 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
The Visual-Inertial-Dynamical UAV Dataset
Mar 20, 2021
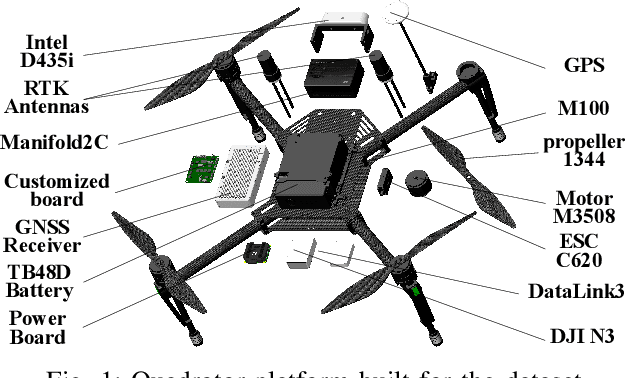
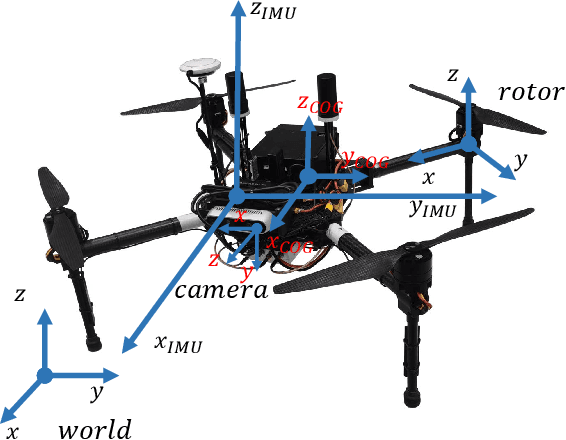
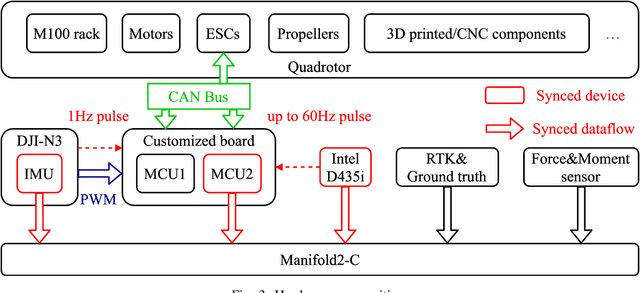

Recently, the community has witnessed numerous datasets built for developing and testing state estimators. However, for some applications such as aerial transportation or search-and-rescue, the contact force or other disturbance must be perceived for robust planning robust control, which is beyond the capacity of these datasets. This paper introduces a Visual-Inertial-Dynamical(VID) dataset, not only focusing on traditional six degrees of freedom (6DOF) pose estimation but also providing dynamical characteristics of the flight platform for external force perception or dynamics-aided estimation. The VID dataset contains hard synchronized imagery and inertial measurements, with accurate ground truth trajectories for evaluating common visual-inertial estimators. Moreover, the proposed dataset highlights the measurements of rotor speed and motor current, dynamical inputs, and ground truth 6-axis force data to evaluate external force estimation. To the best of our knowledge, the proposed VID dataset is the first public dataset containing visual-inertial and complete dynamical information for pose and external force evaluation. The dataset and related open source files are available at \url{https://github.com/ZJU-FAST-Lab/VID-Dataset}.
Lifelong update of semantic maps in dynamic environments
Oct 17, 2020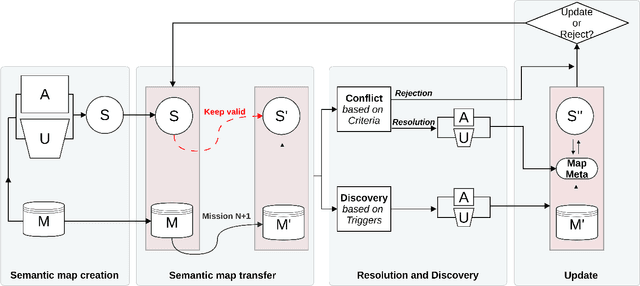
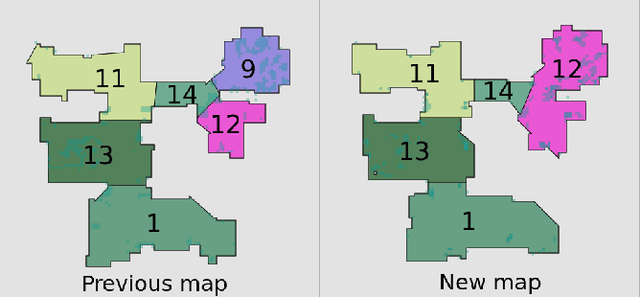
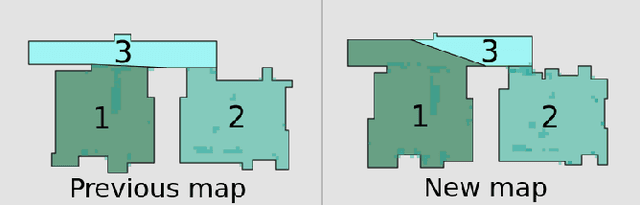
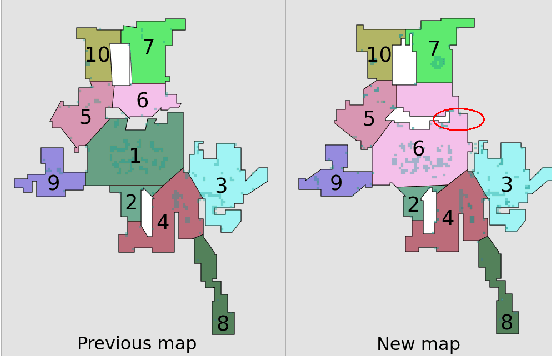
A robot understands its world through the raw information it senses from its surroundings. This raw information is not suitable as a shared representation between the robot and its user. A semantic map, containing high-level information that both the robot and user understand, is better suited to be a shared representation. We use the semantic map as the user-facing interface on our fleet of floor-cleaning robots. Jitter in the robot's sensed raw map, dynamic objects in the environment, and exploration of new space by the robot are common challenges for robots. Solving these challenges effectively in the context of semantic maps is key to enabling semantic maps for lifelong mapping. First, as a robot senses new changes and alters its raw map in successive runs, the semantics must be updated appropriately. We update the map using a spatial transfer of semantics. Second, it is important to keep semantics and their relative constraints consistent even in the presence of dynamic objects. Inconsistencies are automatically determined and resolved through the introduction of a map layer of meta-semantics. Finally, a discovery phase allows the semantic map to be updated with new semantics whenever the robot uncovers new information. Deployed commercially on thousands of floor-cleaning robots in real homes, our user-facing semantic maps provide a intuitive user experience through a lifelong mapping robot.
Graph-based Facial Affect Analysis: A Review of Methods, Applications and Challenges
Apr 05, 2021
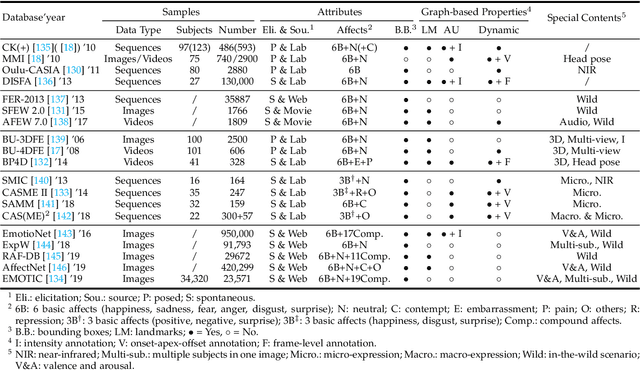
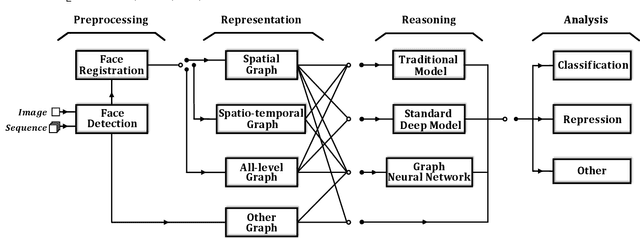
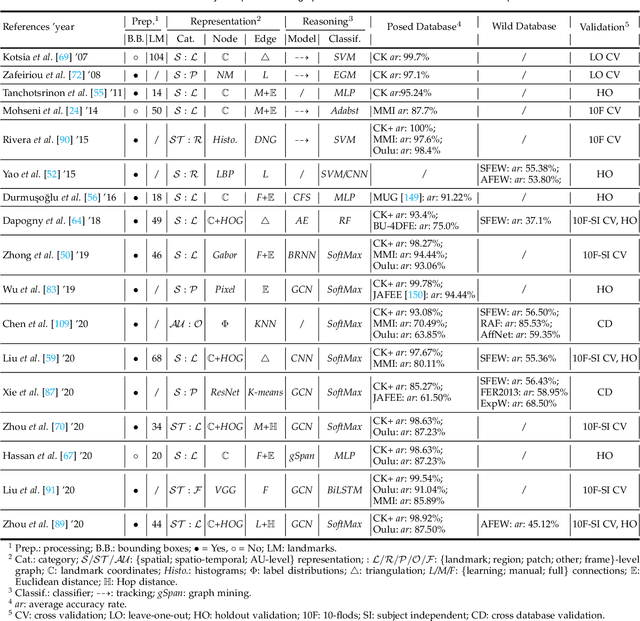
Facial affect analysis (FAA) using visual signals is a key step in human-computer interactions. Early methods mainly focus on extracting appearance and geometry features associated with human affects, while ignore the latent semantic information among individual facial changes, leading to limited performance and generalization. Recent trends attempt to establish a graph-based representation to model these semantic relationships and develop learning frameworks to leverage it for different FAA tasks. In this paper, we provide a comprehensive review of graph-based FAA, including the evolution of algorithms and their applications. First, we introduce the background knowledge of facial affect analysis, especially on the role of graph. We then discuss approaches that are widely used for graph-based affective representation in literatures and show a trend towards graph construction. For the relational reasoning in graph-based FAA, we categorize the existing studies according to their usage of traditional methods or deep models, with a special emphasis on latest graph neural networks. Experimental comparisons of the state-of-the-art on standard FAA problems are also summarized. Finally, we discuss the challenges and potential directions. As far as we know, this is the first survey of graph-based FAA methods, and our findings can serve as a reference point for future research in this field.
Combining Deep Learning and Mathematical Morphology for Historical Map Segmentation
Jan 06, 2021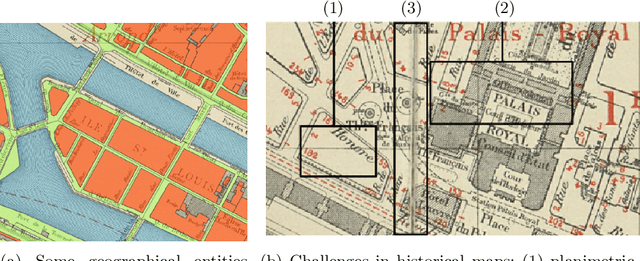
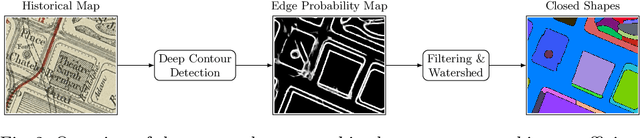


The digitization of historical maps enables the study of ancient, fragile, unique, and hardly accessible information sources. Main map features can be retrieved and tracked through the time for subsequent thematic analysis. The goal of this work is the vectorization step, i.e., the extraction of vector shapes of the objects of interest from raster images of maps. We are particularly interested in closed shape detection such as buildings, building blocks, gardens, rivers, etc. in order to monitor their temporal evolution. Historical map images present significant pattern recognition challenges. The extraction of closed shapes by using traditional Mathematical Morphology (MM) is highly challenging due to the overlapping of multiple map features and texts. Moreover, state-of-the-art Convolutional Neural Networks (CNN) are perfectly designed for content image filtering but provide no guarantee about closed shape detection. Also, the lack of textural and color information of historical maps makes it hard for CNN to detect shapes that are represented by only their boundaries. Our contribution is a pipeline that combines the strengths of CNN (efficient edge detection and filtering) and MM (guaranteed extraction of closed shapes) in order to achieve such a task. The evaluation of our approach on a public dataset shows its effectiveness for extracting the closed boundaries of objects in historical maps.
Generating Intelligible Plumitifs Descriptions: Use Case Application with Ethical Considerations
Nov 24, 2020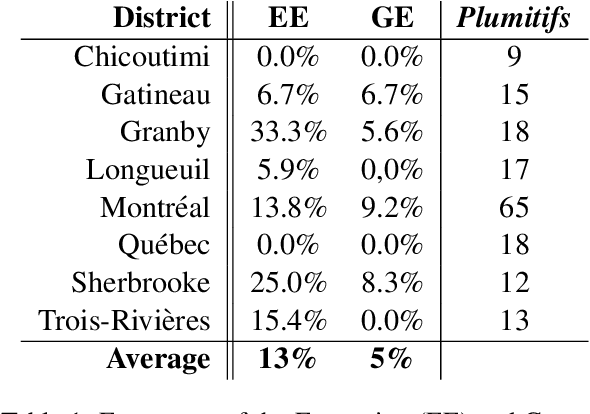
Plumitifs (dockets) were initially a tool for law clerks. Nowadays, they are used as summaries presenting all the steps of a judicial case. Information concerning parties' identity, jurisdiction in charge of administering the case, and some information relating to the nature and the course of the preceding are available through plumitifs. They are publicly accessible but barely understandable; they are written using abbreviations and referring to provisions from the Criminal Code of Canada, which makes them hard to reason about. In this paper, we propose a simple yet efficient multi-source language generation architecture that leverages both the plumitif and the Criminal Code's content to generate intelligible plumitifs descriptions. It goes without saying that ethical considerations rise with these sensitive documents made readable and available at scale, legitimate concerns that we address in this paper.
FairFil: Contrastive Neural Debiasing Method for Pretrained Text Encoders
Mar 11, 2021
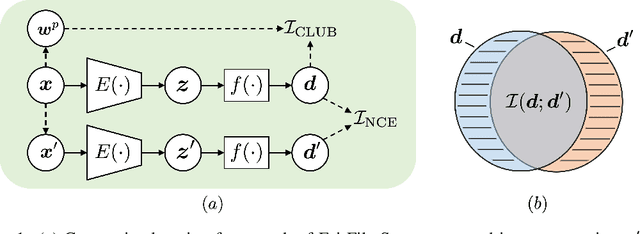
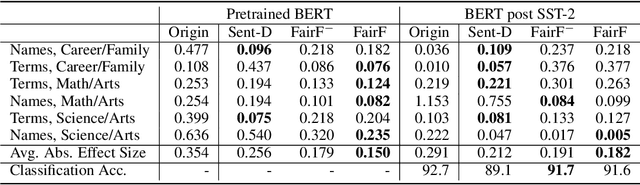
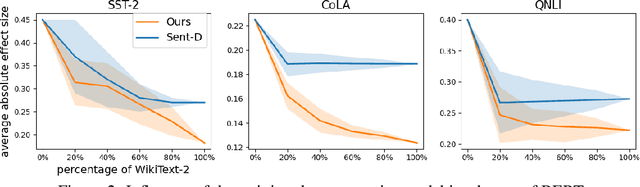
Pretrained text encoders, such as BERT, have been applied increasingly in various natural language processing (NLP) tasks, and have recently demonstrated significant performance gains. However, recent studies have demonstrated the existence of social bias in these pretrained NLP models. Although prior works have made progress on word-level debiasing, improved sentence-level fairness of pretrained encoders still lacks exploration. In this paper, we proposed the first neural debiasing method for a pretrained sentence encoder, which transforms the pretrained encoder outputs into debiased representations via a fair filter (FairFil) network. To learn the FairFil, we introduce a contrastive learning framework that not only minimizes the correlation between filtered embeddings and bias words but also preserves rich semantic information of the original sentences. On real-world datasets, our FairFil effectively reduces the bias degree of pretrained text encoders, while continuously showing desirable performance on downstream tasks. Moreover, our post-hoc method does not require any retraining of the text encoders, further enlarging FairFil's application space.
Explainable Artificial Intelligence Reveals Novel Insight into Tumor Microenvironment Conditions Linked with Better Prognosis in Patients with Breast Cancer
Apr 24, 2021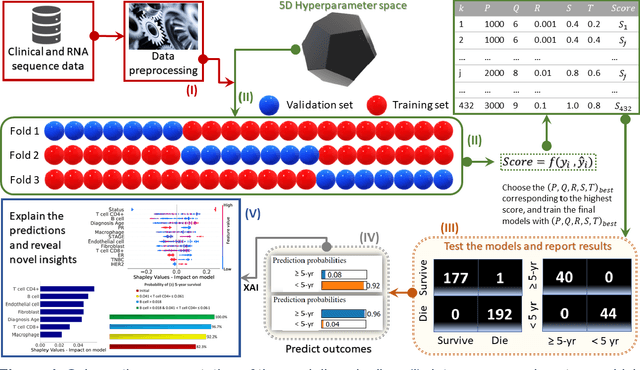
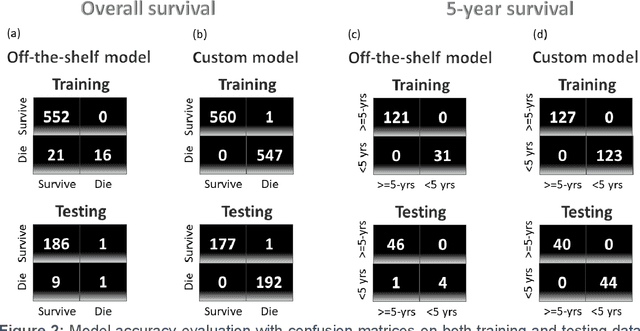
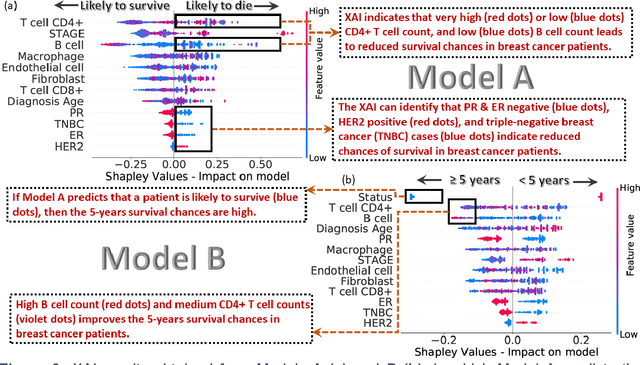
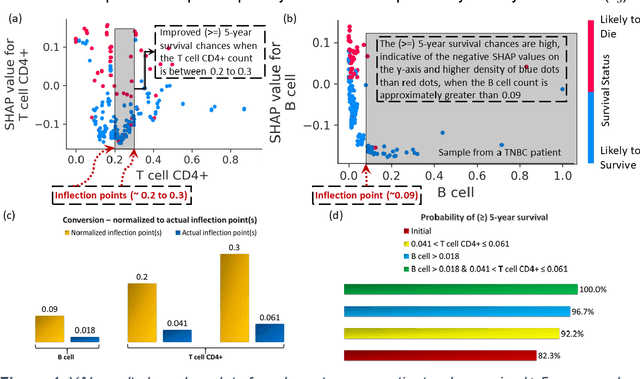
We investigated the data-driven relationship between features in the tumor microenvironment (TME) and the overall and 5-year survival in triple-negative breast cancer (TNBC) and non-TNBC (NTNBC) patients by using Explainable Artificial Intelligence (XAI) models. We used clinical information from patients with invasive breast carcinoma from The Cancer Genome Atlas and from two studies from the cbioPortal, the PanCanAtlas project and the GDAC Firehose study. In this study, we used a normalized RNA sequencing data-driven cohort from 1,015 breast cancer patients, alive or deceased, from the UCSC Xena data set and performed integrated deconvolution with the EPIC method to estimate the percentage of seven different immune and stromal cells from RNA sequencing data. Novel insights derived from our XAI model showed that CD4+ T cells and B cells are more critical than other TME features for enhanced prognosis for both TNBC and NTNBC patients. Our XAI model revealed the critical inflection points (i.e., threshold fractions) of CD4+ T cells and B cells above or below which 5-year survival rates improve. Subsequently, we ascertained the conditional probabilities of $\geq$ 5-year survival in both TNBC and NTNBC patients under specific conditions inferred from the inflection points. In particular, the XAI models revealed that a B-cell fraction exceeding 0.018 in the TME could ensure 100% 5-year survival for NTNBC patients. The findings from this research could lead to more accurate clinical predictions and enhanced immunotherapies and to the design of innovative strategies to reprogram the TME of breast cancer patients.
LexNLP: Natural language processing and information extraction for legal and regulatory texts
Jun 10, 2018LexNLP is an open source Python package focused on natural language processing and machine learning for legal and regulatory text. The package includes functionality to (i) segment documents, (ii) identify key text such as titles and section headings, (iii) extract over eighteen types of structured information like distances and dates, (iv) extract named entities such as companies and geopolitical entities, (v) transform text into features for model training, and (vi) build unsupervised and supervised models such as word embedding or tagging models. LexNLP includes pre-trained models based on thousands of unit tests drawn from real documents available from the SEC EDGAR database as well as various judicial and regulatory proceedings. LexNLP is designed for use in both academic research and industrial applications, and is distributed at https://github.com/LexPredict/lexpredict-lexnlp.
An Approximate Nonmyopic Computation for Value of Information
May 16, 2015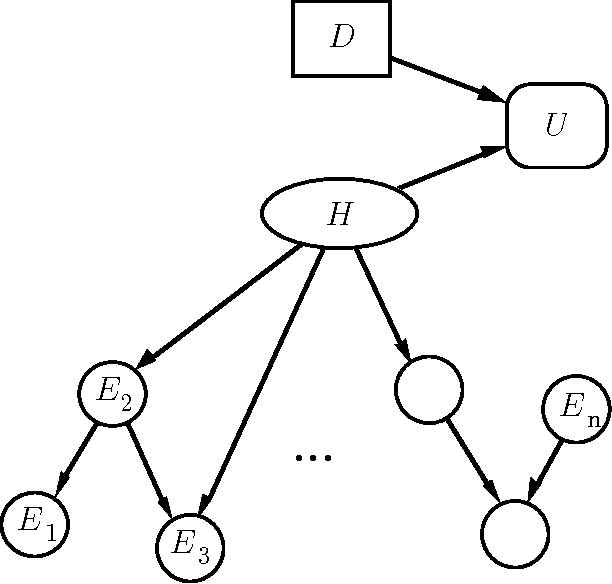
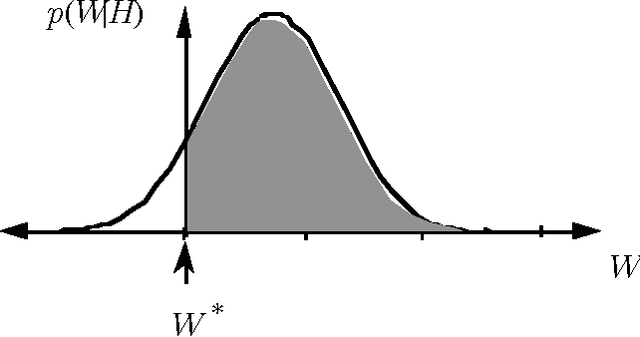
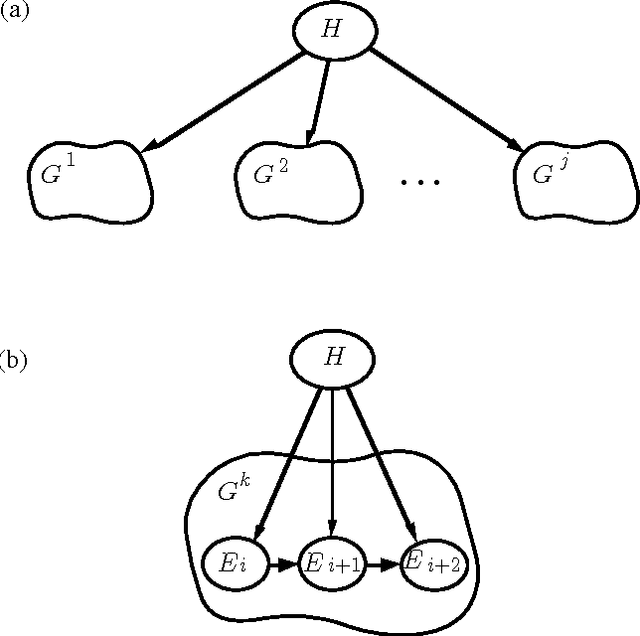
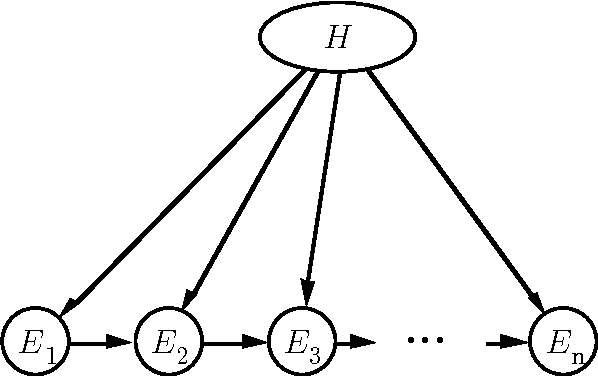
Value-of-information analyses provide a straightforward means for selecting the best next observation to make, and for determining whether it is better to gather additional information or to act immediately. Determining the next best test to perform, given a state of uncertainty about the world, requires a consideration of the value of making all possible sequences of observations. In practice, decision analysts and expert-system designers have avoided the intractability of exact computation of the value of information by relying on a myopic approximation. Myopic analyses are based on the assumption that only one additional test will be performed, even when there is an opportunity to make a large number of observations. We present a nonmyopic approximation for value of information that bypasses the traditional myopic analyses by exploiting the statistical properties of large samples.
Identifying ARDS using the Hierarchical Attention Network with Sentence Objectives Framework
Mar 10, 2021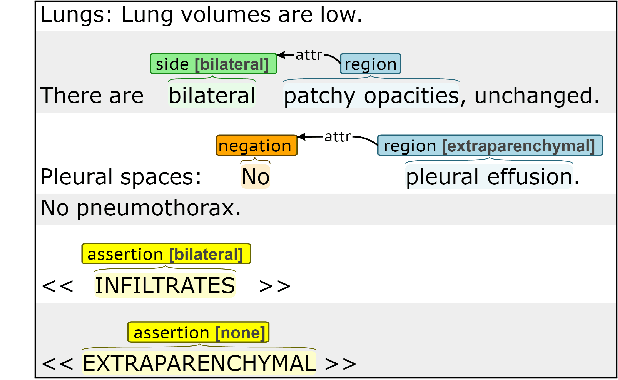
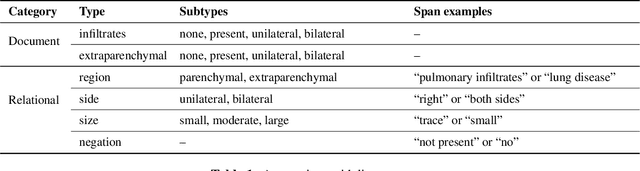

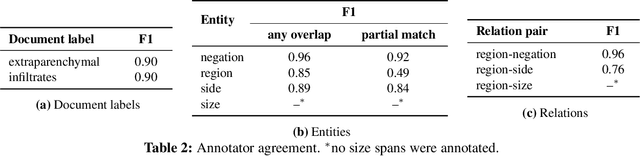
Acute respiratory distress syndrome (ARDS) is a life-threatening condition that is often undiagnosed or diagnosed late. ARDS is especially prominent in those infected with COVID-19. We explore the automatic identification of ARDS indicators and confounding factors in free-text chest radiograph reports. We present a new annotated corpus of chest radiograph reports and introduce the Hierarchical Attention Network with Sentence Objectives (HANSO) text classification framework. HANSO utilizes fine-grained annotations to improve document classification performance. HANSO can extract ARDS-related information with high performance by leveraging relation annotations, even if the annotated spans are noisy. Using annotated chest radiograph images as a gold standard, HANSO identifies bilateral infiltrates, an indicator of ARDS, in chest radiograph reports with performance (0.87 F1) comparable to human annotations (0.84 F1). This algorithm could facilitate more efficient and expeditious identification of ARDS by clinicians and researchers and contribute to the development of new therapies to improve patient care.