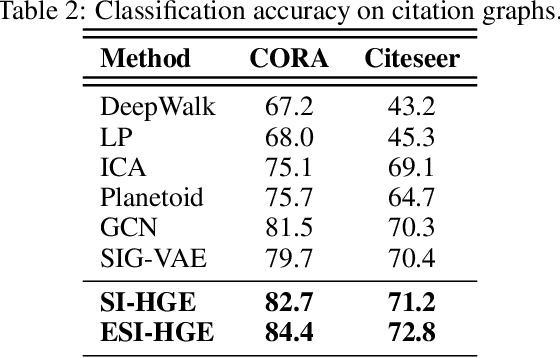
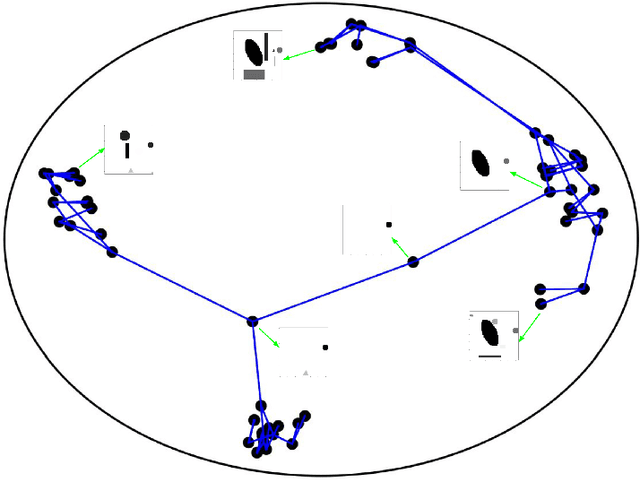
Efficient modeling of relational data arising in physical, social, and information sciences is challenging due to complicated dependencies within the data. In this work we build off of semi-implicit graph variational auto-encoders to capture higher order statistics in a low-dimensional graph latent representation. We incorporate hyperbolic geometry in the latent space through a \poincare embedding to efficiently represent graphs exhibiting hierarchical structure. To address the naive posterior latent distribution assumptions in classical variational inference, we use semi-implicit hierarchical variational Bayes to implicitly capture posteriors of given graph data, which may exhibit heavy tails, multiple modes, skewness, and highly correlated latent structures. We show that the existing semi-implicit variational inference objective provably reduces information in the observed graph. Based on this observation, we estimate and add an additional mutual information term to the semi-implicit variational inference learning objective to capture rich correlations arising between the input and latent spaces. We show that the inclusion of this regularization term in conjunction with the \poincare embedding boosts the quality of learned high-level representations and enables more flexible and faithful graphical modeling. We experimentally demonstrate that our approach outperforms existing graph variational auto-encoders both in Euclidean and in hyperbolic spaces for edge link prediction and node classification.
SIMstack: A Generative Shape and Instance Model for Unordered Object Stacks
Mar 30, 2021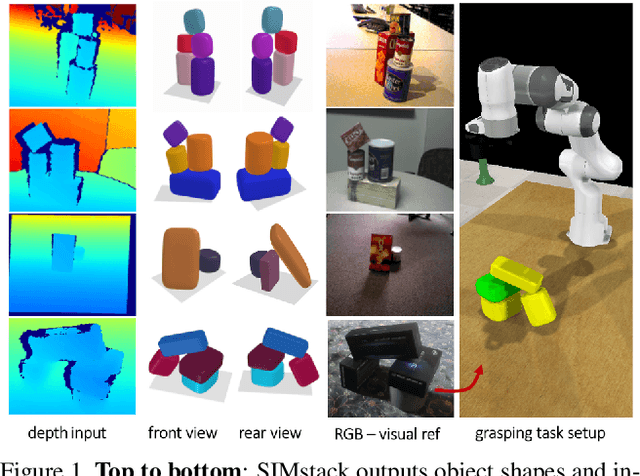
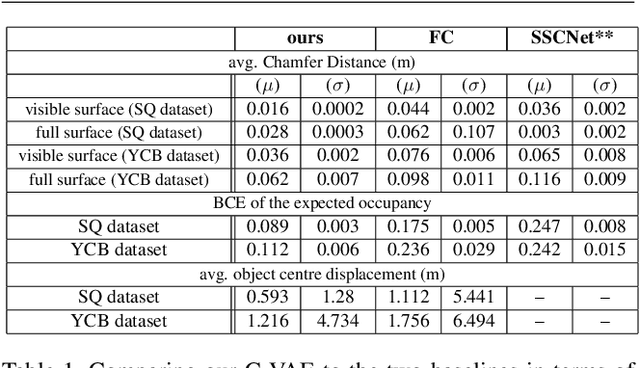
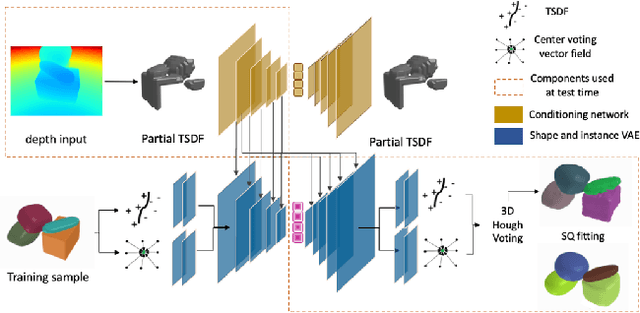

By estimating 3D shape and instances from a single view, we can capture information about an environment quickly, without the need for comprehensive scanning and multi-view fusion. Solving this task for composite scenes (such as object stacks) is challenging: occluded areas are not only ambiguous in shape but also in instance segmentation; multiple decompositions could be valid. We observe that physics constrains decomposition as well as shape in occluded regions and hypothesise that a latent space learned from scenes built under physics simulation can serve as a prior to better predict shape and instances in occluded regions. To this end we propose SIMstack, a depth-conditioned Variational Auto-Encoder (VAE), trained on a dataset of objects stacked under physics simulation. We formulate instance segmentation as a centre voting task which allows for class-agnostic detection and doesn't require setting the maximum number of objects in the scene. At test time, our model can generate 3D shape and instance segmentation from a single depth view, probabilistically sampling proposals for the occluded region from the learned latent space. Our method has practical applications in providing robots some of the ability humans have to make rapid intuitive inferences of partially observed scenes. We demonstrate an application for precise (non-disruptive) object grasping of unknown objects from a single depth view.
Differentiable Agent-Based Simulation for Gradient-Guided Simulation-Based Optimization
Mar 23, 2021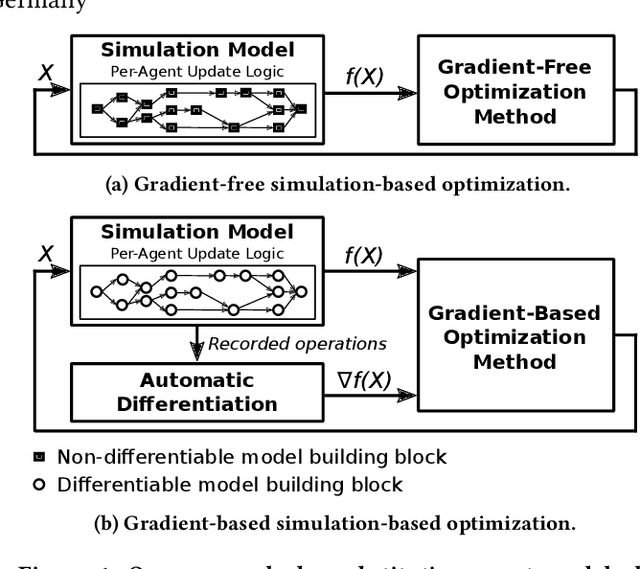
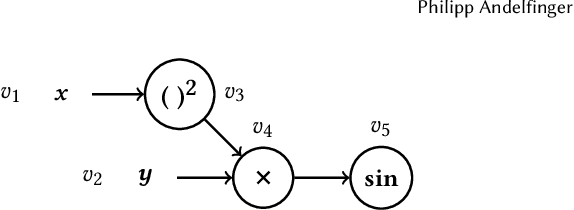
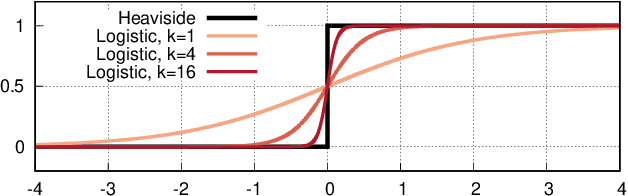
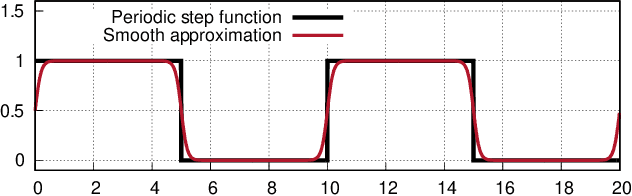
Simulation-based optimization using agent-based models is typically carried out under the assumption that the gradient describing the sensitivity of the simulation output to the input cannot be evaluated directly. To still apply gradient-based optimization methods, which efficiently steer the optimization towards a local optimum, gradient estimation methods can be employed. However, many simulation runs are needed to obtain accurate estimates if the input dimension is large. Automatic differentiation (AD) is a family of techniques to compute gradients of general programs directly. Here, we explore the use of AD in the context of time-driven agent-based simulations. By substituting common discrete model elements such as conditional branching with smooth approximations, we obtain gradient information across discontinuities in the model logic. On the example of microscopic traffic models and an epidemics model, we study the fidelity and overhead of the differentiable models, as well as the convergence speed and solution quality achieved by gradient-based optimization compared to gradient-free methods. In traffic signal timing optimization problems with high input dimension, the gradient-based methods exhibit substantially superior performance. Finally, we demonstrate that the approach enables gradient-based training of neural network-controlled simulation entities embedded in the model logic.
Graph Networks with Spectral Message Passing
Dec 31, 2020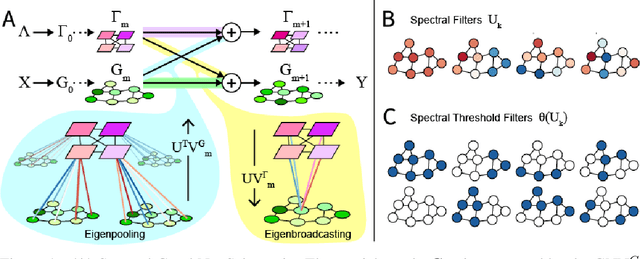
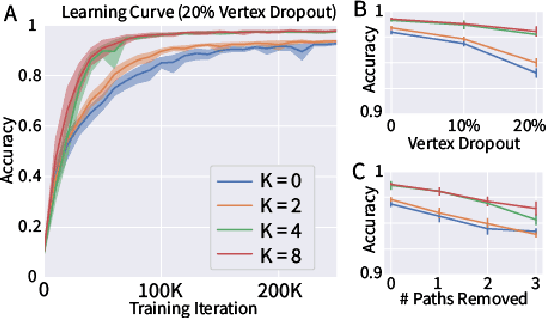
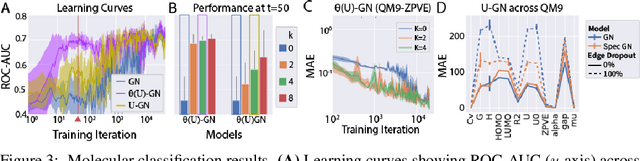
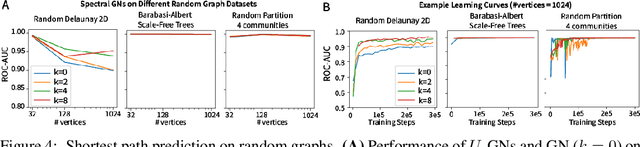
Graph Neural Networks (GNNs) are the subject of intense focus by the machine learning community for problems involving relational reasoning. GNNs can be broadly divided into spatial and spectral approaches. Spatial approaches use a form of learned message-passing, in which interactions among vertices are computed locally, and information propagates over longer distances on the graph with greater numbers of message-passing steps. Spectral approaches use eigendecompositions of the graph Laplacian to produce a generalization of spatial convolutions to graph structured data which access information over short and long time scales simultaneously. Here we introduce the Spectral Graph Network, which applies message passing to both the spatial and spectral domains. Our model projects vertices of the spatial graph onto the Laplacian eigenvectors, which are each represented as vertices in a fully connected "spectral graph", and then applies learned message passing to them. We apply this model to various benchmark tasks including a graph-based variant of MNIST classification, molecular property prediction on MoleculeNet and QM9, and shortest path problems on random graphs. Our results show that the Spectral GN promotes efficient training, reaching high performance with fewer training iterations despite having more parameters. The model also provides robustness to edge dropout and outperforms baselines for the classification tasks. We also explore how these performance benefits depend on properties of the dataset.
Covid-19 risk factors: Statistical learning from German healthcare claims data
Feb 04, 2021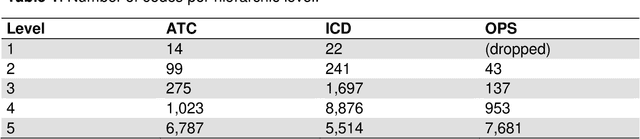
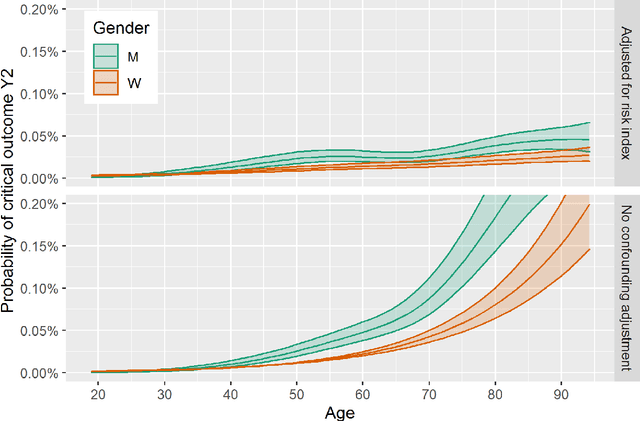
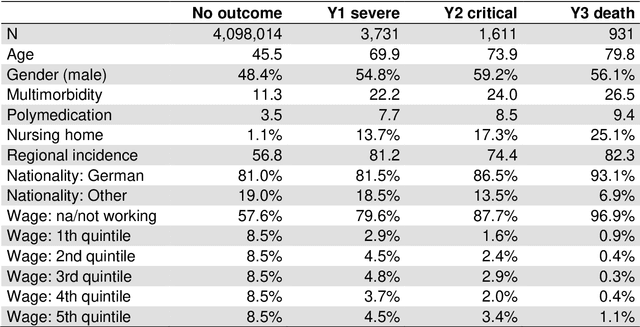
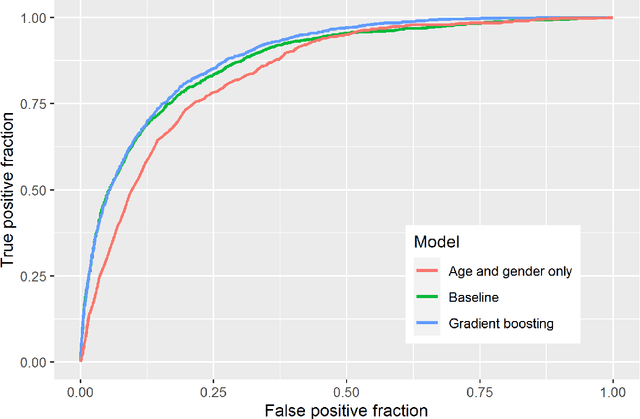
We analyse prior risk factors for severe, critical or fatal courses of Covid-19 based on a retrospective cohort study using claims data of the AOK Bayern. As a methodological contribution, we avoid prior grouping and pre-selection of candidate risk factors and use fine-grained hierarchical information from medical classification systems for diagnoses, pharmaceuticals and procedures, using more than 33,000 covariates. Our approach is competitive to formal analyses using well-specified morbidity groups without needing prior subject-matter knowledge. The methodology and our published coefficients may be of interest for decision makers when prioritizing protective measures towards vulnerable subpopulations as well as for researchers aiming to adjust for confounders in studies of individual risk factors also for smaller cohorts.