 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An Interpretable End-to-end Fine-tuning Approach for Long Clinical Text
Nov 12, 2020
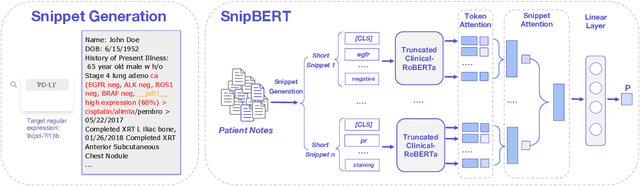
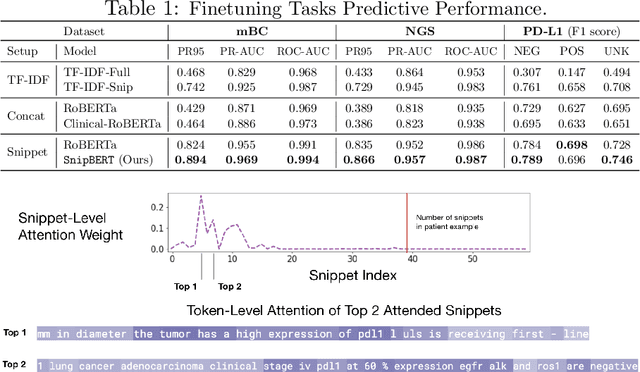
Unstructured clinical text in EHRs contains crucial information for applications including decision support, trial matching, and retrospective research. Recent work has applied BERT-based models to clinical information extraction and text classification, given these models' state-of-the-art performance in other NLP domains. However, BERT is difficult to apply to clinical notes because it doesn't scale well to long sequences of text. In this work, we propose a novel fine-tuning approach called SnipBERT. Instead of using entire notes, SnipBERT identifies crucial snippets and then feeds them into a truncated BERT-based model in a hierarchical manner. Empirically, SnipBERT not only has significant predictive performance gain across three tasks but also provides improved interpretability, as the model can identify key pieces of text that led to its prediction.
Hardness of Learning Halfspaces with Massart Noise
Dec 17, 2020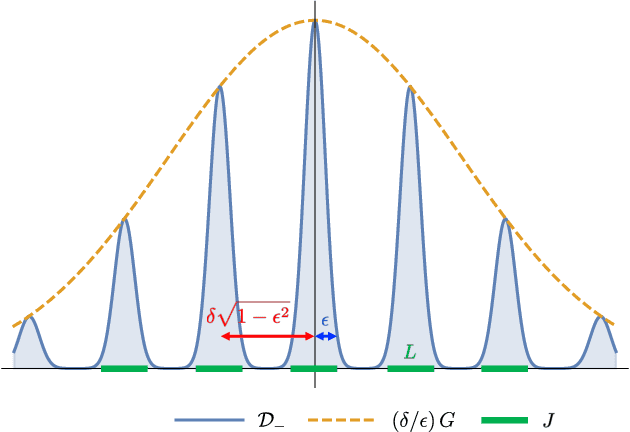
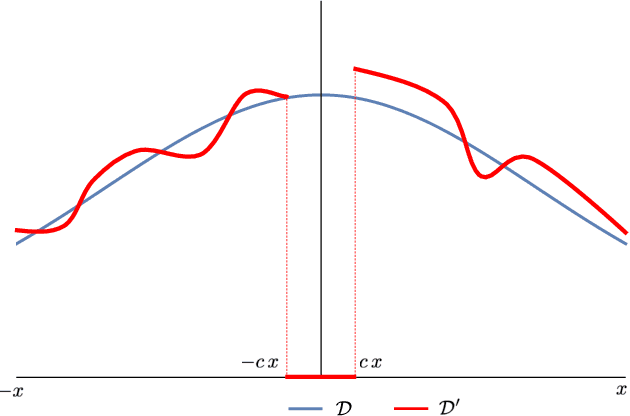
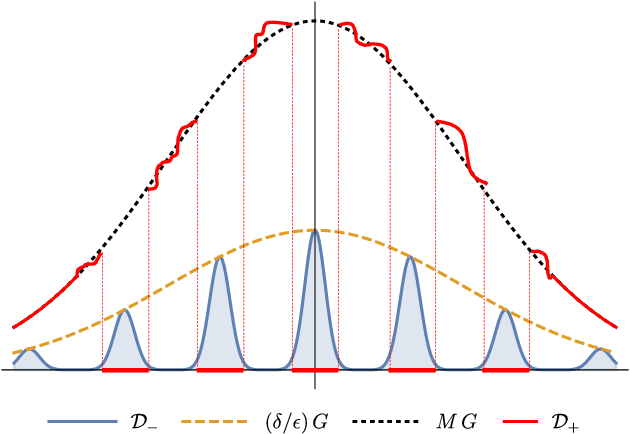
We study the complexity of PAC learning halfspaces in the presence of Massart (bounded) noise. Specifically, given labeled examples $(x, y)$ from a distribution $D$ on $\mathbb{R}^{n} \times \{ \pm 1\}$ such that the marginal distribution on $x$ is arbitrary and the labels are generated by an unknown halfspace corrupted with Massart noise at rate $\eta<1/2$, we want to compute a hypothesis with small misclassification error. Characterizing the efficient learnability of halfspaces in the Massart model has remained a longstanding open problem in learning theory. Recent work gave a polynomial-time learning algorithm for this problem with error $\eta+\epsilon$. This error upper bound can be far from the information-theoretically optimal bound of $\mathrm{OPT}+\epsilon$. More recent work showed that {\em exact learning}, i.e., achieving error $\mathrm{OPT}+\epsilon$, is hard in the Statistical Query (SQ) model. In this work, we show that there is an exponential gap between the information-theoretically optimal error and the best error that can be achieved by a polynomial-time SQ algorithm. In particular, our lower bound implies that no efficient SQ algorithm can approximate the optimal error within any polynomial factor.
Transformer Transforms Salient Object Detection and Camouflaged Object Detection
Apr 20, 2021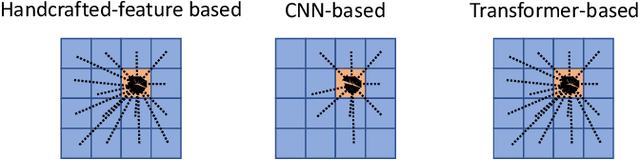
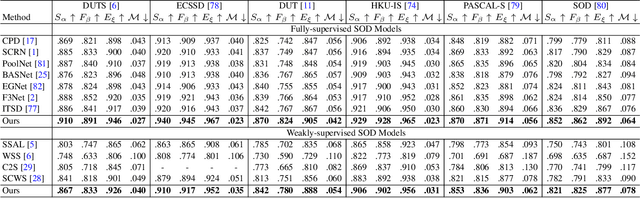
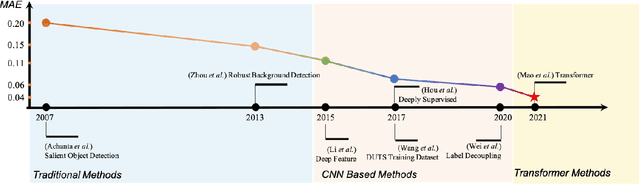
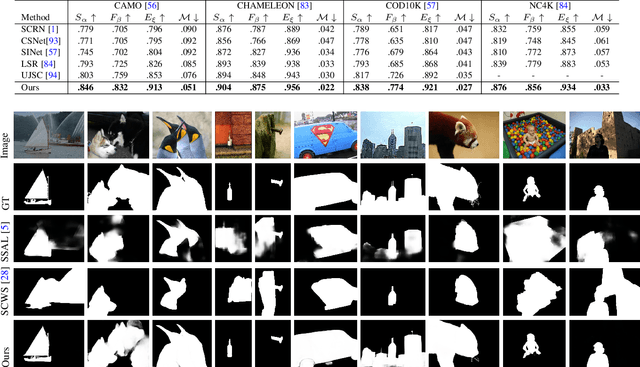
The transformer networks, which originate from machine translation, are particularly good at modeling long-range dependencies within a long sequence. Currently, the transformer networks are making revolutionary progress in various vision tasks ranging from high-level classification tasks to low-level dense prediction tasks. In this paper, we conduct research on applying the transformer networks for salient object detection (SOD). Specifically, we adopt the dense transformer backbone for fully supervised RGB image based SOD, RGB-D image pair based SOD, and weakly supervised SOD via scribble supervision. As an extension, we also apply our fully supervised model to the task of camouflaged object detection (COD) for camouflaged object segmentation. For the fully supervised models, we define the dense transformer backbone as feature encoder, and design a very simple decoder to produce a one channel saliency map (or camouflage map for the COD task). For the weakly supervised model, as there exists no structure information in the scribble annotation, we first adopt the recent proposed Gated-CRF loss to effectively model the pair-wise relationships for accurate model prediction. Then, we introduce self-supervised learning strategy to push the model to produce scale-invariant predictions, which is proven effective for weakly supervised models and models trained on small training datasets. Extensive experimental results on various SOD and COD tasks (fully supervised RGB image based SOD, fully supervised RGB-D image pair based SOD, weakly supervised SOD via scribble supervision, and fully supervised RGB image based COD) illustrate that transformer networks can transform salient object detection and camouflaged object detection, leading to new benchmarks for each related task.
Network Quantization with Element-wise Gradient Scaling
Apr 02, 2021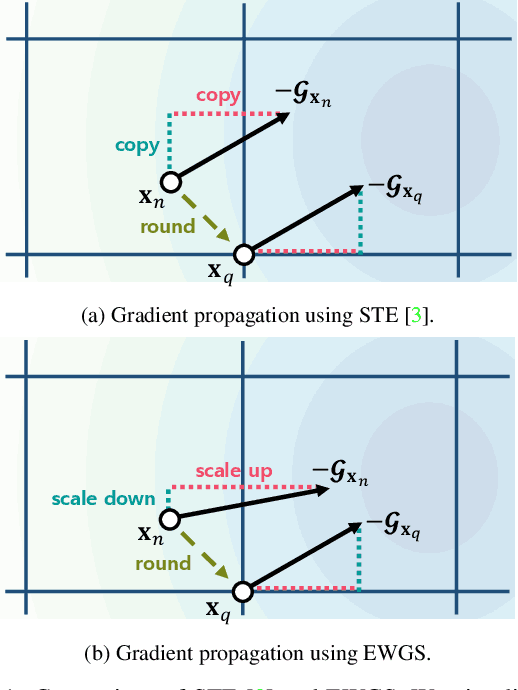
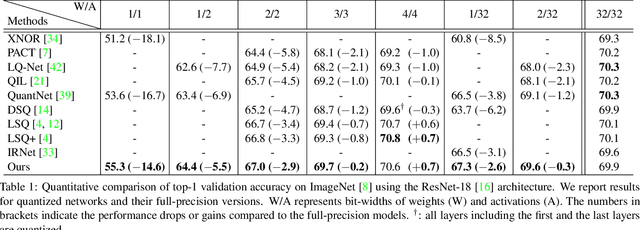
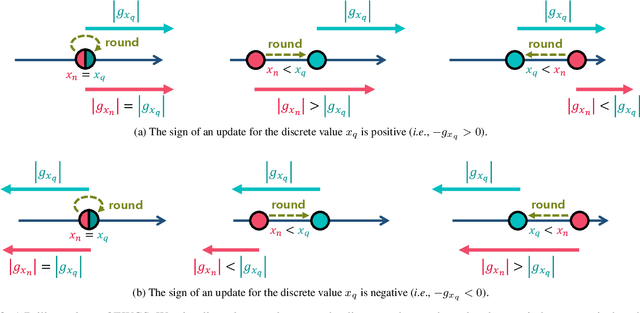
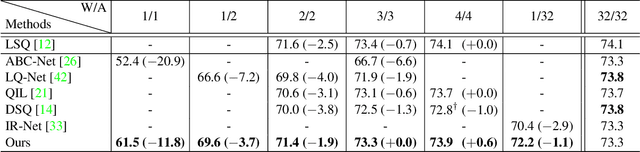
Network quantization aims at reducing bit-widths of weights and/or activations, particularly important for implementing deep neural networks with limited hardware resources. Most methods use the straight-through estimator (STE) to train quantized networks, which avoids a zero-gradient problem by replacing a derivative of a discretizer (i.e., a round function) with that of an identity function. Although quantized networks exploiting the STE have shown decent performance, the STE is sub-optimal in that it simply propagates the same gradient without considering discretization errors between inputs and outputs of the discretizer. In this paper, we propose an element-wise gradient scaling (EWGS), a simple yet effective alternative to the STE, training a quantized network better than the STE in terms of stability and accuracy. Given a gradient of the discretizer output, EWGS adaptively scales up or down each gradient element, and uses the scaled gradient as the one for the discretizer input to train quantized networks via backpropagation. The scaling is performed depending on both the sign of each gradient element and an error between the continuous input and discrete output of the discretizer. We adjust a scaling factor adaptively using Hessian information of a network. We show extensive experimental results on the image classification datasets, including CIFAR-10 and ImageNet, with diverse network architectures under a wide range of bit-width settings, demonstrating the effectiveness of our method.
KBGN: Knowledge-Bridge Graph Network for Adaptive Vision-Text Reasoning in Visual Dialogue
Aug 11, 2020
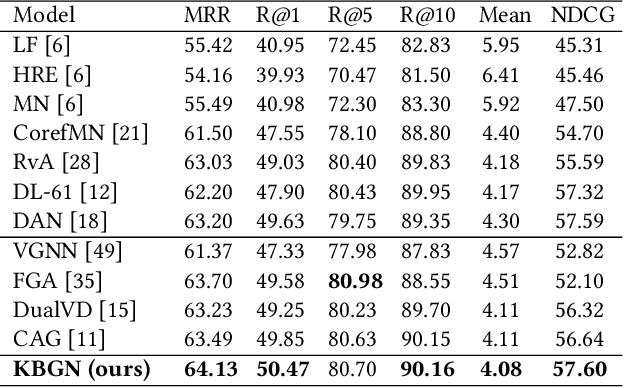
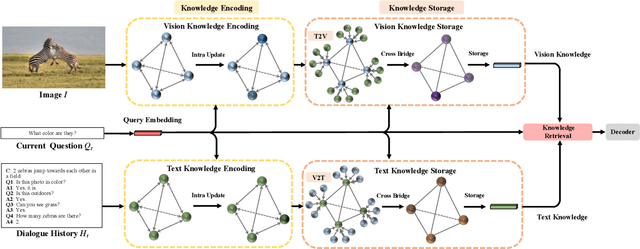
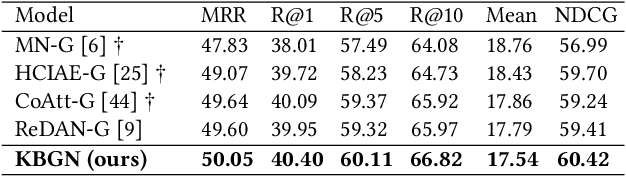
Visual dialogue is a challenging task that needs to extract implicit information from both visual (image) and textual (dialogue history) contexts. Classical approaches pay more attention to the integration of the current question, vision knowledge and text knowledge, despising the heterogeneous semantic gaps between the cross-modal information. In the meantime, the concatenation operation has become de-facto standard to the cross-modal information fusion, which has a limited ability in information retrieval. In this paper, we propose a novel Knowledge-Bridge Graph Network (KBGN) model by using graph to bridge the cross-modal semantic relations between vision and text knowledge in fine granularity, as well as retrieving required knowledge via an adaptive information selection mode. Moreover, the reasoning clues for visual dialogue can be clearly drawn from intra-modal entities and inter-modal bridges. Experimental results on VisDial v1.0 and VisDial-Q datasets demonstrate that our model outperforms exiting models with state-of-the-art results.
An efficient representation of chronological events in medical texts
Oct 16, 2020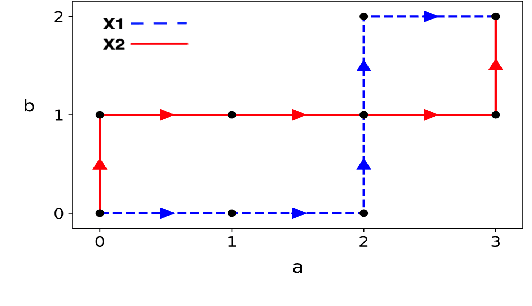
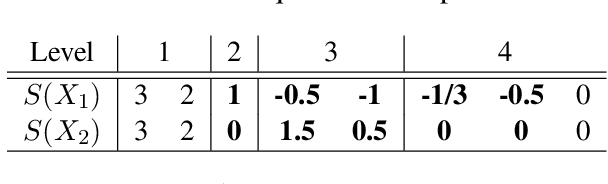

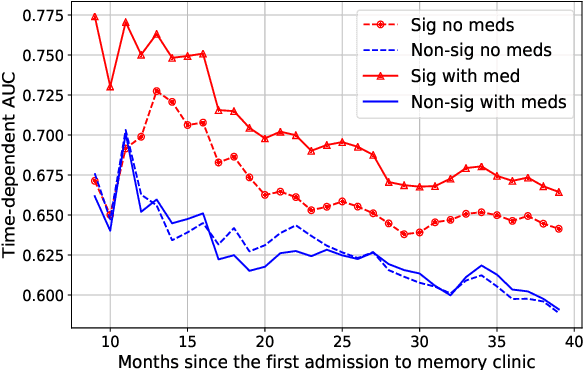
In this work we addressed the problem of capturing sequential information contained in longitudinal electronic health records (EHRs). Clinical notes, which is a particular type of EHR data, are a rich source of information and practitioners often develop clever solutions how to maximise the sequential information contained in free-texts. We proposed a systematic methodology for learning from chronological events available in clinical notes. The proposed methodological {\it path signature} framework creates a non-parametric hierarchical representation of sequential events of any type and can be used as features for downstream statistical learning tasks. The methodology was developed and externally validated using the largest in the UK secondary care mental health EHR data on a specific task of predicting survival risk of patients diagnosed with Alzheimer's disease. The signature-based model was compared to a common survival random forest model. Our results showed a 15.4$\%$ increase of risk prediction AUC at the time point of 20 months after the first admission to a specialist memory clinic and the signature method outperformed the baseline mixed-effects model by 13.2 $\%$.
Identification of particle mixtures using machine-learning-assisted laser diffraction analysis
Jan 25, 2021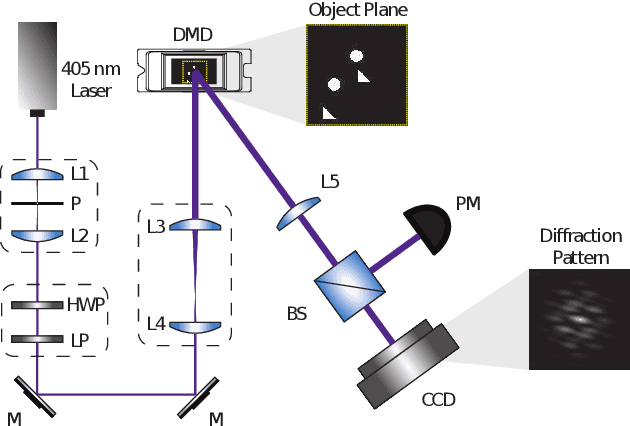
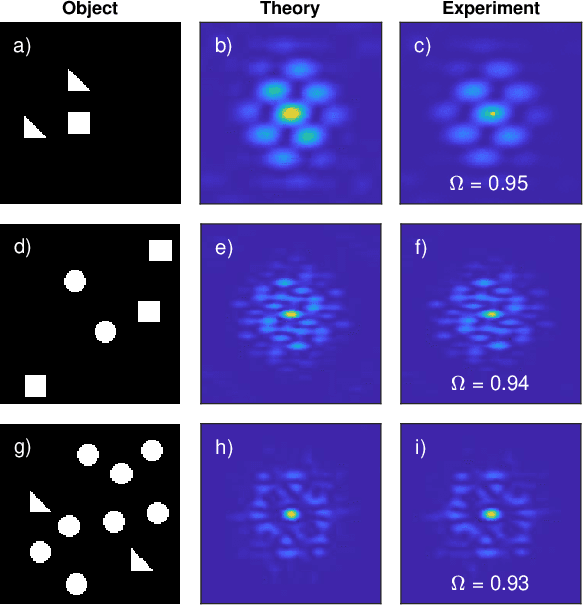
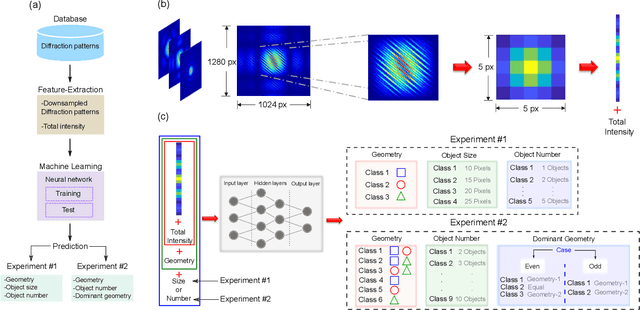
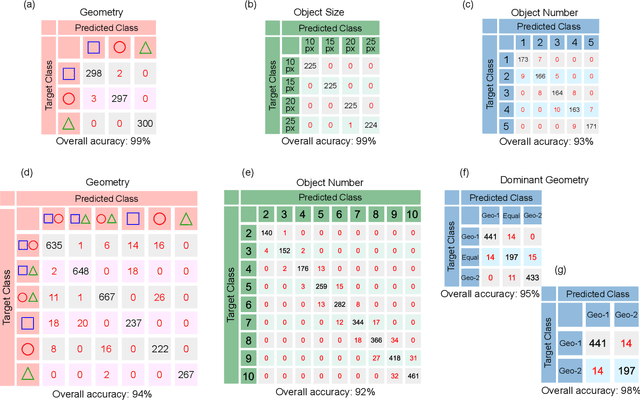
We demonstrate a smart laser-diffraction analysis technique for particle mixture identification. We retrieve information about the size, geometry, and ratio concentration of two-component heterogeneous particle mixtures with an efficiency above 92%. In contrast to commonly-used laser diffraction schemes -- in which a large number of detectors is needed -- our machine-learning-assisted protocol makes use of a single far-field diffraction pattern, contained within a small angle ($\sim 0.26^{\circ}$) around the light propagation axis. Because of its reliability and ease of implementation, our work may pave the way towards the development of novel smart identification technologies for sample classification and particle contamination monitoring in industrial manufacturing processes.
Generalizing Decision Making for Automated Driving with an Invariant Environment Representation using Deep Reinforcement Learning
Feb 12, 2021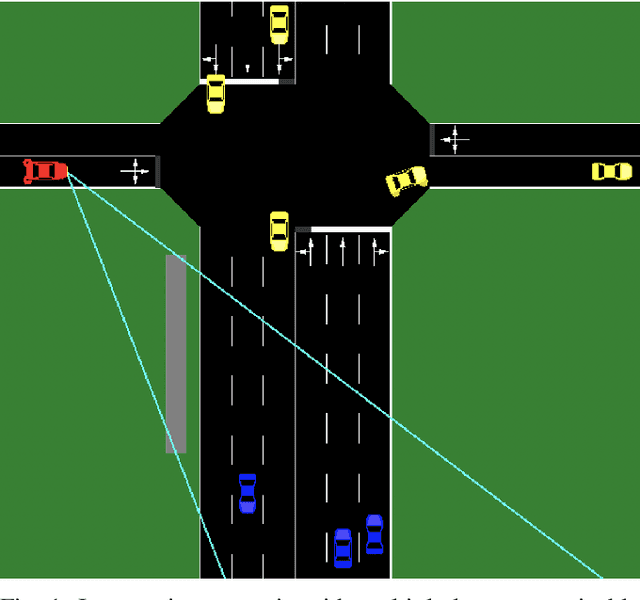
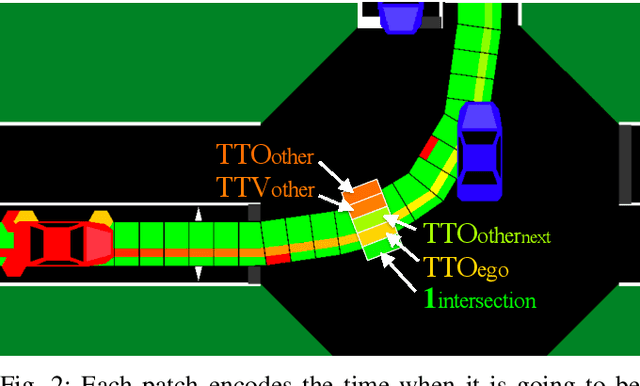
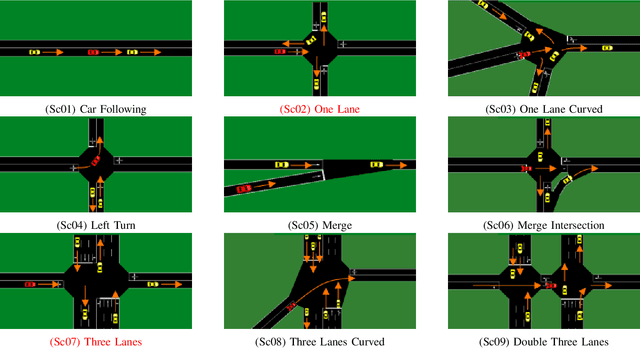
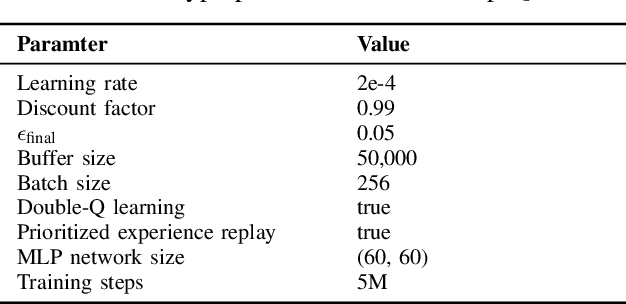
Data driven approaches for decision making applied to automated driving require appropriate generalization strategies, to ensure applicability to the world's variability. Current approaches either do not generalize well beyond the training data or are not capable to consider a variable number of traffic participants. Therefore we propose an invariant environment representation from the perspective of the ego vehicle. The representation encodes all necessary information for safe decision making. To assess the generalization capabilities of the novel environment representation, we train our agents on a small subset of scenarios and evaluate on the entire set. Here we show that the agents are capable to generalize successfully to unseen scenarios, due to the abstraction. In addition we present a simple occlusion model that enables our agents to navigate intersections with occlusions without a significant change in performance.
Self-supervised Video Representation Learning by Context and Motion Decoupling
Apr 02, 2021
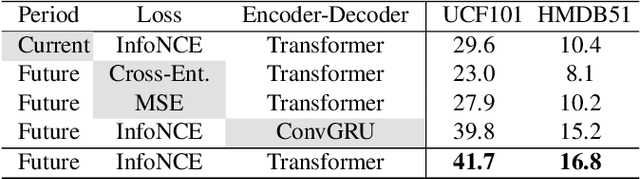
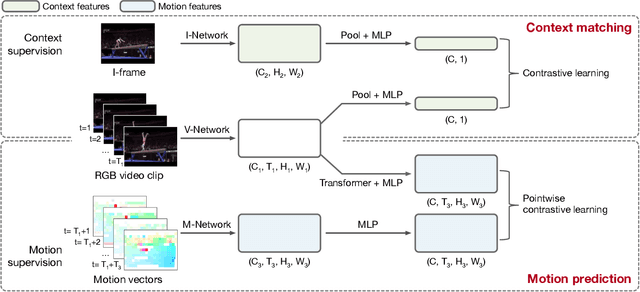
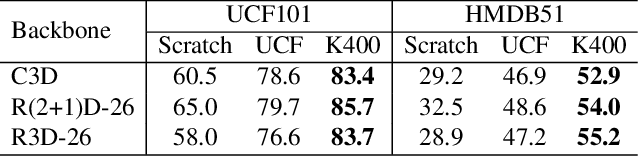
A key challenge in self-supervised video representation learning is how to effectively capture motion information besides context bias. While most existing works implicitly achieve this with video-specific pretext tasks (e.g., predicting clip orders, time arrows, and paces), we develop a method that explicitly decouples motion supervision from context bias through a carefully designed pretext task. Specifically, we take the keyframes and motion vectors in compressed videos (e.g., in H.264 format) as the supervision sources for context and motion, respectively, which can be efficiently extracted at over 500 fps on the CPU. Then we design two pretext tasks that are jointly optimized: a context matching task where a pairwise contrastive loss is cast between video clip and keyframe features; and a motion prediction task where clip features, passed through an encoder-decoder network, are used to estimate motion features in a near future. These two tasks use a shared video backbone and separate MLP heads. Experiments show that our approach improves the quality of the learned video representation over previous works, where we obtain absolute gains of 16.0% and 11.1% in video retrieval recall on UCF101 and HMDB51, respectively. Moreover, we find the motion prediction to be a strong regularization for video networks, where using it as an auxiliary task improves the accuracy of action recognition with a margin of 7.4%~13.8%.
GRN: Generative Rerank Network for Context-wise Recommendation
Apr 02, 2021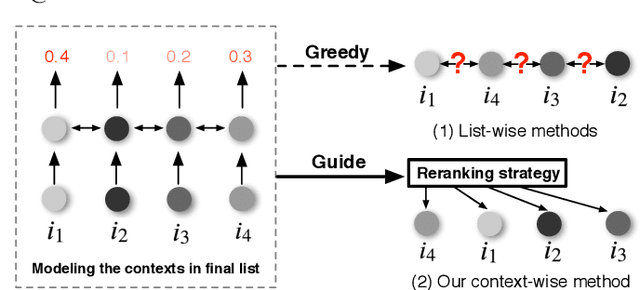
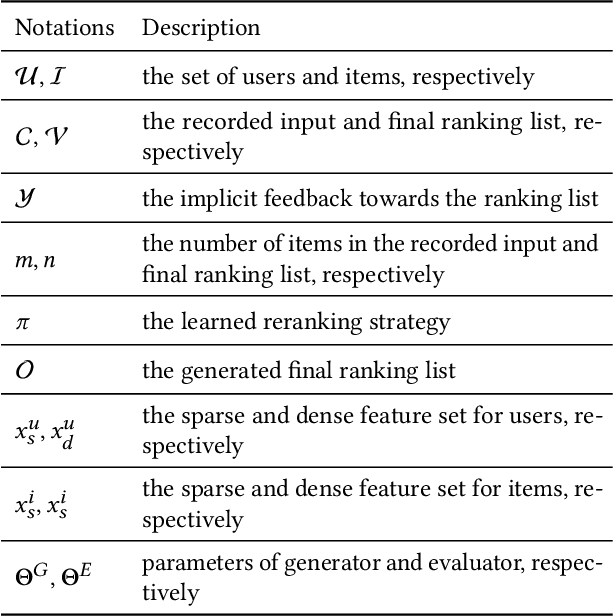
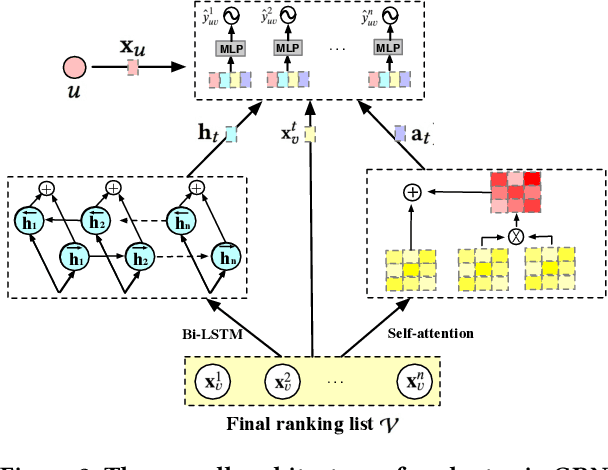
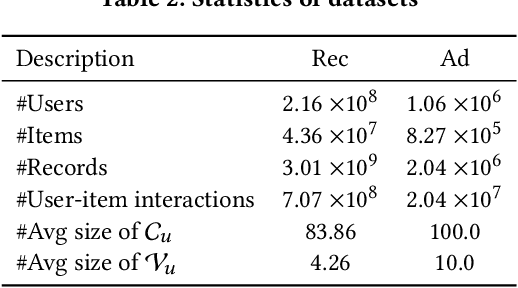
Reranking is attracting incremental attention in the recommender systems, which rearranges the input ranking list into the final rank-ing list to better meet user demands. Most existing methods greedily rerank candidates through the rating scores from point-wise or list-wise models. Despite effectiveness, neglecting the mutual influence between each item and its contexts in the final ranking list often makes the greedy strategy based reranking methods sub-optimal.In this work, we propose a new context-wise reranking framework named Generative Rerank Network (GRN). Specifically, we first design the evaluator, which applies Bi-LSTM and self-attention mechanism to model the contextual information in the labeled final ranking list and predict the interaction probability of each item more precisely. Afterwards, we elaborate on the generator, equipped with GRU, attention mechanism and pointer network to select the item from the input ranking list step by step. Finally, we apply cross-entropy loss to train the evaluator and, subsequently, policy gradient to optimize the generator under the guidance of the evaluator. Empirical results show that GRN consistently and significantly outperforms state-of-the-art point-wise and list-wise methods. Moreover, GRN has achieved a performance improvement of 5.2% on PV and 6.1% on IPV metric after the successful deployment in one popular recommendation scenario of Taobao application.