 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Human Objectives from Sequences of Physical Corrections
Mar 31, 2021
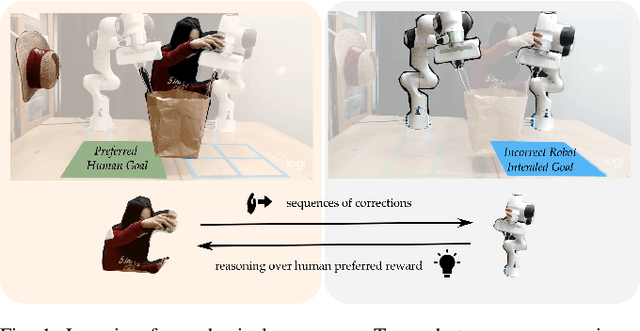
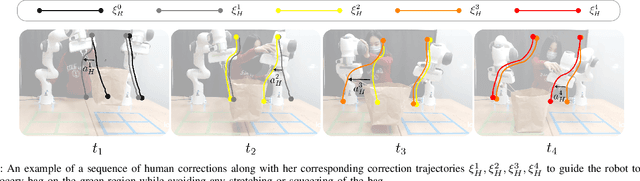
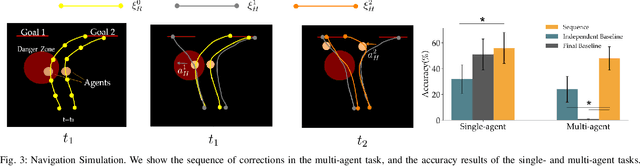
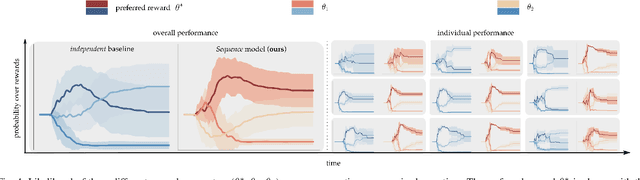
When personal, assistive, and interactive robots make mistakes, humans naturally and intuitively correct those mistakes through physical interaction. In simple situations, one correction is sufficient to convey what the human wants. But when humans are working with multiple robots or the robot is performing an intricate task often the human must make several corrections to fix the robot's behavior. Prior research assumes each of these physical corrections are independent events, and learns from them one-at-a-time. However, this misses out on crucial information: each of these interactions are interconnected, and may only make sense if viewed together. Alternatively, other work reasons over the final trajectory produced by all of the human's corrections. But this method must wait until the end of the task to learn from corrections, as opposed to inferring from the corrections in an online fashion. In this paper we formalize an approach for learning from sequences of physical corrections during the current task. To do this we introduce an auxiliary reward that captures the human's trade-off between making corrections which improve the robot's immediate reward and long-term performance. We evaluate the resulting algorithm in remote and in-person human-robot experiments, and compare to both independent and final baselines. Our results indicate that users are best able to convey their objective when the robot reasons over their sequence of corrections.
The impact of using biased performance metrics on software defect prediction research
Mar 24, 2021
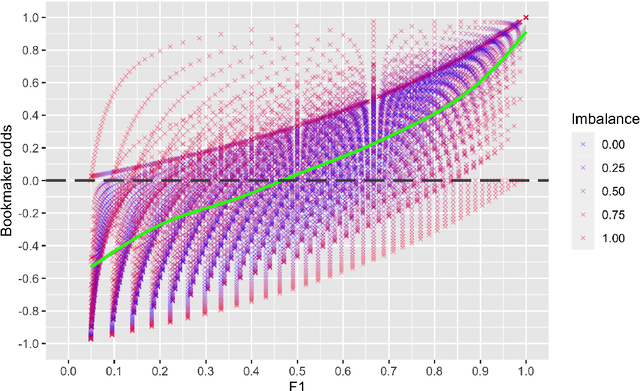
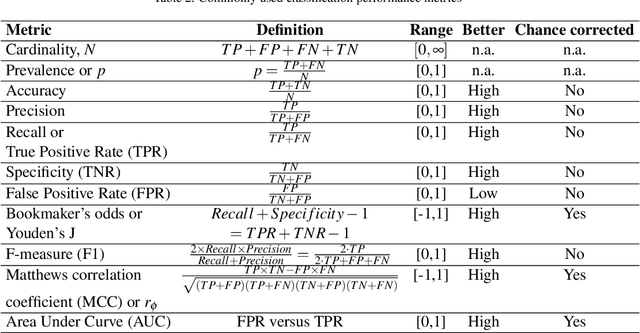
Context: Software engineering researchers have undertaken many experiments investigating the potential of software defect prediction algorithms. Unfortunately, some widely used performance metrics are known to be problematic, most notably F1, but nevertheless F1 is widely used. Objective: To investigate the potential impact of using F1 on the validity of this large body of research. Method: We undertook a systematic review to locate relevant experiments and then extract all pairwise comparisons of defect prediction performance using F1 and the un-biased Matthews correlation coefficient (MCC). Results: We found a total of 38 primary studies. These contain 12,471 pairs of results. Of these, 21.95% changed direction when the MCC metric is used instead of the biased F1 metric. Unfortunately, we also found evidence suggesting that F1 remains widely used in software defect prediction research. Conclusions: We reiterate the concerns of statisticians that the F1 is a problematic metric outside of an information retrieval context, since we are concerned about both classes (defect-prone and not defect-prone units). This inappropriate usage has led to a substantial number (more than one fifth) of erroneous (in terms of direction) results. Therefore we urge researchers to (i) use an unbiased metric and (ii) publish detailed results including confusion matrices such that alternative analyses become possible.
A multi-modal approach towards mining social media data during natural disasters -- a case study of Hurricane Irma
Jan 02, 2021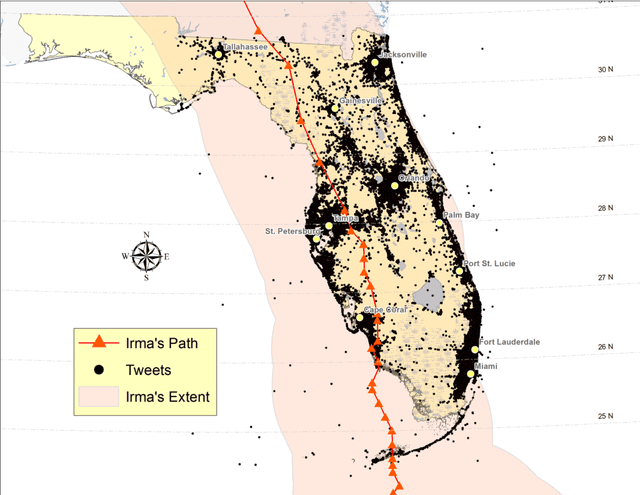
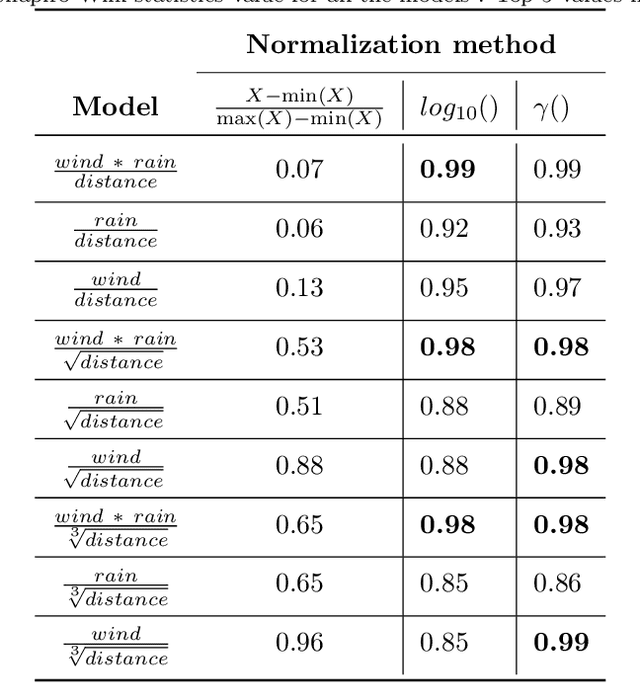
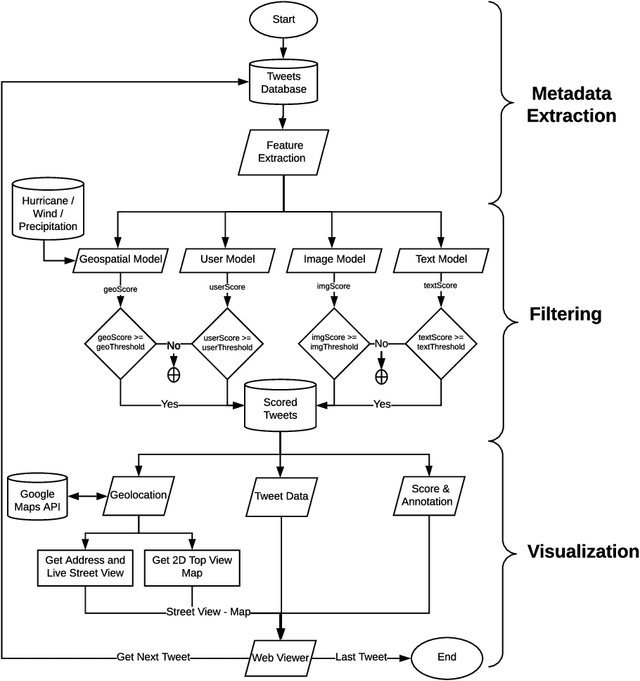
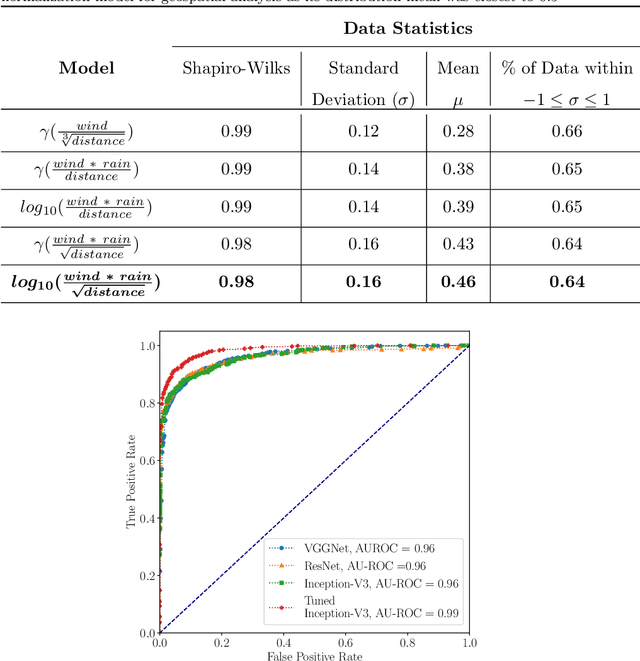
Streaming social media provides a real-time glimpse of extreme weather impacts. However, the volume of streaming data makes mining information a challenge for emergency managers, policy makers, and disciplinary scientists. Here we explore the effectiveness of data learned approaches to mine and filter information from streaming social media data from Hurricane Irma's landfall in Florida, USA. We use 54,383 Twitter messages (out of 784K geolocated messages) from 16,598 users from Sept. 10 - 12, 2017 to develop 4 independent models to filter data for relevance: 1) a geospatial model based on forcing conditions at the place and time of each tweet, 2) an image classification model for tweets that include images, 3) a user model to predict the reliability of the tweeter, and 4) a text model to determine if the text is related to Hurricane Irma. All four models are independently tested, and can be combined to quickly filter and visualize tweets based on user-defined thresholds for each submodel. We envision that this type of filtering and visualization routine can be useful as a base model for data capture from noisy sources such as Twitter. The data can then be subsequently used by policy makers, environmental managers, emergency managers, and domain scientists interested in finding tweets with specific attributes to use during different stages of the disaster (e.g., preparedness, response, and recovery), or for detailed research.
Temporal Memory Attention for Video Semantic Segmentation
Feb 17, 2021
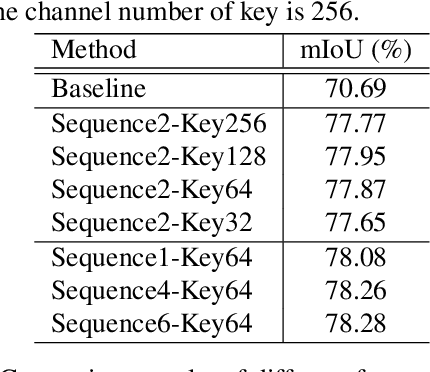
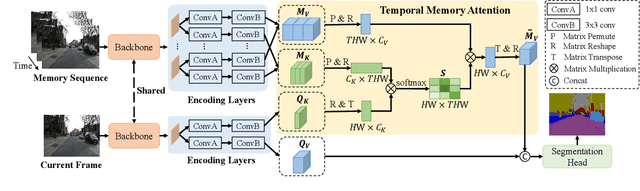

Video semantic segmentation requires to utilize the complex temporal relations between frames of the video sequence. Previous works usually exploit accurate optical flow to leverage the temporal relations, which suffer much from heavy computational cost. In this paper, we propose a Temporal Memory Attention Network (TMANet) to adaptively integrate the long-range temporal relations over the video sequence based on the self-attention mechanism without exhaustive optical flow prediction. Specially, we construct a memory using several past frames to store the temporal information of the current frame. We then propose a temporal memory attention module to capture the relation between the current frame and the memory to enhance the representation of the current frame. Our method achieves new state-of-the-art performances on two challenging video semantic segmentation datasets, particularly 80.3% mIoU on Cityscapes and 76.5% mIoU on CamVid with ResNet-50.
Dynamic Lambda-Field: A Counterpart of the Bayesian Occupancy Grid for Risk Assessment in Dynamic Environments
Mar 08, 2021
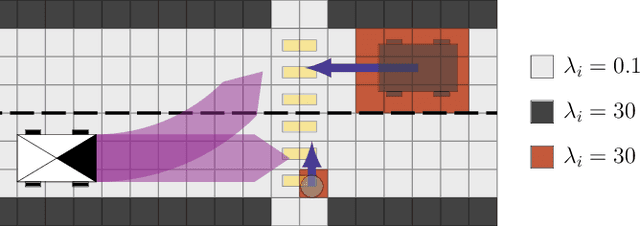
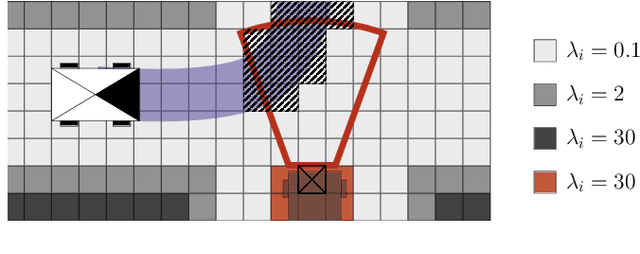
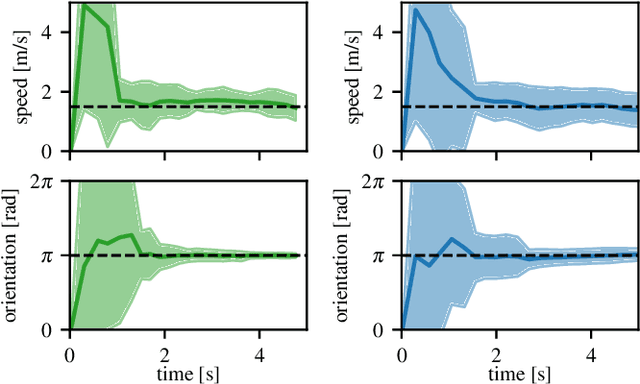
In the context of autonomous vehicles, one of the most crucial tasks is to estimate the risk of the undertaken action. While navigating in complex urban environments, the Bayesian occupancy grid is one of the most popular types of map, where the information of occupancy is stored as the probability of collision. Although widely used, this kind of representation is not well suited for risk assessment: because of its discrete nature, the probability of collision becomes dependent on the tessellation size. Therefore, risk assessments on Bayesian occupancy grids cannot yield risks with meaningful physical units. In this article, we propose an alternative framework called Dynamic Lambda-Field that is able to assess physical risks in dynamic environments without being dependent on the tessellation size. Using our framework, we are able to plan safe trajectories where the risk function can be adjusted depending on the scenario. We validate our approach with quantitative experiments, showing the convergence speed of the grid and that the framework is suitable for real-world scenarios.
Look, Evolve and Mold: Learning 3D Shape Manifold via Single-view Synthetic Data
Mar 08, 2021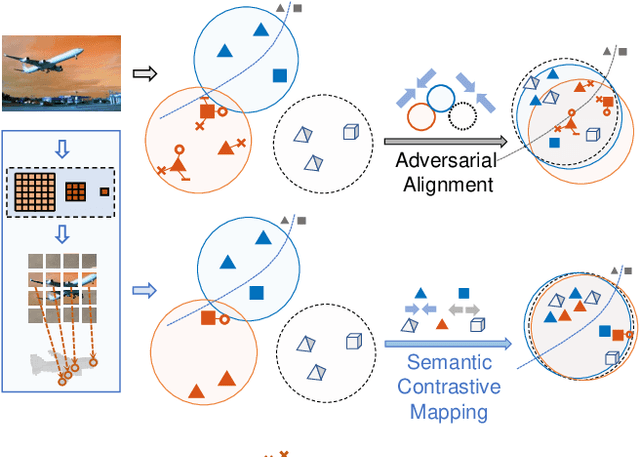
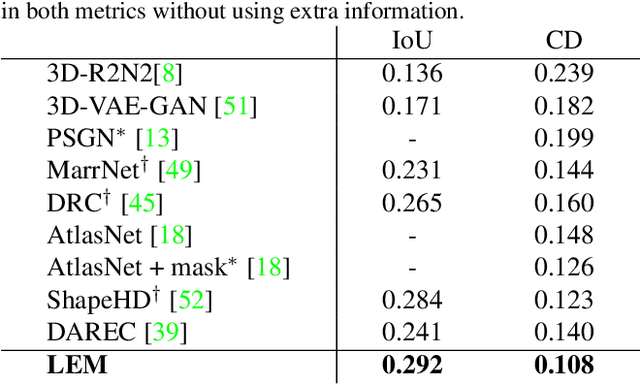
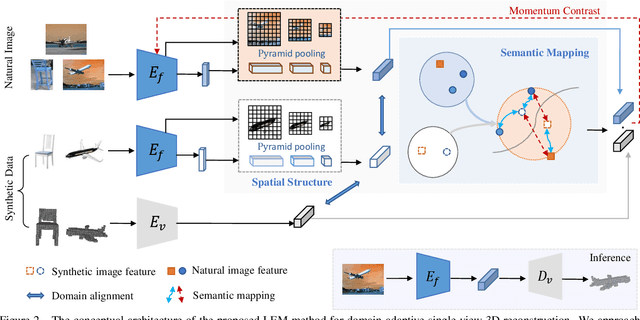
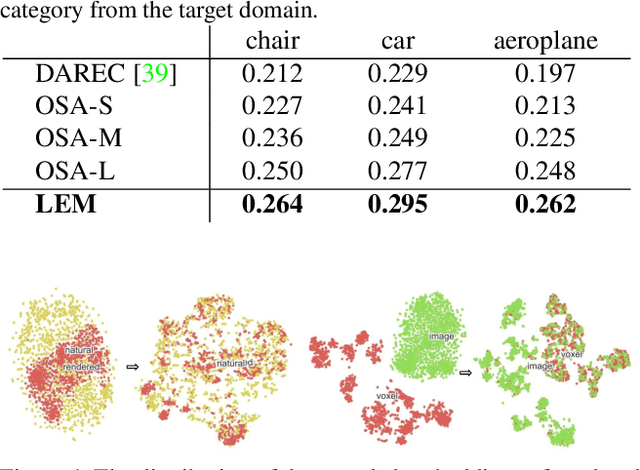
With daily observation and prior knowledge, it is easy for us human to infer the stereo structure via a single view. However, to equip the deep models with such ability usually requires abundant supervision. It is promising that without the elaborated 3D annotation, we can simply profit from the synthetic data, where pairwise ground-truth is easy to access. Nevertheless, the domain gap is not neglectable considering the variant texture, shape and context. To overcome these difficulties, we propose a domain-adaptive network for single-view 3D reconstruction, dubbed LEM, to generalize towards the natural scenario by fulfilling several aspects: (1) Look: incorporating spatial structure from the single view to enhance the representation; (2) Evolve: leveraging the semantic information with unsupervised contrastive mapping recurring to the shape priors; (3) Mold: transforming into the desired stereo manifold with discernment and semantic knowledge. Extensive experiments on several benchmarks demonstrate the effectiveness and robustness of the proposed method, LEM, in learning the 3D shape manifold from the synthetic data via a single-view.
A Relational Tsetlin Machine with Applications to Natural Language Understanding
Feb 22, 2021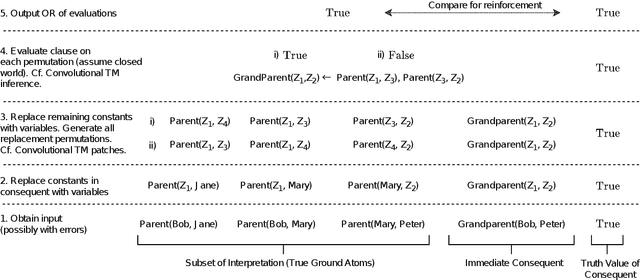


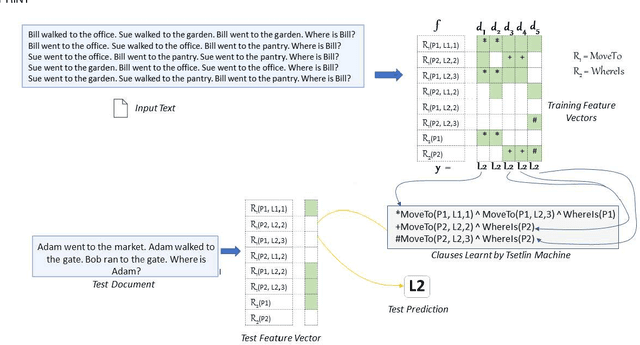
TMs are a pattern recognition approach that uses finite state machines for learning and propositional logic to represent patterns. In addition to being natively interpretable, they have provided competitive accuracy for various tasks. In this paper, we increase the computing power of TMs by proposing a first-order logic-based framework with Herbrand semantics. The resulting TM is relational and can take advantage of logical structures appearing in natural language, to learn rules that represent how actions and consequences are related in the real world. The outcome is a logic program of Horn clauses, bringing in a structured view of unstructured data. In closed-domain question-answering, the first-order representation produces 10x more compact KBs, along with an increase in answering accuracy from 94.83% to 99.48%. The approach is further robust towards erroneous, missing, and superfluous information, distilling the aspects of a text that are important for real-world understanding.
DDGC: Generative Deep Dexterous Grasping in Clutter
Mar 08, 2021
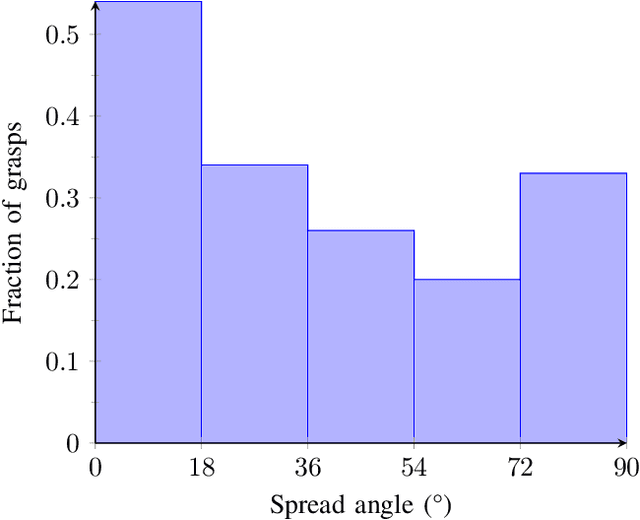
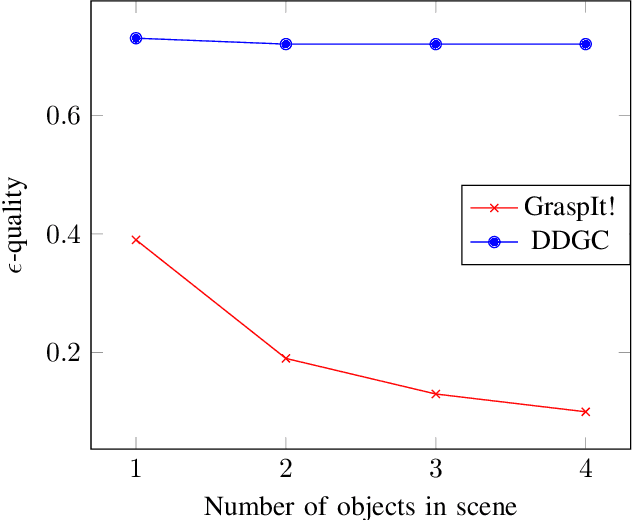

Recent advances in multi-fingered robotic grasping have enabled fast 6-Degrees-Of-Freedom (DOF) single object grasping. Multi-finger grasping in cluttered scenes, on the other hand, remains mostly unexplored due to the added difficulty of reasoning over obstacles which greatly increases the computational time to generate high-quality collision-free grasps. In this work we address such limitations by introducing DDGC, a fast generative multi-finger grasp sampling method that can generate high quality grasps in cluttered scenes from a single RGB-D image. DDGC is built as a network that encodes scene information to produce coarse-to-fine collision-free grasp poses and configurations. We experimentally benchmark DDGC against the simulated-annealing planner in GraspIt! on 1200 simulated cluttered scenes and 7 real world scenes. The results show that DDGC outperforms the baseline on synthesizing high-quality grasps and removing clutter while being 5 times faster. This, in turn, opens up the door for using multi-finger grasps in practical applications which has so far been limited due to the excessive computation time needed by other methods.
Physarum Polycephalum Intelligent Foraging Behaviour and Applications -- Short Review
Feb 27, 2021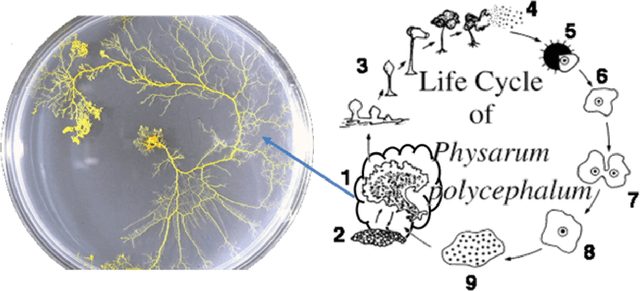
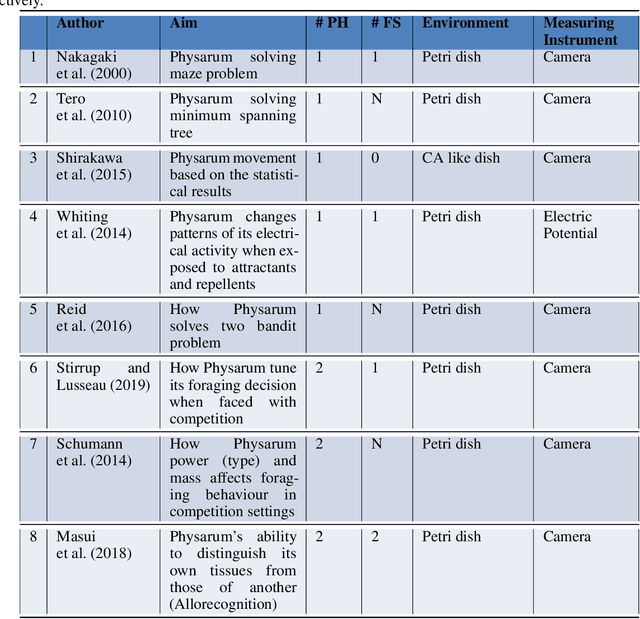
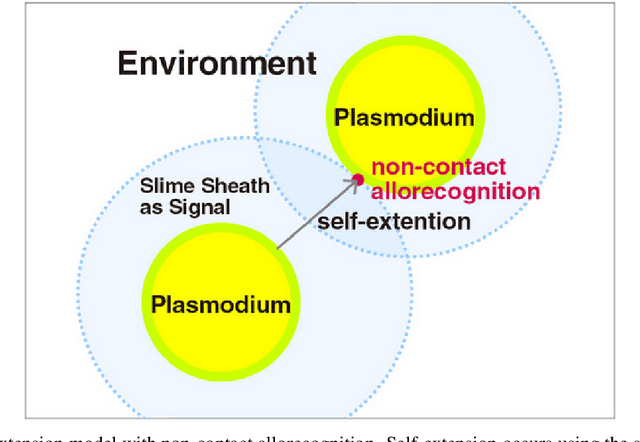
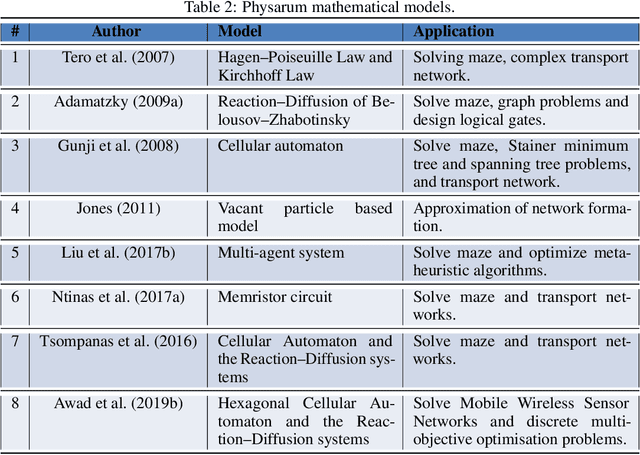
Physarum polycephalum (Physarum for short) is an example of plasmodial slime moulds that are classified as a fungus "Myxomycetes". In recent years, research on Physarum has become more popular after Nakagaki et al. (2000) performed his famous experiments showing that Physarum was able to find the shortest route through a maze. Physarum) may not have a central information processing unit like a brain, however, recent research has confirmed the ability of Physarum-inspired algorithms to solve a wide range of NP-hard problems. This review will through light on recent Physarum polycephalum biological aspects, mathematical models, and Physarum bio-inspired algorithms and its applications. Further, we have added presented our new model to simulate Physarum in competition, where multiple Physarum interact with each other and with their environments. The bio-inspired Physarum in competition algorithms proved to have great potentials in dealing with graph-optimisation problems in a dynamic environment as in Mobile Wireless Sensor Networks, and Discrete Multi-Objective Optimisation problems.
Context Aware 3D UNet for Brain Tumor Segmentation
Oct 25, 2020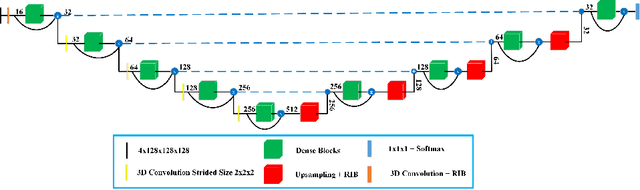
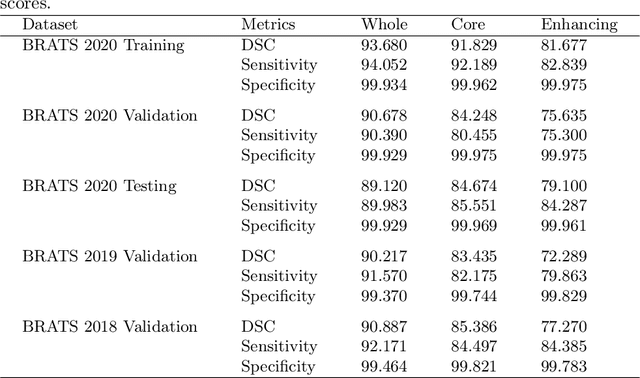
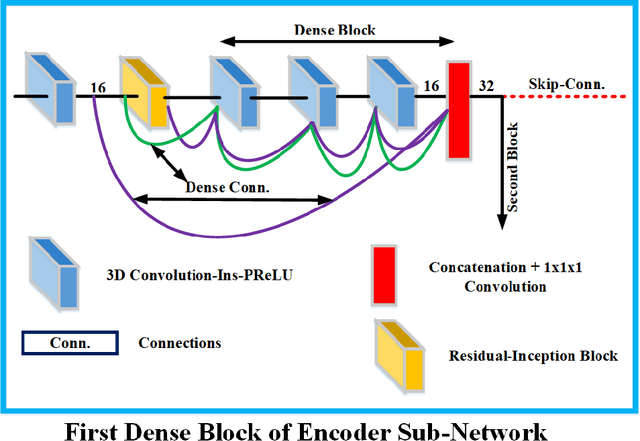

Deep convolutional neural network (CNN) achieves remarkable performance for medical image analysis. UNet is the primary source in the performance of 3D CNN architectures for medical imaging tasks, including brain tumor segmentation. The skip connection in the UNet architecture concatenates features from both encoder and decoder paths to extract multi-contexual information from image data. The multi-scaled features play an essential role in brain tumor segmentation. However, the limited use of features can degrade the performance of the UNet approach for segmentation. In this paper, we propose a modified UNet architecture for brain tumor segmentation. In the proposed architecture, we used densely connected blocks in both encoder and decoder paths to extract multi-contexual information from the concept of feature reusability. The proposed residual inception blocks (RIB) are used to extract local and global information by merging features of different kernel sizes. We validate the proposed architecture on the multimodal brain tumor segmentation challenges (BRATS) 2020 testing dataset. The dice (DSC) scores of the whole tumor (WT), tumor core (TC), and enhancement tumor (ET) are 89.12%, 84.74%, and 79.12%, respectively. Our proposed work is in the top ten methods based on the dice scores of the testing dataset.