 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Estimation of Fiber Orientations Using Neighborhood Information
May 16, 2016
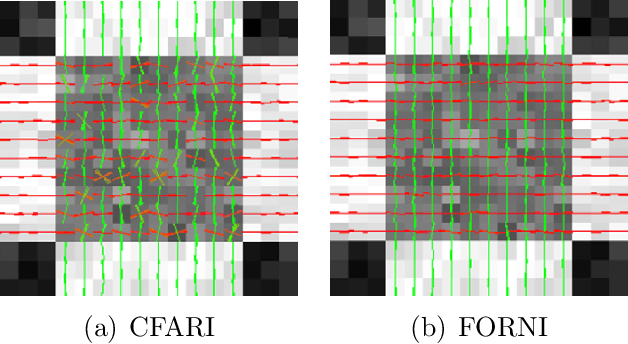

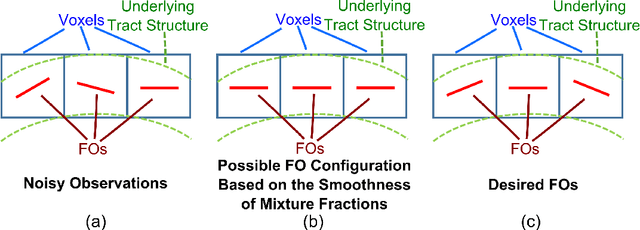

Data from diffusion magnetic resonance imaging (dMRI) can be used to reconstruct fiber tracts, for example, in muscle and white matter. Estimation of fiber orientations (FOs) is a crucial step in the reconstruction process and these estimates can be corrupted by noise. In this paper, a new method called Fiber Orientation Reconstruction using Neighborhood Information (FORNI) is described and shown to reduce the effects of noise and improve FO estimation performance by incorporating spatial consistency. FORNI uses a fixed tensor basis to model the diffusion weighted signals, which has the advantage of providing an explicit relationship between the basis vectors and the FOs. FO spatial coherence is encouraged using weighted l1-norm regularization terms, which contain the interaction of directional information between neighbor voxels. Data fidelity is encouraged using a squared error between the observed and reconstructed diffusion weighted signals. After appropriate weighting of these competing objectives, the resulting objective function is minimized using a block coordinate descent algorithm, and a straightforward parallelization strategy is used to speed up processing. Experiments were performed on a digital crossing phantom, ex vivo tongue dMRI data, and in vivo brain dMRI data for both qualitative and quantitative evaluation. The results demonstrate that FORNI improves the quality of FO estimation over other state of the art algorithms.
Multivariate information measures: an experimentalist's perspective
Aug 29, 2012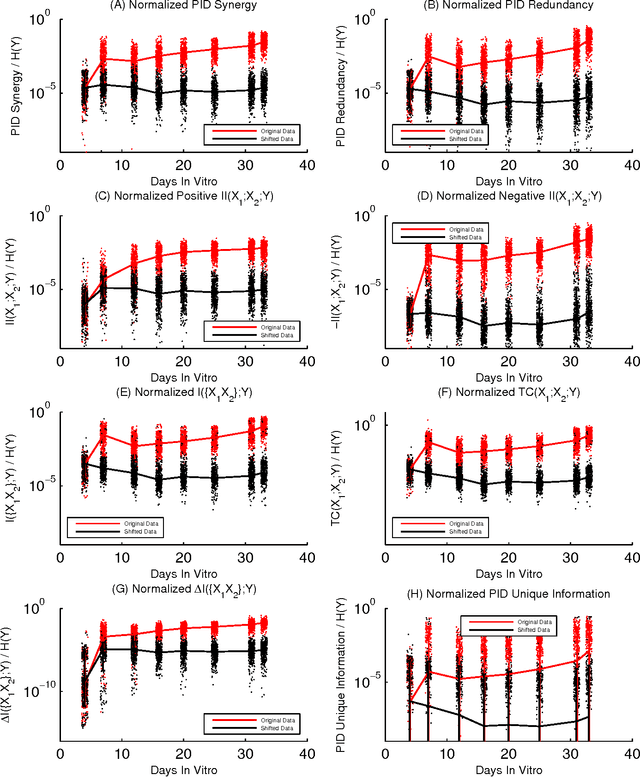
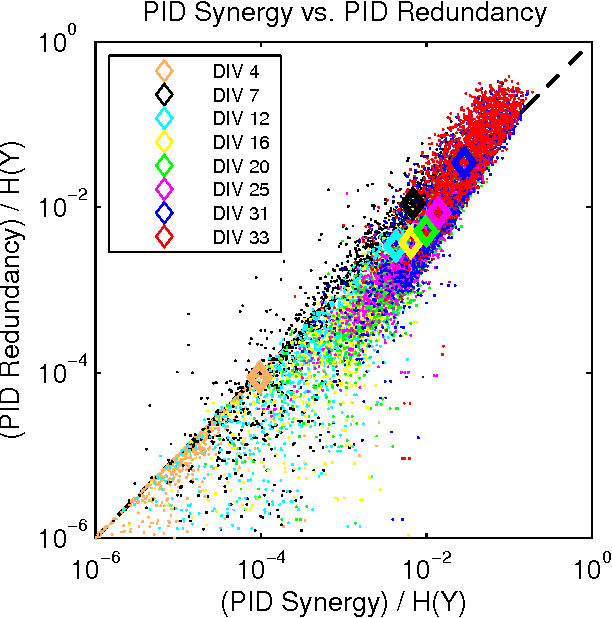


Information theory is widely accepted as a powerful tool for analyzing complex systems and it has been applied in many disciplines. Recently, some central components of information theory - multivariate information measures - have found expanded use in the study of several phenomena. These information measures differ in subtle yet significant ways. Here, we will review the information theory behind each measure, as well as examine the differences between these measures by applying them to several simple model systems. In addition to these systems, we will illustrate the usefulness of the information measures by analyzing neural spiking data from a dissociated culture through early stages of its development. We hope that this work will aid other researchers as they seek the best multivariate information measure for their specific research goals and system. Finally, we have made software available online which allows the user to calculate all of the information measures discussed within this paper.
Deep Models for Engagement Assessment With Scarce Label Information
Oct 21, 2016
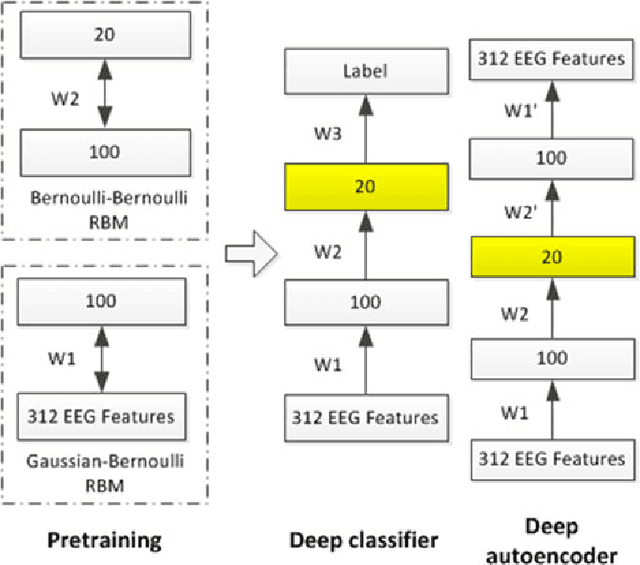
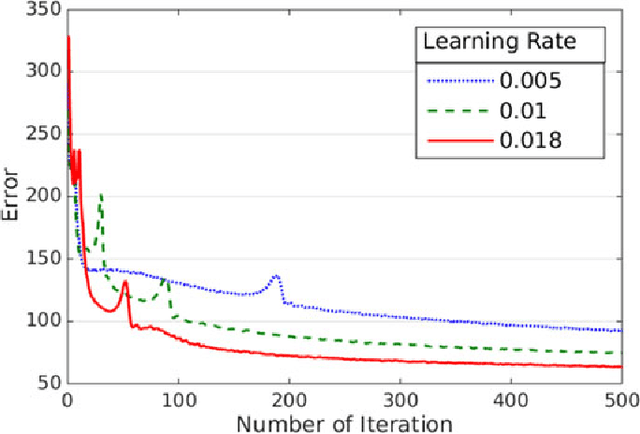
Task engagement is defined as loadings on energetic arousal (affect), task motivation, and concentration (cognition). It is usually challenging and expensive to label cognitive state data, and traditional computational models trained with limited label information for engagement assessment do not perform well because of overfitting. In this paper, we proposed two deep models (i.e., a deep classifier and a deep autoencoder) for engagement assessment with scarce label information. We recruited 15 pilots to conduct a 4-h flight simulation from Seattle to Chicago and recorded their electroencephalograph (EEG) signals during the simulation. Experts carefully examined the EEG signals and labeled 20 min of the EEG data for each pilot. The EEG signals were preprocessed and power spectral features were extracted. The deep models were pretrained by the unlabeled data and were fine-tuned by a different proportion of the labeled data (top 1%, 3%, 5%, 10%, 15%, and 20%) to learn new representations for engagement assessment. The models were then tested on the remaining labeled data. We compared performances of the new data representations with the original EEG features for engagement assessment. Experimental results show that the representations learned by the deep models yielded better accuracies for the six scenarios (77.09%, 80.45%, 83.32%, 85.74%, 85.78%, and 86.52%), based on different proportions of the labeled data for training, as compared with the corresponding accuracies (62.73%, 67.19%, 73.38%, 79.18%, 81.47%, and 84.92%) achieved by the original EEG features. Deep models are effective for engagement assessment especially when less label information was used for training.
Learning Effective Representations from Global and Local Features for Cross-View Gait Recognition
Nov 03, 2020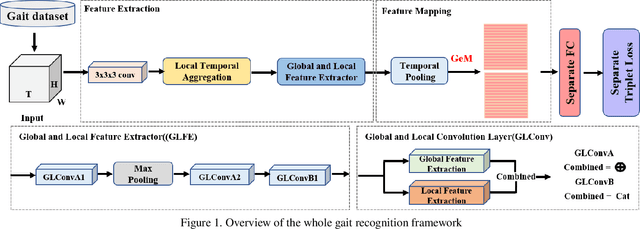
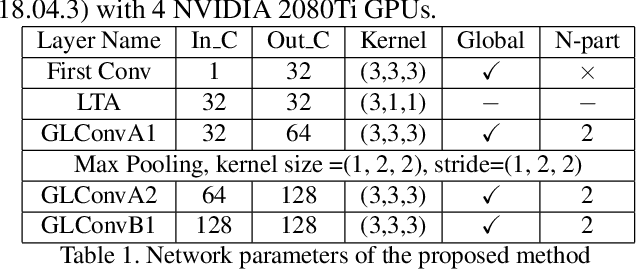
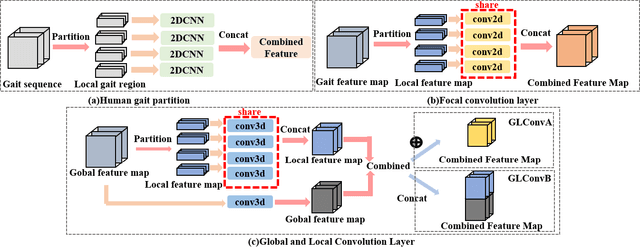
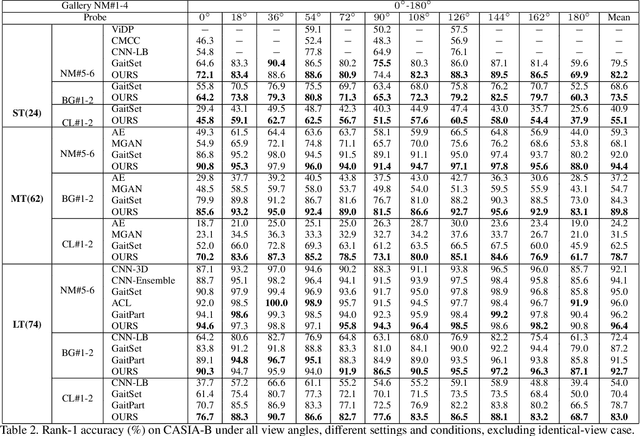
Gait recognition is one of the most important biometric technologies and has been applied in many fields. Recent gait recognition frameworks represent each human gait frame by descriptors extracted from either global appearances or local regions of humans. However, the representations based on global information often neglect the details of the gait frame, while local region based descriptors cannot capture the relations among neighboring regions, thus reducing their discriminativeness. In this paper, we propose a novel feature extraction and fusion framework to achieve discriminative feature representations for gait recognition. Towards this goal, we take advantage of both global visual information and local region details and develop a Global and Local Feature Extractor (GLFE). Specifically, our GLFE module is composed of our newly designed multiple global and local convolutional layers (GLConv) to ensemble global and local features in a principle manner. Furthermore, we present a novel operation, namely Local Temporal Aggregation (LTA), to further preserve the spatial information by reducing the temporal resolution to obtain higher spatial resolution. With the help of our GLFE and LTA, our method significantly improves the discriminativeness of our visual features, thus improving the gait recognition performance. Extensive experiments demonstrate that our proposed method outperforms state-of-the-art gait recognition methods on popular widely-used CASIA-B and OUMVLP datasets.
Identification of particle mixtures using machine-learning-assisted laser diffraction analysis
Jan 25, 2021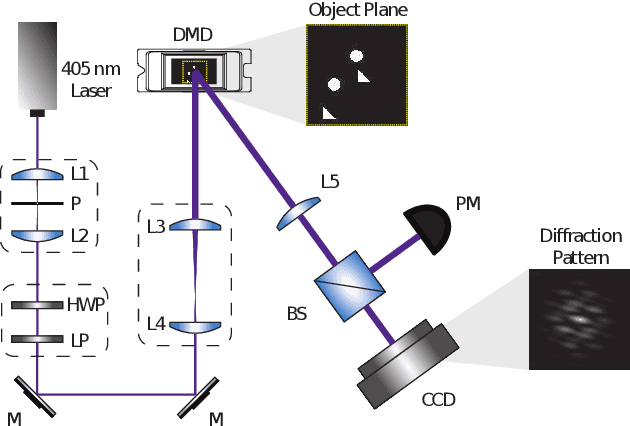
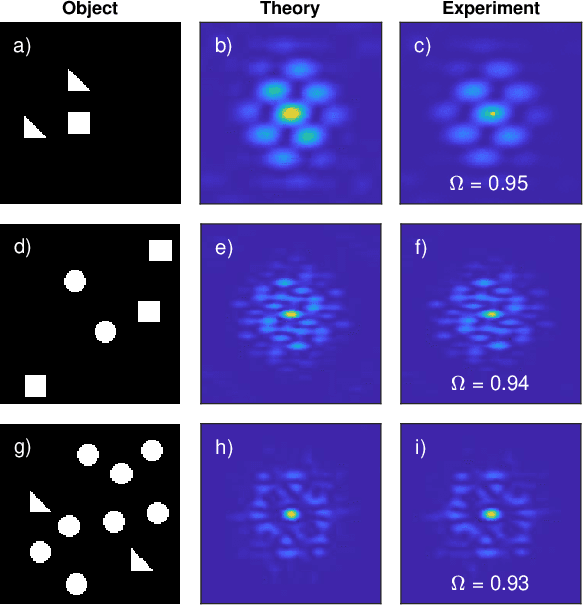
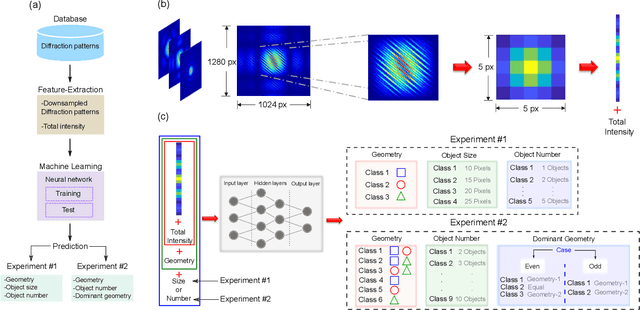
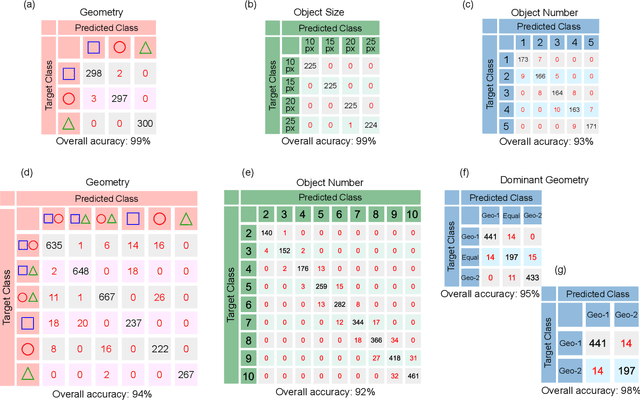
We demonstrate a smart laser-diffraction analysis technique for particle mixture identification. We retrieve information about the size, geometry, and ratio concentration of two-component heterogeneous particle mixtures with an efficiency above 92%. In contrast to commonly-used laser diffraction schemes -- in which a large number of detectors is needed -- our machine-learning-assisted protocol makes use of a single far-field diffraction pattern, contained within a small angle ($\sim 0.26^{\circ}$) around the light propagation axis. Because of its reliability and ease of implementation, our work may pave the way towards the development of novel smart identification technologies for sample classification and particle contamination monitoring in industrial manufacturing processes.
Remedies against the Vocabulary Gap in Information Retrieval
Nov 16, 2017
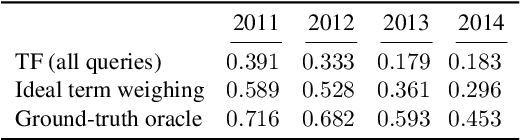
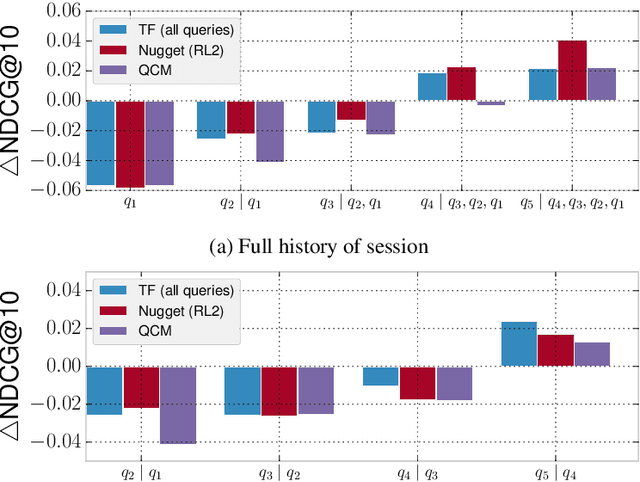
Search engines rely heavily on term-based approaches that represent queries and documents as bags of words. Text---a document or a query---is represented by a bag of its words that ignores grammar and word order, but retains word frequency counts. When presented with a search query, the engine then ranks documents according to their relevance scores by computing, among other things, the matching degrees between query and document terms. While term-based approaches are intuitive and effective in practice, they are based on the hypothesis that documents that exactly contain the query terms are highly relevant regardless of query semantics. Inversely, term-based approaches assume documents that do not contain query terms as irrelevant. However, it is known that a high matching degree at the term level does not necessarily mean high relevance and, vice versa, documents that match null query terms may still be relevant. Consequently, there exists a vocabulary gap between queries and documents that occurs when both use different words to describe the same concepts. It is the alleviation of the effect brought forward by this vocabulary gap that is the topic of this dissertation. More specifically, we propose (1) methods to formulate an effective query from complex textual structures and (2) latent vector space models that circumvent the vocabulary gap in information retrieval.
Learning Dependencies in Distributed Cloud Applications to Identify and Localize Anomalies
Mar 09, 2021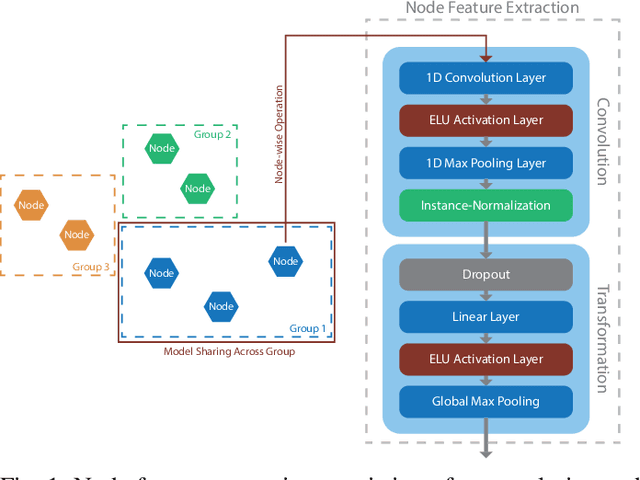
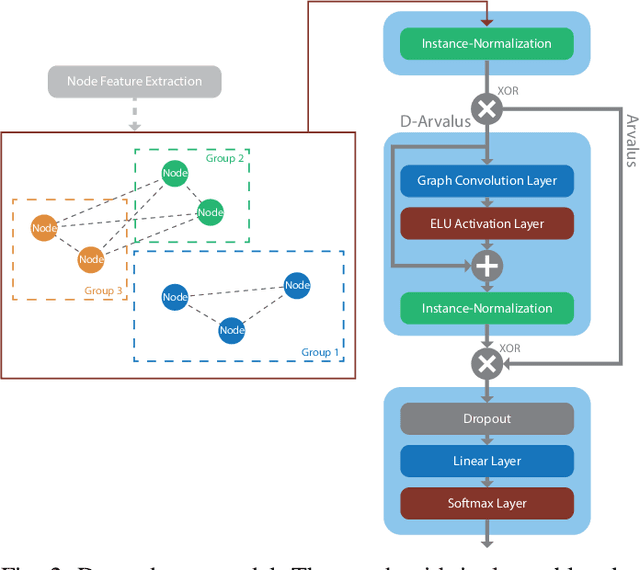
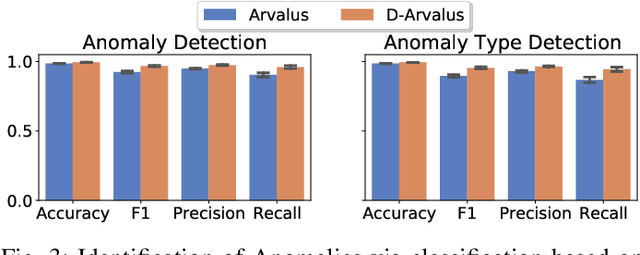
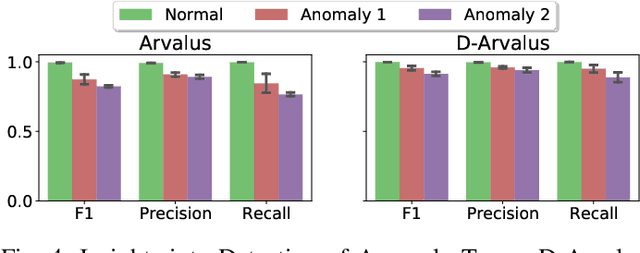
Operation and maintenance of large distributed cloud applications can quickly become unmanageably complex, putting human operators under immense stress when problems occur. Utilizing machine learning for identification and localization of anomalies in such systems supports human experts and enables fast mitigation. However, due to the various inter-dependencies of system components, anomalies do not only affect their origin but propagate through the distributed system. Taking this into account, we present Arvalus and its variant D-Arvalus, a neural graph transformation method that models system components as nodes and their dependencies and placement as edges to improve the identification and localization of anomalies. Given a series of metric KPIs, our method predicts the most likely system state - either normal or an anomaly class - and performs localization when an anomaly is detected. During our experiments, we simulate a distributed cloud application deployment and synthetically inject anomalies. The evaluation shows the generally good prediction performance of Arvalus and reveals the advantage of D-Arvalus which incorporates information about system component dependencies.
User-Oriented Smart General AI System under Causal Inference
Mar 25, 2021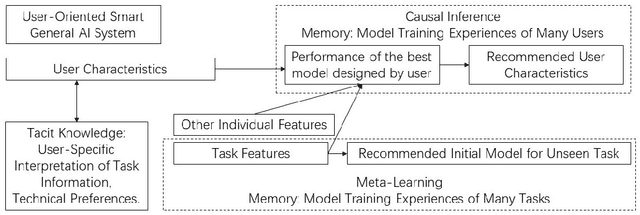
General AI system solves a wide range of tasks with high performance in an automated fashion. The best general AI algorithm designed by one individual is different from that devised by another. The best performance records achieved by different users are also different. An inevitable component of general AI is tacit knowledge that depends upon user-specific comprehension of task information and individual model design preferences that are related to user technical experiences. Tacit knowledge affects model performance but cannot be automatically optimized in general AI algorithms. In this paper, we propose User-Oriented Smart General AI System under Causal Inference, abbreviated as UOGASuCI, where UOGAS represents User-Oriented General AI System and uCI means under the framework of causal inference. User characteristics that have a significant influence upon tacit knowledge can be extracted from observed model training experiences of many users in external memory modules. Under the framework of causal inference, we manage to identify the optimal value of user characteristics that are connected with the best model performance designed by users. We make suggestions to users about how different user characteristics can improve the best model performance achieved by users. By recommending updating user characteristics associated with individualized tacit knowledge comprehension and technical preferences, UOGAS helps users design models with better performance.
Cross-Modal Contrastive Learning for Abnormality Classification and Localization in Chest X-rays with Radiomics using a Feedback Loop
Apr 19, 2021
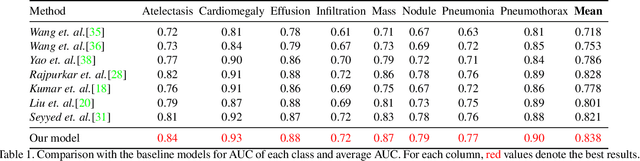
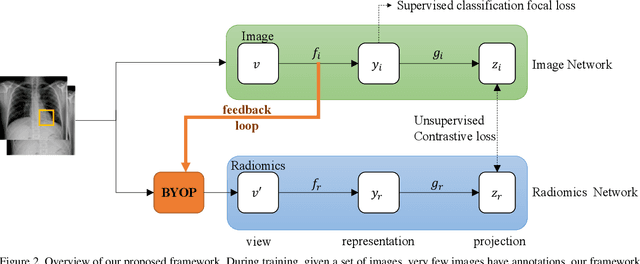
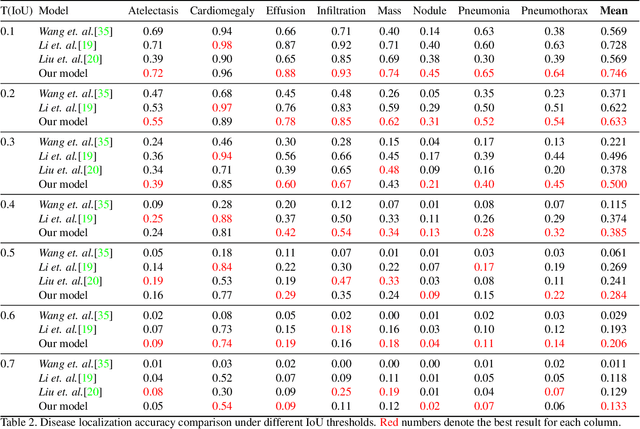
Building a highly accurate predictive model for these tasks usually requires a large number of manually annotated labels and pixel regions (bounding boxes) of abnormalities. However, it is expensive to acquire such annotations, especially the bounding boxes. Recently, contrastive learning has shown strong promise in leveraging unlabeled natural images to produce highly generalizable and discriminative features. However, extending its power to the medical image domain is under-explored and highly non-trivial, since medical images are much less amendable to data augmentations. In contrast, their domain knowledge, as well as multi-modality information, is often crucial. To bridge this gap, we propose an end-to-end semi-supervised cross-modal contrastive learning framework, that simultaneously performs disease classification and localization tasks. The key knob of our framework is a unique positive sampling approach tailored for the medical images, by seamlessly integrating radiomic features as an auxiliary modality. Specifically, we first apply an image encoder to classify the chest X-rays and to generate the image features. We next leverage Grad-CAM to highlight the crucial (abnormal) regions for chest X-rays (even when unannotated), from which we extract radiomic features. The radiomic features are then passed through another dedicated encoder to act as the positive sample for the image features generated from the same chest X-ray. In this way, our framework constitutes a feedback loop for image and radiomic modality features to mutually reinforce each other. Their contrasting yields cross-modality representations that are both robust and interpretable. Extensive experiments on the NIH Chest X-ray dataset demonstrate that our approach outperforms existing baselines in both classification and localization tasks.
Hardness of Learning Halfspaces with Massart Noise
Dec 17, 2020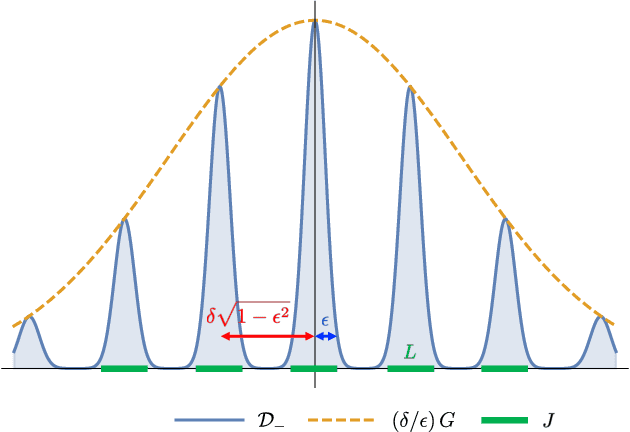
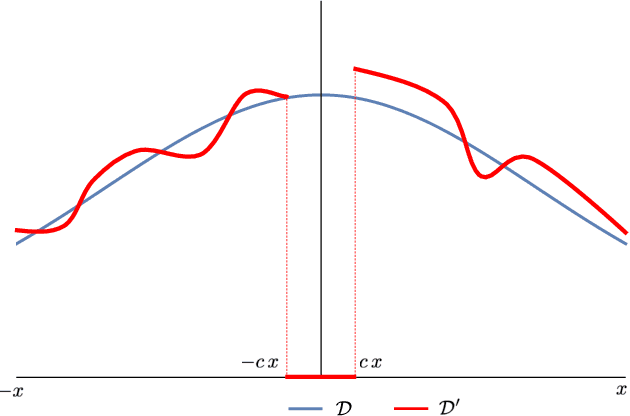
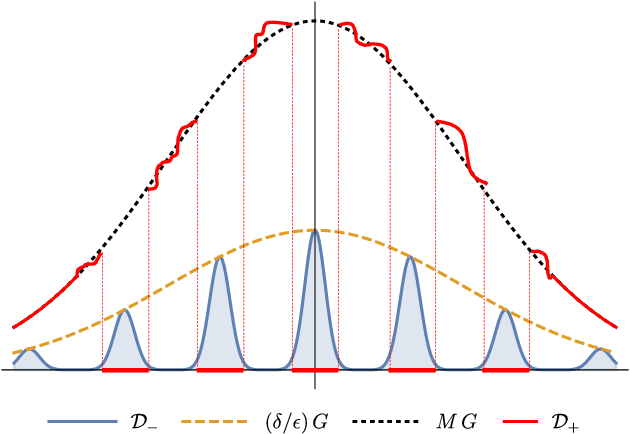
We study the complexity of PAC learning halfspaces in the presence of Massart (bounded) noise. Specifically, given labeled examples $(x, y)$ from a distribution $D$ on $\mathbb{R}^{n} \times \{ \pm 1\}$ such that the marginal distribution on $x$ is arbitrary and the labels are generated by an unknown halfspace corrupted with Massart noise at rate $\eta<1/2$, we want to compute a hypothesis with small misclassification error. Characterizing the efficient learnability of halfspaces in the Massart model has remained a longstanding open problem in learning theory. Recent work gave a polynomial-time learning algorithm for this problem with error $\eta+\epsilon$. This error upper bound can be far from the information-theoretically optimal bound of $\mathrm{OPT}+\epsilon$. More recent work showed that {\em exact learning}, i.e., achieving error $\mathrm{OPT}+\epsilon$, is hard in the Statistical Query (SQ) model. In this work, we show that there is an exponential gap between the information-theoretically optimal error and the best error that can be achieved by a polynomial-time SQ algorithm. In particular, our lower bound implies that no efficient SQ algorithm can approximate the optimal error within any polynomial factor.