 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Adversarial Shape Learning for Building Extraction in VHR Remote Sensing Images
Mar 09, 2021
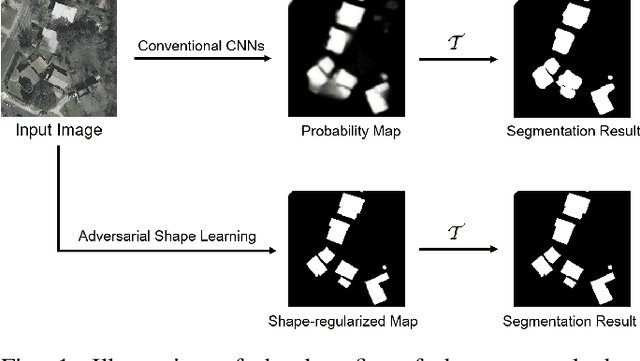
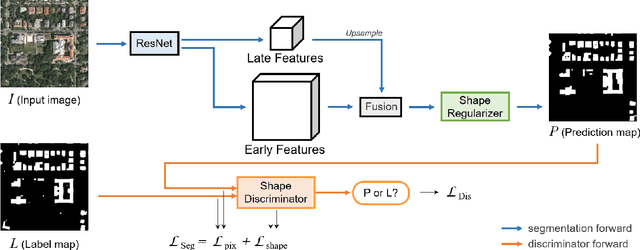
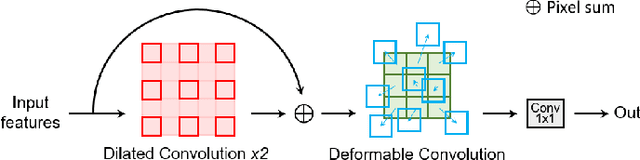
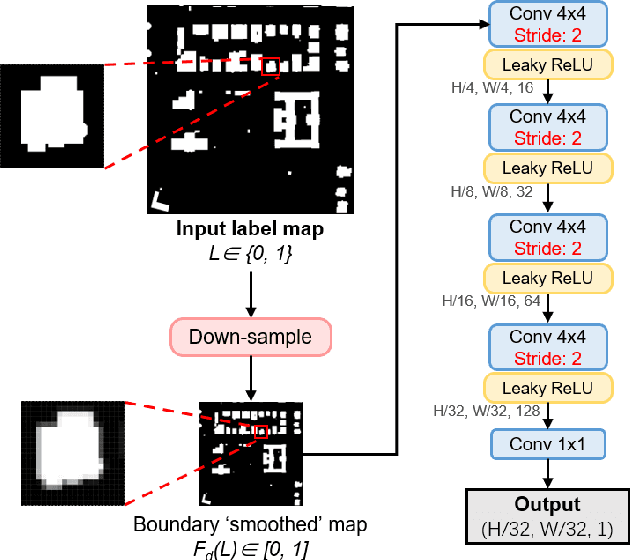
Building extraction in VHR RSIs remains to be a challenging task due to occlusion and boundary ambiguity problems. Although conventional convolutional neural networks (CNNs) based methods are capable of exploiting local texture and context information, they fail to capture the shape patterns of buildings, which is a necessary constraint in the human recognition. In this context, we propose an adversarial shape learning network (ASLNet) to model the building shape patterns, thus improving the accuracy of building segmentation. In the proposed ASLNet, we introduce the adversarial learning strategy to explicitly model the shape constraints, as well as a CNN shape regularizer to strengthen the embedding of shape features. To assess the geometric accuracy of building segmentation results, we further introduced several object-based assessment metrics. Experiments on two open benchmark datasets show that the proposed ASLNet improves both the pixel-based accuracy and the object-based measurements by a large margin. The code is available at: https://github.com/ggsDing/ASLNet
A Gaussian Process Model of Cross-Category Dynamics in Brand Choice
Apr 23, 2021Understanding individual customers' sensitivities to prices, promotions, brand, and other aspects of the marketing mix is fundamental to a wide swath of marketing problems, including targeting and pricing. Companies that operate across many product categories have a unique opportunity, insofar as they can use purchasing data from one category to augment their insights in another. Such cross-category insights are especially crucial in situations where purchasing data may be rich in one category, and scarce in another. An important aspect of how consumers behave across categories is dynamics: preferences are not stable over time, and changes in individual-level preference parameters in one category may be indicative of changes in other categories, especially if those changes are driven by external factors. Yet, despite the rich history of modeling cross-category preferences, the marketing literature lacks a framework that flexibly accounts for \textit{correlated dynamics}, or the cross-category interlinkages of individual-level sensitivity dynamics. In this work, we propose such a framework, leveraging individual-level, latent, multi-output Gaussian processes to build a nonparametric Bayesian choice model that allows information sharing of preference parameters across customers, time, and categories. We apply our model to grocery purchase data, and show that our model detects interesting dynamics of customers' price sensitivities across multiple categories. Managerially, we show that capturing correlated dynamics yields substantial predictive gains, relative to benchmarks. Moreover, we find that capturing correlated dynamics can have implications for understanding changes in consumers preferences over time, and developing targeted marketing strategies based on those dynamics.
Merchant Category Identification Using Credit Card Transactions
Nov 05, 2020
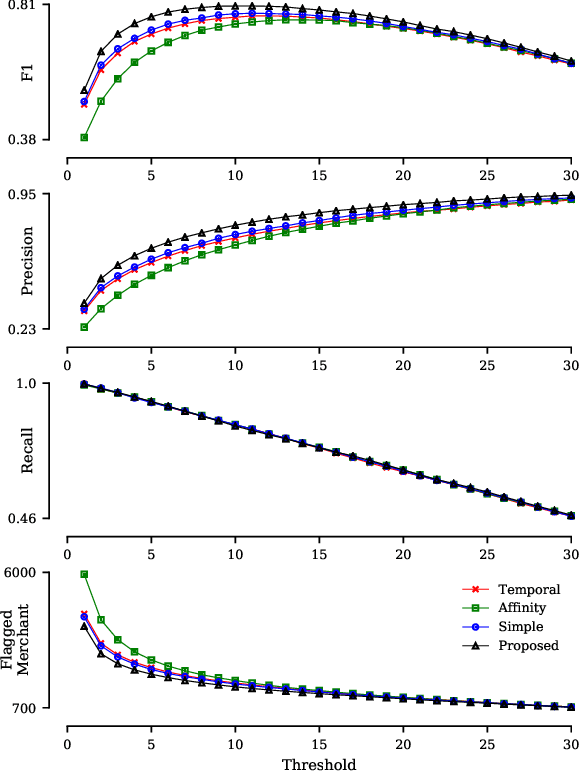
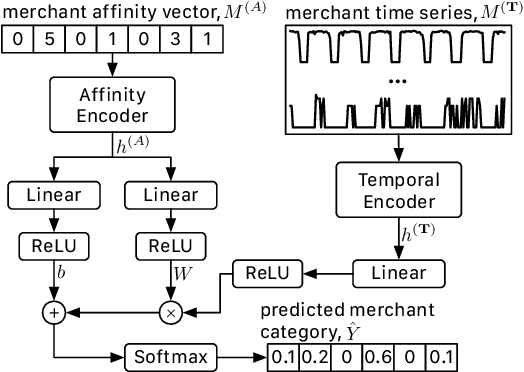
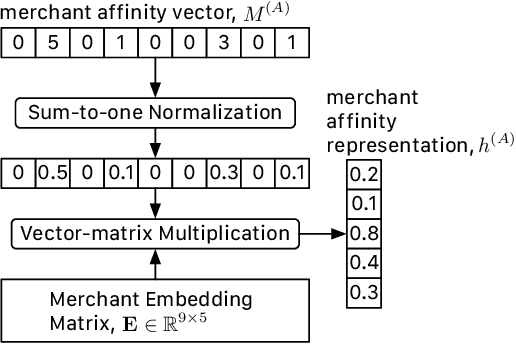
Digital payment volume has proliferated in recent years with the rapid growth of small businesses and online shops. When processing these digital transactions, recognizing each merchant's real identity (i.e., business type) is vital to ensure the integrity of payment processing systems. Conventionally, this problem is formulated as a time series classification problem solely using the merchant transaction history. However, with the large scale of the data, and changing behaviors of merchants and consumers over time, it is extremely challenging to achieve satisfying performance from off-the-shelf classification methods. In this work, we approach this problem from a multi-modal learning perspective, where we use not only the merchant time series data but also the information of merchant-merchant relationship (i.e., affinity) to verify the self-reported business type (i.e., merchant category) of a given merchant. Specifically, we design two individual encoders, where one is responsible for encoding temporal information and the other is responsible for affinity information, and a mechanism to fuse the outputs of the two encoders to accomplish the identification task. Our experiments on real-world credit card transaction data between 71,668 merchants and 433,772,755 customers have demonstrated the effectiveness and efficiency of the proposed model.
Influencing Reinforcement Learning through Natural Language Guidance
Apr 04, 2021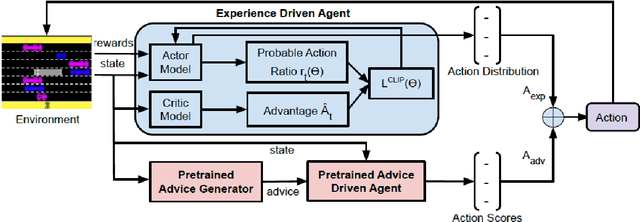
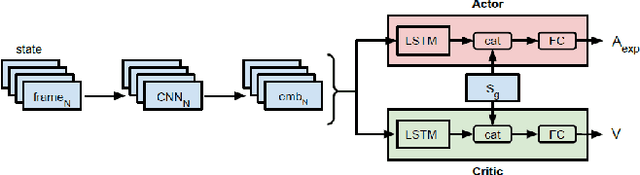
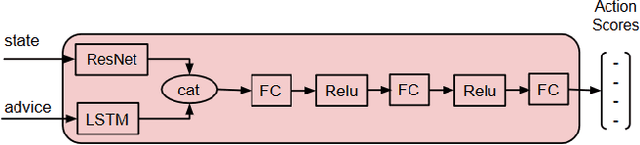

Interactive reinforcement learning agents use human feedback or instruction to help them learn in complex environments. Often, this feedback comes in the form of a discrete signal that is either positive or negative. While informative, this information can be difficult to generalize on its own. In this work, we explore how natural language advice can be used to provide a richer feedback signal to a reinforcement learning agent by extending policy shaping, a well-known Interactive reinforcement learning technique. Usually policy shaping employs a human feedback policy to help an agent to learn more about how to achieve its goal. In our case, we replace this human feedback policy with policy generated based on natural language advice. We aim to inspect if the generated natural language reasoning provides support to a deep reinforcement learning agent to decide its actions successfully in any given environment. So, we design our model with three networks: first one is the experience driven, next is the advice generator and third one is the advice driven. While the experience driven reinforcement learning agent chooses its actions being influenced by the environmental reward, the advice driven neural network with generated feedback by the advice generator for any new state selects its actions to assist the reinforcement learning agent to better policy shaping.
FGAGT: Flow-Guided Adaptive Graph Tracking
Nov 04, 2020
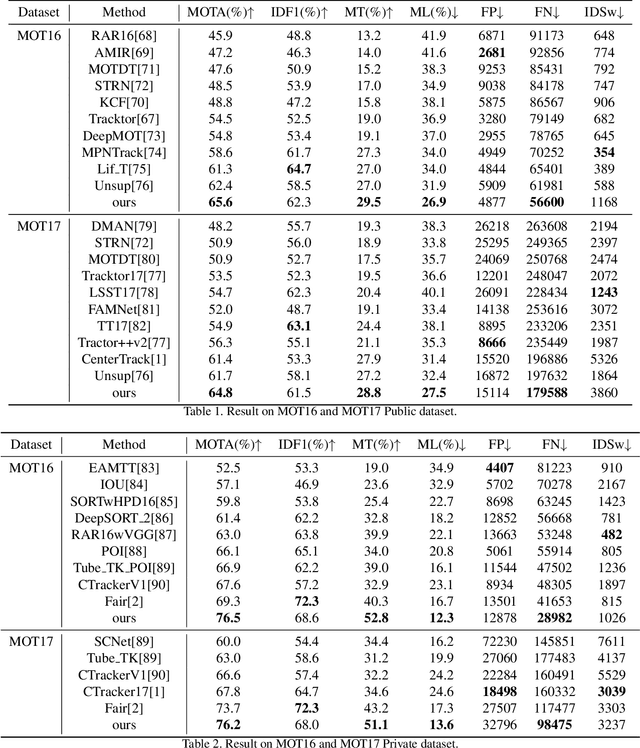
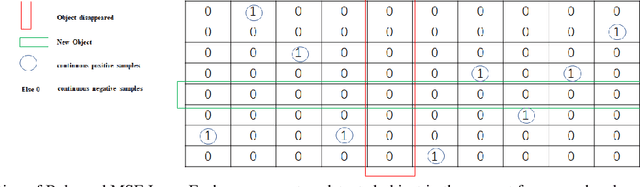
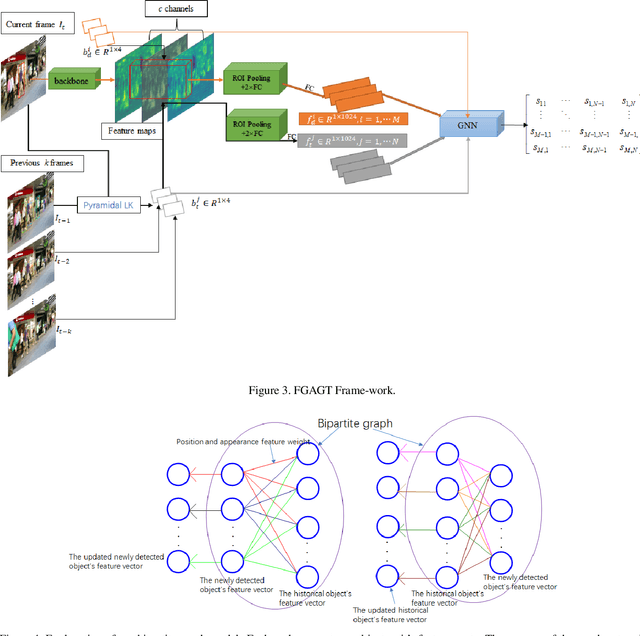
Most previous tracking methods usually use the optical flow method to estimate the position of the historical object in the current frame and then use the linear combination of feature similarity and IOU(Intersection over Union) to perform association matching near the position. However, the features used in these methods are not aligned, i.e., the features of the historical objects are extracted from the historical feature maps, not from the current frame, even the same object may undergo posture, angle, etc. changes during the movement, and even light intensity changes. In addition, most methods only use the appearance information when extracting the feature vector, not the position relationship, nor the feature information of the historical object, so the information is not fully utilized. In order to solve the above problems, we proposed the FGAGT tracker, which uses the optical flow method to predict the center position of the historical object in the current frame and extract the feature vector, so that the feature of the historical object can be aligned with the feature of the object in the current frame. Then these features are input into the graph neural network, and the global Spatio-temporal position and appearance information are integrated to update the feature vectors of all objects. In the training phase, we propose the Balanced MSE LOSS to balance the sample distribution for data association. Experiments show that our method reaches the level of state-of-the-art, where the MOTA index exceeds FairMOT by 2.5 points, and CenterTrack by 8.4 points on the MOT17 dataset, exceeds FairMOT by 1.6 points on the MOT16 dataset. Code will be avaliable.
RODNet: A Real-Time Radar Object Detection Network Cross-Supervised by Camera-Radar Fused Object 3D Localization
Feb 09, 2021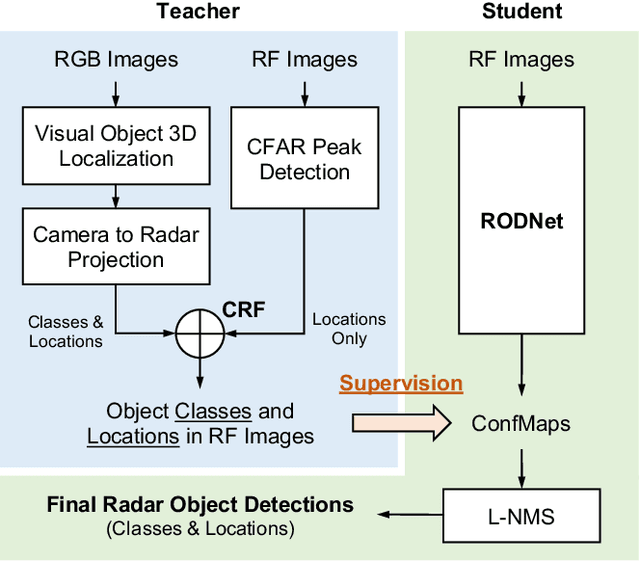
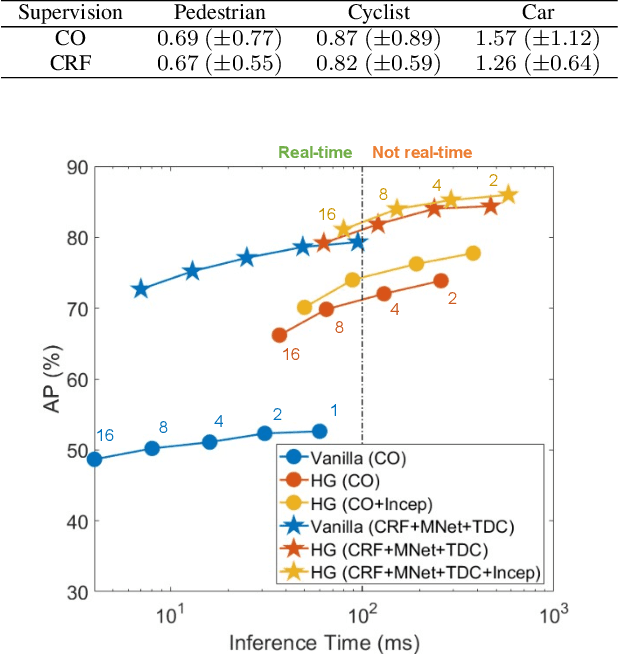
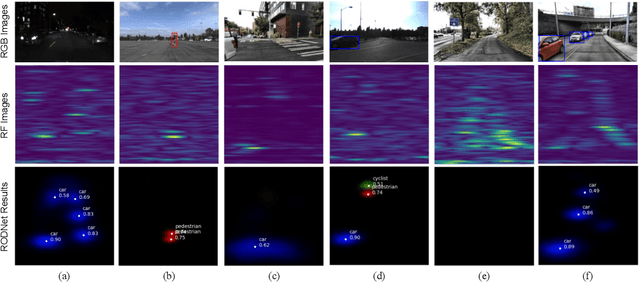
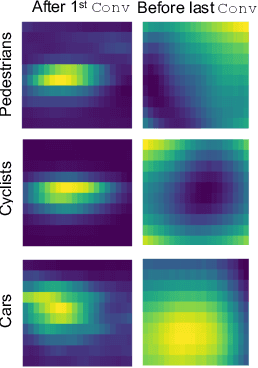
Various autonomous or assisted driving strategies have been facilitated through the accurate and reliable perception of the environment around a vehicle. Among the commonly used sensors, radar has usually been considered as a robust and cost-effective solution even in adverse driving scenarios, e.g., weak/strong lighting or bad weather. Instead of considering to fuse the unreliable information from all available sensors, perception from pure radar data becomes a valuable alternative that is worth exploring. In this paper, we propose a deep radar object detection network, named RODNet, which is cross-supervised by a camera-radar fused algorithm without laborious annotation efforts, to effectively detect objects from the radio frequency (RF) images in real-time. First, the raw signals captured by millimeter-wave radars are transformed to RF images in range-azimuth coordinates. Second, our proposed RODNet takes a sequence of RF images as the input to predict the likelihood of objects in the radar field of view (FoV). Two customized modules are also added to handle multi-chirp information and object relative motion. Instead of using human-labeled ground truth for training, the proposed RODNet is cross-supervised by a novel 3D localization of detected objects using a camera-radar fusion (CRF) strategy in the training stage. Finally, we propose a method to evaluate the object detection performance of the RODNet. Due to no existing public dataset available for our task, we create a new dataset, named CRUW, which contains synchronized RGB and RF image sequences in various driving scenarios. With intensive experiments, our proposed cross-supervised RODNet achieves 86% average precision and 88% average recall of object detection performance, which shows the robustness to noisy scenarios in various driving conditions.
Adversarially Robust Estimate and Risk Analysis in Linear Regression
Dec 18, 2020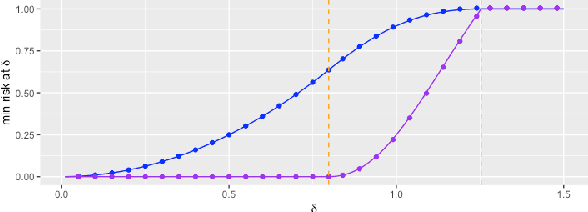

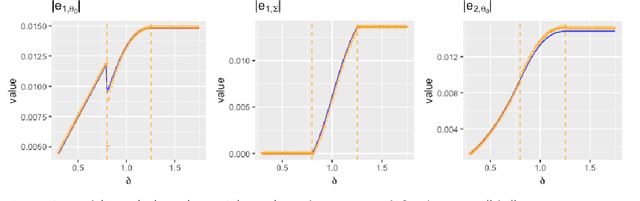
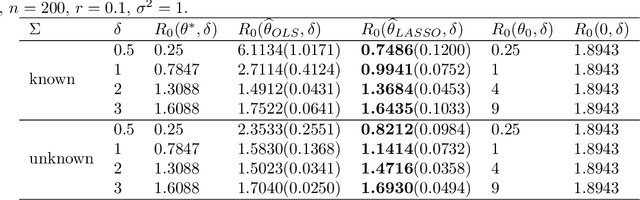
Adversarially robust learning aims to design algorithms that are robust to small adversarial perturbations on input variables. Beyond the existing studies on the predictive performance to adversarial samples, our goal is to understand statistical properties of adversarially robust estimates and analyze adversarial risk in the setup of linear regression models. By discovering the statistical minimax rate of convergence of adversarially robust estimators, we emphasize the importance of incorporating model information, e.g., sparsity, in adversarially robust learning. Further, we reveal an explicit connection of adversarial and standard estimates, and propose a straightforward two-stage adversarial learning framework, which facilitates to utilize model structure information to improve adversarial robustness. In theory, the consistency of the adversarially robust estimator is proven and its Bahadur representation is also developed for the statistical inference purpose. The proposed estimator converges in a sharp rate under either low-dimensional or sparse scenario. Moreover, our theory confirms two phenomena in adversarially robust learning: adversarial robustness hurts generalization, and unlabeled data help improve the generalization. In the end, we conduct numerical simulations to verify our theory.
2-Step Sparse-View CT Reconstruction with a Domain-Specific Perceptual Network
Dec 08, 2020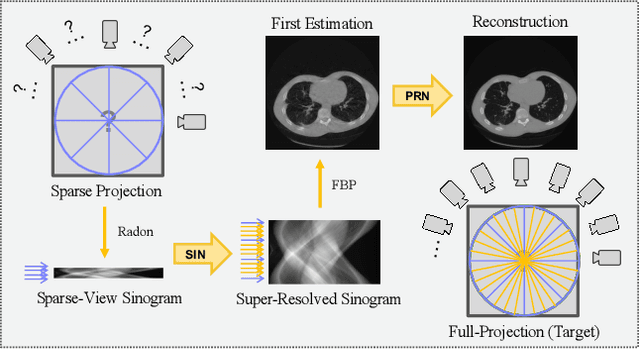
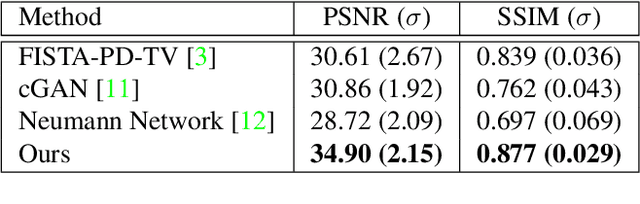
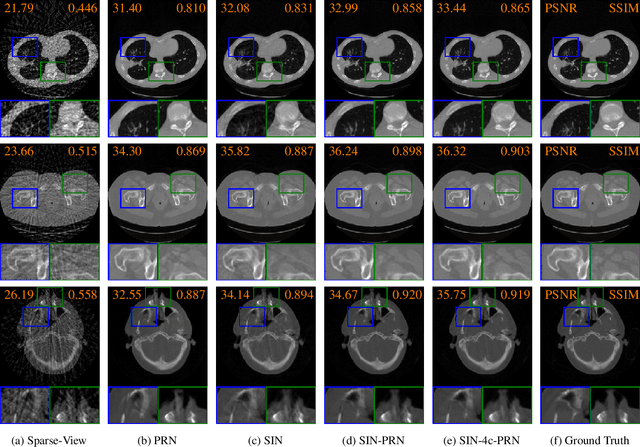
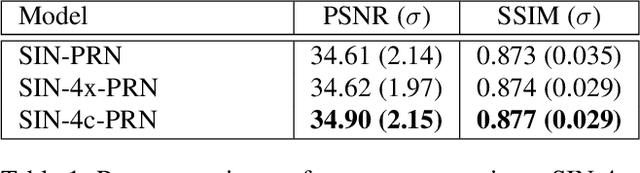
Computed tomography is widely used to examine internal structures in a non-destructive manner. To obtain high-quality reconstructions, one typically has to acquire a densely sampled trajectory to avoid angular undersampling. However, many scenarios require a sparse-view measurement leading to streak-artifacts if unaccounted for. Current methods do not make full use of the domain-specific information, and hence fail to provide reliable reconstructions for highly undersampled data. We present a novel framework for sparse-view tomography by decoupling the reconstruction into two steps: First, we overcome its ill-posedness using a super-resolution network, SIN, trained on the sparse projections. The intermediate result allows for a closed-form tomographic reconstruction with preserved details and highly reduced streak-artifacts. Second, a refinement network, PRN, trained on the reconstructions reduces any remaining artifacts. We further propose a light-weight variant of the perceptual-loss that enhances domain-specific information, boosting restoration accuracy. Our experiments demonstrate an improvement over current solutions by 4 dB.
BasicVSR: The Search for Essential Components in Video Super-Resolution and Beyond
Dec 03, 2020

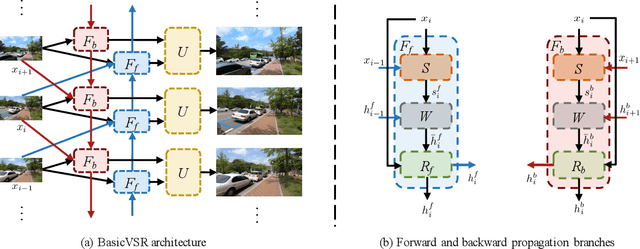
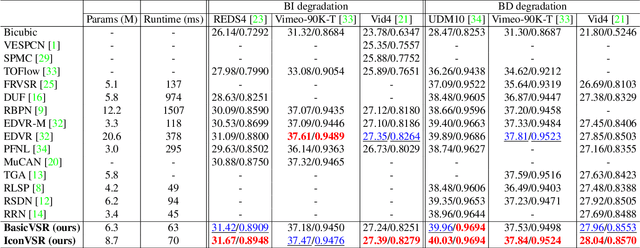
Video super-resolution (VSR) approaches tend to have more components than the image counterparts as they need to exploit the additional temporal dimension. Complex designs are not uncommon. In this study, we wish to untangle the knots and reconsider some most essential components for VSR guided by four basic functionalities, i.e., Propagation, Alignment, Aggregation, and Upsampling. By reusing some existing components added with minimal redesigns, we show a succinct pipeline, BasicVSR, that achieves appealing improvements in terms of speed and restoration quality in comparison to many state-of-the-art algorithms. We conduct systematic analysis to explain how such gain can be obtained and discuss the pitfalls. We further show the extensibility of BasicVSR by presenting an information-refill mechanism and a coupled propagation scheme to facilitate information aggregation. The BasicVSR and its extension, IconVSR, can serve as strong baselines for future VSR approaches.
Transformer Guided Geometry Model for Flow-Based Unsupervised Visual Odometry
Dec 08, 2020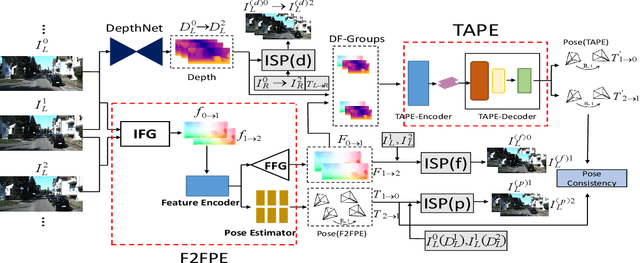
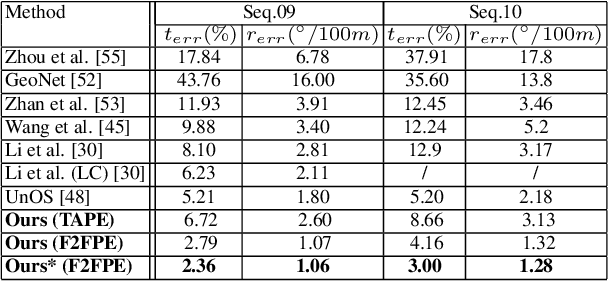
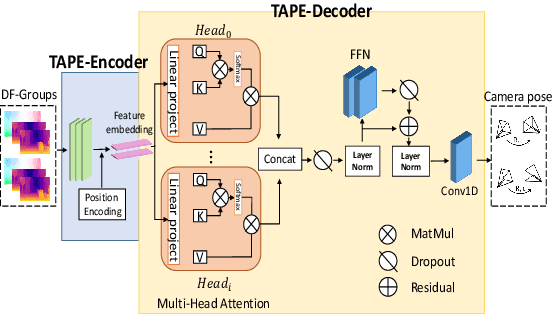
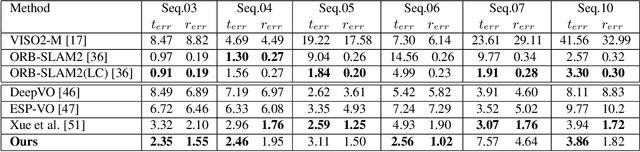
Existing unsupervised visual odometry (VO) methods either match pairwise images or integrate the temporal information using recurrent neural networks over a long sequence of images. They are either not accurate, time-consuming in training or error accumulative. In this paper, we propose a method consisting of two camera pose estimators that deal with the information from pairwise images and a short sequence of images respectively. For image sequences, a Transformer-like structure is adopted to build a geometry model over a local temporal window, referred to as Transformer-based Auxiliary Pose Estimator (TAPE). Meanwhile, a Flow-to-Flow Pose Estimator (F2FPE) is proposed to exploit the relationship between pairwise images. The two estimators are constrained through a simple yet effective consistency loss in training. Empirical evaluation has shown that the proposed method outperforms the state-of-the-art unsupervised learning-based methods by a large margin and performs comparably to supervised and traditional ones on the KITTI and Malaga dataset.