 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Novel Algorithm to Report CSI in MIMO-Based Wireless Networks
Apr 01, 2021
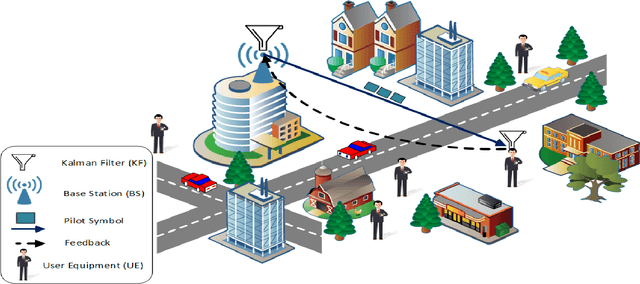
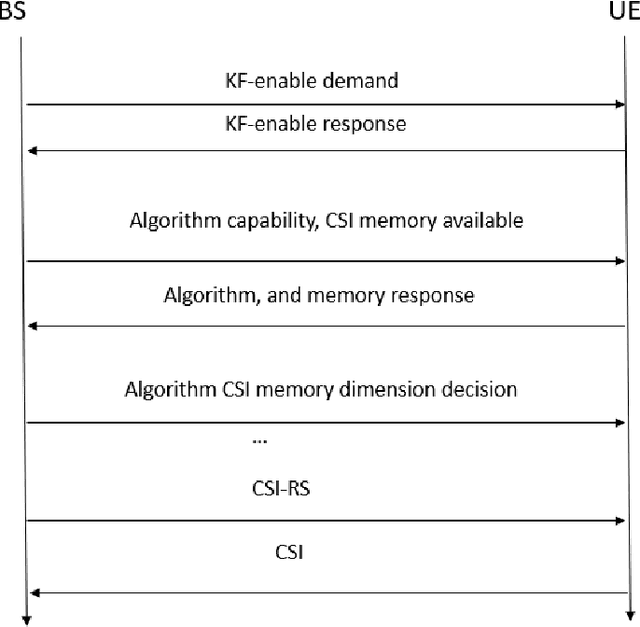
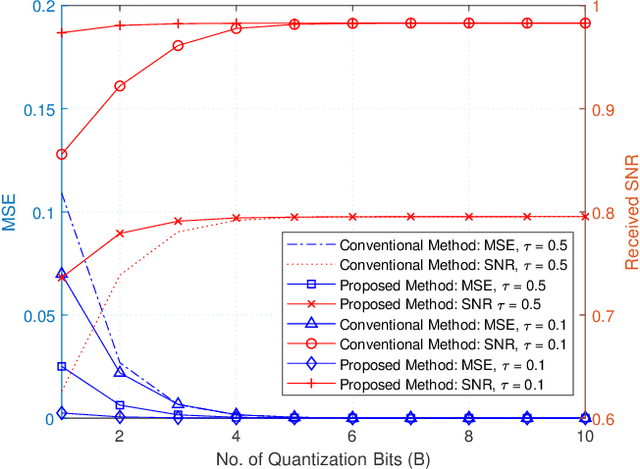
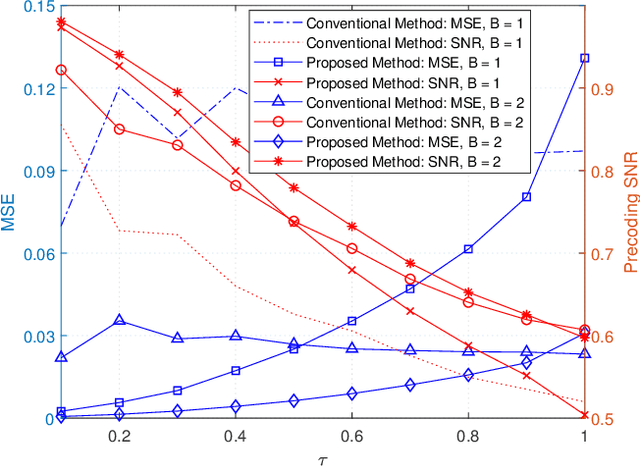
In wireless communication, accurate channel state information (CSI) is of pivotal importance. In practice, due to processing and feedback delays, estimated CSI can be outdated, which can severely deteriorate the performance of the communication system. Besides, to feedback estimated CSI, a strong compression of the CSI, evaluated at the user equipment (UE), is performed to reduce the over-the-air (OTA) overhead. Such compression strongly reduces the precision of the estimated CSI, which ultimately impacts the performance of multiple-input multiple-output (MIMO) precoding. Motivated by such issues, we present a novel scalable idea of reporting CSI in wireless networks, which is applicable to both time-division duplex (TDD) and frequency-division duplex (FDD) systems. In particular, the novel approach introduces the use of a channel predictor function, e.g., Kalman filter (KF), at both ends of the communication system to predict CSI. Simulation-based results demonstrate that the novel approach reduces not only the channel mean-squared-error (MSE) but also the OTA overhead to feedback the estimated CSI when there is immense variation in the mobile radio channel. Besides, in the immobile radio channel, feedback can be eliminated, which brings the benefit of further reducing the OTA overhead. Additionally, the proposed method provides a significant signal-to-noise ratio (SNR) gain in both the channel conditions, i.e., highly mobile and immobile.
Dynamic Lambda-Field: A Counterpart of the Bayesian Occupancy Grid for Risk Assessment in Dynamic Environments
Mar 08, 2021
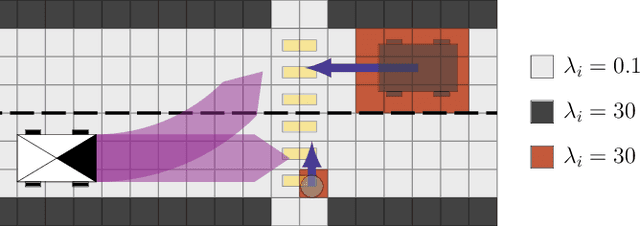
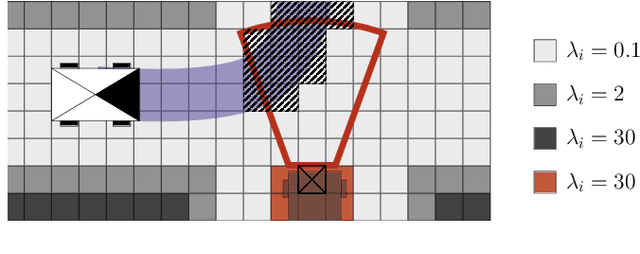
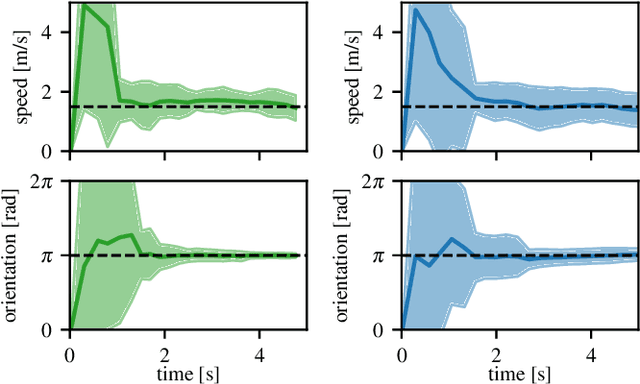
In the context of autonomous vehicles, one of the most crucial tasks is to estimate the risk of the undertaken action. While navigating in complex urban environments, the Bayesian occupancy grid is one of the most popular types of map, where the information of occupancy is stored as the probability of collision. Although widely used, this kind of representation is not well suited for risk assessment: because of its discrete nature, the probability of collision becomes dependent on the tessellation size. Therefore, risk assessments on Bayesian occupancy grids cannot yield risks with meaningful physical units. In this article, we propose an alternative framework called Dynamic Lambda-Field that is able to assess physical risks in dynamic environments without being dependent on the tessellation size. Using our framework, we are able to plan safe trajectories where the risk function can be adjusted depending on the scenario. We validate our approach with quantitative experiments, showing the convergence speed of the grid and that the framework is suitable for real-world scenarios.
Look, Evolve and Mold: Learning 3D Shape Manifold via Single-view Synthetic Data
Mar 08, 2021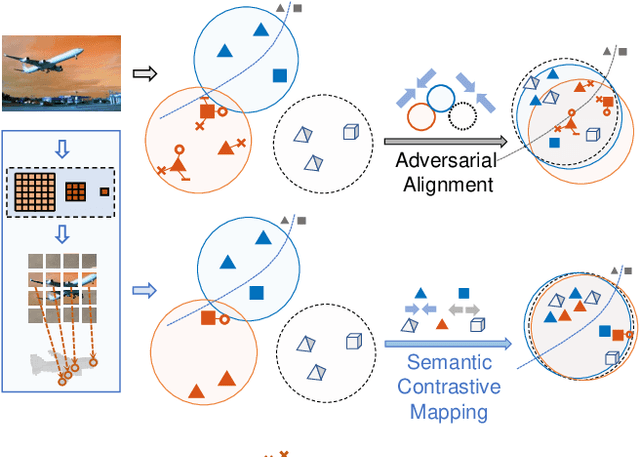
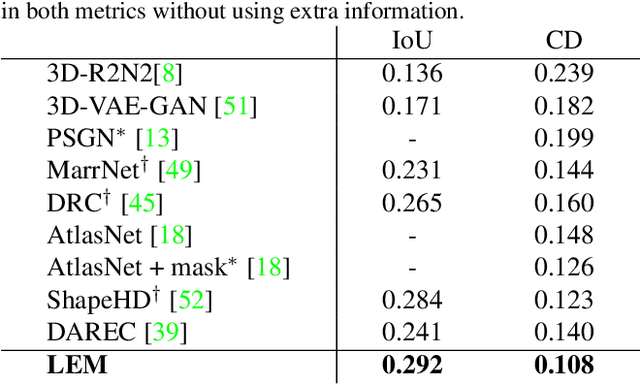
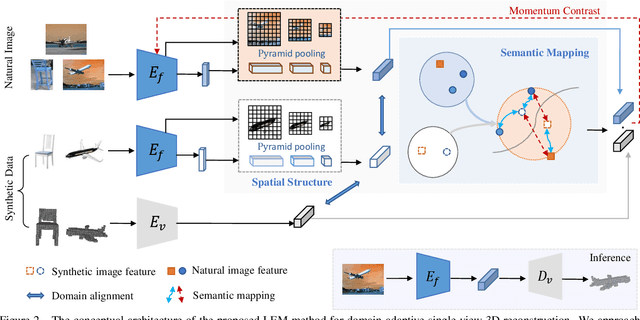
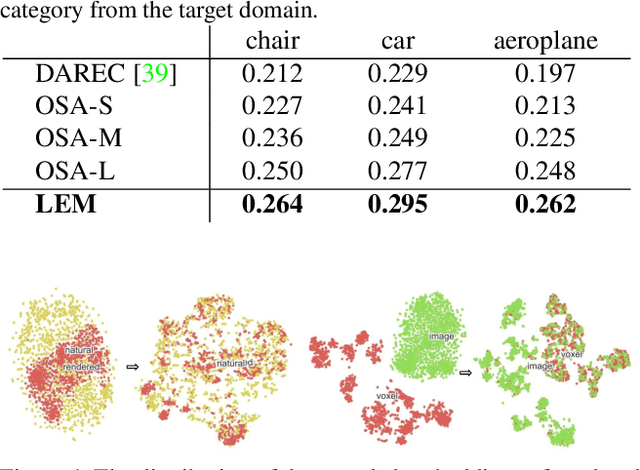
With daily observation and prior knowledge, it is easy for us human to infer the stereo structure via a single view. However, to equip the deep models with such ability usually requires abundant supervision. It is promising that without the elaborated 3D annotation, we can simply profit from the synthetic data, where pairwise ground-truth is easy to access. Nevertheless, the domain gap is not neglectable considering the variant texture, shape and context. To overcome these difficulties, we propose a domain-adaptive network for single-view 3D reconstruction, dubbed LEM, to generalize towards the natural scenario by fulfilling several aspects: (1) Look: incorporating spatial structure from the single view to enhance the representation; (2) Evolve: leveraging the semantic information with unsupervised contrastive mapping recurring to the shape priors; (3) Mold: transforming into the desired stereo manifold with discernment and semantic knowledge. Extensive experiments on several benchmarks demonstrate the effectiveness and robustness of the proposed method, LEM, in learning the 3D shape manifold from the synthetic data via a single-view.
DDGC: Generative Deep Dexterous Grasping in Clutter
Mar 08, 2021
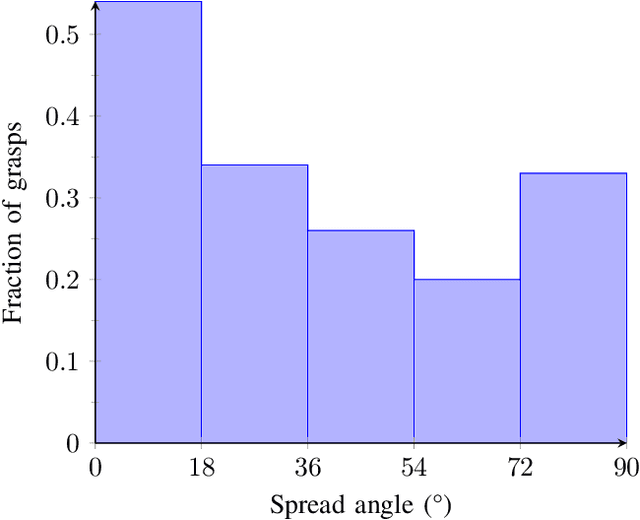
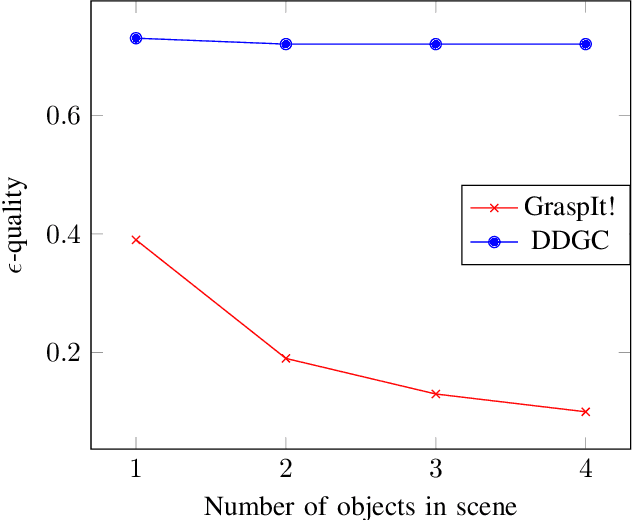

Recent advances in multi-fingered robotic grasping have enabled fast 6-Degrees-Of-Freedom (DOF) single object grasping. Multi-finger grasping in cluttered scenes, on the other hand, remains mostly unexplored due to the added difficulty of reasoning over obstacles which greatly increases the computational time to generate high-quality collision-free grasps. In this work we address such limitations by introducing DDGC, a fast generative multi-finger grasp sampling method that can generate high quality grasps in cluttered scenes from a single RGB-D image. DDGC is built as a network that encodes scene information to produce coarse-to-fine collision-free grasp poses and configurations. We experimentally benchmark DDGC against the simulated-annealing planner in GraspIt! on 1200 simulated cluttered scenes and 7 real world scenes. The results show that DDGC outperforms the baseline on synthesizing high-quality grasps and removing clutter while being 5 times faster. This, in turn, opens up the door for using multi-finger grasps in practical applications which has so far been limited due to the excessive computation time needed by other methods.
Neutron-Induced, Single-Event Effects on Neuromorphic Event-based Vision Sensor: A First Step Towards Space Applications
Jan 29, 2021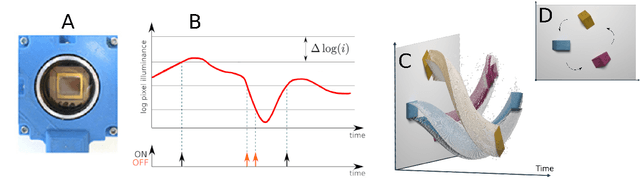

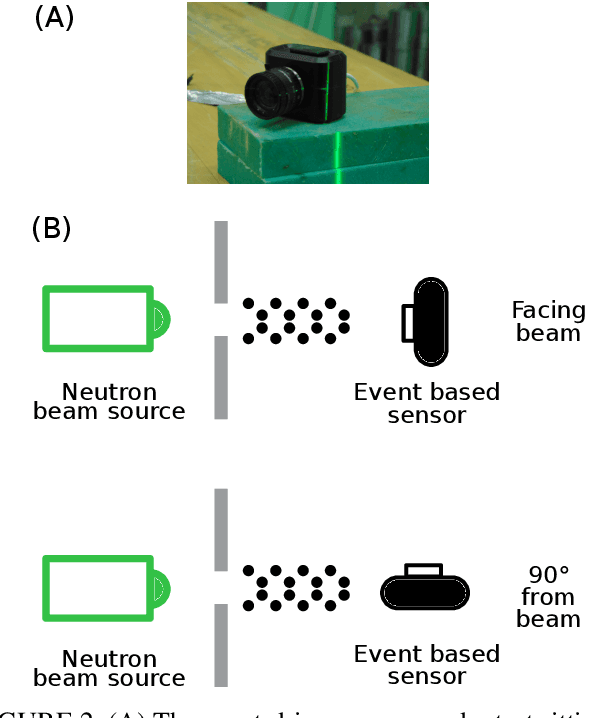
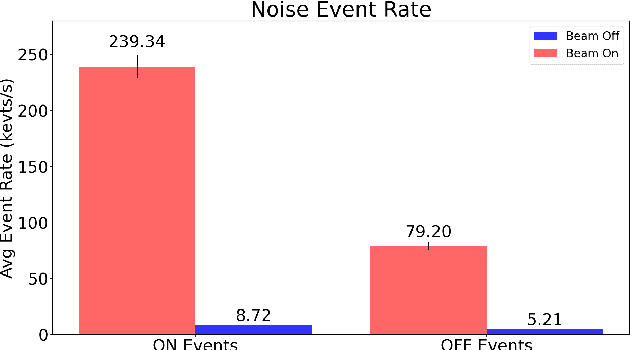
This paper studies the suitability of neuromorphic event-based vision cameras for spaceflight, and the effects of neutron radiation on their performance. Neuromorphic event-based vision cameras are novel sensors that implement asynchronous, clockless data acquisition, providing information about the change in illuminance greater than 120dB with sub-millisecond temporal precision. These sensors have huge potential for space applications as they provide an extremely sparse representation of visual dynamics while removing redundant information, thereby conforming to low-resource requirements. An event-based sensor was irradiated under wide-spectrum neutrons at Los Alamos Neutron Science Center and its effects were classified. We found that the sensor had very fast recovery during radiation, showing high correlation of noise event bursts with respect to source macro-pulses. No significant differences were observed between the number of events induced at different angles of incidence but significant differences were found in the spatial structure of noise events at different angles. The results show that event-based cameras are capable of functioning in a space-like, radiative environment with a signal-to-noise ratio of 3.355. They also show that radiation-induced noise does not affect event-level computation. We also introduce the Event-based Radiation-Induced Noise Simulation Environment (Event-RINSE), a simulation environment based on the noise-modelling we conducted and capable of injecting the effects of radiation-induced noise from the collected data to any stream of events in order to ensure that developed code can operate in a radiative environment. To the best of our knowledge, this is the first time such analysis of neutron-induced noise analysis has been performed on a neuromorphic vision sensor, and this study shows the advantage of using such sensors for space applications.
Triplet-Watershed for Hyperspectral Image Classification
Mar 17, 2021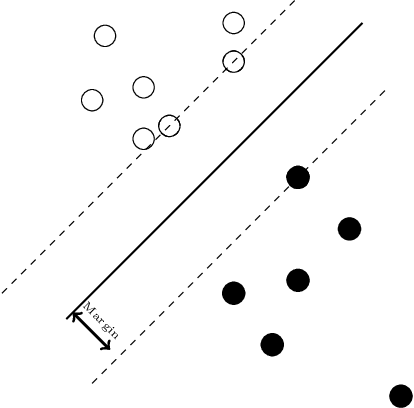
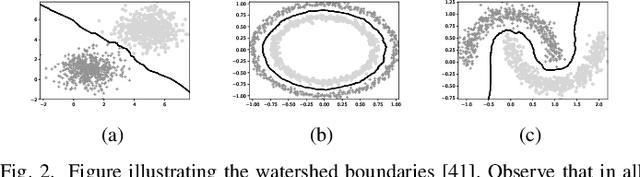
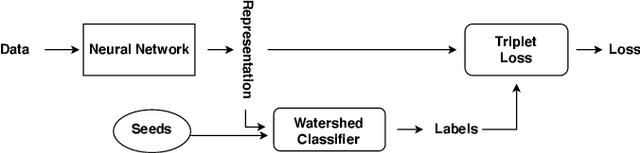
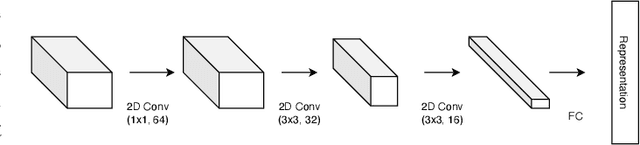
Hyperspectral images (HSI) consist of rich spatial and spectral information, which can potentially be used for several applications. However, noise, band correlations and high dimensionality restrict the applicability of such data. This is recently addressed using creative deep learning network architectures such as ResNet, SSRN, and A2S2K. However, the last layer, i.e the classification layer, remains unchanged and is taken to be the softmax classifier. In this article, we propose to use a watershed classifier. Watershed classifier extends the watershed operator from Mathematical Morphology for classification. In its vanilla form, the watershed classifier does not have any trainable parameters. In this article, we propose a novel approach to train deep learning networks to obtain representations suitable for the watershed classifier. The watershed classifier exploits the connectivity patterns, a characteristic of HSI datasets, for better inference. We show that exploiting such characteristics allows the Triplet-Watershed to achieve state-of-art results. These results are validated on Indianpines (IP), University of Pavia (UP), and Kennedy Space Center (KSC) datasets, relying on simple convnet architecture using a quarter of parameters compared to previous state-of-the-art networks.
SPICE: Semantic Pseudo-labeling for Image Clustering
Mar 17, 2021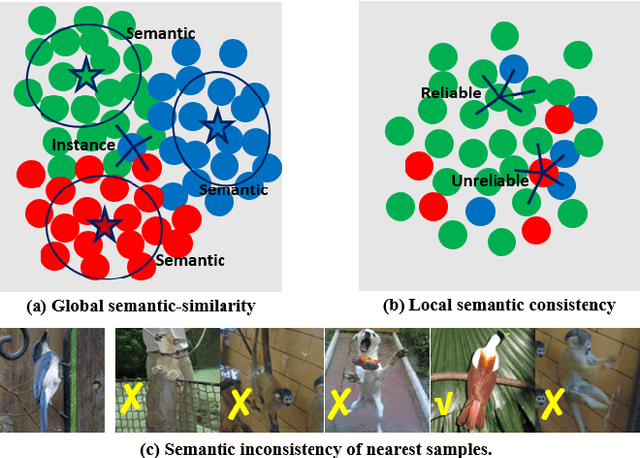
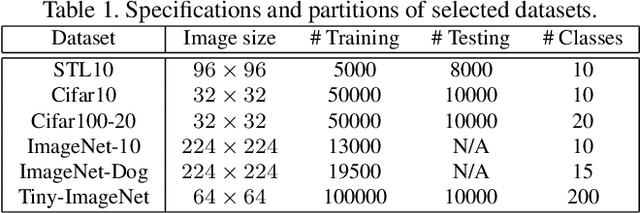
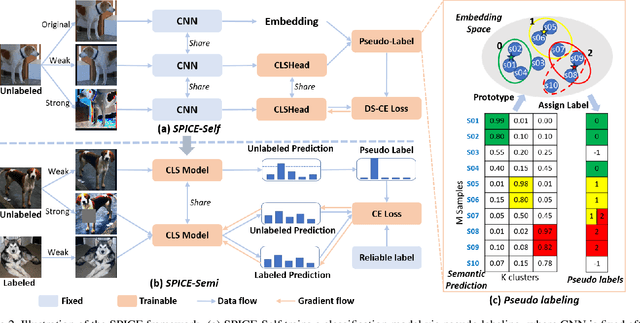
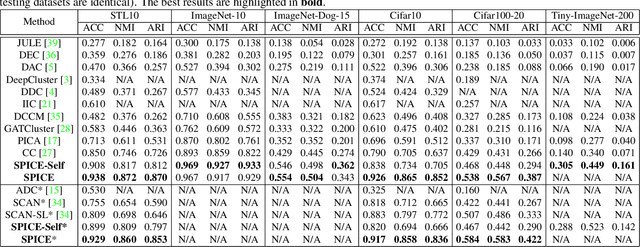
This paper presents SPICE, a Semantic Pseudo-labeling framework for Image ClustEring. Instead of using indirect loss functions required by the recently proposed methods, SPICE generates pseudo-labels via self-learning and directly uses the pseudo-label-based classification loss to train a deep clustering network. The basic idea of SPICE is to synergize the discrepancy among semantic clusters, the similarity among instance samples, and the semantic consistency of local samples in an embedding space to optimize the clustering network in a semantically-driven paradigm. Specifically, a semantic-similarity-based pseudo-labeling algorithm is first proposed to train a clustering network through unsupervised representation learning. Given the initial clustering results, a local semantic consistency principle is used to select a set of reliably labeled samples, and a semi-pseudo-labeling algorithm is adapted for performance boosting. Extensive experiments demonstrate that SPICE clearly outperforms the state-of-the-art methods on six common benchmark datasets including STL10, Cifar10, Cifar100-20, ImageNet-10, ImageNet-Dog, and Tiny-ImageNet. On average, our SPICE method improves the current best results by about 10% in terms of adjusted rand index, normalized mutual information, and clustering accuracy.
Predictive Relay Selection: A Cooperative Diversity Scheme Using Deep Learning
Feb 05, 2021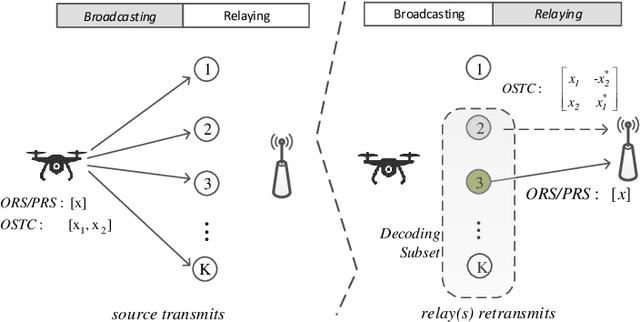
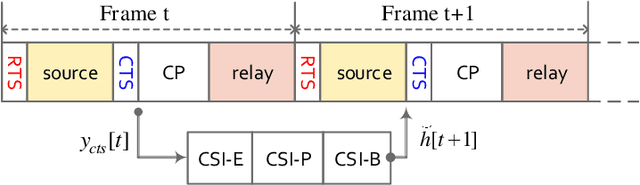
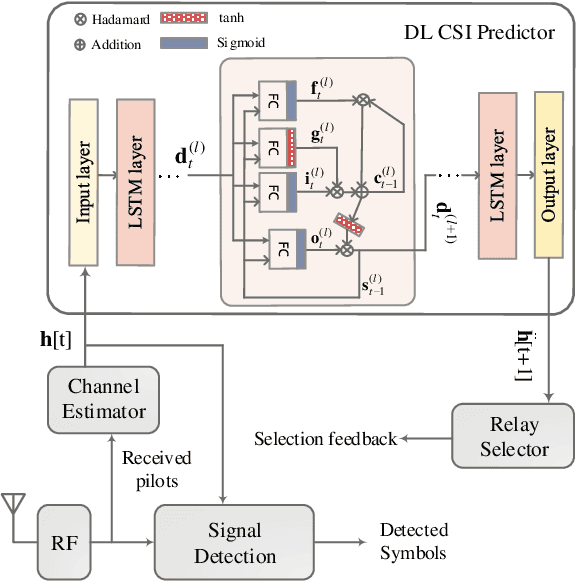
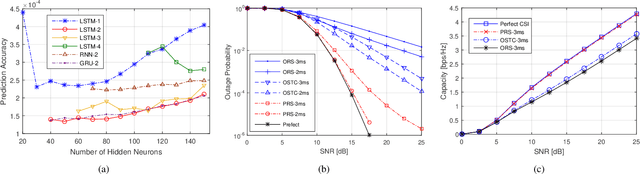
In this paper, we propose a novel cooperative multi-relay transmission scheme for mobile terminals to exploit spatial diversity. By improving the timeliness of measured channel state information (CSI) through deep learning (DL)-based channel prediction, the proposed scheme remarkably lowers the probability of wrong relay selection arising from outdated CSI in fast time-varying channels. It inherits the simplicity of opportunistic relaying by selecting a single relay, avoiding the complexity of multi-relay coordination and synchronization. Numerical results reveal that it can achieve full diversity gain in slow-fading channels and substantially outperforms the existing schemes in fast-fading wireless environments. Moreover, the computational complexity brought by the DL predictor is negligible compared to off-the-shelf computing hardware.
Dual-Task Mutual Learning for Semi-Supervised Medical Image Segmentation
Mar 08, 2021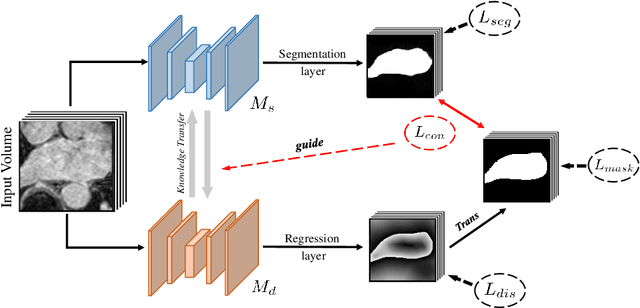
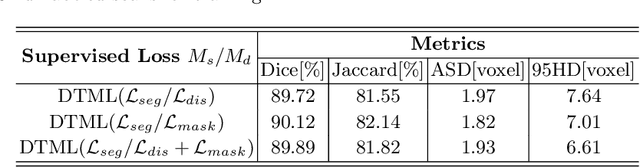
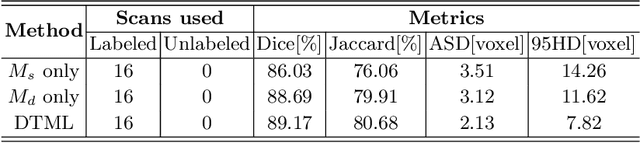
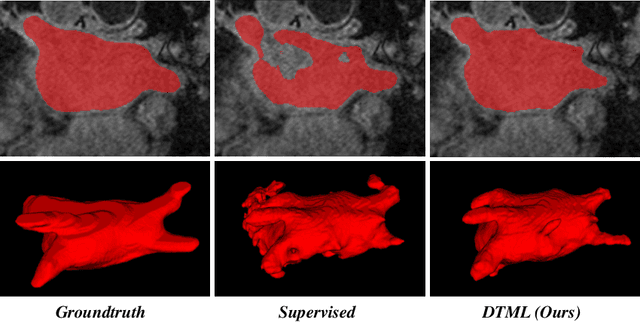
The success of deep learning methods in medical image segmentation tasks usually requires a large amount of labeled data. However, obtaining reliable annotations is expensive and time-consuming. Semi-supervised learning has attracted much attention in medical image segmentation by taking the advantage of unlabeled data which is much easier to acquire. In this paper, we propose a novel dual-task mutual learning framework for semi-supervised medical image segmentation. Our framework can be formulated as an integration of two individual segmentation networks based on two tasks: learning region-based shape constraint and learning boundary-based surface mismatch. Different from the one-way transfer between teacher and student networks, an ensemble of dual-task students can learn collaboratively and implicitly explore useful knowledge from each other during the training process. By jointly learning the segmentation probability maps and signed distance maps of targets, our framework can enforce the geometric shape constraint and learn more reliable information. Experimental results demonstrate that our method achieves performance gains by leveraging unlabeled data and outperforms the state-of-the-art semi-supervised segmentation methods.
Distributed Reinforcement Learning for Flexible and Efficient UAV Swarm Control
Mar 08, 2021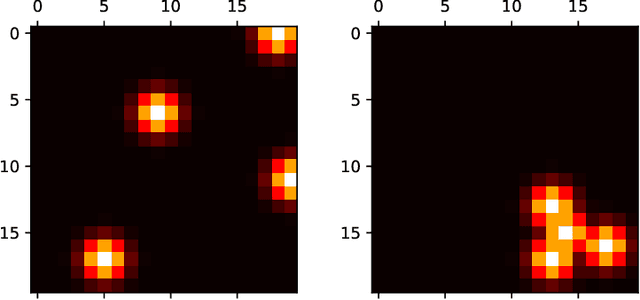
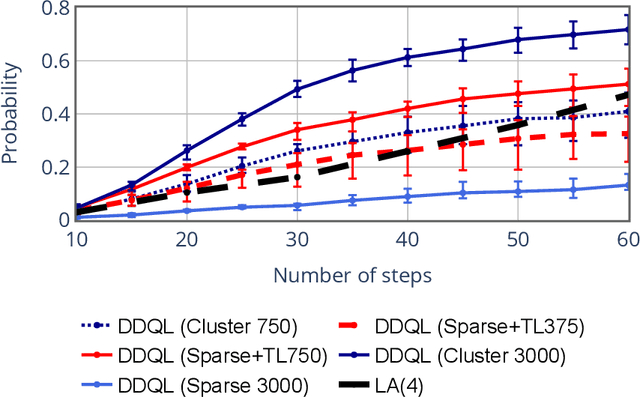
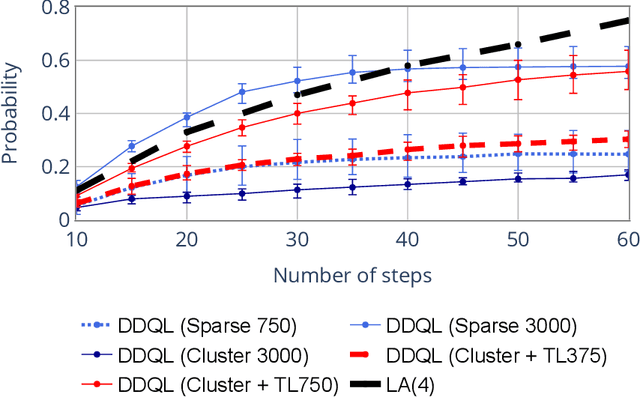
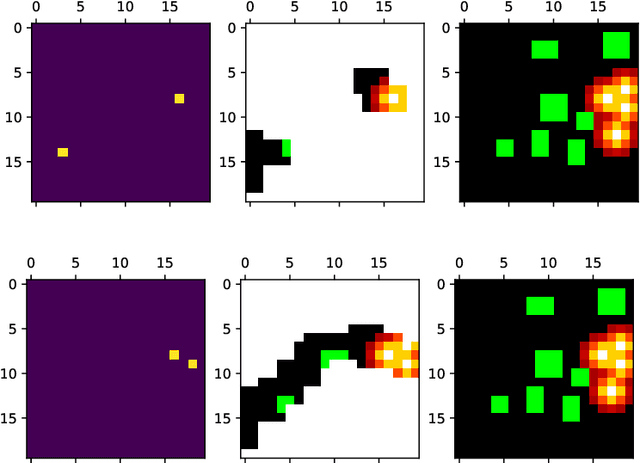
Over the past few years, the use of swarms of Unmanned Aerial Vehicles (UAVs) in monitoring and remote area surveillance applications has become widespread thanks to the price reduction and the increased capabilities of drones. The drones in the swarm need to cooperatively explore an unknown area, in order to identify and monitor interesting targets, while minimizing their movements. In this work, we propose a distributed Reinforcement Learning (RL) approach that scales to larger swarms without modifications. The proposed framework relies on the possibility for the UAVs to exchange some information through a communication channel, in order to achieve context-awareness and implicitly coordinate the swarm's actions. Our experiments show that the proposed method can yield effective strategies, which are robust to communication channel impairments, and that can easily deal with non-uniform distributions of targets and obstacles. Moreover, when agents are trained in a specific scenario, they can adapt to a new one with minimal additional training. We also show that our approach achieves better performance compared to a computationally intensive look-ahead heuristic.