 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An efficient representation of chronological events in medical texts
Oct 24, 2020
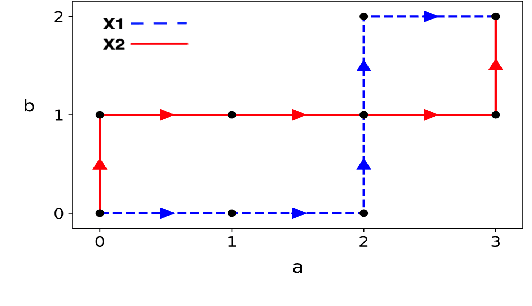
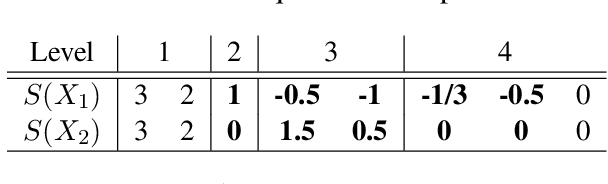

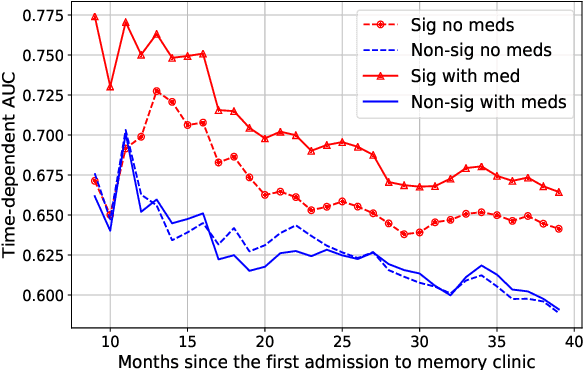
In this work we addressed the problem of capturing sequential information contained in longitudinal electronic health records (EHRs). Clinical notes, which is a particular type of EHR data, are a rich source of information and practitioners often develop clever solutions how to maximise the sequential information contained in free-texts. We proposed a systematic methodology for learning from chronological events available in clinical notes. The proposed methodological {\it path signature} framework creates a non-parametric hierarchical representation of sequential events of any type and can be used as features for downstream statistical learning tasks. The methodology was developed and externally validated using the largest in the UK secondary care mental health EHR data on a specific task of predicting survival risk of patients diagnosed with Alzheimer's disease. The signature-based model was compared to a common survival random forest model. Our results showed a 15.4$\%$ increase of risk prediction AUC at the time point of 20 months after the first admission to a specialist memory clinic and the signature method outperformed the baseline mixed-effects model by 13.2 $\%$.
Improving Physical Layer Security for Reconfigurable Intelligent Surface aided NOMA 6G Networks
Jan 18, 2021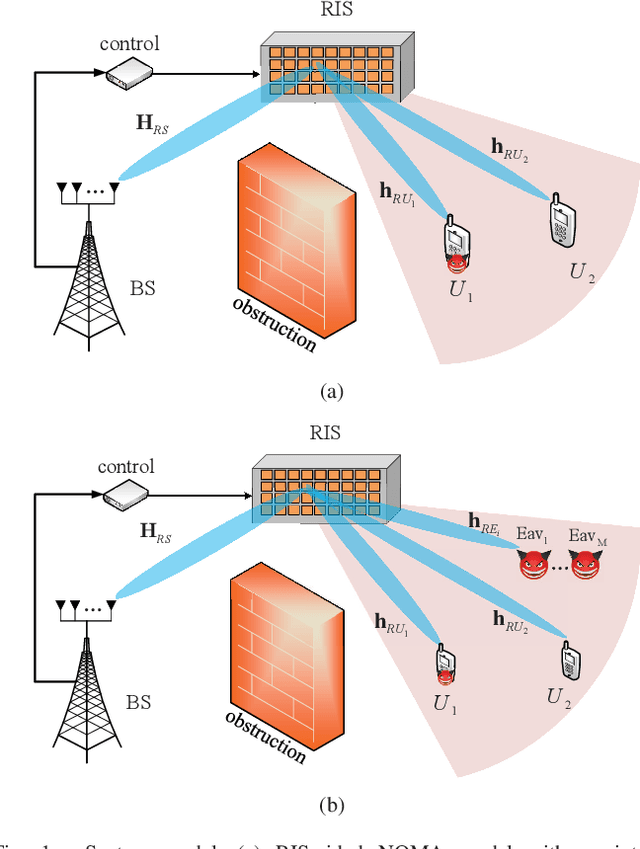
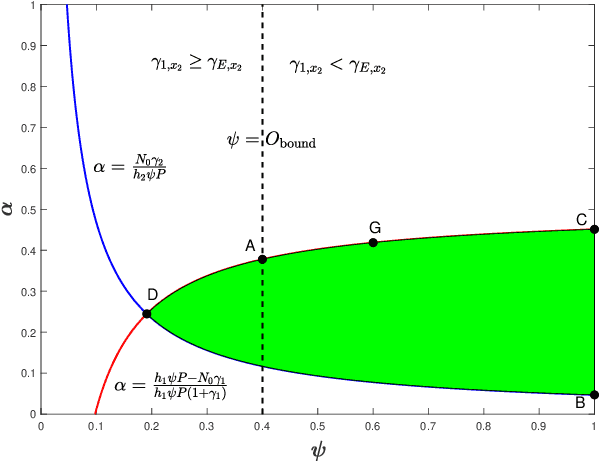
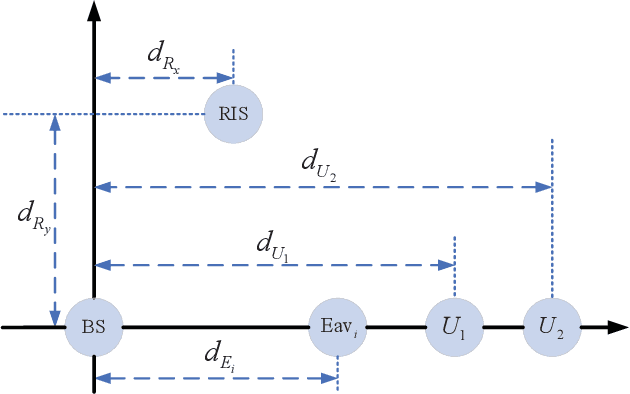
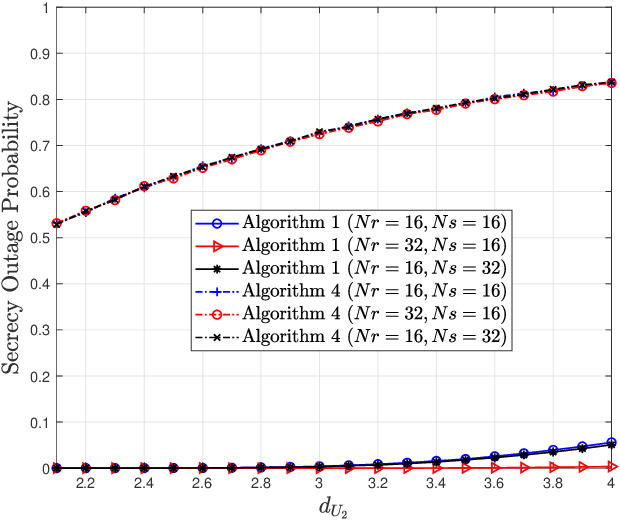
The intrinsic integration of the nonorthogonal multiple access (NOMA) and reconfigurable intelligent surface (RIS) techniques is envisioned to be a promising approach to significantly improve both the spectrum efficiency and energy efficiency for future wireless communication networks. In this paper, the physical layer security (PLS) for a RIS-aided NOMA 6G networks is investigated, in which a RIS is deployed to assist the two "dead zone" NOMA users and both internal and external eavesdropping are considered. For the scenario with only internal eavesdropping, we consider the worst case that the near-end user is untrusted and may try to intercept the information of far-end user. A joint beamforming and power allocation sub-optimal scheme is proposed to improve the system PLS. Then we extend our work to a scenario with both internal and external eavesdropping. Two sub-scenarios are considered in this scenario: one is the sub-scenario without channel state information (CSI) of eavesdroppers, and another is the sub-scenario where the eavesdroppers' CSI are available. For the both sub-scenarios, a noise beamforming scheme is introduced to be against the external eavesdroppers. An optimal power allocation scheme is proposed to further improve the system physical security for the second sub-scenario. Simulation results show the superior performance of the proposed schemes. Moreover, it has also been shown that increasing the number of reflecting elements can bring more gain in secrecy performance than that of the transmit antennas.
The Role of Context in Detecting Previously Fact-Checked Claims
Apr 15, 2021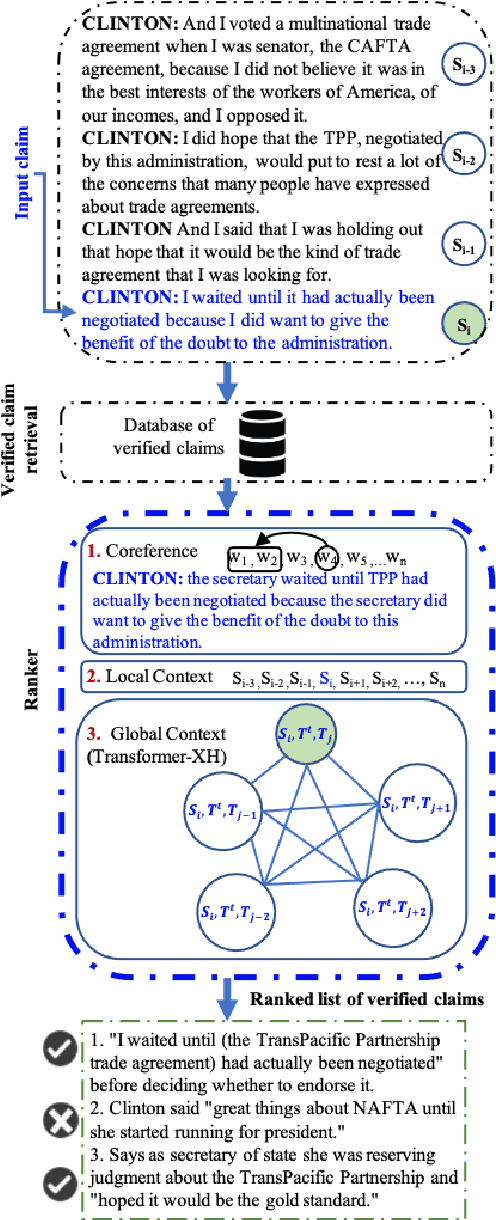
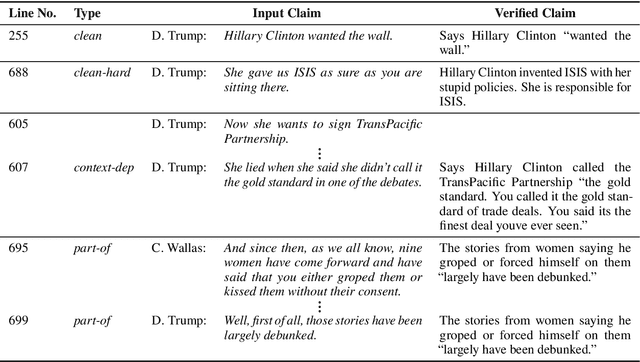


Recent years have seen the proliferation of disinformation and misinformation online, thanks to the freedom of expression on the Internet and to the rise of social media. Two solutions were proposed to address the problem: (i) manual fact-checking, which is accurate and credible, but slow and non-scalable, and (ii) automatic fact-checking, which is fast and scalable, but lacks explainability and credibility. With the accumulation of enough manually fact-checked claims, a middle-ground approach has emerged: checking whether a given claim has previously been fact-checked. This can be made automatically, and thus fast, while also offering credibility and explainability, thanks to the human fact-checking and explanations in the associated fact-checking article. This is a relatively new and understudied research direction, and here we focus on claims made in a political debate, where context really matters. Thus, we study the impact of modeling the context of the claim: both on the source side, i.e., in the debate, as well as on the target side, i.e., in the fact-checking explanation document. We do this by modeling the local context, the global context, as well as by means of co-reference resolution, and reasoning over the target text using Transformer-XH. The experimental results show that each of these represents a valuable information source, but that modeling the source-side context is more important, and can yield 10+ points of absolute improvement.
Active Feature Acquisition with Generative Surrogate Models
Oct 06, 2020
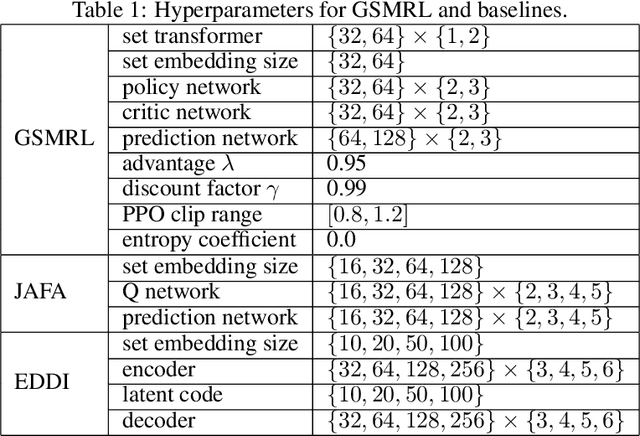
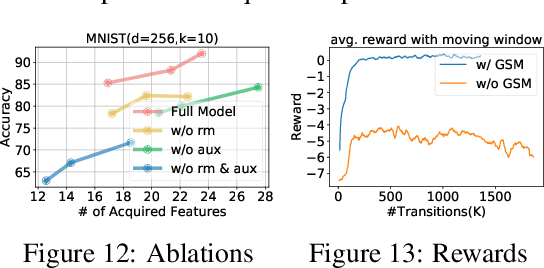
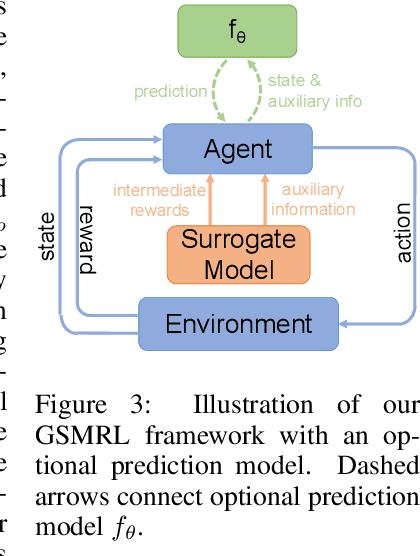
Many real-world situations allow for the acquisition of additional relevant information when making an assessment with limited or uncertain data. However, traditional ML approaches either require all features to be acquired beforehand or regard part of them as missing data that cannot be acquired. In this work, we propose models that perform active feature acquisition (AFA) to improve the prediction assessments at evaluation time. We formulate the AFA problem as a Markov decision process (MDP) and resolve it using reinforcement learning (RL). The AFA problem yields sparse rewards and contains a high-dimensional complicated action space. Thus, we propose learning a generative surrogate model that captures the complicated dependencies among input features to assess potential information gain from acquisitions. We also leverage the generative surrogate model to provide intermediate rewards and auxiliary information to the agent. Furthermore, we extend AFA in a task we coin active instance recognition (AIR) for the unsupervised case where the target variables are the unobserved features themselves and the goal is to collect information for a particular instance in a cost-efficient way. Empirical results demonstrate that our approach achieves considerably better performance than previous state of the art methods on both supervised and unsupervised tasks.
Hierarchical Convolutional Neural Network with Feature Preservation and Autotuned Thresholding for Crack Detection
Apr 21, 2021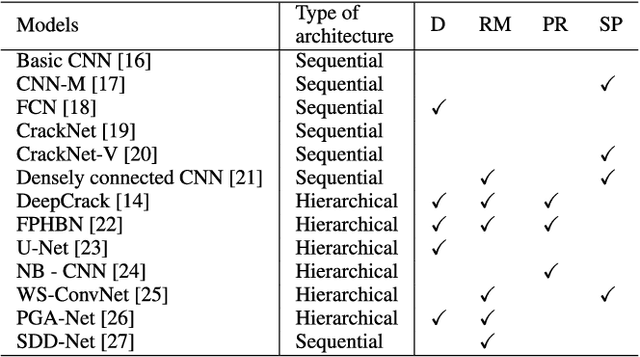
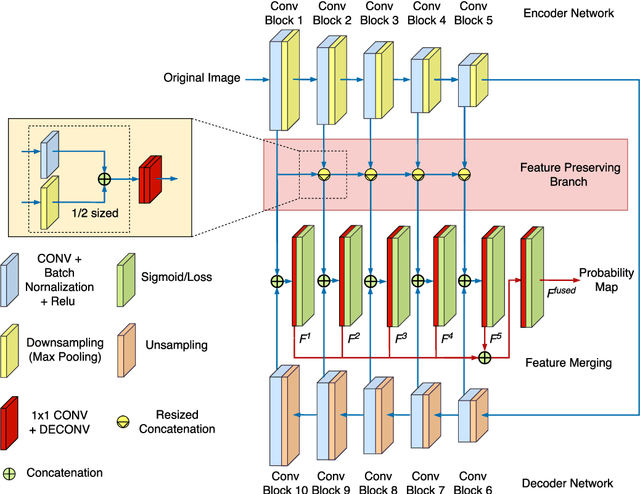
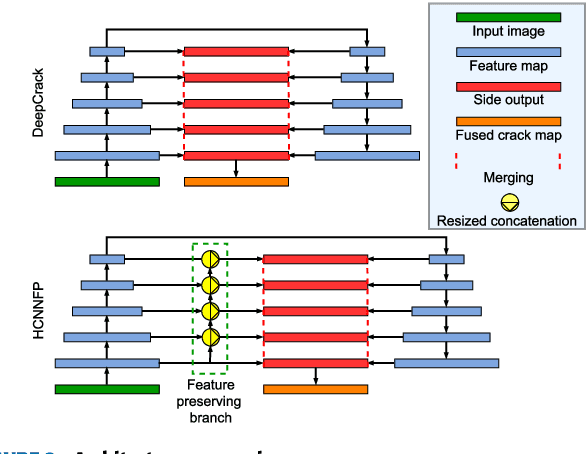
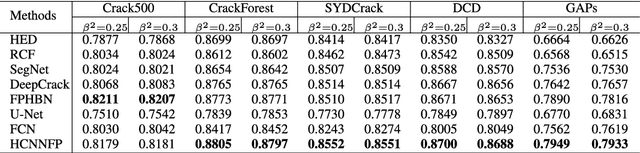
Drone imagery is increasingly used in automated inspection for infrastructure surface defects, especially in hazardous or unreachable environments. In machine vision, the key to crack detection rests with robust and accurate algorithms for image processing. To this end, this paper proposes a deep learning approach using hierarchical convolutional neural networks with feature preservation (HCNNFP) and an intercontrast iterative thresholding algorithm for image binarization. First, a set of branch networks is proposed, wherein the output of previous convolutional blocks is half-sizedly concatenated to the current ones to reduce the obscuration in the down-sampling stage taking into account the overall information loss. Next, to extract the feature map generated from the enhanced HCNN, a binary contrast-based autotuned thresholding (CBAT) approach is developed at the post-processing step, where patterns of interest are clustered within the probability map of the identified features. The proposed technique is then applied to identify surface cracks on the surface of roads, bridges or pavements. An extensive comparison with existing techniques is conducted on various datasets and subject to a number of evaluation criteria including the average F-measure (AF\b{eta}) introduced here for dynamic quantification of the performance. Experiments on crack images, including those captured by unmanned aerial vehicles inspecting a monorail bridge. The proposed technique outperforms the existing methods on various tested datasets especially for GAPs dataset with an increase of about 1.4% in terms of AF\b{eta} while the mean percentage error drops by 2.2%. Such performance demonstrates the merits of the proposed HCNNFP architecture for surface defect inspection.
Rethinking Self-Supervised Learning: Small is Beautiful
Mar 25, 2021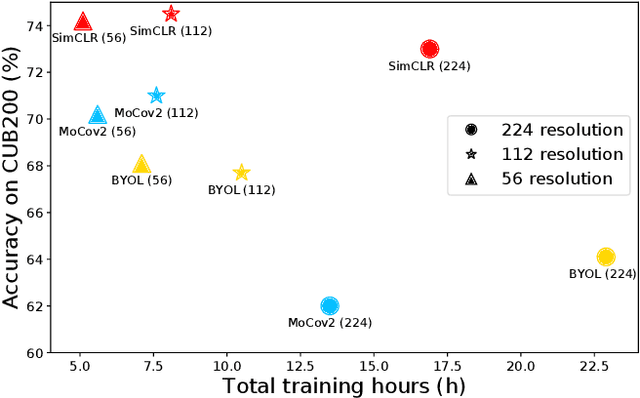
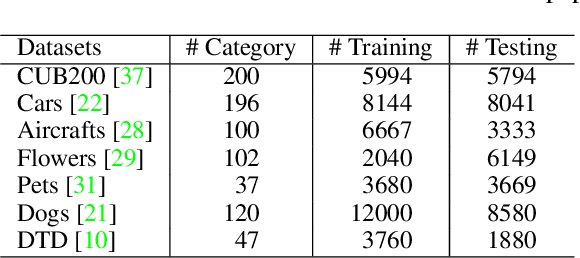
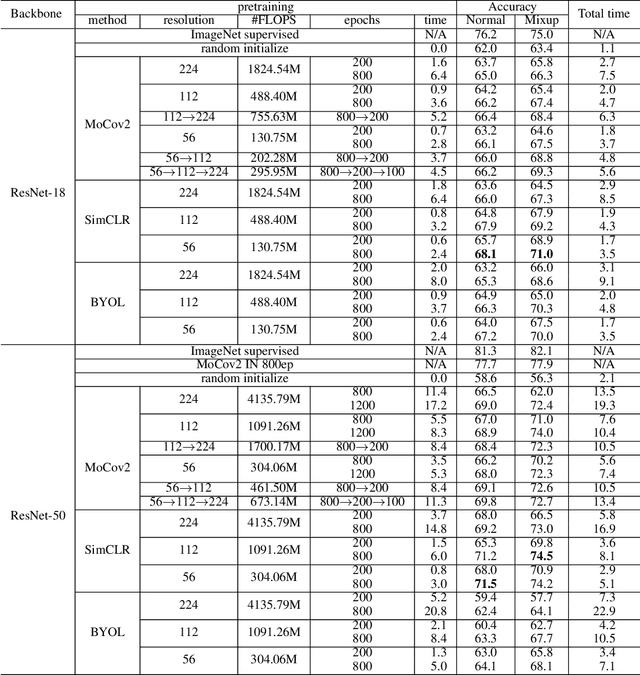
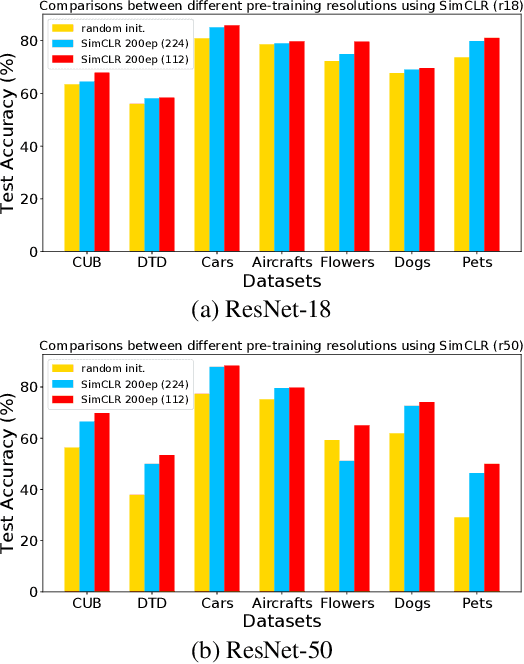
Self-supervised learning (SSL), in particular contrastive learning, has made great progress in recent years. However, a common theme in these methods is that they inherit the learning paradigm from the supervised deep learning scenario. Current SSL methods are often pretrained for many epochs on large-scale datasets using high resolution images, which brings heavy computational cost and lacks flexibility. In this paper, we demonstrate that the learning paradigm for SSL should be different from supervised learning and the information encoded by the contrastive loss is expected to be much less than that encoded in the labels in supervised learning via the cross entropy loss. Hence, we propose scaled-down self-supervised learning (S3L), which include 3 parts: small resolution, small architecture and small data. On a diverse set of datasets, SSL methods and backbone architectures, S3L achieves higher accuracy consistently with much less training cost when compared to previous SSL learning paradigm. Furthermore, we show that even without a large pretraining dataset, S3L can achieve impressive results on small data alone. Our code has been made publically available at https://github.com/CupidJay/Scaled-down-self-supervised-learning.
Quantum-Assisted Feature Selection for Vehicle Price Prediction Modeling
Apr 08, 2021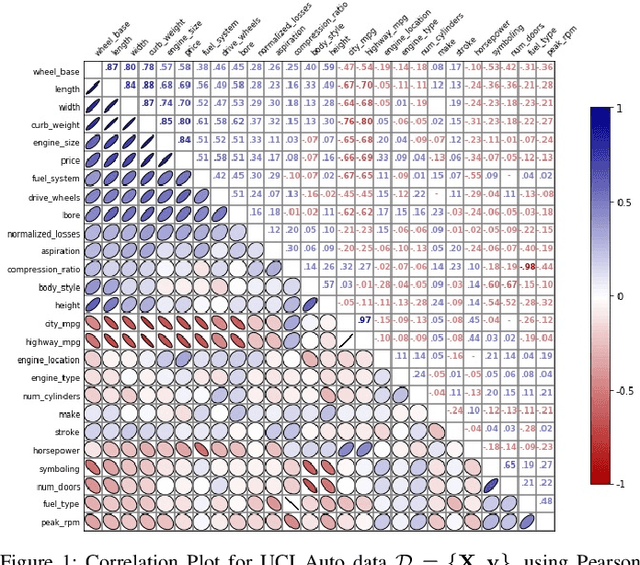
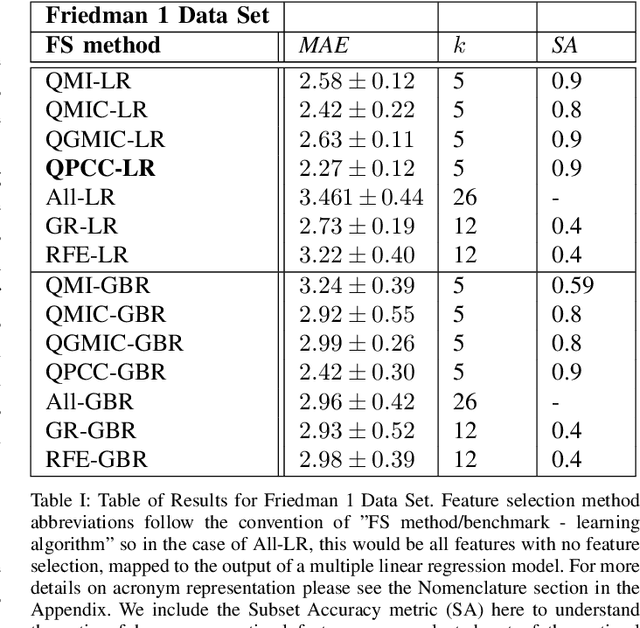
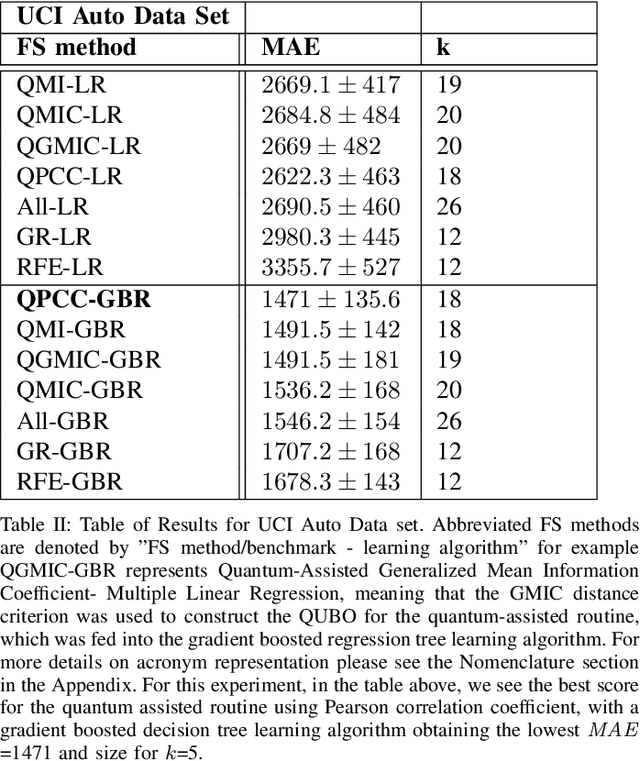
Within machine learning model evaluation regimes, feature selection is a technique to reduce model complexity and improve model performance in regards to generalization, model fit, and accuracy of prediction. However, the search over the space of features to find the subset of $k$ optimal features is a known NP-Hard problem. In this work, we study metrics for encoding the combinatorial search as a binary quadratic model, such as Generalized Mean Information Coefficient and Pearson Correlation Coefficient in application to the underlying regression problem of price prediction. We investigate trade-offs in the form of run-times and model performance, of leveraging quantum-assisted vs. classical subroutines for the combinatorial search, using minimum redundancy maximal relevancy as the heuristic for our approach. We achieve accuracy scores of 0.9 (in the range of [0,1]) for finding optimal subsets on synthetic data using a new metric that we define. We test and cross-validate predictive models on a real-world problem of price prediction, and show a performance improvement of mean absolute error scores for our quantum-assisted method $(1471.02 \pm{135.6})$, vs. similar methodologies such as recursive feature elimination $(1678.3 \pm{143.7})$. Our findings show that by leveraging quantum-assisted routines we find solutions that increase the quality of predictive model output while reducing the input dimensionality to the learning algorithm on synthetic and real-world data.
Cross-Domain Recommendation: Challenges, Progress, and Prospects
Mar 02, 2021
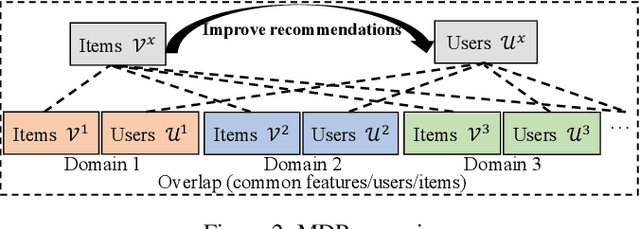
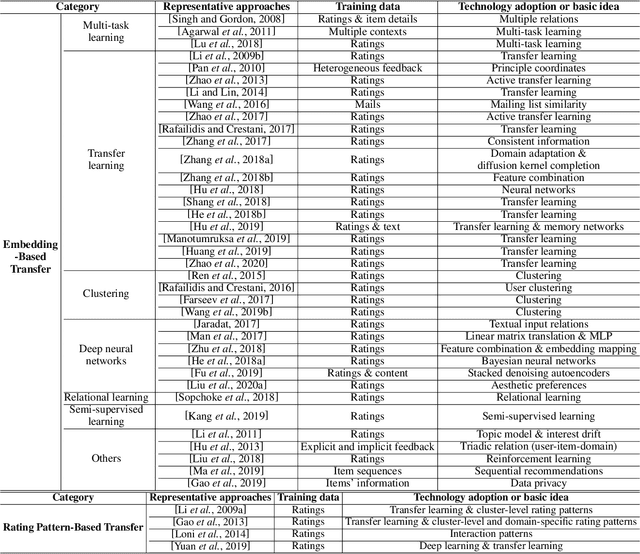
To address the long-standing data sparsity problem in recommender systems (RSs), cross-domain recommendation (CDR) has been proposed to leverage the relatively richer information from a richer domain to improve the recommendation performance in a sparser domain. Although CDR has been extensively studied in recent years, there is a lack of a systematic review of the existing CDR approaches. To fill this gap, in this paper, we provide a comprehensive review of existing CDR approaches, including challenges, research progress, and future directions. Specifically, we first summarize existing CDR approaches into four types, including single-target CDR, multi-domain recommendation, dual-target CDR, and multi-target CDR. We then present the definitions and challenges of these CDR approaches. Next, we propose a full-view categorization and new taxonomies on these approaches and report their research progress in detail. In the end, we share several promising research directions in CDR.
Spatial-temporal switching estimators for imaging locally concentrated dynamics
Feb 19, 2021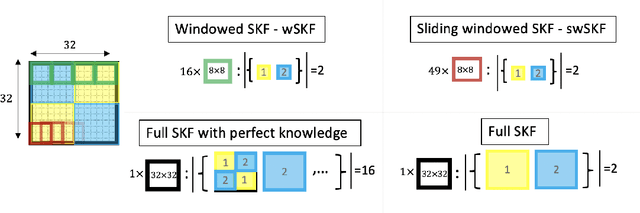
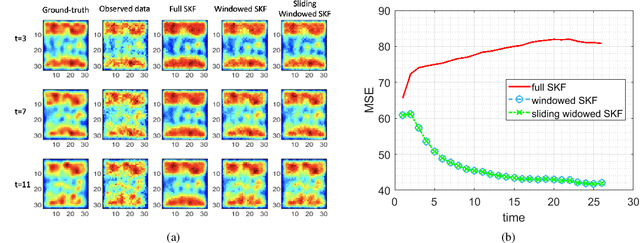
The evolution of images with physics-based dynamics is often spatially localized and nonlinear. A switching linear dynamic system (SLDS) is a natural model under which to pose such problems when the system's evolution randomly switches over the observation interval. Because of the high parameter space dimensionality, efficient and accurate recovery of the underlying state is challenging. The work presented in this paper focuses on the common cases where the dynamic evolution may be adequately modeled as a collection of decoupled, locally concentrated dynamic operators. Patch-based hybrid estimators are proposed for real-time reconstruction of images from noisy measurements given perfect or partial information about the underlying system dynamics. Numerical results demonstrate the effectiveness of the proposed approach for denoising in a realistic data-driven simulation of remotely sensed cloud dynamics.
DEFT: Distilling Entangled Factors
Feb 08, 2021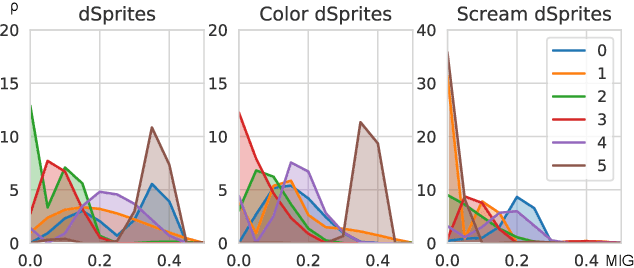
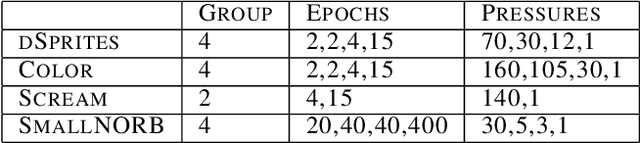
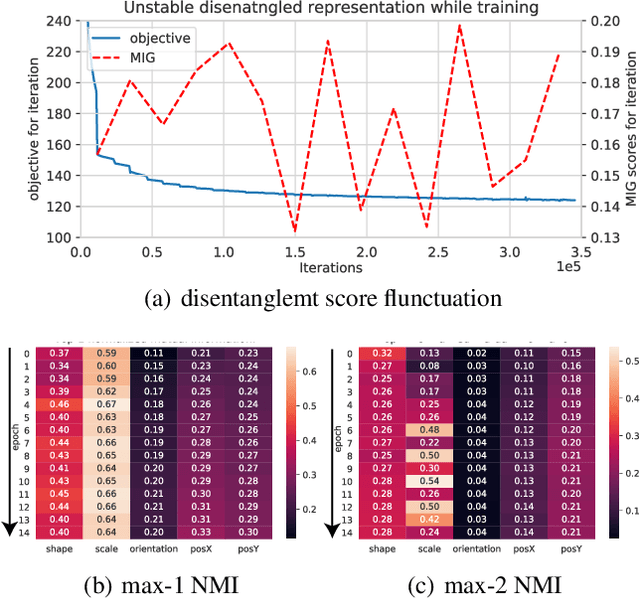
Disentanglement is a highly desirable property of representation due to its similarity with human understanding and reasoning. However, the performance of current disentanglement approaches is still unreliable and largely depends on the hyperparameter selection. Inspired by fractional distillation in chemistry, we propose DEFT, a disentanglement framework, to raise the lower limit of disentanglement approaches based on variational autoencoder. It applies a multi-stage training strategy, including multi-group encoders with different learning rates and piecewise disentanglement pressure, to stage by stage distill entangled factors. Furthermore, we provide insight into identifying the hyperparameters according to the information thresholds. We evaluate DEFT on three variants of dSprite and SmallNORB, showing robust and high-level disentanglement scores.